模型介绍
baichuan-7B是由百川智能开发的一个开源的大规模预训练模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
huggingface
github
部署环境
- 系统:centos7.8.2003
- GPU:2 * 3090 (24G)
代码下载
git clone https://github.com/baichuan-inc/baichuan-7B.git
模型下载
下载地址:https://huggingface.co/baichuan-inc/baichuan-7B/tree/main
huggingface模型下载有几种方式:
- 使用git下载
git lfs install
git clone https://huggingface.co/baichuan-inc/baichuan-7B
- 网页直接下载,一个个下载,然后放置到固定文件夹下即可。
- 使用代码自动加载huggingface模型
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/baichuan-7B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/baichuan-7B", device_map="auto", trust_remote_code=True)
环境安装
python == 3.8.16
pip install -r requirements.txt
独立测试
GPU应该选择至少30G的显存。我这里一块24G卡,测试启动不稳定,显存容易溢出(可以通过修改max_new_tokens参数为64,勉强可以跑)。2块24G卡没问题。
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
os.environ["CUDA_VISIBLE_DEVICES"] = '4, 5'
if __name__ == '__main__':
text_generation_zh = pipeline(task=Tasks.text_generation, model='baichuan-inc/baichuan-7B',model_revision='v1.0.2')
text_generation_zh._model_prepare = True
result_zh = text_generation_zh('今天天气是真的')
print(result_zh)
模型处填写保存模型的目录路径

服务接口
# !/usr/bin/env python
# -*- coding:utf-8 -*-
from flask import Flask, request, jsonify
import threading
from flask_cors import CORS
import os
from transformers import AutoModelForCausalLM, AutoTokenizer
os.environ["CUDA_VISIBLE_DEVICES"] = '4, 5'
app = Flask(__name__)
CORS(app)
# 加载模型
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/baichuan-7B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/baichuan-7B", device_map="auto", trust_remote_code=True)
# 创建线程锁和计数器
lock = threading.Lock()
counter = 0
MAX_CONCURRENT_REQUESTS = 5 # 最大并发请求数
@app.route('/baichuan/conversation', methods=['POST'])
def conversation():
global counter
# 请求过载,返回提示信息
if counter >= MAX_CONCURRENT_REQUESTS:
return jsonify({'message': '请稍等再试'})
# 获取线程锁
with lock:
counter += 1
try:
# 接收 POST 请求的数据
question = request.json['question']
question += '->'
inputs = tokenizer(question, return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs, max_new_tokens=1024, repetition_penalty=1.1)
text = tokenizer.decode(pred.cpu()[0], skip_special_tokens=True)
print("result:", text)
# 返回结果
response = {'result': text[len(question):]}
return jsonify(response)
finally:
# 释放线程锁并减少计数器
with lock:
counter -= 1
if __name__ == '__main__':
print("Flask 服务器已启动")
app.run(host='0.0.0.0', port=30908)
接口调用
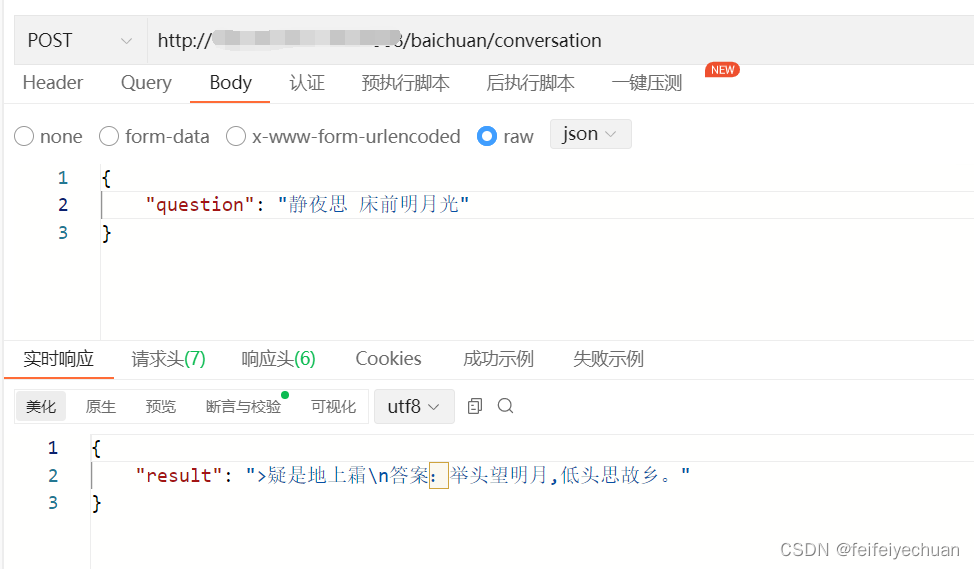
测试小结
- 该模型是一个文本生成模型,对话式效果较差,但是如果prompt为问答式,还是有一些效果的。如果需要对话式满足自己的需求,还是需要进行后续的fintune微调。
官方也说了:
chatgpt 等模型专门针对对话进行了微调,目前 baichuan-7B 暂时还没针对对话微调,所以不支持对话。
但目前模型是有推理能力的。
模型介绍页面已经举例用法了,如“登鹳雀楼->王之涣\n夜雨寄北->”,给定示例“登鹳雀楼->王之涣”,也就是根据诗歌名称推理作者名称,那么给定问题“夜雨寄北->”,就能够正确推理出来,作者是“李商隐”。 如果你想实现对话能力,你可以找 gpt 的公开对话数据集,自己对 baichuan-7B 进行微调。
- 看社区也有大佬已经微调了对话模型 https://huggingface.co/hiyouga/baichuan-7b-sft ,有时间可以试试。
希望
- 希望有更多的大佬微调出更出色的AIGC能力。