概述
最近研究超平面排列(Hyperplane Arrangement)问题的时候,发现ReLU有其缺陷,即举例来说,ReLU 无法使用单一的超平面将分离的所有数据,完整的输出,即只会输出半个空间映射的数据,而另一半空间的数据被置为0; ReLU 要完整的映射输入空间的所有数据需要至少3个节点才能办到,比如在2维的输入空间上,当只有2个节点时构成的超平面排列将输入空间划分4个区域,其中其中一定有一个区域全部输出为[0,0]即所谓的死区(Dead Region),死区在ReLU的网络中是普遍问题。
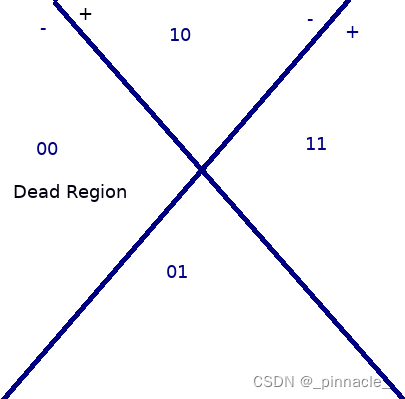
所以想用ReLU的网络构造基于二叉树结构的网络是不行的。而二叉树有非常好的性质,在分类问题上表现为无限层的二叉空间划分一定可以将输入空间中任意一点分类为所属类别,即无限逼近能力,这是一个非常强大的性质。而基于softmax的激活函数却能构造出这样的性质,而且该激活函数是构成self-attention的重要组成,后文会详细介绍。
Softmax函数
softmax函数在深度学习中被广泛使用,其公式也比较简单:
s
o
f
t
m
a
x
(
z
i
)
=
e
z
i
∑
j
=
1
n
e
z
j
softmax(z_i)=\frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j} }
softmax(zi)=∑j=1nezjezi其中
i
∈
{
1
,
2
,
.
.
,
n
}
i \in \{1,2,..,n\}
i∈{1,2,..,n} ,
n
n
n为大于1的自然数,且
s
o
f
t
m
a
x
(
z
i
)
softmax(z_i)
softmax(zi)的值域为
[
0
,
1
]
[0,1]
[0,1]。softmax函数的作用即是求任意的节点值的指数与所有节点值的指数和的比值。
softmax函数也可以写为向量形式
s
o
f
t
m
a
x
(
z
)
=
e
z
∑
j
=
1
n
e
z
j
softmax(z)=\frac{e^{z}}{\sum_{j=1}^{n} e^{z_j} }
softmax(z)=∑j=1nezjez其中
z
∈
R
n
z \in R^n
z∈Rn,即
z
z
z为
n
n
n维实向量,这里
z
j
z_j
zj表示
z
z
z的第
j
j
j维数据。
基于Softmax的激活函数
我们知道softmax本身也是激活函数,但是一般只在分类层使用,方便训练时反向传播或测试时获得近似的概率值,而很少被用于隐藏层中。但是self-attention与transformer的流行,使得softmax在隐藏层中被大量使用也产生了很好的效果,本节将解析一种基于softmax的激活函数,并研究其性质,最后解释这种激活函数与Seft-Attention的关系。
在讲解基于Softmax的激活函数之前先定义softmax的hard形式,方便解释其运行原理
h
a
r
d
m
a
x
(
z
i
)
=
{
0
z
i
≠
max
(
z
1
,
.
.
.
,
z
n
)
1
z
i
=
max
(
z
1
,
.
.
.
,
z
n
)
hardmax(z_i)=\left\{\begin{matrix} 0& z_i\ne \max(z_1,...,z_n) \\ 1& z_i= \max(z_1,...,z_n) \end{matrix}\right.
hardmax(zi)={01zi=max(z1,...,zn)zi=max(z1,...,zn) 即对于所有的输入,该输入如果不是最大值则为0,如果为最大值则为1。为了方便我们也将其写为向量形式(这个其实就是one-hot形式的表示)。
h
a
r
d
m
a
x
(
z
)
=
h
a
r
d
m
a
x
(
[
z
1
,
.
.
,
z
n
]
)
=
[
h
a
r
d
m
a
x
(
z
1
)
,
.
.
.
,
h
a
r
d
m
a
x
(
z
n
)
]
hardmax(z)=hardmax([z_1,..,z_n])=\begin{matrix} [hardmax(z_1),...,hardmax(z_n)] \end{matrix}
hardmax(z)=hardmax([z1,..,zn])=[hardmax(z1),...,hardmax(zn)] 对于有2个输出节点的神经网络而言,其结构如图:
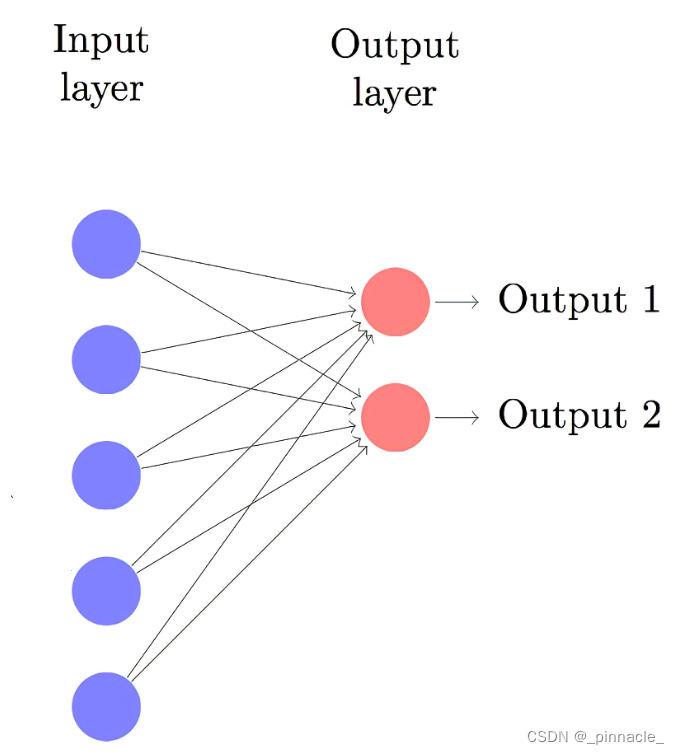
各节点的公式可以表示为:
y
1
=
w
1
T
x
+
b
1
y_1 = w_1^ \mathsf{T}x +b_1
y1=w1Tx+b1
y
2
=
w
2
T
x
+
b
2
y_2 = w_2^ \mathsf{T}x +b_2
y2=w2Tx+b2 将输出表示为向量形式
V
=
[
y
1
,
y
2
]
T
V=[y_1,y_2]^\mathsf{T}
V=[y1,y2]T,我们构造以下函数(这个函数其实就是maxout激活函数的等价形式):
m
a
x
o
u
t
(
x
)
=
h
a
r
d
m
a
x
(
V
T
)
V
maxout(x)=hardmax(V^ \mathsf{T})V
maxout(x)=hardmax(VT)V显然,
h
a
r
d
m
a
x
(
V
T
)
hardmax(V^ \mathsf{T})
hardmax(VT)只可能为
[
0
,
1
]
[0,1]
[0,1]或
[
1
,
0
]
[1,0]
[1,0],那么可以得到
m
a
x
o
u
t
(
x
)
=
{
y
1
y
1
≥
y
2
y
2
y
1
<
y
2
maxout(x)=\left\{\begin{matrix} y_1& y_1\ge y_2 \\ y_2& y_1<y_2 \end{matrix}\right.
maxout(x)={y1y2y1≥y2y1<y2可以推出
m
a
x
o
u
t
(
x
)
=
{
y
1
w
1
T
x
+
b
1
≥
w
2
T
x
+
b
2
y
2
w
1
T
x
+
b
1
<
w
2
T
x
+
b
2
maxout(x)=\left\{\begin{matrix} y_1& w_1^ \mathsf{T}x +b_1\ge w_2^ \mathsf{T}x +b_2 \\ y_2& w_1^ \mathsf{T}x +b_1<w_2^ \mathsf{T}x +b_2 \end{matrix}\right.
maxout(x)={y1y2w1Tx+b1≥w2Tx+b2w1Tx+b1<w2Tx+b2做一次代数替换,令
w
T
=
(
w
1
−
w
2
)
T
w^\mathsf{T}=(w_1-w_2)^\mathsf{T}
wT=(w1−w2)T,
b
=
b
1
−
b
2
b=b_1-b_2
b=b1−b2,那么可得
m
a
x
o
u
t
(
x
)
=
{
y
1
w
T
x
+
b
≥
0
y
2
w
T
x
+
b
<
0
maxout(x)=\left\{\begin{matrix} y_1& w^\mathsf{T}x +b\ge 0 \\ y_2& w^\mathsf{T}x +b<0 \end{matrix}\right.
maxout(x)={y1y2wTx+b≥0wTx+b<0我们发现与ReLU是比较相似的
R
e
L
U
(
x
)
=
{
w
T
x
+
b
w
T
x
+
b
≥
0
0
w
T
x
+
b
<
0
ReLU(x)=\left\{\begin{matrix} w^\mathsf{T}x +b & w^\mathsf{T}x +b\ge 0 \\ 0& w^\mathsf{T}x +b<0 \end{matrix}\right.
ReLU(x)={wTx+b0wTx+b≥0wTx+b<0 我们知道ReLU构造的超平面为
H
=
{
x
∣
w
T
x
+
b
=
0
}
H=\{ x|w^\mathsf{T}x +b = 0 \}
H={x∣wTx+b=0},同理
m
a
x
o
u
t
(
x
)
maxout(x)
maxout(x)也是一样的,与ReLU不同的是,ReLU只输出超平面一侧的数据,而丢弃了另一侧的数据;而
m
a
x
o
u
t
(
x
)
maxout(x)
maxout(x)可以输出两侧的数据,且只使用单个超平面就能实现,也就是说这个函数不存在所谓的死区问题,这是一个非常良好的性质。
以上描述了很多,其实是想引出maxout的soft形式,那么
m
a
x
o
u
t
s
o
f
t
(
x
)
=
s
o
f
t
m
a
x
(
V
T
)
V
maxout_{soft}(x)=softmax(V^ \mathsf{T})V
maxoutsoft(x)=softmax(VT)V对于2个节点,当
y
1
=
y
2
y_1=y_2
y1=y2时,
s
o
f
t
m
a
x
(
y
1
)
=
s
o
f
t
m
a
x
(
y
2
)
=
0.5
softmax(y_1)=softmax(y_2)=0.5
softmax(y1)=softmax(y2)=0.5,所以
s
o
f
t
m
a
x
softmax
softmax的这种形式并不影响上述内容
h
a
r
d
m
a
x
hardmax
hardmax形式的超平面位置,也就不影响上面得到的结论,唯一的区别是softmax最后的输出是soft形式(各节点值加权平均)的
y
y
y值,即
y
=
∑
i
=
1
n
α
i
∗
y
i
y=\sum_{i=1}^{n} \alpha_i*y_i
y=i=1∑nαi∗yi其中
∑
i
=
1
n
α
i
=
1
\sum_{i=1}^{n} \alpha_i=1
∑i=1nαi=1,这里
n
=
2
n=2
n=2,当任意
α
i
=
1
\alpha_i=1
αi=1时,
m
a
x
o
u
t
s
o
f
t
(
x
)
maxout_{soft}(x)
maxoutsoft(x) 退化为
m
a
x
o
u
t
(
x
)
maxout(x)
maxout(x)的形式。
当 n ≥ 3 n\ge 3 n≥3个节点时,也是同理, s o f t m a x softmax softmax也不影响超平面的位置,多个节点的网络会使用超平面排列(Hyperplane Arrangement)构造出类似下图的决策边界

对于 m a x o u t ( x ) maxout(x) maxout(x)当某个节点为最大值时,网络构造的分类区域中一个区域会被直接输出,如上图中3个节点的网络会有1个区域(完整包含1类模式,如蓝色区域)的数据输出,而 m a x o u t s o f t ( x ) maxout_{soft}(x) maxoutsoft(x)则是根据 s o f t m a x softmax softmax获取的权值,加权后输出。
以上就是 s o f t m a x softmax softmax 的性质的描述,且构造了 m a x o u t s o f t ( x ) = s o f t m a x ( V T ) V maxout_{soft}(x)=softmax(V^ \mathsf{T})V maxoutsoft(x)=softmax(VT)V的激活函数,其实我们会发现这个形式和self-attention是非常相似的,那么这个激活函数是否就是self-attention的等价形式呢?这个是接下来要研究的问题。
Self-Attention原理初步
上文构造了类self-attention的激活函数,而self-attention的公式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
1
d
k
Q
K
T
)
V
Attention(Q,K,V) = softmax(\frac{1}{\sqrt{d_k} } QK^\mathsf{T})V
Attention(Q,K,V)=softmax(dk1QKT)V其中Q,K,V分别表示Query,Key,Value,且
Q
=
x
W
q
Q = xW_q
Q=xWq
K
=
x
W
k
K = xW_k
K=xWk
V
=
x
W
v
V = xW_v
V=xWv即Q,K,V都是
x
x
x 经过线性变换后的数据,而
1
d
k
\frac{1}{\sqrt{d_k}}
dk1只是避免矩阵乘值过大的超参数,本质上说self-attention的核心内容为:
A
t
t
e
n
t
i
o
n
(
x
)
=
s
o
f
t
m
a
x
(
x
W
q
(
x
W
k
)
T
)
V
Attention(x) = softmax(xW_q(xW_k)^\mathsf{T})V
Attention(x)=softmax(xWq(xWk)T)V可以写为
A
t
t
e
n
t
i
o
n
(
x
)
=
s
o
f
t
m
a
x
(
x
(
W
q
W
k
T
)
x
T
)
V
Attention(x) = softmax(x(W_qW_k^\mathsf{T})x^\mathsf{T})V
Attention(x)=softmax(x(WqWkT)xT)V令
W
~
=
W
q
W
k
T
\tilde{W} = W_qW_k^\mathsf{T}
W~=WqWkT,其中
W
~
\tilde{W}
W~是一个方阵,可以得到
A
t
t
e
n
t
i
o
n
(
x
)
=
s
o
f
t
m
a
x
(
x
W
~
x
T
)
V
Attention(x) = softmax(x\tilde{W}x^\mathsf{T})V
Attention(x)=softmax(xW~xT)V而不管
w
T
x
+
b
w^\mathsf{T}x+b
wTx+b 或者
x
W
xW
xW本质都是一样的,即
x
x
x的线性变换;我们可以令
W
=
w
T
W=w^\mathsf{T}
W=wT,将
b
b
b写到
W
W
W当中可以得到
W
x
Wx
Wx,所以两者是形式等价的,
x
W
xW
xW的形式更方便程序计算。所以上节中的
m
a
x
o
u
t
s
o
f
t
(
x
)
=
s
o
f
t
m
a
x
(
V
T
)
V
maxout_{soft}(x)=softmax(V^ \mathsf{T})V
maxoutsoft(x)=softmax(VT)V与self-attention的不同之处是
x
W
~
x
T
x\tilde{W}x^\mathsf{T}
xW~xT与
x
W
v
xW_v
xWv的区别,权值不同很好理解,Attention使用了新的权值矩阵,且
W
~
\tilde{W}
W~是
n
×
n
n\times n
n×n方阵,而
W
v
W_v
Wv是
n
×
m
n\times m
n×m的矩阵;另一个不同是
x
W
v
xW_v
xWv只是
x
x
x的一个简单线性变换,而
x
W
~
x
T
x\tilde{W}x^\mathsf{T}
xW~xT则不是这样的。
为了论述方便,我们假设当 W ~ \tilde{W} W~为对角矩阵时,如
d
i
a
g
(
[
1
,
1
,
1
]
)
=
[
1
0
0
0
1
0
0
0
1
]
diag([1,1,1])=\begin{bmatrix} 1& 0 &0 \\ 0 & 1 & 0 \\ 0& 0 & 1 \end{bmatrix}
diag([1,1,1])=
100010001
x
W
~
x
T
x\tilde{W}x^\mathsf{T}
xW~xT退化为了
x
x
T
xx^\mathsf{T}
xxT,而
x
x
T
xx^\mathsf{T}
xxT一般用于协方差矩阵(Covariance Matrix)或相关矩阵(Correlation Matrix),而不管是协方差矩阵还是相关矩阵都可以用于描述矩阵各行,列向量之间的相关程度或相关关系,自协方差矩阵公式是这样的
C
o
v
x
,
y
=
E
(
(
x
−
x
ˉ
)
(
x
−
x
ˉ
)
T
)
=
[
c
x
1
,
y
1
…
c
x
1
,
y
N
…
…
…
c
x
N
,
y
1
…
c
x
N
,
y
N
]
Cov_{x,y} = E((x-\bar{x})(x-\bar{x})^\mathsf{T})=\begin{bmatrix} c_{x_1,y_1}& \dots &c_{x_1,y_N} \\ \dots & \dots & \dots \\ c_{x_N,y_1}& \dots & c_{x_N,y_N} \end{bmatrix}
Covx,y=E((x−xˉ)(x−xˉ)T)=
cx1,y1…cxN,y1………cx1,yN…cxN,yN
其中
c
x
n
,
x
n
c_{x_n,x_n}
cxn,xn表示两元素的方差,其中
n
∈
{
1
,
.
.
,
N
}
n\in\{1,..,N\}
n∈{1,..,N},而自相关矩阵是这样的
R
x
,
x
=
E
(
x
x
T
)
=
[
r
x
1
,
x
1
…
r
x
1
,
x
N
…
…
…
r
x
N
,
x
1
…
r
x
N
,
x
N
]
R_{x,x} = E(xx^\mathsf{T})=\begin{bmatrix} r_{x_1,x_1}& \dots &r_{x_1,x_N} \\ \dots & \dots & \dots \\ r_{x_N,x_1}& \dots & r_{x_N,x_N} \end{bmatrix}
Rx,x=E(xxT)=
rx1,x1…rxN,x1………rx1,xN…rxN,xN
其中
r
x
n
,
x
n
r_{x_n,x_n}
rxn,xn表示两元素相关系数。我们再把
W
~
\tilde{W}
W~设置为普通的方阵,那么
x
W
~
x
T
x\tilde{W}x^\mathsf{T}
xW~xT则表示经过
W
~
\tilde{W}
W~线性映射的
x
x
x与
x
x
x自身的相关关系矩阵。
有了相关关系的矩阵,便可以通过softmax函数获取每个元素的权值,如在自然语言里,就是每个单词的权值,再乘 V V V就是每个单词关于句子加权求和之后的表示,即所谓的Attention。
所以, m a x o u t s o f t ( x ) maxout_{soft}(x) maxoutsoft(x) 与 self-attention还是不太相同的,而self-attention确实用到了 m a x o u t s o f t ( x ) maxout_{soft}(x) maxoutsoft(x)的激活函数的性质。
总结
self-attention部分写的有点粗糙,大概解析了self-attention的部分逻辑,后面有新的内容再补充。
参考
- Maxout networks
- Attention Is All You Need
- Understand Maxout Activation Function in Deep Learning
- Correlation coefficients
- Scan and Snap: Understanding Training Dynamics and Token Composition in 1-layer Transformer
- Understanding the Covariance Matrix
![学习open62541 --- [78] 单线程和多线程的使用场景](https://img-blog.csdnimg.cn/c6d27177476b468f9048358ab74bd52a.png)