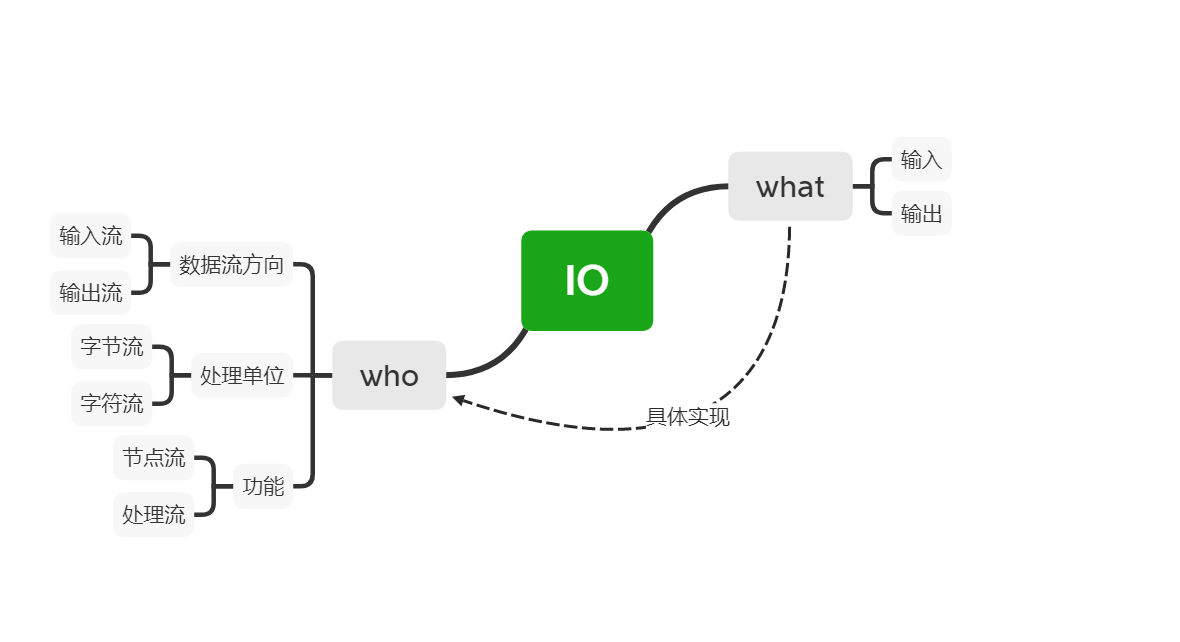
感知机,应该是很简单的模型了
1. 建立模型
感知机的模型,是一种多元线性回归+符号函数的二分类模型。
多元线性回归函数:【Z =
W
T
X
W^{T}X
WTX】
符号函数:
- y = sign(Z) = 1,当y>=0时
- y = sign(y) = -1,当y<0时
这个符号函数,其实就是根据多元线性回归的函数值,是否大于0,来判断类别的。
在程序中,可以直接用if进行判断,即
if Z>=0: y = 1
else: y = -1
"""太简单了吧"""
2.学习模型
2.1 选择损失函数
感知机是二分类,分类有如下四种情况
当多元线性值 Z ≥ 0 时:
- ①分类正确:当实际数据的类别 y 也是1,那么 y*Z > 0
- ②分类错误:当实际数据的类别 y 是 -1 时,那么y*Z<0
当多元线性值 Z < 0 时: - ①分类正确:当实际数据的类别 y 也是-1,那么 y*Z > 0
- ②分类错误:当实际数据的类别y 是 1时,那么y*Z < 0
综合来看,
- 当分类错误时,yZ都是<0的,那么我们应该让yZ尽可能变大,也就是 -y*Z 尽可能变小
- 当分类正确时,yZ都是>0的,那么我们应该让yZ尽可能变大,也就是 -y*Z 尽可能变小
因此,-y*Z可以作为损失函数,求损失函数的极小值,就能让感知机模型尽可能最优
【但实际上,是通过点到超平面的距离来算的,点到超平面距离的公式推导】
L o s s = − y ∗ z = − y ∗ ( w x + b ) = − Y T ( X W T ) Loss = -y*z=-y*(wx+b) = -Y^T(XW^T) Loss=−y∗z=−y∗(wx+b)=−YT(XWT)
2.2 损失函数的优化方法
2.2.3 梯度下降法
W k + 1 = W k − η ∗ d ( L o s s ) d W ) W_{k+1}=W_k - η*\frac{d(Loss)}{dW)} Wk+1=Wk−η∗dW)d(Loss)
d
(
L
o
s
s
)
d
W
)
=
Y
T
X
\frac{d(Loss)}{dW)}= Y^TX
dW)d(Loss)=YTX——————no,不是这样的!!!
感知机多少有点儿暴力破解了,它是挨个挨个去看哪个值分类错误,就立马纠正参数W,直到那个值分类正确后,继续往后找分类错误的值,继续纠正参数W…直到挨个挨个确认每个分类值都分类正确后,就完事了
所以,梯度不是全体数据计算出来的梯度,而是分类错误的那条数据的参数梯度
g
r
a
d
i
e
n
=
−
y
i
∗
X
i
gradien = - y_i*X_i
gradien=−yi∗Xi
这里的
y
i
y_i
yi是实际分类的值(-1或1),
X
i
X_i
Xi是影响该值的因素
(
x
0
,
x
1
.
.
.
x
m
)
(x_0,x_1...x_m)
(x0,x1...xm)——相当于一条误分类的数据
因此当分类错误时(即 y i ∗ X i < 0 时), W k + 1 = W k − η ∗ g r a d i e n t y_i*X_i<0时),W_{k+1} = W_k-η*gradient yi∗Xi<0时),Wk+1=Wk−η∗gradient
2.3 代码实现(手动 对比 sklearn)
from sklearn import linear_model
import pandas as pd
import numpy as np
import time
# 获取所需数据:'推荐分值', '推荐类型'
datas = pd.read_excel('./datas_perception.xlsx')
important_features = ['推荐分值', '推荐类型']
datas_1 = datas[important_features]
# 明确实际类别Y为'推荐类型',X为'推荐分值'
Y_original = datas_1['推荐类型']
# Y 转为独热编码
Y = np.where(Y_original=='低推荐',1,-1)
X_original = datas_1.drop('推荐类型',axis=1)
rows,columns = X_original.shape
X_0 = np.ones((rows,1))
X = np.concatenate((X_0,X_original),axis=1)
def perception_inhand():
W0 = np.ones(columns + 1)
jump = 1
a = 0.001 # 设置学习率a
times = 10000000
num = 0
num_round = 1
while jump and num_round<times:
for i in range(rows):
mistake = Y[i]*np.matmul(X[i,:],W0.T)
while mistake < 0 and num<times:
# print(f"迭代{num + 1}次,该点的分类结果值为{mistake},参数W为{W0}")
gradient = -(Y[i]*X[i,:])
W = W0-a*gradient
mistake = Y[i] * np.matmul(X[i, :], W.T)
num += 1
# print(f"调整后为,该点的分类结果值为{mistake},调整后参数W为{W}")
W0 = W
if mistake >= 0:
break
# print(f"第{i+1}个分类正确")
# 检查是否全部分类正确:实际无需检查的,因为有凸函数梯度是下降的,这个有相应的证明
jump = 0
for i in range(rows):
mistake = Y[i] * np.matmul(X[i, :], W0.T)
if mistake<0:
jump = 1
print(f"______第{num_round}轮迭代,第{i}个值分类错误_______")
break
num_round += 1
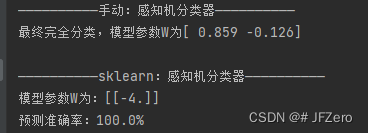
print("——————————手动:感知机分类器——————————")
print(f"最终完全分类,模型参数W为{W}\n")
# sklearn的梯度下降分类器
def perception_sklearn():
# 1. 建立模型:随机梯度下降分类模型
classifier = linear_model.Perceptron()
# 2. 学习模型
classifier.fit(X_original,Y)
Y_hat = classifier.predict(X_original) # 模型分类
labels = classifier.classes_ # 获取分类标签
w = classifier.coef_ # 获取参数 W
b = classifier.intercept_ # 获取偏差b,或称W0
print("——————————sklearn:感知机分类器——————————")
print(f'模型参数W为:{w}')
# 3. 衡量模型
accurency = classifier.score(X_original,Y_hat)
print(f"预测准确率:{accurency*100}%")
perception_inhand()
perception_sklearn()
2.4 感知机对偶形式
对偶形式,本质与之前形式是一样的。
唯一的区别在于,对偶形式在迭代时对参数的更新,是对误分类数据的迭代次数更新。
当一条数据是误分类点时,我们会逐步进行迭代更新,每次迭代更新的学习率η是固定的,而迭代更新的梯度实际也是固定的 y i ∗ x i y_i*x_i yi∗xi,因此每次迭代的幅度Δw也是固定的。
这就会出现,有时某条误分类数据,需要多次迭代(例如n次),才能使分类变得正确。
那么,对偶形式,则是将迭代次数n也纳入了迭代范畴。——【具体不作讲解,因为实际迭代过程与之前差不多】