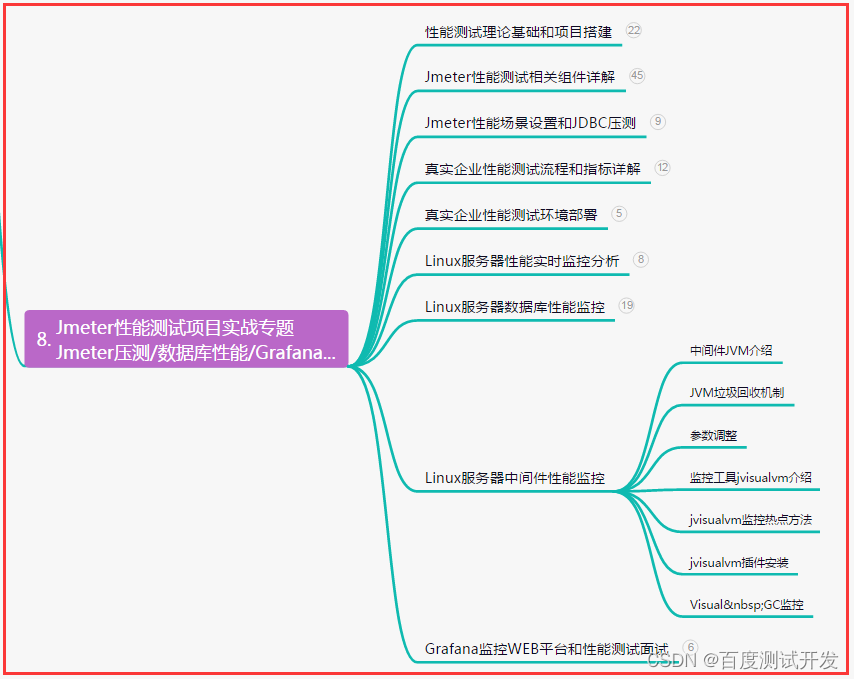
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,阿里云专家博主
- 📕系列专栏:Java设计模式、Spring源码系列、Netty源码系列、Kafka源码系列、JUC源码系列、duubo源码系列
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
- 📝联系方式:hls1793929520,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀

文章目录
- 一、引言
- 二、服务调用流程
- 1、消费端
- 1.1 动态代理的回调
- 1.2 过滤器
- 1.3 路由逻辑
- 1.4 重试次数
- 1.5 负载均衡
- 1.4.1 自定义负载均衡
- 1.6 调用服务
- 1.6.1 配置 RPCinvocation
- 1.6.2 调用 RPC 同步返回结果
- 1.6.3 等待返回结果
- 三、流程
- 四、总结
一、引言
对于 Java 开发者而言,关于 dubbo ,我们一般当做黑盒来进行使用,不需要去打开这个黑盒。
但随着目前程序员行业的发展,我们有必要打开这个黑盒,去探索其中的奥妙。
本期 dubbo 源码解析系列文章,将带你领略 dubbo 源码的奥秘
本期源码文章吸收了之前 Spring、Kakfa、JUC源码文章的教训,将不再一行一行的带大家分析源码,我们将一些不重要的部分当做黑盒处理,以便我们更快、更有效的阅读源码。
虽然现在是互联网寒冬,但乾坤未定,你我皆是黑马!
废话不多说,发车!
二、服务调用流程
1、消费端
上一篇文章,讲解了我们的消费端如何订阅我们服务端注册到 Zookeeper 的服务接口:从源码全面解析 dubbo 服务订阅的来龙去脉
既然消费端已经知道了我们的服务信息,那么下一步就要开始正式调用了
我们先从消费端聊聊服务调用的流程
1.1 动态代理的回调
我们聊到消费端订阅服务时,最终创建的代码如下:
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {
return (T) Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));
}
相信看过 动态代理 的小伙伴应该知道,当我们调用 代理 的接口时,实际上走的是 InvokerInvocationHandler 该类的 invoke 方法
public Object invoke(Object proxy, Method method, Object[] args){
// 获取方法名=getUserById
String methodName = method.getName();
// 获取参数
Class<?>[] parameterTypes = method.getParameterTypes();
// 组装成 RpcInvocation 进行调用
RpcInvocation rpcInvocation = new RpcInvocation(serviceModel, method.getName(), invoker.getInterface().getName(), protocolServiceKey, method.getParameterTypes(), args);
// 执行调用方法
return InvocationUtil.invoke(invoker, rpcInvocation);
}
这里我们重点介绍下 RpcInvocation 的几个参数:
serviceModel(Consumer):决定了服务的调用方式,包括使用哪种协议、注册中心获取服务列表、负载均衡和容错策略等。method.getName:getUserByIdinvoker.getInterface().getName:com.common.service.IUserServiceprotocolServiceKey:com.common.service.IUserService:dubbomethod.getParameterTypes:方法的入参类型(Long)args:方法的入参值(2)
我们继续往下看 InvocationUtil.invoke 做了什么
public static Object invoke(Invoker<?> invoker, RpcInvocation rpcInvocation) throws Throwable {
URL url = invoker.getUrl();
String serviceKey = url.getServiceKey();
rpcInvocation.setTargetServiceUniqueName(serviceKey);
return invoker.invoke(rpcInvocation).recreate();
}
// 判断当前的是应用注册还是接口注册
public Result invoke(Invocation invocation) throws RpcException {
if (currentAvailableInvoker != null) {
if (step == APPLICATION_FIRST) {
if (promotion < 100 && ThreadLocalRandom.current().nextDouble(100) > promotion) {
return invoker.invoke(invocation);
}
return decideInvoker().invoke(invocation);
}
return currentAvailableInvoker.invoke(invocation);
}
}
我们继续往下追源码
1.2 过滤器
// 过滤器责任链模式
// 依次遍历,执行顺序:
public interface FilterChainBuilder {
public Result invoke(Invocation invocation) throws RpcException {
Result asyncResult;
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Filter " + filter.getClass().getName() + " invoke.");
asyncResult = filter.invoke(nextNode, invocation);
}
}
这里会依次遍历所有的 filter:
ConsumerContextFilter:将消费者端的信息(远程地址、应用名、服务名)传递给服务提供者端ConsumerClassLoaderFilter:将消费者端的ClassLoader传递给服务提供者端,以便服务提供者端可以在调用时使用相同的ClassLoader加载类。FutureFilter:异步调用MonitorFilter:统计服务调用信息(调用次数、平均响应时间、失败次数)RouterSnapshotFilter:动态路由,它可以根据路由规则选择服务提供者,并缓存路由结果,以提高性能。
具体每个过滤器怎么实现的,这里就不展开讲了,后面有机会单独出一章
1.3 路由逻辑
当我们的责任链完成之后,下一步会经过我们的 路由 逻辑
public Result invoke(final Invocation invocation) throws RpcException {
//
List<Invoker<T>> invokers = list(invocation);
InvocationProfilerUtils.releaseDetailProfiler(invocation);
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
return doInvoke(invocation, invokers, loadbalance);
}
其中 List<Invoker<T>> invokers = list(invocation) 这里就是我们的路由逻辑:
List<Invoker<T>> invokers = list(invocation);
public List<Invoker<T>> list(Invocation invocation) throws RpcException {
List<Invoker<T>> routedResult = doList(availableInvokers, invocation);
}
public List<Invoker<T>> doList(BitList<Invoker<T>> invokers, Invocation invocation) {
// 这里就是我们的路由策略!!!
List<Invoker<T>> result = routerChain.route(getConsumerUrl(), invokers, invocation);
return result == null ? BitList.emptyList() : result;
}
这里的路由策略比较多,我举两个比较经典的:
-
simpleRoute(简单路由策略):默认的路由策略
-
routeAndPrint(自定义路由策略):我们可以自定义其路由逻辑
而对于整体路由的流程:
- 获取可用的服务提供者列表
- 过滤出符合条件的服务提供者
- 对过滤后的服务提供者列表进行排序
- 得到符合规定的服务提供者信息
到这里,我们路由会把符合要求的 服务端 给筛选出来,接下来就进入我们的负载均衡环节了
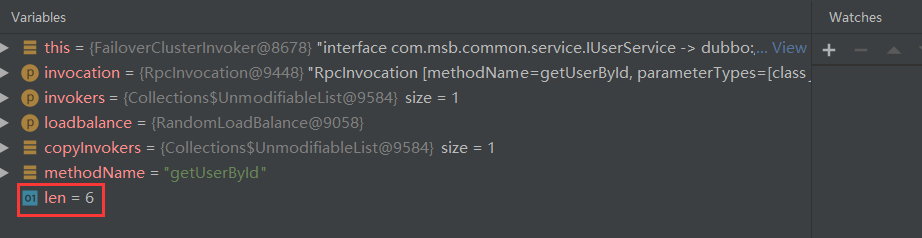
1.4 重试次数
这里我们设置 retries 为 5
@DubboReference(protocol = "dubbo", timeout = 100, retries = 5)
private IUserService iUserService;
我们看下源码里面有几次调用:根据源码来看,我们会有 5+1 次调用
int len = calculateInvokeTimes(methodName);
for (int i = 0; i < len; i++) {}
private int calculateInvokeTimes(String methodName) {
// 获取当前的重试次数+1
int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1;
RpcContext rpcContext = RpcContext.getClientAttachment();
Object retry = rpcContext.getObjectAttachment(RETRIES_KEY);
if (retry instanceof Number) {
len = ((Number) retry).intValue() + 1;
rpcContext.removeAttachment(RETRIES_KEY);
}
if (len <= 0) {
len = 1;
}
return len;
}
我们直接 Debug 一下看看:
1.5 负载均衡
这一行 LoadBalance loadbalance = initLoadBalance(invokers, invocation) 得到我们的负载均衡策略,默认情况下如下:

我们可以看到,默认情况下是 RandomLoadBalance 随机负载。
我们继续往下追源码:
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) {
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
Set<String> providers = new HashSet<String>(len);
for (int i = 0; i < len; i++) {
// 如果是重新调用的,要去更新下Invoker,防止服务端发生了变化
if (i > 0) {
checkWhetherDestroyed();
copyInvokers = list(invocation);
// 再次校验
checkInvokers(copyInvokers, invocation);
}
// 负载均衡逻辑!!!
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
invoked.add(invoker);
RpcContext.getServiceContext().setInvokers((List) invoked);
boolean success = false;
try {
Result result = invokeWithContext(invoker, invocation);
success = true;
return result;
}
}
}
这里我简单将下负载均衡的逻辑:
Invoker<T> invoker = doSelect(loadbalance, invocation, invokers, selected);
private Invoker<T> doSelect(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, List<Invoker<T>> selected){
// 如果只有一个服务端,那还负载均衡个屁
// 直接校验下OK不OK直接返回就好
if (invokers.size() == 1) {
Invoker<T> tInvoker = invokers.get(0);
checkShouldInvalidateInvoker(tInvoker);
return tInvoker;
}
// 如果多个服务端,需要执行负载均衡算法
Invoker<T> invoker = loadbalance.select(invokers, getUrl(), invocation);
return invoker;
}
Dubbo 里面的负载均衡算法如下:

这里也就不一介绍了,正常情况下,我们采用的都是 RandomLoadBalance 负载均衡
当然这里博主介绍另外一个写法,也是我们业务中使用的
1.4.1 自定义负载均衡
上面我们看到,通过 LoadBalance loadbalance = initLoadBalance(invokers, invocation) ,我们可以得到一个负载均衡的实现类
在我们的生产场景中,不同的集群上含有不同的合作方,我们需要根据合作方去分发不同集群的调用
这个时候,我们可以重写我们的 LoadBalance ,在里面重写我们 doSelect 的逻辑,而这里的 集群A 也就是我们的 group
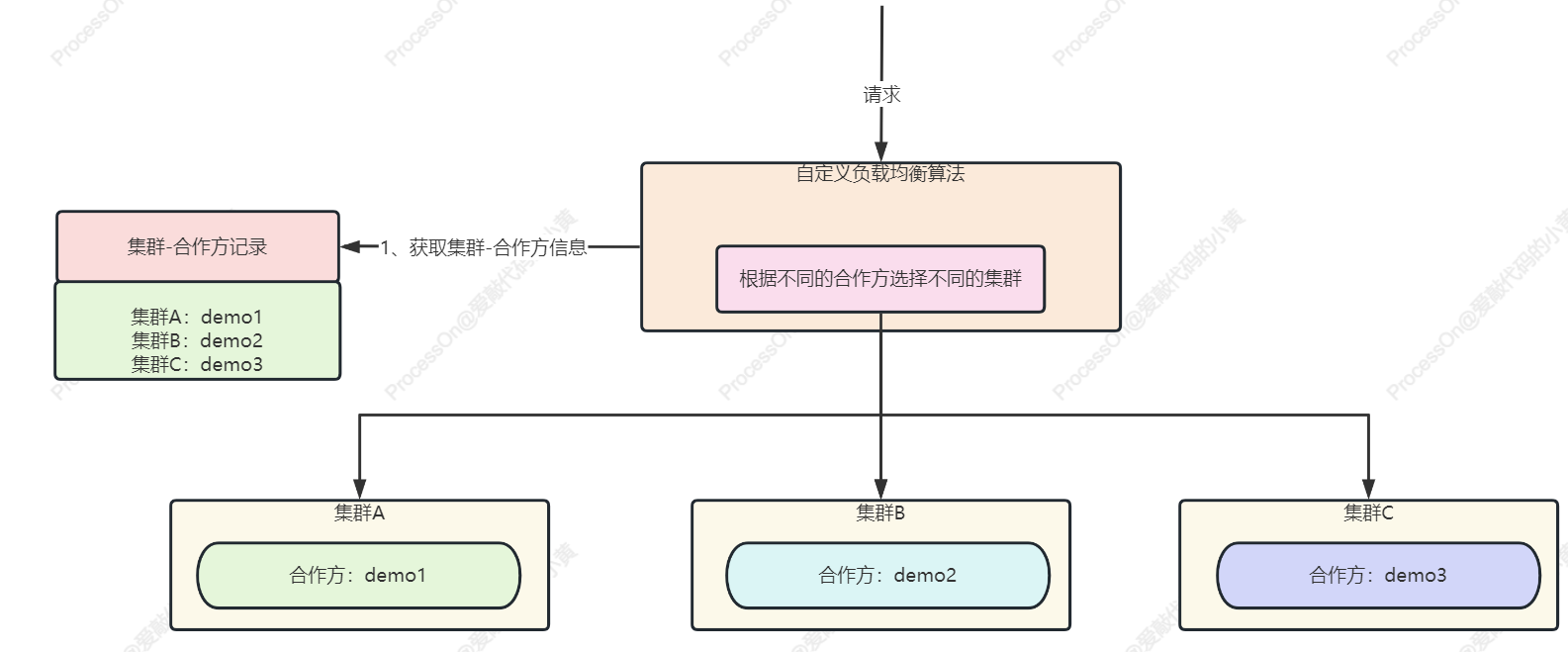
1.6 调用服务
当我们完成下面的流程:过滤器 —> 路由 —> 重试 —> 负载均衡,就到了下面这行:
Result result = invokeWithContext(invoker, invocation)
我们继续往下追:
public Result invoke(Invocation invocation) throws RpcException {
try {
// 加读写锁
lock.readLock().lock();
return invoker.invoke(invocation);
} finally {
lock.readLock().unlock();
}
}
我们直接追到 AbstractInvoker 的 invoke 方法
public Result invoke(Invocation inv) throws RpcException {
RpcInvocation invocation = (RpcInvocation) inv;
// 配置RPCinvocation
prepareInvocation(invocation);
// 调用RPC同时同步返回结果
AsyncRpcResult asyncResult = doInvokeAndReturn(invocation);
// 等待返回结果
waitForResultIfSync(asyncResult, invocation);
return asyncResult;
}
我们可以看到,对于调用服务来说,一共分为一下三步:
- 配置
RPCinvocation - 调用
RPC同步返回结果 - 等待返回结果
1.6.1 配置 RPCinvocation
这里主要将 Invocation 转变成 RPCInvocation
- 设置
RpcInvocation的Invoker属性,指明该调用是由哪个Invoker发起的 - 当前线程的一些状态信息
- 同步调用、异步调用
- 异步调用生成一个唯一的调用
ID - 选择序列化的类型
private void prepareInvocation(RpcInvocation inv) {
// 设置 RpcInvocation 的 Invoker 属性,指明该调用是由哪个 Invoker 发起的
inv.setInvoker(this);
// 当前线程的一些状态信息
addInvocationAttachments(inv);
// 同步调用、异步调用
inv.setInvokeMode(RpcUtils.getInvokeMode(url, inv));
// 异步调用生成一个唯一的调用 ID
RpcUtils.attachInvocationIdIfAsync(getUrl(), inv);
// 选择序列化的类型
Byte serializationId = CodecSupport.getIDByName(getUrl().getParameter(SERIALIZATION_KEY, DefaultSerializationSelector.getDefaultRemotingSerialization()));
if (serializationId != null) {
inv.put(SERIALIZATION_ID_KEY, serializationId);
}
}
1.6.2 调用 RPC 同步返回结果
private AsyncRpcResult doInvokeAndReturn(RpcInvocation invocation) {
asyncResult = (AsyncRpcResult) doInvoke(invocation);
}
protected Result doInvoke(final Invocation invocation){
// 获取超时时间
int timeout = RpcUtils.calculateTimeout(getUrl(), invocation, methodName, DEFAULT_TIMEOUT);
// 设置超时时间
invocation.setAttachment(TIMEOUT_KEY, String.valueOf(timeout));
// 从dubbo线程池中拿出一个线程
ExecutorService executor = getCallbackExecutor(getUrl(), inv);
// request:进行调用
CompletableFuture<AppResponse> appResponseFuture = currentClient.request(inv, timeout, executor).thenApply(obj -> (AppResponse) obj);
FutureContext.getContext().setCompatibleFuture(appResponseFuture);
AsyncRpcResult result = new AsyncRpcResult(appResponseFuture, inv);
result.setExecutor(executor);
return result;
}
这里的 currentClient.request 进行请求的发送:
public CompletableFuture<Object> request(Object request, int timeout, ExecutorService executor){
return client.request(request, timeout, executor);
}
public CompletableFuture<Object> request(Object request, int timeout, ExecutorService executor){
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setData(request);
DefaultFuture future = DefaultFuture.newFuture(channel, req, timeout, executor);
channel.send(req);
return future;
}
这里的 channel.send(req) 是 dubbo 自己包装的 channel,我们去看看其实现
当然,我们这里如果看过博主 Netty 源码文章的话,实际可以猜到,肯定是封装了 Netty 的 channel
public void send(Object message, boolean sent) throws RemotingException {
// 校验当前的Channel是否关闭
super.send(message, sent);
boolean success = true;
int timeout = 0;
try {
// channel 写入并刷新
// channel:io.netty.channel.Channel
ChannelFuture future = channel.writeAndFlush(message);
if (sent) {
// 等待超时的时间
// 超过时间会报错
timeout = getUrl().getPositiveParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
success = future.await(timeout);
}
// 这里如果报错了,就会走重试的逻辑
Throwable cause = future.cause();
}
}
1.6.3 等待返回结果
waitForResultIfSync(asyncResult, invocation);
private void waitForResultIfSync(AsyncRpcResult asyncResult, RpcInvocation invocation) {
// 判断当前的调用是不是同步调用
// 异步调用直接返回即可
if (InvokeMode.SYNC != invocation.getInvokeMode()) {
return;
}
// 获取超时时间
Object timeoutKey = invocation.getObjectAttachmentWithoutConvert(TIMEOUT_KEY);
long timeout = RpcUtils.convertToNumber(timeoutKey, Integer.MAX_VALUE);
// 等待timeout时间
// 获取失败-直接抛出异常
asyncResult.get(timeout, TimeUnit.MILLISECONDS);
}
public Result get(long timeout, TimeUnit unit){
// 获取响应返回的数据-等待timeout时间
return responseFuture.get(timeout, unit);
}
如果没有异常,如下图所示:
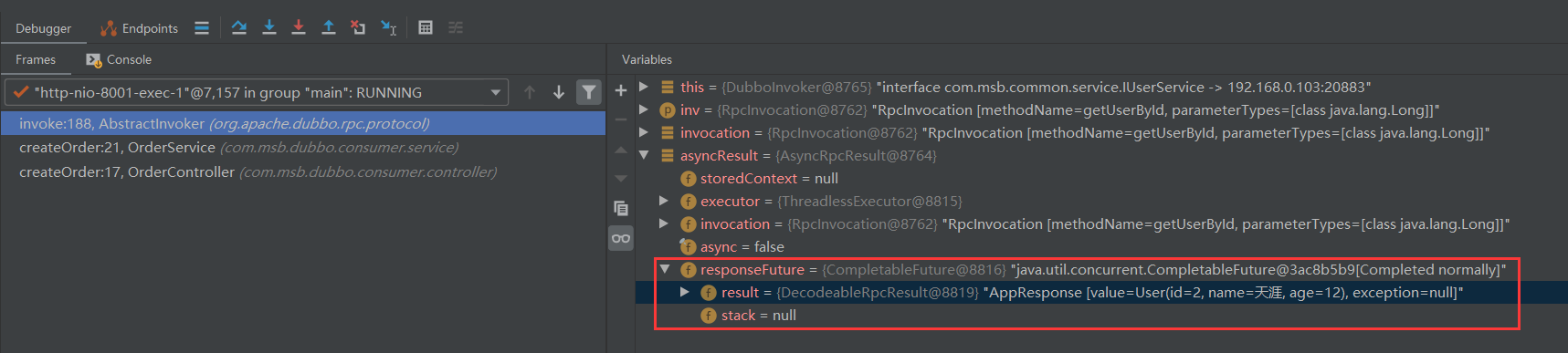
到这里我们的消费端调用服务的整个流程源码剖析就完毕了~
三、流程
高清图片可私聊博主

四、总结
鲁迅先生曾说:独行难,众行易,和志同道合的人一起进步。彼此毫无保留的分享经验,才是对抗互联网寒冬的最佳选择。
其实很多时候,并不是我们不够努力,很可能就是自己努力的方向不对,如果有一个人能稍微指点你一下,你真的可能会少走几年弯路。
如果你也对 后端架构和中间件源码 有兴趣,欢迎添加博主微信:hls1793929520,一起学习,一起成长
我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,喜欢后端架构和中间件源码。
我们下期再见。
我从清晨走过,也拥抱夜晚的星辰,人生没有捷径,你我皆平凡,你好,陌生人,一起共勉。
往期文章推荐:
- 美团二面:聊聊ConcurrentHashMap的存储流程
- 从源码全面解析Java 线程池的来龙去脉
- 从源码全面解析LinkedBlockingQueue的来龙去脉
- 从源码全面解析 ArrayBlockingQueue 的来龙去脉
- 从源码全面解析ReentrantLock的来龙去脉
- 阅读完synchronized和ReentrantLock的源码后,我竟发现其完全相似
- 从源码全面解析 ThreadLocal 关键字的来龙去脉
- 从源码全面解析 synchronized 关键字的来龙去脉
- 阿里面试官让我讲讲volatile,我直接从HotSpot开始讲起,一套组合拳拿下面试