文章目录
- 前言
- 一、图数据库区别于其他数据库的核心是什么?
- 二、图数据库能解决哪些问题?
- 1.图的优势
- 2.目前的图的实现方式及优劣
- 3.图的技术趋势及优势小结
- 总结
前言
《图数据库知识点》系列有20讲,每一讲中会重点分享一个图数据库知识点(好吧,其实每个知识点从图思维方式延展开来的话,都会关联很多其它的知识点,因此它其实是个知识的子图、子网)。通过把20个知识点串联起来,大家会对图数据库有个脉络化的理解。希望在阅读本系列的过程中大家可以get到新的知识,并能很好的在日常工作学习实践中做到举一反三、融会贯通,开启开挂的人生。
May the best graph be with you...
Before you start, ask yourself this: Am I graph-thinking?
一、图数据库区别于其他数据库的核心是什么?
这个问题也可能是:图数据库和其它NoSQL数据库、数仓的区别在哪里?图数据库和关系型数据库的差异是什么?等等。
回答这个问题的第一步是要问一个问题:关系型数据库(数仓、数湖)遇到了哪些问题?
关系型数据库、数仓或数湖遇到的问题可以总结为4大问题:
-
僵化、低维的建模能力:RDBMS与SQL不够灵活
-
低效:RDBMS与SQL不够快、时效性差
-
老化、黑盒:架构老化、可解释性差
-
短链:分布式RDBMS或数仓、数湖不擅长解决“长链”、复杂、深度查询等问题
这几个问题每个如果展开都很复杂、庞大,我们可以简单的归纳一下具体的问题:
-
传统数据库的基于二维关系表的数据建模模式本身就非常僵硬,难以简捷表达业务所需的多维关联关系。如果大家回忆ER模型图就会明白,本来ER图就是一种实体关系的关联模型,但是却要让高维的多实体关联关系模型被割裂到一张张的二维表中进行低维表达。这种模式本身就意味着一种降维操作而导致的低效性,以及对灵活性的抹杀!
-
采用SQL查询语言很难做到简捷地进行递归查询(例如下钻、穿透、归因、溯源分析、深度路径查询……), 关于这一点我们后续的知识点中会单独撰文剖析。
-
多表关联(join-table)可能会造成出现“笛卡尔积”问题,让SQL查询效率大幅下滑。每多一张表关联,SQL进程的处理时耗就会指数级增长。大量T+1类SQL存储进程出现的原因都源于多表关联!
-
关系型数据库RDBMS/SQL以存储引擎为中心,计算引擎是二等公民。而业务更多的时候需要更高的计算效率。尽管很多数仓都宣称对SQL查询可以进行加速,但是数仓加速的逻辑是基于更多的表(中间表、临时表)、更宽的表对数据进行了各种抽取、组合,在本质上并没有改变数据编织的低维性(二维表)。换言之,所有数仓可以完成的工作,Oracle都可以完成,而且通常会更快!如果大家对这一点有疑问,可以参考国内知名的某大厂孵化的分布式数据库的CTO在市场上鼓吹了很多年如何用分布式攻城拔寨去IOE后对外承认:在处理复杂查询时,依然与Oracle的性能相差较远……
-
数仓、数湖的现状是:数据一旦进入湖、仓,如同进入沼泽。面向业务的查询效率低下。
-
复杂查询可解释性差,大量SQL存储进程都具有类似的“黑盒”特征,维护成本高。试想动辄上万行的SQL代码,可维护性得有多差,可解释性一样的差。
-
另外,需要指出的是,分布式关系型数据库或数仓湖所(能)解决的是“短链”交易(例如秒杀)问题,无法解决金融场景中的“长链”交易、复杂查询的挑战。所谓短链,可以看作是面向元数据的,非常适用于分布式的写入和读取的场景,不涉及数据间的关联分析(下钻分析、归因分析、跨指标分析等)。而长链交易需要的是对分布式系统上的不同分片的数据之间不断的进行数据传输与依赖关系,这种数据处理模式是任何所谓的水平分布式系统所极不擅长的!换言之,同样的长链查询,集中式的系统会指数级快于水平分布式(指数级指的是10倍或者100倍以上)——关于这个知识点我们也会后续讨论。
二、图数据库能解决哪些问题?
对应上文中提到的关系型数据库、数仓湖所遇到的挑战,图数据库解决的主要问题、相对于其他数据库的优势如下:
-
灵活:支持高维建模(相对于SQL的二维表而言)、动态建模(schema可动态调整——并非所有的图数据库都可以实现该能力)。
-
快、高算力:高效的复杂查询与计算、多表关联查询(递归查询、深度下钻),动态、海量、复杂模型的实时计算与分析。
-
前所未有的能力:归因分析、溯源、溯因、反向追溯、正向模拟等类操作 (传统数据库因为多表关联造成的“笛卡尔积”的问题而无法实现快速归因分析!)。
-
白盒化、可解释:区别于传统的复杂SQL代码查询的黑盒化问题,以及深度学习、人工智能算法中常见的黑盒化、不可解释性等问题,图数据库中的查询、算法整体的特点是计算(查询)的结果基本上是确定性的,每一步都是可解释、白盒化的。注:关于白盒化·可解释性问题,我们在后面的知识点中会专门展开论述。
另外一个重要的点、需要澄清和解惑的知识点:并非所有的图数据库都是一样的!
目前业界有3大类图数据库的实现方式:
-
基于关系型数据库的图数据库实现,也包含多模数据库实现方式(Cosmos DB、Oracle PGX等)
-
基于Hadoop/Spark或NoSQL存储引擎的“图数据库”(例如,JanusGraph、星环、创邻、Nebula等)
-
原生图数据库(原生图存储+计算引擎),例如:Neo4j、TigerGraph、Ultipa等。
在国内,还有很多原本是做应用层知识图谱开发的厂商,因为知识图谱的故事讲不下去了,被迫“转型”做图数据库,通常有两条路线:1. 包皮社区版的Neo4j或者是其它开源的图数据库;2. 宣称自研(事实上,在这一点上,很多厂商即便是包了开源或闭源的第三方数据库,也都会宣称自己100%自主可控,用户需要加以甄别——天下没有免费的午餐,免费的恰恰是最贵的,也是最不可控的)。
关于以上三类图数据库的架构搭建实现方式,优劣之处但凡有commmon-sense的人都会明白,在此仅做简要分析:
-
基于关系型数据库来实现图计算,意味着强行把两种架构和查询逻辑拼凑在一起,用户体验一定跳跃性极大,类似于强扭的瓜不甜。这种架构通常是SQL时代的巨头采用的方式,但是因为缺少创新思路和惰性,此种方式的图数据库(或图计算引擎)都是附着于关系型存储引擎而存在的,不会单独以图数据库形式售卖。在数据处理能力上面以及创新性方面会大打折扣。通常它们面对的是已有的客户,但是想一窥图世界之端倪...
-
基于Hadoop/Spark/NoSQL框架构建的图数据库几乎都缺少OLTP的能力,且OLAP的效率也不高。此种架构因为通常采用水平分布式,可以做到大规模数据的分布式存储,但是计算效率却很低下,并且因为其非原生存储与计算的底层限制,较关系型+图计算并没有本质的优势。采用这种架构的厂家通常是互联网和喜欢”白嫖“开源大数据的公司。
-
原生图数据库在逻辑上一定是原生图存储引擎+原生图计算引擎+原生图查询引擎,三者缺一不可。存储如果是原生的,计算必须是原生的,查询也必然是原生的。这一点,在国内市场就非常混乱,任何厂家都可能宣称自己是原生图、支持HTAP,尽管它的底层可能包裹的是Neo4j。查询引擎是很重要的一环,所有宣称同时支持多种图查询语言的公司,一定是个骗局——例如某图数据库公司宣称自己同时支持OpenCypher、Gremlin及SPARQL,可以想象,它对于任何一种图查询语言的特性的支持都一定不会好!这就好比Oracle宣称自己除了支持自家的PL/SQL外,还能无缝支持DB2、SQL Server、MySQL的SQL-dialect一样荒谬与无知(and 无耻)。图查询引擎是需要根据底层的存储与计算引擎的(架构和数据结构)的特性进行优化设计的,即便是去通过翻译、适配的方式去支持其他非原生的查询语言,那么一定很多该语言的特性、能力、效率会大打折扣!
图数据库如果不追求极致的性能与易用性,它就会变成为了存在而存在——因此,用大数据、数仓思维去构建图数据库的那种模式的厂家,注定是场骗局。说明这些厂家完全没有get到图数据库、图计算应该解决的场景。时间会证明一切。
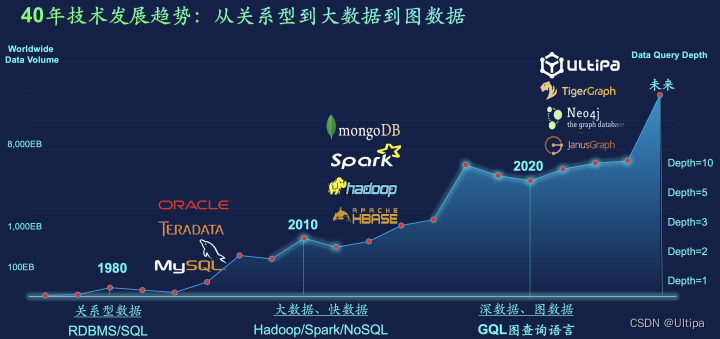
上图中展示了过去近半个世纪的数据处理技术的发展趋势:从关系型数据库到大数据,直至图数据、深数据。
相比与前两代的数据库形态,图数据(与图计算)的显著特点与优势(再次总结):
1.白盒化、可解释
2.计算高效、深度下钻与关联
3.灵活数据建模与分析
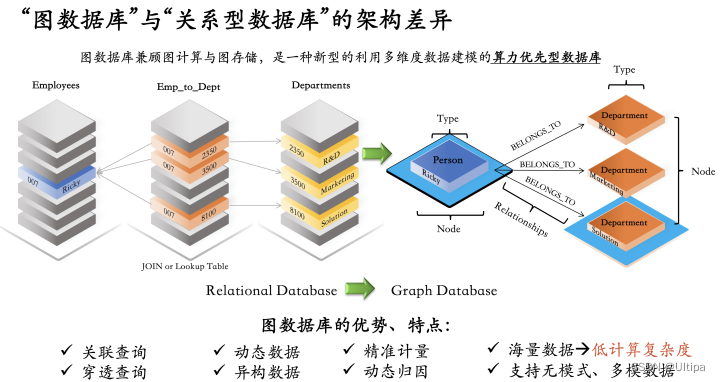
图数据库兼顾图计算与图存储,是一种新型的利用多维度数据建模的算力优先型数据库
在查询逻辑层面,图数据库的架构优势尤其体现在“关联查询”时,如上图所示,原生图的(依托近邻无索引数据结构技术)查询效率会显著的高于关系型数据库(也包含数仓、数湖等架构),而且随着查询深度增加,每增加一层查询复杂度,时耗的差异也会显著增加,直至形成指数级的时耗差异(成百、上千、上万倍的差异)。
如果读者对于图数据库和关系型数据库架构差异有兴趣深入剖析,推荐阅读机械工业出版社2022年8月最新出版的《图数据库原理、架构与应用》一书。
从关系型数据库(及数仓、湖)向图数据库迁移是个大概率不可逆的趋势。它背后的推动因素主要是:工业界和学术界纷纷对于现有的SQL的诸多限制与不足的不满,亟需一种新型的、高效的、灵活的、高维的架构和查询标准的出现,因此GQL在2023年的出现可谓万众期待,毕竟SQL已经走过了40年的光阴,数以千万人的时光都“白白浪费”在里面……

从关系型到高维图模型的迁移、转换的方式很多,一方面是工具赋能,可视化、低代码的迁移工具可以很好的帮助用户实现高维数据建模,另一方面因为图的高维性,绝不止一种建模方式。图数据库的时代一定要保持灵活,能根据业务的需求来进行动态建模,并通过比较不同建模方式来在实践中发现何种建模方式更为高效。例如图论中有个基础概念(很多人都忽略了)叫做简单图(simple graph) 与复杂图(或多边图 = multi-graph)——有的业务场景适合用简单图,但是更多的业务场景用多边图更为高效(例如金融场景中,多边图显然比单边图更为灵活高效)。这个时候,如果一个厂家只能支持单边图建模,就会事倍而功半!具体的厂家们的名字我们就不在这里挑明了。
类似的,有的图数据库只能对顶点及属性进行过滤,却不能支持对关系(边)进行过滤,可以想象这种能力的限制对于业务功能的实现会产生多严重的负面影响!还是那句话:不是所有的图数据库都是一样的。鱼目混珠的是多数。
总结
最后我们来梳理图数据库的优势如下:
-
深度数据关联分析与计算
-
实时计算与分析
-
高效商业决策
-
白盒化可解释性
-
创新行业应用
-
更高效的硬件资源利用(更小的集群规模、减排、碳中和)
关于最后一点,再次强调,用大数据/Hadoop/Spark之类的方式来构建图数据库框架无异于严重的资源浪费,动辄几十台机器的集群,一堆开源框架的堆叠(Elastic Search、Redis、MapReduce等等),这种最多能算作是把数据存在那里,根本算不动——这种面向资源浪费的低效、低算力框架,根本不必上图数据库。关于此知识点,我们也会后文中展开论述。
在后续的知识点中我们会带领大家真正进入到图数据库的世界, Stay tuned.