目录
一、CAS
1、介绍
2、CAS与volatile
3、为什么无锁效率高
4、总结
二、原子整数
三、原子引用
1、介绍
2、ABA问题
3、AtomicStampedReference
4、AtomicStampedReference
四、原子累加器
1、介绍
2、LongAdder重要关键域
CAS锁
原理之伪共享
3、LongAdder源码
Add
longAccumulate方法
五、Unsafe
一、CAS
1、介绍
来看看这段代码,我们new了个AtomicInteger来实现线程安全,在更新的时候,我们先获取旧值,然后修改,然后调用compareAndSet方法更新,如果成功才返回,失败一直循环重试
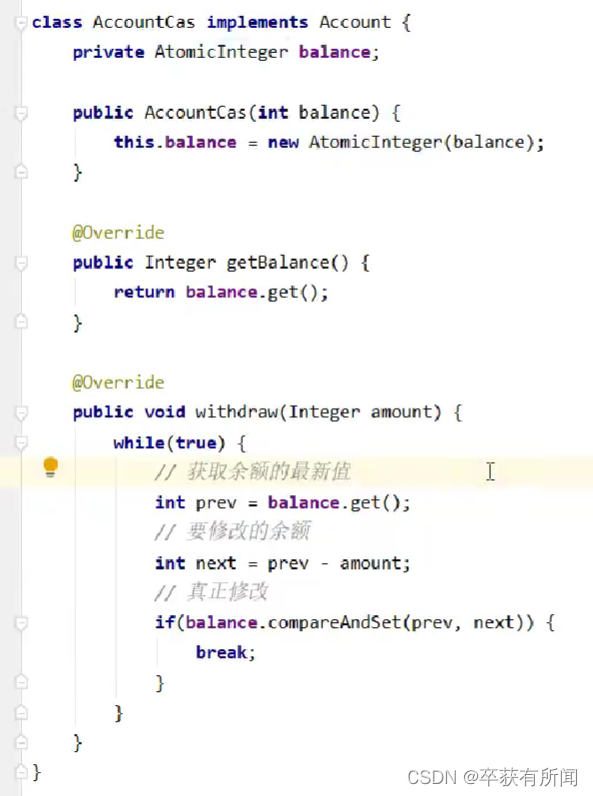
其中关键就是这个compareAndSet,这个操作是检测前后修改前和修改是不是原子性的,如果是就成功,简称就是CAS
大概的慢过程就是这样的,线程1用了cas去操作的话,如果线程修改过程中,中间有线程去改了数据,就失败重试
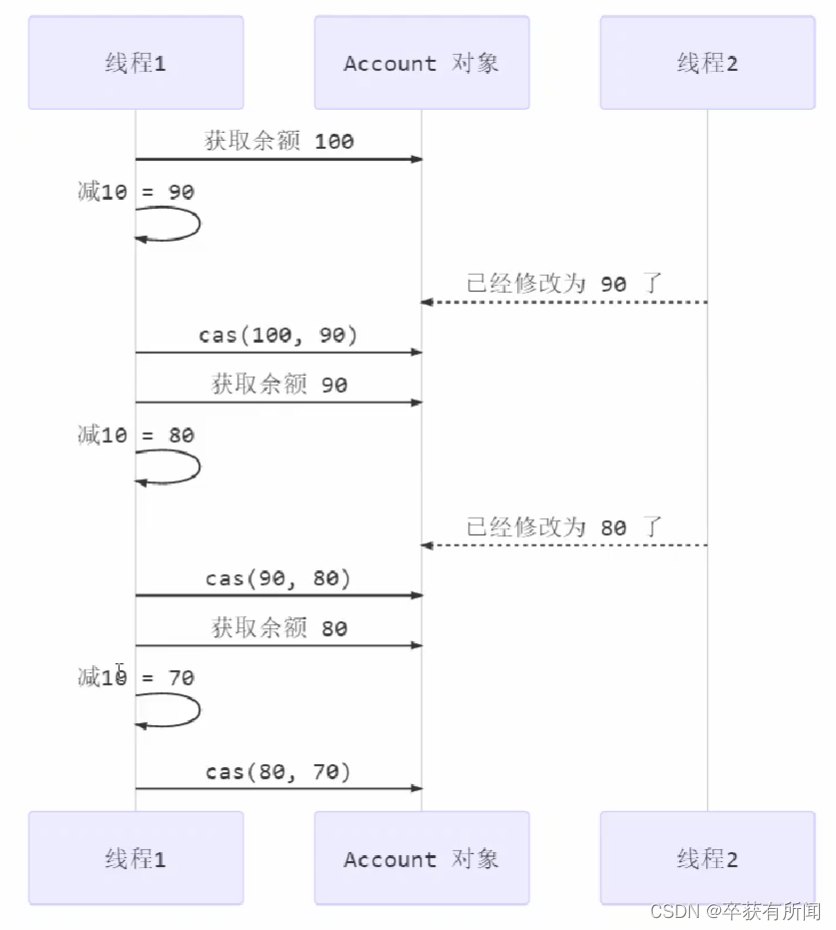
注意:cas底层是lock cmpxchg指令(x86架构)在单核cpu和多核cpu下都能保证的原子性
(在多核状态下,某个核执行到带lock的指令时,cpu会让总线锁住,当这个核把指令执行完毕,再开启总线,这个过程中不会被其他线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子性的)
2、CAS与volatile
我们点开AtomicInteger这个类,发现他的value属性加了个volatile标识,为了保证多线程下该变量的可见性。因为每次都必须要拿到最新的来cas比较,如果拿到旧的肯定就有可能直接成功了,所以cas必须要配合volatile才能发挥作用
3、为什么无锁效率高
无锁的情况下,即使重试失败,线程始终在高速运行,没有停歇,而syn会让线程在没有获锁的时候发生上下文切换(线程状态从运行到阻塞,cpu上下文切换会成本比较高的,因为他要把线程的信息进行保存,从新唤醒的时候又要恢复)
但是无锁情况下,因为线程要保证运行,需要额外的cpu支持,cpu在这里就好比高速跑道,没有额外的跑道,线程也没办法运行,虽然不会堵塞,但由于没分到时间片,仍然会进入可运行状态,还是会导致上下文切换。
4、总结
结合cas和volatile可以实现无锁并发,使用与线程数少、多核cpu的场景下
cas是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,改了就重试
synchronized是基于悲观锁的思想:得防止其他线程来修改共享变量,操作前都上锁
cas体现的是无锁并发、无阻塞并发,因为没有使用syn,所以多线程不会陷入阻塞,这是效率提升的因素之一,但是如果竞争激烈反而会影响效率。
二、原子整数
AtomicInteger为例子来讲,AtomicBoolean和AtomicLong的原理和他都是差不多的
前面讲到,底层就是用volatile修饰的value来保证可见,用cas保证线程安全
(volatile可以保证有序性,跟那个单例的原理一样,如果cpu指令重排的话,读的时候可能会出现问题,但是加了volatile写屏障就不会出现这种线赋值的问题)
在这里面有个increamentAndGet方法意思是++i,getAndIncrement方法是i++
要手动实现一个线程安全的计算:
(其中这个IntUaryOperator就是一个接口只有一个方法,交函数式接口,可以用lamda表达式来写,这样用了个策略模式来实现要做什么运算传个实现类的方法进来就行)
public static void updateAndGet(AtomicInteger i, IntUnaryOperator operator){
while(ture){
int prev = i.get();
int next = operator.applyAsInt(prev);
if(i.compareAndSet(prev, next)){
break;
}
}
}三、原子引用
1、介绍
AtomicReference,我们要保护的类型不一定是基本类型,如果要保护BigDecimal这种小数类型就需要用到原子引用来保证线程安全。
2、ABA问题
在cas过程中,只是判断前和后的值是不是相同,相同才成功,但是这个过程中其他的线程改了又改回去了,他还是可以成功的,这就是aba问题,其实变量被修改了但是那个线程察觉不到,在大部分场景下对业务并不会产生影响
3、AtomicStampedReference
如果我们想做到线程可以感知到cas中有没有被修改,就需要用到AtomicStampedReference
底层就是在AtomicReference的基础上加上了版本号,每次修改版本号都会增加
4、AtomicStampedReference
有了AtomicStampedReference版本号的机制可以知道中间被修改了多少次,但我们并不需要知道中间修改多少次,只想知道是否被改过
其实就是用boolean来标记有没有被更改过,刚开始是true,只要被修改过就会变为false,如果false就不能成功,成功后自己也会把他变为false
四、原子累加器
1、介绍
JAVA 8后为了加快原子整数的自增效率,专门设计的自增类,就是LongAdder。是并发大师Doug Lea的作品,设计的非常精巧
性能提升的原理:因为因为每次都会是更新一个单元,cas在有竞争的时候要不断重试可能影响效率,所以他设置了多个单元,线程1改1单元Cell,2改2单元,因此减少了cas重试次数,从而提高性能,但是不会超过cpu的核心数,因为没有意义了
2、LongAdder重要关键域
在这个自增类LongAdder中有几个关键的设计

CAS锁
cas锁就是用个atomicInteger去修改,如果为0就用cas把他修1,修改成功就是加锁成功,释放锁就改成0,因为释放的时候只有拿锁线程所以不用加锁。这种cas锁平时项目中不要写,因为可能会导致问题,没拿到锁的线程会一直重试,占cpu资源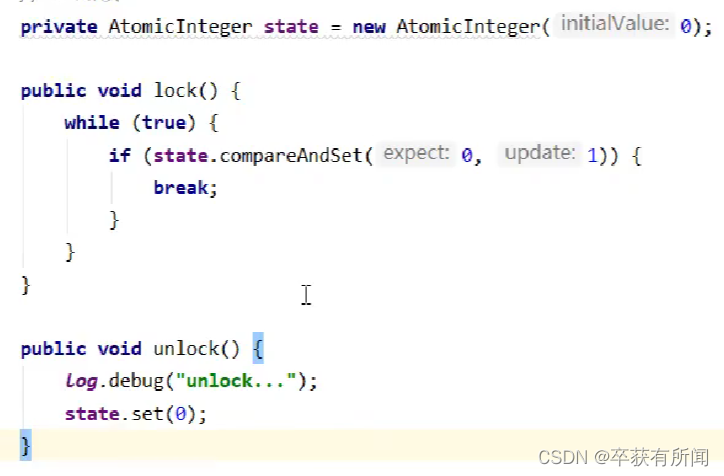
其实源码中的cellsBusy就是类似上面这个cas锁,用来做加锁的标记,用来保证某些情况的线程安全,我们在Cell[]创建或者扩容的时候会用到他。
原理之伪共享
其中Cell即为累加单元

Cell类就是有个value属性来记录增加的数量,然后构造器给他赋值,然后有个cas方法来做自增,但是我们可以看到类上有个注解Contended,这个注解是来防止缓存行伪共享的
什么是缓存行?
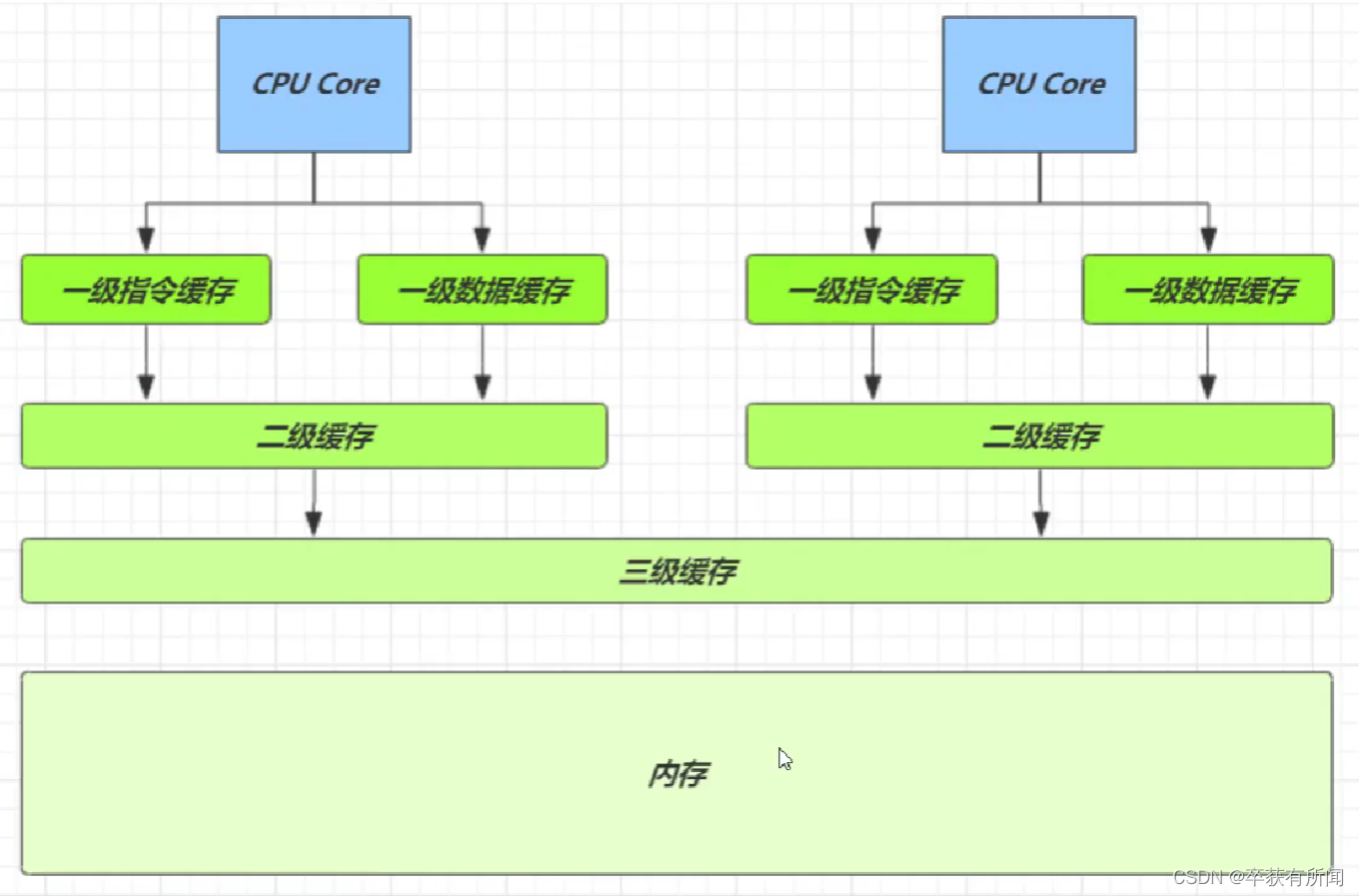
缓存其实是有很多层的,越接近的约快,一级花奴才能的速度回比内存快几十倍,缓存一缓存行为单位,每个缓存行对应着一块内存,一般64byte(8个long)
虽然缓存可以提高效率,但是可能造成数据副本的产生,同一份数据会缓存再不同核心的缓存行中,cpu要保证数据一致性,如果某个cpu核心改了数据,其他cpu核心对应的整个缓存行必失效,这样可能会影响效率,就是会把一个缓存行的全部
举个栗子:
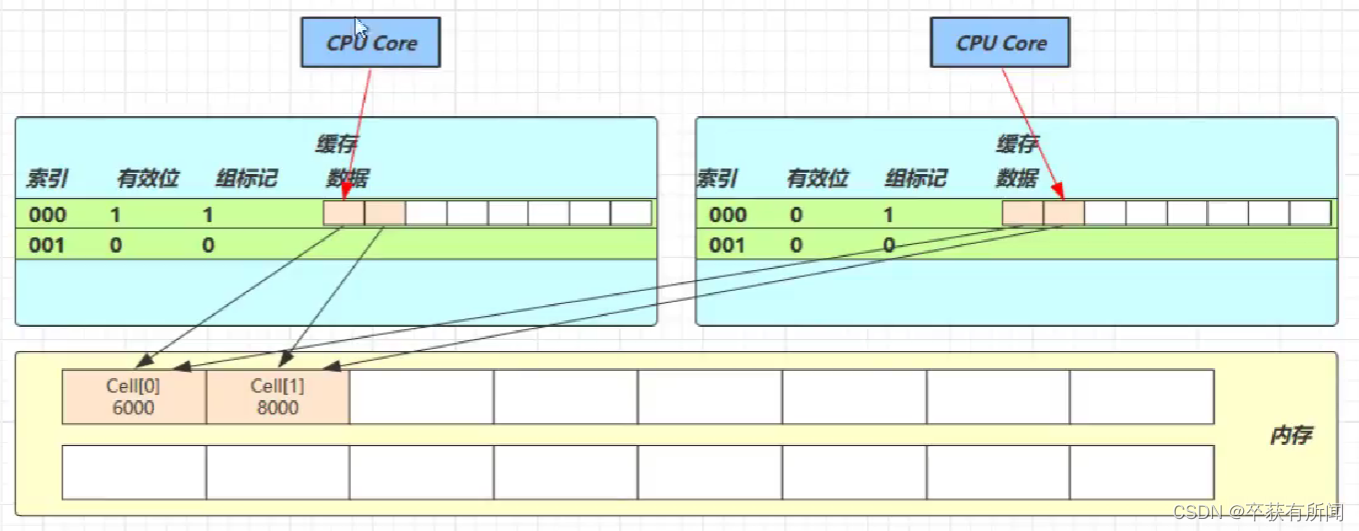
如上图,我们的cell数组形式存储,在内存中是连续的,一个cell为24字节,因此缓存行可以存下2个cell对象,这样问题就来了,核心1要改cell[0],核心1要改cell[1],无论谁成功,都会让对方core的缓存行失效,因为他们在一个缓存行里面,别的修改了他就会失效,这样又要重新去内存读
@sum.misc.Contended注解用来解决这个问题,他的原理是在使用此注解的对象或字段前后各增加128字节大小的padding,从而让cpu将对象预读到缓存时占用不同的缓存行,这样,就不会造成对方的缓存行的失效

为什么是128?
GPT:在JDK 8中,
@Contended注解的实现方式是通过在注解标记的变量前后添加一定数量的填充(Padding)字节来实现的。这些填充字节会将注解标记的变量与其他变量分开,从而避免多个线程同时访问同一缓存行的不同变量。填充字节的长度通常是2的整数次幂,因为缓存行的长度通常是2的整数次幂。在大多数现代处理器上,缓存行的长度通常是64字节或者128字节。因此,@Contended注解在缓存行上加的长度通常是缓存行长度的整数倍,这样可以保证注解标记的变量与其他变量之间有足够的填充字节,从而避免伪共享问题。在JDK 8中,@Contended注解默认的填充字节数是128字节,因为这是大多数现代处理器上缓存行的长度。
3、LongAdder源码
Add

他首先会判断cells数组是不是为空,cells数组是懒惰创建的,一开始没有竞争时是null,竞争发生的时候才会尝试创建数组和累加单元cell。
如果判断为空说明没有竞争,直接去基础数据base里面累加,如果累加成功就返回,不成功就进入longAccumlate方法,进行cells和cell的创建
如果判断cells不为空,看当前线程是否创建cell,创建了就cas对cell累加,累加失败或者没有创建cell也走longAccumulate
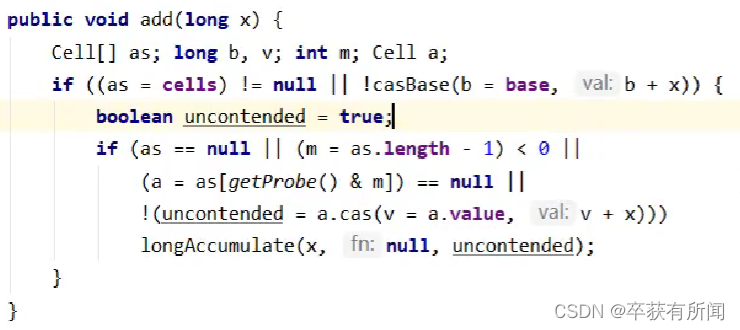
longAccumulate方法
当线程基础base累加失败或者当前线程的cell累加失败或者没有创建cells都会进入这个方法
创建cells

当cells没有创建的时候,他会走创建cells
如果cellsBusy标志位为0(cas锁的标志位,用来保证创建数组时的安全),cells==as,表示未被其他线程创建,还有个条件当cas加锁成功,才能创建成功cells并初始化一个cell(创建一开始是大小为2的数组并默认一个cell单元,然后只给当前线程创建一个cell,是和1去&随机分配到0或1位置上,只初始化一个cell,懒加载后面用到再初始化cell)
加锁失败的话就cas在base上进行累加,成功就return,失败就回到顺循重新尝试
创建cell
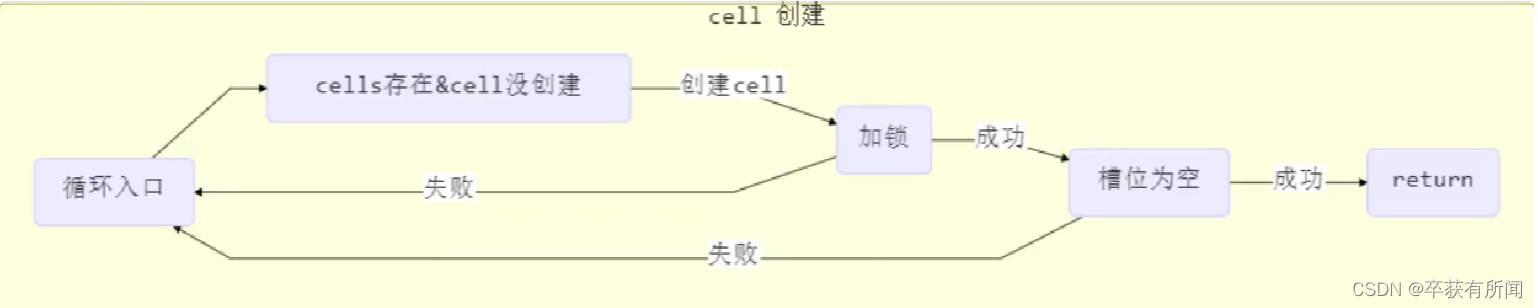
数组创建出来只会给当前线程创建累加单元cell,假如其他线程来看到有数组cells,但是没有cell就会创建。
也是会先cellsBusy这个cas锁来创建,如果为0就是可以加锁,创建一个cell对象,然后判断一下cas加锁成功还会再次检查数组是不是空,cell有没有被创建,如果没问题就把对象赋值到空的槽位上,然后成功。中间有判断失败就重新循环重试
cas累加cell
先判断cells和cell都存在,成功就cas对cell进行累加,成功返回,失败就检查数组长度是不是大于cpu的上线,如果大于就不扩容,小于就会加锁进行扩容,没拿到锁和刚刚的大于cpu上线都没办法扩容,这个时候就会尝试给他换一个cell重新循环看看能不能累加成功。如果直接cpu小于且拿到cas锁,直接扩容。
扩容是重新new了个原来的长度<<1的数组(扩大两倍),再把旧数组的内容拷贝到新数组再替换,最后扩容成功还是会重新循环,这次循环可能会创建个新的cell对象来递增
sum方法
这么多个累加单元最终的统计操作就是用的这个sum方法,其实就是直接循环这个数字如果不为空就一直累加,最后返回

五、Unsafe
Unsafa对象提供了非常底层,操作内存、线程的方法,不能直接调用,只能通过反射获得
他是sum.misc包下的类,final不能被继承,他有个私有的静态final单列变量,所以只能通过反射去活动,因为比较底层所以不建议编程人员使用就叫unsafe
AtomicInteger的incrementAndGet(++i)就是用了这个unsafe对象的getAndAddInt方法
用unsafe的objectFeildOffset方法就能获取到他在内存中的偏移量,然后就可以直接操作内存(用cas的compareAndSwap方法传入对象和偏移量和修改前后的值)

![P31[10-1]软件模拟IIC通信协议(使用stm32库函数)(内含:实物连接+IIC时序解释+硬件电路+IIC基本时序单元(起始 终止 发送接收 ))](https://img-blog.csdnimg.cn/8daa1d681c6e45aa986067e0d8329314.png)