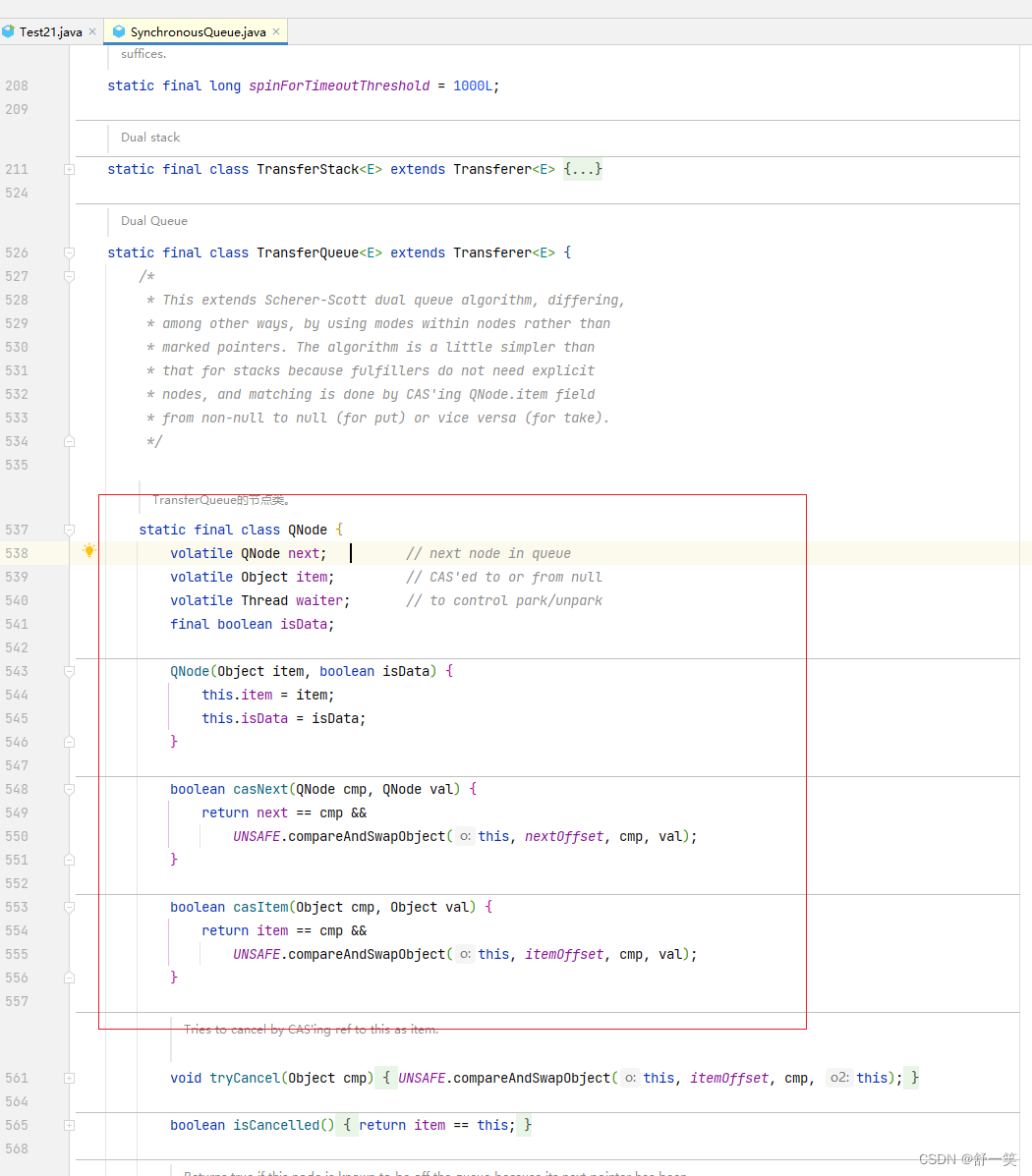
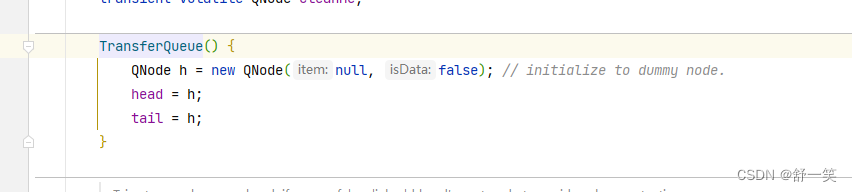
QNode的源码信息分析
- 一行一行的分析大概内容;下面会省略大量的CAS操作
- 当前节点可以获取到的next节点
- item在生产者和消费者下有所不同。生产者是有数据。消费者为null。
- waiter为当前线程
- isData属性是用来区分消费者和生产者的属性。值得一提的是最终生产者需要将item交给消费者,最终消费者需要向生产者获取item
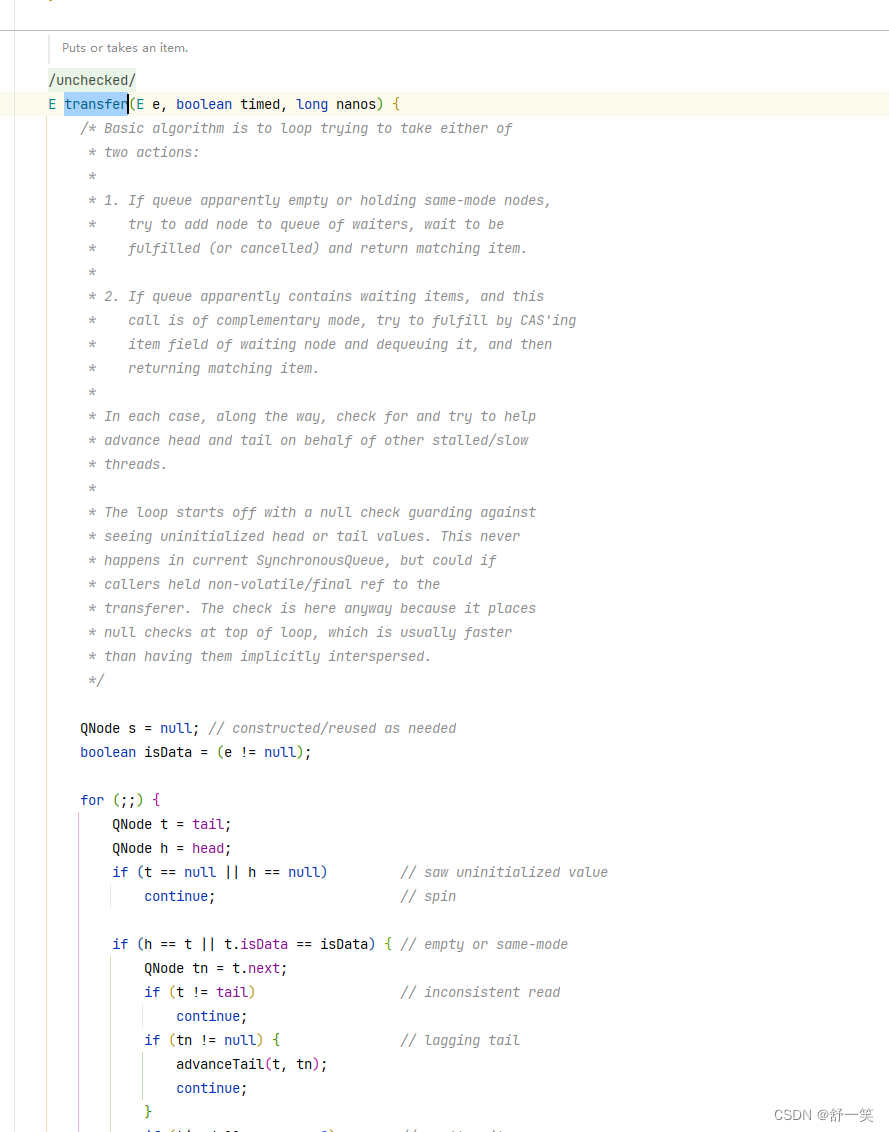
SynchronousQueue的TransferQueue源码中核心方法transfer方法分析
- 作为TransferQueue的核心内容存在
- e作为要传递的参数
- timed属性,为false代表无限阻塞。true代表阻塞nacos时间
- QNode s = null,是要封装当前的生产者和消费者信息。
- 布尔类型的isData ,e要是为null,那么isData为false。代表消费者;反之要是e不为null,isData为true是生产者。
- 下面这个死循环是作者的一种写作习惯。
- 接下来的获取头节点head,获取尾节点tail。
- 下面是健壮性判断,防止TransferQueue还没有被初始化。因为在TransferQueue的构造方法中是不会出现都为空的,只有一种可能那就是指令重排了,所以需要重新初始化。
-
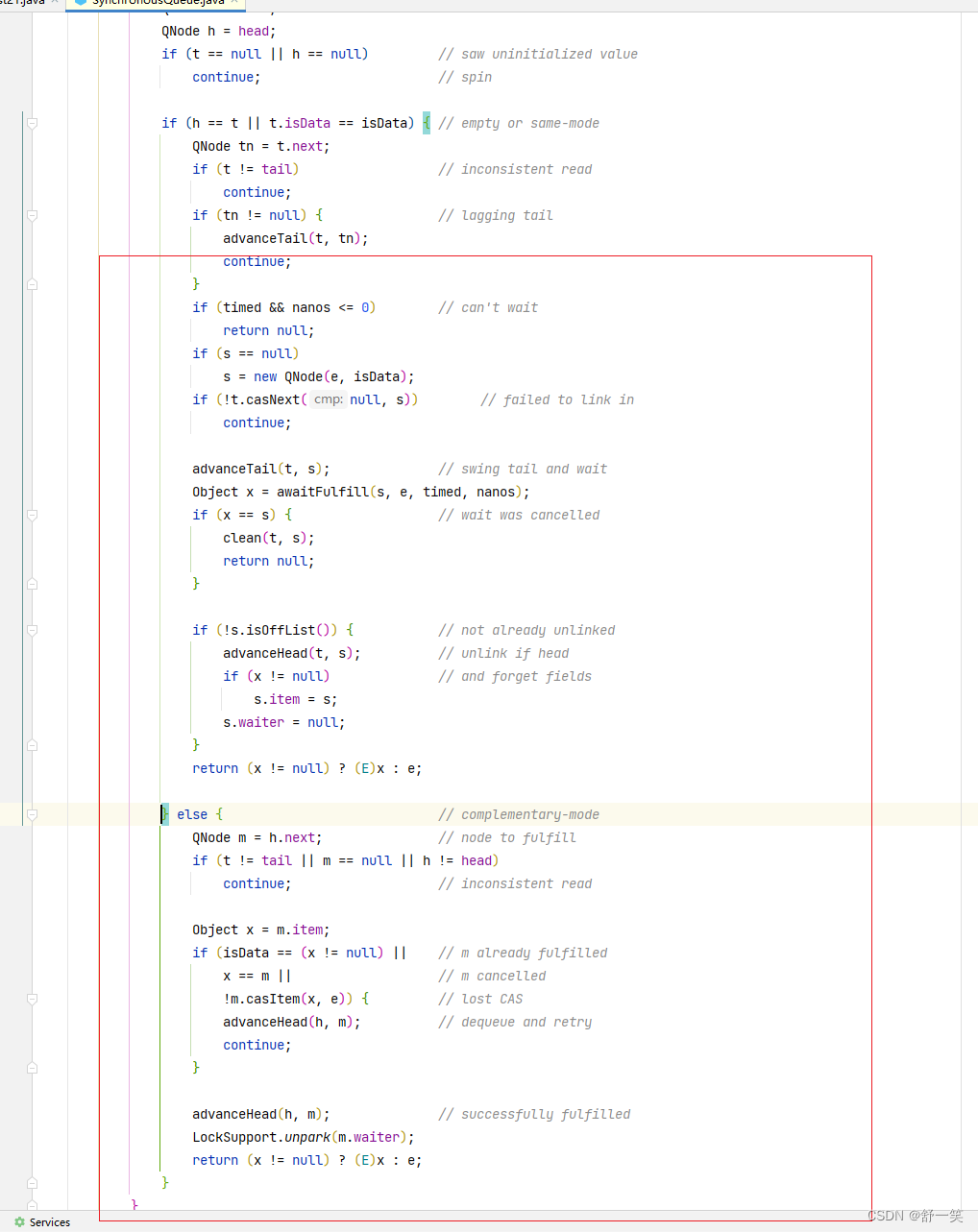
接着上面说,判断h==t,代表头节点和尾节点相等。队列为空,没有生产者和消费者。或者要是前一个判断不成立,那说明队列中是存在元素,那就进行后续的判断,当前节点和队列节点是不是同一种角色。也就说要是队列中是存在生产者,那我来一看我也是生产者那么我也进队列。要是队列中存在的是消费者,那我过来一看我也是消费者那我也进队列。或循环的特点就是只要满足了任意一个条件那我就进队列。
-
进来之后首先获取尾节点的next,要是t不是尾节点,说明当前由其他线程并发进来修改了tail,那就重新走for循环吧
-
要是尾节点的下一个节点不为空,说明前面的线程存在并发添加了一个节点,那就修改尾节点的指向,重新走for循环。
-
总结就是进来之后就是处理了并发的问题。
-
前面都没有问题,那就没有并发问题我们继续。
-
下面是一个判断 if (timed && nanos <= 0) ,判断当前线程是不是可以阻塞,要是timed为true代表可以阻塞一会,但是要是阻塞的时间小于等于0,那就不需要进行下去了。
-
if (s == null),经过前面的判断,证明可以阻塞,需要将加入到队列的节点构建出来。
-
(!t.casNext(null, s)) 这个是基于CAS的操作,将当前线程尾节点的next节点设置为新创建的节点s。但是主要是一个非判断,证明是失败才进来那就要说明修改失败了。需要重新for循环。
-
advanceTail(t, s); 还能继续说明CAS成功了,那就替换掉tail的指向。
-
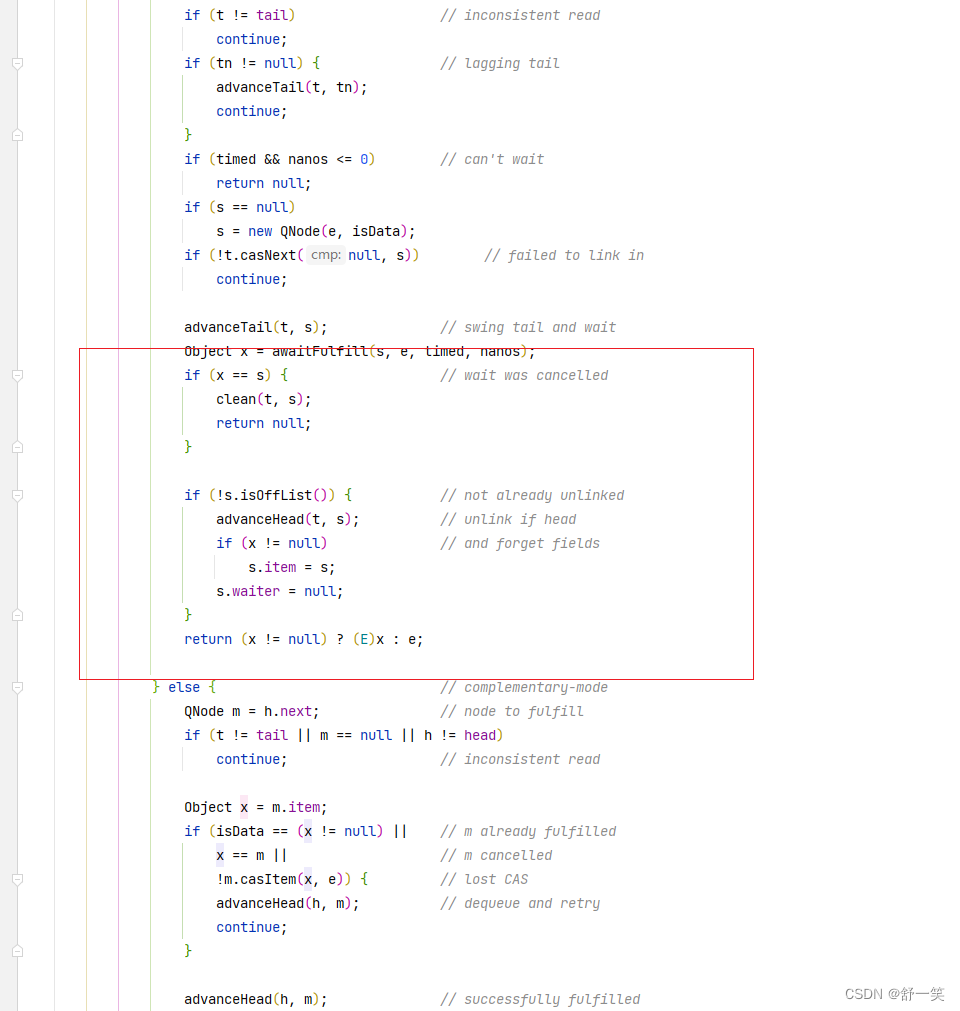
Object x = awaitFulfill(s, e, timed, nanos);说明进入到队列中,那就需要挂起线程。等待消费者或者生产者。x则是作为替代返回后的数据
-
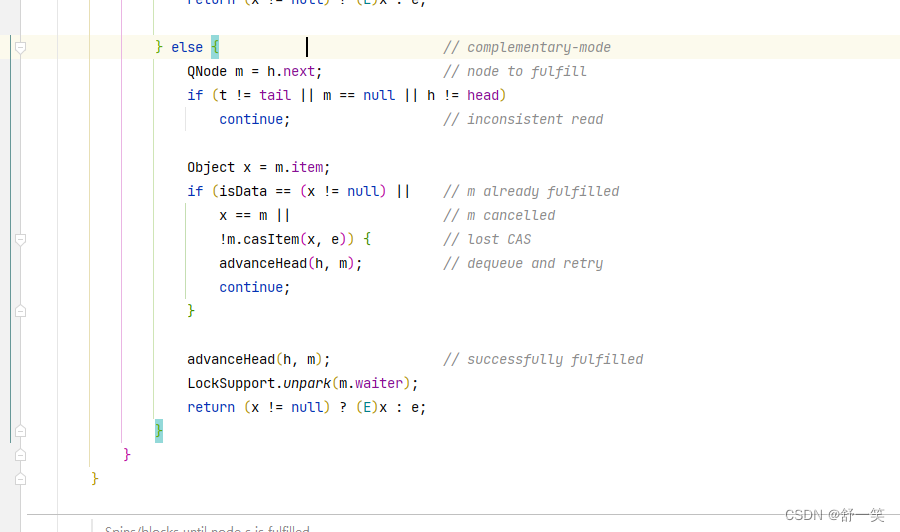
前面那个if判断没有进去,代表者队列中由元素,而我的类型还和那个不一样,那我就要进去消费了。
-
获取头节点的next节点,作为要匹配的节点。
-
下面这个三个或逻辑的判断,t不是尾节点,m为null,或者头节点不是头节点那就重新走for循环。
-
否则说明并发没有问题,可以获取数据了
-
Object x = m.item;或者m的item节点作为x;
-
首先下面这个判断x不为空,然后再才和左边这个判断类型是一致的话,那就说明出现了并发的问题,消费者匹配消费者,生产者匹配生产者没有意义。
-
x == m这个判断条件是说明节点取消了,那就没必要去匹配了。
-
!m.casItem(x, e))这个判断条件注意前面的逻辑非,要是判断到这里说明可以交换数据了,但是要是交换失败了,那也说明并发有问题。
-
然后就需要方法块中的语句重新设置head节点,并且重新走一遍for循环。
-
要是判断都没有进去说明一切正常,那就继续往后面走。
-
advanceHead(h, m);替换head
-
唤醒head的next线程
-
最后返回,要是x不为空那说明是生产者,那就直接返回x,要是为null,那就返回e
- 判断要是元素和节点相等,那说明节点取消了。进入清空当前节点,将上一个节点的next指向当前节点的next,就是绕过当前节点。直接拜拜。
- 判断当前节点是不是还在队列中
- 要是在进入方法将当前节点这是为head
- 要是x不为null,说明是消费者获取到了数据,将当前节点设置尾自己,方便GC,线程位置null
- 最后返回数据,生产者不为null,返回自己生产的数据x,消费者则是返回消费的数据e。