【问题描述】
编写程序统计一个英文文本文件中每个单词的出现次数(词频统计),并将统计结果按单词字典序输出到屏幕上。
注:在此单词为仅由字母组成的字符序列。包含大写字母的单词应将大写字母转换为小写字母后统计。
【输入形式】
打开当前目录下文件article.txt,从中读取英文单词进行词频统计。
【输出形式】
程序将单词统计结果按单词字典序输出到屏幕上,每行输出一个单词及其出现次数,单词和其出现次数间由一个空格分隔,出现次数后无空格,直接为回车。
【样例输入】
当前目录下文件article.txt内容如下:
Do not take to heart every thing you hear.;
Do not spend all that you have.;
Do not sleep as long as you want;
【样例输出】
all 1
as 2
do 3
every 1
have 1
hear 1
heart 1
long 1
not 3
sleep 1
spend 1
take 1
that 1
thing 1
to 1
want 1
you 3
【样例说明】
输出单词及其出现次数。
数据集下载:wordcount数据集
提取码:k3v2
代码实现:
#include <fstream>
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <omp.h>
using namespace std;
int main(int argc, char* argv[]) {
int n = atoi(argv[1]); //线程数
ifstream file("input.txt");
string word;
vector<string> words;
map<string, int> wordCount;
while (file >> word) {
for (int i = 0; i < word.length(); i++) {
if (ispunct(word[i])) {
word.erase(i--, 1);
}
}
words.push_back(word);
}
omp_set_num_threads(n); //设置线程数
double starttime = omp_get_wtime();
#pragma omp parallel for
for (int i = 0; i < words.size(); i++) {
#pragma omp critical
{
wordCount[words[i]]++;
}
}
double endtime = omp_get_wtime();
for (auto it = wordCount.begin(); it != wordCount.end(); it++) {
cout << it->first << ": " << it->second << endl;
}
printf("\n并行时间:%lfs\n", endtime - starttime);
return 0;
}
编译:g++ ./filename.cpp -o ./filename -fopenmp
运行:./filename n n为设置的线程数
运行结果:
一个进程:
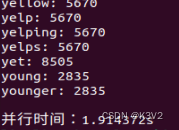
4个进程:
可以看到4个进程比
比一个的慢了差不多一倍,这是由于通讯时间比交耗时造成的。
加速比为:1.914/2.751= 0.6957470010905125
由于通讯时间较长反而没达到加速效果。
OpenMP基本概念
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
在VS中启用OpenMP很简单,很多主流的编译环境都内置了OpenMP。在项目上右键->属性->配置属性->C/C++->语言->OpenMP支持,选择“是”即可。
OpenMP执行模式
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:
OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
编译制导
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。常用的功能指令如下:
parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行;
for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
parallel for:parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
sections:用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
parallel sections:parallel和sections两个语句的结合,类似于parallel for;
single:用在并行域内,表示一段只被单个线程执行的代码;
critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
flush:保证各个OpenMP线程的数据影像的一致性;
barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
atomic:用于指定一个数据操作需要原子性地完成;
master:用于指定一段代码由主线程执行;
threadprivate:用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别。
相应的OpenMP子句为:
private:指定一个或多个变量在每个线程中都有它自己的私有副本;
firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
num_threads:指定并行域内的线程的数目;
schedule:指定for任务分担中的任务分配调度类型;
shared:指定一个或多个变量为多个线程间的共享变量;
ordered:用来指定for任务分担域内指定代码段需要按照串行循环次序执行;
copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
copyin:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
default:用来指定并行域内的变量的使用方式,缺省是shared。
利用omp_set_num_threads()来设置线程数,
利用#pragma omp parallel sections 声明下面大括号中的语句要并行多线程执行;
利用#pragma omp section 分配线程。
看懂下列helloworld的代码对openmp并行就会有一定了解。