Go语言unsafe包
Go语言的unsafe包提供了一些底层操作的函数,这些函数可以绕过Go语言的类型系统,直接操作内存。虽然这些函数很强大,但是使用不当可能会导致程序崩溃或者产生不可预料的行为。因此,使用unsafe包时必须小心谨慎。
此外,他提供了一些方法和类型如下
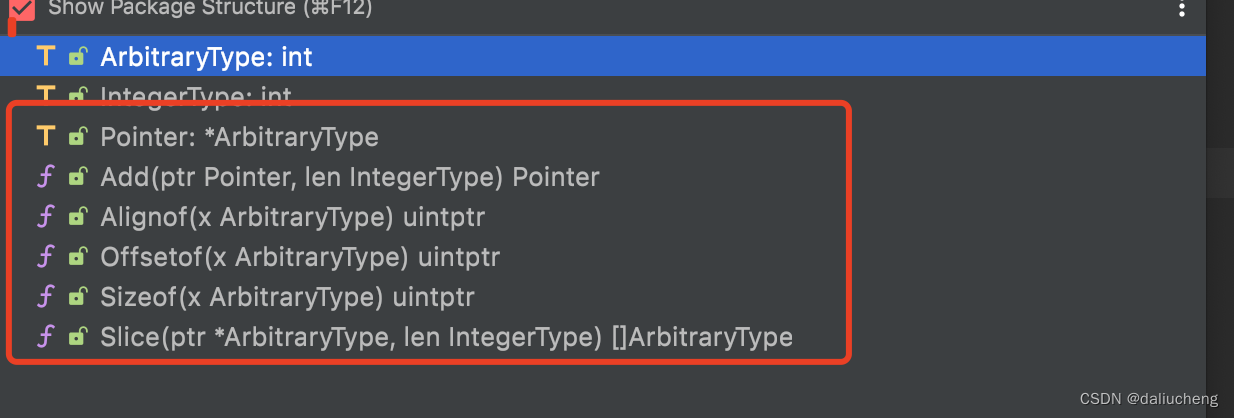
其中Pointer的功能是很强大的,reflect包的功能大多基于它实现,具体可看下面内容
类型
type ArbitraryType int // 代表go中任意类型
type IntegerType int // int 类型
type Pointer *ArbitraryType // 是可以指向ArbitraryType的指针
Pointer详解
关于Pointer有一些规范如下:
- 任意类型的指针都可以转换为Pointer,同理,Pointer可以转换为任意类型的指针。
- uintptr可以转换为pointer,pointer也可以转换为uintptr。
需要注意,Pointer可以操作任意内存,使用起来要小心
Pointer的使用有下面的几种情景:
利用Pointer将*T1转换为*T2
ps:需要注意,底层数据长度可以对上,就可以转换,不一定要固定的类型
package main
import (
"fmt"
"unsafe"
)
func main() {
var a = 4.5
println(Float64bits(a))
var b = []string{"1","2"}
bits := SliceBits(b)
fmt.Printf("%v \n",bits)
var c = true
println(BoolBits(c))
println(BoolBitsInt(c))
}
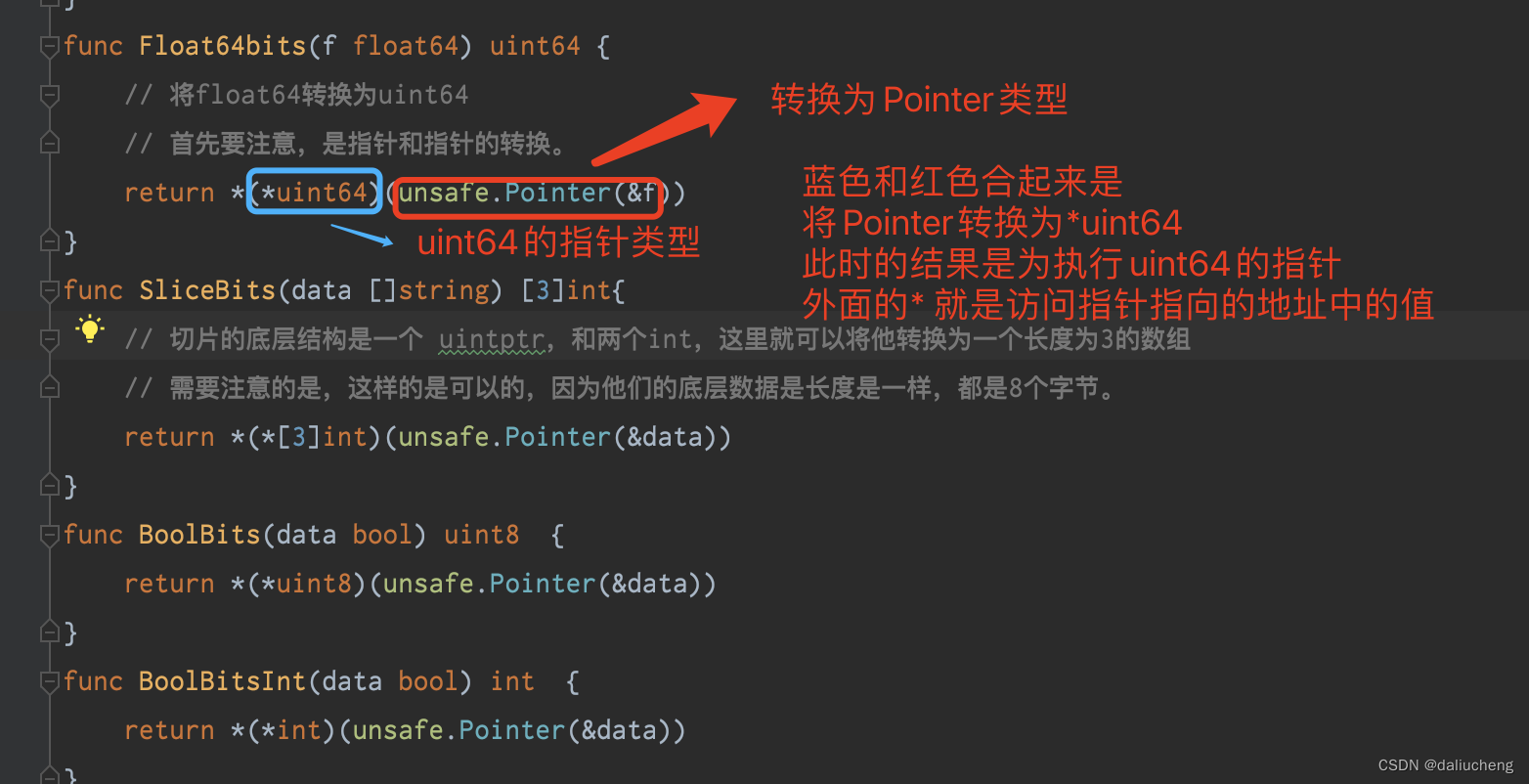
func Float64bits(f float64) uint64 {
// 将float64转换为uint64
// 首先要注意,是指针和指针的转换。
return *(*uint64)(unsafe.Pointer(&f))
}
func SliceBits(data []string) [3]int{
// 切片的底层结构是一个 uintptr,和两个int,这里就可以将他转换为一个长度为3的数组
// 需要注意的是,这样的是可以的,因为他们的底层数据是长度是一样,都是8个字节。
return *(*[3]int)(unsafe.Pointer(&data))
}
func BoolBits(data bool) uint8 {
return *(*uint8)(unsafe.Pointer(&data))
}
func BoolBitsInt(data bool) int {
return *(*int)(unsafe.Pointer(&data))
}
//outPut:
4616752568008179712
[1374389948232 2 2]
1
286655889801473 // 底层数据不一致,出了问题
解释如下:
利用Pointer可以来移动指针
func main() {
var p = Point{
x: 2,
y: 3,
}
yUintptr := uintptr(unsafe.Pointer(&p)) + 8 // 在p的地址上增加了8个偏移量,找到了p,这个时候p还是uintptr
println(*(*int)(unsafe.Pointer(yUintptr))) // output:3
// 将uintptr转换为*int的指针,然后访问值
// 上面的操作相当于
// println(*(*int)(unsafe.Add(unsafe.Pointer(&p), 8)))
// 从p开始,移动8个,然后访问值
}
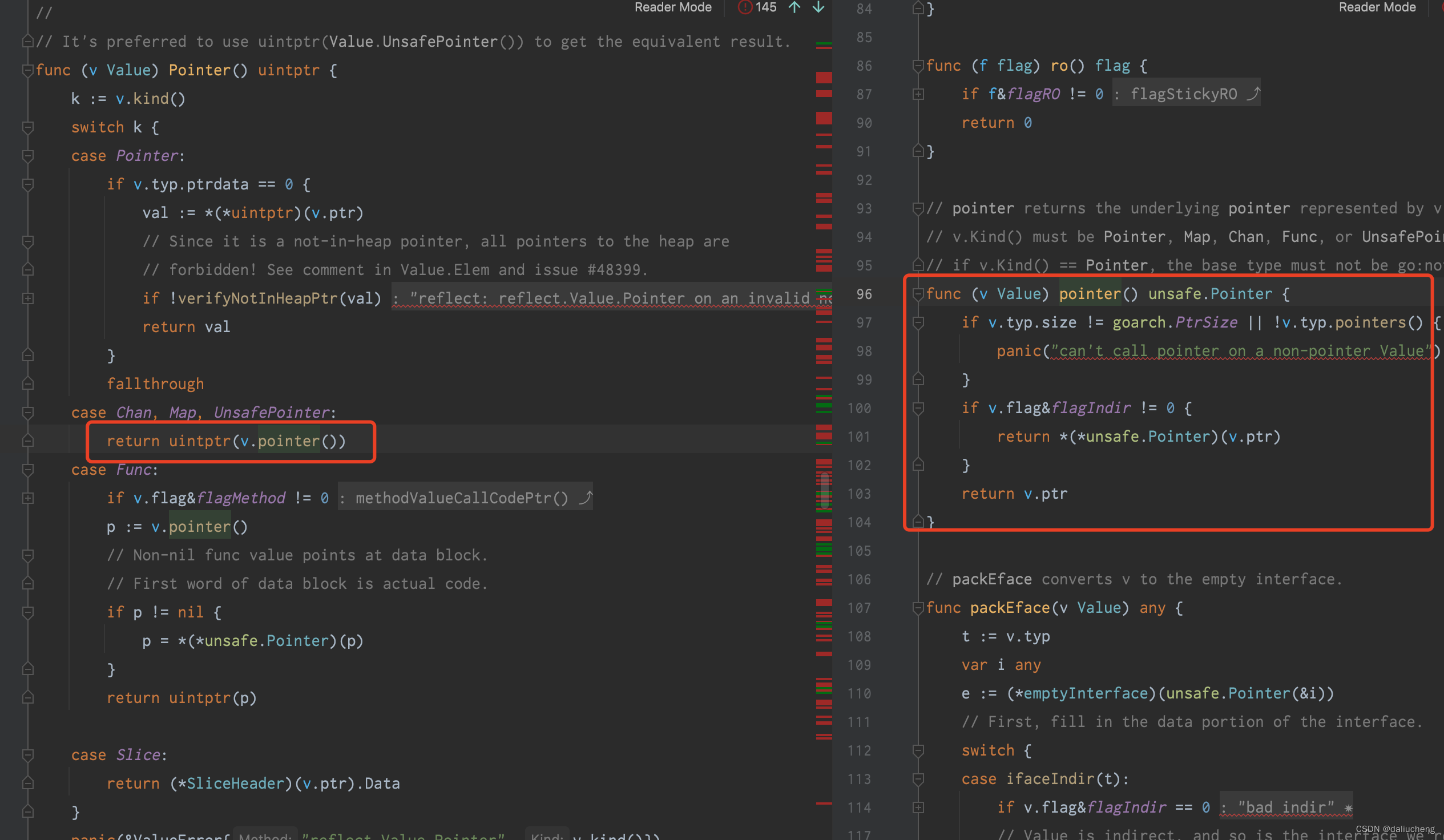
将reflect.Value.Pointer or reflect.Value.UnsafeAddr方法的返回值转换为Pointer
这底层用的是Pointer来做的
func main() {
var p = Point{
x: 2,
y: 3,
}
reflect.ValueOf(p).Pointer() // 返回值为 uintptr
reflect.ValueOf(p).UnsafePointer() // 返回值为 unsafe.Pointer
reflect.ValueOf(p).UnsafeAddr() // 返回值为 uintptr
}
我们看一个reflect.ValueOf()的实现
将Pointer转换为reflect.SliceHeader和reflect.StringHeader
可以通过这种方式来查看String和slice底层的数据结构,直接做转换.
func main() {
var a = "this"
s := (*reflect.StringHeader)(unsafe.Pointer(&a))
fmt.Printf("%+v \n",s) //&{Data:4304632499 Len:4}
var a1 = []string{"1","2","3"}
s2 := (*reflect.SliceHeader)(unsafe.Pointer(&a1))
fmt.Printf("%+v",s2) // &{Data:1374389961088 Len:3 Cap:3}
}
利用将string转为[]byte或者[]byte转string的时候不copy底层数组
string转[]byte不拷贝底层数组
-
验证copy操作
利用汇编可以看到在转[]byte的时候调用了函数
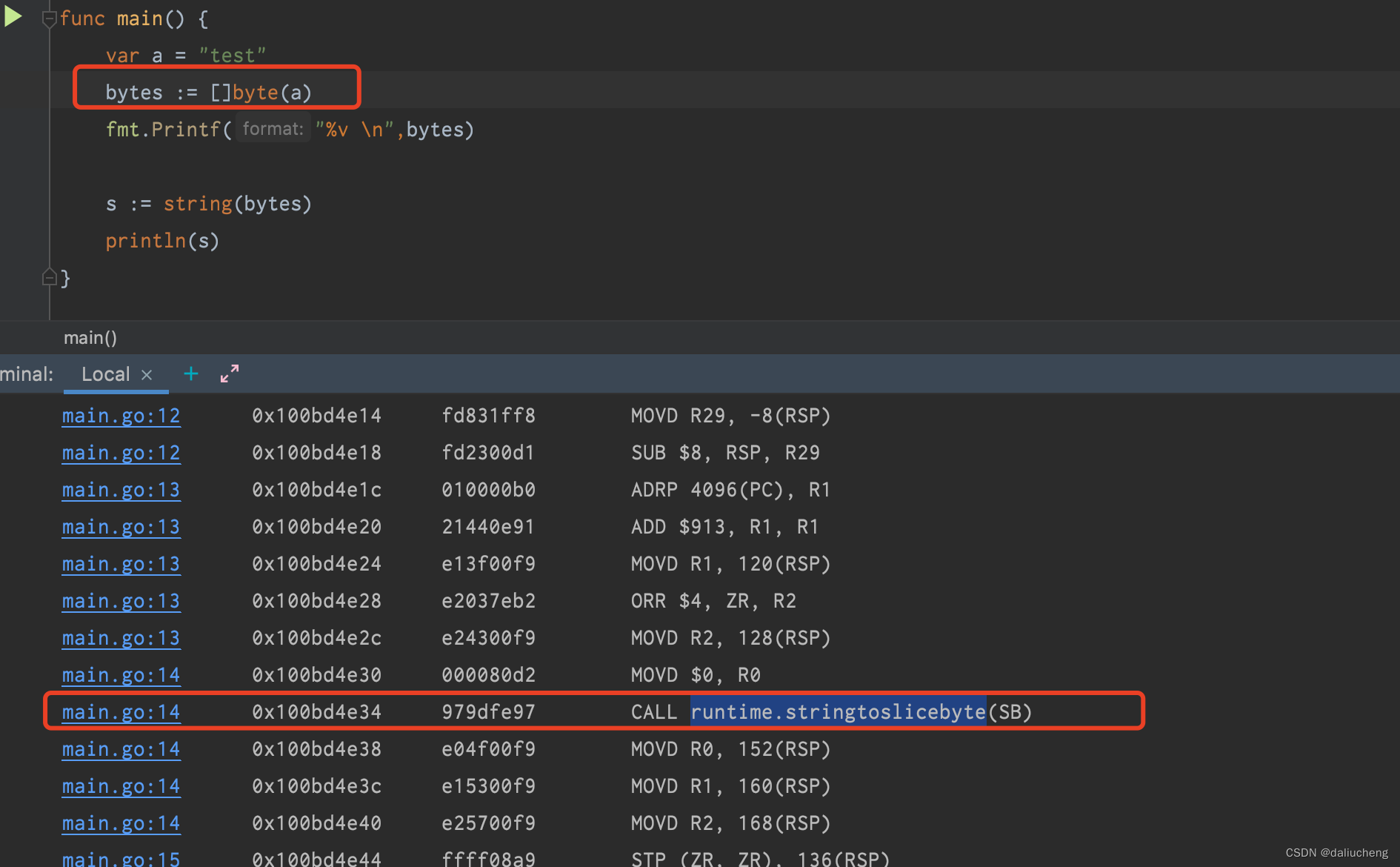
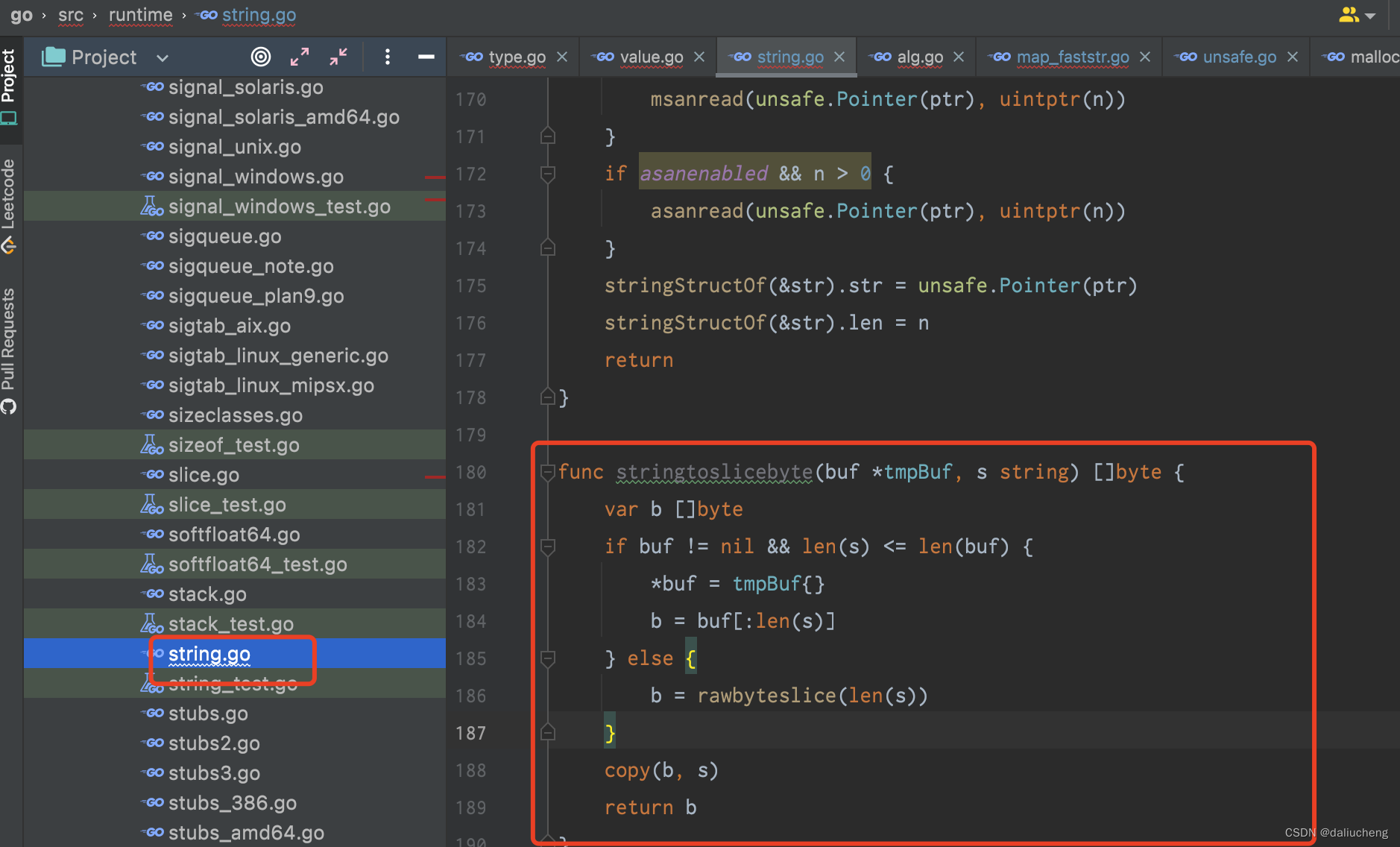
源码链接:https://github.com/golang/go/blob/261e26761805e03c126bf3934a8f39302e8d85fb/src/runtime/string.go#L166
-
自己做,省略copy操作
func main() { var a = "test" // 创建str // 本质来说就是切片和stringHead的转换 ints := *(*[2]int)(unsafe.Pointer(&a)) fmt.Printf("%+v \n",ints) // [4297030033 4] var b = [3]int{ // 这里我将stringHead和sliceHead看成了int类型的数组,0 index表示data的ptr,1 index为长度,2index为容量 ints[0], ints[1], ints[1], } s := (*[]byte)(unsafe.Pointer(&b)) fmt.Printf("%+v\n",*s) // [116 101 115 116] }

上面的操作就是现将String转为长度为2的数组,然后构建一个长度为3的数组,转为[]byte切片。
ps: 需要注意,在转换的时候只要底层的数据长度能对上,就可以转换
下面的代码是我按照正常流程写的
func main() {
var a = "test" // 创建str
s := *(*reflect.StringHeader)(unsafe.Pointer(&a)) // 转出stringHead
header := reflect.SliceHeader{ // 构建sliceHeader
Data: s.Data,
Len: s.Len,
Cap: s.Len,
}
i := *(*[]byte)(unsafe.Pointer(&header)) // 转为[]byte
fmt.Printf("%+v \v",i)
}
例子
int转char
func main() {
var a = 65
s := *(*[1]byte)(unsafe.Pointer(&a)) // int看为长度为1的byte数组
fmt.Printf(string(s[0])) // A 65对应的asill码是A
}
字符串转byte
func main() {
var a = "test"
i := *(*[]byte)(unsafe.Pointer(&a))
fmt.Printf("%+v",i) // [116 101 115 116]
}
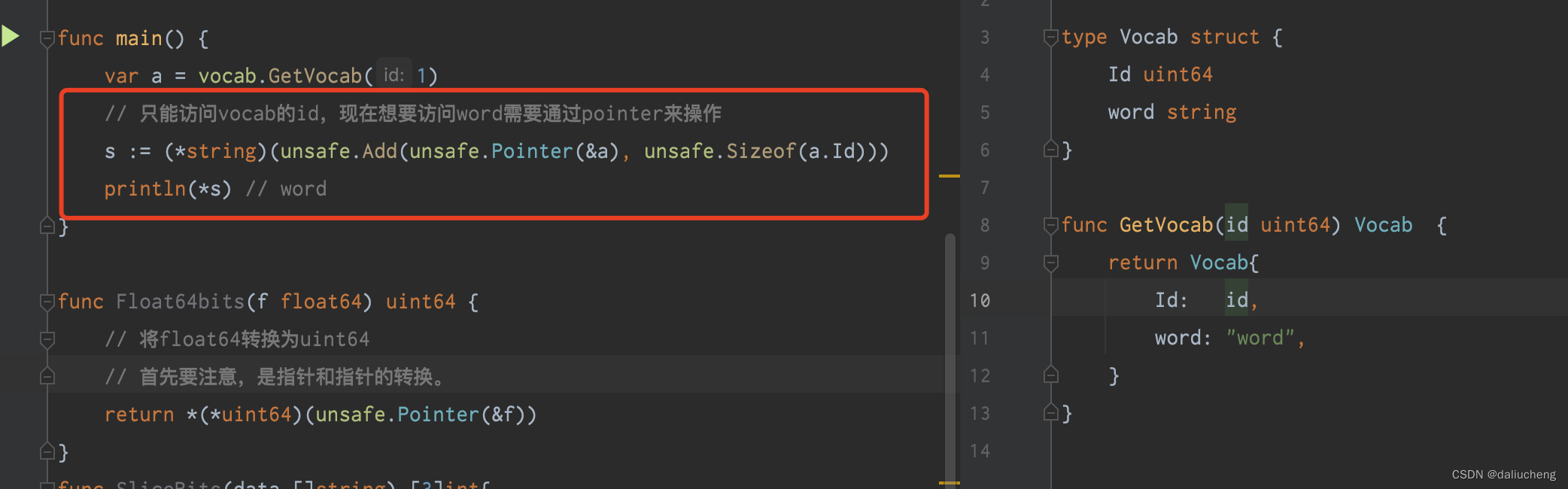
操作非导出字段
方法
Sizeof
func Sizeof(v ArbitraryType) uintptr
Sizeof函数返回类型v的大小。ArbitraryType表示任意类型。
package main
import (
"fmt"
"unsafe"
)
type Point struct {
x, y int
}
func main() {
var p Point
size := unsafe.Sizeof(p)
fmt.Println(size) // Output: 16
var p1 = ""
size1 := unsafe.Sizeof(p1)
fmt.Println(size1) // Output: 16 // string对应的结构体是reflect.StringHeader,StringHeader有两个字段 Data:uintptr类型,表示底层数组,Len int类型,表示数组长度,
}
SizeOf返回的是p类型的的大小,也就是Point类型所占的空间大小
int占8个字节,这里有两个变量,x,y结果就是16
顺便来看看,go中用map实现set的时候,v为什么是空结构体?
func main() {
var a = []string{"a", "a", "b"}
set := Set(a)
fmt.Printf("%v \n", set) // outPut Set
var b = struct {}{}
sizeof := unsafe.Sizeof(b)
println(sizeof) // output: 0
}
// Set 用泛型实现set
func Set[T comparable](data []T) []T {
m := make(map[T]struct{}, len(data))
for _, item := range data {
m[item] = struct{}{}
}
res := make([]T, 0, len(m))
for t := range m {
res = append(res, t)
}
return res
}
因为空结构体不占内存空间。
Offsetof
func Offsetof(x ArbitraryType) uintptr
Offsetof函数返回结构体字段x相对于结构体起始位置的偏移量。ArbitraryType表示任意类型。
type Point struct {
x, y int
}
func main() {
var p Point
offset := unsafe.Offsetof(p.y)
fmt.Println(offset) // Output: 8
}
Point结构体中,y变量相对于起始位置偏移量为8,因为y前面有x,x为int,int占在64机器上占8个字节
Alignof
func Alignof(v ArbitraryType) uintptr
Alignof函数返回类型v的对齐方式。ArbitraryType表示任意类型。
type Point struct {
x, y int
}
func main() {
align := unsafe.Alignof(Point{})
fmt.Println(align) // Output: 8
}
Add
func Add(p unsafe.Pointer, x uintptr) unsafe.Pointer
Add函数返回指针p加上偏移量x后的指针。注意,返回的指针仍然是unsafe.Pointer类型,需要转换为具体的指针类型才能使用。
package main
import (
"unsafe"
)
type Point struct {
x, y int
}
func main() {
var p = Point{
x: 123,
y: 3123,
}
pointer := unsafe.Pointer(&p) // 将p的指针转换为 pointer
yPointer := unsafe.Add(pointer, unsafe.Sizeof(p.x)) // 在p的指针上,增加了8个字节的长度,其实就是int类型的长度
yPtr := (*int)(yPointer) // 此时pointer已经指向了y,将此pointer转换为 int类型的指针
println(*yPtr) // 通过指针访问y的值
}
add方法就是移动指针,在go里面不支持指针的运算,所以不能像c那样直接位移指针,但go作为新时代的c语言,在加上确实有这个需求,就提供了这种方式来操作指针。
Slice
func Slice(p unsafe.Pointer, len, cap int) unsafe.Pointer
Slice函数返回指针p开始的长度为len、容量为cap的切片。注意,返回的指针仍然是unsafe.Pointer类型,需要转换为具体的切片类型才能使用。
func main() {
arr := [10]byte{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} //数组
data := unsafe.Slice(&arr[0], len(arr)) // 从数组第0个元素开始,长度为len,返回一个地址的切片
array := *(*[len(arr)]byte)(data) // 转换为 数组类型
fmt.Printf("%v \n",array) // [0 1 2 3 4 5 6 7 8 9]
array[5] = 3
fmt.Printf("%v \n",array) // [0 1 2 3 4 3 6 7 8 9]
}
Slice函数返回一个切片,切片的开始位置是底层数组的开始位置,长度和容量都是len
Slice(ptr, len) 相当于 (*[len]ArbitraryType)(unsafe.Pointer(ptr))[:]
或者下面的例子
func main() {
arr := [10]byte{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} //数组
data := unsafe.Slice(&arr[0], 3) // 从数组第0个元素开始,长度为len,返回一个地址的切片
array := *(*[3]byte)(data) // 转换为 数组类型
fmt.Printf("%v \n",array) // [0 1 2]
array[2] = 9
fmt.Printf("%v \n",array) // [0 1 9]]
}
// 从arr创建了一个长度为3的切片
可以看这篇回答 :
How to create an array or a slice from an array unsafe.Pointer in golang?
以上就是unsafe包中常用的一些函数,使用时需要谨慎,避免出现不可预料的错误。


![[架构之路-215]- 系统分析-领域建模基本概念](https://img-blog.csdnimg.cn/img_convert/4c9251dceb3ff67823831f80be8921a6.jpeg)

![[保姆教程] Windows平台OpenCV以及它的Golang实现gocv安装与测试(亲测通过)](https://img-blog.csdnimg.cn/338ac4274be643d7ab98fe35a954cfa8.jpeg#pic_center)

![学习open62541 --- [78] 单线程和多线程的使用场景](https://img-blog.csdnimg.cn/c6d27177476b468f9048358ab74bd52a.png)