今天开始了新的课程
由我们的星哥带领我们踏入Spark的神秘殿堂
01_SparkCore
1. Spark简介
1.1 什么是Spark
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache的顶级项目,2014年5月发布spark1.0,2016年7月发布spark2.0,2020年6月18日发布spark3.0.0
1.2 Spark的特点
- Speed:快速高效
Hadoop的MapReduce作为第一代分布式大数据计算引擎,在设计之初,受当时计算机硬件条件所限(内存、磁盘、cpu等),为了能够计算海量数据,需要将中间结果保存到HDFS中,那么就要频繁读写HDFS从而使得网络IO和磁盘IO成为性能瓶颈。Spark可以将中间结果写到本地磁盘或将中间cache到内存中,节省了大量的网络IO和磁盘IO开销。并且Spark使用更先进的DAG任务调度思想,可以将多个计算逻辑构建成一个有向无环图,并且还会将DAG先进行优化后再生成物理执行计划,同时 Spark也支持数据缓存在内存中的计算。性能比Hadoop MapReduce快100倍。即便是不将数据cache到内存中,其速度也是MapReduce10 倍以上。
- Ease of Use:简洁易用
Spark支持 Java、Scala、Python和R等编程语言编写应用程序,大大降低了使用者的门槛。自带了80多个高等级操作算子,并且允许在Scala,Python,R 的使用命令进行交互式运行,可以非常方便的在Spark Shell中地编写spark程序。
- Generality:通用、全栈式数据处理
Spark提供了统一的大数据处理解决方案,非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。 同时Spark还支持SQL,大大降低了大数据开发者的使用门槛,同时提供了SparkStream和Structed Streaming可以处理实时流数据;MLlib机器学习库,提供机器学习相关的统计、分类、回归等领域的多种算法实现。其高度封装的API 接口大大降低了用户的学习成本;Spark GraghX提供分布式图计算处理能力;PySpark支持Python编写Spark程序;SparkR支持R语言编写Spark程序。
- Runs Everywhere:可以运行在各种资源调度框架和读写多种数据源
Spark支持的多种部署方案:Standalone是Spark自带的资源调度模式;Spark可以运行在Hadoop的YARN上面;Spark 可以运行在Mesos上(Mesos是一个类似于YARN的资源调度框架);Spark还可以Kubernetes实现容器化的资源调度
丰富的数据源支持。Spark除了可以访问操作系统自身的本地文件系统和HDFS之外,还可以访问 Cassandra、HBase、Hive、Alluxio(Tachyon)以及任何 Hadoop兼容的数据源。这极大地方便了已经 的大数据系统进行顺利迁移到Spark。
1.3 Spark与MapReduce的对比
| 框架 | 优点 | 缺点 |
| MapReduce | 历史悠久、稳定 | 编程API不灵活、速度慢、只能做离线计算 |
| Spark | 通用、编程API简洁、快 | 跟MapReduce比暂无缺点 |
面试题:MapReduce和Spark的本质区别:
- MR只能做离线计算,如果实现复杂计算逻辑,一个MR搞不定,就需要将多个MR按照先后顺序连成一串,一个MR计算完成后会将计算结果写入到HDFS中,下一个MR将上一个MR的输出作为输入,这样就要频繁读写HDFS,网络IO和磁盘IO会成为性能瓶颈。从而导致效率低下。
- spark既可以做离线计算,又可以做实时计算,提供了抽象的数据集(RDD、Dataset、DataFrame、DStream)
有高度封装的API,算子丰富,并且使用了更先进的DAG有向无环图调度思想,可以对执行计划优化后在执行,并且可以数据可以cache到内存中进行复用,shuffle时,数据可以不排序
注意:MR和Spark在Shuffle时数据都落本地磁盘
2. Spark架构体系
StandAlone模式是spark自带的集群运行模式,不依赖其他的资源调度框架,部署起来简单。
StandAlone模式又分为client模式和cluster模式,本质区别是Driver运行在哪里,如果Driver运行在SparkSubmit进程中就是Client模式,如果Driver运行在集群中就是Cluster模式
2.1 standalone client模式

2.2 standalone cluster模式

2.3 Spark On YARN cluster模式

2.4 Spark执行流程简介

- Job:RDD每一个行动操作都会生成一个或者多个调度阶段 调度阶段(Stage):每个Job都会根据依赖关系,以Shuffle过程作为划分,分为Shuffle Map Stage和Result Stage。每个Stage对应一个TaskSet,一个Task中包含多Task,TaskSet的数量与该阶段最后一个RDD的分区数相同。
- Task:分发到Executor上的工作任务,是Spark的最小执行单元
- DAGScheduler:DAGScheduler是将DAG根据宽依赖将切分Stage,负责划分调度阶段并Stage转成TaskSet提交给TaskScheduler
- TaskScheduler:TaskScheduler是将Task调度到Worker下的Exexcutor进程,然后丢入到Executor的线程池的中进行执行
2.5 Spark中重要角色
- Master :是一个Java进程,接收Worker的注册信息和心跳、移除异常超时的Worker、接收客户端提交的任务、负责资源调度、命令Worker启动Executor。
- Worker :是一个Java进程,负责管理当前节点的资源管理,向Master注册并定期发送心跳,负责启动Executor、并监控Executor的状态。
- SparkSubmit :是一个Java进程,负责向Master提交任务。
- Driver :是很多类的统称,可以认为SparkContext就是Driver,client模式Driver运行在SparkSubmit进程中,cluster模式单独运行在一个进程中,负责将用户编写的代码转成Tasks,然后调度到Executor中执行,并监控Task的状态和执行进度。
- Executor :是一个Java进程,负责执行Driver端生成的Task,将Task放入线程中运行。
2.6 Spark和Yarn角色对比
| Spark StandAlone的Client模式 | YARN |
| Master | ResourceManager |
| Worker | NodeManager |
| Executor | YarnChild |
| SparkSubmit(Driver) | ApplicationMaster |
3. StandAlone模式环境搭建
3.1 搭建步骤
环境准备:三台Linux,一个安装Master,其他两台机器安装Worker

- 下载spark安装包,下载地址:Downloads | Apache Spark

- 上传spark安装包到Linux服务器上
- 解压spark安装包
| Shell |
- 进入到spark按照包目录并将conf目录下的spark-env.sh.template重命名为spark-env.sh,再修改
| Shell |
- 将conf目录下的workers.template重命名为workers并修改,指定Worker的所在节点
| Shell |
- 将配置好的spark拷贝到其他节点
| Shell |
3.2 启动Spark集群
- 在Spark的安装目录执行启动脚本
| Shell |
- 执行jps命令查看Java进程
| Shell |
在ndoe-1上可以看见Master进程,在其他的节点上可以看见到Worker进程
- 访问Master的web管理界面,端口8080

3.3 一些重要参数
| Shell |
3.4 standalone模式高可用部署
spark的standalone模式可以启动两个以上的Master,但是需要依赖zookeeper进行协调,所有的节点启动后,都向zk注册
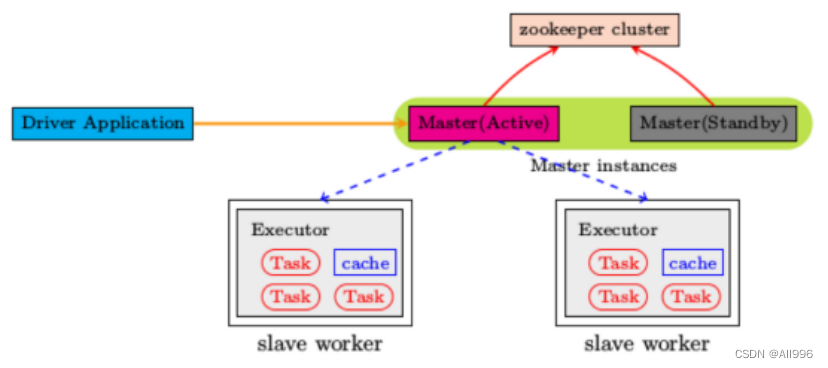
修改配置文件spark-env.sh
| Shell |