一、概述
title:SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
论文地址:https://arxiv.org/abs/2212.10560
代码:GitHub - yizhongw/self-instruct: Aligning pretrained language models with instruction data generated by themselves.
1 Motivation
- 构造instruction data非常耗时耗力,常受限于质量,多样性,创造性,阻碍了instruction-tuned模型的发展。
- 背景:instruction-tuned方法是指利用非常多的指令数据【人类instructions指令和respond回答数据】去finetuned LLM模型,让模型能够理解人类指令,训练后使其对新的任务有非常强的zero-shot能力。
2 Methods
- 方法概述:本文提出self-instruct框架,通过bootstrapping off方法让原始的LM模型直接生成instruction数据,通过过滤和筛选后,产生大量的insturction指令数据(多样性和效果都不错),进而可以极大降低instruction数据的构建成本。
- 方法步骤总结:通过少量种子数据 + LM模型本身(未经过tuned模型)=> 生成instruction(指令)+ input(指令提到的输入,可以为空)+ output(响应输出)=> 然后filters过滤无效和相似的样本 => 来构造非常多的instruction指令遵循数据,详细步骤如下:
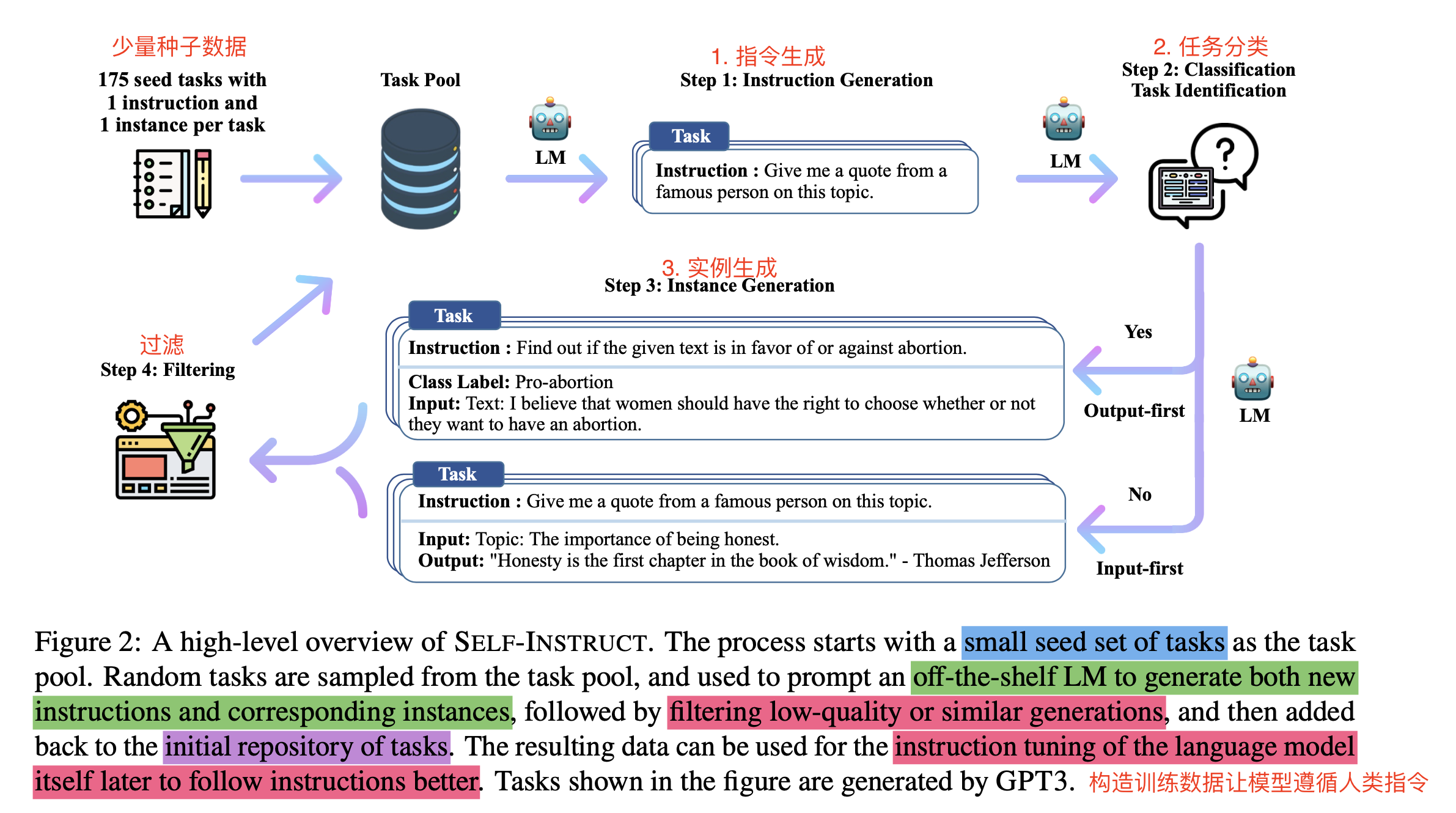
2.1 Defining Instruction Data
- Instruction:指令
- X:根据instruction,X可能为空或者不为空。例如:输入X为空的Instruction:write an essay about school safety,输入不为空的Instruction:write an essay about the following topic
- Y:答案,只根据X或者Instruction理想的response回答
2.2 Automatic Instruction Data Generation
- Instruction Generation:使用175个种子数据来生成新的Instruction,每一步采用8-few-shot的策略,其中6个是人类写的,2个是机器生成的。

- Classification Task Identification:利用LM采用few-shot的方式来预测1中生成的instructions是否为分类任务,采用12个分类任务,19个非分类任务作为few-shot的例子。

2.3 Instance Generation:采用两种方法来生成实例X和Y
- 输入优先方法(Input-first Approach),首先根据说明提出输入字段X,然后产生相应的输出Y,这里task就是input X,output就是输出Y,也是通过in-context learning来做的,主要处理非分类的实例生成。

- 分类任务的输出优先方法(Output-first Approach),先生成可能的类标签,然后生成对应句子【这么做是为了控制正负样本比例】

2.3 Filtering and Postprocessing
- 过滤相似度比较高的,和已有的样本ROUGE-L小于0.7的才要
- 过滤image,picture,graph通常LLM无法处理的词
- 过滤instruction相同但是answer不同的
- 过滤太长或者太短
2.4 FineTuning
- 采用多个templates模版,来encode instruction和instance进行训练,提升不同格式的鲁棒性。
1.3 Conclusion
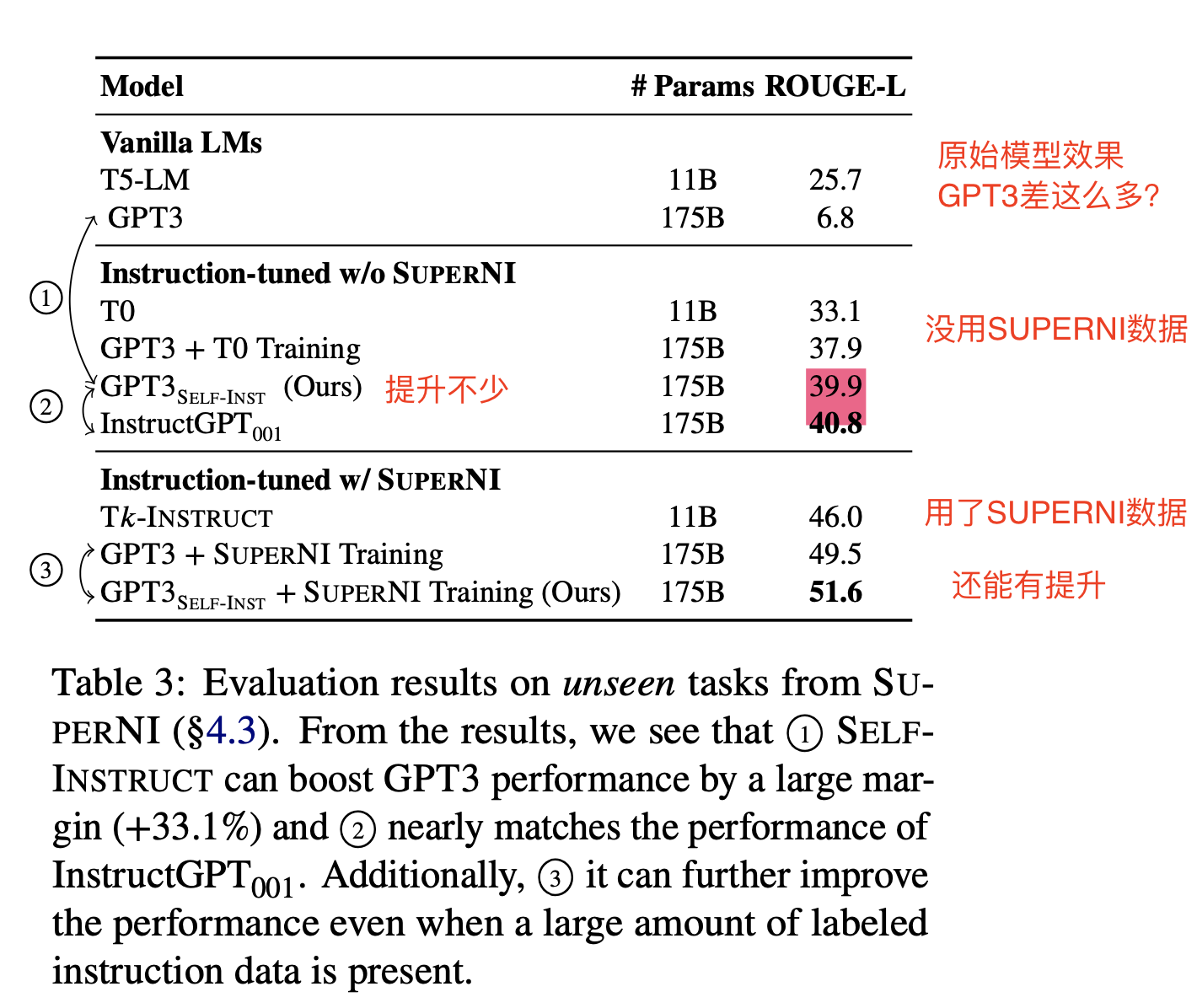
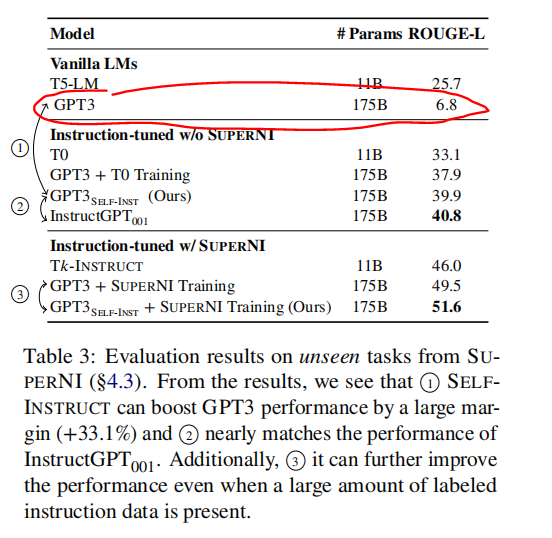
- 比原始的GPT-3模型,绝对提升了33%,并且达到了差不多追上InstructGPT001的效果。就算利用公开的instruct数据,也有不错的提升。
- 总结:
-
- 就用了175个原始种子数据,利用GPT3接口finetuned模型,比原始的GPT3高了33个点,并且居然和InstructGPT001效果差不太多了。
- 有了充分的训练数据,在SUPERNI数据集(其更偏向于研究领域任务,与人类的Instruction的分布还是有差异,后续也针对真实的人类Instruction分布做了实验)上训练,用了本文提出的self-instruct还是有2个点的提升。
- self-instruct提供了一个不用大量标注就能让原始的LM(未进过指令学习的模型)学习理解人类指令的解决方案,极大的降低指令数据的生成和标注成本。
- 本文发布了大规模的synthetic数据集,方便后续大家进行instruction tuning的研究。
1.4 limitation
- 长尾效应还比较严重:self-instruct依赖于LMs生成数据,会继承LM的缺陷,偏向于出现频率高的词。在常见的指令上效果可能不错,在长尾样本上可能效果比较差。
- 依赖大模型:依赖大模型的归纳偏差(inductive biases),可能只在大模型上效果比较好,由于大模型资源要求比较大,这也限制了小模型的使用。
- 增强LM的偏见:可能会放大social bias,例如模型可能无法产生比较balanced的label。
二、详细内容
1 构建面向用户实际需求的Instructions进行训练进而评估self-instruct是否有效果

- 背景:SUPERNI数据更偏向于研究任务,这里通过头脑风暴构造了一些更偏向用户实际需求的Instructions,来检验self-instruct的效果,还是和InstructGPT系列来比较
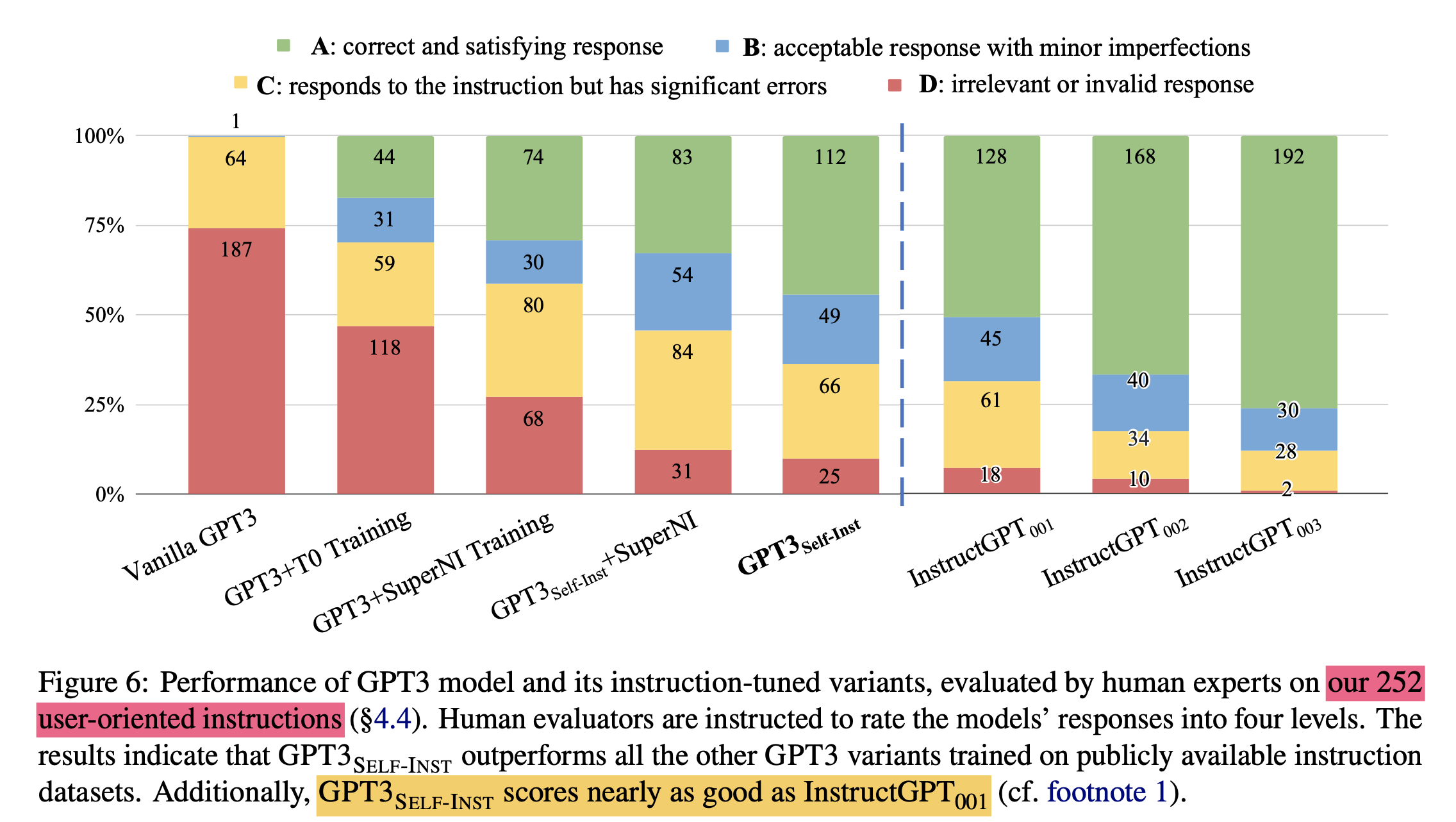
- 结论:效果也基本接近InstructGPT001,说明了其有效性,这里只使用了252个种子数据,也可以极大的降低Instruction构建的成本。
2 评估使用本文self-instruct方法扩充的Instruction是否真的有用
方法:从Instruction数量、回复response质量两个角度来进行试验,其中response质量对比是通过蒸馏更好模型的response来做的实验。
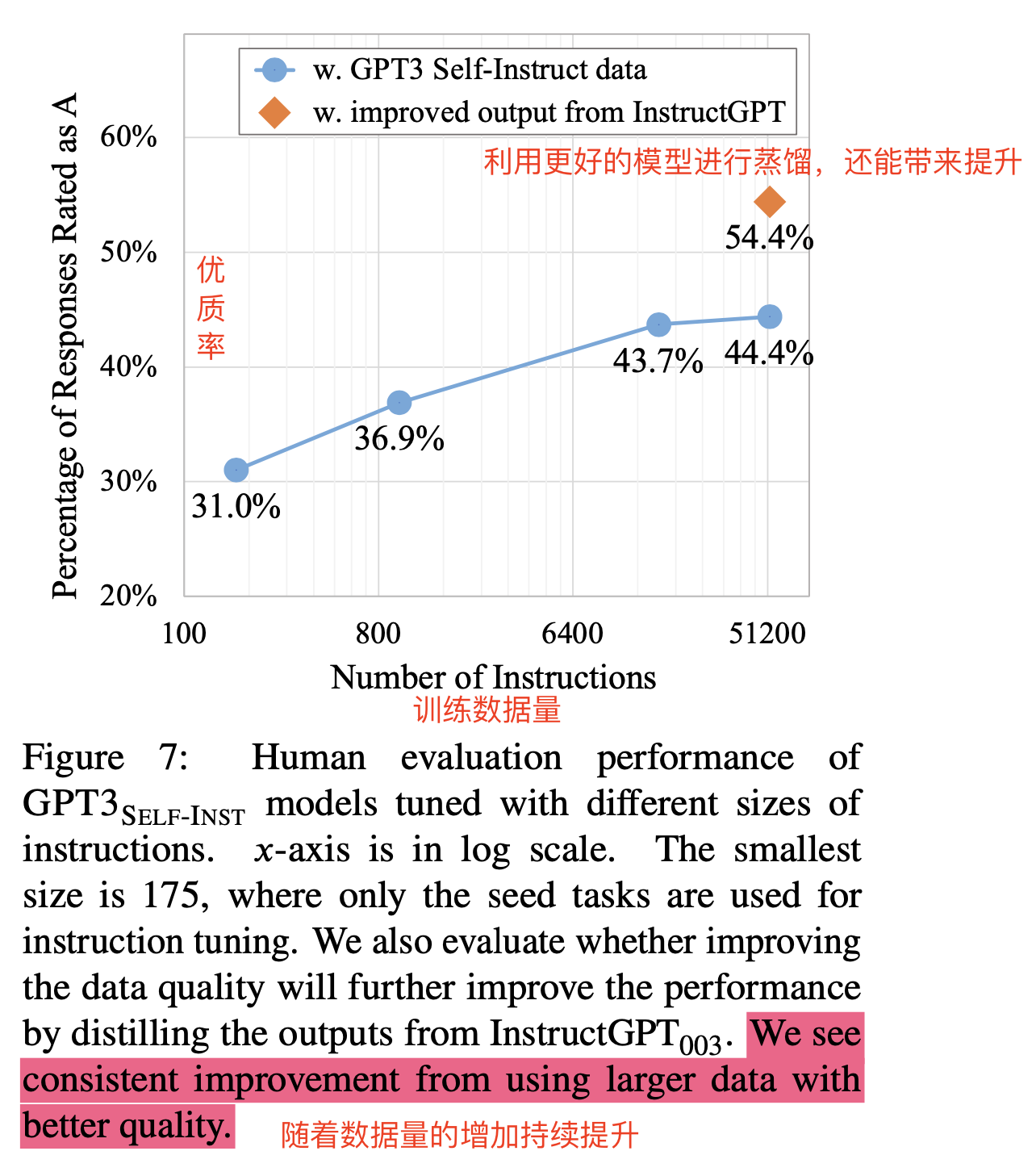
- 实验1:评估扩充的训练数据量级对效果的影响
-
- 方法:从最开是的175个种子数据,逐步增加数据量,评估效果。
- 结论:大概训练数据在16K左右,效果就比较平了,带来的提升没那么大了。
- 实验2:评估生成的response的质量对效果的影响(从更好的模型InstructGPT蒸馏得到更好的response)
-
- 结论:44.4%提升道54.4%,说明更好的回复质量对模型的提升也是巨大的。
3 生成的数据量级
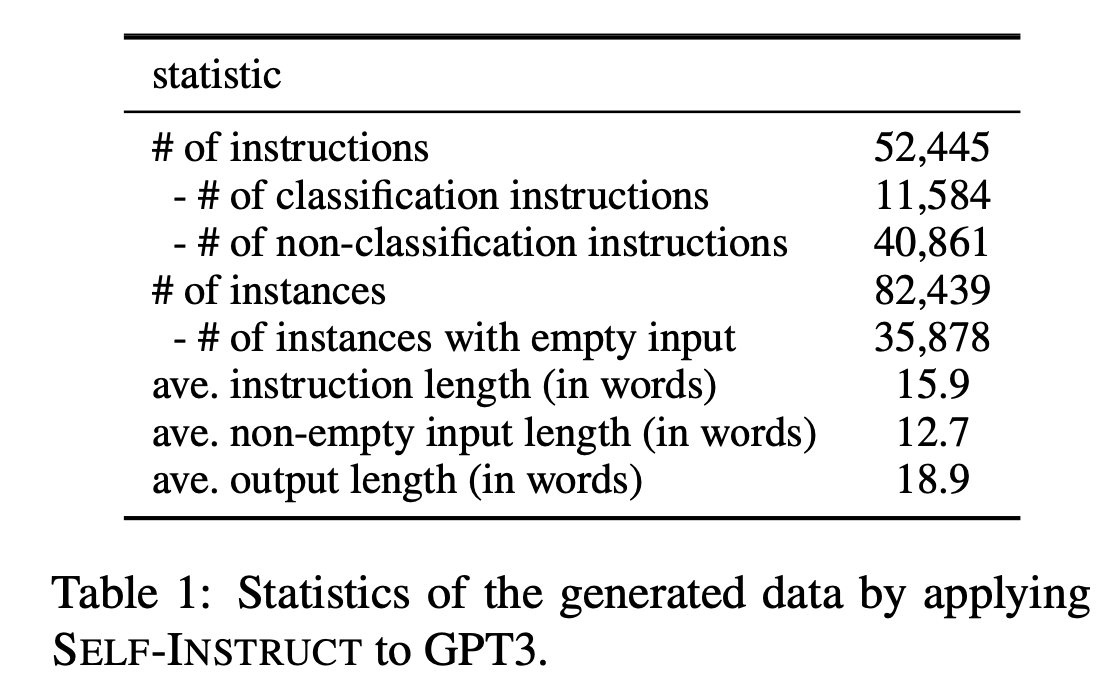
- 数量GPT3的数据量级:52k个Instruction数据,82k个实例。
4 生成的数据的多样性

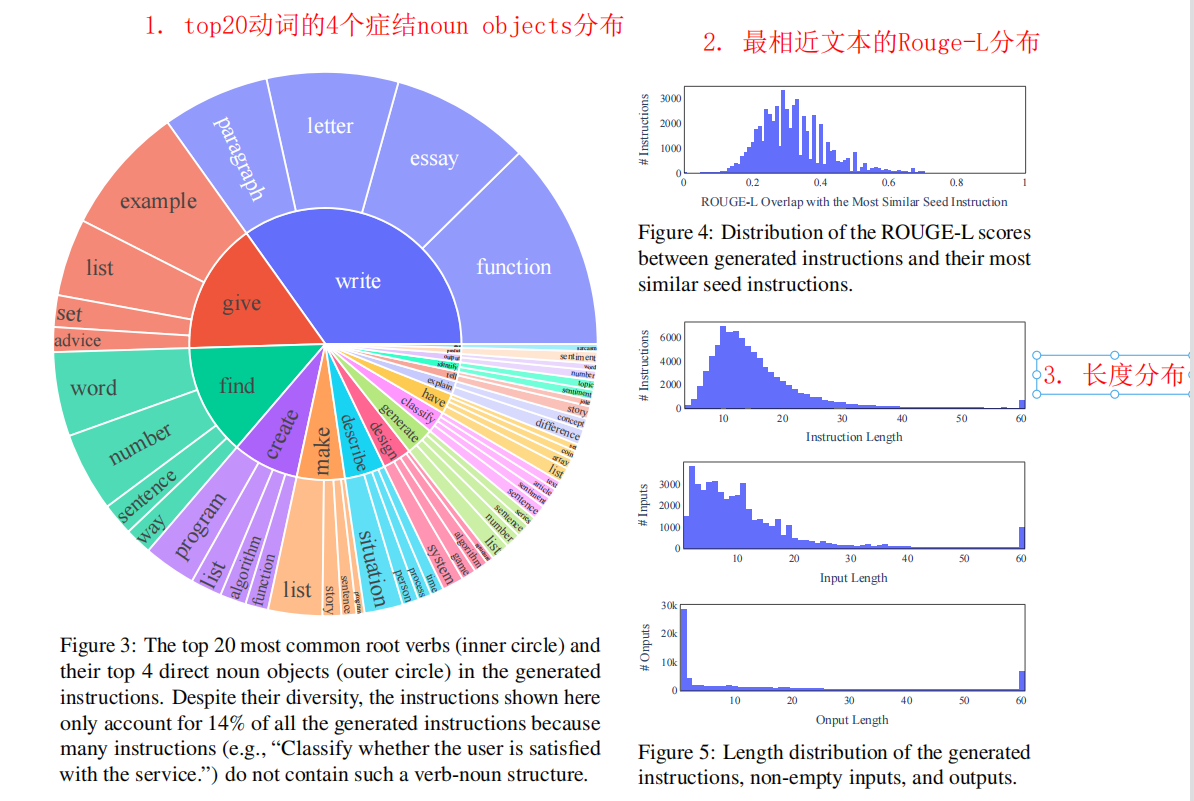
- 评估方法1:挑选top20最常见的动词,然后画出其top4的直接noun object分布,衡量整体的数据分布。
- 评估方法2:画出与种子数据中,最相近文本的Rouge-L的分布,衡量与种子数据的分布差异。
- 结论:发现多样性还不错,这也是生成的数据能让模型学会通用的指令遵循的原因之一。
5 生成数据的质量
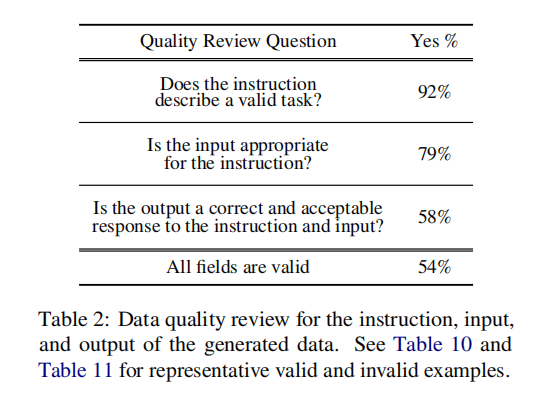
- 统计指标:随机挑选200个指令,每个指令随机挑选一个实例来标注
-
- 指令有效率:92%
- input与指令一致:79%
- output正确(能很好的响应Instruction和input的要求):58%
- 各个场景都有效:54%
- 总结:尽管生成的数据还是包含误差,但是大多数还是正确的,可以提供有用的指导,让模型能学会遵循人类指令。
三、个人总结
- 相当于验证了少量种子数据 + 原始预训练模型 => 生成大批量 多样性 + 质量还不错的 指令数据的可行性 => 好处是可以极大降低指令遵循数据集构建的成本。
- 这篇文章解释了为什么大模型能听懂人类指令的困惑,可以看出,原始的GPT-3模型学习了非常多的知识,但是人类指令遵循的能力非常非常差,通过self-instruct构造大量的多样、高质量的指令数据和答案,模型就开始能听懂指令,理解这个指令的具体含义,并给出人类期望的respond响应。其中指令的【多样性】和回复的【质量】是非常关键的两个因素。
- 对于如何对齐人类的价值观:可以参考复旦moss模型【参考资源1】,也是构造了非常多的对人类无害的种子数据,然后利用模型生成非常多的指令遵循数据,让模型尽可能的生成无害的结果,从另一个角度看,如果不法份子诱导模型去生成暴力倾向等不符合人类期望的答案,那么可能会训练出毒性非常大的模型,这也是非常恐怖的,难怪微软的文章说原始的gpt-3.5系列可能具备更强的能力,说明OpenAI在这方面做了非常强的约束。也难怪OpenAI强烈建议对大模型进行监管。
- 最近的OpenAI state of GPT的分享【参考资源2】,也提到原始next word predict训练的预训练摸LM擅长构建类似的问题,而不善于遵循人类指令生成回复,这个预训练阶段的任务也是Match的,同时本文利用其擅长构建类似问题的特点来构建更多的指令数据,也比较符合常理。

四、参考资源
- 复旦团队大模型 MOSS 开源了,有哪些技术亮点值得关注? - 孙天祥的回答 - 知乎 https://www.zhihu.com/question/596908242/answer/2994534005
- https://karpathy.ai/stateofgpt.pdf
欢迎大家关注我的微信公众号,时刻掌握第一手论文更新消息!