Java学习记录
- Java中的内存区域划分
- Java中的包(package)
- Java中的枚举(Enum)
- Java中的包装类
- Java中的Math数学计算类
- Java中的Random&UUID
- Java中的format数字格式化
- Java中字符串和数字的转换
- Java中的高精度计算
- Java中的String操作(重要)
- String基本概念
- 字符串常量池(String Constant Pool)
- 字符串的初始化
- intern方法
- String类的一些常用API
- StringBuilder(重要)
- Java中的日期Date
- Java中的异常Exception(比较重要)
- 异常的基础知识
- 如何处理异常(try-catch处理)
- finally和try-catch的搭配
- 如何处理异常(throws处理)
- throw抛出新建异常
- 自定义异常
- 异常机制的好处
- Java中的正则表达式(重要)
- 字符串的合法验证
- 单字符匹配
- 预定义字符
- 量词(Quantifier)
- Pattern、Matcher类
- Matcher-贪婪、勉强、独占的区别
- 捕获组(Capturing Group)
- 边界匹配符(Boundary Matcher)
- 常用模式
- 练习
- Java中的泛型
- 泛型基本概念
- 泛型的继承概念
- 原始类型(Raw Type)
- 限制泛型的类型
- 泛型的使用限制
- Java中的函数式接口(重要)
- Lambda表达式
- Supplier函数式接口
- Consumer函数式接口
- Predicate函数式接口
- Function函数式接口
- Java中的集合(Collections)
- Java中的并发编程-多线程(究极重要)
- 进程的概念
- 线程的概念
- 多线程基本概念
- 多线程编程实现
- 多线程的内存布局
- 线程的不同状态
- 线程安全问题(比较重要)
- 线程同步解决线程安全问题
- 死锁(Deadlock)
- 线程间的通信(很重要)
- 可重入锁(ReentrantLock)
- 线程池(Thread Pool)
- Java中的I/O流(重要)
- File类基本概念
- File类的常用方法
- 练习:递归搜索某个文件夹下的全部文件
- 练习:剪切文件(支持剪切到目前不存在的目录下)
- 字符集(Character Set)
- 字符编码(Character Encoding)
- 字节流(Byte Streams)
- 练习:将内存中的字节数据写入文件
- 练习:从文件中读取字节数据到内存
- 练习:复制文件到另一个文件(字节复制)
- try-wtih-resources语句
- 字符流(Character Streams)
- 练习:将本文文件中的内容逐个字符打印出来
- 缓冲流(Buffered Streams)
- 练习:用缓冲流修改write方法
- 练习:用缓冲流修改read方法
- 数据流(Data Streams)
- 对象流(Object Streams)
- Java中的网络编程
- 网络互连模型
- 网络分层里的数据
- HTTP请求过程
- TCP/IP协议
- TCP vs UDP
- TCP建立连接之三次握手
- TCP释放连接之四次挥手
- Socket编程
这篇blog主要记录Java与C++中一些不同的概念,也就是记录Java的特色。所以,文章没有脉络,适合熟悉C++的童鞋赏阅。
Java中的内存区域划分
Java虚拟机在执行Java程序的时候,会将内存区域划分为若干个不同的数据区域,主要有:
- PC寄存器(Program Counter Register):存储JVM正在执行的字节码指令的地址。我们编写的.java文件被编译成字节码文件,JVM执行字节码指令完成实际操作的执行(比如a+1这种实际操作)。PC寄存器就存储着字节码指令的地址,用于让JVM找到需要执行的字节码指令(类似于C++中的IP寄存器,存储着下一条指令的地址)
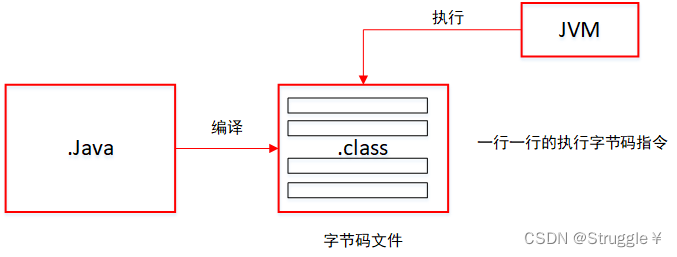
- Java虚拟机栈(Java Virtual Machine Stack):存储栈帧,也就是C++中的栈空间
- 堆(Heap):存储着GC所管理的各种对象,也就是我们平常new出来的变量,都在堆中,也就是C++中的堆空间
- 方法区(Method Area):存储着每一类的结构信息(结构信息指的是:类中有成员名,方法名,方法参数类型,返回值等等),类中的方法就是存储在这一个区域。存放的是上述东西的字节码数据,类似于C++中的数据段。
- 本地方法栈(Native Method Stack):这也是个栈,只不过用来支持Native方法的调用(比如用C语言编写的方法)
Java中的包(package)
Java的包就是C++中的命名空间(namespace),包的本质是文件夹,常见作用:
- 将不同的类进行组织管理,访问控制
- 解决命名冲突(不同包下的类可以起一样的名字)
可以看出,这就是C++中的namespace的作用。
包的命名建议:
- 为了保证包名的唯一性,一般包名都是以公司域名的到写开头,比如com.baidu.*这种。
类中第一行代码,必须使用package关键字声明自己使用的是哪一个包。



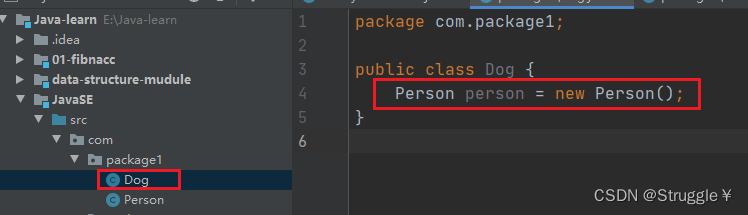
下图展示了:如何在package2的Dog类,使用package1中的Person类
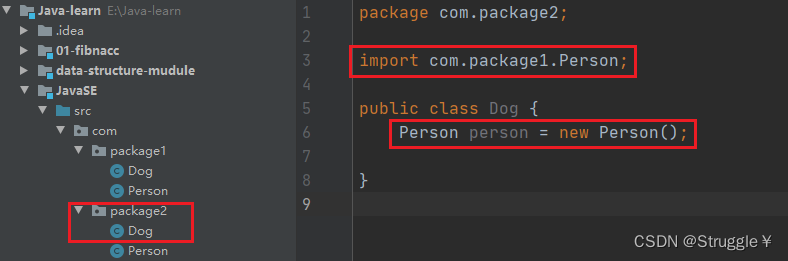
为了方便,Java编译器会为每个源文件自动导入2个包
- import java.lang.*,lang包含了Java很多常用操作,比如String类型,Interger类型等等
- import 所在文件夹.*,这是什么意思呢?这意味着,同一个包下的不同类在使用时,不需要额外导入,编译器自动帮你导入了。下图展示了package1中的Dog类使用package1中的Person类时的样子,并没有import…
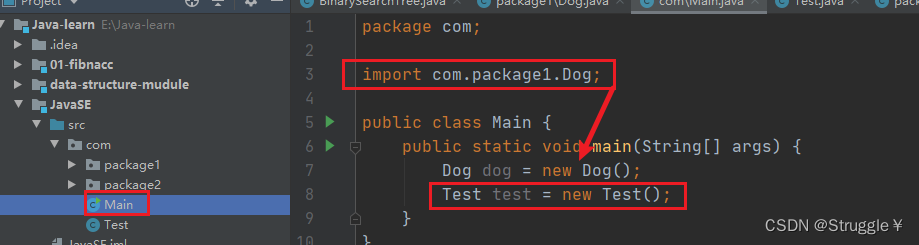
还有一个细节,编译器默认导的包,指的是同一个包下直接出现的类。对于那些间接出现的类,编译器并不默认帮你import。比如说下面展示的:Main类使用Test就可以直接使用,使用Dog必须导入。
Java中的枚举(Enum)
在开发过程中,某些变量的取值就是固定的几种(不可以取别的值),比如季节,只可以取四个值:春夏秋冬。这种需求下,使用枚举类型就是很合适的。
下面,我们先自己手动实现一个枚举类型(先不使用Java自带的枚举类型)
声明一个季节类,把构造函数私有化,这样外部就不能new一个季节对象。只能通过访问季节类内部的静态变量,赋值给季节对象。
public class Season {
private Season(){ }
public static final Season SPRING = new Season();
public static final Season SUMMER = new Season();
public static final Season FALL = new Season();
public static final Season WINTER = new Season();
}
也就是说,将来我创建season对象时,只能取到下面四个值。这就是完成了枚举类型的实现。
public static void main(String[] args) {
Season season0 = Season.SPRING;
Season season1 = Season.SUMMER;
Season season2 = Season.FALL;
Season season3 = Season.WINTER;
}
下面,我们来感受一下,Java内部自带的枚举类型如何定义,已经如何使用。
再次强调,如果一个变量的取值只可能是固定的几个值,可以考虑使用枚举类型,Java中使用enum关键字声明枚举类型:
public enum Season {
SPRING,SUMMER,FALL,WINTER
}
这样的话,等到我们用的时候,跟自定义实现枚举类型一样,都是使用Season.SPRING这种调用方式:
public static void main(String[] args) {
Season season0 = Season.SPRING;
Season season1 = Season.SUMMER;
Season season2 = Season.FALL;
Season season3 = Season.WINTER;
System.out.println(season0.name());
System.out.println(season0.ordinal());
System.out.println(season2.ordinal());
}
另外,枚举类型还有一些常用的方法,比如name就是返回当前对象的值,ordinal就是返回当前值在枚举中的索引。下图打印出了结果:

使用枚举类型,我们就可以使用switch处理,这不就是妥妥的枚举处理过程吗:
Season s = Season.SPRING;
switch (s){
case SPRING:
System.out.println("春天");
break;
case SUMMER:
System.out.println("夏天");
break;
case FALL:
System.out.println("秋天");
break;
case WINTER:
System.out.println("冬天");
break;
}
这里说一下Java中的枚举,本质就是类。因此,枚举类型定义完常量后,还可以定义一些成员。
public enum Season {
SPRING,SUMMER,FALL,WINTER;
private int temporture;
private String name;
}
枚举内部也可以声明构造函数,因为枚举本质就是类。但是不允许,我们在外部主动调用构造方法,因此如果枚举内部声明构造函数,必须不能是public或者protected类型的。
即使我们不在枚举类里面声明构造函数,Java会主动的调用构造方法初始化每一个常量。也就是说,其实那些常量本质上就是对象new出来的,只不过Java内部给你封装好了。
现在,我想弄点特色的东西给这些常量:我们为每个季节弄上最低温度和最高温度,必须在内部就初始化完毕。
public enum Season {
SPRING(0,15),
SUMMER(15,35),
FALL(10,25),
WINTER(-10,0);
private int min_temporture;
private int max_temporture;
Season(int min,int max){
this.min_temporture = min;
this.max_temporture = max;
}
public int getMin_temporture() {
return min_temporture;
}
public int getMax_temporture() {
return max_temporture;
}
}
这样的话,我们的枚举类型又多了一些自定义方法,比如获取春天的最低温度这种。
public static void main(String[] args) {
Season season = Season.SPRING;
System.out.println(season.getMin_temporture());//0
System.out.println(season.getMax_temporture());//15
}
千万不要这样调用(把枚举类中的形式拿到这来):因为构造方法不是给外部调用的。

必须要直接调用:

Java中的包装类
这个Java中一个新的概念与C++相比。包装类的出现就是为了解决基本数据类型的一些应用限制的。
基本数据类型在某些场合有如下限制:
- 无法表示不存在的值(null值),比如我想要在数组中新添加一个null值,int这种基本数据类型是不允许的。
int[] money = {100,200,-300,500,100};
int[] money = {100,200,null,500,100};//会报错
- 不能直接调用一些方法,比如引用类型String就可以调用一些方法。而基本数据类型是无法调用的。
String str = "sdda";
str.length();
解决方案就是,把这些基本类型全部包装一下,封装在类里面,然后既可以赋值null,还可以调用一些想要的方法。Java内部将所有的基本数据类型都包装成了对应的包装类,如下:
| 基本类型 | 对应的包装类 |
|---|---|
| byte | Byte |
| char | Character |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
内部实现的原理大概是这样,以Int为例:
public class IntObject {
private int value;
public IntObject(int value){
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
//一些可调用方法,比如,转为double,转为char等等
//......
}
实现了包装类时候,我们在看看效果:可以存null值,可以调用一些内置方法对基本数据类型做处理。很完美的一个设计!
Integer[] money = {100,200,null,500,100};//可以存null值
money[0].doubleValue();//将100转为double类型
可以发现一个细节,自从使用了包装类之后,可以将基本数据类型直接赋值给引用类型,这个其实是Java编译器帮你做了一个操作:调用valueOf方法,将基本类型转换为包装类。这个过程在Java中叫做 “自动装箱”
Integer i1 = 10;
//Integer i1 = Integer.valueOf(10);
但本质,将一个基本类型赋值给一个包装类的引用类型时,需要额外执行两步操作:new一个对象,然后自动装箱。只不过这两步编译器自动帮你省略了,但要知道原理。
Integer i1 = new Integer(10);//先new一个引用对象,把基本数值传进去
Integer i1 = Integer.valueOf(10);//编译器自动装箱
Integer i1 = 10;//我们书写的代码
有自动装箱,就应该有 “自动拆箱”。顾名思义,将引用类型直接赋值给基本数据类型:见引用类型的i1转换为int类型的i2,编译器默认调用intValue方法。其他基本数据类型也一样,这里只不过用int类型举例。
Integer i1 = 10;
int i2 = i1;
//int i2 = i1.intValue();
总结一下:可以直接将基本数据类型和引用包装类型互相赋值的操作机理(tips:包装类的数组和基本类型的数组不支持自动装箱和自动拆箱)
- 自动装箱:Java编译器会自动调用valueOf()方法,将基本类型转换为包装类
- 自动拆箱:Java编译器会自动调用xxxValue方法,将包装类转换为基本类型
下面重点再次介绍一下,使用包装类需要注意的细节:
- 判断两个包装类型的数值大小时,不推荐使用原运算符,比如
“==,!=, >, <”这种,而是使用equals()方法。
Integer i1 = 88;
Integer i2 = 88;
Integer i3 = 888;
Integer i4 = 888;
//不推荐
System.out.println(i1 == i2);//true
System.out.println(i3 == i4);//false
//推荐
System.out.println(i1.equals(i2));//true
System.out.println(i3.equals(i4));//true
不推荐直接使用运算符的原因也很简单,因为对比两个引用对象,其实对比的是地址值(就跟C++中,对比指向相同数据的指针一样,地址值可能是不同的),根本就不是对比的原数值。
但是,发现了一个奇怪的事了吗?System.out.println(i1 == i2)的结果竟然等于true,而System.out.println(i3 == i4)的结果为false。如果按照常理,两个结果应该都等于false。为什么System.out.println(i1 == i2)的结果等于true呢?
这里就要提到Java对于Integer类的一个封装,里面嵌入了一个IntegerCache缓存对象,会将所有的[-128, 127]的数字存放在一个缓存区,也就是只要这个数字在这个范围内,引用的值就是一样的,就是内部缓存对象的值。所以,i1和i2的引用才能一样。
再看看下面的代码,还可以进一步理解:直接使用88赋值引用对象和使用Integer.valueOf(88)赋值引用对象是一样的,都是存在缓存区里。但是new出来的,是存放在栈空间的,地址值指定不一样,所以是false。
Integer i1 = 88;
Integer i2 = Integer.valueOf(88);
Integer i3 = new Integer(88);
System.out.println(i1 == i2);//true
System.out.println(i1 == i3);//false
tips:上面的例子都是Integer,其它的那些包装类也是一样的。
Java中的Math数学计算类
java.lang.Math类中提供了常见的数学计算功能。这一节了解就行,不用死记硬背。
-
自然常数,就是我们常说的e

-
圆周率π

-
常见的数学运算:绝对值、比大小、向下取整、向上取整、四舍五入、求平方、求根方

-
继续:求e的多少次方,求以e为底的对数值,将角度转换为弧度,三角函数等等

-
生成一个[0,1)的随机数

Java中的Random&UUID
通过Math调用random方法生成的随机数,只能是[0,1)区间的,有很大的应用场景限制,因此Java有一个自带的Random类,被封装在java.util.Random中。可以更方便的生成各种随机数。
使用的时候,需要new Random对象,然后调用四种不同的生成四种随机类型的函数。比如,nextBoolean就会生成随机的true和false,nextInt就会生成随机的int数值…。注意:这样调用生成的随机数只会遵循int类型本身的数值范围,无法按照指定的范围生成随机数。

想要生成自定义范围的随机数,需要传参。
//生成[0,99]范围的整数
int num1 = (int) (Math.random() * 100);//生成[0,1)然后再乘以100,就可以做到生成[0,99]范围的整数
int num2 = new Random().nextInt(100);//生成[0,参数)范围内的随机整数
//生成[10,99]范围的整数
int num3 = 10 + (int) (Math.random() * 90);
int num4 = 10 + new Random().nextInt(90);
做一个小练习:随机生成四位大写字母的验证码。(要知道,字母的本质是ASCII码值)
只要生成[0,25]的随机数,加上A的ASCII码,就可以随意得到A~Z之间的,任何一个字母的ASCII码。然后再将其转换为char类型,就可以返回这个字母。
for (int i = 0; i < 4; i++) {
char c = (char) (new Random().nextInt(26) + 'A');
System.out.print(c);
}
也就意味着,对于字母和数字之间的通信,要依赖ASCII码值。
下面介绍一下UUID(Universally Unique Identifier),叫做通用唯一标识符。
UUID的目的是让分布式系统中的所有元素都能有唯一的标识符,而不再需要中央控制端来做标识符的指定。
在分布式系统中,所有的主机都有可能被用户访问,但是他们却共同属于一个系统,因此用户id必须唯一。那怎么办到用户1和用户2访问不同的主机所注册的用户id唯一呢?
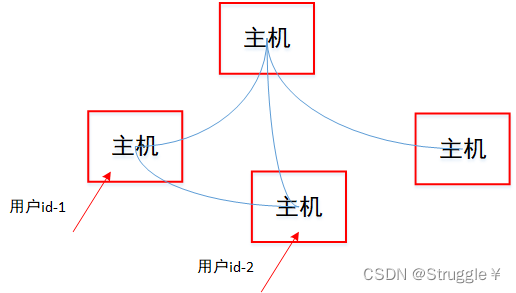
这时候UUID技术就起到了作用。可以利用java.util.UUID类的randomUUID方法生成一个128bit(32位的16进制数)的随机UUID。

Java中的format数字格式化
类似于C语言的%d%f那种,python中的format等等。了解一下就好。
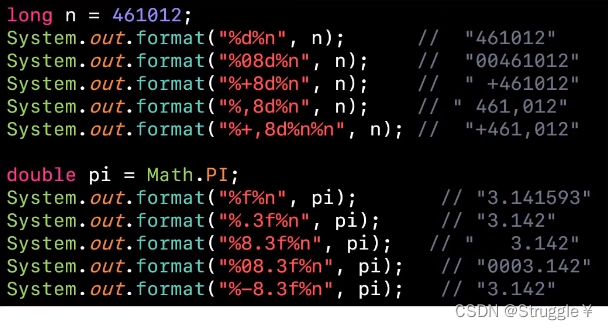
打印时的一些额外需求,可以在下表中找到。
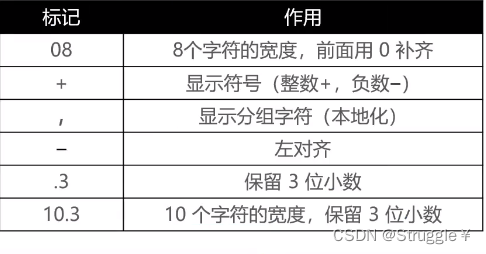
另外,使用java.text.DecimalFormat可以更便捷的控制前0、后0、前缀、后缀、分组分隔符等的自定义需求。
比如:下面的例子想要123456.789打印出123,456.789。就可以调用DecimalFormat对象的format方法完成
DecimalFormat fmt = new DecimalFormat("###,###.###");
System.out.print(fmt.format(123456.789));//123,456.789
此外还有一些别的玩法,如下所示,权当了解即可。
DecimalFormat fmt = new DecimalFormat("###,###.###");
System.out.println(fmt.format(123456.789));//123,456.789
DecimalFormat fmt1 = new DecimalFormat("###.##");
System.out.println(fmt1.format(123456.789));//123456.79
DecimalFormat fmt2 = new DecimalFormat("00000000.000");
System.out.println(fmt2.format(123456.789));//00123456.789
DecimalFormat fmt3 = new DecimalFormat("$###,###.###");
System.out.println(fmt3.format(123456.789));//$123,456.789
Java中字符串和数字的转换
字符串和数字之间的转换是很常见的,下面先介绍字符串转换为数字
字符串转换为数字,需要使用包装类的valueOf方法或者parseXXX方法。
Integer i1 = Integer.valueOf("12");//12
int i2 = Integer.parseInt("12");//12
int i3 = Integer.parseInt("FF",16);//255
Float f1 = Float.parseFloat("12.34");//12.34
float f2 = Float.parseFloat("12.34");//12.34
注意:
- 必须得是字符串,
char字符不可以作为参数 valueOf和parseInt的应用场景不同,如果是引用返回类型使用valueOf,如果是基本数据返回类型,那就使用parseInt。因为,效率问题。如果基本数据类型作为返回值,还使用valueOf,还得new,还得调用函数,很耗时。
数字转换为字符串,有哪些方法呢?
第一种方法就是:使用String字符串类的valueOf函数;第二种就是:对应包装类调用toString方法,就可以把数字转换为字符串
String str1 = String.valueOf(12.34);//12.34
String str2 = Integer.toString(255);//255
String str3 = Integer.toString(255,16);//ff,这种还可以转换为16进制
String str4 = Float.toString(12.34f);//12.34
Java中的高精度计算
先看一个例子,计算两个浮点数的乘积,可以看到,存在精度丢失问题。因为float或者double存储的并不是真正的0.7,而是0.7的近似值。所以,相乘才会出现不是0.49的问题。
double d1 = 0.7;
double d2 = 0.7;
System.out.println(d1*d2);//0.48999999999999994
float d1 = 0.7f;
float d2 = 0.7f;
System.out.println(d1*d2);//0.48999998
假如,在银行业务开发中使用double,那可能就要背锅了,不知道会损失多少钱。
Java中有一个技术可以进行高精度计算,那就是使用java.math.BigDecimal类。
使用方法,必须声明对象,然后传的参数必须是String类型。
Double v = 0.7;
BigDecimal v1 = new BigDecimal(v.toString());
BigDecimal v2 = new BigDecimal(v.toString());
System.out.println(v1.add(v2));//加,1.4
System.out.println(v1.subtract(v2));//减,0
System.out.println(v1.multiply(v2));//乘,0.49
System.out.println(v1.divide(v2));//除,1
System.out.println(v1.setScale(3));//设置v1保留三位小数,0.700
这样就实现了高精度计算。
注意,不能直接传入0.7,因为直接传入0.7本身就是不准确的,字符串是准确的。
BigDecimal v1 = new BigDecimal(0.7);
BigDecimal v2 = new BigDecimal(0.7);
直接传入0.7打印出来的结果

知其然,还要知其所以然。为什么BigDecimal可以执行高精度计算。因为BigDecimal内部存储0.7根本就不是我们认为的。而是存成一个字符数组{‘0’,‘.’,‘7’}这种,然后在做整数的加减乘除,最后返回的还是一个BigDecimal对象,这个对象值是可以直接打印的。类似于下面:
BigDecimal d = v1.add(v2);
System.out.println(d);//加,1.4
Java中的String操作(重要)
String基本概念
Java中使用java.lang.String类代表字符串,底层使用char[]存储字符数据,从Java9开始,底层使用byte[]存储字符数据。但是,现在企业中用的最多的还是Java8,因此,本节都是使用char[]存储字符数据。
char[] cs = {'a','b','c'};
String str = "abc"; //内部实现本质就是上面的样子
所有的字符串的字面量(比如直接写出来的数据:“abc”)都是String类的实例,也就是说本质就是一个对象,new出来的那种,那也就是说String的字面量都存储在堆空间。
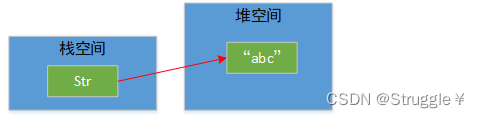
还有一个需要注意的点,String对象一旦创建完毕,它的字符内容是不可以修改的。这句话什么意思呢,我们来看一段程序:首先声明一个str = “abc”,然后改了str的内容,变成"efg",最后打印,发现确实str被改了。
String str = "abc";
str = "efg";
System.out.println(str);//efg
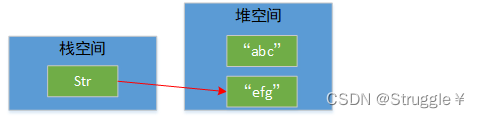
嗯?不是说不能改吗?要注意我上面的话,字符对象的内容不可更改,也就是说"efg"并不是在 "abc"的基础上改的,而是新创建了一个对象,让str指向了。原本的 "abc"没有更改。就如下面所示,"abc"消失也好怎么也罢,其内容都不会被更改。
字符串常量池(String Constant Pool)
Java中有一个字符串常量池(String Constant Pool,简称SCP),从Java7开始,SCP开始属于堆空间的一部分(之前是在方法区)。
SCP有啥特点呢?下面我们看一个例子,理解一下:
String str1 = "abc";
String str2 = "abc";
System.out.println(str1 == str2);//true
我们知道,对于引用类型来说,不要用运算符作比较。对比的不是内容,而是指针。但是,这里str1和str2竟然神奇的相等,按理说这两个是不同的对象,应该指向不同的堆空间区域,怎么可能相等呢?
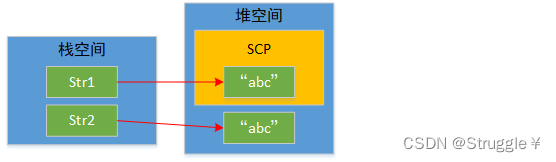
这里就该引出SCP了,SCP的特点就是,新创建的String对象要首先去SCP查看,是否有相同的字面量内容的其他对象,如果有,直接返回这个对象,如果没有,就把新的String继续放进SCP中。这个SCP是在堆空间。
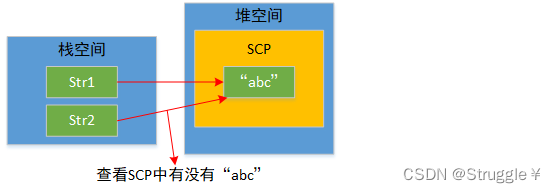
也就是说,只要是用的字面量创建String对象,就要经历这一步骤。我么还可以得出个结论:SCP中的字面量内容是唯一的。下图展示了,new出来的,和字面量是不一样的。new出来的不放在SCP中。
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1 == str2);//false
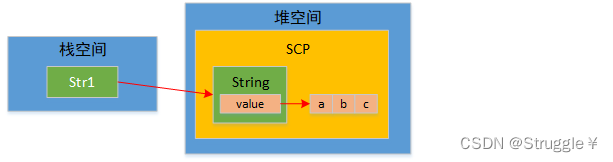
字符串的初始化
String str1 = "abc";
先铺垫一个知识点:String内部是使用char[]数组实现字符串的存放的,因此新建一个String对象,str1首先指向这个String对象,然后String对象内部的value数组指向真正存储内容的字符数组(对于字面量来说,String对象和字符数组都在SCP中)。如下图所示,体现了一个String对象的所有内存布局。
铺垫完这个知识点, 我们来看一下字符串初始化的例子,并分析内存布局是如何的。
字符串的初始化方法有很多,大概就是下面几种:
String str1 = "abc";//字面量初始化
String str2 = new String("abc");//new一个String对象初始化,并传入字面量
String str3 = new String(str1);//利用字面量对象初始化
String str4 = new String(str2);//利用new出来的String对象初始化
char[] cs = {'a','b','c'};
String str5 = new String(cs);//利用char字符数组初始化
String str6 = new String(str5);//利用字符数组初始化的String初始化
现在,我要画出所有遍历的内存布局,感受一下
- str1指向的对象是字面量,一定是存在SCP中
- str2指向的是new出来的String,并且传入的参数是字面量。根据Java源码,我们知道这种情况是把字面量的value直接赋值给当前对象的value。也就是说,把字面量的value赋值给当前String对象的value。我们知道字面量只要相同那就是SCP中的同一个,因此str2的value和str1的value是一个。由于str2是先new出来的,因此String对象的内存就是在普通的堆空间。
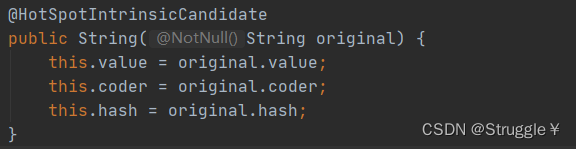
- str3利用String对象str1初始化,也就是说str1的value会传递给str3的value
- str4利用String对象str2初始化,也就是说str2的value会传递给str4的value。因为str1和str2的value都是一个,所以str1~str4都是一个value,都共用str1的value。
- str5是利用char数组初始化,根据Java源码,用char数组最为构造函数参数时,会new一个char数组出来。然后把传进来的char数组内容放在这个新new的char数组中,当做当前对象value的值。

- str6利用String对象str5初始化,跟上面一样了,str5的value会传递给str6的值。
- 当然,字符串数组,也是数组,也是引用类型,内存也在堆空间。
所以,所有的变量内存布局如下所示。希望好好理解一下,搞清楚本质。
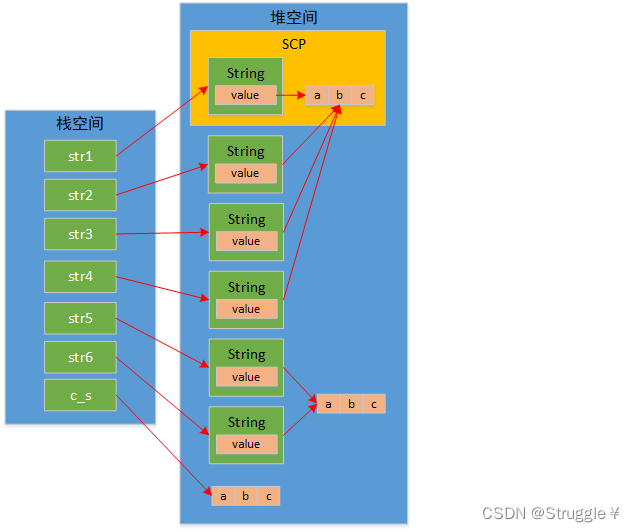
总结:字符串初始化有四种方法,分别是:
1、字面量直接初始化
2、new String对象,参数传入字面量
3、new String对象,参数传入String对象
4、new String对象,参数传入char数组
intern方法
这个方法,很不常见,但是有必要了解一下!
String str1 = "abc";
String str2 = str1.intern();
调用方法就是str.intern()。作用是
- 如果SCP中存在与str内容一样的字符串对象C时,就返回C
- 否则,将str加入到SCP中,返回str
简单地说就是把str放到SCP中,但是要先判断之前有没有,如果之前就有就不用放了,直接返回之前的对象。
String str1 = new String("abc");
String str2 = str1.intern();
String str3 = "abc";
System.out.println(str2 == str3);//true
System.out.println(str1 == str2);//false,不止为何,应该有bug
System.out.println(str1 == str3);//false,不止为何,应该有bug
我认为intern的作用就是能把new出来的String也放在SCP中(因为之前只能是字面量存储在SCP中)。
String类的一些常用API
记住某些API即可,就不一一解释了,没啥意义。
//去除左右的空格
System.out.println(" 123 456 ".trim());//123 456
//小写变大写
System.out.println("abc".toUpperCase());//ABC
//大写变小写
System.out.println("ABC".toLowerCase());///abc
//查看字符串中是否包含某个字符子串
System.out.println("123456".contains("234"));//true
//查看字符串是否以某段字符串开头
System.out.println("123456".startsWith("123"));//true
//查看字符串是否以某段字符串结尾
System.out.println("123456".endsWith("456"));//true
//按照某个字符分割字符串,可以转换成数组打印
System.out.println(Arrays.toString("1_2_3_4".split("_")));//[1, 2, 3, 4]
//比较字符串,一个一个字符去比,如果返回的是小于0,说明当前字符串比较小,反之亦然
System.out.println("abc".compareTo("adc"));//-2
//忽略大小写也能比较
System.out.println("abc".compareToIgnoreCase("aDc"));//-2
//比较字符串是否相等
System.out.println("abc".equals("aBc"));//false
//忽略大小写比较是否相等
System.out.println("abc".equalsIgnoreCase("aBc"));//true
//截取字符串,从索引3开始,一直到最后
System.out.println("xhb12138zmm".substring(3));//12138zmm
//按照区间截取字符串,从3开始,8结束,区间是左闭右开[3,8)
System.out.println("xhb12138zmm".substring(3,8));//12138
//从左向右,检索字符首次出现的位置
System.out.println("xhb12138zmm".indexOf("1"));//3
//从右向左,检索字符首次出现的位置,返回的索引还是正常的索引
System.out.println("xhb12138zmm".lastIndexOf("1"));//5
字符串的截取是很常用的,因此这个说一个小例子:截取mj字符,就有了如下步骤,好好理解吧!
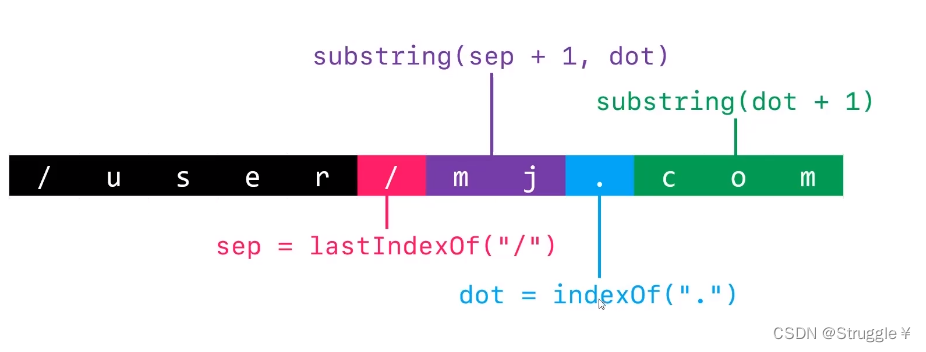
StringBuilder(重要)
这个是一个类,服务于String的一个类。这个类有什么用呢?
在进行大量字符串的改动操作时(比如拼接,替换,插入,删除)使用String会非常消耗内存。而使用StringBuilder,效率是最高的。
比如下面的拼接例子,使用String也能完成拼接,使用StringBuilder对象调用append也能完成拼接。但是效率差很多。
String s1 = "" + "123" + "456";
StringBuilder s2 = new StringBuilder();
s2.append("123").append("456");
System.out.println(s1);//123456
System.out.println(s2);//123456
我们实际演示一下,这两个操作在进行大量的字符串改动操作时的时间消耗。我们设置50000次迭代,采样不同的方法拼接
long begin = System.currentTimeMillis();
String s1 = "";
for (int i = 0; i < 50000 ; i++) {
s1 += i;
}
long end = System.currentTimeMillis();
System.out.println("String -> " + (end - begin));
long begin2 = System.currentTimeMillis();
StringBuilder s2 = new StringBuilder();
for (int i = 0; i < 50000 ; i++) {
s2.append(i);
}
long end2 = System.currentTimeMillis();
System.out.println("StringBuilder -> " + (end2 - begin2));
可以看出时间的消耗差距是非常大的:

为什么String进行字符串改动时会耗时呢?
这就不得不回想之前的一个知识点了:String对象的内容一经创建不可更改。因此,String想要改动字符串必须新创建一个String对象,并把之前的丢弃。如果进行大量的字符串改动,开辟栈空间的次数就会很多,也就影响了性能。
为什么StringBuilder进行字符串改动会不太耗时呢?
那就反之亦然,因为StringBuilder改动字符串开辟的堆空间次数少。StringBuilder内部使用动态数组存放char字符数组,如果改动的话,就直接在数组中操作,在容量够用的情况下不用开辟或者销毁栈空间。假如append很多,就会进行动态扩容,扩容的大小是2倍+2。因此,时间消耗就会很少相较于String。
StringBuilder的常用方法有:append拼接,insert插入,delete删除,replace替换,reverse翻转。很常用,记住!
Java中的日期Date
在开发过程中,经常使用到的一个类,Date日期类,被封装在java.util.Date中(不是java.sql.Date中的)。
Date对象里包含了年,月,日,时,分,秒等信息。比如:Mon May 29 17:11:46 CST 2023 CST是中国标准时间。
下面两个Date对象都表示当前时间:
Date date1 = new Date();
Date date2 = new Date(System.currentTimeMillis());//可以传参
System.out.println(date1);//Mon May 29 17:11:46 CST 2023
System.out.println(date2);//Mon May 29 17:11:46 CST 2023
既然Date构造函数可以传参,下面表示什么意思呢?这个参数的意思是,Thu Jan 01 08:00:00 CST 1970 加上参数里的毫秒数,返回对应的时间。这个Thu Jan 01 08:00:00 CST 1970指的是计算机元年(本来计算机元年是Thu Jan 01 00:00:00 GMT 1970 ,传唤为中国时间就是早上8.)。我传入的是2000ms,也就是2s,因此打印出来的是Thu Jan 01 08:00:02 CST 1970。
Date date = new Date(2000);
System.out.println(date);//Thu Jan 01 08:00:02 CST 1970
到这,其实就能理解new Date(System.currentTimeMillis())可以返回当前时间的原理是:System.currentTimeMillis()记录着从Thu Jan 01 08:00:00 CST 1970 到当前时间的毫秒数。可以看出,有一万多亿毫秒。
System.out.println(System.currentTimeMillis());//1685351875809
下面介绍一些Date的常用方法:了解即可。
还得了解一下,日期的格式化处理,也是很常用的。被封装在java.text.SimpleDateFormat中。可以将日期对象转换为字符串形式,这样更美观
SimpleDateFormat fmt = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
String str = fmt.format(new Date());
System.out.println(str); // 2023年05月29日 17:27:51
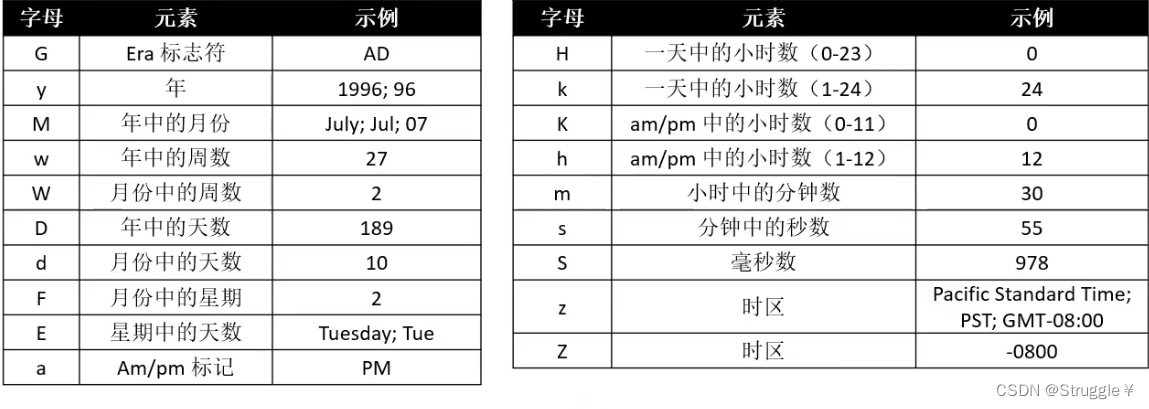
注意:里面的字母必须一样,不能更改。下图是Java指定的标准字母表,以后可查阅。
还可以将字符串解析为日期对象:使用parse方法
Date date = fmt.parse(str);
System.out.println(date);//Mon May 29 17:27:51 CST 2023
下面再介绍一下,另一个常见的日期处理类:java.util.Calendar,英文翻译过来叫做日历。
Calendar的功能比Date类更加丰富,Date中很多过期的方法都迁移到了Calendar类中。下面介绍一些Calendar的基本变量
Calendar c = Calendar.getInstance();
System.out.println(c.getTime());//Mon May 29 17:44:38 CST 2023
//YEAR表示年
System.out.println(c.get(Calendar.YEAR));//2023
//MONTH表示月,取值范围是[0,11],所以4表示5月
System.out.println(c.get(Calendar.MONTH));//4
//DAY_OF_MONTH表示这月的第几天
System.out.println(c.get(Calendar.DAY_OF_MONTH));//29
//DAY_OF_WEEK表示这周的第几天
System.out.println(c.get(Calendar.DAY_OF_WEEK));//2
//DAY_OF_YEAR表示今年的第几天
System.out.println(c.get(Calendar.DAY_OF_YEAR));//149
//HOUR表示当前小时
System.out.println(c.get(Calendar.HOUR));//5
//MINUTE表示分钟
System.out.println(c.get(Calendar.MINUTE));//44
//SECOND表示秒
System.out.println(c.get(Calendar.SECOND));//39
//MILLISECOND表示毫秒
System.out.println(c.get(Calendar.MILLISECOND));//183
还可以更改时间:包括设置,添加天数。。。
Calendar c = Calendar.getInstance();
System.out.println(c.getTime());//Mon May 29 17:51:36 CST 2023
c.set(2017,06,06);
System.out.println(c.getTime());//Thu Jul 06 17:51:36 CST 2017
c.add(Calendar.DAY_OF_MONTH,5);
System.out.println(c.getTime());//Thu Jul 11 17:51:36 CST 2017
Java中的异常Exception(比较重要)
异常在Java开发者中就跟C++中写指针那样家常便饭,是必备的,是常见的,是默认的。所以,异常在Java中是很重要的。
异常的基础知识
Java中的所有异常最终都继承于java.lang.Throwable
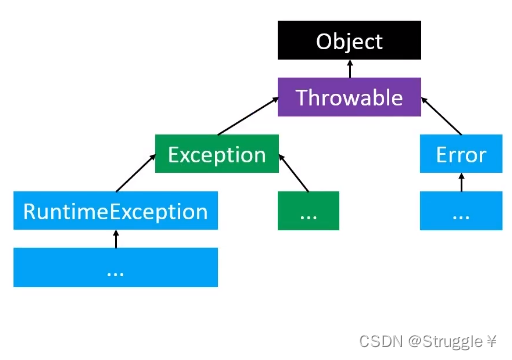
也就是说,Java中的异常可能是RuntimeException,Exception,Error等等类型的。因为Java中可能存在各种各样的异常情况,我们要对其归归类。
- 检查型异常(Checked Exception):这类异常一般难以避免编译器会进行检查,如果开发者没有处理这类异常,编译器将会报错。(除了RuntimeException,Error以外的异常都叫做检查型异常)这类异常的最大特点就是,你写代码的时候,直接报错,都不用等到你运行。如果你想要避免不报错,就必须提前处理,比如使用try-catch之类的。说白了,这类异常很可能发生,因此编译器要求开发者必须提前预防这些异常。
常见的检查型异常,这里举一个例子:比如Java有一个文件输出流的类,需要传入一个路径。这个类就会提示你,没有处理异常。这种异常就是必须要提前处理才行。

我用throws提前处理了一下,抛出可能文件没被找到的异常,就不会报错了。(因为,文件找不到大概率会发生,用户使用时,路径可能是不同的,所以这里大概率会异常)
 或者使用try-catch处理:
或者使用try-catch处理:
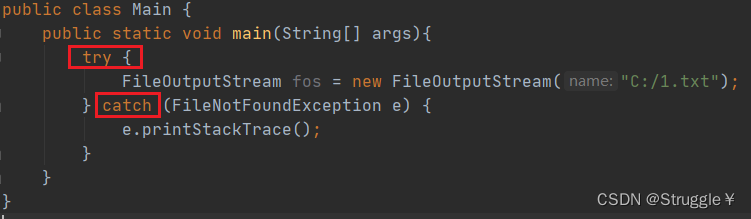
编译器一旦发生,你提前预防了这种检查型异常,它就不报错了。这里有一个小tips,有些需要字符串输入的,有可能你会瞎写,因此编译器会提前预判你。
- 非检查型异常(UnChecked Exception):这类异常一般是可以避免的,因此编译器不会在运行前检查。就算开发者没有处理这些异常,编译器也不会报错(RuntimeException,Error类型的异常都叫做非检查型异常)。说白了这类异常大概率不会发生,因此编译器没必要强制要求开发者预防。
首先看看Error异常的情况常见而定有哪些:
-
比如,有一个
java.lang.OutOfMemoryError的错误异常,表示内存不够用了,发生了错误
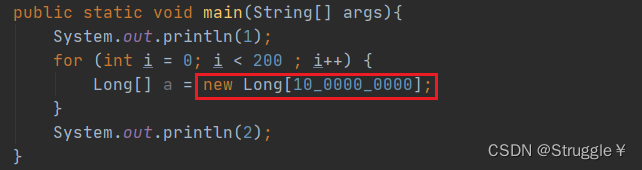
为什么Error叫非检查型异常呢,因为可以避免。比如本例的避免方式:new堆空间的时候,就不用搞这么大的内存了。 -
还有这种无限递归的Error,会抛出
java.lang.StackOverflowError类型的错误。
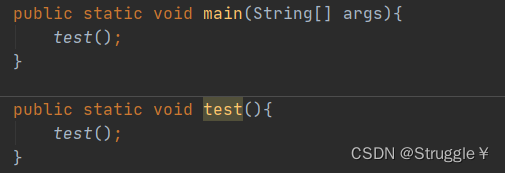

那么本例的避免方式,就注意一下不用弄成死循环就可以了。
再看看常见的RuntimeException异常都有哪些:
-
空指针异常,使用空指针调用方法


本例的避免方式,就是在调用方法前,判断一下对象是不是为空即可。 -
格式问题,比如,“abc”不可能转换为Integer类型。

 这类异常的避免,就是注意下格式问题即可。
这类异常的避免,就是注意下格式问题即可。 -
还有一个比较常见的异常,那就是数组索引越界的异常


为什么JAVA要把异常分为检查型异常和非检查型异常呢?检查型异常为什么又要必须处理呢?
因为检查型异常我们控制不了,也就是说无论你写代码多规范,都避免不了的问题,都归为检查型异常。
因为非检查型异常,我们可以控制,只要我们代码写的规范,可以100%避免这种异常,所以把他它们归为非检查异常。
那怎么处理异常呢,这里系统的说一下:
异常有两种处理方式:
try-catch组合,用来捕获异常throws,将异常往上抛
如何处理异常(try-catch处理)
怎么使用try-catch组合来捕获异常呢?下图给了一个很清晰的解释:

注意注意:只要我通过try-catch处理异常后呢,后面的代码是会正常执行的,程序不会终止。
注意注意:异常A不1可以是异常B/C的父类,因为如果是父类,就把后面的异常包含了。也就是说,只要是异常B/C都会执行异常A,那么异常B/C就没机会执行到了。同理,异常B也不可以是异常C的父类型。总之,父类的异常都要放在子类后面。
也就是说:我只要用一个终极父类Throwable就可以拦截所有的异常。
至于异常是什么类型,那就得慢慢积累。(也可以不积累,因为终极异常Throwable可以拦截所有异常)
比如刚才的数组越界问题,我们只需要把可能出现的异常ArrayIndexOutOfBoundsException捕获到,我们就可以让程序提示我们到底出现了什么异常。这种异常,你知道可能会抛出什么异常,所以设置一些检查。到时候程序出错时,可以立马提醒到你。
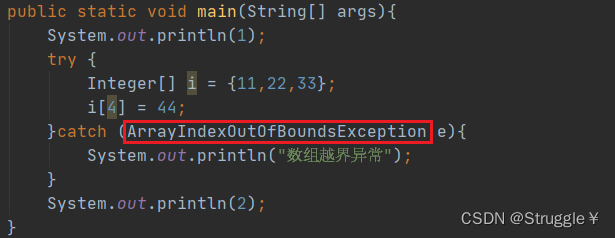
可以看出,只要处理了异常,程序就可以向下执行,不会报错,但是会给你一些提示的机会。

但是,实际开发中不可能这么low,打印一句汉字啥的。应该把异常信息打印出来,这里使用getMessage()即可打印异常信息内容,如果直接打印异常,还会把异常的类型打印出来。
System.out.println(1);
try {
Integer[] i = {11,22,33};
i[4] = 44;
}catch (ArrayIndexOutOfBoundsException e){
System.out.println(e.getMessage());//Index 4 out of bounds for length 3
System.out.println(e);//java.lang.ArrayIndexOutOfBoundsException: Index 4 out of bounds for length 3
}
System.out.println(2);
这些还不是终极打印方法,我们最最最常用的方法,是想知道那行代码出现了问题,也就是可以通过打印信息,定位到那个文件,那行代码出现了问题。也就是使用e.printStackTrace()方法,可以定位到那个文件的哪行代码。
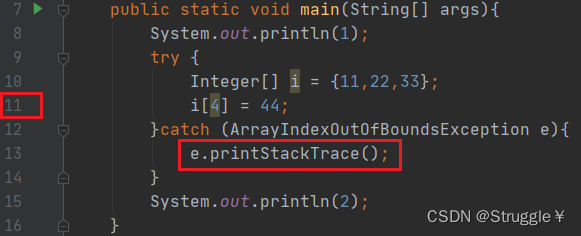

这里注意,虽然输出了一堆红色,但是程序是继续执行的,并没有终止,跟上面的一样。
一个catch可以捕获多种类型的异常,也就是说可以把三个catch合并:

这里的e是final类型,不可以在下面修改。
思考,下面程序会打印出什么?
Integer[] nums = {11,null,22};
for (int i : nums) {
System.out.println(i);
}
结果:只打印了11,因为Integer的null赋值给int类型的时候,会自动拆箱,会调用intValue方法,null怎么可以调用方法呢?所以,就会出现空指针异常。

因此,建议遍历包装类数组的时候,不要用基本数据类型接,还是要用包装类接。
finally和try-catch的搭配
finally和try-catch的搭配有两种方法:1、写在catch的后面;2、直接跟try搭配,不写catch

那finally有什么用呢?作用就是:try或者catch正常执行完毕后,一定会执行finally中的代码。
既然无论任何时候都会执行,那finally就很有用了。经常会在finally中编写一些关闭、释放资源的代码(比如关闭文件)
一定有这样的需求:当我操作文件时,操作完之后想要把文件关闭,节省资源。但是在操作的过程中可能会发生异常,这样就会使得关闭文件的代码不被执行。假设,我无论有没有异常都要在执行完毕之后关闭文件,那就要把关闭文件的代码写在finally里面,以确保必然执行。
下面的例子诠释了这一过程:

相反,如果程序像下面一样,假设红色框部分出现了异常,那么关闭文件的代码就不会被执行了。
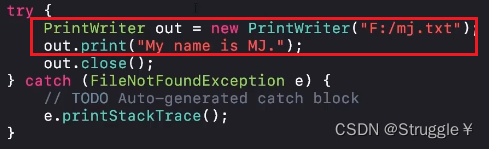
交代一下finally的一些细节:
- 如果在执行
try或者catch时,JVN退出或者当前线程被中断、杀死,那么finally可能不会执行。 - 如果
try或者catch中使用了return、break、continue等提前结束语句时,finally会在return、break、continue之前执行!!!

思考,上述程序会打印出啥呢?只有2_try_2不会被打印
如何处理异常(throws处理)
throws的作用:将异常抛给上一层方法,也就是调用本异常的方法。
这里千万要注意,throws不处理异常,只会把异常甩给上层方法(不处理异常,只做异常的搬运工)
比如说,文件未找到异常是检查型异常。main函数中有异常的语句,所以就throws给JVM了。一旦,"F:/1.txt"不存在,程序直接崩掉。因为异常抛给了JVM之前都没有处理,所以如果出现了错误就会崩掉。

相反,如果使用try-catch处理,那么程序就不会终止。
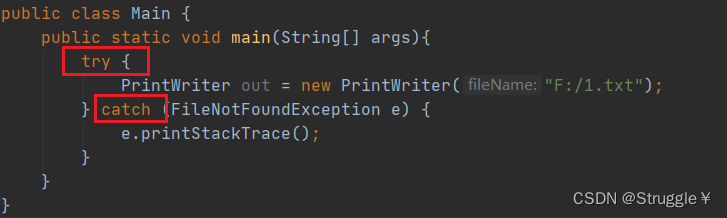
这句是try-catch的throws的区别!!!!说白了try-catch是干实事的,throws是不干实事的。
下面细说一下不断向上抛异常是啥意思。
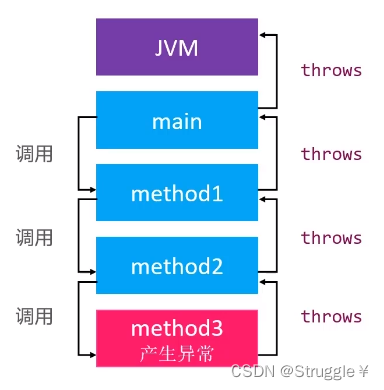
首先我定义了三个method方法,从method3函数不断地向上被调用,直到main方法。而我此时在method3内写了一个带有检查型异常的代码,因此不作任何处理会报错。
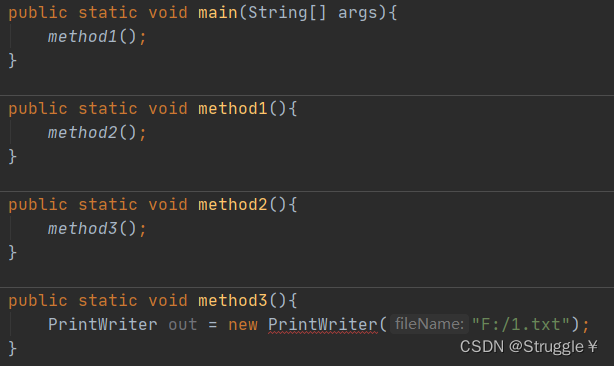
此刻,我对method3向上抛出一个异常,说明当前method3不管了,上层方法管吧。也就是抛给了调用者method2,可以看到,method2报错了,因为没有处理这个检查型异常。
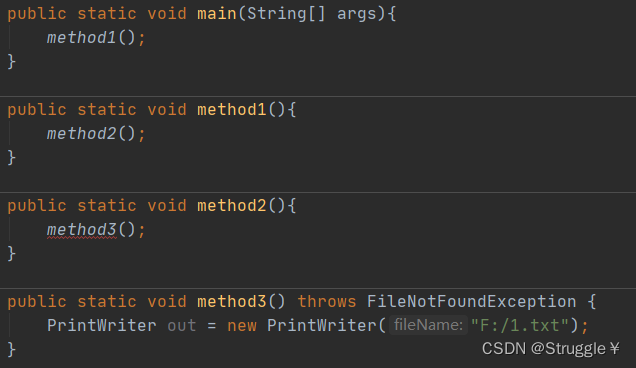
method2继续向上抛,method1报错
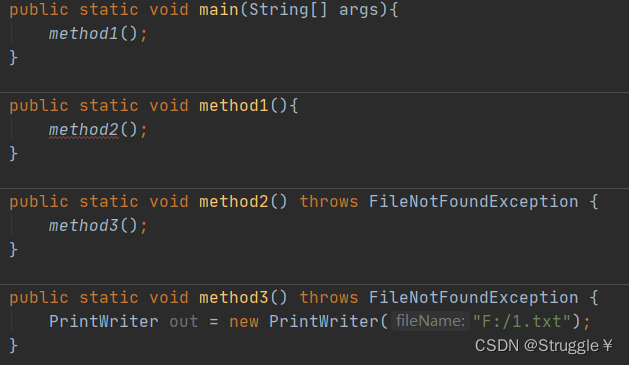
直到抛给main方法,main方法抛给JVM,编译器才善罢甘休。
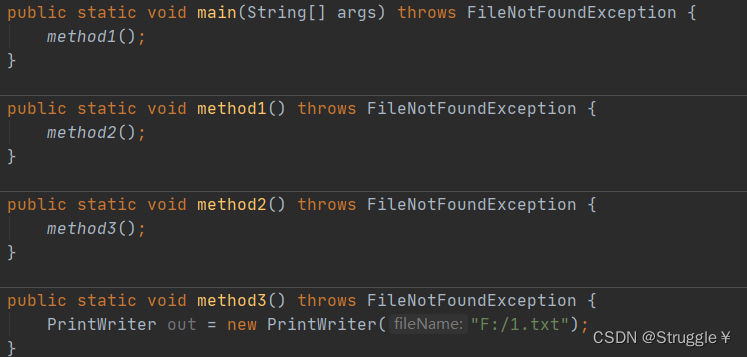
整个流程就如下图所示:如果throws一直抛到JVM,假如到时候真发生了异常,程序就会终止。
throws的一些父类子类继承关系:子类重写父类中带有异常的成员函数时,需要遵循以下规则:
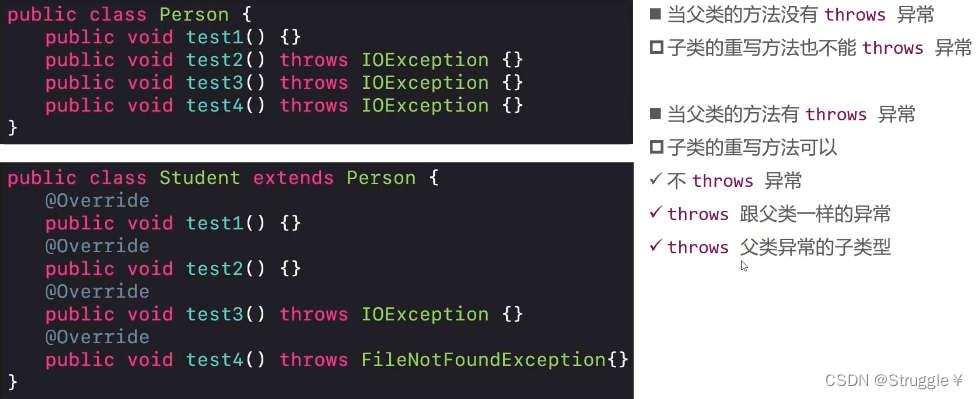
throw抛出新建异常
throw也是我们经常用的,比throws还经常用。用于强烈提示一些异常信息,并且会中断程序。比如,下面的例子中:除法是不允许除数等于0的,所以,这里判断如果除数等于0,我就抛出一个异常,并中断程序。
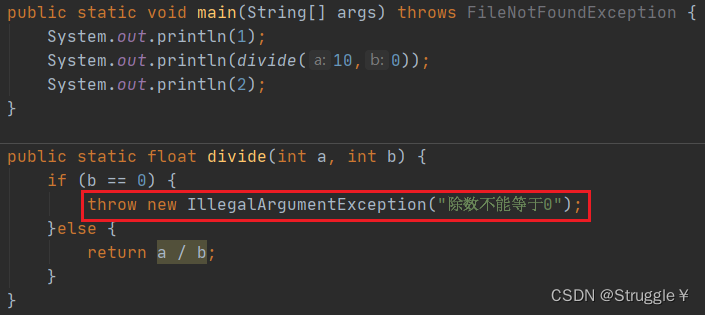
可以看到很明显的异常信息,并且中断了程序,2没有被打印出来。

其实我们还可以把抛出异常的部分用打印的方式告知我们的异常情况,但是并没有throw显眼,也没有throw友善。这就是throw的好用之处。
自定义异常
开发过程中,可以自定义异常。因为官方给的一些异常多数是通用的,没有一些专门针对特点需求的异常。有时候,我们就是需要抛出一些非常显眼,让开发者一眼就知道是什么bug的异常。
这时候就可以自定义异常。开发者自定义异常基本都是以下两种做法:
- 继承自Exception:把自定义异常声明为检查型异常,使用起来代码会稍微复杂,希望开发者重视这个异常,并且认真处理这个异常。
- 继承自RuntimeException:把自定义异常声明为非检查异常,使用起来代码会更加间接,不严格要求开发者去处理这个异常。
比如被除数不能等于0的异常,就可以直接定义一个很明显的异常,继承自RuntimeException,并super父类的构造函数,传入自己将来想输出的异常信息

将来,我就可以抛出自定义的异常了,而且在外面都不用传参,因为定义异常的时候都写好了。
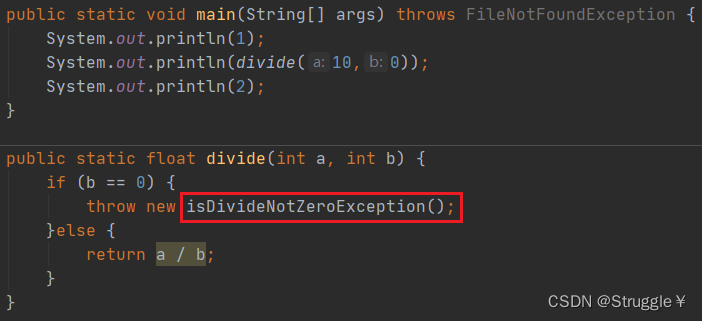
可以看到抛出的异常都是我自定义类型的了,并且还输出了我想要的自定义信息,而且还能定位那一行出错了。那将来找bug的时候,就很方便了。

异常机制的好处
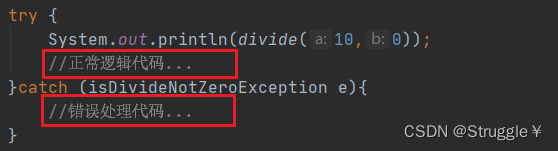
-
将错误处理代码和正常的逻辑代码明显的区分开。让别人一眼就知道catch里一定是处理错误发生后的处理代码,try一定是正常运行过程中的逻辑代码。
-
能将错误信息传播到调用堆栈中。也就意味着,使用了异常机制后,我们可以追踪出错的地方。(相反,如果我们采用打印,返回值来判断出不出错,就不会定位到出错点。)

-
能对错误类型进行区分和分组。也就是不同的错误类型,可以使用不同异常来明显的告知开发者。比如,下面的例子,我一眼就知道是除数等于0了。

Java中的正则表达式(重要)
正则表达式(Regex Expression),几乎所有编程语言里都有。之前只闻其声不见其人,今天终于学到了。
提前打一个预防针:正则表达式很多,不用挨个记住,你只需要知道哪些问题可以用正则表达式解决就可以了。
字符串的合法验证
在开发中,我们经常会对一些字符串进行合法验证。比如下面的登录注册需求,需要我们输入邮件地址,密码,手机号等。这些字符串通常是有要求的,如果不合格,系统会提示非法输入,需要重新编辑。
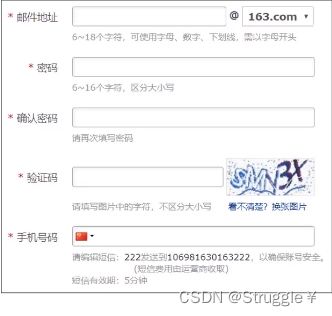
这里,我们用最土的方法来实现这个功能:6~8个字符,可使用字母,数字,下划线,需要以字母开头
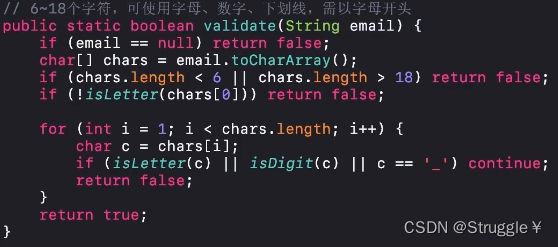
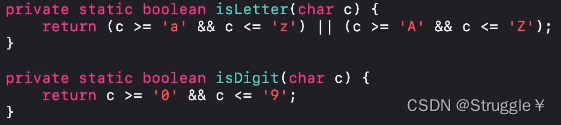
可以看到,我们要遍历每一个字符,看看是不是数字,字母,下划线。还要判断输入字符串的长度,以及第一个字符是不是字母等。需要考虑很多细节,然后编写较多的代码。
但是,我来给你看一下,正则化表达式解决这个问题,有多简单!第一个必须是字母,后面必须是数字、字母、下划线,并且整个字符串的长度是6~18,就这么简单!!!

正则表达式,就是这么牛,接下来,我们来学习正则表达式的一些语法。
单字符匹配
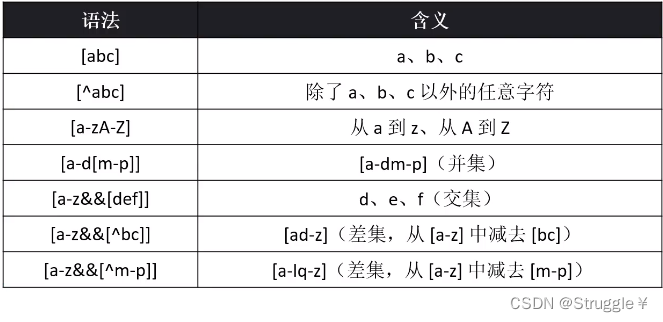
单字符匹配,总结就是下面一张表
下面我们举例子,来温习一下上面的语法:
-
正则表达式的最开始是
[bcr]的意思就是,字符串中第一个字母必须是‘b’‘c’‘r’中的其中一个。后面没有括号的at表示字符串后两个字符必须是at。也就是说:bat,cat,rat都匹配上了,所以都返回true。而hat的第一个字母不是[bcr]中的,所以返回false。

-
正则表达式的最开始是
[^bcr]的意思就是,字符串中第一个字母必须不是‘b’‘c’‘r’中的其中一个。因此这时hat返回true。

-
下面的两个例子更能巩固上面的例子。[1-5]表示必须是1~5之间的字符才能匹配,[^1-5] 表示必须不是1~5之间的数才能匹配

-
下面这个例子,可以更好的理解
[]的含义,没有写[],1-5就表示三个简简单单的字符,'1''-''5',想要返回true,必须一一匹配上才行.

-
这个例子是表中的并集的意思,
[0-4[6-8]]完全等价于[0-46-8],也就意味着,这首先是个单字符,必须是0~4或者6~8之间的数才能匹配。

-
这个例子,就是表中交集的意思。
[0-9&&[345]]也就意味着0~9和3或者4或者5之间的交集,那也就是3或者4或者5,因此下面的返回值说明了这一点。
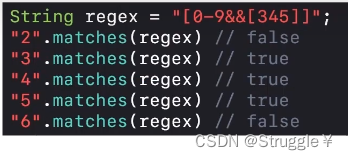
-
这个例子就是表中差集的意思,也就是说从
0~9中砍掉[345],其余的都可以匹配成功,下面的返回值说明了这一点。

预定义字符
什么叫预定义字符,就是Java中预先定义好的一些特殊字符,用来为开发者在使用正则化表达式时,提供方便。如下所示:
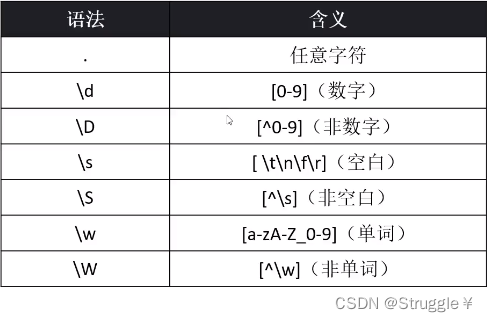
这里注意一个细节,就是我们在使用时,必须双反斜杠才行,因为Java会转义掉原有字符。

因此,为了在正则表达式中完整地表示预定义字符,需要以2个反斜杠开头,比如,"\\d"。下面我们来举一些例子,温习上面的预定义字符的语法知识
-
正则表达式中,一个
.表示匹配任意字符,因此无论输入什么字符,都会匹配成功
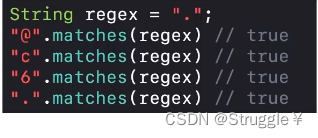
-
如果我就想匹配
.这个字符,其他的字符我都不想匹配,就需要在正则表达式中加上两个反下划线,把.变成普通的字符。这个很有用,以后我们可能需要查看文件中是不是都是以.java结尾,那我们就可以将正则表达式设置为\\.java了,如果正则表达式是.java,表示的是,任意字符+java都行,这就不是我们的想要的了。
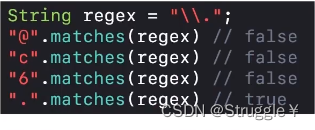
-
既然知道双反斜杠可以把一些正则表达式中的字符变为普通字符,那下面的例子我们也就能看懂了。这回
[]就不是单字符匹配中的[]了,而就是普通的[]。
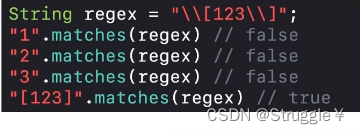
-
不是所有的上双反下划线都可以把正则表达式中的字符都变成普通字符。对这些预定义字符恰恰相反,必须得用双反下划线,比如
\\d表示数字,因此字符c返回的是false。

-
\\D表示非数字,因此c是对的,6是错的。
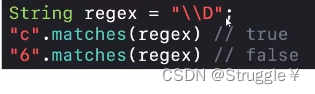
-
\\s表示空白字符,因此只有规定的那几个空白字符才能匹配上。

-
\\S表示非空白字符,因此只有普通字符才能匹配上。
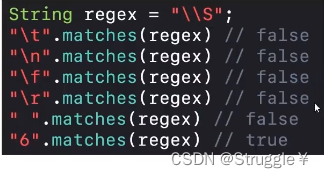
-
\\w匹配的是单词字符,Java认为单词字符包括:大小写字母,数字,下划线。因此只有+没有匹配成功。

量词(Quantifier)
什么叫正则表达式中的量词呢?顾名思义,就是有数量的词。与单字符匹配形成对比,这里可以多个字符。量词有三种模式,分别是贪婪,勉强,独占。后续会解释,这三者的区别,我们默认使用的是贪婪模式。
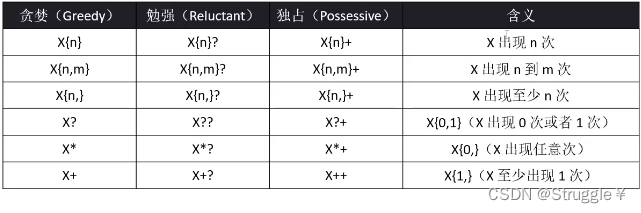
下面,我们还是举例子,来说明这些正则表达式的用法:
-
对应
X{n}。大括号{}前面有一个数字6,这个大括号就为6这一个独立的字符服务。6{3}也就意味着6必须连着出现3次,才能匹配成功。下面的打印正好说明这一点。
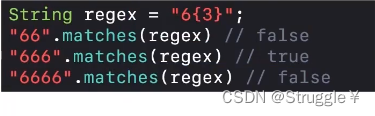
-
对应
X{n,m}。下面的例子,表示6要出现2~4次都可以匹配成功
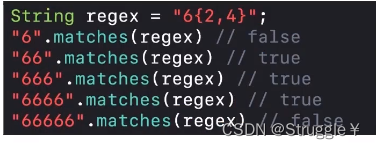
-
对应对应
X{,}。表示6至少出现2次,最多可以出现很多次了。。。
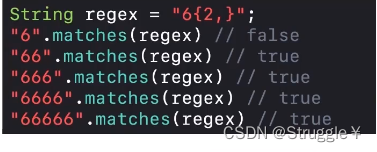
-
对应
X?。等价于6{0,1},表示出现0次或者1次6都可以匹配成功。(不出现6,也不可以出现其他字符,这样不被认为出现了0次6,出现0次6只有一种情况,那就是没有字符)
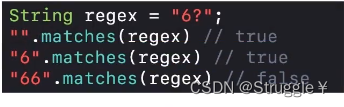
-
对应
X*。表示可以出现任意次的6,都可以匹配成功,0次,1次,2次都可以

-
对应
X+。表示可以出现至少一次的6,0次不行,1次及其以上可以匹配成功

Pattern、Matcher类
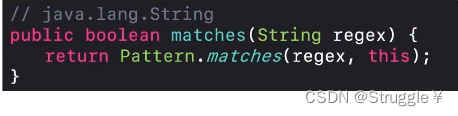
String中的matches方法底层用到了Pattern和Matcher两个类。
matches就是我们前面使用的匹配方法,这是String类下的, String.matches(regex)的意思是传入一个正则表达式,看看是否和我们输入的`String``对象匹配。
实际上,String的matchs方法底层是这么写的:
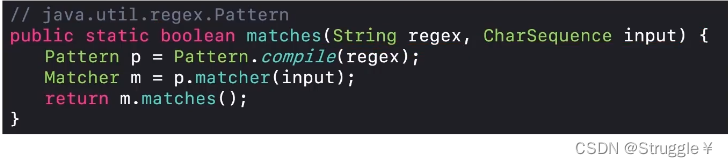
首先String的matchs方法调用的是Pattern的matches方法:
Pattern的matchs方法内部调用了Matcher的matches方法
下面的程序中,正则表达式要求三个连续的数字,而input明显不匹配(整个字符串不知只有3个数字,还有下划线)。所以会返回false。

但是我实际应用中可能存在这样的需求:我就想看看字符串中有没有连续的3个字符,然后进行一些操作啥的。很多时候,我们并不是想看整个字符串是不是完全匹配,而是想看看其中有没有子串是匹配的。这时候直接使用matches是不行的。
这时候,我们就要使用Matcher类的一些其他方法,实现这种自定义的需求。我们就可以通过Pattern和Matcher类,把内部的原理实现出来。
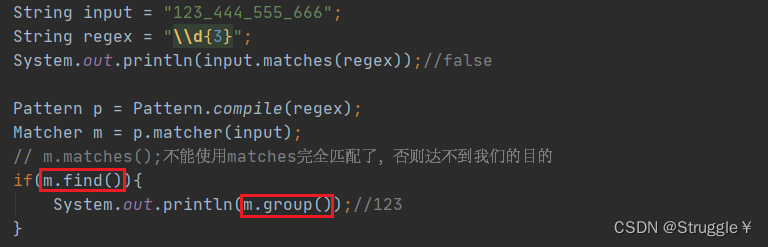
注意,不想要字符串和正则表达式完全匹配,就不要使用matches方法。要使用find方法(find方法从头开始找,一点找到匹配正则的字符串立马返回true,并将匹配到的字符串存在group里)
如果想要获取匹配的位置,就调用start和end方法,返回匹配到的子串的索引位置,遵循左闭右开。
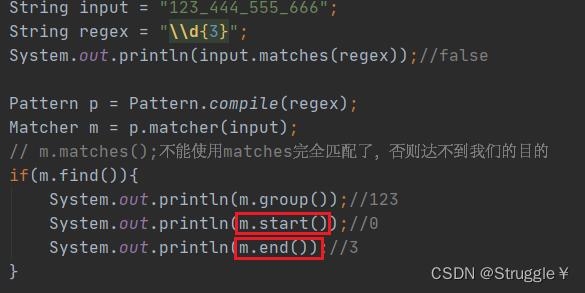
find函数有一个特点,只能匹配一次,只要匹配到了,直接结束返回true。如果匹配了整个字符串还没匹配到,就返回false。
所以,如果想要获得一个字符串所有的匹配结果,可以使用while循环:
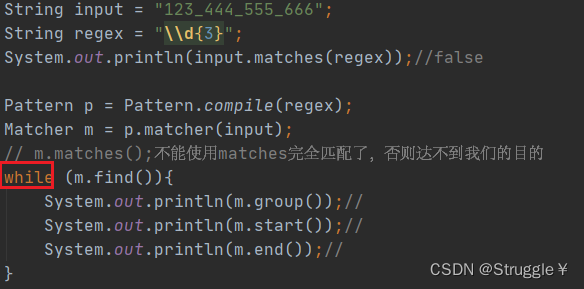
可以看出把所有的匹配子串都找出来了

这个需求是经常遇到的:通过正则表达式搜索出符合条件的子串。
既然这么常用,那我们就封装一下。功能就是:传入正则表达式和字符串,可以返回从字符串中找到所有匹配正则表达式的子串,并返回子串和对应的索引位置。(这个flags是啥,后面我们再说)
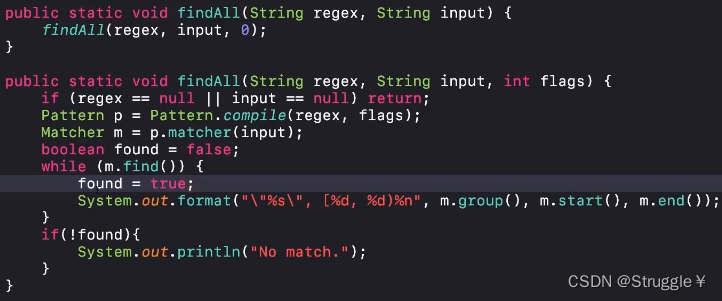
下面我们就举一些例子,熟悉一下Matcher类的使用:
-
可以看出,把所有123的都匹配到了
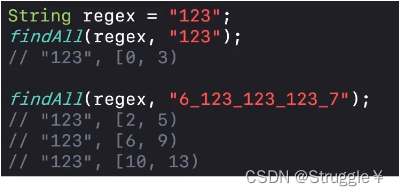
-
找连着的数字就行。34找完了就把34吐出去了,因此45并不能匹配到
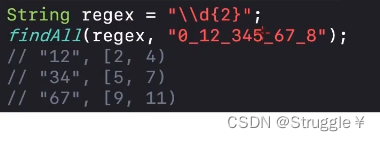
-
[abc]{3}是什么意思?看到{3},就立马把前面一个独立的整体复制三份,也就等同于[abc][abc][abc]。因此三个字符,只要是连续的abc中的一个就行。匹配完的字符要吐出去,下次不可匹配。

-
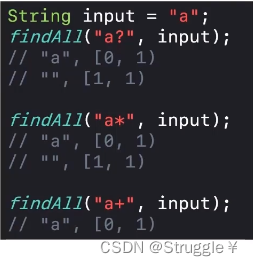
input是空串,第一个正则是
“a?”表示a出现0次或者1次都行;第二个正则“a*”表示a出现任意次都行,所以0次可以;但是正则“a+”表示至少出现一次a,很明显空串不匹配,所以返回No match。

-
下面的例子有意思了。我们知道
“a?”表示a出现0次或者1次都行,因此出现1次的a被匹配到,出现0次的空字符也会被匹配到,为什么呢?因为a出现1次备匹配成功,就要把字符串中的a吐出去,因此原来的字符串就剩空字符,“a?”一看,空字符我也能匹配,所以就匹配到了。“a*”也是同理。但是“a+”表示至少出现一次,在匹配a之后剩下空串之后,明显空串不满足“a+”,所以不会被匹配到空串。
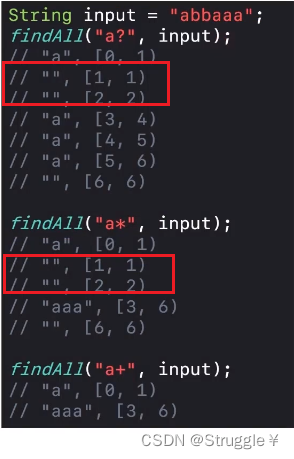
-
下面的例子更有意思。匹配完a之后遇到了b,也被判定出现了0次a,这是规定好的记住就行了。
Matcher-贪婪、勉强、独占的区别
我们平常写的其实是贪婪模式下的。'.*'表示匹配任意多次的任意字符,默认贪婪模式。'.*?'就表示勉强模式,'.*+'就表示独占模式。'.*foo'表示这一段字符必须以foo结尾,前面是啥我不管。然后根据结果,看看三种模型不同的匹配规则:
-
贪婪模式:先吞掉整个input进行匹配,很明显整个串跟正则是不匹配的。如果不能匹配,此时吐掉最后一个字符。然后再次匹配,重复此过程,直到匹配成功就结束。所以,吐掉最后一个a,发现就能匹配成功了,直接返回。
-
勉强模式:先吞掉input第一个字符进行匹配。若匹配失败,则再吞掉下一个字符。然后再次匹配,重复此过程直到匹配成功。所以先匹配到afoo,然后把匹配到的吐掉,继续再剩下的字符串里匹配,还可以匹配到aaaaaafoo。
-
整个字符串必须完全匹配才行,也就是吞掉input,进行唯一一次的匹配。

捕获组(Capturing Group)
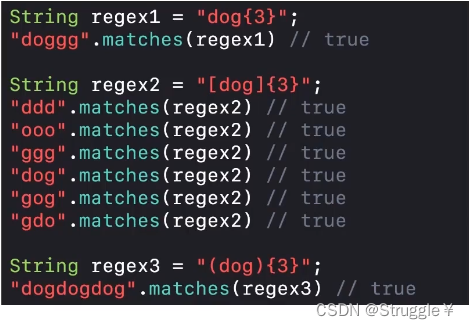
我们之前都是单字符匹配,即使使用贪婪模式,本质也是对单字符重复多次。下面我们要多字符匹配,被称为捕获组。用小括号括起来的字符,是一个组的,被称为捕获组。
看下面的例子,regex3中的(dog),就是一个捕获组。后面再加一个{3}表示的是,dog这一个整体必须连续出现三次,才能匹配成功。
下面看一个实用的的东西,叫做:捕获组-反向引用(Backreference)
什么意思呢?
可以使用反斜杠(\\)+捕获组的编号(从1开始)便捷的引用组的内容(直接获取组的内容)
下面的例子,(\\d\\d)是一个捕获组,后面\\1表示再次引用前面的内容,也就是意味着,前面是什么后面就必须是什么。所以1212匹配成功,1234匹配失败。

进阶一个例子,([a-z]{2})是第一个捕获组,([A-Z]{2})是第二个捕获组。因此\\2表示引用第二个捕获组,\\1表示引用第一个捕获组。也就意味着字符串必须是ABBA的形式才可以匹配成功。

捕获组还可以嵌套。也就意味着,小括号里还可能有小括号。
((A)(B(C))),一共是四个捕获组,分别是(C) (B(C)) (A) ((A)(B(C)))。那具体怎么编号呢,哪个是第一组哪个是第二组呢?
看左括号,哪个组的左括号在前面哪个就是前面的组
1、((A)(B(C)))
2、(A)
3、(B(C))
4、(C)
边界匹配符(Boundary Matcher)
顾名思义,匹配的是边界,而不是字符。也就是说,匹配的是字符的边界位置。匹配的是位置。跟我们之前介绍的预定义字符是有本质区别的。预定义字符是用来匹配某个字符的,而边界匹配符匹配的位置。
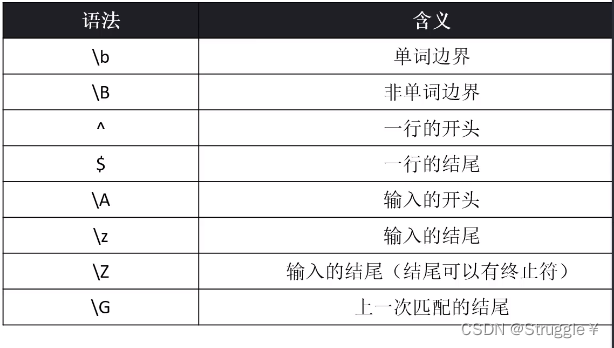
上面的表中有一个一行的开头,还有一个输入的开头。这个一行和输入有啥区别呢?
我们先来了解一些概念:终止符,也就是我们常说的\r,\n,\r\n,回车符,换行符,回车换行符都叫做字符串中的终止符。
输入的定义:整个字符串,从头到尾,不管中间有多少个终止符
一行的定义:以终止符结尾的字符串片段,或者整个输入的结尾。
如果我们的输入是:“dog\ndog\ndog”,整个字符串就叫做输入。那么三个dog都叫做一行。
下面,我么举一些例子,来感受一下什么叫边界匹配符。
-
单词边界匹配符
\b,也就意味着将来的字符串里有单词边界,才能匹配上。比如,下面的箭头所指向的位置叫做单词的边界。
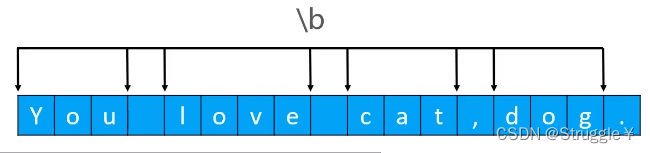
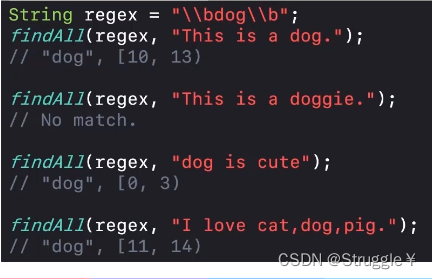
看一道例子,正则是“\\bdog\\b”意味着,将来在字符串中匹配到dog是一个独立的单词才可以匹配成功。因为该正则要求d这个字符前面是单词边界,要求g这个字符后面是单词边界。可以看到第二个doggie中的dog没有被匹配出来,因为g后面不是单词边界,只有e后面才是单词边界。
两边都是单词的边界的匹配的应用场景:匹配单个的单词,而不是字符串中的子串。 -
下面的例子中,正则是
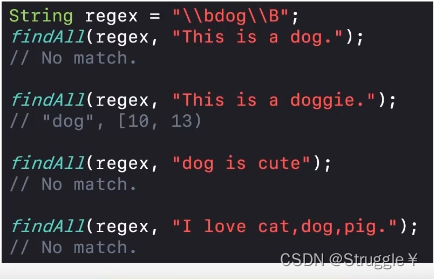
“\\bdog\\B”也就意味着,d的左边必须是单词边界,右边不能是单词边界,如果是单词边界,反而不能匹配成功。可以看出,只有doggie匹配成功了。
-
下面的例子中,正则是
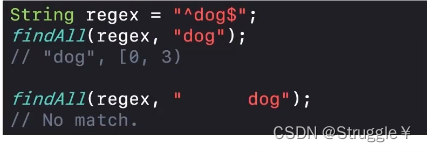
“^dog$”,也就意味着要求dog的d必须是一行的开头,g必须是一行的结尾。第二个匹配中,d不是一行的开头,所以不能匹配。
常用模式
我们在前面封装findALL的时候,有一个参数flags,表示的是可以传入一些模式。就是下面的三种常见模式:
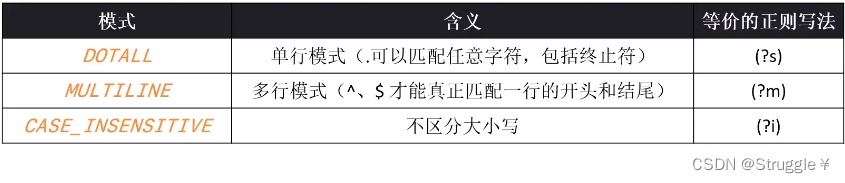
先来看一下,不区分大小写的CASE_INSENSITIVE模式。也就意味着,匹配的时候不区分大小写.下面的例子可以说明这一点。
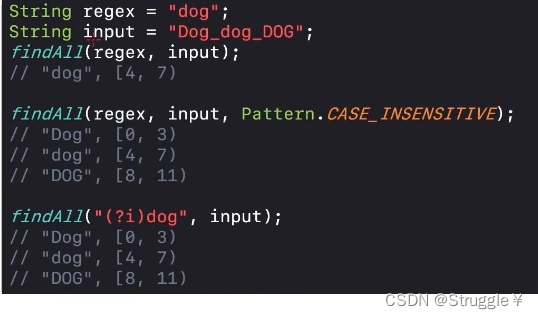
按照正常情况下,预定义字符中的.可以匹配任意字符。但是默认模式下,.无法匹配回车和换行这种终止符。当flags调换成DOTALL模式下,.就可以匹配终止符了。
练习
String类下有两个方法,replace和replaceAll,都是可以替换一些字符串中的子串。不同的是replaceAll的第一个参数是正则表达式,而replace就是目标字符子串。

对于本例而言,输出的结果是相同的。

- 练习1:将单词row换成单词line。分别使用replace和replaceAll方法。可以看出替换后的结果相同。
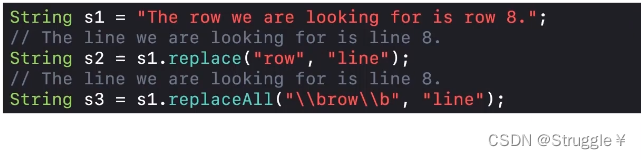
如果,是下面的例子,replace就有问题了。可以看到把Tomorrow替换成了Tomorline,把brown换成了blinen。这也就意味着replace只替换出现的row字符,并不能检查是不是单个单词。而我们使用replaceAll方法,就可以在正则表达式中清楚地定义我们就要找单个单词的row。因此,可以替换成功。
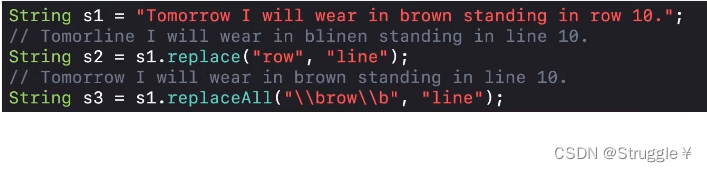
- 练习2:利用数字分割字符串。String中的split方法不仅仅可以接受固定的参数(比如下划线),还可以传入正则表达式,比如
\\d+,意味着,我可以使用至少一个数字来分割字符串。

可以看到,正则表达式在对于字符串的处理过程中有着很牛的功效。往往可以实现一些我们意想不到的功能。
Java中的泛型
C++中学过,所以这里就说一下Java中的特色。
泛型基本概念
-
从Java7开始,等号左边写泛型右边就不用写了。比如String类型在左边写了,右边的<>中就不用写了。

-
建议,声明泛型的时候,使用单个单词,不要写太长,容易有歧义,别人可能认为Type是一个类。

建议下方这么写,不建议上方那么写。

泛型的继承概念
- 泛型的继承。我们知道
Integer继承Number,但是Box<Integer>可不继承Box<Number>。也好理解,因为无论是Box<Integer>还是Box<Number>,首先这是一个Box类,Box类怎么能继承Box类呢。但是所有类都继承Object,因此这两个也继承Object。

但是,下面这种,是可以继承的。虽然是泛型类的继承,但本质是先有类的继承,再有泛型类的继承。

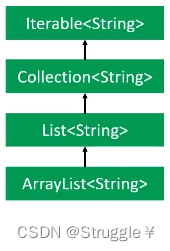
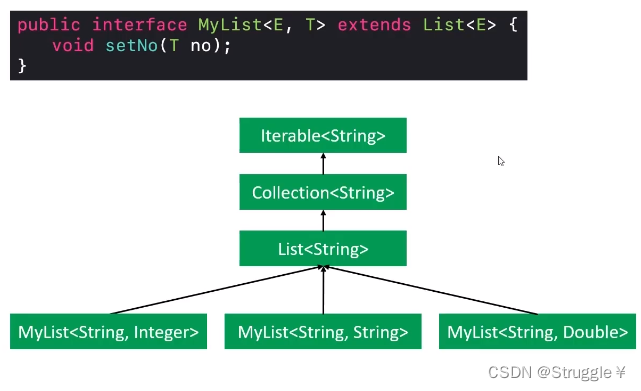
但是,下面的继承关系就不成立。嗯?怎么与我们理解的不太一样呢?我们之前的理解不是说,只要类是继承,不管泛型。显然我们理解错了。因此结论来了:泛型继承,也就是String继承Object每错,但是写在泛型里就不是继承了。泛型类别想要继承就必须:类首先继承,泛型还要相同。

下面的例子还能说明一个问题,类首先继承,泛型只需要第一个相同就行,也可以继承。
原始类型(Raw Type)
- 原始类型(Raw Type)。在使用泛型类的时候,没有传入具体的类型,就叫做原始类型。编译器会发出警告。原始类型跟传入一个Object在调用方法时一样,但是有本质区别。
Box就叫原始类型,Box<Integer>叫做非原始类型。

限制泛型的类型
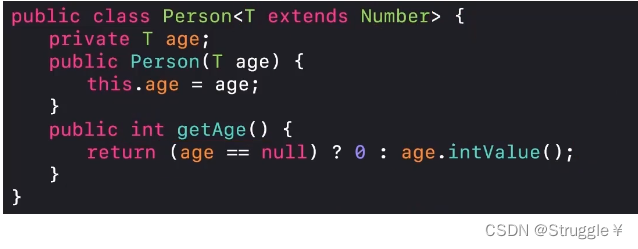
-
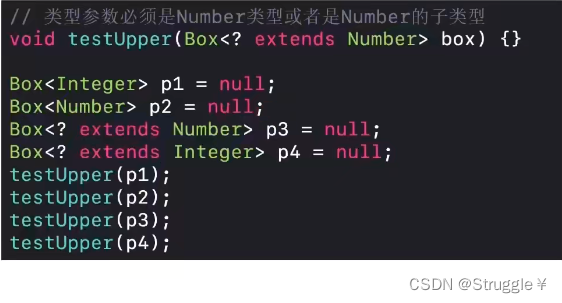
限制类型参数。可以在生成泛型类的时候,规定,泛型类型必须是继承某个类的。比如下面的例子,要求
T必须是继承自Number的。这种设置也合理啊,因为我这个泛型可能泛型的是年龄这种数字类型的,所以必须要求继承Number类型非常合理。
-
通配符。在泛型中,问号
?被称为通配符。下面的例子中,使用通配符可以将泛型类型设置的模糊一下,只要是继承Number的类型都行,更加的灵活。
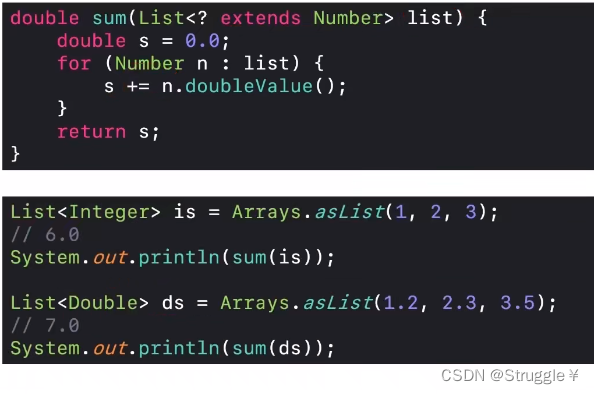
比如有这一个需求:求列表的和。我定义一个sum函数,参数传的就是列表,但是链表里边的内容是什么类型我先不定死,我要求只要是数字类型即可。我就可以使用通配符来要求泛型的类型只要是继承Number即可,也就是泛型类型只要是Number本身或者子类即可。
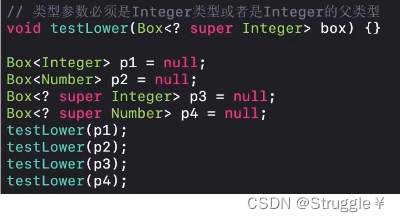
我们可以使用? extends设置泛型的上届(级别不超过后面的)。那我们也可以使用?super设置泛型的下届(级别不低于后面的)。比如下面的例子,要求泛型类型必须是Integer本身或者父类才行。
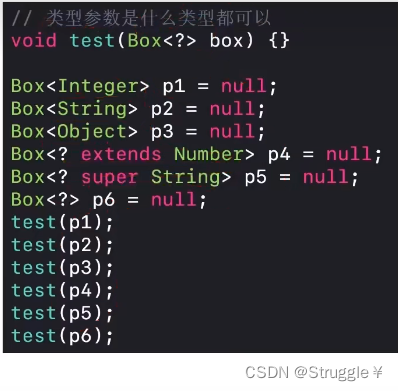
假如我想要无限制,也就是传什么类型都可以,那就只写一个问号即可。这才叫真正的通配符。
泛型的使用限制
- 基本类型不能作为类型参数,比如int,char不能做作为泛型的类型参数。其包装类是可以的。

- 不能使用类型参数实例化对象,如果想要实例化类型参数的对象,必须使用Class下的newInstance方法。
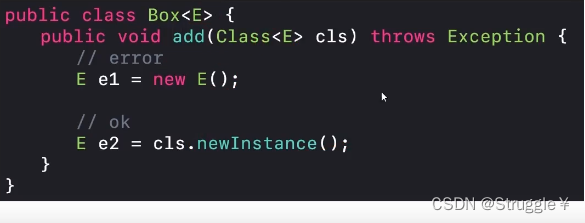
- 不能定义为类型参数的静态变量。因为静态变量只有一份内存,将来我创建不同的类型时,这个惊静态变量到底是啥类型的呢,这是会出错的。比如,Integer类型和String类型,请问将来这个value是啥类型,这不就乱套了吗。

- 相同类名,不同泛型参数不构成重载函数

- 自定义异常类的时候,不可以使用泛型。

Java中的函数式接口(重要)
函数式接口:有且仅有一个抽象方法的接口,java中的函数式编程体现就是Lambda表达式,所以函数式接口就是可以适用于Lambda使用的接口,只有确保接口有且仅有一个抽象方法,java中的Lambda才能顺利的进行推导
这里综述一下,函数式接口的作用:当A方法存在某个输入参数,这个输入参数我不想规规矩矩的传入某个变量,我想要在调用A方法的时候传入一个函数来丰富这个输入参数的形式,并且达到多种应用场景的灵活效果,这时候就用函数式接口。
Lambda表达式
Lambda的作用就是,简化函数式接口的代码书写。让我们看看lambda的一些用法:
下面是举一个例子:
//普通函数写法
int sum(int a,int b){
return a+b;
}
//Lambda表达式写法
(a,b) -> a+b
下面是更多的例子
// 1. 不需要参数,返回值为 2
() -> 2
// 2. 接收一个参数(数字类型),返回其2倍的值
x -> 2 * x
// 3. 接受2个参数(数字),并返回他们的和
(x, y) -> x + y
// 4. 接收2个int型整数,返回他们的乘积
(int x, int y) -> x * y//可以加类型
// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
(String s) -> System.out.print(s)
但我觉得,记住一个模板就行了,
//普通函数写法
返回值类型 函数名(参数列表){
//函数体
return 返回值;
}
//Lambda表达式写法
(参数列表) -> {函数体}
如果没有函数体,只有返回值,那就不用加大括号,直接写上返回值就行了(参数列表) -> 返回值
Supplier函数式接口
凡是函数式接口,官方都会在接口的上面加上@FunctionalInterface,可以看到函数式接口的特点:首先是个接口interface,其次只有一个抽象方法。
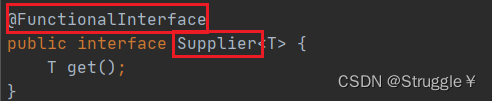
Supplier接口也被称为生产型接口,如果我们指定了接口的泛型是什么类型,那么接口中的get方法就会生产什么类型的数据供我们使用。接下来我们看看这个接口怎么使用:
假如,我们日常开发中有这么一个需求:别人传入两个字符串,我要返回第一个不为空的字符串。
public static void main(String[] args){
String str1 = "xhb";
String str2 = "zmm";
System.out.println(getFirstNotEmptyString(str1,str2));//xhb
}
static String getFirstNotEmptyString(String s1,String s2){
if(s1 != null && s1.length() != 0) return s1;
if(s2 != null && s2.length() != 0) return s2;
return null;
}
这么一看没啥毛病,可以实现我们想要的功能。但是日常开发过程中,这两个字符串很可能是通过某些复杂的方法最后得到的。也就是说,可能是这样的形式:第二个字符串是通过某些复杂的算法得到的,第一个字符串我们暂且不管,假设就是输入的。
public static void main(String[] args){
System.out.println(getFirstNotEmptyString("xhb",make2ndString()));//xhb
}
//第二个字符串是通过函数获得的
static String make2ndString(){
//一大堆复杂代码,很耗时的那种
System.out.println("make2ndString()");
return "zmm";
}
static String getFirstNotEmptyString(String s1,String s2){
if(s1 != null && s1.length() != 0) return s1;
if(s2 != null && s2.length() != 0) return s2;
return null;
}

我们仔细想想这个函数的功能:返回第一个不为空的字符串。假设第一个不为空,我们还有必要去获得第二个字符串了吗?上面的代码,判断完第一个字符串之后,还会调用第二个函数,这是没有必要的(因为我们已经明知第一个符合条件了,还回去调用第二个方法去构建字符串)。
所以,开发中,有一种方法可以解决这种可能不必要的耗时行为。也就是说,第一个判断完,第二个是什么已经不重要了。
我们在方法处,的第二个参数传入一个函数式接口的参数:Supplier<String> supplier。然后我们内部原本的s2字符串,也就是第二个字符串,我是通过函数式接口的get方法返回值得到。
static String getFirstNotEmptyString(String s1,Supplier<String> supplier){
if(s1 != null && s1.length() != 0) return s1;
String s2 = supplier.get();
if(s2 != null && s2.length() != 0) return s2;
return null;
}
怎么通过get方法,获得我原本需要输入的字符串“zmm”呢?
只需要我们调用getFirstNotEmptyString方法时,实现第二个函数式接口的get方法。(我们知道,只要new一个接口,就会自动实现接口下的方法)
public static void main(String[] args){
System.out.println(getFirstNotEmptyString("xhb", new Supplier<String>() {
@Override
public String get() {
return make2ndString();
}
}));//xhb
}
//第二个字符串是通过函数获得的
static String make2ndString(){
//一大堆复杂代码,很耗时的那种
System.out.println("make2ndString()");
return "zmm";
}
可以看到,get方法返回的是,make2ndString(),也就是我们前面获取第二个字符串的那个方法。
也就是说,下面函数最终会获得第二个字符串的数据,也就是“zmm”,然后这个字符串“zmm”会在getFirstNotEmptyString内部通过supplier.get()获得。这就是该函数时接口的传递逻辑。
new Supplier<String>() {
@Override
public String get() {
return make2ndString();
}
}
这样做的效果是:当我需要s2字符串,才会去调用get方法,才会调用make2ndString()方法把“zmm”构建出来。
整个代码如下图所示:
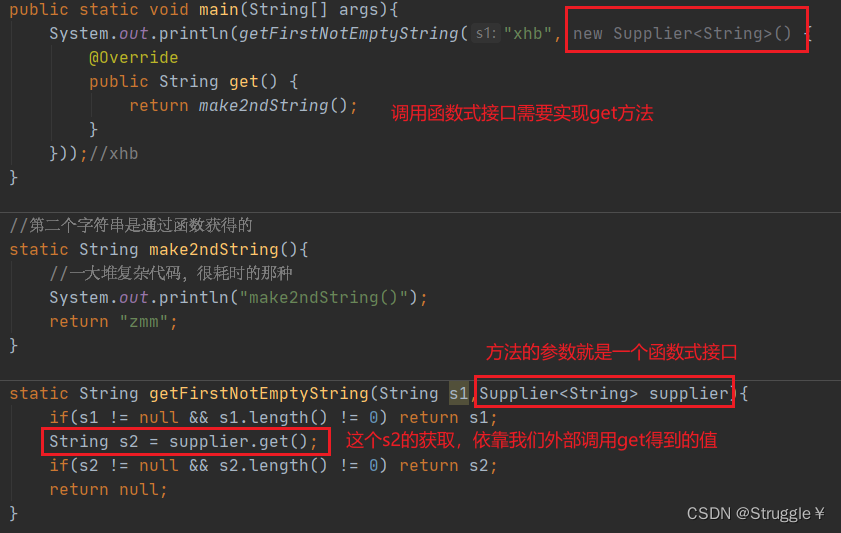
很明显,如果s1不为空,那就直接返回s1了,就不会走到下面调用get方法的那一行。不调用get方法,自然也不会调用make2ndString()方法,就实现了我们的目的。
因为调用方法时,会一次性的把形参全部读进来。这里函数式接口读入的也只不过是supplier这一个变量而已,发生的只不过是这样一个过程Supplier<String> supplier = new Supplier<String>(),也就是创建了个supplier对象而已。只有s1为空,才会出现supplier调用get方法进而调用make2ndString()方法的耗时过程。
再回顾之前的,如下所示,如果没有函数式接口,一次性把形参读进来,读到s2的时候,就会出现这样一个过程String s2 = make2ndString(),就会不由自主的调用make2ndString()方法。
public static void main(String[] args){
System.out.println(getFirstNotEmptyString("xhb",make2ndString()));//xhb
}
//第二个字符串是通过函数获得的
static String make2ndString(){
//一大堆复杂代码,很耗时的那种
System.out.println("make2ndString()");
return "zmm";
}
static String getFirstNotEmptyString(String s1,String s2){
if(s1 != null && s1.length() != 0) return s1;
if(s2 != null && s2.length() != 0) return s2;
return null;
}
所以,该函数式接口做到的了,用到我的时候,才调用我的目的。
既然是函数式接口,我们用lambda简化书写:
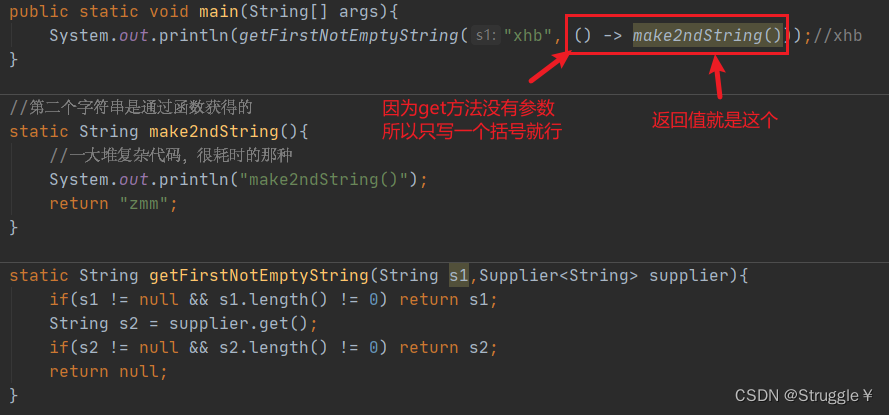
来来来,我们来看看函数接口有啥不同。如果我们使用其它方法,能不能实现我们的目的呢?
我声明一个类,里面就有一儿get方法,返回的就是make2ndString()方法。
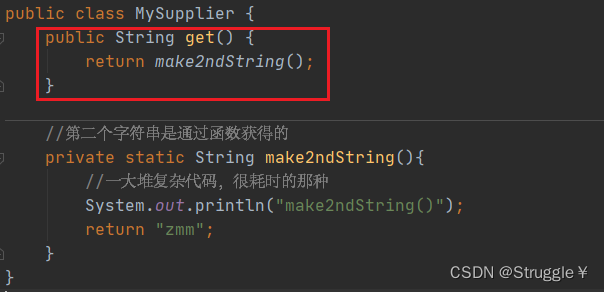
我在定义getFirstNotEmptyString(String s1, MySupplier supplier)方法时,第二个参数是一个对象,就是我刚才定义类的对象。然后我在调用getFirstNotEmptyString方法的时候,就new一个对象即可。也可以实现和函数式接口相同的目的。
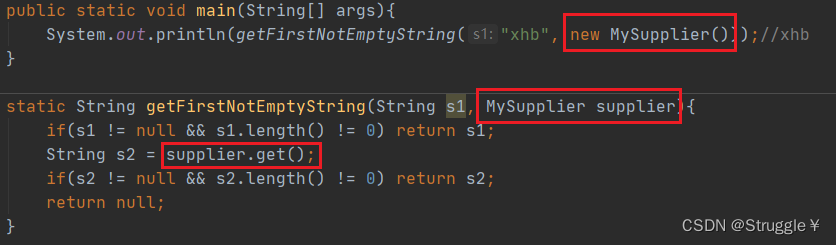
这么一看,我设计一个类啥的,也可以是做到跟函数式接口相同的目的。
那么,我们为什么要用函数式接口呢?
答案是:简化代码书写,以更少的更清晰的成本完成灵活的需求。因为函数式接口(本质是接口类里的函数),我们可以在调用处重载get方法(至于怎么重载,根据需求可以在调用时决定,非常的灵活),如果是普通类的话,就必须写死在类的成员里。
Consumer函数式接口
该接口也被称为消费型接口。下图中可以看到该接口的内部实现。包含一个accept方法,和一个默认方法。
哎?不是说函数式接口只包含一个抽象方法吗?这里怎么两个方法呢?
默认方法不算抽象方法,是为了在外部调用时赋予更多的接口本身的特性而设计的。比如这个andThen函数,允许两个Consumer对象接连着调用accept方法。
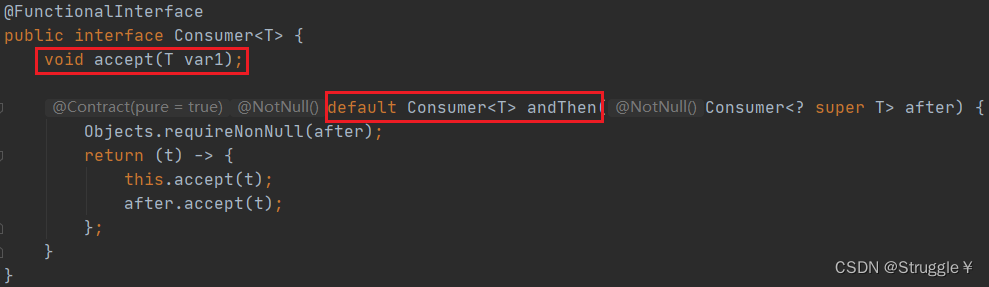
Supplier接口是有一个get方法,会返回一个值。而Consumer是accept方法,会吞掉一个值。下面,我们根据一个实际场景,看看Consumer函数式接口如何使用。
需求:遍历数组每一个元素,拿到每一个元素时,我对这个元素做一些我想做的事。
比如,我想要拿到原数组里的数据,直接打印、加上100再打印,判断奇数偶数之类的,一系列自定义操作。那我不能每次想做一个自定义操作,就写一个for循环啥的吧!
int[] nums = {11,22,33};
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]);
}
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i] + 100);
}
for (int i = 0; i < nums.length; i++) {
if(nums[i] % 2 ==0){
System.out.println("偶数");
}else {
System.out.println("奇数");
}
}
因此,我们的想法是把遍历数组这个事,封装成一个函数。并使用Consumer函数式接口作为forEach的参数。
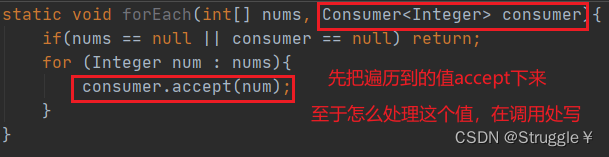
我们还可以将方法泛型,这样forEach就可以遍历存储着各种类型数据的数组了。
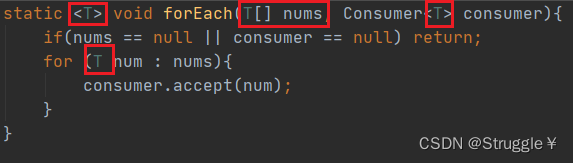
这样,我们在调用forEach函数时,就可以现场规定如何处理遍历到的数据。只需要重写accept方法即可。
Integer[] nums = {11,22,33};
forEach(nums, new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
});
forEach(nums, new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer + 100);
}
});
forEach(nums, new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
if(integer % 2 ==0){
System.out.println("偶数");
}else {
System.out.println("奇数");
}
}
});
既然有了lambda表达式,还可以把函数式接口继续简化。
Integer[] nums = {11,22,33};
forEach(nums, (integer) -> System.out.println(integer));
forEach(nums, (integer) -> System.out.println(integer+100));
forEach(nums, (integer) -> {
if(integer % 2 ==0){
System.out.println("偶数");
}else {
System.out.println("奇数");
}
});
经过Supplier和Consumer这两个函数式接口的练习,你是不是已经非常的清楚函数接口是怎么互相调用彼此的了吗?
明确一个点:一定是先执行到函数调用,再去执行调用的函数函数体。
就比如forEach函数,我们在外部调用forEach函数,会执行forEach的函数体,执行函数体的过程中,会调用到函数式接口的函数accept,紧接着就要去执行accpet的函数体。然后再继续执行forEach接下来的语句。
说人话:函数式接口的作用就是,forEach这种方法中途要干点事(可以是通过外面获取值,也可以是对内部的值按照外面的处理逻辑进行处理),需要函数式接口的协助。
还记不记得Consumer接口里还有一个默认的andThen方法,怎么用的呢?可以在forEach参数处,定义两个函数式接口,然后andThen,两次调用accept方法。也就是说consumer1和consumer2都会拿到num干事情。

我在调用的时候,就需要实现两个函数接口:
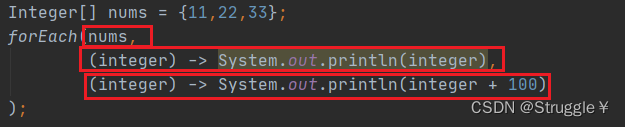
也就是,分别拿到num进行操作。

Predicate函数式接口
这个函数式接口的返回值是Boolean类型,猜也可以猜到,通常用来筛选某个变量的。
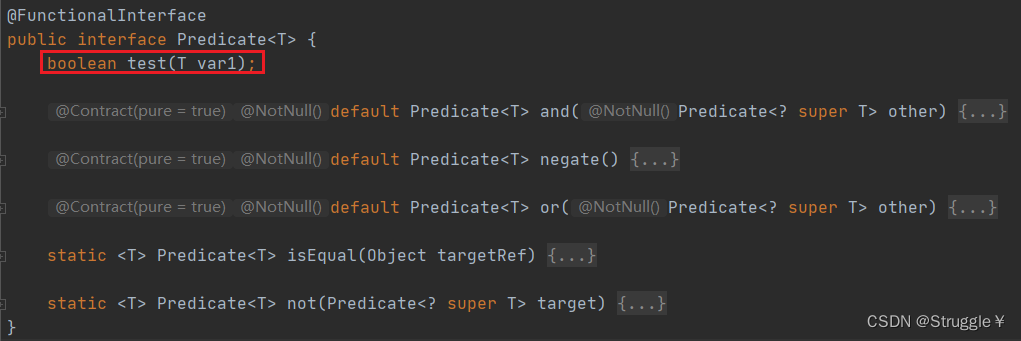
现在有这样一个需求:拼接数组中的元素,只不过我有要求,我可能只拼接奇数,或者拼接偶数。
大概的思路就是:先遍历数组,然后对每个元素进行判断,是不是奇数或者是不是偶数,如果是,我就拼接,如果不是我就不拼接。
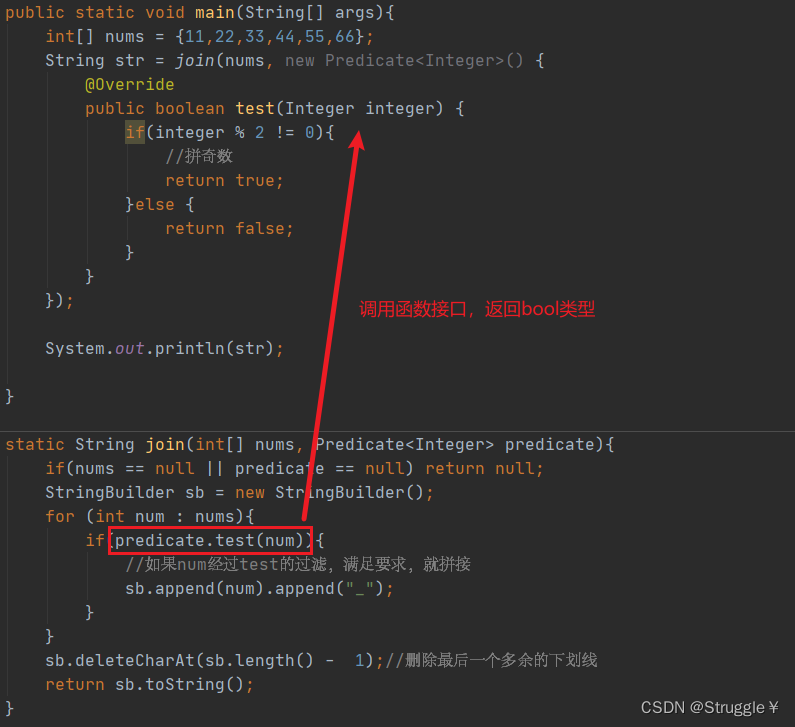
可以看到,我们把奇数都拼起来了。

所以,Predicate接口函数的用途通常用来过滤,筛选我们想要的数据。
假如,我想要更改需求,我想要拼接偶数,我只需要在调用处轻轻一改即可。
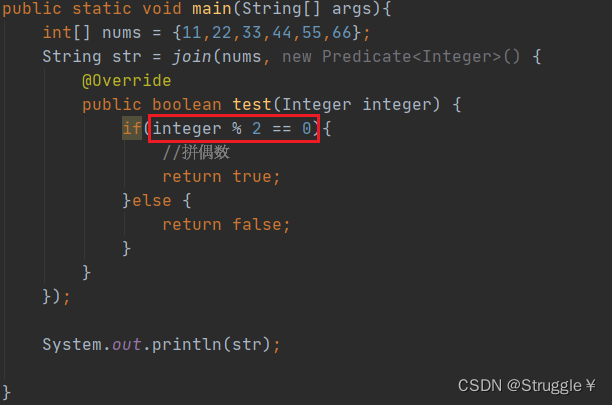

Function函数式接口
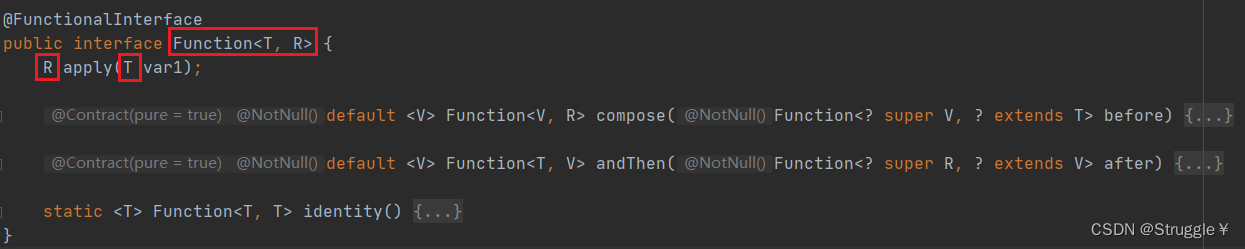
我们在前面学习的Supplier函数式接口是返回值可以是泛型,Consumer函数式接口是接受的数据类型可以是泛型。这一节学习的Function函数式接口时,返回值和输入参数都可以泛型。
该函数式接口通常用来转换数据,比如输入的是String类型,我转为Integer类型这种
这样的话,可操作性,灵活性,以及适用的场景就更多了。
比如,我将R泛型为Boolean,就可以取代Predicate函数式接口。
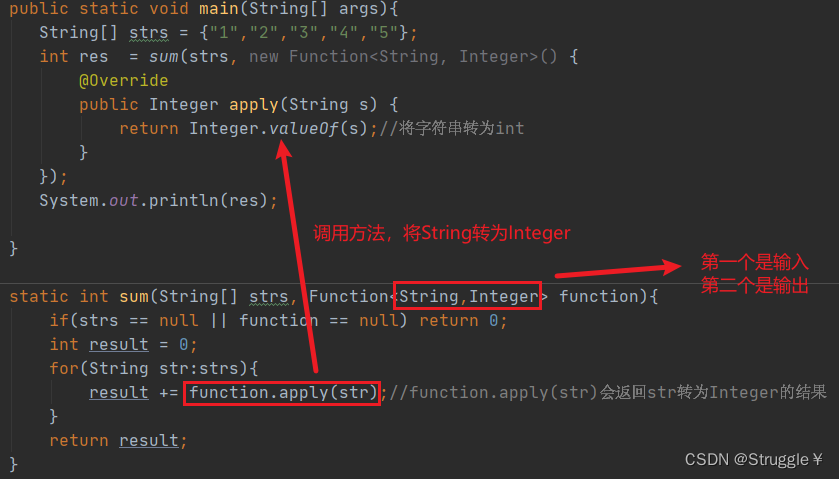
来,下面我们来举一个例子,感受一下Function是如何完成转换数据类型的需求的。需求是这样的:把一个String字符数组里的字符转为Interger,并相加。
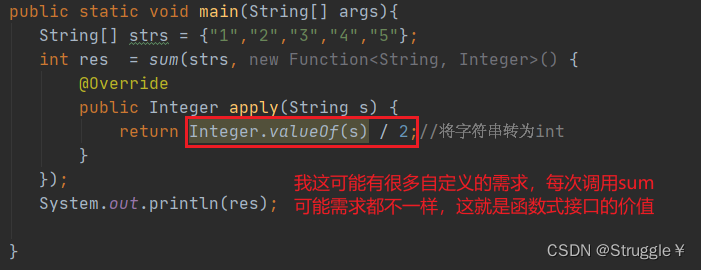
或者,我还可以灵活地处理我拿到的数据,比如每个数字除以2再相加。
当然,我们还是换成lambda表达式:
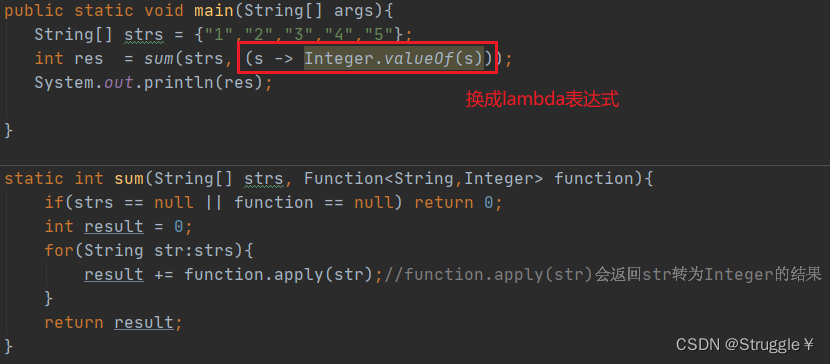
Java中的集合(Collections)
此集合非set,而是字面意思,集合。java.util包中有一个集合框架(Collections Framework),提供了一大堆常用的数据结构。包括:ArrayList、LinkedList、Queue、Stack、HashSet、HashMap等。
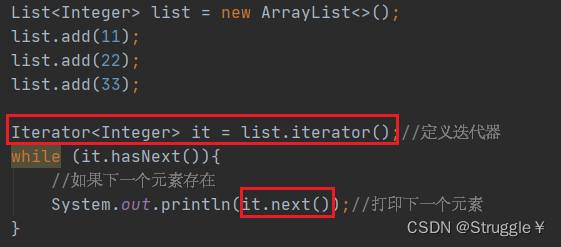
因为ArrayList、LinkedList、Queue、Stack我们在数据结构与算法的课中学过,因此这里不过多介绍。提一嘴,Java中的迭代器怎么写:使用的是Iterator<Integer> it = list.iterator()这种定义方式,跟C++是类似的

只学习HashSet、HashMap。
看了看,没啥学的,知道有这些东西就行。
Java中的并发编程-多线程(究极重要)
进程的概念
学习线程之前,我们需要了解一下什么是进程?
什么是进程呢?进程就是在操作系统中的一个应用程序。比如,同时打开QQ和微信,操作系统会分别启动两个进程:

每个进程都是独立的,每个进程均运行在其专用且受保护的内存空间内。
线程的概念
什么是线程呢?
一个进程想要执行任务,必须得有线程(每一个进程至少要有一个线程),一个进程的所有任务都在线程中执行。
比如,使用酷狗播放音乐,使用迅雷下载文件,都需要在线程中执行。

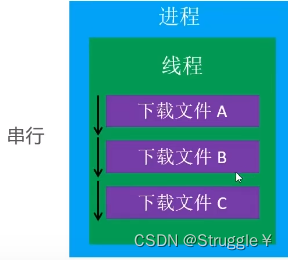
一个线程中任务的执行时串行的。如果要在单独的一个线程中执行多个任务,那么只能一个一个地按顺序执行这些任务。即,在同一时间内,一个线程只能执行一个任务。
比如在一个线程中下载3个文件,有一种串行的感觉(先执行A,在执行BC,多个任务不可以在一个线程中同时执行)
多线程基本概念
什么是多线程?
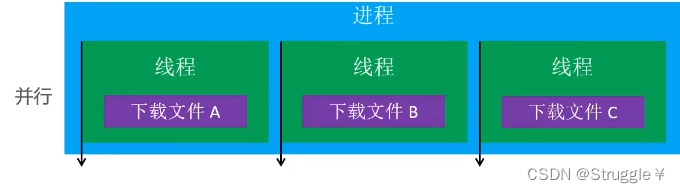
一个进程中可以开启多个线程,所有的线程可以并行(同时)执行不同的任务。
如果把进程比喻成:车间,那么多线程就类似于:车间的多个工人。
多线程技术可以提高程序的执行效率。
比如,同时开启3个线程分别下载3个文件(分别是A,B,C),如下图所示:
那,多线程的原理是什么呢?怎么办到平行执行三个不同的线程的呢?
这里我们要明白一个事:同一时间,CPU的一个核心只能处理一个线程(多核处理器先不说,咱就说单核的时候)。
嗯?那单核的CPU如何做到多线程的呢?
答案:多线程并发执行,其实是CPU的一个核心快速地在多个线程之间调度(切换) 如下图所示,
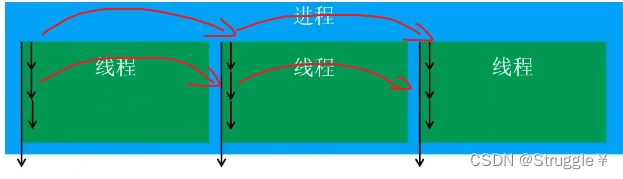
如果CPU调度线程的速度足够快,就造成了多线程并发执行的假象!!!
切记,上述说的是CPU一个核心干的事,如果是多核CPU,才真正地实现了多个线程同时执行。
思考:如果线程非常非常多,会发生什么事情呢?
CPU会在N个线程之间调度,消耗了大量的CPU资源,CPU会累死的。也会造成每条线程被调度执行的频次降低(也就是说,线程的执行效率很低)
来,我们总结一下多线程的优缺点:
- 优点:能适当提高程序的执行效率;能适当提高资源利用率
- 缺点:开启线程需要占用一定的内存空间,如果开启的线程越多,内存空间消耗的就越多,会降低程序的性能;程序设计也会更加复杂,比如线程之间的通信问题,多线程的数据共享问题。
多线程编程实现
每一个Java程序启动后,会默认开启一个线程,称为主线程(也就是main方法所在的线程)
与此同时,每一个线程其实都是一个对象,是一个java.lang.Thread对象,可以通过Thread.currentThread()方法获得,这个Thread.currentThread()方法会说明当前线程是哪个线程。

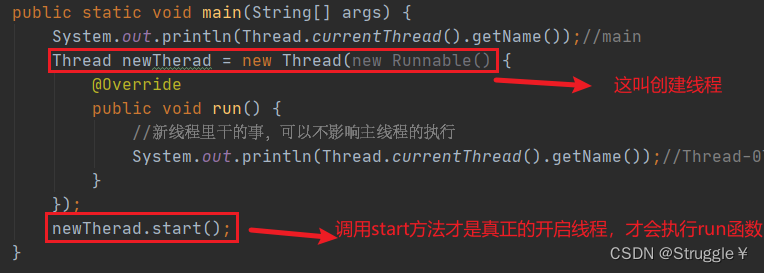
开启新线程的第一种方法
- 需要new一个Thread对象,然后重新Runnable的run函数在里面实现子线程的事情
- new一个线程对象顶多叫做创建一个子线程,调用start才叫开启线程。
- 调用getName还会打印当前线程的名字(可以看到主线程的名字叫main,我创建的子线程的名字叫做Thread-0)
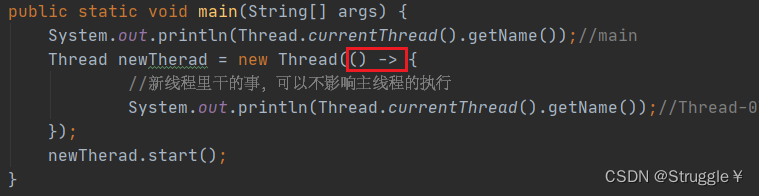
既然是函数式接口,可以用lambda表达式优化一下。当然,不优化也没任何问题。
开启新线程的第二种方法
这种方法,也是我们日常开发过程中经常使用的方法。即,自定义线程类,继承Thread,然后重写run方法。(跟QT的多线程简直一模一样)
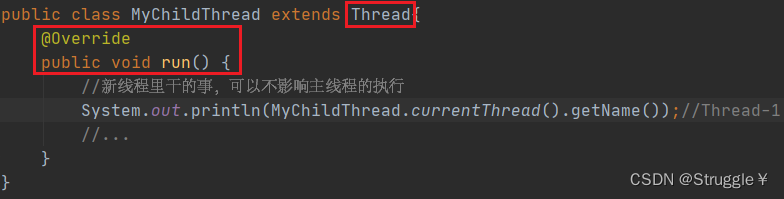
然后,在main函数中,就可以开启这个线程。可以看到,打印该线程的名字是Thread-1,又是另一个线程。
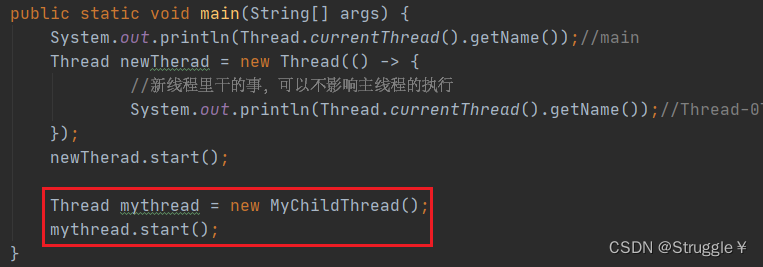
这里额外补充一个可能出错的地方:反正调用start都是执行run函数,那我直接调用run函数不就得了。
如果直接调用run函数,那么run函数就是在主线程执行的,而不是在子线程执行。因为start内部不仅仅是只调用了run函数,还做了一些开辟子线程的事。
多线程的内存布局
还记得,第一章讲的Java中的内存布局吗?下面我把图片截了过来:

可以看到,JVM在执行一个java程序的时候,会将内存区域分为五部分,都是为当前这个java程序服务的。那么在多线程编程中,每一个线程的内存布局是什么样的呢?都有哪些内存区域为当前这一个线程服务呢?
- PC寄存器:每一个线程都有自己独立的PC寄存器。
为什么呢?因为不同的线程指向指令的速度不同,如果共用一个PC寄存器,那指令地址的存储与读取就乱套了。
- Java虚拟机栈:每一个线程也都有自己独立的JAM栈。
为什么呢?因为我们知道栈空间用来为函数的调用开辟存储空间,函数调用完也会释放掉这块区域。因为,不同的线程开辟回收一些函数的时机一定是不同的。如果不同的线程共用一个栈空间,那么出栈和入栈就会乱套。比如,线程1想要出栈一个函数,但此时栈顶是线程2的一个函数,怎么办?难道要把线程2的出掉?所以说,每一个线程都必须要有自己独立的JVM栈空间。
- 堆:多个线程可以共享
这个也比较好理解,因为申请堆空间是随机的分配内存,所以多个线程可以共用一个。
- 方法区:多个线程也是可以共享的
这个也比较好理解,因为方法区就是存放一些函数代码的,没必要划分。
- 本地方法栈:每一个线程都有自己的本地方法栈。
为什么呢?因为本地方法栈跟普通的栈性质是一样的,只不过调用的函数不同而已。本地方法栈是用来调用本地的函数,那么每个线程都可能会调用用于本线程的函数,因此必须独立。
线程的不同状态
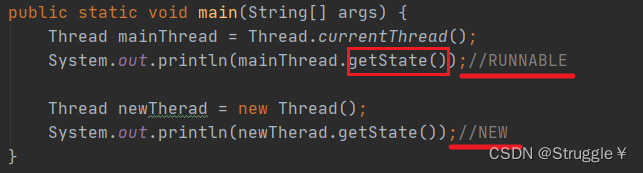
可以通过Thread.getState()来获取当前线程的状态。比如,我看看当前主线程的状态是RUNNABLE,也就是正在运行。
看看新建的一个子线程的状态是,NEW,也就是新建的,还没运行。
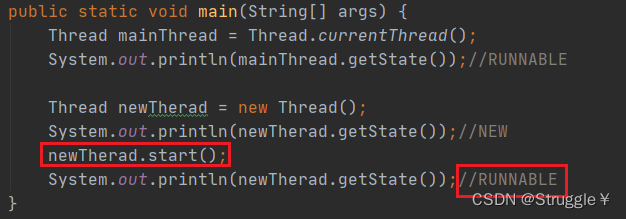
当我把线程开启,运行状态就变成了RUNNABLE。
线程的状态可不止这两种,我们看看都有哪些:
-
NEW(新建):线程尚未启动
-
RUNNABLE(可运行状态):也就是说当前线程正在JVM中运行,或者说等待CPU的调度(但本质也是在运行,只不过这几毫秒可能没在运行而已)
-
BLOCKED(阻塞状态):意味着当前线程正在等待监视器锁(也叫内部锁),也就说这个线程正在等着某个线程执行完某个函数,这个线程才能去指向该函数。必须等待上一个线程释放掉该函数的内部锁,这个线程才能拿到这个内部锁,执行该函数。
-
WAITING(等待状态):等待另一个线程,这个跟阻塞状态可不一样。阻塞状态是消耗CPU时间片的,等待状态不消耗CPU时间片。
-
TIMED_WAITING(定时等待状态):当前线程有时间的等待一些事,比如调用sleep睡眠函数这种。
-
TERMINATED(终止状态):线程已经执行完毕,就是这个状态。
这几个状态的切换可以总结为下面的图:
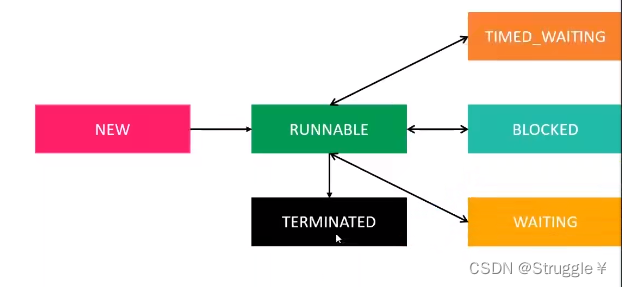
其中双向箭头表示可以随时互相切换,意味着运行着的线程可以随时处于等待状态,处于等待状态的线程可以随时变成运行时刻。总之,一但线程由RUNNABLE变成TIMED_WAITING、BLOCKED、WAITING中的任意一个,线程都是处于等待状态,也就是啥也不干,等待。
下面我们介绍一些改变线程状态的方法:
- sleep函数:可以通过
Thread.sleep方法暂停当前线程继续向下执行,进入WAITING状态
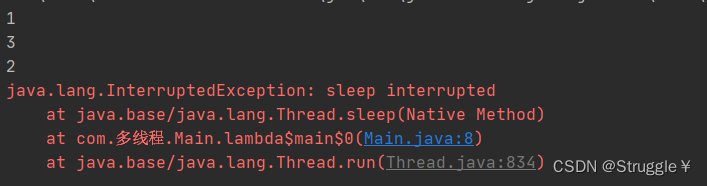
我新建一个子线程,在子线程里调用sleep方法,可以看到这是一个检查型异常,必须处理
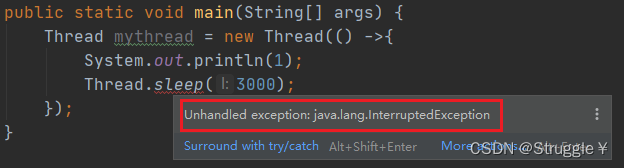
这个异常的意思是,如果当前线程在sleep的过程中,被打断了,就抛出异常。也就意味着,线程调用sleep的时候不可以被打断。我用try-catch处理一下,就可以了。
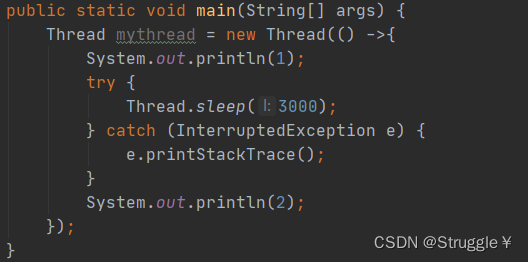
下面的程序打印的结果是:1,3,2。也在意料之中,因为子线程睡的3秒钟,主线程也会执行,两者不耽误,只不过主线程睡1秒,因此一定会先打印3,再打印2。
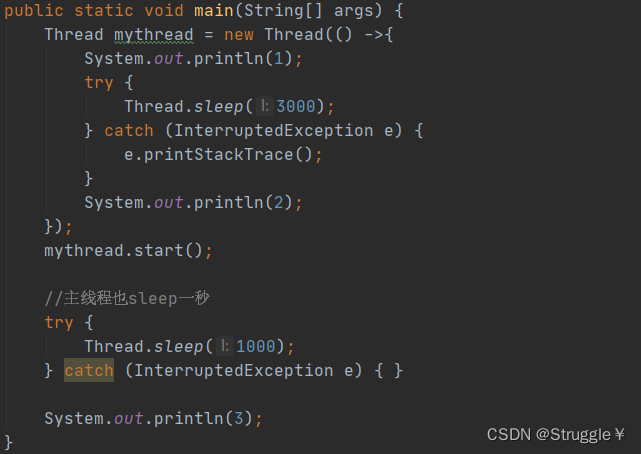
这时候,我们中断子线程,看看是不是抛出异常:
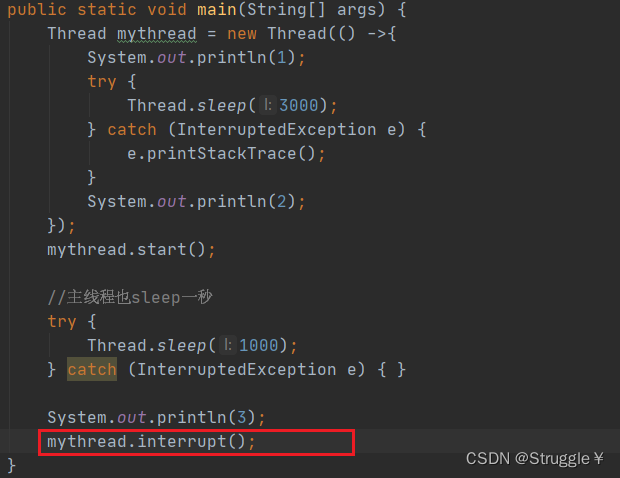
可以看到,会抛出异常。这就是sleep的特性,不允许被吵醒。由于我们是处理过这个跟异常的,因此代码会继续执行,2也就会被打印出来。
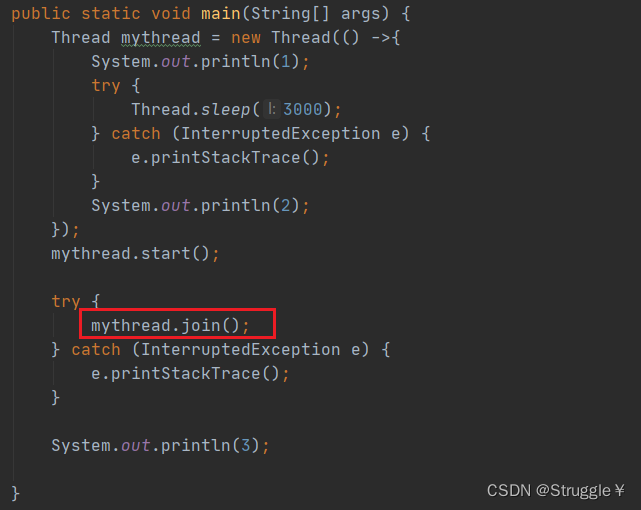
- join方法:在线程
A中调用B.join()方法,就会发生这么一件事:等A线程执行完毕,B线程在继续执行接下来的代码。可以传参指定最长等待时间。
原本的是打印1,3,2。但是,我在主线程里调用子线程mythread的join方法,就会暂停当前主线程的执行,先把子线程执行完毕之后,在接下来执行主线程。
所以,就会出现打印1、2、3的情况。

当我,在join中传入参数时,表明最长等待时间:
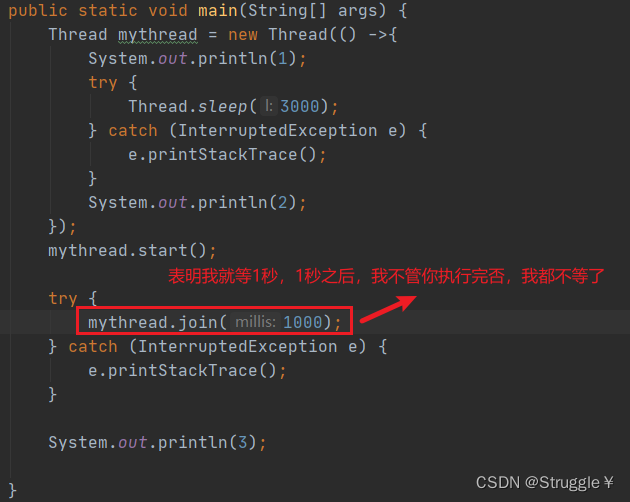
可以看出,还是按照1、3、2的顺序打印。因为主线程就等了子线程1秒,而子线程要睡3秒,所以还是先打印3后打印2。

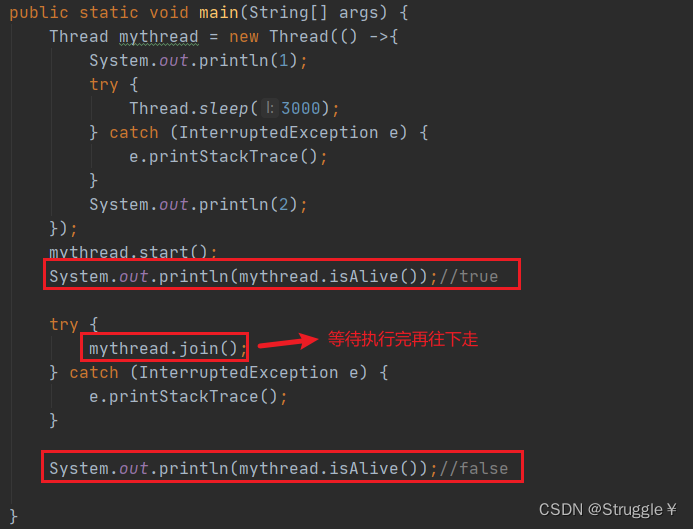
- isAlive方法,查看线程是否还活着
线程安全问题(比较重要)
多个线程可能会共享(访问)同一资源。比如访问同一个对象、同一个变量、同一个文件。
当多个线程访问同一块资源时,很容易引发数据错乱和数据安全的问题,这个问题称为线程安全问题。
什么情况下,才会出现线程安全问题呢?满足两个条件:
- 多个线程共享同一个资源
- 且至少有一个线程正在进行写的操作(也就是正在改变这一数据)
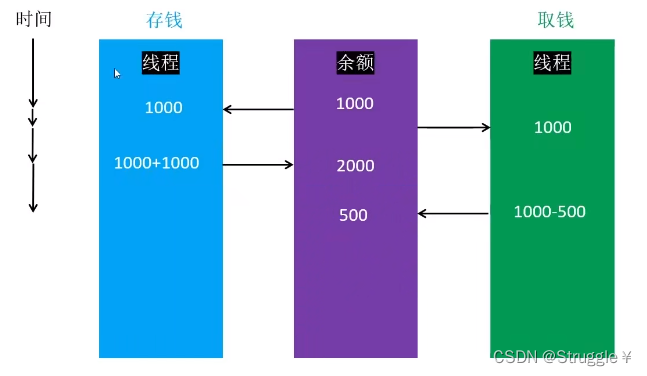
一个经典的线程安全问题:存钱取钱问题。两个线程同时访问余额,都会对余额这一内存进行写的操作。看可以发现,如果存钱和取钱的时间性刚好碰在一起,就会发生数据错乱。(在取钱的过程中,突然存钱,但是取钱的线程接收到的余额是1000,因此取500之后就会返回1000-500余额内存,这就会导致丢钱了)
还有一个经典的线程安全问题:景区买票问题。两个线程同时开卖,就可以导致明明卖了两张,最后票数余额只减了一张。
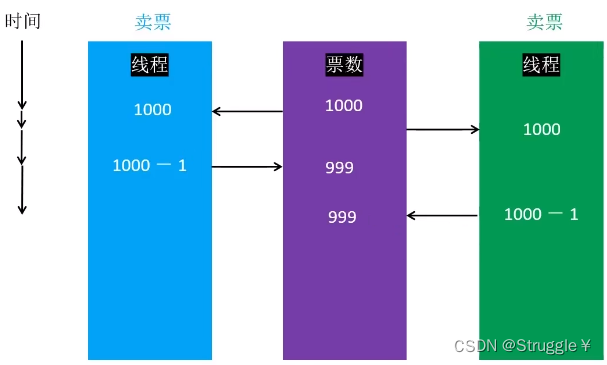
下面,我们以买票问题为例,解决一下线程安全问题。
首先我创建了一个车站类,继承Thread,然后重写run函数。run函数里不断地调用saleTicket买票,直到票数为0。
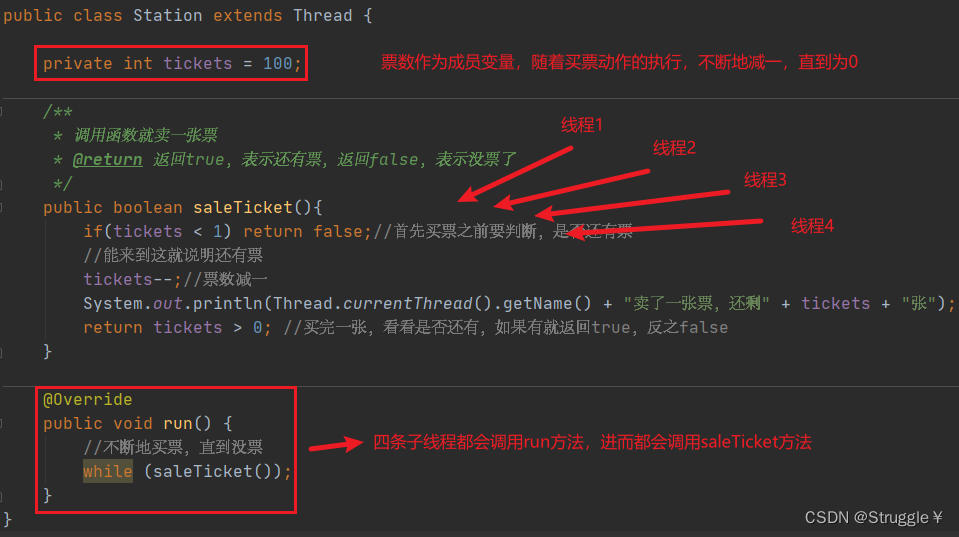
我在main函数处新建了四条线程,四条不同的station线程。分别去卖票
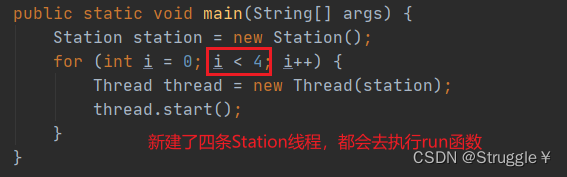
也就是说,到时候,四条线程都会执行run函数,都会调用saleTicket函数,去让票数tickets减一。
打印结果可知,发生了线程安全问题。因为四条线程同时访问一个数据tickets,就会造成票数的错乱。
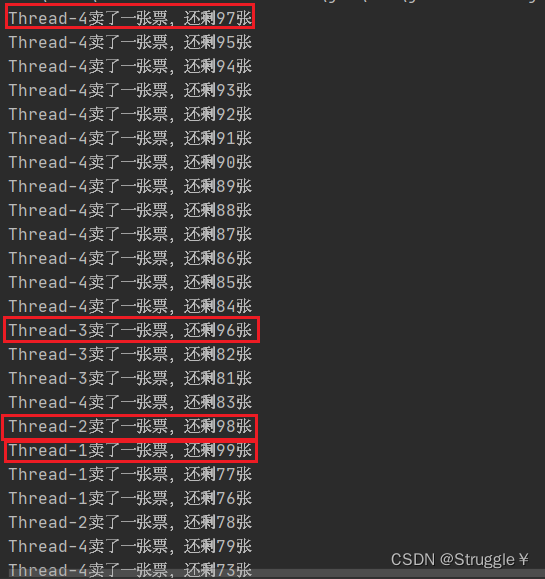
如何解决线程安全问题!等同于如何解决这样一件事:四条线程不可以同时访问一个数据,必须有先有后。
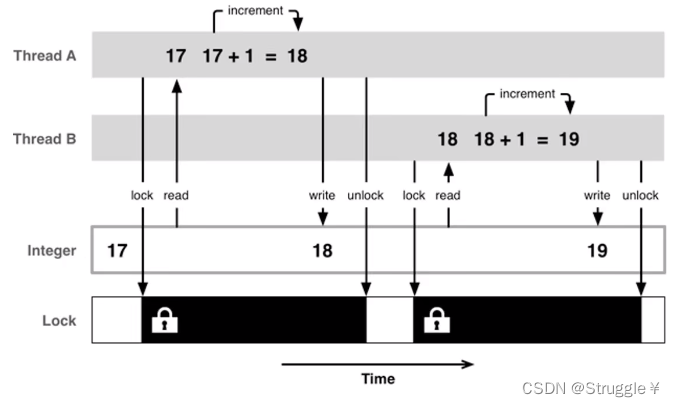
解决方案就是:加锁与解锁!下图可以解释什么是加锁,什么是解锁。
有一个整数Integer=17,线程A和B都想访问它并且把这个数+1。即便都想访问,在某一时刻一定会有一个先访问到这个17。假设是A先访问到了17,一旦访问到了,立马加锁lock,然后改17变为18,然后把18写回去,一套操作完事之后,解锁unlock。此时Integer就变成了18,紧接着B线程访问到这个数就是18,B也按照A的操作加锁、解锁。然后继续下一个线程访问。
这一套操作下来,可以保证当有多个线程同时访问某个数据的时候,这个数据不会错乱。举一个不恰当的例子(四个人上卫生间,一定是一个人先上,然后锁门,完事之后再开门,下一个人才能进来…)
那Java中代码怎么实现加锁和解锁这个事呢?
线程同步解决线程安全问题
刚才上面说的加锁解锁技术,官方说法叫做:线程同步技术。
线程同步在Java中有两种解决方法:
- 同步语句(Synchronize Statement)
- 同步方法(Synchronize Method)
看看这两种方法怎么回事,第一种 同步语句(Synchronize Statement):
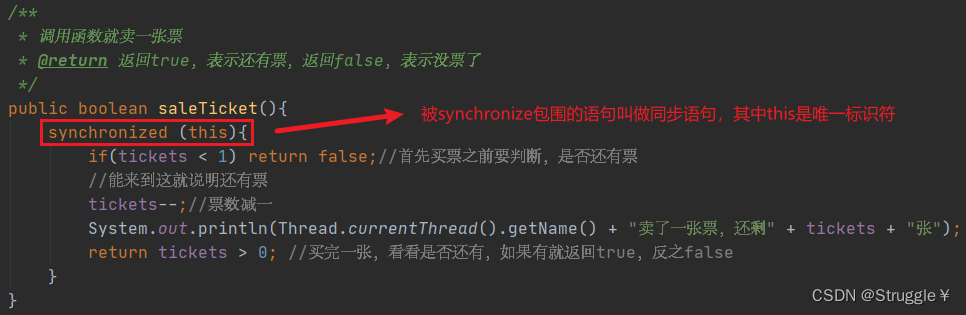
把可能被好几个线程同时访问的语句放在同步语句之下,结果就对了。可以看到,从99张一直变成0张。
同步语句的原理:synchronized (this)是怎么回事呢?
我们首先要知道,这个参数其实是一个对象类型的都可以也就是synchronized (Object obj)。
了解一个前提:Java中的每一个对象,任何一个对象都有一个与它相关的内部锁(监视器锁)。
重点来了:第一个执行到同步语句的线程,可以率先获得obj的内部锁,在执行完同步语句中的代码后释放其锁。
一旦第一条线程拥有了obj的内部锁,其他线程就无法获得内部锁,也就无法执行同步语句中的代码,这是其他线程就等着处于阻塞状态BLOCKED,等第一个线程把内部锁释放掉,然后随机选择一位幸运线程再次持有该对象的内部锁。
OK,了解完了synchronized (Object obj)的原理,我们来剖析一下为什么synchronized (this)可以实现同步语句
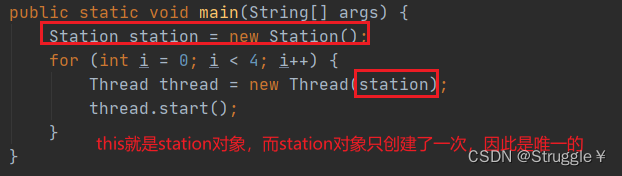
也就是说,第一条线程执行到synchronized (this)会获得station对象的内部锁。第二条线程执行到这的时候,一看this,也就是station对象的内部锁已经被第一条线程获得了,所以只能干等。
假如,我把程序写成这样:就会失去同步语句的意义。

相反,我只要写一个固定的对象,都可以实现:
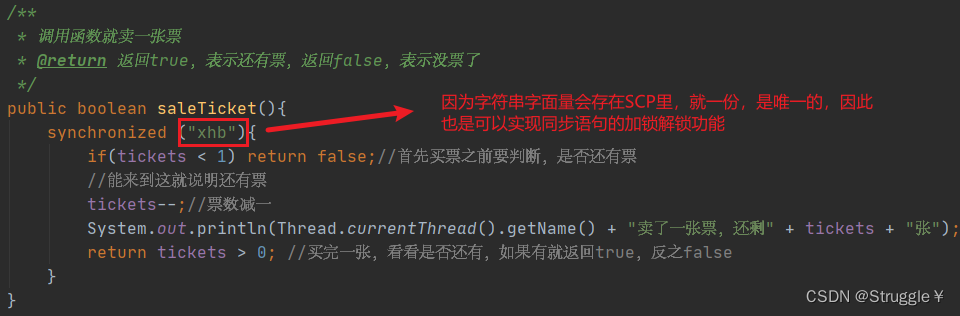
现在我们再来看看,同步方法(Synchronize Method)是怎么回事?
同步语句,是在函数内部包围住部分语句
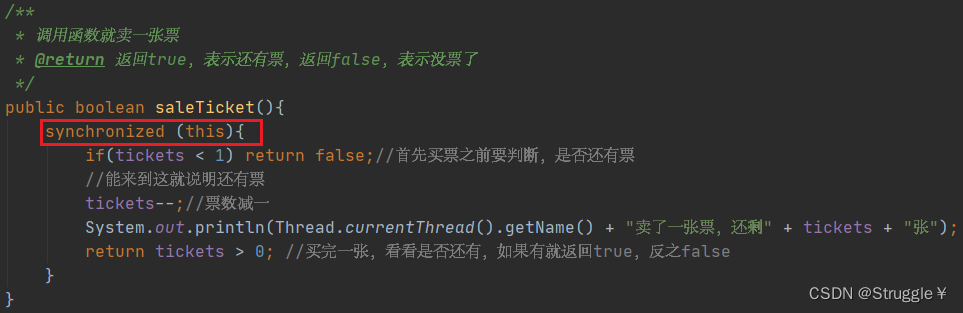
同步方法则是,直接在函数的声明处,加上Synchronize 关键字,让这个函数变成同步方法:
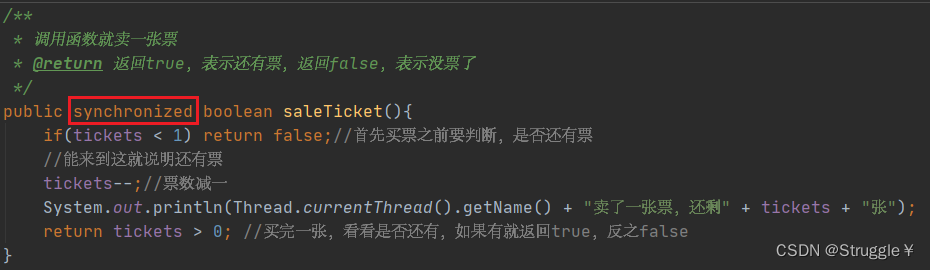
方法分为实例方法、构造方法,静态方法。Synchronize 不可以修饰构造方法,知道就行。
同步方法的本质是什么呢?
- 对于实例方法来说,同步方法本质就是在实例方法内部放一个同步语句
synchronized (this),只不过这个同步语句,必须把所有的函数体包围住 - 对于静态方法来说,同步方法的本质,就是在静态方法内部放一个同步语句
synchronized (类对象),因为静static方法没有this的概念,不可以被对象调用,但是可以被类直接调用。
同步语句比同步方法更灵活一些,因为同步语句可以精准的控制需要加锁的代码范围。
使用了线程同步技术后,可以解决线程安全问题,但却降低了程序的执行效率。所以,在真正有必要的时候,才是用线程同步技术,而不是用了多线程就要使用线程同步技术。
死锁(Deadlock)
什么叫死锁?
指的是,两个或多个线程永远阻塞,相互等待。
这种情况发生在,A线程执行的图中需要获得B线程已经得到的内部锁,同时B线程执行的过程中需要获得A线程已经得到的内部锁,这样的话,AB两个线程都不会结束,也就都不会释放掉本身已经获得的内部锁,彼此就会陷入死锁状态。
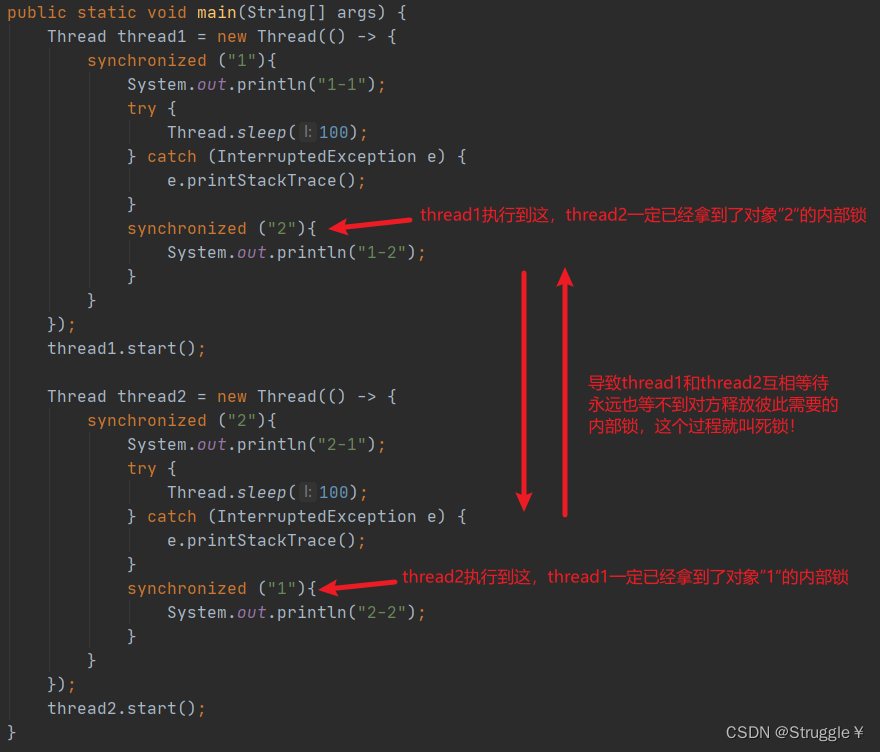
线程间的通信(很重要)
一定有这样一个应用场景:线程B执行的过程中需要从线程A中获取一些数据,反之亦然。这就叫线程间的通信。
经典的线程间通信的例子,就是生产者-消费者模型。生产者生产出一些食物,然后告诉消费者食物生产好了,消费者这时候就会从生产者那里获取食物。
Java中可以使用Object.wait、Object.notify、Object.notifyAll方法实现线程之间的通信。
首先,无论是生产者还是消费者都是两个线程,这里可以直接实现Runnable作为一个线程类(跟extend Thread效果一样)
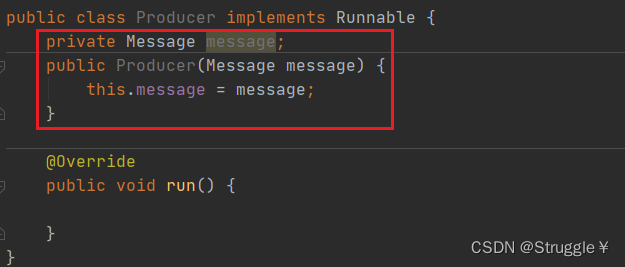
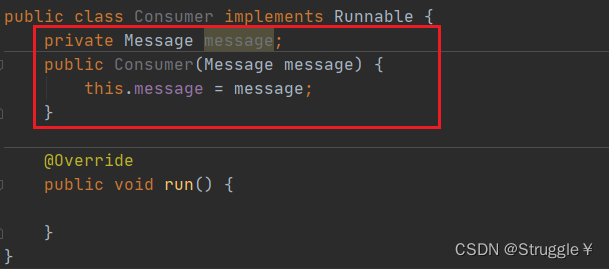
然后,我为了规范一些,定义了一个消息类,表明将来生产者和消费者之间的线程间通信,传递的消息。
然后,我会在生产者和消费者类中,定义这个消息。因为,无论是发消息还是接收消息,都要有消息这个属性。
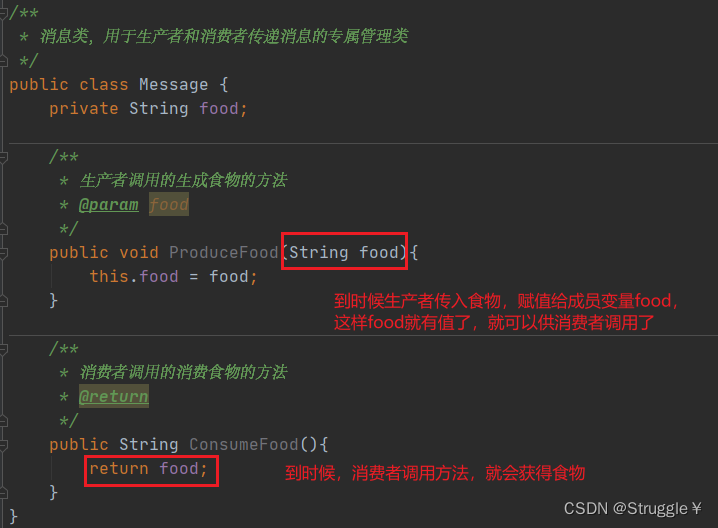
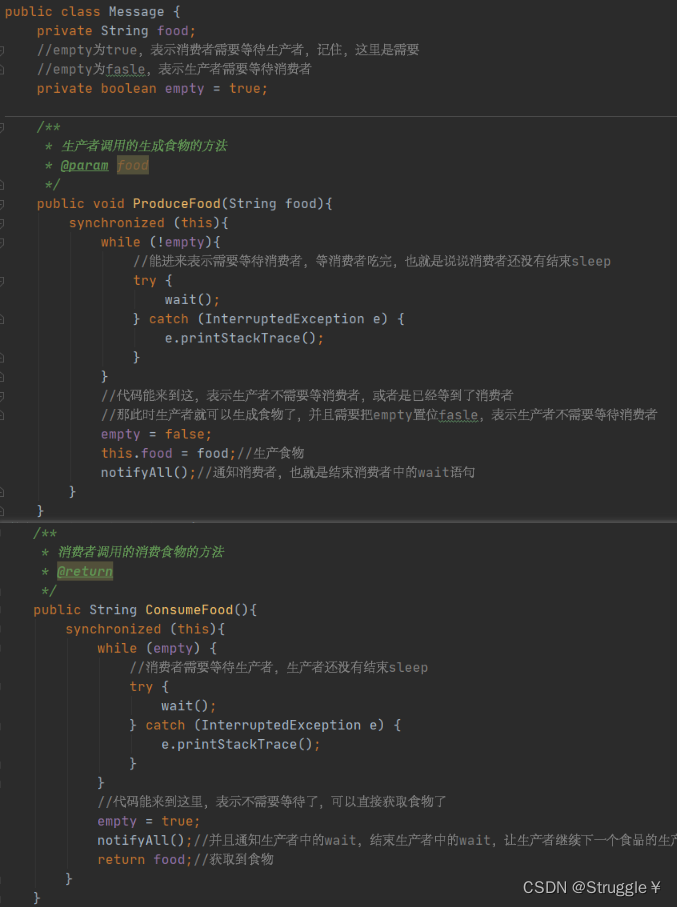
进一步,消息类中,可以定义两个方法,供生产者和消费者调用的:
但是,如果这样的话,直接在生产者或者消费者的run方法中调用这两个方法似乎也不合理。因为线程是同时执行,假如生产者还没有生成完毕,也就是说food变量还没有值呢,消费者此时获得食物岂不是会出错。
因此,合理的设计应该是这样:生产者生产食物的时候,消费者等待,生产者生产完之后,通知消费者,然后消费者去获得。
1、消费者调用wait,生产者调用notifAll用的必须是同一个对象
2、消费者调用obj.wait时,生产者调用obj.notifAll必须时,已经取得了obj的内部锁
wait是等待,notifyAll是结束wait,让程序继续往下执行。
因此,基于上述两个限制,线程间通信需要具备一些条件:
1、线程方法必须是同步语句方法,因为要获得内部锁
2、同步语句的对象obj得是相同的
下面的代码表示生产者和消费者都应该互相等待和互相通知。因为生产者内部有sleep,消费者内部也有sleep。
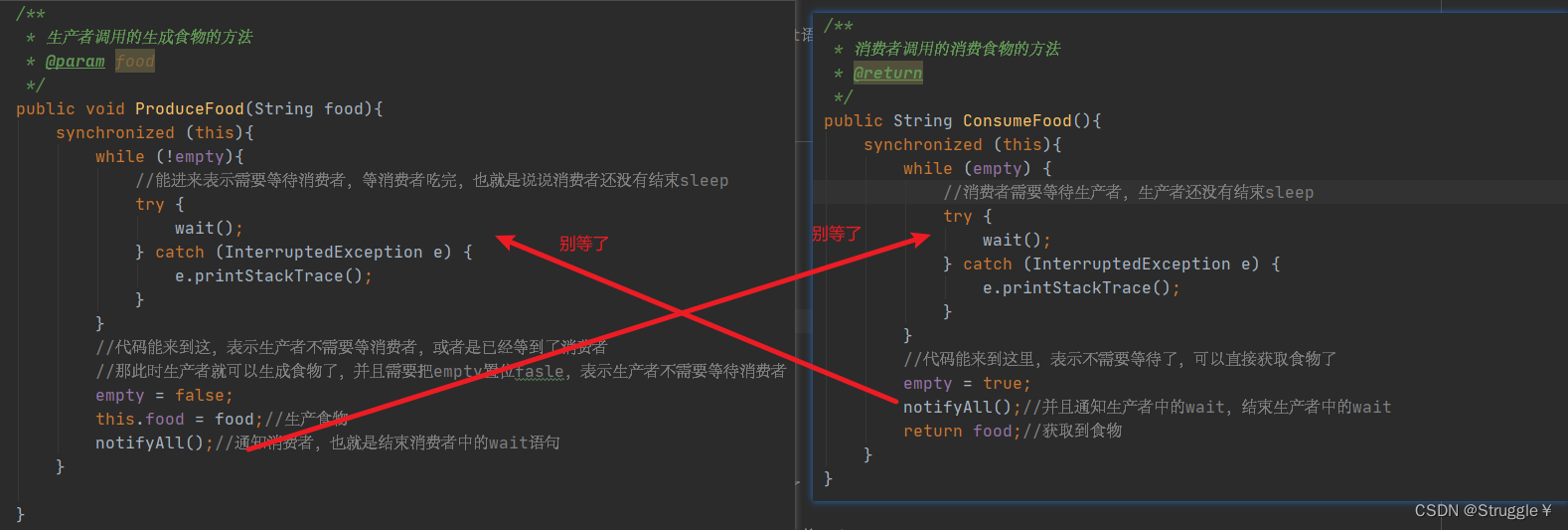
有人可能就会有疑问了,让消费者等我可以接受,让生产者等是为什么呢?
假如消费者内部的sleep没有结束,生产者就继续生产,是不是可能让消费者下次获得食物的时候,错过一些食物。比如生产者不等的情况下,生产者生产了两个食品,消费者才sleep结束,那么消费者就会错过前一个食物。
消费者需要等,那就很好理解了,生产者如果没有为food赋值,消费者也获取不到,所以要等生产者为food赋值之后,消费者才可以return food。
整个工程如下:实现生产者一个一个生成食品,消费者一个一个接收食品
生产者线程类:
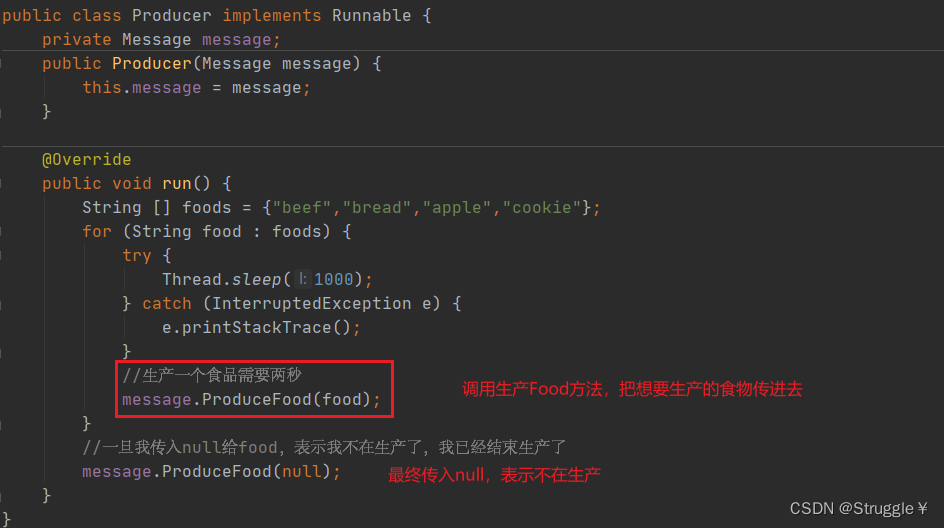
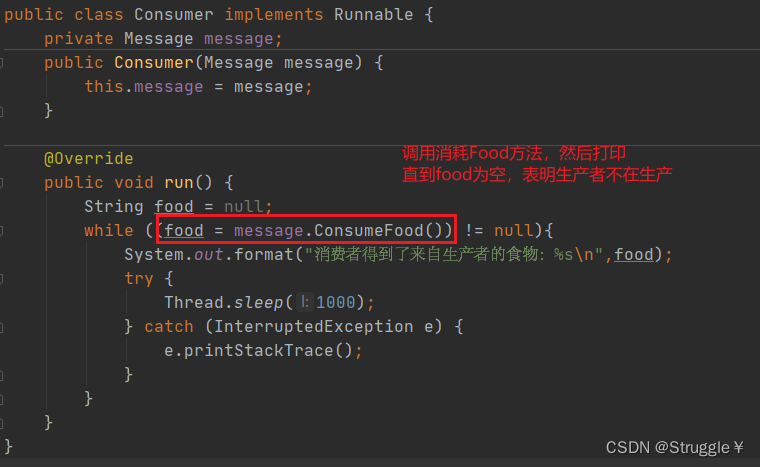
消费者线程类:
消息类里,存放food变量,并且实现生产食物和获得食物的具体表现:
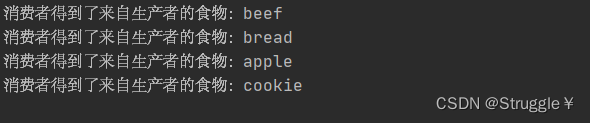
最终实现了如下效果:一个一个生产,一个一个获得。不缺一个,不多一个。
可重入锁(ReentrantLock)
具有跟同步语句、同步方法一样的一些基本功能,但功能更加强大。
比如,ReentrantLock除了最基本的加锁lock、解锁unlock,还有trylock和islock方法。因此功能更强大。
回顾卖票时,需要将卖票方法设置为同步方法。
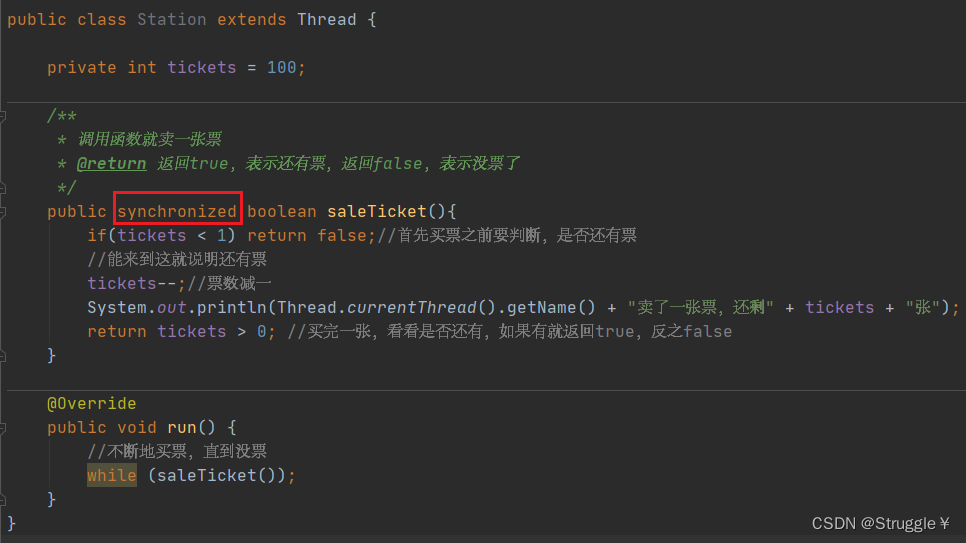
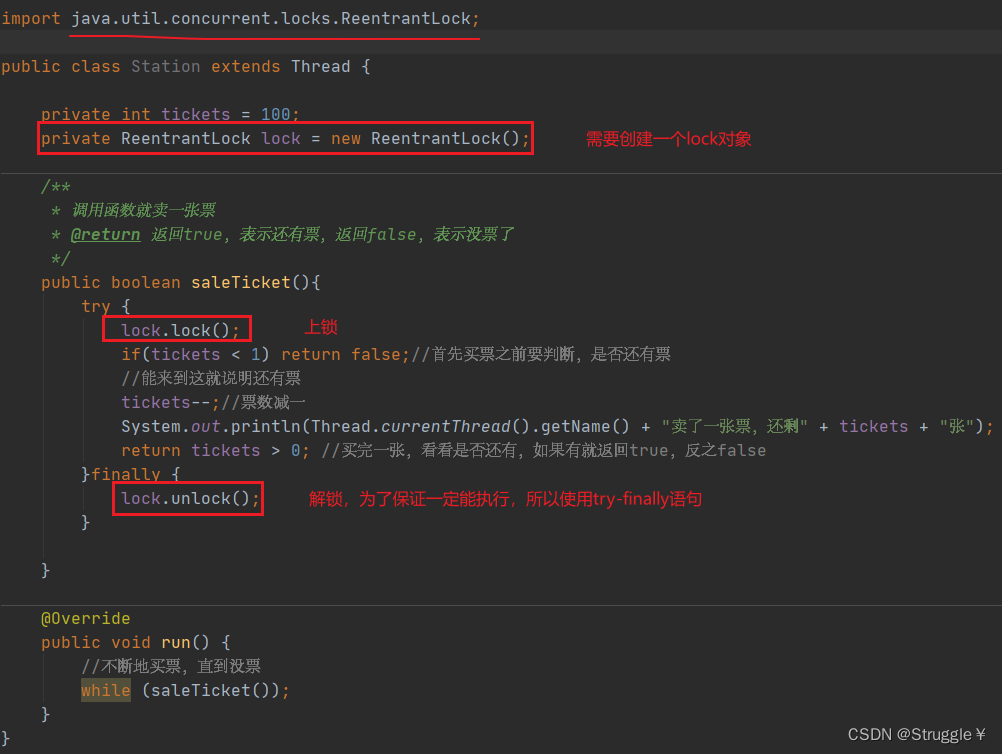
这里也可以使用可重入锁来实现:A线程进入try,就会上锁,B线程看到lock上锁了,就会等。这跟之前的同步语句一样。
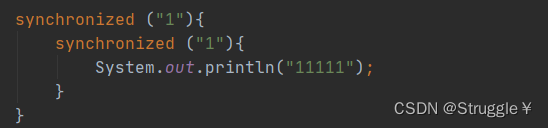
什么叫可重入锁?也就是“1”这个对象已经被获得了锁,如果是同一个线程还可以再次获得“1”的锁,“1”这个对象就叫做可重入锁。在有的编程语言中,这种是不可以重入的。
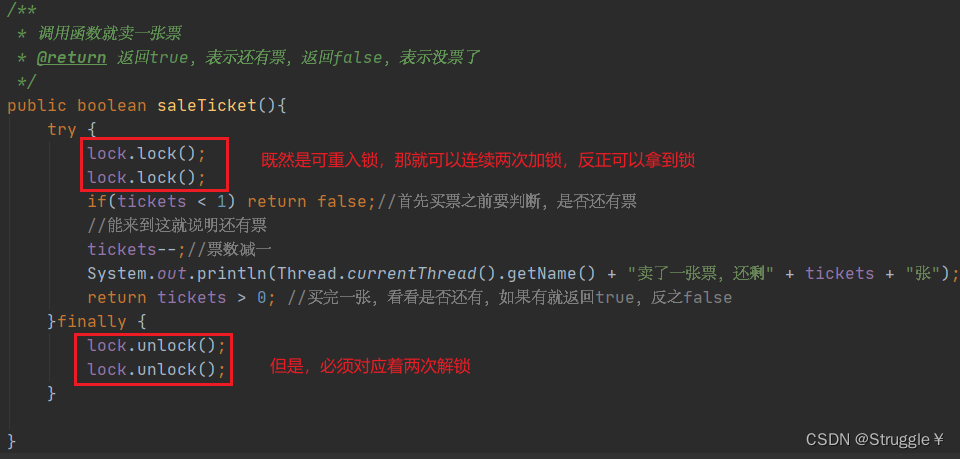
lock也就可以多次加锁和解锁了
线程池(Thread Pool)
一个线程对象被创建的时候,会分配一些内存空间给这个线程。如果在大型的应用程序中,频繁地创建和销毁线程对象会产生大量的内存管理消耗。
(我需要线程的时候,创建一个,线程执行完任务,就会终止。我下次还需要线程的时候,还得创建,然后重复上述步骤)
这个过程是很消耗资源的,有没有一种技术可以解决这个事呢?
线程池技术:一个池子里,固定的放几个线程,只要我不关闭,这几个线程就不会死,而是一直处于等待状态,等待任务的到来。这样就省去了频繁创建和销毁线程所带来的消耗。
线程池里面的线程叫什么呢?叫工作线程(Worker Thread),与普通线程最大的区别就是,工作线程并不是执行完一个任务就会销毁,而是执行完任务之后就处于等待状态,等待下一个任务的到来。
举一个例子:有20个任务,需要一个线程池执行。而线程池中只有5个工作线程,那么整个过程的步骤是什么呢?
20个任务都会被添加到队列Queue中(先进先出),然后再从队列中一个一个的取出任务提交到线程池。
接下来,我们看看Java如何搭建一个线程池:
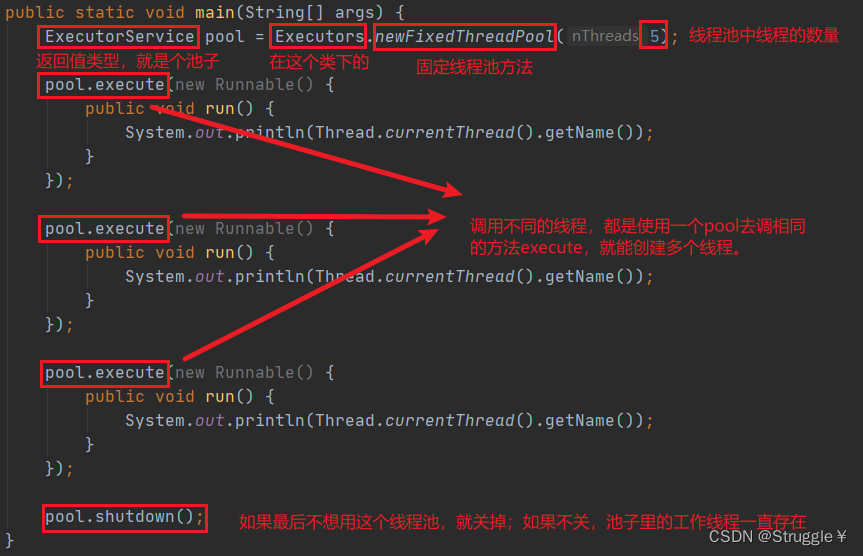
可以看到三个线程,都是不同的线程,同属于pool-1的三个线程:

Java中的I/O流(重要)
I/O流全称是Input/Output流,译为“输入/输出流”。我们要明白输入和输出的参照物是谁?
我们使用IO,通常都是对文件或者设备进行操作,也就是实现我们编写的程序和文件或设备之间的一个通信。
输出流指的是:Java程序向文件输出二进制码,即Java程序写东西进文件中
输入流指的是:Java程序受到文件的输入二进制码,即Java程序读东西从文件中
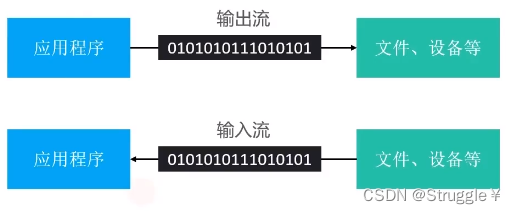
可以看得出,输入输出流是相对于Java程序说的,输入就是向Java程序输入(也就是Java程序的读操作);输出就是Java程序向外输出(也就是Java程序的写操作)
常用的IO流可以归结为下表:
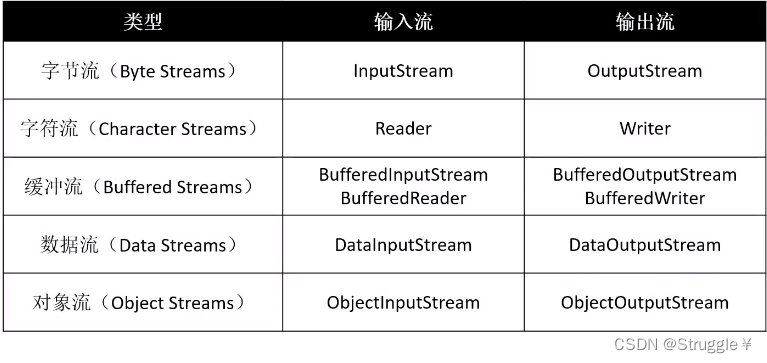
这里先粗略的解释一下:字节流就是输入输出字节的,字符流就是输入输出字符的,缓冲流就是字节流或者字符流带有缓冲区,数据流就是输入输出直接是基本数据类型的,对象流就是输入输出是对象类型的。
既然,IO流几乎针对的就是我们读写文件的操作,那我们很有必要先学习一个类,叫做File类
File类基本概念
明确:一个File对象就代表一个单独的文件或者一个文件夹(这个文件夹下还有文件或者文件夹)。也就是说,File对象可以被这两种类型的文件赋值。
如下所示,可以用File类声明一个文件file或者一个文件夹dir,这都是可以的。

注意:Java中反斜杠必须得写两遍,要不然就会被Java转义掉。或者采用正斜杠的方法声明路径,正斜杠在所有的操作系统中都是通用的,比如Unix、Mac、Linux、Windows,而双反斜杠只在Windows下可用。

路径中的反斜杠叫做分隔符,可以用Java中的File.separator查看当前系统下,推荐的分隔符是什么
System.out.println(File.separator);
可以看到在Windows是反斜杠,在其他操作系统中就是正斜杠了。

那么一个万能的,跨平台的编写路径的方法就来了:凡是分隔符的地方,都有这个属性替代,就可以保证程序运行在Window和Linux都不会出错。

File类的常用方法
我拿到一个File对象,我能干什么呢,如何从文件中获取一些我想要的信息呢?接下来,我们过一遍Java中对File对象的一些操作方法。
一些获取文件固有信息的一些方法:

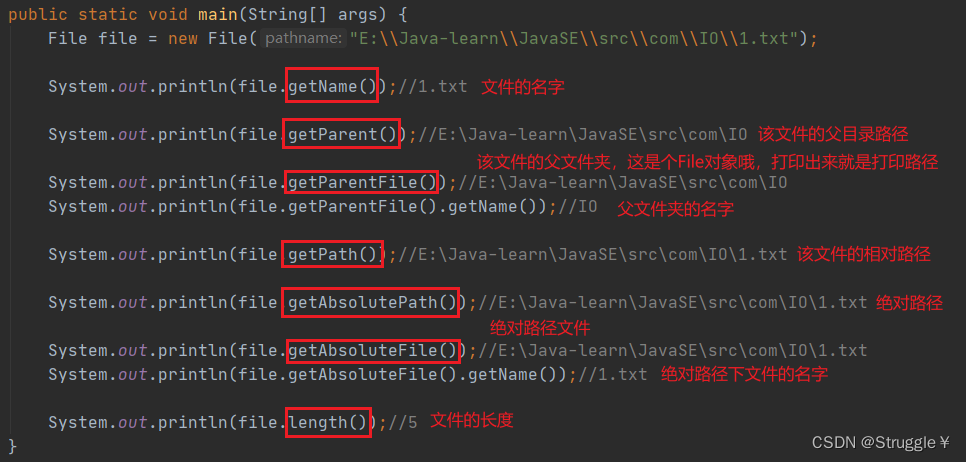
一些判断文件性质的方法:

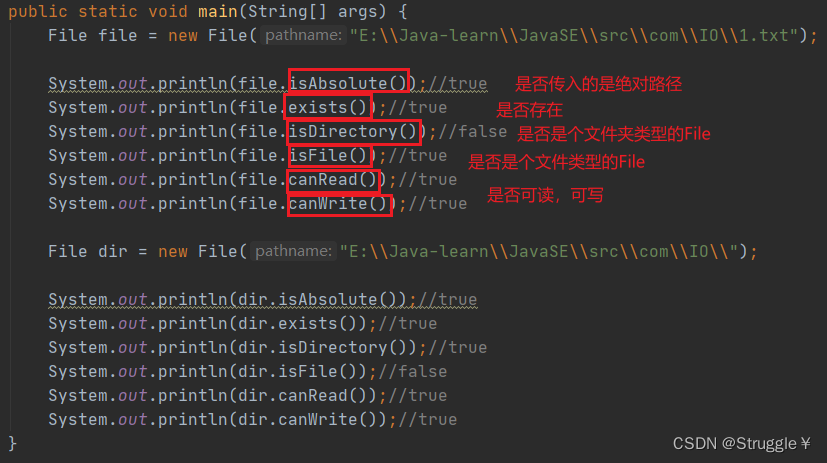
获取目录下子文件或者子目录的一些方法:

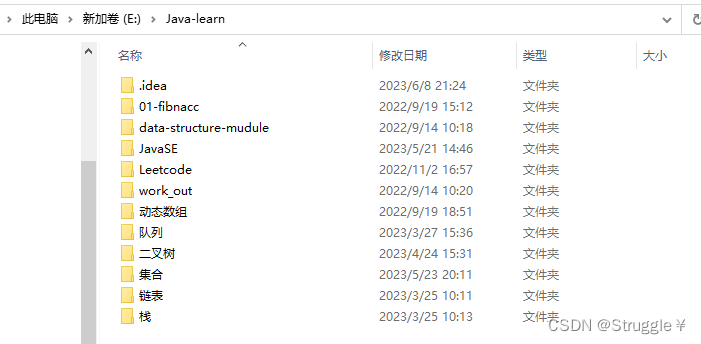
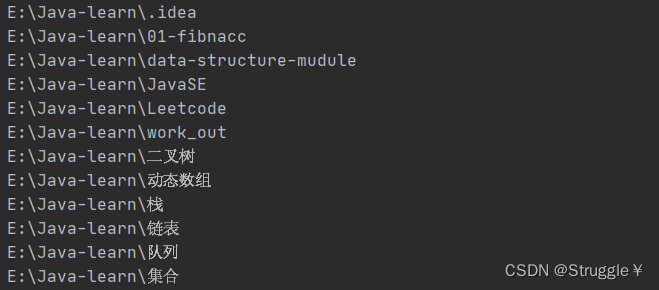
上图展示的是E:\Java-learn\JavaSE\src\com目录下的情况,我们先看看String[] list()方法的作用:
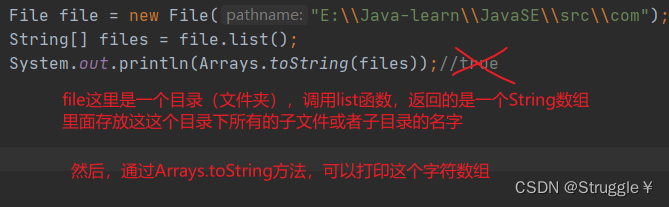
打印结果如下:

可以看出,调用list只会返回第一层的所有子文件,并不会继续遍历子文件夹还有没有其他的孙子文件。
然后,我们再来看看,File[] listFiles()方法的作用:
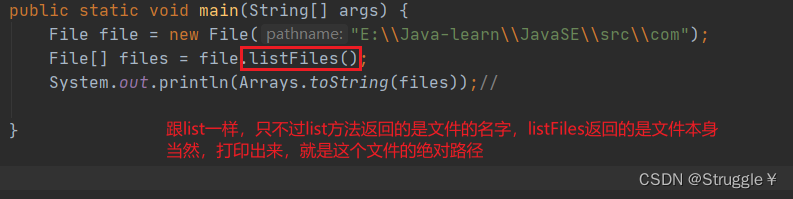
这里就先展示一部分,打印的也是第一层文件或者文件夹的名字。但是listFiles返回的是File类型的对象数组,不像list,返回的只是名字。

可以看出,调用listFiles只会返回第一层的所有子文件,并不会继续遍历子文件夹还有没有其他的孙子文件。
因此,想要把一个目录下的所有子文件,子文件夹,子子文件全都遍历出来,需要递归遍历,Java官方没有给出直接的API,后续会讲怎么实现。
创建文件或者创建文件夹的一些方法:

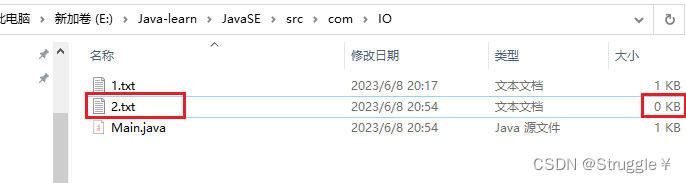
- createNewFile()创建新的文件,不会覆盖旧文件,如果之前存在2.txt,那么这个方法就不会覆盖掉之前的旧文件,直接返回。

- delete删除文件,可以删除文件,也可以删除目录(注意,删除的东西不经过回收站,无法找回因此,一定要小心,别删错了东西)

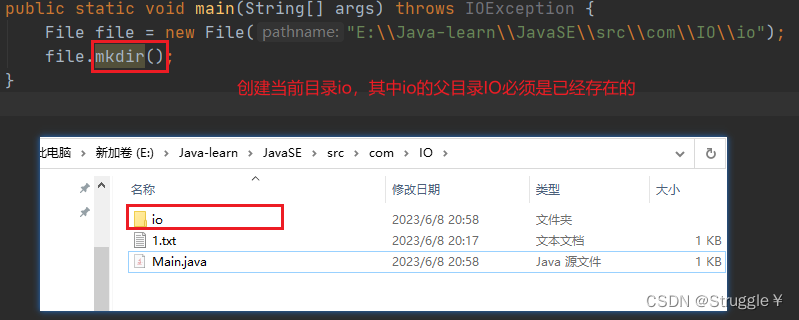
- mkdir基于已有的父目录,创建一个新的目录文件夹
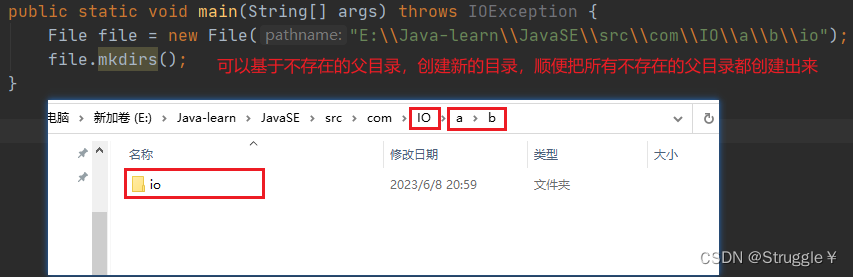
- mkdirs基于已有的父目录,创建一个新的目录文件夹
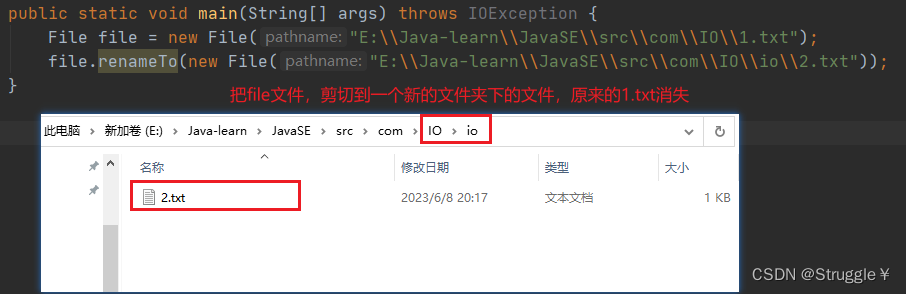
- renameTo可以把当前文件剪切为另一个文件,可以改名字。只可以剪切文件,不可以剪切文件夹。
练习:递归搜索某个文件夹下的全部文件
不断地查找所有的子文件夹已经里面的里面的文件,反正就是搜索全部文件,最终的需求是打印出来文件名即可。
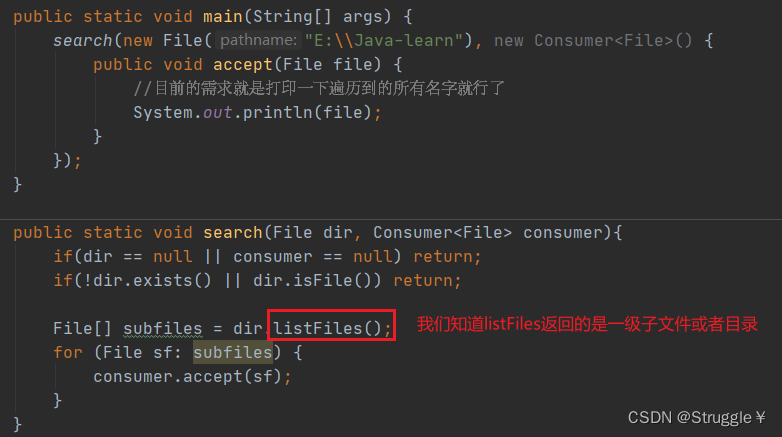
因此,最终遍历到的,还是一级子文件或者子文件:
因此,上面的代码并不是实现遍历所有的文件。下面我们要递归的搜索遍历到的第一级子文件夹,就可以实现继续向里面遍历的目的:
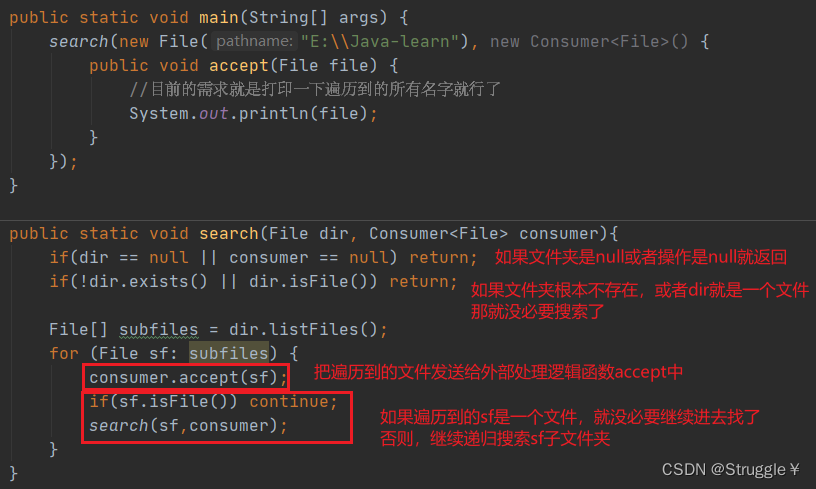
可以发现,实现了遍历所有子文件的目的:
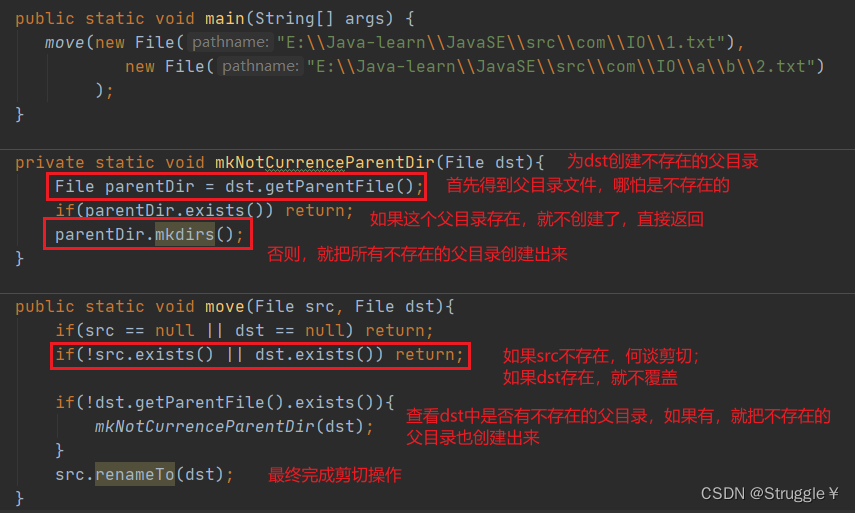
练习:剪切文件(支持剪切到目前不存在的目录下)
这是一个功能更加完备的剪切文件的实现。
字符集(Character Set)
学习I/O流之前,还要学习一个概念:字符集
在计算机里面,一个中文汉字是一个字符,一个英文字母也是一个字符,一个阿拉伯数字也是一个字符,一个标点符号也是一个字符…
字符集顾名思义,就是由字符组成的集合,常见的字符集:
- ASCII字符集:ASCII是一种基本的字符集,它包含了128个字符,其中包括数字、字母、标点符号和控制字符。ASCII字符集通常用于英语和其他西方语言。
- ISO-8859字符集:ISO-8859是一系列字符集,用于支持欧洲语言。ISO-8859字符集包含了256个字符,其中包括拉丁字母、希腊字母、西里尔字母等。
- Big5字符集:Big5是一种用于中文的字符集,主要用于台湾地区。Big5字符集包含了超过13,000个字符,其中包括中文字符、注音符号等。
- GB2312字符集:GB2312是一种用于中文的字符集,包含了超过7000个中文字符。GB2312字符集是中国国家标准,它被广泛用于中文计算机系统中。
- Unicode字符集:Unicode是一种更广泛的字符集,它包含了世界上几乎所有的字符和符号。Unicode字符集支持多种语言,包括中文、日文、阿拉伯文等。Unicode字符集包含了超过130,000个字符,其中包括基本拉丁字母、汉字、表情符号等。
目前,使用的最多的就是Unicode字符集。
字符编码(Character Encoding)
每个字符集都有对应的字符编码方式,比如Unicode里的字符,采用的是Unicode编码方式;GBK字符集采用的是GBK编码方式。
编码方式,决定了,每个字符,如何转成二进制存储在计算机中。意味着,同一个字符,采用Unicode编码和采用GBK编码,编出来的二进制序列是不同的。等到将来解码的时候,也要按照对应的编码方式来,否则就会出现乱码。
下图是不同编码方式的一个大致编码逻辑:

我们可以看一些例子,体会一下不同编码方式编出来的码是什么样的:

字符串只有一个,因此不同编码方式所编的字符都是相同的。只不过不同的编码方式,得到的编码结果是不同的。
getBytes("编码方式")可以返回对应字符的编码结果。
一般将【字符串】转为【二进制】的过程,我们称为编码(Encode);
一般将【二进制】转为【字符串】的过程,我们称为解码(Decode);
下面是乱码的例子:对于同一个字符串,编码和解码的方式不同,就会导致乱码。
字节流(Byte Streams)
前面铺垫了这么多,终于要到I/O各种流的学习了,首先我们先学习字节流(非常重要,因为是最底层的数据形式–字节)。
字节流的特点:
- 一次只读写一个子节
- 最终都继承自InputStream和OutputStream
- 常用的字节流有FileInputStream和FileOutputStream
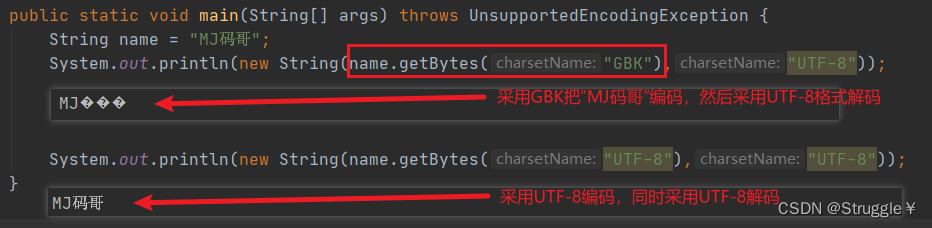
我们首先来看看字节输出流FileOutputStream怎么用:左边用FileOutputStream的父类OutputStream修饰也行,右边需要new一个FileOutputStream对象,需要传入文件名的参数,意味着我需要知道将来我要写入的文件是什么。
其中,77和74分别是一个子节,记事本对77和74进行了解码,采用utf-8解码方式(因为,我们默认编码方式就是utf-8)
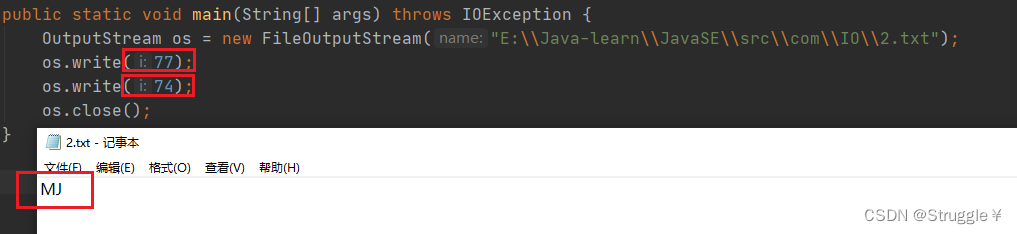
还可以,直接把子节数组传进去,也是一样的解析:
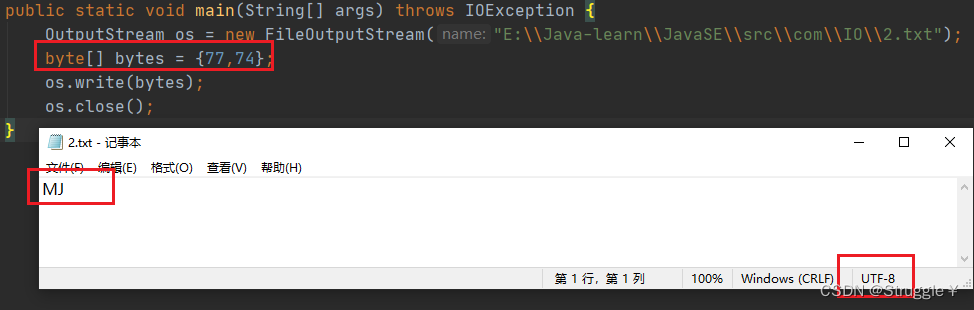
但是,这种每次write的时候,都会直接覆盖掉原来所有的数据,如果我想追加write,怎么操作:
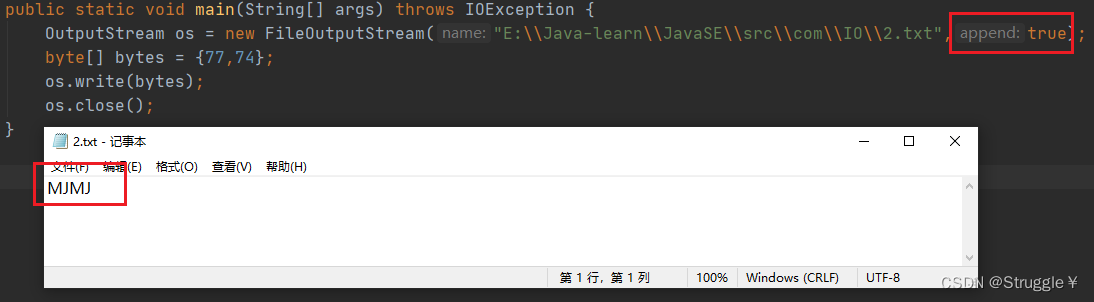
只需要在构造函数处,换一种传参方式:多写一个append参数,声明为true即可
我们首先来看看字节输出流FileInputStream怎么用:构造函数需要传入文件名字,表明我们从哪个文件中读取字节数据。
文件中有四个字节,如果想要一个一个读取,就要一个一个调用read函数,就能把字节值读出来,读出来的就是字母对应的字节值,对于ASCII来说,就是0~127之间的int整数。
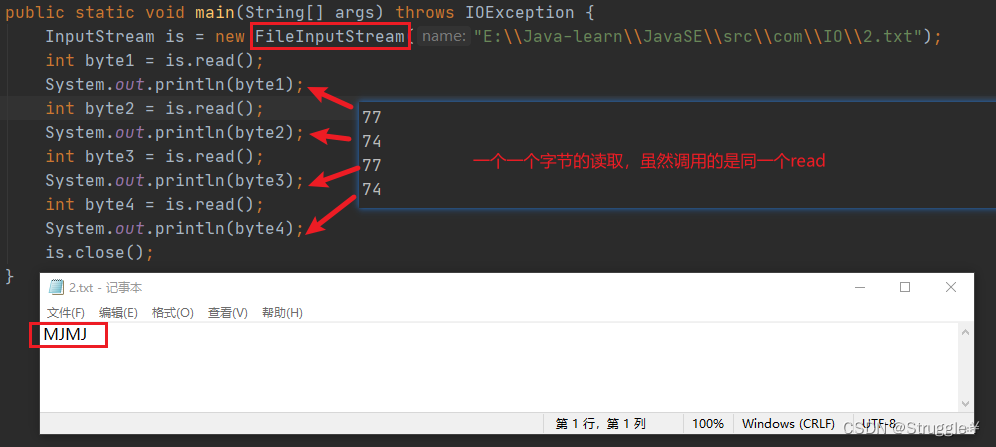
如果,我文件中存的是汉字,我想要读取出来,怎么办:
就不能采用一个一个字节的读了,因为一个汉字是由多个字节编码而成的
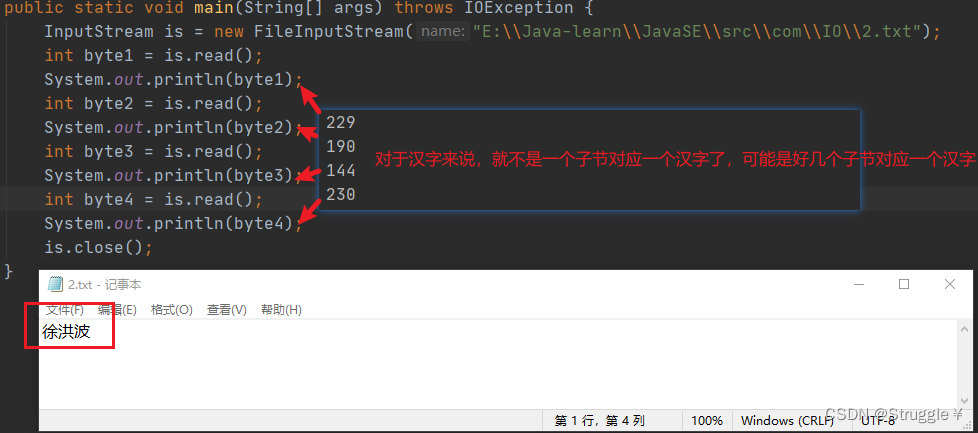
不信看一眼,这个文件中字节的个数:

我们来看一看,这三个汉字的字节是什么?
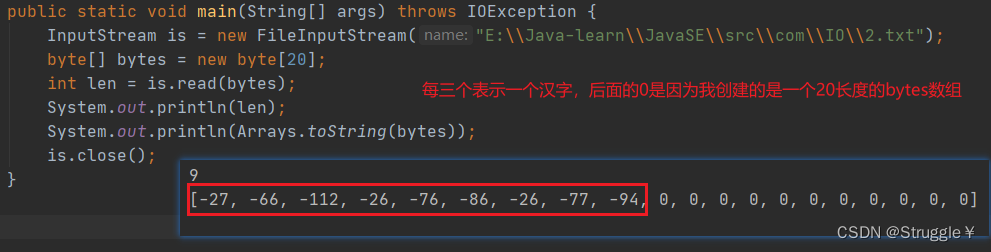
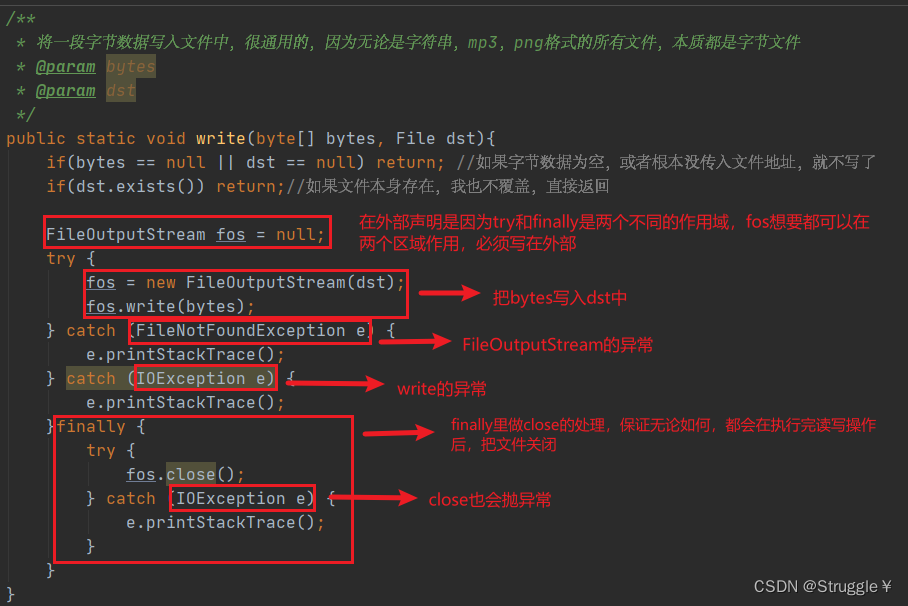
练习:将内存中的字节数据写入文件
检验函数执行效果:用Java自带的read方法读取2.txt的字节,用我们上面实现的write方法写入到dst中
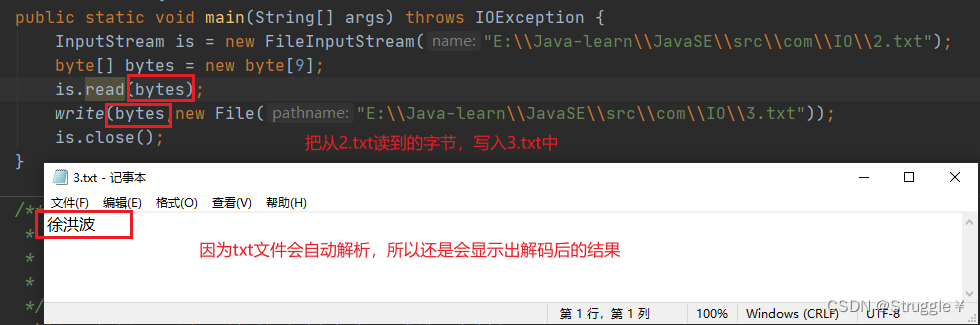
还可以,继续完善,也就是说,将来我想要写的这个文件,它的父目录可能是不存在的,我要把父目录创建出来。因此,可以调用之前写的方法:
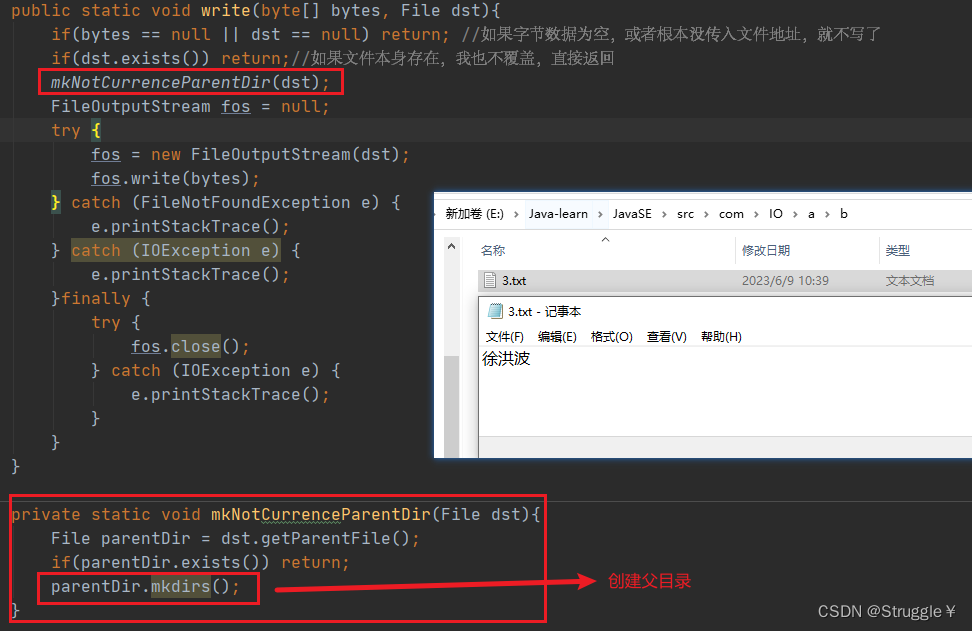
练习:从文件中读取字节数据到内存
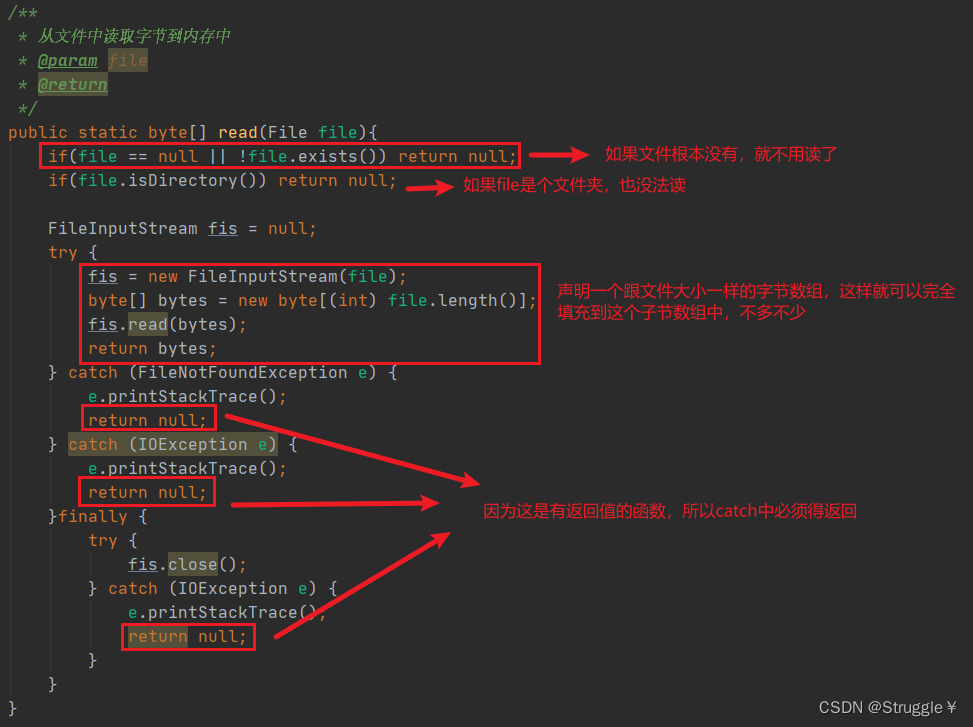
检测一下读取函数的实现:发现成功从3.txt文件中读取到了字节。

如果我想要把读取到的字节,在程序中顺便解析为字符串,怎么实现呢?

可以看出,当初我用UTF-8编码的,我解码时采用UTF-8就会完全解析出来。反之,我采用GBK解码,就会出现乱码。
练习:复制文件到另一个文件(字节复制)
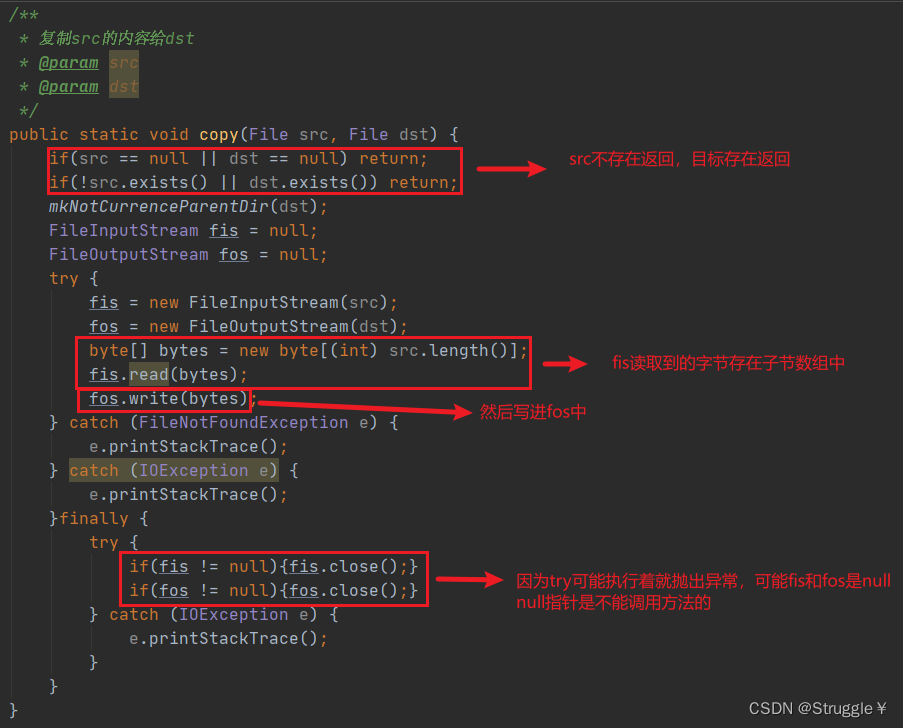
我们来看一下测试效果,可以实现一个txt文件的复制:
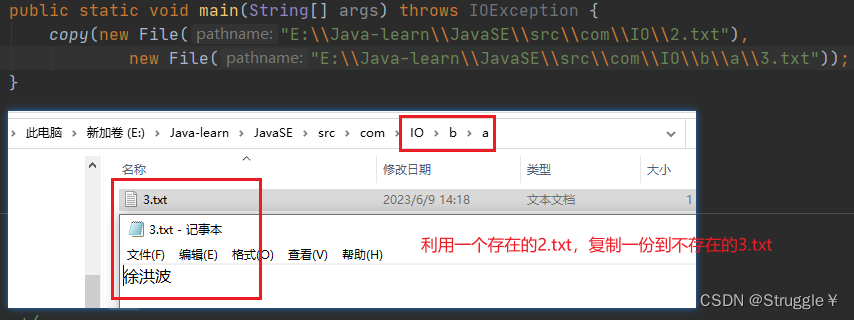
因为,我们是字节流传输,因此可以复制任何格式的文件,下面我们来复制一个jpg图片:
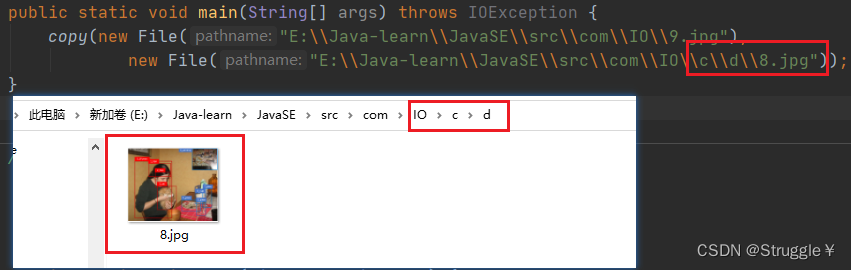
非常的完美。
try-wtih-resources语句
我们在写I/O流的过程中,经常需要在使用完IO流之后,关掉它,也就是在finally里声明close方法。因此需要处理很多的异常,就如下图一样。这将会大大增加代码量已经恶心程度。
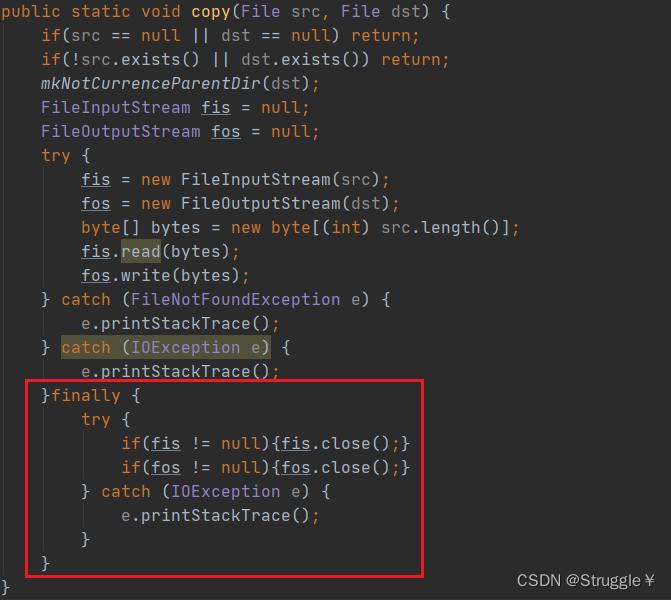
有没有一些方法,可以减少异常代码的书写呢?答案是,当然有!
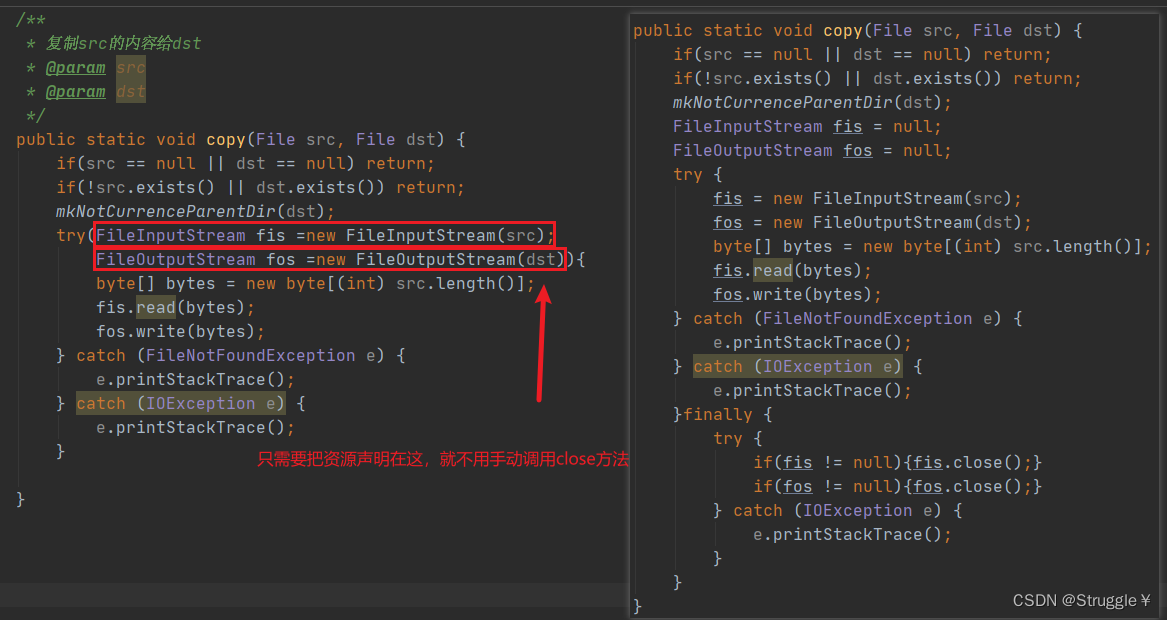
就是从Java7开始推出的try-with-resources语句(可以没有catch、finally),这种语句可以在try后面的小括号中声明一个或多个资源(resource)(什么叫资源呢?实现了java.lang.AutoCloseable接口的实例都可以称之为资源)。

try-with-resources语句有什么特点呢?
不管try中的语句时正常结束还是异常结束,最终都会自动按照顺序调用每一个资源的close方法(close方法的调用顺序与资源的声明顺序相反)
下面我来改造一下,copy函数。左边是使用try-with-resources语句,右边是之前的。可以看到,使用try-with-resources语句的代码里大大减少。
字符流(Character Streams)
我们在上面学习了字节流,也就是Java程序和文件之间进行字节数据的传输。本节,我们学习字符流,顾名思义,那就是传输字符。
字节流是一个一个字节的读写,字符流就是一个字符一个字符的读写。
常用的字符流有FileReader和FileWriter。注意,这两个类只适用于文本文件,例如.txt,.java等这类文件,无法读取图片、视频、音频等文件。
首先我们看看FileWriter如何写字符到文件中:可以直接写字符进文件,也可以直接写字符串进文件。
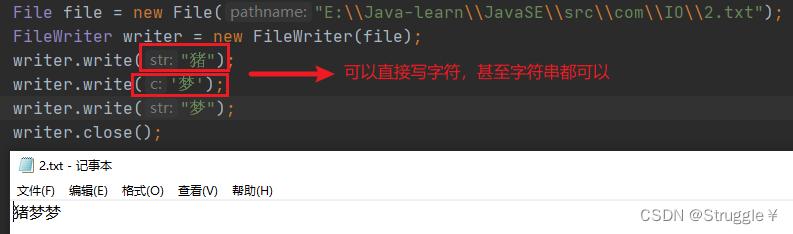
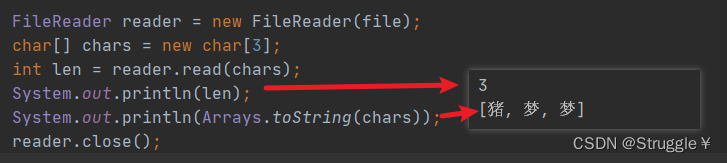
现在我们来看看FileReader的用法:可以从文件中读取字符,read返回的是字符的长度,之前字节流返回的是字节的长度。
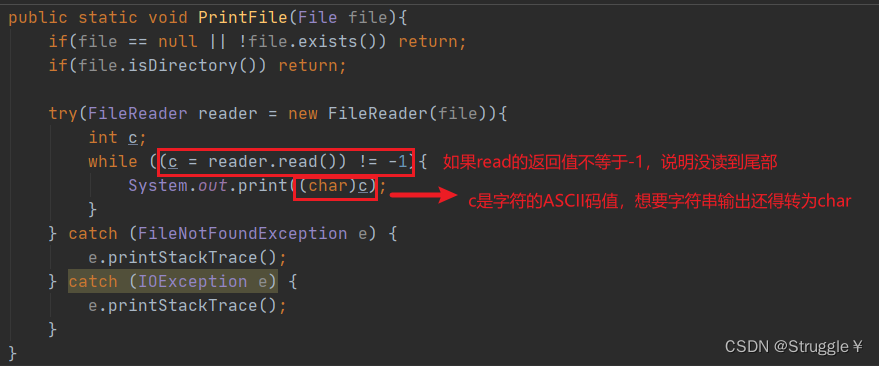
练习:将本文文件中的内容逐个字符打印出来
我打印的就是Main.java文件,也就是当文件:
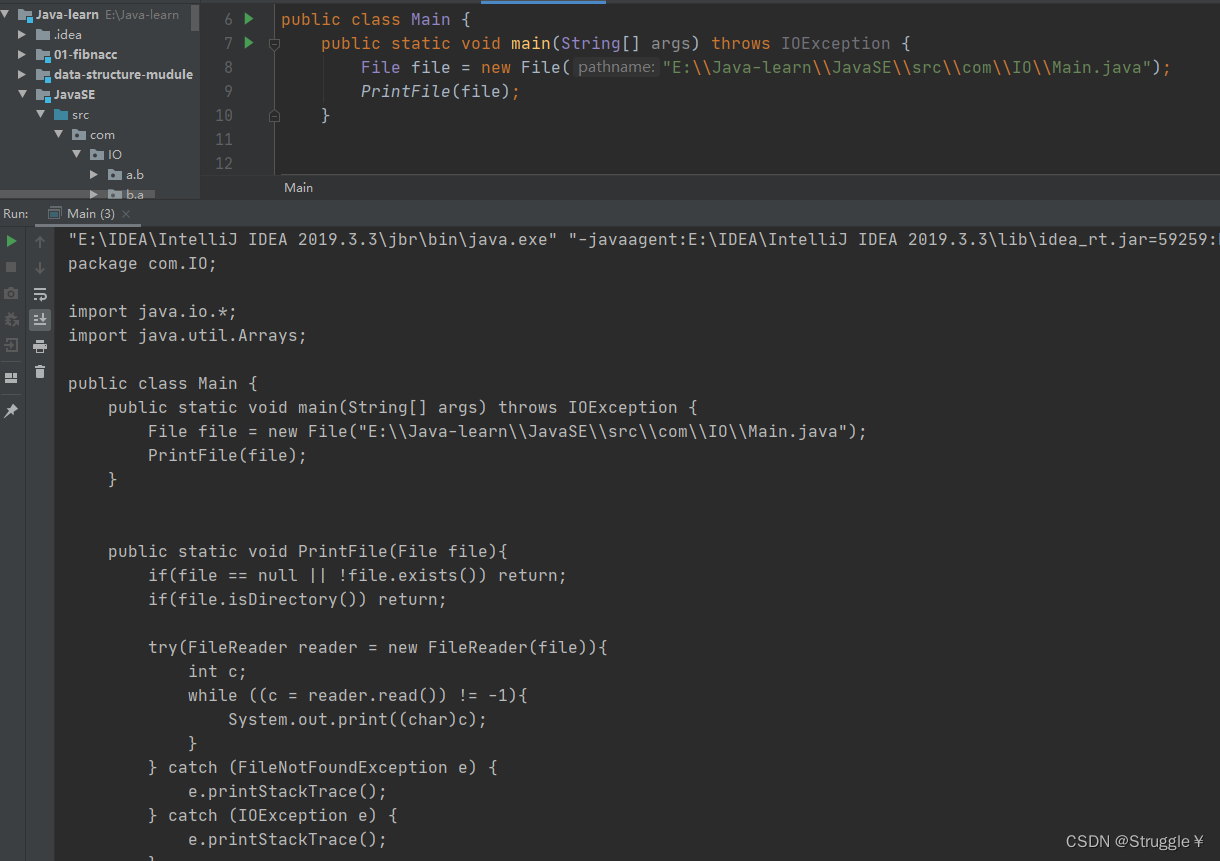
可以看出,想要读取字符文件,使用字符流是最方便的。
缓冲流(Buffered Streams)
之前学习的字节流、字符流,都是无缓冲的I/O流,每个读写操作均由最底层的操作系统直接处理。
每个读写操作通常会触发磁盘访问,因此大量的读写操作,可能会使得程序的效率大大降低。
为了减少读写操作带来的开销,Java实现了缓冲的I/O流
- 缓冲输入流:从缓冲区读取数据,并且只有当缓冲区为空的时候,才调用本地的输入API
- 缓冲输出流:将数据写入缓冲区,并且只有当缓冲区已满时,才调用本地的输出API
说白话:读和写都是Java程序访问缓冲区。当缓冲区没了或者缓冲区满了,才会建立缓冲区向操作系统之间的联系。
缓冲就是一层Buffer,还是去服务字节流和字符流的。

上述表格中4个缓冲流的默认缓冲区的大小是8KB,可以通过构造方法传参设置缓冲区的大小
那,缓冲流如何使用呢?又有什么特点呢?
缓冲流常见的使用方式:将无缓冲流传递给缓冲流的构造方法(也就是,将无缓冲流的IO流包装成缓冲流)

一个很恰当的比喻:如果把无缓冲流比作是一个无装备的士兵,那么缓冲流就是一个有着强力装备的士兵。
下面的例子是缓冲字符输出流:
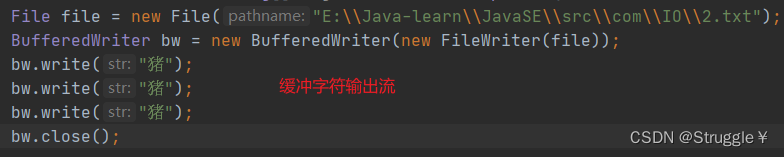
缓冲流中有一个细节,那就是缓冲区的存在,可能会导致我们写数据到文件中,可能第一时间文件中并没有出现数据。原因是,数据都在缓冲区里,还没有到文件中呢!!!
比如,上面的缓冲流进行write的时候,如果不调用close函数,可以发现2.txt中是没有出现数据的。
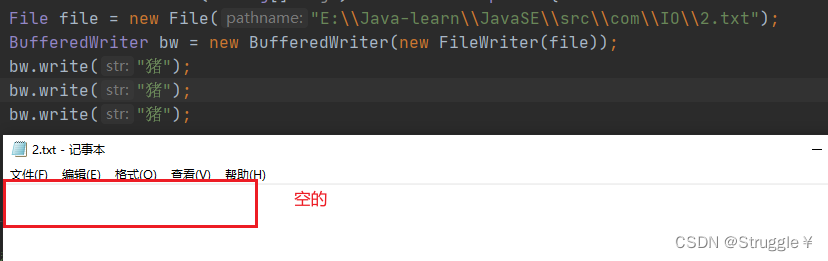
如果想要第一时间写完就出现在文件中,怎么处理呢?
调用缓冲输出流的flush,会强制调用本地的输出API,把缓冲区的数据立马写进文件中。
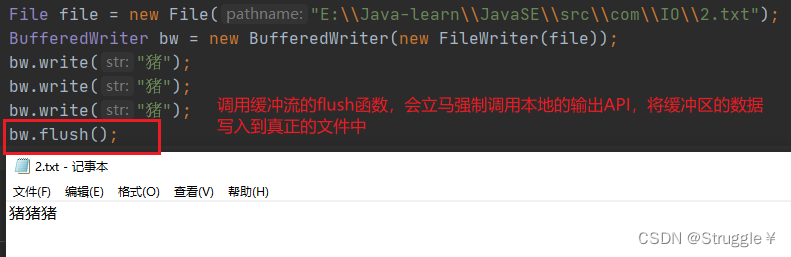
缓冲输出流的close方法,内部会调用一次flush方法,所以我们平常close之后,也会把缓冲区里的数据立马写进真正的文件中。
练习:用缓冲流修改write方法
我们可以把字节输出流包装成缓冲输出流,也就是说,写数据到文件中,不一个一个写进去了,先写在缓冲区里,然后一下子从缓冲区写到文件里,可以提高效率。
练习:用缓冲流修改read方法
也就是把字节输入流,包装成缓冲输入流,可以读取字节数据的时候,不一个一个读了,一次读多点,放在缓冲区里,这样就会提高读的效率。
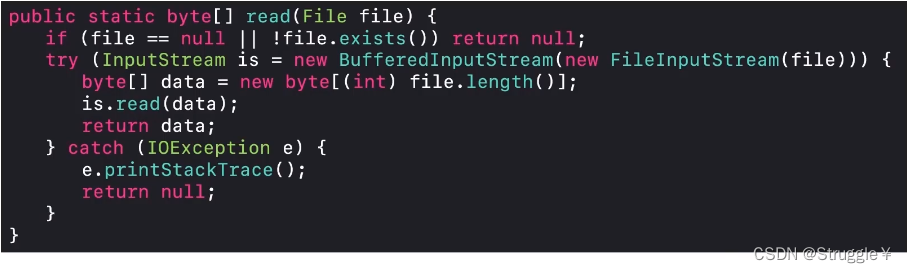
数据流(Data Streams)
有两个数据流:DataInputStream、DataOutputStream,支持基本类型、字符串类型的I/O操作。
之前我们要不就是对字节数据进行读写,要不就是对字符数据进行读写。我们还没有对int,double类型进行读写呢。
数据流就可以办到这件事。
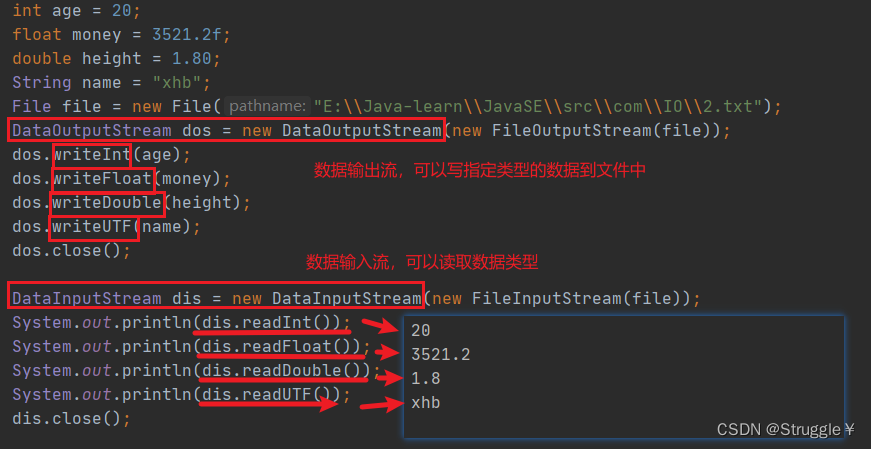
看看2.txt里长什么样子:可以看出,数据流会进行一定形式的编码,没啥规律其实。但是niubility之处在于读的时候,原封不动读出来。
场景:想做一些基本数据类型的存档,存到一个文件中去,以后我们在读出来,就可以使用数据输入输出流。
对象流(Object Streams)
有两个对象流:ObjectInputStream、ObjectOutputStream,支持对象引用类型的IO操作。
有一个前提,只有实现了java.io.Serializable接口的类才能使用对象流进行I/O操作。
所谓存对象的数据,不就是存对象内成员的数据吗,我们首先看看使用数据流怎么办到。
首先声明一个Perosn类
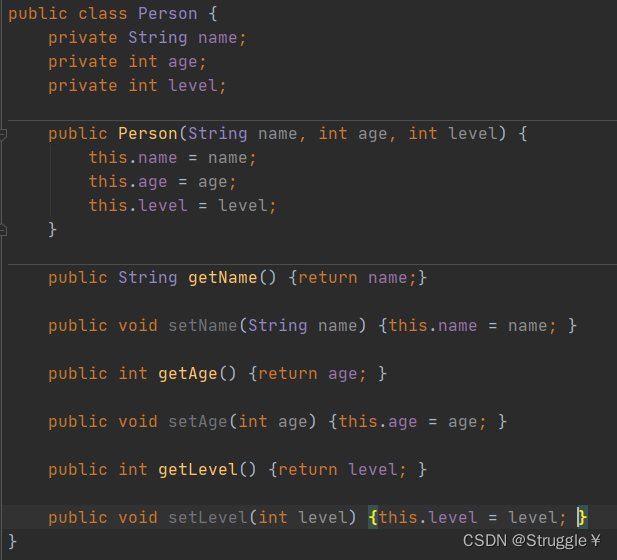
然后使用数据流,把类的数据写进文件中去。
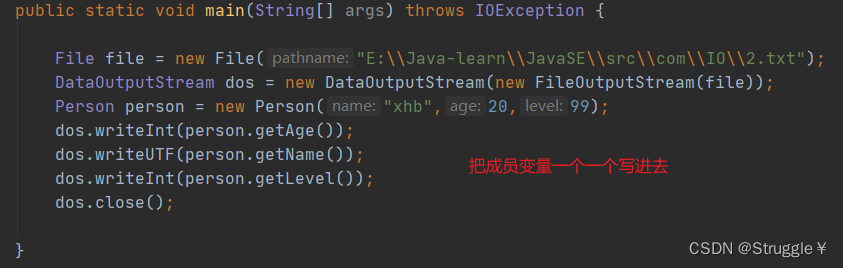
假如,一个类有好几百个成员变量呢?这样写,是不是太麻烦了!!
这就得请出对象流了,看看怎么使用的:
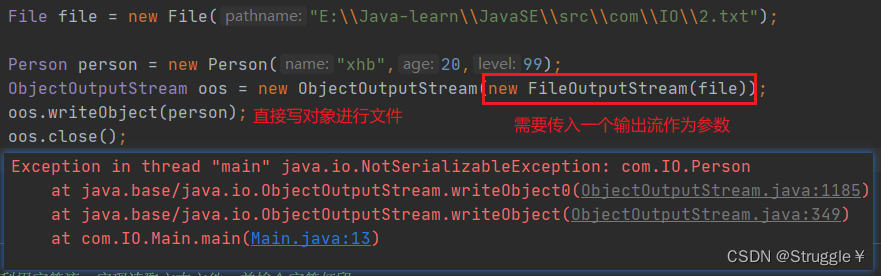
这里爆出了一个异常:原因是我们上面说的,想要使用对象流,这个对象必须实现Serializable。
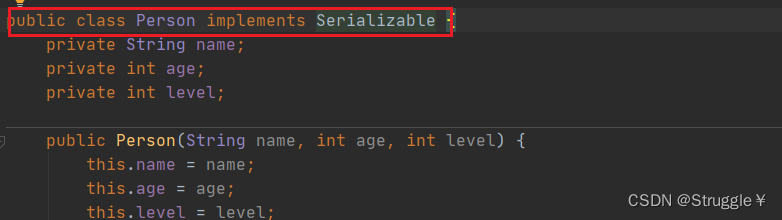
可以看到,我们想要写入的类对象,实现了Serializable,就不会报错了。
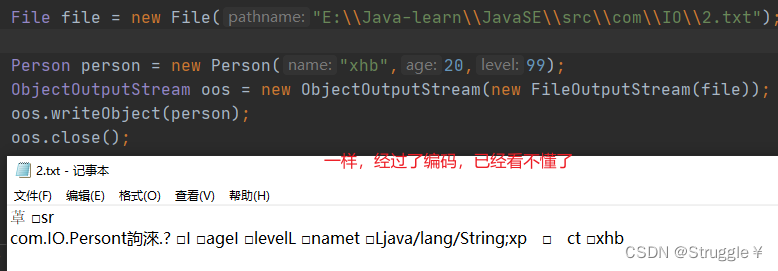
接下来,我们读取这个对象,看看能不能把对象的东西读出来:
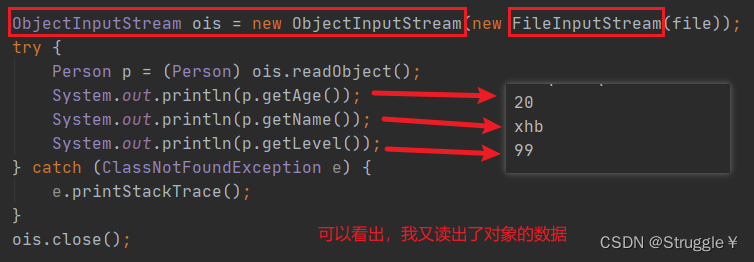
可以看出,我读取对象的数据成功了。
对象流的读写,有专业术语:写叫做序列化,读叫做反序列化。这也能说明为啥想要进行对象流的类都必须实现Serializable。(序列化的效率不高,在实际开发过程中,还是得用数据库 )
- 序列化:将对象转换为可以存储或传输的数据,利用ObjectOutputStream可以实现对象的序列化。
- 反序列化:从序列化后的数据中恢复出对象,利用ObjectInputStream可以实现对象的反序列化。
有一个关键字,transient,用来修饰不想要被序列化的对象成员变量。
比如,我不想序列化level这个变量,就用transient修饰即可,也就是说,写对象到文件中时,这个变量不会被写进去,或者只写它的初始值。
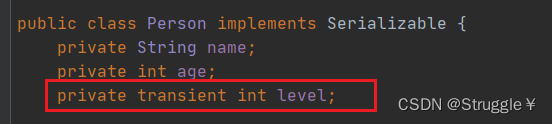
可以看到,我明明初始化为99,但是读出来确是0。这就是没有被序列化的标志。
读出来的数据,需要强制转换成Person类,才能当做Person对象使用。
对象流还有一个非常重要的属性,那就是serialVersionUID。这个东西是干什么的呢?
先说明一个使用场景:我们已经把Person对象写进了文件中,等到我读的时候,Person类的内部被我改了(比如我删除了一个成员变量)。也就是说,文件中存储着旧版本的Person,现在我想要把旧版本的Person读出来强制转换为新版本的Person,这不就出错了嘛!!
每一个可序列化的类都有一个serialVersionUID属性,相当于类的版本号。只要某个类实现了Serializable,Java内部就会为当前类给出一个serialVersionUID。如果我们在写完对象之后,类发生了变化,那么当前类的版本号就会变。但是文件中存储着的类的版本号还是之前的那个serialVersionUID。然后等到强制转换的时候,就会报错:serialVersionUID不一致。
那么我们怎么解决上述的场景问题呢(即便我后续改了类,我也想把之前的读出来)?
这里给出答案:强烈建议每一个可序列化类都自定义serialVersionUID,不用使用系统给出的默认值。
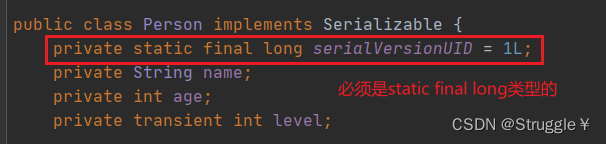
这样的话:之前在把Person对象写在文件中的serialVersionUID就是1。即使我后续更改了Person内部(比如删了一个成员变量之类的),我的serialVersionUID还是1。因此在强转的时候,会对比文件中Person的serialVersionUID和现在Person的serialVersionUID,发现是一致的,就不会报错。
Java中的网络编程
具体,更加细节的知识,可以去学习《计算机网络》这本书。本节只介绍一些最经典的案例。
网络互连模型
为了更好地促进互联网网络的研究和发展,国际标准化组织ISO在1985制定了网络互互连模型。
最早的网络互连模型叫做OSI(Open System Interconnect Model),具有七层结构。

但是,由于这个模型太复杂,因此并不常用。我们最常用的是TCP/IP协议模型

我们,日常学习研究,采用的是小改版的TCP/IP协议模型(五层结构):
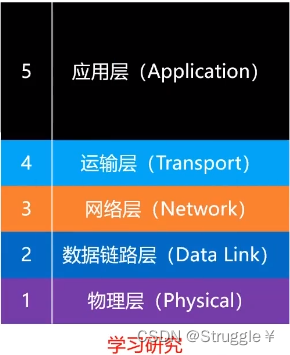
下面我们利用这个五层结构,讲解一下网络互连是咋互连的(也就是经典的三次握手,四次挥手)
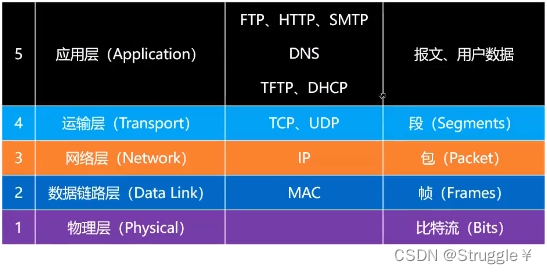
网络分层里的数据
HTTP请求过程
下面我们来介绍一下HTTP的请求过程,也就是我们平常输入网址返回一个网页的过程。
我们输入网址的地方,就是浏览器,也叫客户端。返回网页数据的,是服务器端。中间还可能要经过一些路由器的连接之类的。
下面是一个http请求从客户端到服务器的过程:
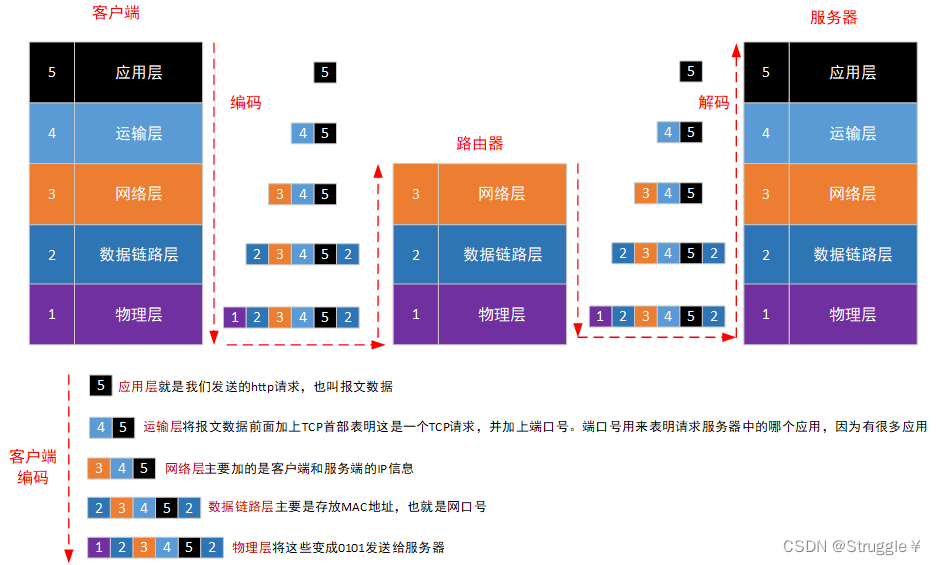
路由器为啥只有三层:因为路由器的作用就是通过IP寻路。找到最短的路径能让客户端的东西发发送到服务器。因此网络层上面就不需要了。
总之,客户端到服务器之间的过程其实很复杂。大致总结为一下说法:
- 客户端将报文数据一顿编码,加上各种必要的信息。
- 服务器对编码后的结果一顿解码,获得原始的报文数据。
TCP/IP协议
TCP/IP协议,简称TCP/IP。
是一个网络通信模型,以及一整个网络传输协议家族,为国际网络的基础通信架构。
TCP/IP不仅仅指的是TCP和IP两个协议,是指一个由FTP,SMTP,TCP,UDP,IP等构成的协议家族。
只不过TCP,IP协议是该协议家族最早通过的标准,所以称为TCP/IP。
TCP:Transmission Control Protocol,传输控制协议
IP:Internet Protocol,网际协议
TCP vs UDP
在运输层中,有两组常见的协议,就是TCP和UDP。
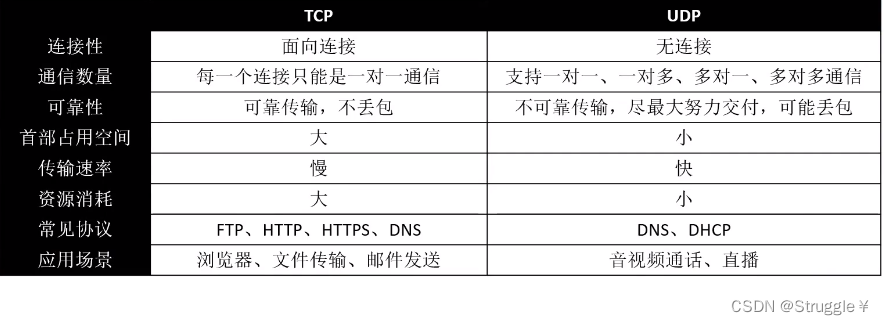
- 连接性:TCP要确保客户端和服务器建立连接,才能执行客户端的发送;UDP则不需要建立连接就能从客户端向服务器发,至于能不能发到服务器上,不保准。
- 可靠性:TCP是确保连接上了,才从客户端发到服务器,是一种可靠传输,不丢包。UDP知道服务器的IP和端口号,相当于从客户端撒东西出去,不管服务器接没接到,是一种不可靠传输,可能会丢包。(TCP如何保证不丢包:客户端发送数据到服务器,如果服务器没有收到,就不会发送信号给客户端,客户端会再发一下,直到客户端收到了服务器端的应答)
- 应用场景:TCP用在浏览器,文件传输,邮件发送,最大限度保证不出错。UDP可以用在视频通话,直播追求效率,但是可能会丢包(比如,卡了,卡的那段时间对方说的话不会再听到了,会接着视频)
TCP建立连接之三次握手
客户端和服务器之间想要建立TCP的连接,都有哪些操作呢?
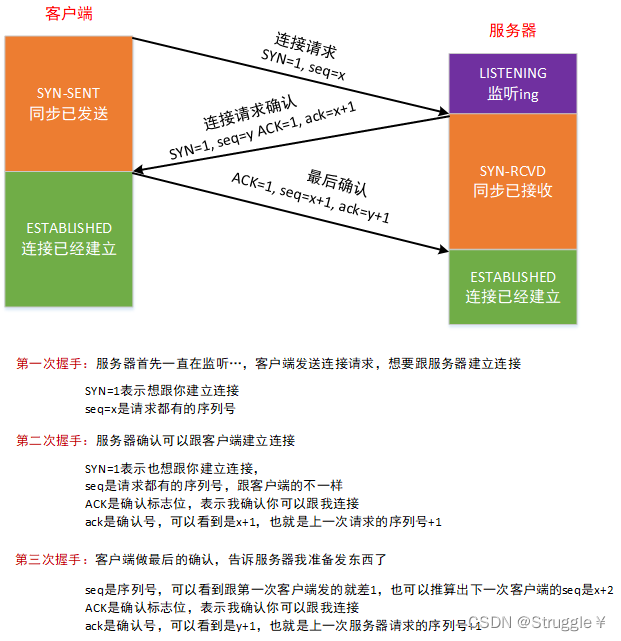
总结核心要点:
- 三次握手,就是为了建立连接,下一步才是发送数据
- 无论是客户端还是服务器,每一次请求的序列号seq都是上一次加1
- 无论是客户端还是服务器,确认号ack都是上一个的请求序列号+1,确认号可以理解为对上一个请求的响应
TCP释放连接之四次挥手
释放连接通常发生在数据传输完毕之后,客户端为了不浪费服务器的资源,选择释放掉与服务器的连接。具体都有哪些步骤呢?
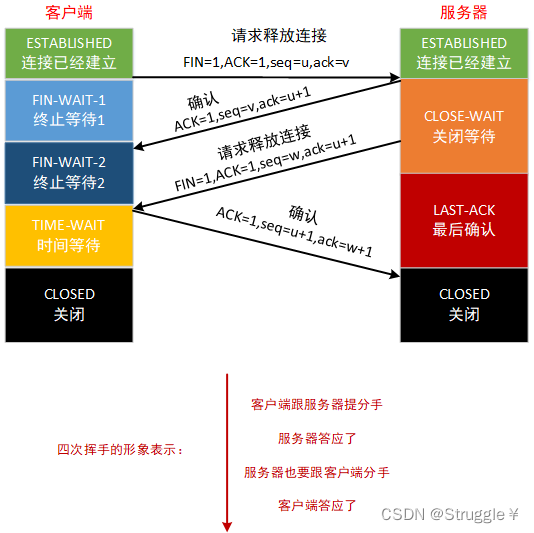
Socket编程
上面介绍了那么多TCP的一些知识,下面看看Java中是如何实现TCP请求的。
在Java中,使用java.net.Socket、Java.net.ServerSocket可以实现TCP请求。
- 首先我们来编写服务器的程序
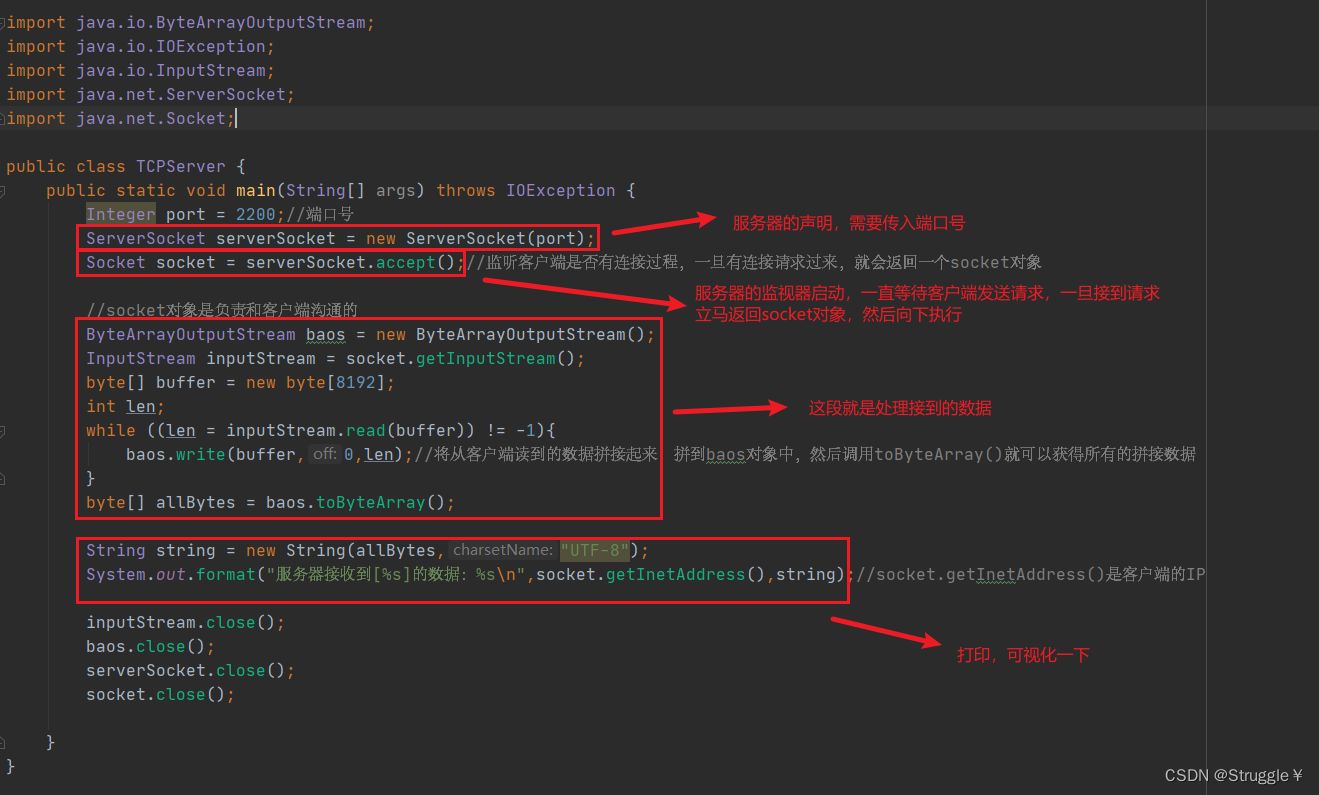
只要,服务器程序启动,就会一直监听,程序也会一直运行。

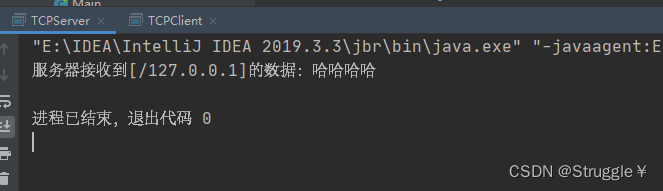
- 下面编写客户端程序:
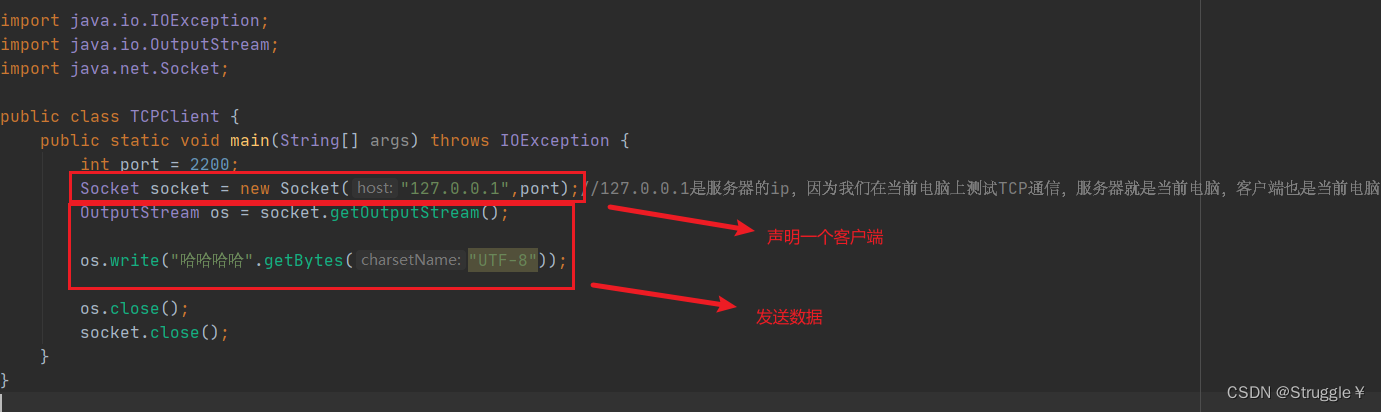
然后可以看到,服务器的控制台输出了: