文章目录
- 关注和取关
- 查看其他用户界面及共同关注
- 关注推送
关注和取关
因为关注用户的时候可能涉及到共同关注的对象,所以需要利用到交集,而在Redis中可以使用交集的,是Set以及ZSet数据结构,但是显然这里并不需要排序,所以Set已经满足了我们的需求。所以对于每一个用户来说,都需要维护一个Set,用来保存这个用户关注的人的id。
如果进行的关注,那么这时候需要将两者添加到tb_follow数据库表中,同时将被关注的用户id添加到当前的用户对应的Set中,否则如果进行的是取关操作,那么就需要删除数据库表中对应的记录,同时需要将被关注的用户id从当前用户对应的Set中删除。
那么我们将如何判断是进行的关注操作还是取关操作呢?如下所示:
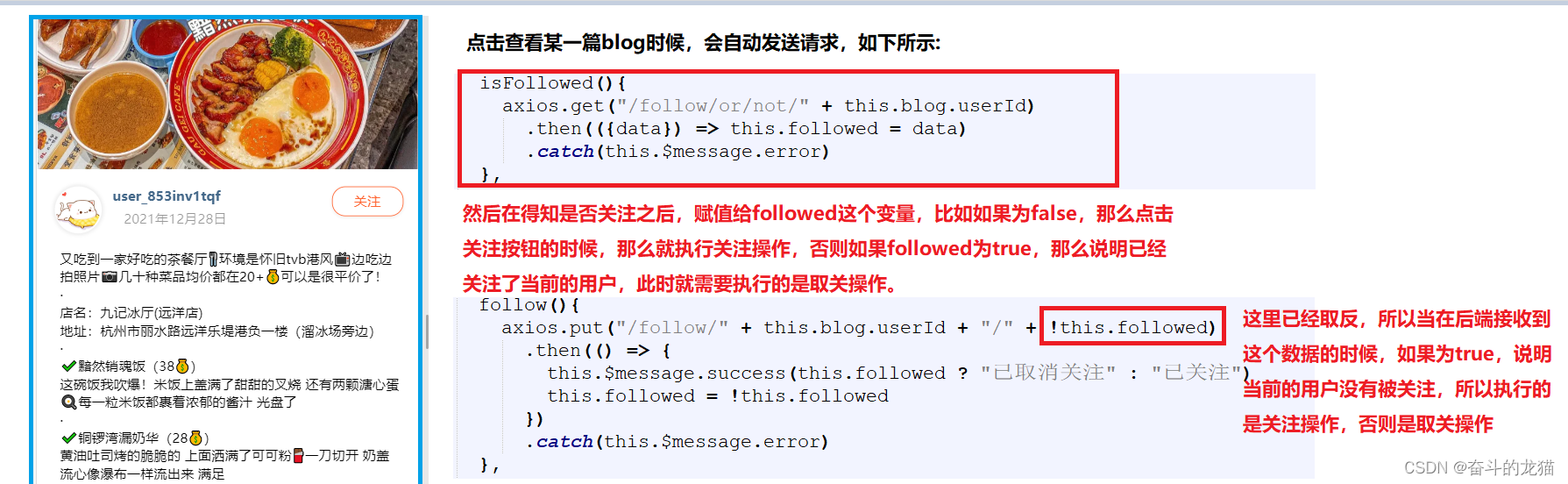
所以我们需要给这个关注接口传递参数,从而判断执行的是关注操作还是取关操作,对应的代码:
/**
* 当前用户关注/取关followerUser
* @param followerUserId
* @param isFollowed
* @return
*/
@Override
public Result follow(Long followerUserId, Boolean isFollowed) {
//1、获取当前用户的id
Long userId = UserHolder.getUser().getId();
//2、判断isFollowed的值,从而判断是关注还是取关
String user_key = RedisConstants.FOLLOW_USER_KEY + userId;
if(isFollowed){
//2.1 关注followerUser,那么将这一条数据插入到数据库tb_follower中
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followerUserId);
boolean isSuccess = save(follow);
if(isSuccess){
//将followerUserId添加到当前的用户的set中,来统计当前用户关注的人
stringRedisTemplate.opsForSet().add(user_key, followerUserId.toString());
}
}else{
//2.2 取关followerUser,那么将这一条数据删除
boolean isSuccess = remove(new LambdaQueryWrapper<Follow>().eq(Follow::getUserId, userId).eq(Follow::getFollowUserId, followerUserId));
if(isSuccess){
//将followerUserId从当前用户关注的set中删除
stringRedisTemplate.opsForSet().remove(user_key, followerUserId.toString());
}
}
return Result.ok();
}
判断当前blog的作者是否被当前的用户关注,那么只需要判断被关注的用户id是否存在于当前用户对应的Set中即可,所以对应的接口代码为:
//判断当前的用户是否已经关注了followUserId这个用户
@Override
public Result followOrNot(Long followUserId) {
UserDTO user = UserHolder.getUser();
if(user == null){
//1、用户没有登录,那么默认是没有关注
return Result.ok(false);
}
Long userId = user.getId();
//获取当前用户关注的set的key
String user_key = RedisConstants.FOLLOW_USER_KEY + userId;
Boolean isMember = stringRedisTemplate.opsForSet().isMember(user_key, followUserId.toString());
return Result.ok(BooleanUtil.isTrue(isMember));
}
查看其他用户界面及共同关注
如果我们点击查看某一篇blog,突然对这个博主写的内容感兴趣,那么就会点击这个作者,此时我们就会来到其他用户的界面,那么对应的步骤如下所示:
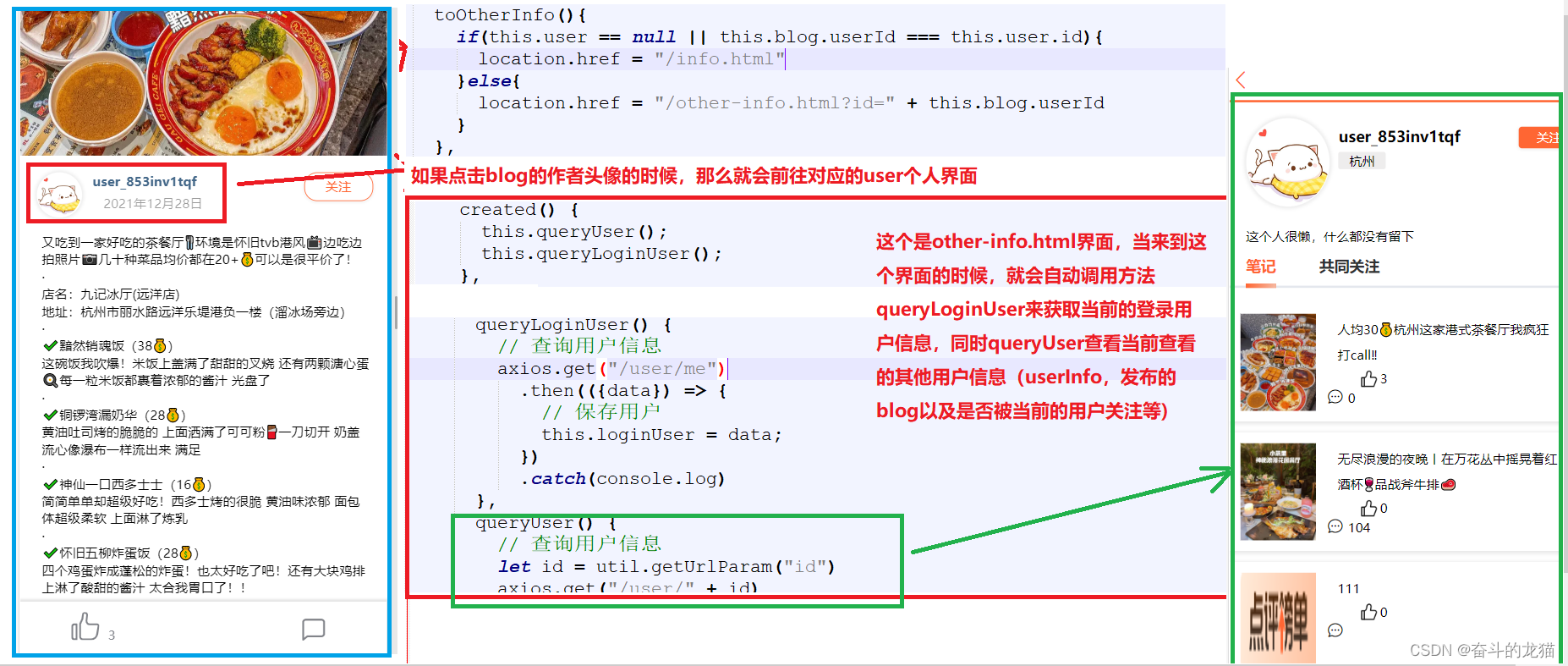
所以根据这个步骤,需要在UserController中添加API接口,用于获取其他用户的信息,所以对应的代码为:
根据userId来获取用户信息:
//根据userId来获取这个id对应的用户的基本信息
@GetMapping("/{userId}")
public Result queryById(@PathVariable("userId")Long userId){
return userService.queryUserDTOById(userId);
}
根据userId来获取userInfo信息,例如粉丝数量,用户的简介,点赞数等,对应的代码为:
@GetMapping("/info/{id}")
public Result info(@PathVariable("id") Long userId){
// 查询详情
UserInfo info = userInfoService.getById(userId);
if (info == null) {
// 没有详情,应该是第一次查看详情
return Result.ok();
}
info.setCreateTime(null);
info.setUpdateTime(null);
// 返回
return Result.ok(info);
}
根据userId,来获取这个用户写的所有blog,所以blogController需要添加新的API接口,对应的代码为:
/**
* 当进入其他用户的主页的时候,需要获取其他用户的博客
* @param userId
* @param current
* @return
*/
@GetMapping("/of/user")
public Result queryByUser(@RequestParam("id") Long userId, @RequestParam(value = "current", defaultValue = "1") Long current){
return blogService.queryByUser(userId, current);
}
而BlogService接口提供的API接口为queryByUser,对应的实现类重写的方法代码为:
/**
* 获取userId中的第current页的笔记
* @param userId
* @param current
* @return
*/
@Override
public Result queryByUser(Long userId, Long current) {
Page<Blog> page = query().eq("user_id", userId) //获取当前用户的博客
//根据点赞数降序排序
.orderByDesc("liked")
//获取第current页的记录,并且每一页有MAX_PAGE_SIZE条
.page(new Page<Blog>(current, SystemConstants.MAX_PAGE_SIZE));
//将page页的博客通过getRecords方法获取出来
List<Blog> records = page.getRecords();
records.forEach(blog -> {
this.isLikeByCurrentUser(blog);
this.queryBlogUser(blog);
});
return Result.ok(records);
}
而如果来到我的界面的时候,同样获取对应的信息,只是这时候相对于前者来到其他用户界面的时候,少了queryLoginUser方法,而是直接调用queryUser,对应的代码如下所示:
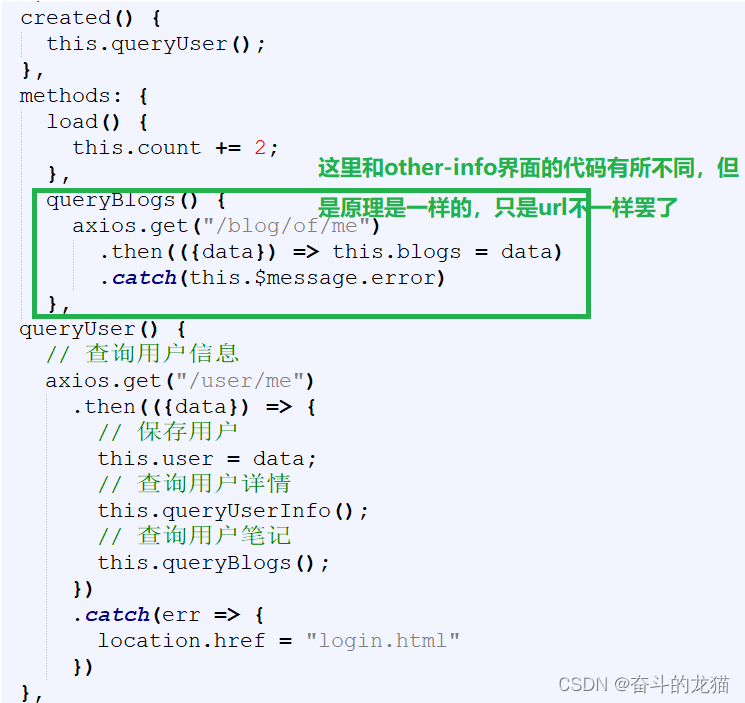
所以我们需要在BlogController中添加API接口,用于获取当前登录用户的blog,对应的代码为:
//获取当前登录用户的第current页的blog
@GetMapping("/of/me")
public Result queryMyBlog(@RequestParam(value = "current", defaultValue = "1") Integer current) {
return blogService.queryMyBlog(current);
}
对应的BlogService对应的API接口以及子类重写的方法:
//BlogService接口中的方法
Result queryMyBlog(Integer current);
//BlogServiceImpl重写的方法
@Override
public Result queryMyBlog(Integer current) {
// 获取登录用户
UserDTO userDTO = UserHolder.getUser();
// 根据用户查询
Page<Blog> page = query()
.eq("user_id", userDTO.getId()).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
records.forEach(blog -> {
this.isLikeByCurrentUser(blog);
this.queryBlogUser(blog);
});
return Result.ok(records);
}
当我们来到其他的用户界面的时候,我们需要获取它和当前用户共同关注的人的时候,那么这时候我们将分别获取两者的Set(保存的是关注的用户Id),然后获取两者的交集就是共同关注的用户Id,然后将遍历这些用户Id,获取这些用户的基本信息在返回给前端,对应的代码为:
对应FollowController提供的API接口代码为:
/**
* 获取当前的用户和otherUserId的共同关注的人
* @param otherUserId
* @return
*/
@GetMapping("/common/{otherUserId}")
public Result queryCommonFollow(@PathVariable("otherUserId")Long otherUserId){
return followService.queryCommonFollow(otherUserId);
}
对应的FollowService接口以及子类重写的代码为:
/**
* 获取当前用户和otherUserId的共同关注对象
* @param otherUserId
* @return
*/
@Override
public Result queryCommonFollow(Long otherUserId) {
Long userId = UserHolder.getUser().getId();
String current_user_key = RedisConstants.FOLLOW_USER_KEY + userId;
String other_user_key = RedisConstants.FOLLOW_USER_KEY + otherUserId;
//获取当前用户和otherUserId共同关注的用户id
List<Long> userIds = stringRedisTemplate.opsForSet().intersect(current_user_key, other_user_key)
.stream()
.map(Long::valueOf)
.collect(Collectors.toList());
if(userIds == null || userIds.isEmpty()){
return Result.ok(Collections.emptyList());
}
//获取共同关注的UserDTO
List<UserDTO> userDTO = userService.listByIds(userIds)
.stream()
.map(user -> {
return BeanUtil.copyProperties(user, UserDTO.class, "false");
})
.collect(Collectors.toList());
return Result.ok(userDTO);
}
之所以返回共同的用户ID之后,还需要查询UserDTO,因为我们总不能仅仅返回共同关注的UserId吧,至少得需要知道共同关注得用户Nickname吧,因此返回的是UserDTO。
关注推送
如果我们关注了某一个用户的时候,那么当被关注的人如果发布了新的blog,那么就需要将新的blog推送给它的粉丝,此时就需要利用到了Feed流来实现推送。
而Feed流产品有2中模式:
- Timeline: 不会对内容进行筛选,而是简单按照发布时间升序排序,通常用于好友或者关注
- 智能排序: 利用智能算法屏蔽违规,不感兴趣的内容。
而当前的项目中则采用Timeline模式来实现Feed流推送,实现关注推送,其中Timeline同样存在3中方案,如下所示:
- 拉模式: 也称为读扩散,当被关注的用户一旦发布了blog,那么会将blog保存到发布者这边,只有粉丝点击关注的人,才会拉取关注者的blog。显然,每次都需要粉丝来去关注者的blog,耗时。
- 推模式:也成为写扩散,当被关注的用户一旦发布了blog,就会主动推送到粉丝的收件箱,那么这时候当粉丝需要查看的时候,就可以直接从自己的收件箱中获取,从而节省了时间。但是这时候就会出现一个问题,如果被关注者有很多的粉丝,那么这时候就会导致需要将一篇blog复制成多篇,才可以推送给粉丝,从而导致内存占用的问题。
- 推拉结合:也叫读写混合,兼具了拉和推模式的优点。
在这次的项目中采用的是推模式来实现Feed流推送,此时就需要保证每个用户都有一个收件箱,用来保存关注者推送的blogId,当粉丝查看的时候,那么需要保证这些blog是根据发布时间排序的,那么这时候就需要保证有序。
此时Redis中可以利用List以及ZSet来保证有序,因为List可以实现队列这种数据结构,而ZSet则是拥有score属性,只要将时间戳的值作为score,那么就可以实现按照时间戳排序了。
但是如果采用的是Feed流推送的时候,采用的分页并不是传统给的分页模式,按照下标来获取的,如下所示:
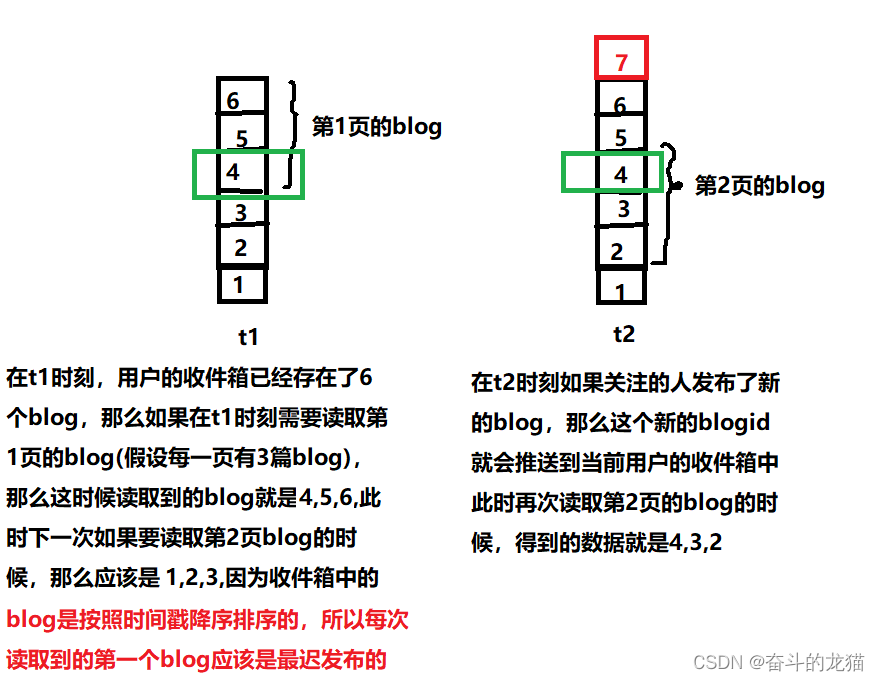
所以这时候可以知道,如果是按照传统的方式来进行分页(也即根据起始下标来进行分页),那么就会导致查询到的记录有重复的情况(即不同的页有重复的blog)。
所以这时候并不会采用List这种数据结构作为用户的收件箱(List只能根据起始下标来实现分页),但是ZSet是否可以呢?答案是肯定的,因为ZSet除了可以根据下标来获取元素之后,还可以获取score范围的元素,即通过命令zrangebyscore来获得,因此这里就可以利用score(时间戳)来实现滚动分页,避免每页存在重复blog的情况。
但是这里需要根据时间戳降序排序的,因此应该利用的命令是zrevrangebyscore.此外由于采用的是zrevrangebyscore,那么我们就需要考虑到score的范围应该设置多少才可以获取到对应页的blog。
如果是第1次来查询的时候,那么score的最大值应该是当前的时间戳,最小值为0,下一次再来查询的时候,那么score的最大值就是上一次查询记录的最小值,最小值依旧是0, 所以我们除了获取元素值之外,还需要的值对应的score属性的值,因此命令再次改为使用zrevrangebyscorewithscore.
上面仅仅实现了获取某一个score范围的元素,并没有实现分页,这时候我们同样可以通过limit offset count来实现分页,其中的offset表示起始下标, count表示获取条目。此时我们就需要考虑offset的值应该如何设置。
如果是第1次查询,那么offset应该是0,表示从第1条记录开始查询,否则,如果不是第1次查询,那么offset应该是上一次查询记录中的最小score出现次数。
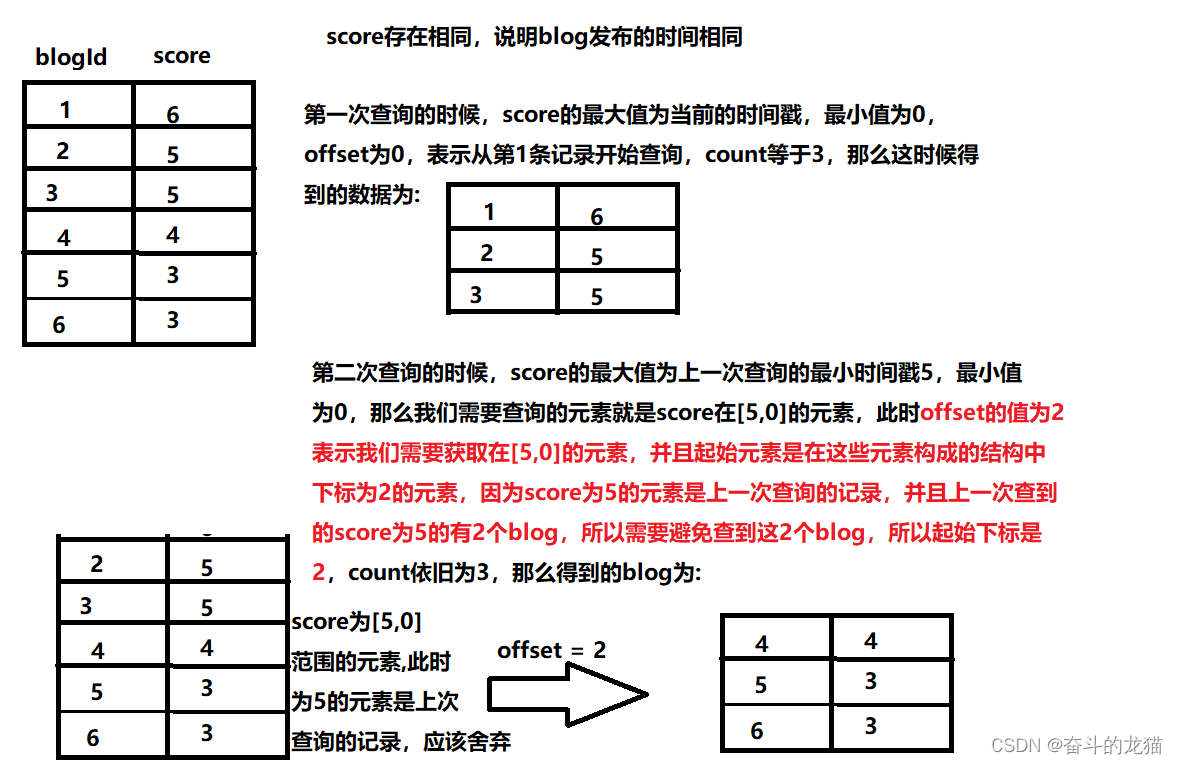
所以利用ZSet来实现滚动分页查询的命令就是zrevrangebyscorewithscore key max min limit offset count,其中max的初始值为当前的时间戳(用于第1次查询),下次再查询的时候,值为上一次查询中的最小时间戳, min固定为0; offset表示起始下标,那么第1次查询时offset值为0,下一次再来查询的时候offset的值为上一次查询的最小时间戳出现的次数, count表示每页的blog数量。因此我们只需要关注max以及offset即可。
所以利用Feed流来实现关注推送,以及查看关注者的blog代码为:
发布blog的时候,需要将blogId推送到粉丝的收件箱中:
//发布blog,并将blog推送给粉丝
@Override
public Result saveBlog(Blog blog) {
// 1、获取登录用户
UserDTO user = UserHolder.getUser();
Long userId = user.getId();
blog.setUserId(userId);
// 2、保存探店博文
Boolean isSuccess = save(blog);
if(BooleanUtil.isFalse(isSuccess)){
return Result.fail("发布blog失败");
}
// 3、将blog推送给粉丝
// 3. 1 查询数据库,从而获取当前用户的所有粉丝
List<Follow> follows = followService.query().eq("follow_user_id", userId).list();
// 3. 2 获取所有的follow中的userId,就是粉丝的id,然后分别推送到粉丝id中的收件箱中
//并且是根据发布的时间降序排序的
for(Follow follow : follows){
stringRedisTemplate.opsForZSet().add(RedisConstants.FEED_KEY + follow.getUserId(), blog.getId().toString(), System.currentTimeMillis());
}
// 4、返回id
return Result.ok(blog.getId());
}
当用户点击关注的时候,那么就会看到关注的人发布的blog,如下所示:
这时候需要实现滚动分页,在获取到分页的内容之后,需要将对应blog数据,最小时间戳以及最小时间戳出现的次数封装到ScrollResult这个实体中,然后再将其返回,之所以需要封装到这个实体,因为下次查询的时候需要利用到上次的记录,此时如果我们将数据封装到这个实体中,就可以从这个实体中获取上次的记录了,对应的代码为:
/**
* 实现滚动分页查询,从而获取关注者发布的blog
* @param offset
* @param lastId
* @return
*/
@Override
public Result queryOfFollow(Long offset, Long lastId) {
//1、获取当前的登陆用户
Long userId = UserHolder.getUser().getId();
//2、根据Feed流,进行滚动查询,其中是根据上一次查询到的记录后面的offset开始
//lastId就是上一次查询记录的时间戳
String key = RedisConstants.FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0,lastId, offset, 5L);
if(typedTuples == null || typedTuples.isEmpty()){
//2.1 数据为空
return Result.ok();
}
//3、解析数据,获取关注着的blogId,以及发布时间,然后统计记录中的最小时间戳以及出现的次数
//为下一次请求的时候,发送offset以及lastId
List<Long> blogIds = new ArrayList<>();
long minTime = 0L, time;
int count = 0;
for(ZSetOperations.TypedTuple<String> typedTuple : typedTuples){
//获取blogId
long blogId = Long.parseLong(typedTuple.getValue());
blogIds.add(blogId);
//获取时间戳,由于zset已经实现了降序,所以可以直接遍历,那么最后一个必然就是这一次查询
//中的最小时间戳
time = typedTuple.getScore().longValue();
if(time != minTime){
minTime = time;
count = 1;
}else{
++count;
}
}
//获取查询到的blog,但是需要根据Order BY FIELD (id, xxx, xxx)方式排序查询
//因为如果直接是listByIds,那么数据库根据in子句进行查询,此时查询到的数据不一定
//是和上面分页记录中的blogIds一致
String idStr = StrUtil.join(",", blogIds);
System.out.println("idStr = " + idStr);
List<Blog> blogs = query().in("id", blogIds)
.last("ORDER BY Field(id, " + idStr + " )").list();
//4、对每一个blog,都需要获取blog的作者,避免点击blog的时候,发现作者发生报错
//同时需要判断blog是否被当前的用户点赞了
blogs.forEach(blog -> {
isLikeByCurrentUser(blog);
queryBlogUser(blog);
});
//5、封装blogs,count以及minTime
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs);
scrollResult.setMinTime(minTime);
scrollResult.setOffset(count);
return Result.ok(scrollResult);
}
ScrollResult实体代码为:
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}