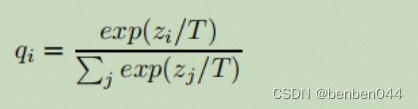文章目录
- 摘要
- 问题
- 算法
- 3.1 文生图扩散模型
- 3.2 个性化文生图模型
- 3.3 特定类别先验保留损失
- 实验
- 评估方式
- 比较
- 消融实验
- PPL
- 类别先验
- 应用
- 限制
- 结论
论文: 《DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation》
project: https://dreambooth.github.io/
第三方代码: https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
摘要
文本生成图像模型取得不错进展,但是无法根据提供的参考集生成新模态。DreamBooth利用预训练模型语义先验及新的特定目标先验保留损失合成未出现在参考图中的各种场景、姿势、视角、光照下目标。
问题
现有文本生成图片模型无法依据参考图生成该目标。
算法
仅需3-5张图像不需要任何文本描述,即可通过各种prompt引导生成目标变体。
3.1 文生图扩散模型
损失函数如式1,对于初始噪声
ϵ
∈
N
(
0
,
I
)
\epsilon \in N(0, I)
ϵ∈N(0,I),x为真值。
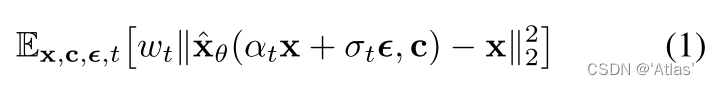
3.2 个性化文生图模型
常规思路是通过少量数据集进行finetune,但是容易出现过拟合及模式坍塌。但是作者发现大规模文生图扩散模型擅长整合新信息且不会遗忘先验知识,也不会过拟合到小规模训练集。
作者设计prompt为“a [identifier] [class noun]”,[identifier]为目标相关固定标识符,[class noun]为目标类别描述,比如猫、狗。如果不使用类别描述或使用错误类别描述将导致增加训练时间或者发生语言偏移,进而降低表现。
标识符使用常见单词或随机字母,效果相似,因为每个字母分别进行tokenize,因此作者使用词汇中不常见token
f
(
V
^
)
f( \hat V)
f(V^)转换进文本空间
V
^
\hat V
V^。
3.3 特定类别先验保留损失
直接finetune所有模型所有层将导致语言偏移;同时可能导致输出多样性降低。
针对上述问题作者提出一种自生特定类别先验损失用于保证多样性同时抑制语言偏移。该方法本质上使用生成样本监督模型。损失函数如式2,其中
C
p
r
C_{pr}
Cpr仅包含类别信息,图3展示该过程。
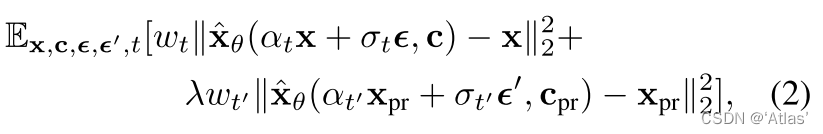
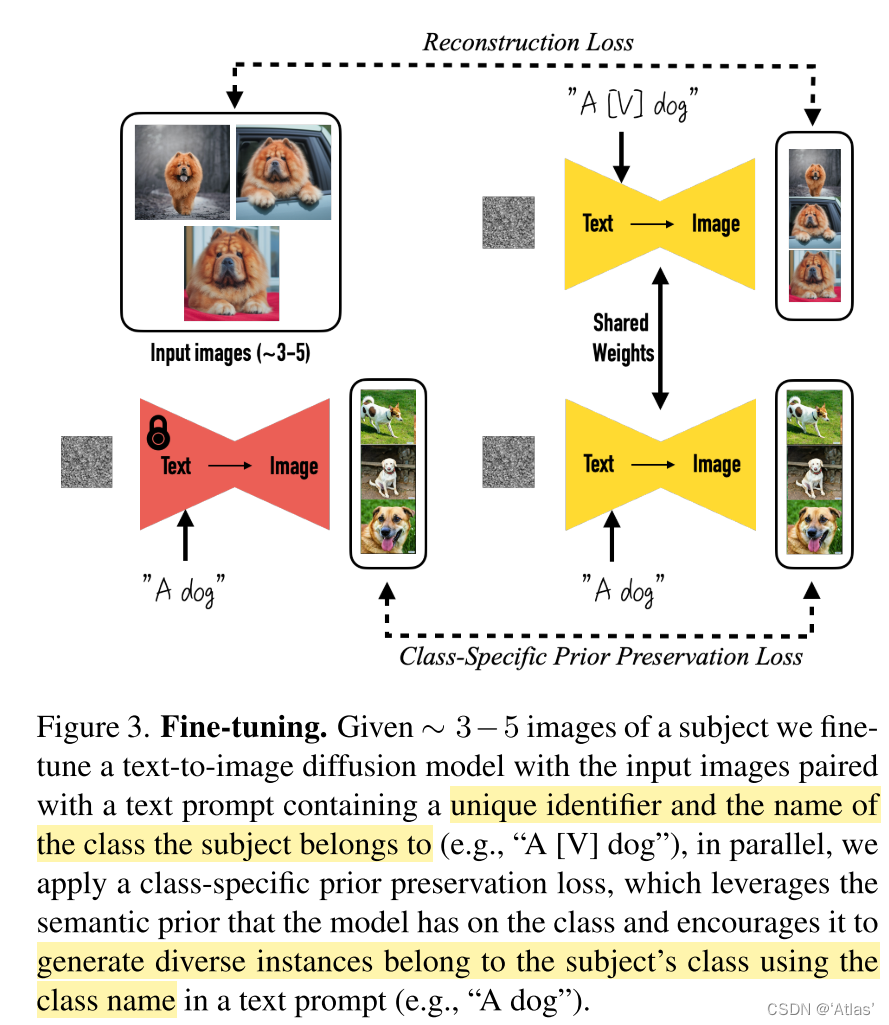
实验
评估方式
- CLIP-I:CLIP的提取生成图与真图的embedding,计算两者之间的余弦相似度;
- DINO:ViT- S/16 DINO提取生成图与真图的embedding,计算两者之间的余弦相似度;
- CLIP-T:计算prompt机图像的CLIP embedding之间余弦相似度
比较
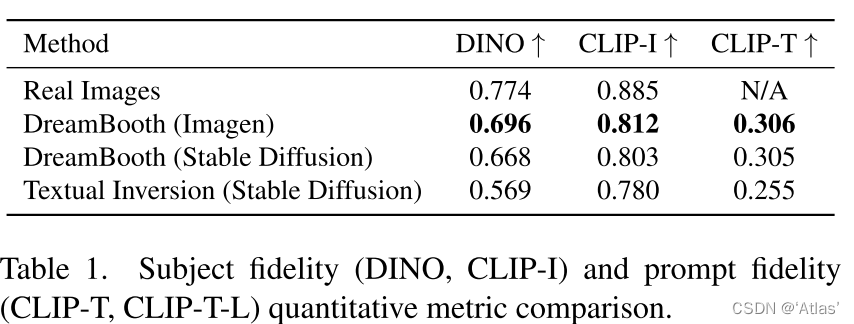
表1作者比较DreamBooth超越Textual Inversion,同时使用Imagen优于使用Stable Diffusion,
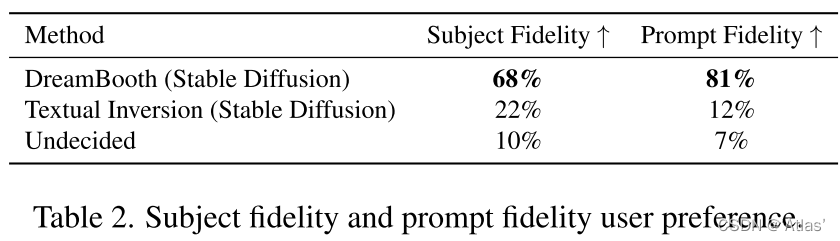
表2展示人工评测结果,在目标精确度以及prompt一致性上DreamBooth优于Textual Inversion;结合表1,量化指标微小差异,对用户直观感受差异巨大。可视化结果如图4.

消融实验
PPL
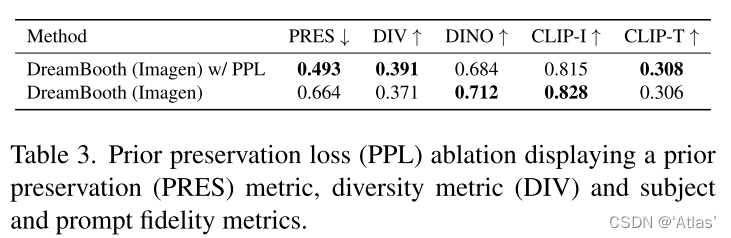
作者比较prior preservation loss (PPL)影响,结果如表3,评估方式为PRES,计算先验类别随机生成目标与真实图指定目标之间DINO embedding距离,该指标越高表明目标多样性不足,发生模式坍塌。同时作者使用平均LPIPS进行多样性评估(DIV)。作者发现使用PPL具有更高多样性,可视化结果如图6。

类别先验
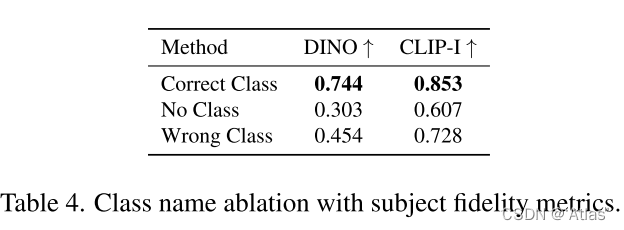
使用类别先验,可生成各种纹理目标;使用错误类别,将导致生成奇怪物体;不使用类别先验,导致模型难以拟合,进而生成错误目标。实验结果如表4。
应用
重构。可生成在不同环境中目标,如图7。

艺术再现。如图8
新颖视角生成。如图8,仅使用4张正面图可生成未见过视角:侧面、上面、下面。
属性修改。如图8,输入prompt为:“a cross of a [V] dog and a [target species]”

限制

图9为一些失败案例。
作者归因于:
a.较弱先验,或者目标与特定概念很少出现在训练集;
b.环境与目标外观耦合;
c.过拟合到真实图片,当prompt与真实图相似时易出现。
同时对于一些比较少见目标,模型难以生成该目标多个变体。
结论
作者提出的DreamBooth,仅需要3-5张目标图片,通过prompt引导就可生成该目标变体。该方法核心为将该目标与特定标识符绑定。