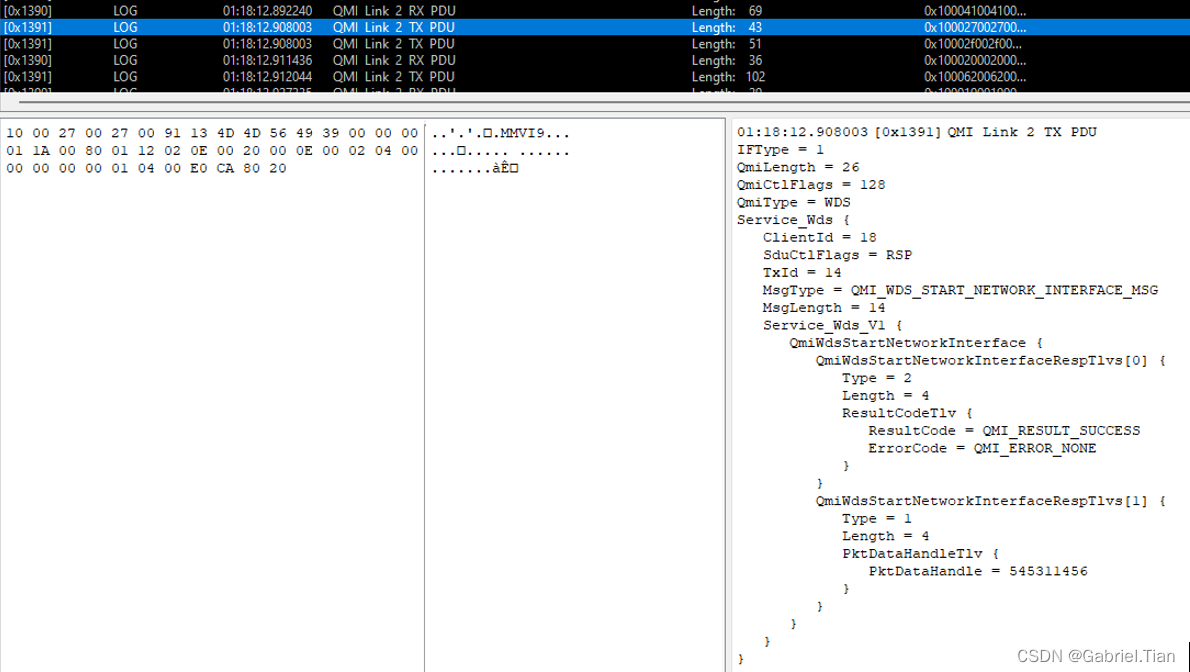
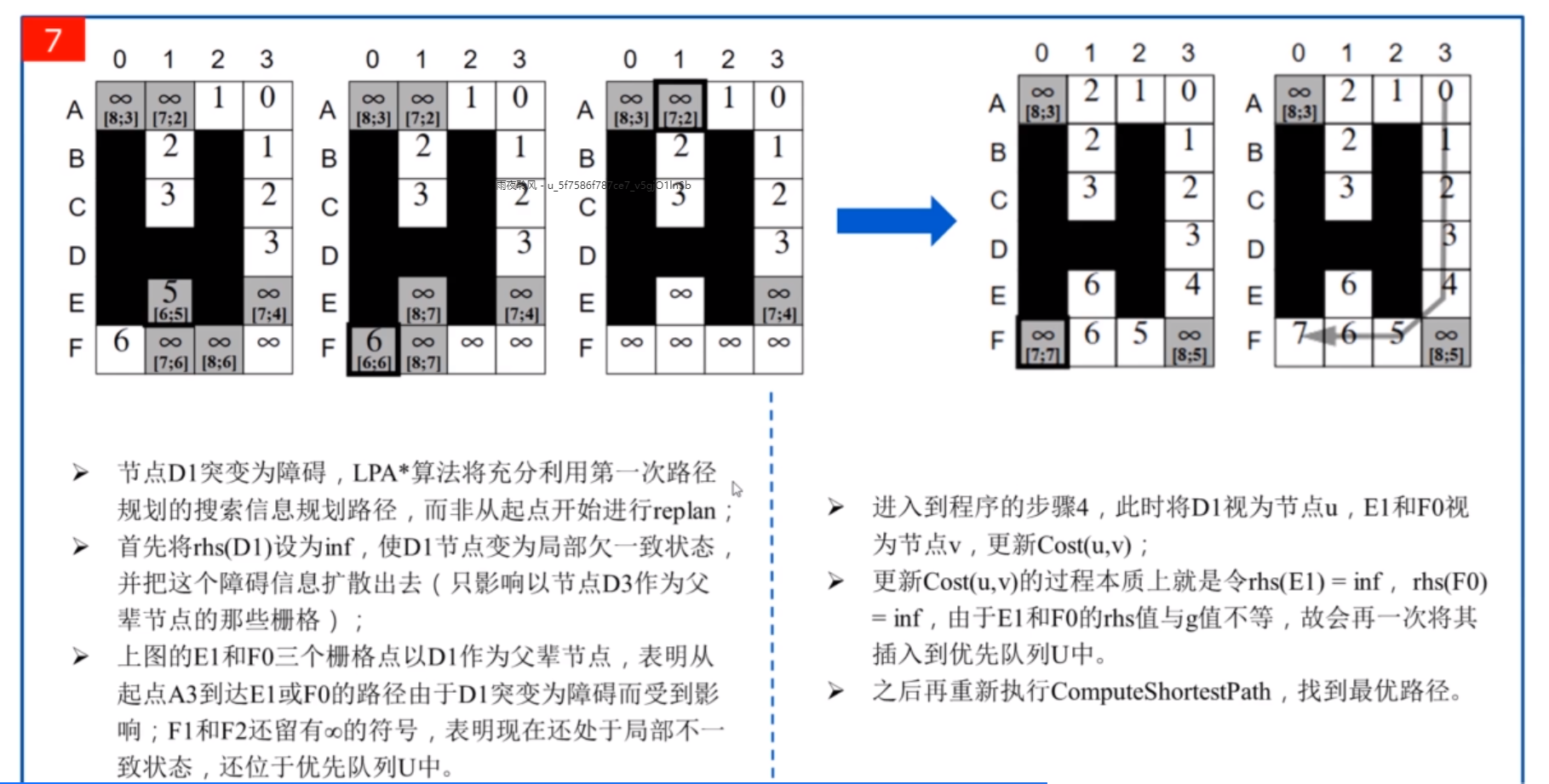
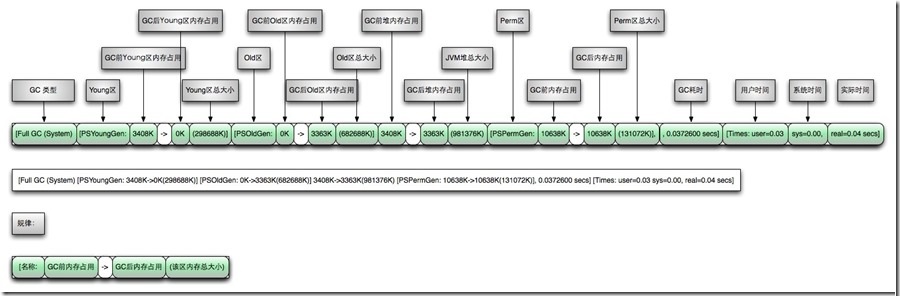
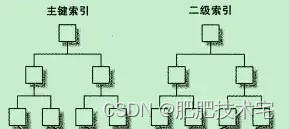
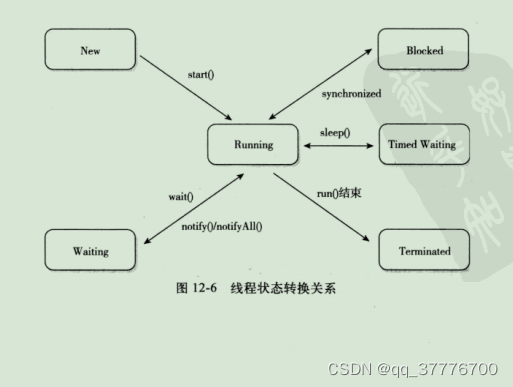
文件系统实现
- 🏞️1. 整体组织
- 🌁2. 文件组织:inode
- 🌠3. 多级索引
- 📖3.1 间接指针
- 📖3.2 多重间接指针
- 📖3.3 基于范围的方法
- 🌌4. 目录组织
- ⛺5. 空闲空间管理
- 🌿6. 读取和写入文件
- 📖6.1 读取文件
- 📖6.2 写入文件
- 🍁7. 缓冲和缓存
- 🏜️8. 理解静态划分与动态划分
🏞️1. 整体组织
我们想要了解文件系统在磁盘上的数据结构的整体组织,首先需要将磁盘分成块(block). 简单的文件系统只使用一种块大小,我们选择常用的4KB.
因此,我们对构建文件系统的磁盘分区看法很简单:一系列块,每块大小为4KB,在大小为N个4KB块的分区中,这些块的地址为0~N-1,假设我们有一个非常小的磁盘,只有64块:
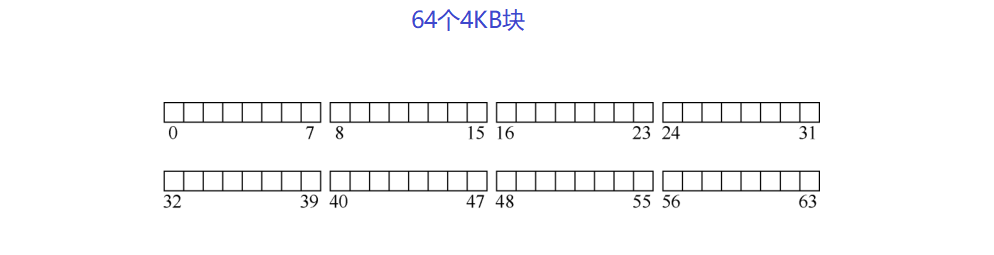
那么我们需要在这些块中存储什么呢?
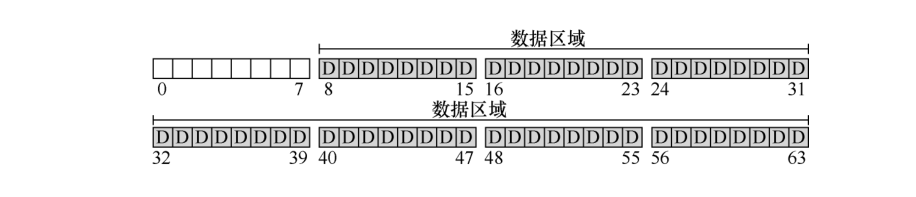
首先需要存储用户数据,任何文件系统大多数的空间都是用户数据,我们将用于存放用户数据的块称为数据区域,所以我们将上述磁盘中的56个块用来存放用户数据:
文件系统还必须记录每个文件的信息,该信息是元数据的关键部分,记录着诸如文件中包含哪些数据块、文件的大小、其所有者和访问权限、访问和修改时间以及其他类似信息的事情. 为了存储这些信息,文件系统通常有一个名为inode的结构.
为了存放inode,我们还需要在磁盘上留出一些空间,我们将这部分的磁盘称为inode表. 它保存了一个磁盘上inode的数组,现在,我们将磁盘区域中的5块用于inode:
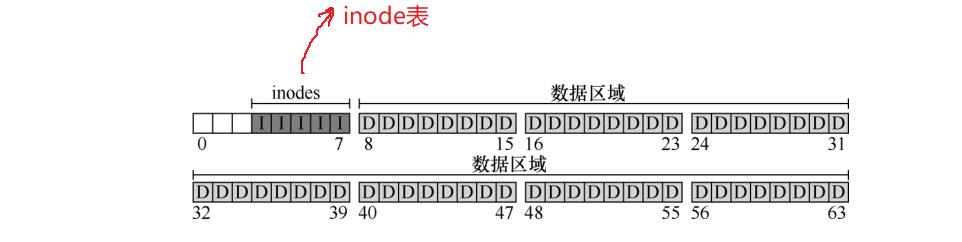
inode通常没有那么大,假设每个inode大小为256字节,一个4KB的块可以容纳16个inode,所以我们上面的文件系统包含了80个inode.
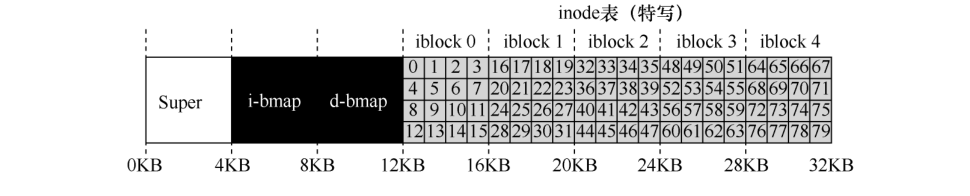
我们还需要某种方法来记录inode或数据块是空闲还是已分配,因此,我们选择一种简单而流行的结构:位图. 一种用于数据区域(data bitmap),另一种用于inode表(inode bitmap).
位图中的每个位用于指示相应的对象/块是空闲还是正在使用,因此新的磁盘布局如下,包含inode位图(i)和数据位图(d):

在这个简单的磁盘结构设计中,还有一块,我们将它留给超级块(superblock),用S表示,超级块包含关于该特定文件系统的信息,例如文件系统中有多少个inode和数据块,inode表的起始位置等等.
在挂载文件系统时,操作系统首先将读取超级块,初始化各种参数.
🌁2. 文件组织:inode
文件系统最重要的磁盘结构之一是inode,几乎所有的文件系统都有类似的结构. 名称inode是index inode.
每个inode都有一个数字隐式引用(number),我们称之为文件的低级名称. 在一个文件系统中,给定一个number,能够直接计算磁盘上相应节点的位置.
例如,上述文件系统的inode表:大小为20KB(5个4KB块),因此由80个inode(每个256字节)组成,假设inode区域从12KB开始(即超级块从0KB开始,inode位图在4KB地址,数据位图在8KB),inode表紧随其后,因此,我们为文件系统分区的开头提供了以下布局:
要读取inode号32,文件系统首先会计算inode区域的偏移量(32 * inode的大小),再将它加上磁盘的起始地址(12KB),从而得到inode块的地址:20KB.
但磁盘不是按字节寻址的,而是由大量的可寻址扇区组成,通常为512字节,因此为了获取包含索引节点32的索引节点块,inode块的扇区地址可计算如下:
sector = inumber * sizeof(inode_t) + BaseAddr / sectorSize
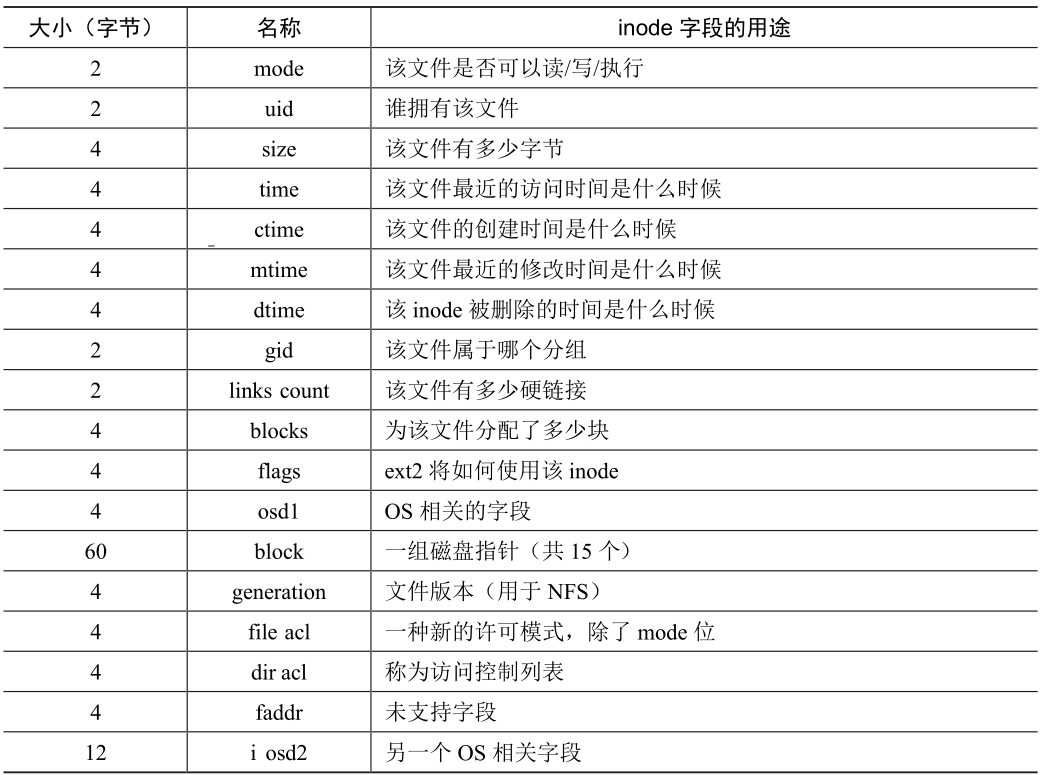
在每个inode中,实际上是所有关于文件的信息:文件类型(普通文件、目录等)、大小、分配给它的块数、保护信息(谁拥有文件以及谁可以访问它)、一些时间信息(包括文件创建、修改或上次访问的时间)、以及有关其数据块驻留在磁盘上的位置信息,我们将所有关于文件的信息称为元数据.
在设计inode时,最重要的是它如何引用数据块的位置,一种简单的方法是在inode中有一个或多个直接指针(磁盘地址). 每个指针指向属于该文件的一个磁盘块.
下表所示的是ext2的inode的例子:
🌠3. 多级索引
📖3.1 间接指针
为了支持更大的文件,文件系统必须在inode中引入不同的结构,一个常见的思路是加入一个称为间接指针的特殊指针. 它不是指向包含用户数据的块,而是指向包含更多指针的块,每个指针指向用户数据. 因此,inode有一些固定数量的直接指针和一个间接指针.
如果文件变得足够大,则会在磁盘的数据块区域分配一个间接块,并将inode的间接指针指向它.
假设一个块为4KB,磁盘地址是4字节,所以就增加了1024个指针,文件的大小可以为(12 + 1024)* 4KB,即4144KB.
📖3.2 多重间接指针
如果我们希望支持更大的文件呢?
只需要添加另一个指向inode的指针:双重间接指针,该指针指向的是一个包含间接块指针的块,每个间接块都包含指向数据块的指针.
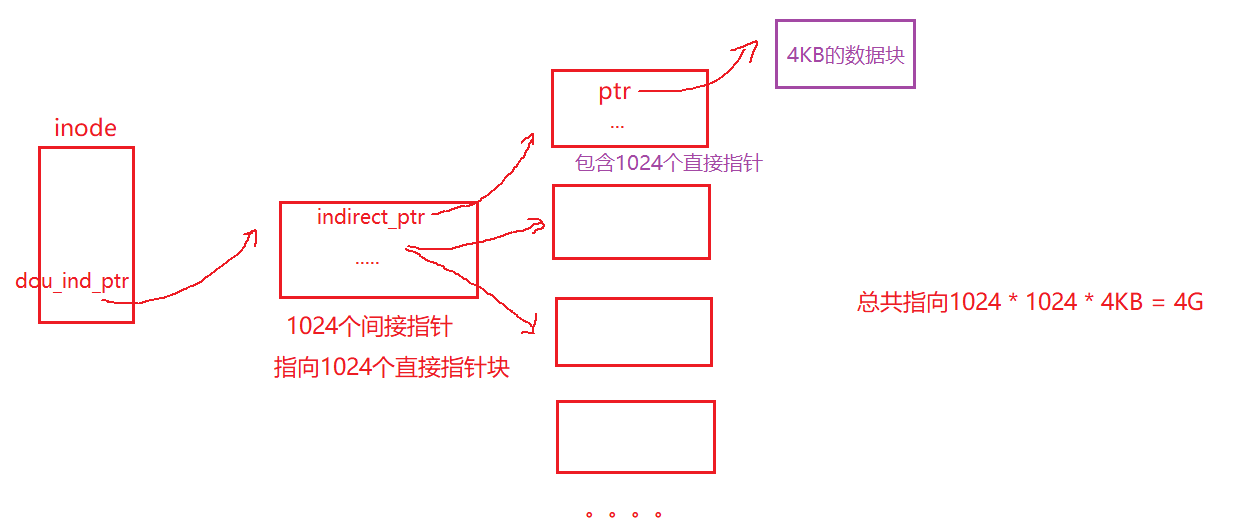
这种不平衡树被称为指向文件块的多级索引方法,我们来看一个例子:它有12个直接指针,以及一个间接指针和一个双重间接指针,假设块大小为4KB,并且指针为4字节,则该结构可以容纳一个刚好超过4GB的文件,即(12 + 1024 + 1024^2)* 4KB.
📖3.3 基于范围的方法
另一种方法是使用范围而不是指针,范围就是一个磁盘指针加一个长度(以块为单位),因此,不需要指向文件的每个块的指针,只需要指针和长度来指定文件的磁盘位置. 只有一个范围是有局限的,因为分配文件时可能无法找到连续的磁盘可用空间块. 所以,基于范围的文件系统通常允许多个范围,从而在文件分配期间给予文件系统更多的自由.
🌌4. 目录组织
目录的组织很简单,一个目录基本上只包含一个二元组(条目名称,inode号)的列表,对于给定目录中的每个目录或文件,目录的数据块中都有一个字符串和一个数字.
例如,假设目录dir(inode号是5)中有个文件(foo、bar和foobar),它们的inode号分别为12、13和24,dir在磁盘上的数据可能如下:

删除一个文件(例如调用unlink())会在目录中间留下一段空白空间,因此应该有一些方法来标记它(用一个保留的inode号,比如0),这种删除是我们需要记录长度的一个原因:
新的条目可能会重复使用旧的、更大的条目,从而在其中留有额外的空间.
⛺5. 空闲空间管理
文件系统还必须记录哪些inode和数据块是空闲的,这样在分配新文件或目录时,就可以为它找到空间,因此,空闲空间管理对于所有文件系统都很重要,我们使用两个简单的位图来完成这个任务:
例如,当我们创建一个文件时,我们必须为该文件分配一个inode,文件系统将通过位图搜索一个空闲的内容,并将其分配给该文件,并将inode标记为已使用,接着更新磁盘上的位图.
🌿6. 读取和写入文件
📖6.1 读取文件
当你发出一个open("/foo/bar", O_RDONLY)调用时,文件系统首先需要找到文件bar的inode,从而获取关于该文件的一些基本信息(权限信息、文件大小等),因此,文件系统必须找到inode,通过遍历路径名,从而找到所需的inode.

📖6.2 写入文件
与读取不同,写入文件可能会分配一个块,当写入一个新文件时,每次写入操作不仅需要将数据写入磁盘,还必须首先决定将哪个块分配给文件,从而相应的更新磁盘的其他结构(例如数据位图和inode),因此,每次写入文件在逻辑上会导致IO:读取数据位图,写入位图,写入inode,最后写入数据块.

🍁7. 缓冲和缓存
读取和写入文件是非常昂贵的,会导致磁盘的许多IO,这会对性能造成较大影响,所以大多数文件系统使用系统内存(DRAM)来缓存重要的块.
现代系统采用动态划分方法,将虚拟内存页面和文件系统页面集成到统一页面缓存中,可以在虚拟内存和文件系统之间更灵活的分配内存,具体取决于给定时间哪个对内存的需求量更大.
但是这种缓存对写入操作并没有优化,因为写入操作必须最终写入磁盘,所以需要用写缓冲解决:
通过延迟写入,文件系统可以将一些更新编成一批,放入一组IO中,例如,在创建一个文件时,inode位图被更新,稍后在创建另一个文件时又被更新,则文件系统会在第一次更新后延迟写入,从而节省一次IO,通过将一些写入缓冲在内存中,系统可以调度后续的IO,从而提高性能.
还有一些写入甚至可以使用延迟来完全避免,例如,如果应用程序创建文件并将其删除,则将文件创建延迟写入磁盘,可以完全避免写入.
🏜️8. 理解静态划分与动态划分
在不同 客户端/用户 之间划分资源时,可以使用静态划分或动态划分.
静态方法简单的将资源一次分成固定的比例. 例如,如果有两个可能的内存用户,则可以给一个用户固定的内存部分,其余的则分配给另一个用户.
动态方法更灵活,随着时间的推移提供不同数量的资源. 例如:一个用户可能会在一段时间内获得更高的磁盘带宽百分比,之后,系统可能会切换,决定为不同的用户提供更大比例的可用磁盘带宽.
每种方法都有其各自的优点:
静态方法优点:静态划分可确保每个用户共享一些资源,通常提供更可预测的性能,也更易实现.
动态方法优点:动态划分可以实现更好的利用率(让资源匮乏的用户占用其他空闲资源),但实现起来可能会更复杂,并且可能导致空闲资源被其他用户占用,然后在需要时花费很长时间收回,从而导致这些用户性能变差.