介绍
任务介绍
自监督学习(Self-supervised learning, SSL)是一种极具潜力的学习范式,它旨在使用海量的无标注数据来进行表征学习。在SSL中,我们通过构造合理的预训练任务(可自动生成标注,即自监督)来进行模型的训练,学习到一个具有强大建模能力的预训练模型。基于自监督学习获得的训练模型,我们可以提升各类下游视觉任务(图像分类,物体检测,语义分割等)的性能。
MMSelfSup
MMSelfSup 是一个基于 PyTorch 实现的开源自监督表征学习工具箱。
框架如下:
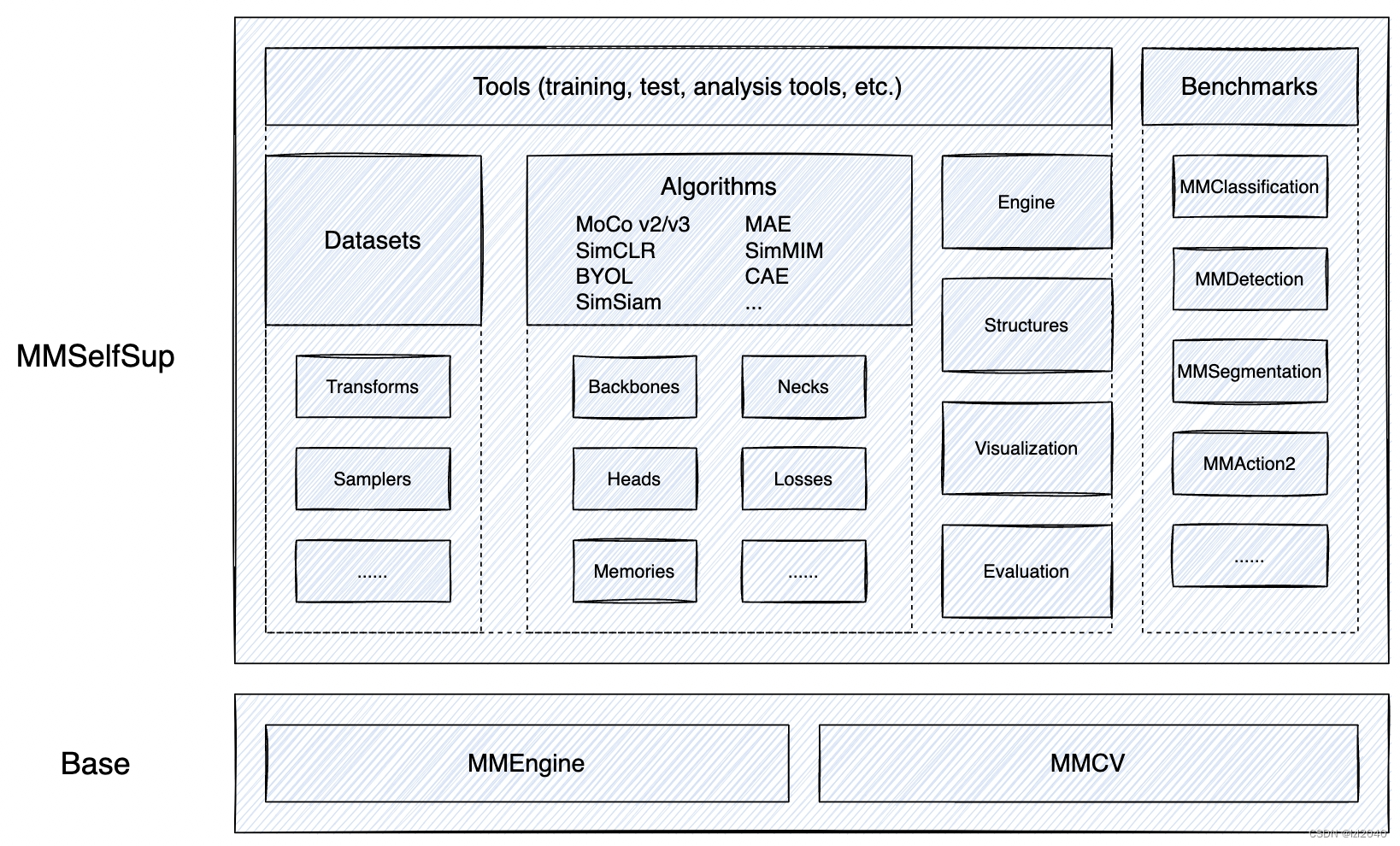
它的特点有:
- 多方法集成
MMSelfSup 提供了多种前沿的自监督学习算法,大部分的自监督预训练学习都设置相同,以在基准中获得更加公平的比较。 - 模块化设计
MMSelfSup 遵照 OpenMMLab 项目一贯的设计理念,进行模块化设计,便于用户自定义实现自己的算法。 - 标准化的性能评测
MMSelfSup 拥有丰富的基准进行评估和测试,包括线性评估, 线性特征的 SVM / Low-shot SVM, 半监督分类, 目标检测和语义分割。 - 兼容性
兼容 OpenMMLab 各大算法库,拥有丰富的下游评测任务和预训练模型的应用。
步骤
首先确保安装了pytorch。
1.安装mmcv库
pip install openmim
mim install mmcv
### 2.下载mmselfsup项目
git clone https://github.com/open-mmlab/mmselfsup.git
可以使用git,也可以在github上下载压缩包然后解压
3.进入项目主文件夹,安装所需的第三方包
cd mmselfsup-main
pip install -e .
4.找到所选定模型的配置文件,文件路径在:configs/selfsup里面
configs/selfsup下的文件如下图所示:
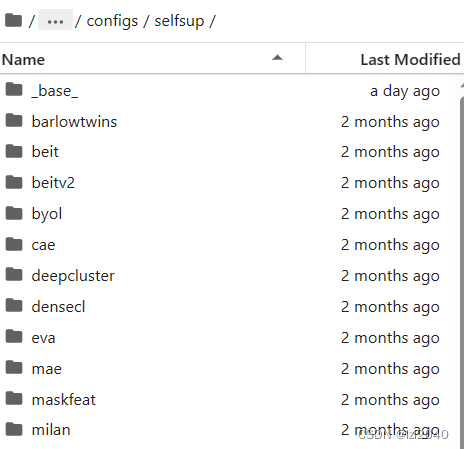
其中文件夹名字就是模型的名称,beit就代表BEIT模型。
这里我选择的是simsiam。
5.进入该文件夹,该文件夹下面存在一些配置文件,用于之后的训练过程
该文件夹下的情况如下:
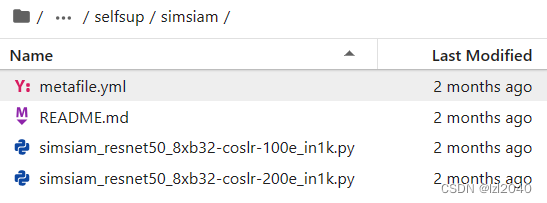
其中配置文件的命名规则为:
{模型信息}_{模块信息}_{训练信息}_{数据集信息}
simsiam_resnet50_8xb32-coslr-100e_in1k.py表示模型名称为simsiam,里面使用的模块包括resnet50,训练为8卡,batch size为32,采用cos类型的学习率变化函数,数据集为imagenet1k。
配置文件内部为:
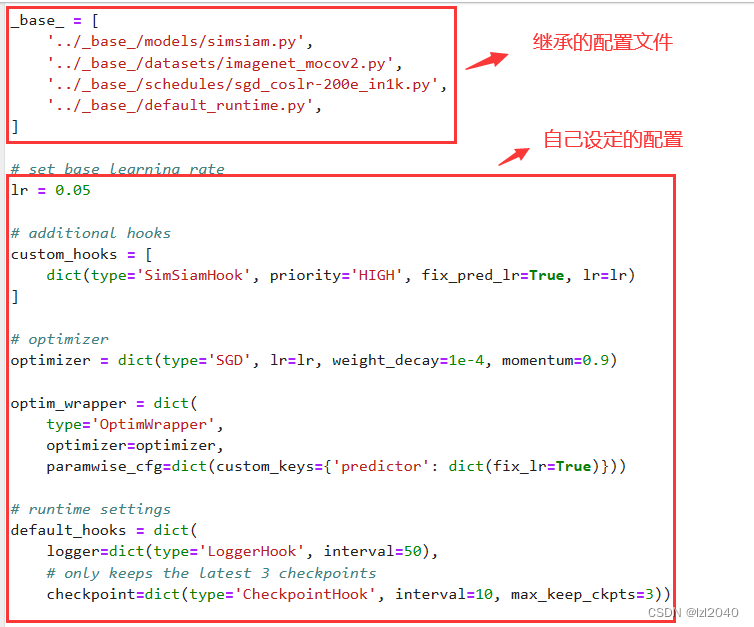
其中继承的配置文件地址在:configs/selfsup/base,如下图:
6.查看数据集的继承的配置文件
文件内部介绍
因为我们所使用的数据集的路径跟继承的配置文件中设置的路径不同,所以需要进行修改。
为此,需要先看看继承的配置文件里面是什么样的。
首先需要修改数据集的根目录:
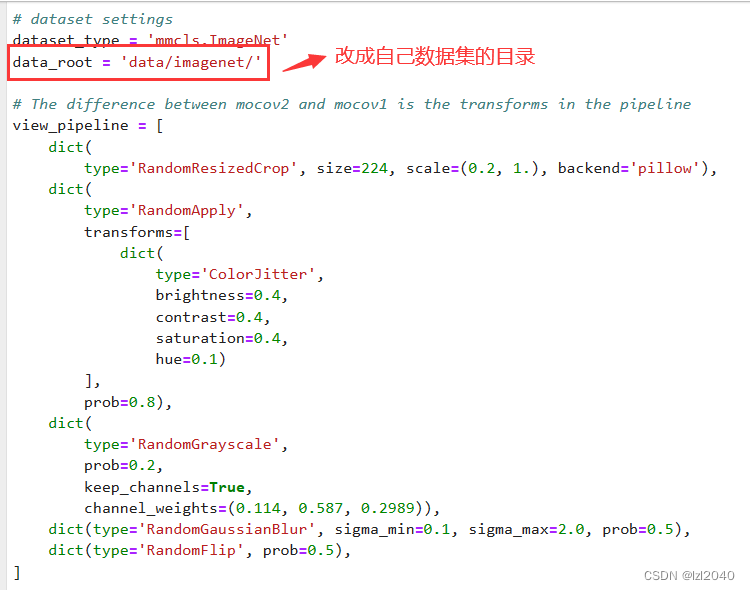
然后更改标签文件和数据文件的相对路径,改成自己的即可。
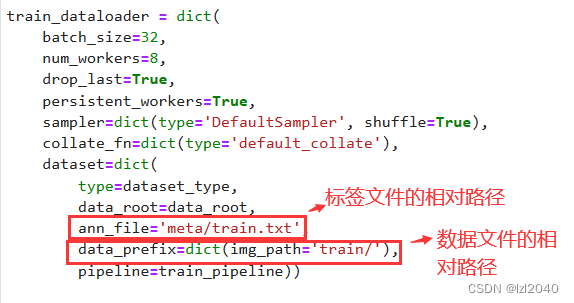
标签文件的构建
需要注意的是,除开VOC类型的,一般的数据集文件夹结构为:
data
│ ├── datasetname
│ │ ├── meta
│ │ ├── train
│ │ ├── val
其中meta文件夹里面存在标签文件,train和val文件夹里面存放数据文件,如图片。(train和val也可以放在一个文件夹里面)
对于有监督的训练,标签文件的基本组成为:
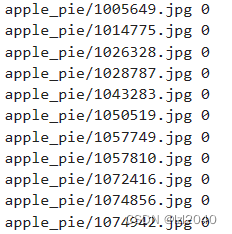
其中左边是数据文件的相对路径,右边是对应的标签。
标签文件的构建mmselfsup给我们提供了一个样例,文件路径在:tools/dataset_converters/convert_imagenet_subsets.py,按照它的思路进行修改即可。
7.构建自己的配置文件
在配置文件所在文件夹新建一个文件,命名方式跟之前说过的一致,这样便于理解。
然后根据自己的实际情况进行相应的修改,注意修改的时候定义的变量名称不是随便定义的,要和继承的文件中的名字一致。下面介绍大致流程。
首先选择继承哪个文件,这里我选择的是:simsiam_resnet50_8xb32-coslr-200e_in1k.py
_base_ = 'simsiam_resnet50_8xb32-coslr-200e_in1k.py'
注意要使用_base_,然后右边的相当于配置文件所在的路径。
然后更改学习率,因为没有采用和继承的配置文件一样的设置,所以需要修改。继承的配置文件使用的是8 * 32,而我使用的是1 * 32,因此学习率要除以8。
lr = 0.05 / 8
optimizer = dict(lr=lr)
接着修改数据集的相关设置,如:data_root
data_root = '/root/dataset/food-101/'
train_dataloader = dict(
dataset=dict(
ann_file='meta/food101_train.txt',
data_prefix=dict(img_path='images/')
)
)
最后修改训练的次数,每隔多少次保存一次模型和打印日志的间隔。
default_hooks = dict(
logger=dict(interval=10),
checkpoint=dict(interval=20, max_keep_ckpts=5)
)
train_cfg = dict(max_epochs=200)
8.进行训练
训练的代码在tools/train.py,也可以使用dist_train.sh文件。其中train.py适用于单卡,dist_train.sh可以进行分布式训练。
使用dist_train.sh进行训练的代码如下:
bash dist_train.sh ${CONFIG} ${GPUS} --cfg-options model.pretrained=${PRETRAIN}
使用train.py进行训练的代码如下:
python train.py ${CONFIG_FILE} [optional arguments]
如:python train.py /root/Project/mmselfsup-main/configs/selfsup/simsiam/simsiam_resnet50_1xb32-coslr-200e_food101.py
如果想要后台运行,改成:nohup python train.py /root/Project/mmselfsup-main/configs/selfsup/simsiam/simsiam_resnet50_1xb32-coslr-200e_food101.py &
结语
openmm系列是一个十分优秀的深度学习开源框架,里面集成了很多优秀的算法,十分值得借鉴学习,可以省去很多自己写代码的时间。





![P31[10-1]软件模拟IIC通信协议(使用stm32库函数)(内含:实物连接+IIC时序解释+硬件电路+IIC基本时序单元(起始 终止 发送接收 ))](https://img-blog.csdnimg.cn/8daa1d681c6e45aa986067e0d8329314.png)