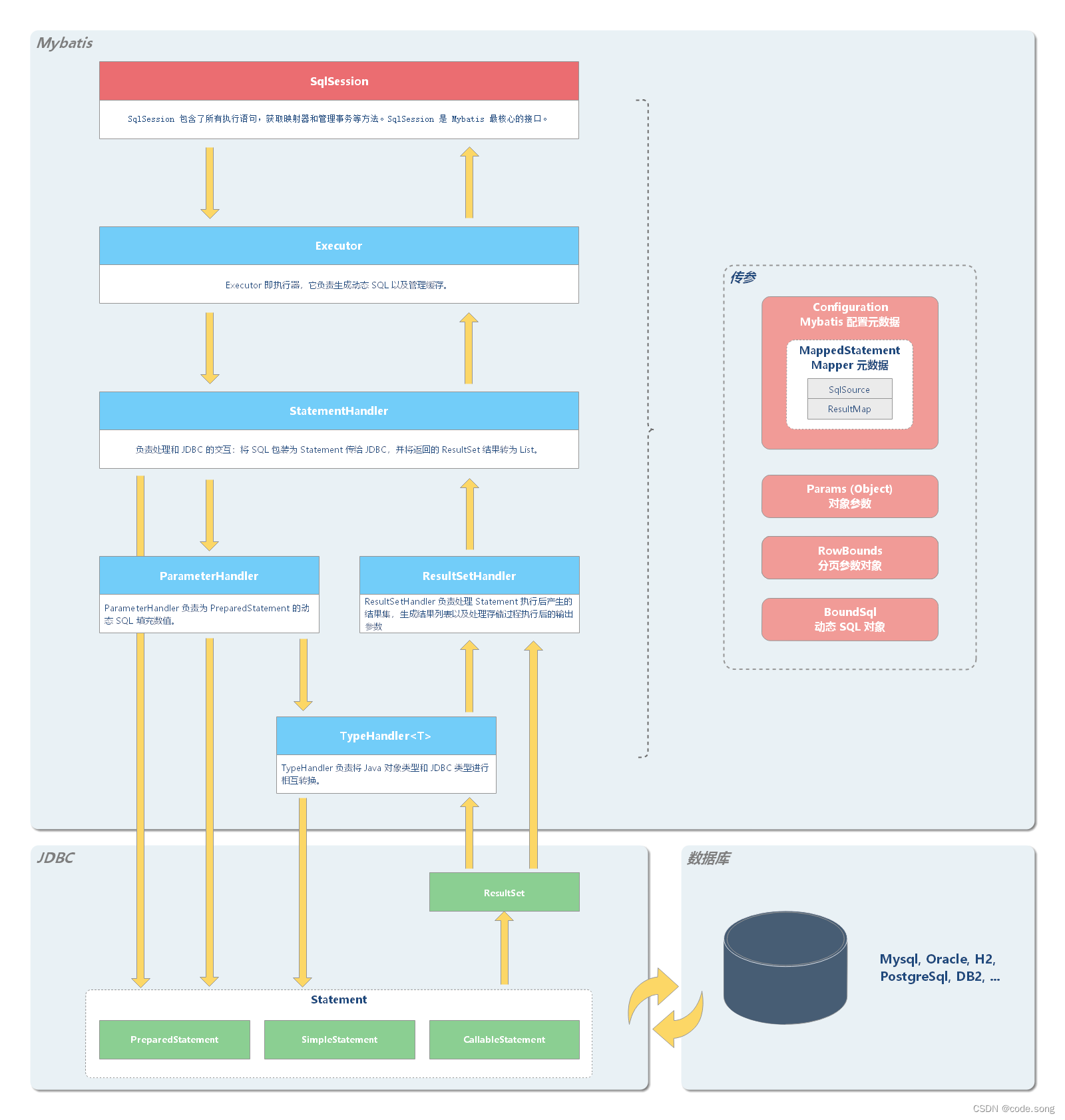
一、MyBatis架构
从 MyBatis 代码实现的角度来看,MyBatis 的主要组件有以下几个:
-
SqlSession - 作为 MyBatis 工作的主要顶层 API,表示和数据库交互的会话,完成必要数据库增删改查功能。
-
Executor - MyBatis 执行器,是 MyBatis 调度的核心,负责 SQL 语句的生成和查询缓存的维护。
-
StatementHandler - 封装了 JDBC Statement 操作,负责对 JDBC statement 的操作,如设置参数、将 Statement 结果集转换成 List 集合。
-
ParameterHandler - 负责对用户传递的参数转换成 JDBC Statement 所需要的参数。
-
ResultSetHandler - 负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合。
-
TypeHandler - 负责 java 数据类型和 jdbc 数据类型之间的映射和转换。
-
MappedStatement - MappedStatement 维护了一条 <select|update|delete|insert> 节点的封装。
-
SqlSource - 负责根据用户传递的 parameterObject,动态地生成 SQL 语句,将信息封装到 BoundSql 对象中,并返回。
-
BoundSql - 表示动态生成的 SQL 语句以及相应的参数信息。
-
Configuration - MyBatis 所有的配置信息都维持在 Configuration 对象之中。
这些组件的架构层次如下:

1.1. 配置层
配置层决定了 MyBatis 的工作方式。
MyBatis 提供了两种配置方式:
-
基于 XML 配置文件的方式
-
基于 Java API 的方式
SqlSessionFactoryBuilder 会根据配置创建 SqlSessionFactory ;SqlSessionFactory 负责创建 SqlSessions 。
1.2. 接口层
接口层负责和数据库交互的方式。MyBatis 和数据库的交互有两种方式:
1)使用 SqlSession:SqlSession 封装了所有执行语句,获取映射器和管理事务的方法。
-
用户只需要传入 Statement Id 和查询参数给 SqlSession 对象,就可以很方便的和数据库进行交互。
-
这种方式的缺点是不符合面向对象编程的范式。
2)使用 Mapper 接口:MyBatis 会根据相应的接口声明的方法信息,通过动态代理机制生成一个 Mapper 实例;MyBatis 会根据这个方法的方法名和参数类型,确定 Statement Id,然后和 SqlSession 进行映射,底层还是通过 SqlSession 完成和数据库的交互。
1.3. 数据处理层
数据处理层可以说是 MyBatis 的核心,从大的方面上讲,它要完成两个功能:
1)根据传参 Statement 和参数构建动态 SQL 语句
-
动态语句生成可以说是 MyBatis 框架非常优雅的一个设计,MyBatis 通过传入的参数值,使用 Ognl 来动态地构造 SQL 语句,使得 MyBatis 有很强的灵活性和扩展性。
-
参数映射指的是对于 java 数据类型和 jdbc 数据类型之间的转换:这里有包括两个过程:查询阶段,我们要将 java 类型的数据,转换成 jdbc 类型的数据,通过 preparedStatement.setXXX() 来设值;另一个就是对 resultset 查询结果集的 jdbcType 数据转换成 java 数据类型。
2)执行 SQL 语句以及处理响应结果集 ResultSet
-
动态 SQL 语句生成之后,MyBatis 将执行 SQL 语句,并将可能返回的结果集转换成 List<E> 列表。
-
MyBatis 在对结果集的处理中,支持结果集关系一对多和多对一的转换,并且有两种支持方式,一种为嵌套查询语句的查询,还有一种是嵌套结果集的查询。
1.4. 框架支撑层
1) 事务管理机制 - MyBatis 将事务抽象成了 Transaction 接口。MyBatis 的事务管理分为两种形式:
-
使用 JDBC 的事务管理机制:即利用 java.sql.Connection 对象完成对事务的提交(commit)、回滚(rollback)、关闭(close)等。
-
使用 MANAGED 的事务管理机制:MyBatis 自身不会去实现事务管理,而是让程序的容器如(JBOSS,Weblogic)来实现对事务的管理。
2) 连接池管理
3) SQL 语句的配置 - 支持两种方式:
-
xml 配置
-
注解配置
4) 缓存机制 - MyBatis 采用两级缓存结构;
-
一级缓存是 Session 会话级别的缓存 - 一级缓存又被称之为本地缓存。一般而言,一个 SqlSession 对象会使用一个 Executor 对象来完成会话操作,Executor 对象会维护一个 Cache 缓存,以提高查询性能。
-
一级缓存的生命周期是 Session 会话级别的。
-
二级缓存是 Application 应用级别的缓存 - 用户配置了 "cacheEnabled=true",才会开启二级缓存。
-
如果开启了二级缓存,SqlSession 会先使用 CachingExecutor 对象来处理查询请求。CachingExecutor 会在二级缓存中查看是否有匹配的数据,如果匹配,则直接返回缓存结果;如果缓存中没有,再交给真正的 Executor 对象来完成查询,之后 CachingExecutor 会将真正 Executor 返回的查询结果放置到缓存中,然后在返回给用户。
-
二级缓存的生命周期是应用级别的。

二、SqlSession 内部工作机制
从前文,我们已经了解了,MyBatis 封装了对数据库的访问,把对数据库的会话和事务控制放到了 SqlSession 对象中。那么具体是如何工作的呢?接下来,我们通过源码解读来进行分析。
SqlSession 对于 insert、update、delete、select 的内部处理机制基本上大同小异。所以,接下来,我会以一次完整的 select 查询流程为例讲解 SqlSession 内部的工作机制。相信读者如果理解了 select 的处理流程,对于其他 CRUD 操作也能做到一通百通。
2.1 SqlSession 子组件
前面的内容已经介绍了:SqlSession 是 MyBatis 的顶层接口,它提供了所有执行语句,获取映射器和管理事务等方法。
实际上,SqlSession 是通过聚合多个子组件,让每个子组件负责各自功能的方式,实现了任务的下发。
在了解各个子组件工作机制前,先让我们简单认识一下 SqlSession 的核心子组件。
2.1.1 Executor
Executor 即执行器,它负责生成动态 SQL 以及管理缓存。

-
Executor 即执行器接口。
-
BaseExecutor
是 Executor 的抽象类,它采用了模板方法设计模式,内置了一些共性方法,而将定制化方法留给子类去实现。
-
SimpleExecutor
是最简单的执行器。它只会直接执行 SQL,不会做额外的事。
-
BatchExecutor
是批处理执行器。它的作用是通过批处理来优化性能。值得注意的是,批量更新操作,由于内部有缓存机制,使用完后需要调用 flushStatements 来清除缓存。
-
ReuseExecutor
是可重用的执行器。重用的对象是 Statement,也就是说,该执行器会缓存同一个 SQL 的 Statement,避免重复创建 Statement。其内部的实现是通过一个 HashMap 来维护 Statement 对象的。由于当前 Map 只在该 session 中有效,所以使用完后需要调用 flushStatements 来清除 Map。
-
CachingExecutor 是缓存执行器。它只在启用二级缓存时才会用到。
2.1.2 StatementHandler
StatementHandler 对象负责设置 Statement 对象中的查询参数、处理 JDBC 返回的 resultSet,将 resultSet 加工为 List 集合返回。
StatementHandler 的家族成员:

-
StatementHandler 是接口;
-
BaseStatementHandler
是实现 StatementHandler 的抽象类,内置一些共性方法;
-
SimpleStatementHandler
负责处理 Statement;
-
PreparedStatementHandler
负责处理 PreparedStatement;
-
CallableStatementHandler
负责处理 CallableStatement。
-
RoutingStatementHandler
负责代理 StatementHandler 具体子类,根据 Statement 类型,选择实例化 SimpleStatementHandler、
PreparedStatementHandler、
CallableStatementHandler。
2.1.3 ParameterHandler
ParameterHandler 负责将传入的 Java 对象转换 JDBC 类型对象,并为 PreparedStatement 的动态 SQL 填充数值。
ParameterHandler 只有一个具体实现类,即 DefaultParameterHandler。
2.1.4 ResultSetHandler
ResultSetHandler 负责两件事:
-
处理 Statement 执行后产生的结果集,生成结果列表
-
处理存储过程执行后的输出参数
ResultSetHandler 只有一个具体实现类,即 DefaultResultSetHandler。
2.1.5 TypeHandler
TypeHandler 负责将 Java 对象类型和 JDBC 类型进行相互转换。
2.2 SqlSession 和 Mapper
// 2. 创建一个 SqlSession 实例,进行数据库操作
SqlSession sqlSession = factory.openSession();
// 3. Mapper 映射并执行
Long params = 1L;
List<User> list = sqlSession.selectList("io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey", params);
for (User user : list) {
System.out.println("user name: " + user.getName());
}示例代码中,给 sqlSession 对象的传递一个配置的 Sql 语句的 Statement Id 和参数,然后返回结果io.github.dunwu.spring.orm.mapper.
UserMapper.selectByPrimaryKey 是配置在 UserMapper.xml 的 Statement ID,params 是 SQL 参数。
UserMapper.xml 文件中的代码片段:
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select id, name, age, address, email
from user
where id = #{id,jdbcType=BIGINT}
</select>MyBatis 通过方法的全限定名,将 SqlSession 和 Mapper 相互映射起来。
2.3. SqlSession 和 Executor
org.apache.ibatis.session.defaults.DefaultSqlSession 中 selectList 方法的源码:
@Override
public <E> List<E> selectList(String statement) {
return this.selectList(statement, null);
}
@Override
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
// 1. 根据 Statement Id,在配置对象 Configuration 中查找和配置文件相对应的 MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
// 2. 将 SQL 语句交由执行器 Executor 处理
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
说明:
MyBatis 所有的配置信息都维持在 Configuration 对象之中。中维护了一个 Map<String, MappedStatement> 对象。其中,key 为 Mapper 方法的全限定名(对于本例而言,key 就是 io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey ),value 为 MappedStatement 对象。所以,传入 Statement Id 就可以从 Map 中找到对应的 MappedStatement。
MappedStatement 维护了一个 Mapper 方法的元数据信息,数据组织可以参考下面 debug 截图:

小结:通过 "SqlSession 和 Mapper" 以及 "SqlSession 和 Executor" 这两节,我们已经知道:SqlSession 的职能是:根据 Statement ID, 在 Configuration 中获取到对应的 MappedStatement 对象,然后调用 Executor 来执行具体的操作。
2.4. Executor 工作流程
继续上一节的流程,SqlSession 将 SQL 语句交由执行器 Executor 处理。那又做了哪些事呢?
(1)执行器查询入口
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 1. 根据传参,动态生成需要执行的 SQL 语句,用 BoundSql 对象表示
BoundSql boundSql = ms.getBoundSql(parameter);
// 2. 根据传参,创建一个缓存Key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}执行器查询入口主要做两件事:
-
生成动态 SQL:根据传参,动态生成需要执行的 SQL 语句,用 BoundSql 对象表示。
-
管理缓存:根据传参,创建一个缓存 Key。
(2)执行器查询第二入口
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 略
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
// 3. 缓存中有值,则直接从缓存中取数据;否则,查询数据库
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
// 略
return list;
}实际查询方法主要的职能是判断缓存 key 是否能命中缓存:
-
命中,则将缓存中数据返回;
-
不命中,则查询数据库:
(3)查询数据库
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 4. 执行查询,获取 List 结果,并将查询的结果更新本地缓存中
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}queryFromDatabase 方法的职责是调用 doQuery,向数据库发起查询,并将返回的结果更新到本地缓存。
(4)实际查询方法。SimpleExecutor 类的 doQuery()方法实现;
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 5. 根据既有的参数,创建StatementHandler对象来执行查询操作
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 6. 创建java.Sql.Statement对象,传递给StatementHandler对象
stmt = prepareStatement(handler, ms.getStatementLog());
// 7. 调用StatementHandler.query()方法,返回List结果
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}上述的 Executor.query()方法几经转折,最后会创建一个 StatementHandler 对象,然后将必要的参数传递给 StatementHandler,使用 StatementHandler 来完成对数据库的查询,最终返回 List 结果集。从上面的代码中我们可以看出,Executor 的功能和作用是:
-
根据传递的参数,完成 SQL 语句的动态解析,生成 BoundSql 对象,供 StatementHandler 使用;
-
为查询创建缓存,以提高性能
-
创建 JDBC 的 Statement 连接对象,传递给 StatementHandler 对象,返回 List 查询结果。
prepareStatement() 方法的实现:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
//对创建的Statement对象设置参数,即设置SQL 语句中 ? 设置为指定的参数
handler.parameterize(stmt);
return stmt;
}对于 JDBC 的 PreparedStatement 类型的对象,创建的过程中,我们使用的是 SQL 语句字符串会包含若干个占位符,我们其后再对占位符进行设值。
2.5. StatementHandler 工作流程
StatementHandler 有一个子类 RoutingStatementHandler,它负责代理其他 StatementHandler 子类的工作。
它会根据配置的 Statement 类型,选择实例化相应的 StatementHandler,然后由其代理对象完成工作。
【源码】RoutingStatementHandler
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}【源码】RoutingStatementHandler 的
parameterize 方法源码
【源码】PreparedStatementHandler 的
parameterize 方法源码
StatementHandler使用ParameterHandler对象来完成对Statement 的赋值。
@Override
public void parameterize(Statement statement) throws SQLException {
// 使用 ParameterHandler 对象来完成对 Statement 的设值
parameterHandler.setParameters((PreparedStatement) statement);
}【源码】StatementHandler 的 query 方法源码
StatementHandler 使用 ResultSetHandler 对象来完成对 ResultSet 的处理。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
// 使用ResultHandler来处理ResultSet
return resultSetHandler.handleResultSets(ps);
}2.6. ParameterHandler 工作流程
【源码】DefaultParameterHandler 的 setParameters 方法
@Override
public void setParameters(PreparedStatement ps) {
// parameterMappings 是对占位符 #{} 对应参数的封装
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 不处理存储过程中的参数
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
// 获取对应的实际数值
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
// 获取对象中相应的属性或查找 Map 对象中的值
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 通过 TypeHandler 将 Java 对象参数转为 JDBC 类型的参数
// 然后,将数值动态绑定到 PreparedStaement 中
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}2.7. ResultSetHandler 工作流程
ResultSetHandler 的实现可以概括为:将 Statement 执行后的结果集,按照 Mapper 文件中配置的 ResultType 或 ResultMap 来转换成对应的 JavaBean 对象,最后将结果返回。
【源码】DefaultResultSetHandler 的 handleResultSets 方法。handleResultSets 方法是 DefaultResultSetHandler 的最关键方法。其实现如下:
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 第一个结果集
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
// 判断结果集的数量
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
// 遍历处理结果集
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}