Python 中的 Raincloud 图
` 提示:一种强大的数据可视化方法,由小提琴图、散点图和箱线图的组合组成
提示:目录
Python 中的 Raincloud 图绘制
- Python 中的 Raincloud 图
- 前言
- 一、什么是 Raincloud 图?
- 二、使用步骤
- 1.加载数据集
- 2.读入数据
- 3.数据可视化
- 总结
前言
提示:大概内容:
上述每种可视化方法都有自己的优点和缺点。但是,如果我们可以将它们组合在一起并获得更强大的数据可视化技术,即Raincloud plots呢
提示:正文内容
一、什么是 Raincloud 图?
雨云图是一种更强大、更直观的数据可视化形式。正如我之前提到的,它们是多种方法的混合,这些方法放在一起可以很好地概述我们需要了解的关于数据集中观察的大多数统计数据和模式。
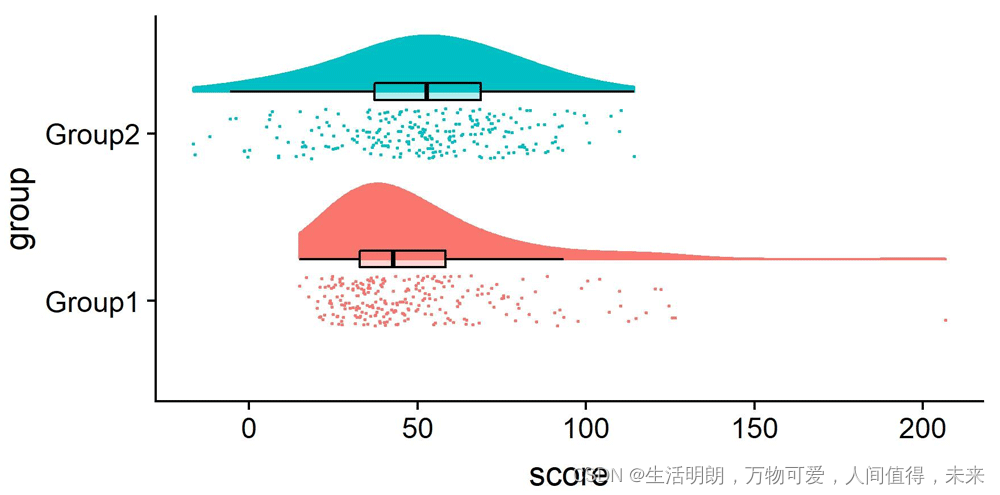
在本文中,我们将学习如何使用numpy和matplotlib库在 Python 中使用和实现此类绘图。
二、使用步骤
1.加载数据集
为了简单起见,对于这个例子,我们将在给定的值范围内生成两个随机分布。
让我们导入所需的库
代码如下(示例):
# 导入
import numpy as np
import matplotlib.pyplot as plt
2.读入数据
接下来,以下代码片段将为我们生成两个数字分布,稍后我们将使用它们在雨云图中可视化数据
# 生成 0-10 之间整数的随机分布作为第一个特征
x1 = np.random.choice([ 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ], p=[ 0.01 , 0.01 , 0.15 , 0.19 , 0.05 , 0.11 , 0.2 , 0.16 , 0.10 , 0.01 , 0.01 ], 尺寸=( 500 ))
# 在每个样本上应用随机噪声,这样它们就不会在散点图中的 x 轴上重叠
idxs = np.arange( len (x1))
out = x1.astype( float )
out.flat[idxs] += np. random.uniform(low=- 1 , high= 1 , size= len (idxs))
x1 = out
# 生成6-17之间整数的随机分布作为第二个特征
x2 = np.random.choice([ 6 , 7 , 8、9、10、11、12、13、14、15、16、17 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _], p=[ 0.01 , 0.01 , 0.15 , 0.23 , 0.14 , 0.06 , 0.05 , 0.10 , 0.12 , 0.11 , 0.01 , 0.01 ], size=( 500 ))
# 在每个样本上应用随机噪声,这样它们就不会重叠散点图中的 y 轴
idxs = np.arange( len (x2))
out = x2.astype( float )
out.flat[idxs] += np.random.uniform(low=- 1 , high= 1 , size = len (idxs))
x2 = 输出
# 在列表中组合特征
data_x = [x1, x2]
3.数据可视化
接下来,以下代码片段将为我们生成两个数字分布,稍后我们将使用它们在雨云图中可视化数据
fig, ax = plt.subplots(figsize=(8, 4))8 , 4 )) #根据
你拥有的特征数量为箱线图
创建颜色列表False ) # Change to the desired color and add transparency for patch, color in zip (bp[ 'boxes' ], boxplots_colors): patch.set_facecolor(color) patch.set_alpha( 0.4 ) # 创建小提琴图的颜色列表基于你拥有的特征数量violin_colors = [
'thistle' , 'orchid' ]
# Violinplot 数据
vp = ax.violinplot(data_x, points= 500 ,
showmeans= False , showextrema= False , showmedians= False , vert= False )
for idx, b in enumerate (vp[ 'bodies ' ]):
# 获取图的中心
m = np.mean(b.get_paths()[ 0 ].vertices[:, 0 ])
# 修改它以便我们只看到小提琴图的上半部分
b.get_paths ()[ 0 ].vertices[:, 1 ] = np.clip(b.get_paths()[0 ].vertices[:, 1 ], idx+ 1 , idx+ 2 )
# 更改为所需的颜色
b.set_color(violin_colors[idx])
# 根据你拥有的特征数量为散点图创建颜色列表
scatter_colors = [ 'tomato' , 'darksalmon' ] # idx的
散点图数据
,枚举中 的特征(data_x): # 添加抖动效果,使特征在 y 轴上不重叠 y = np.full( len (features), idx + .8 ) idxs = np.arange( len (y)) out = y.astype(
float )
out.flat[idxs] += np.random.uniform(low=- .05 , high= .05 , size= len (idxs))
y = out
plt.scatter(features, y, s= .3 , c=scatter_colors[idx])
plt.yticks(np.arange( 1 , 3 , 1 ), [ 'Feature 1' , 'Feature 2' ]) # 设置文本标签。
plt.xlabel( 'Values' )
plt.title( "雨云图" )
plt.show()
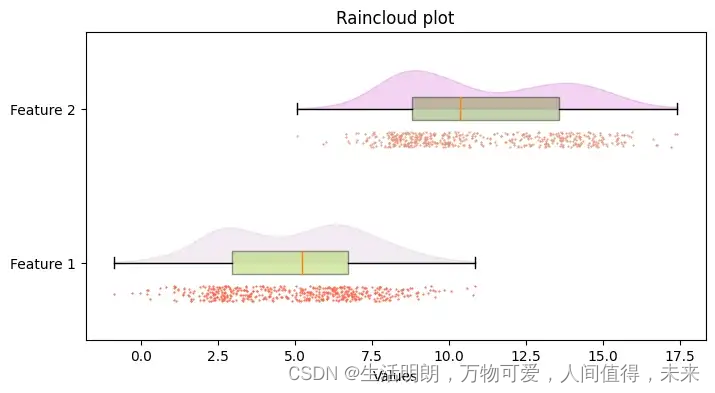
上述代码片段的结果将是以下结果:
总结
提示:总结:
如您所见,这为我们提供了在初始数据探索阶段我们需要了解的关于数据集的几乎所有信息。我们对总体分布、个体趋势、中位数、四分位数和异常值有一些见解。
此外,由于它非常直观,因此对于几乎没有或没有统计/数据科学背景的人来说,阅读起来会容易得多。
参考文献:
https://medium.com/mlearning-ai/getting-started-with-raincloud-plots-in-python-2ea5c2d01c11