目录
一、Elasticsearch下载
二、安装
三、启动
四、安装可视化插件(elasticsearch-head)
1、下载地址
2、解压缩下载好的压缩文件
3、进入解压缩目录
五、解决跨域问题
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。
Elasticsearch 的实现原理主要分为以下几个步骤
- 首先用户将数据提交到Elasticsearch 数据库中
- 再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据
- 当用户搜索数据时候,再根据权重将结果排名,打分
- 再将返回结果呈现给用户。
Elastic Stack(ELK stack)
E---Elasticsearch 数据存储、查询
L---Logstash 数据收集和日志解析引擎
K---Kibana 分析和可视化平台
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elasticsearch是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
总结起来就是,在大数据量时使用Elasticsearch可以提高搜索效率。
最常见的使用场景就是电商网站搜索商品,或者在日志系统中搜索日志时,或者百度等搜索引擎等等。如果使用传统的关系型数据库进行模糊查询,那么就有可能会出现索引失效的情况,导致执行效率非常的低(数据量大的情况下)
如:select age from user where name like “%航%”
Elasticsearch概念(以下简称Elastic )
| 关系型数据库 | Elasticsearch |
| 数据库(database) | 索引index |
| 表(tables) | 类型Types(8.x后会弃用) |
| 行(rows) | 文档documents |
| 字段(columns) | 字段fields |
Elastic (集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下可以包含多个文档(行),每个文档中可以包含多个字段(列)文档可以嵌套
1、 Node 与 Cluster
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
2、 Index(相当于MySQL中的Database)
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
3、 Document(相当于MySQL中的Table里的行记录)
Index 里面单条的记录称为 Document(文档)。
许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,下面是一个例子。
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
4、 Type(相当于MySQL中的Table)------以后会弃用,了解即可
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
elasticsearch下载、安装、启动
一、Elasticsearch下载
声明:最低要求JDK1.8(需要配置号当前的Java环境变量)
官网下载:Download Elasticsearch | Elastic
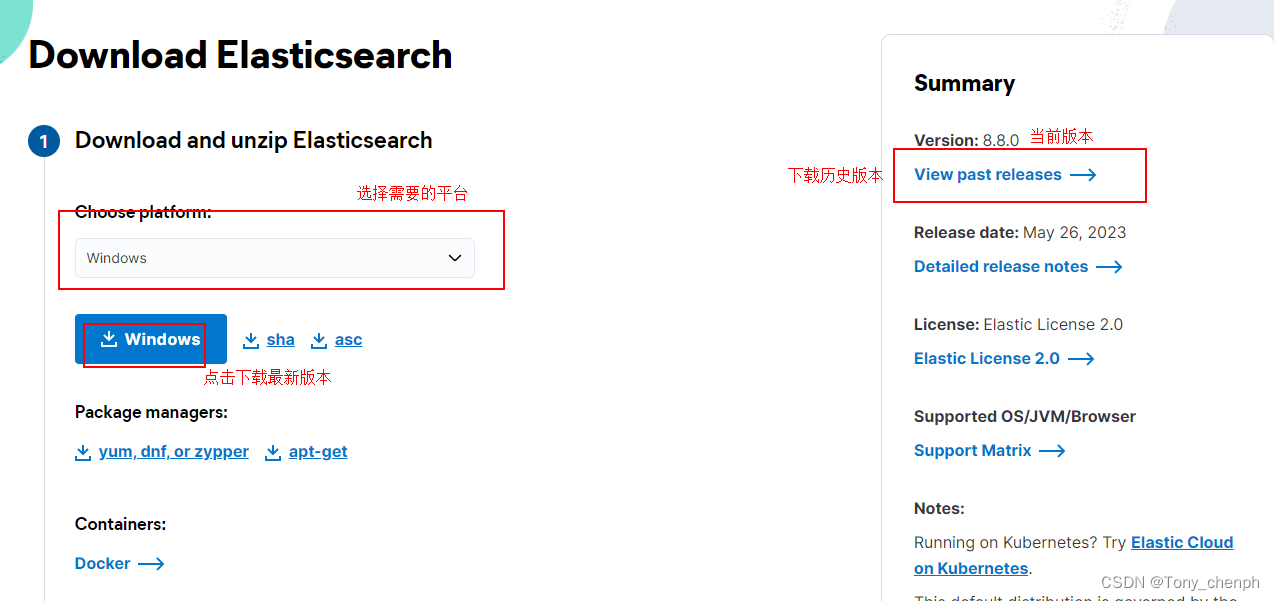
二、安装
将步骤一下载好的文件(elasticsearch-7.6.1-windows-x86_64.zip)解压缩到合适的路径下(一般路径不含中文、空格)

目录介绍:
bin 启动文件
config 配置文件
log4j2.properties 日志配置
jvm.options java虚拟机相关参数的配置
elasticsearch.yml elasticsearch默认配置文件,默认9200端口
jdk java环境相关
lib elasticsearch相关jar包
logs 日志文件
modules 功能模块
plugins 插件安装位置,如ik分词器插件
三、启动
进入elasticsearch目录的bin目录,双击打开elasticsearch.bat启动
启动完成后访问http://127.0.0.1:9200/

四、安装可视化插件(elasticsearch-head)
声明:elasticsearch-head是一个前端项目,启动时需要依托nodejs,所以需要提前安装好nodejs
1、下载地址
https://github.com/mobz/elasticsearch-head

2、解压缩下载好的压缩文件
3、进入解压缩目录
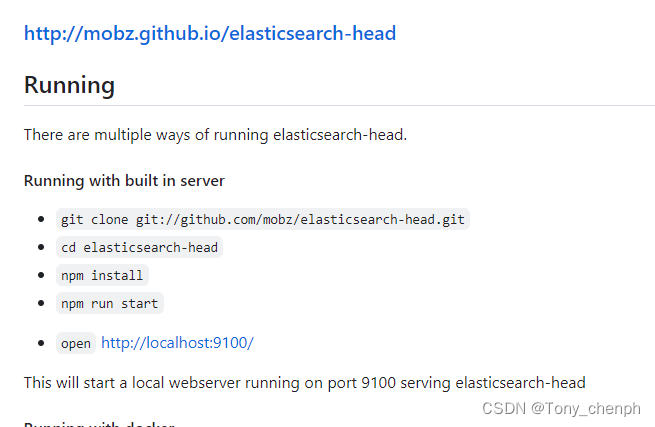
npm install(需要联网,最终在解压缩的目录下得到一个文件夹node_modules)
首次运行时需要执行此命令,后续则直接进到解压缩目录直接运行启动命令即可
启动运行
npm run start
访问http://localhost:9100/

此时发现连接不上elasticSearch,F12打开控制台窗口
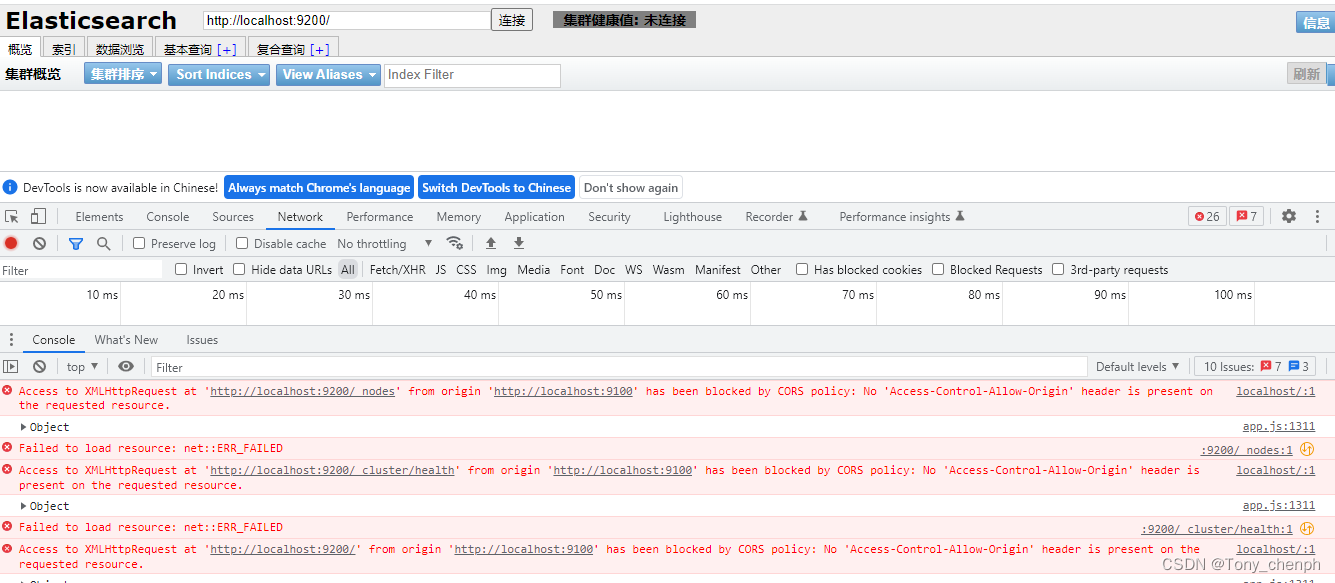
发现是由于跨域导致访问失败
跨域问题:
http://localhost:9200/
http://localhost:9100/
请求协议://IP:端口号
只要协议、IP、端口号有一个不同都是跨域
五、解决跨域问题
打开elasticsearch的配置文件,在最后添加跨域支持,保存修改重启服务即可
D:\elasticSearch\elasticsearch-7.6.1\config\elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
重启elasticsearch服务后重新访问http://localhost:9100/
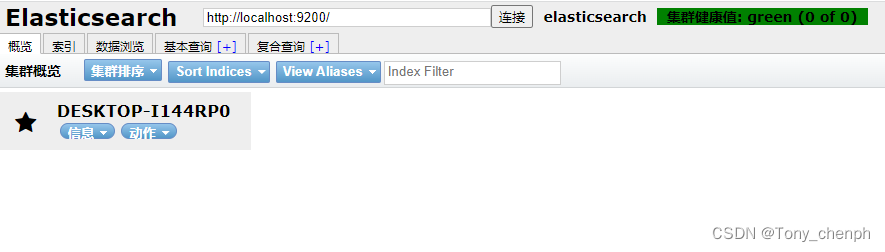
一般可以使用head插件作为数据展示的工具,elasticSearch的相关操作指令(新增索引,查询等操作)通过kibana来完成