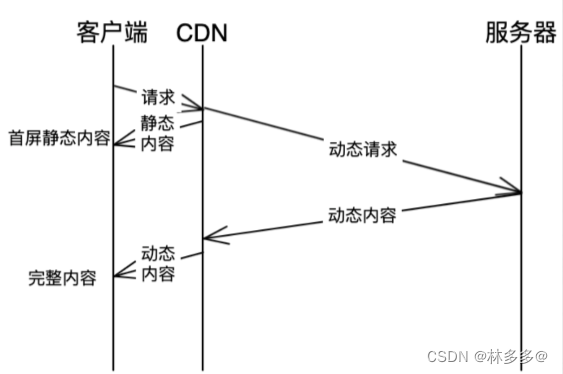
正式观看本文之前,设想一个问题,高并发情况下,首页列表数据怎么做?

类似淘宝首页,这些商品是从数据库中查出来的吗?答案肯定不是,在高并发的情况下,数据库是扛不住的,那么我们要怎么去扛住C端端大并发量呢,这快我们可以借助Redis,我们知道Redis是一个基于内存的NoSQL数据库。学过操作系统我们都知道,内存要比磁盘的效率大的多,那我们Redis就是基于内存的,而数据库是基于磁盘的。
我们现在知道要用Redis去做首页数据的分页,那么我们应该用Redis的那种数据结构来做呢。
Redis有5种基本的数据结构,我们这里用list类型做分页。
在 Redis 中,List(列表)类型是按照元素的插入顺序排序的字符串列表。你可以在列表的头部(左边)或者尾部(右部)添加新的元素。
ok,那么接下来我们就通过一个案例实操一下,首页热点数据怎么放到Redis中去查询。
SpringBoot整合RedisTemplate这里就不做过多介绍啦,大家可以网上找篇博文 整合一下。
<!-- 创建SpringBoot项目加入redis的starter依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
编写ProductService,定于数据分页方法。
public interface ProductService {
Map<String,Object> productListPage(int current, int size) throws InterruptedException;
}
编写ProductServiceImpl实现类。
/**
* @author lixiang
* @date 2023/6/18 21:01
*/
@Service
@Slf4j
public class ProductServiceImpl implements ProductService {
private static final String PRODUCT_LIST_KEY = "product:list";
private static final List<Product> PRODUCT_LIST;
//模拟从数据库中查出来的数据
static {
PRODUCT_LIST = new ArrayList<>();
for (int i = 1; i <= 100; i++) {
Product product = new Product();
product.setId(UUID.randomUUID().toString().replace("-", ""));
product.setName("商品名称:" + i);
product.setDesc("商品描述:" + i);
product.setPrice(new BigDecimal(i));
product.setInventory(2);
PRODUCT_LIST.add(product);
}
}
@Autowired
private RedisTemplate redisTemplate;
@Override
public Map<String, Object> productListPage(int current, int size) throws InterruptedException {
//从缓存中拿到分页数据
List<Product> productList = getProductListByRedis(current, size);
if (productList == null || productList.size() == 0) {
log.info("当前缓存中无分页数据,当前页:" + current + ",页大小:" + size);
//从数据库中拿到分页数据
productList = getProductListByDataSource(current, size);
}
Map<String, Object> resultMap = new HashMap<>();
//计算当前总页数
int totalPage = (PRODUCT_LIST.size() + size - 1) / size;
resultMap.put("total", PRODUCT_LIST.size());
resultMap.put("data", productList);
resultMap.put("pages", totalPage);
return resultMap;
}
private List<Product> getProductListByRedis(int current, int size) {
log.info("从Redis取出商品信息列表,当前页:" + current + ",页大小:" + size);
// 计算总页数
int pages = pages(size);
// 起始位置
int start = current <= 0 ? 0 : (current > pages ? (pages - 1) * size : (current - 1) * size);
// 终止位置
int end = start+size-1;
List<Product> list = redisTemplate.opsForList().range(PRODUCT_LIST_KEY, start, end);
List<Product> productList = list;
return productList;
}
/**
* 获取商品信息集合
*
* @return
*/
private List<Product> getProductListByDataSource(int current, int size) throws InterruptedException {
//模拟从DB查询需要300ms
Thread.sleep(300);
log.info("从数据库取出商品信息列表,当前页:" + current + ",页大小:" + size);
// 计算总页数
int pages = pages(size);
// 起始位置
int start = current <= 0 ? 0 : (current > pages ? (pages - 1) * size : (current - 1) * size);
//数据缓存到redis中
redisTemplate.opsForList().rightPushAll(PRODUCT_LIST_KEY, PRODUCT_LIST);
//设置当前key过期时间为1个小时
redisTemplate.expire(PRODUCT_LIST_KEY,1000*60*60, TimeUnit.MILLISECONDS);
return PRODUCT_LIST.stream().skip(start).limit(size).collect(Collectors.toList());
}
/**
* 获取总页数
* @param size
* @return
*/
private Integer pages(int size){
int pages = PRODUCT_LIST.size() % size == 0 ? PRODUCT_LIST.size() / size : PRODUCT_LIST.size() / size + 1;
return pages;
}
}
ok,然后编写controller,进行测试。
@RestController
@RequestMapping("/api/v1/product")
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/page")
public Map<String,Object> page(@RequestParam("current") int current,@RequestParam("size") int size){
Map<String, Object> stringObjectMap;
try {
stringObjectMap = productService.productListPage(current, size);
} catch (InterruptedException e) {
stringObjectMap = new HashMap<>();
}
return stringObjectMap;
}
}
当第一次访问的时候,先去Redis中查询,发现没有,然后就去查DB,将要缓存的数据页放到Redis中。



第二次访问的时候。就直接访问Redis啦



通过Redis和DB查询的对比,我们发现从Redis中拿出来只用了18ms,从公DB中需要300ms,由此可见Redis的一个强大之处。
那么我们观察一下查询逻辑,会不会有什么问题。
public Map<String, Object> productListPage(int current, int size) throws InterruptedException {
//从缓存中拿到分页数据
List<Product> productList = getProductListByRedis(current, size);
if (productList == null || productList.size() == 0) {
log.info("当前缓存中无分页数据,当前页:" + current + ",页大小:" + size);
//从数据库中拿到分页数据
productList = getProductListByDataSource(current, size);
}
}
设想,假如某一时刻,Redis中的缓存失效啦,大量的请求,全部查到DB上,也会带来一个灾难。所以这快又涉及到一个缓存击穿的问题。
解决缓存击穿
- 方案一:永不过期
- 提前把热点数据不设置过期时间,后台异步更新缓存。
- 方案二:加互斥锁或队列
- 其实我理解缓存击穿和缓存穿透差不多,所以加一个互斥锁,让一个线程正常请求数据库,其他线程等待即可(这里可以使用线程池来处理),都创建完缓存,让其他线程请求缓存即可。
OK,整篇的案例整合 我们就到这里,觉得博主写的不错的,记得给个三连哦!!!





![[Day 3 of 17]Building a document scanner in OpenCV](https://img-blog.csdnimg.cn/ebf4ca234a8948de9503262c55651dae.png)