注1:本文系“简要介绍”系列之一,仅从概念上对计算机视觉中的开放词汇(open vocabulary)进行非常简要的介绍,不适合用于深入和详细的了解。
注2:"简要介绍"系列的所有创作均使用了AIGC工具辅助
计算机视觉中的开放词汇:挑战与未来
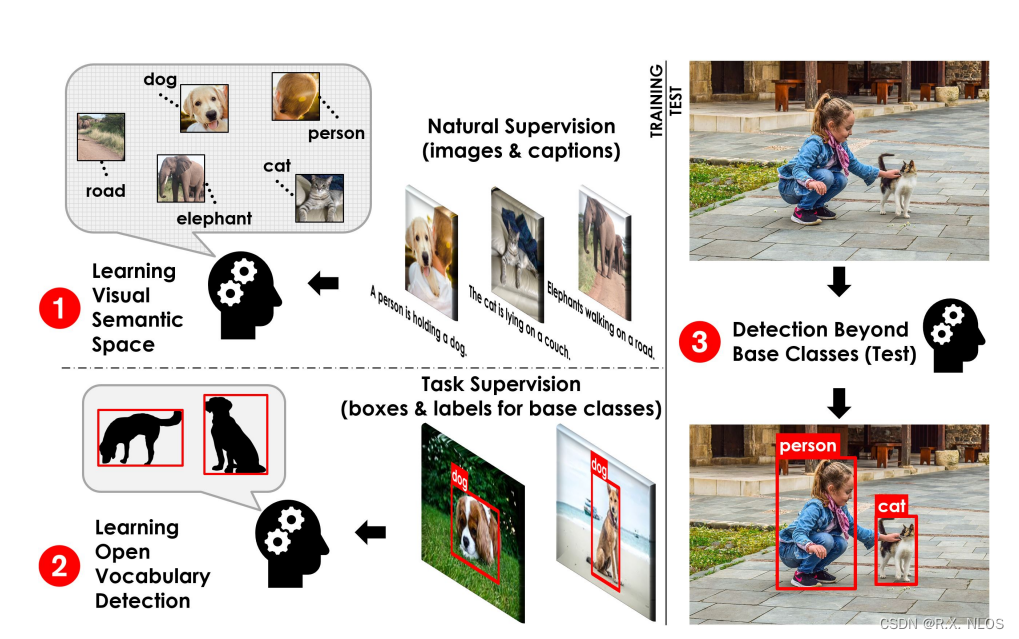
1. 背景介绍
计算机视觉(Computer Vision)是一门研究如何使计算机能够 理解和解释 图像或视频中的场景的学科。计算机视觉的一个核心问题是识别图像中的物体和场景。为了实现这一目标,研究者们在过去几十年里开发了许多方法,包括:基于特征的方法、基于模型的方法、基于深度学习的方法等。
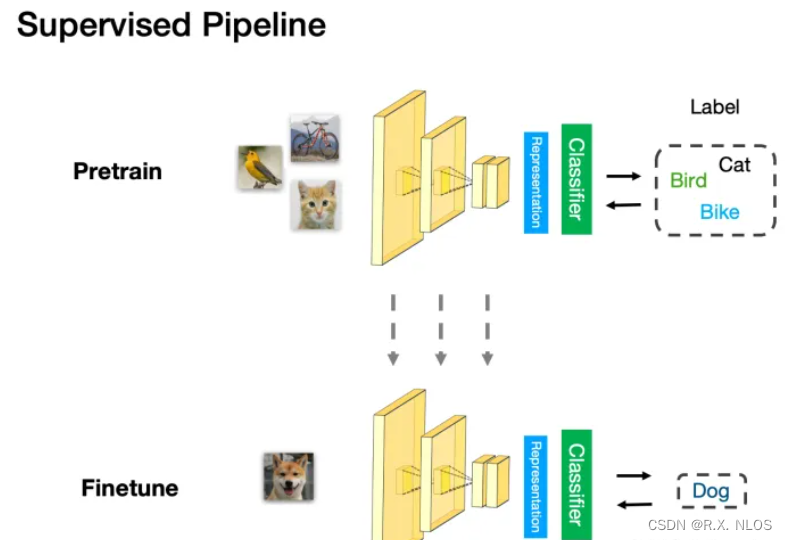
在传统的计算机视觉任务中,通常会有一个固定的标签集合,即封闭词汇(Closed Vocabulary)。然而,现实世界中的物体和场景是多样的,难以用一个固定的标签集合来描述。为了应对这一挑战,研究者们提出了开放词汇(Open Vocabulary)的概念。
2. 开放词汇的原理与推导
2.1 原理概述
开放词汇指的是一种 可扩展的标签集合,它允许计算机视觉系统在遇到 新的物体或场景 时,能够 自我更新 并学习到新的标签。这种方法可以让计算机视觉系统更好地适应现实世界的多样性。
2.2 数学建模详细描述
在开放词汇的计算机视觉任务中,我们希望找到一个模型,使得对于所有的输入图像 x x x和输出标签集合 y y y,模型能够最小化预测与真实标签之间的损失。我们可以通过以下步骤进行数学建模:
-
定义损失函数:我们需要定义一个损失函数 L ( y , f ( x ) ) L(y, f(x)) L(y,f(x)),用于衡量预测 f ( x ) f(x) f(x)与真实标签 y y y之间的差距。损失函数的选择可能会受到具体任务和数据集的影响。常见的损失函数包括:交叉熵损失、均方误差损失等。
-
定义模型空间:我们需要定义一个模型空间 F \mathcal{F} F,表示所有可能的计算机视觉模型。在深度学习领域,模型空间通常由多层神经网络组成,每层由一些参数化的权重矩阵和激活函数构成。
-
优化问题:我们的目标是找到一个模型 f ∗ f^* f∗,使得损失函数 L ( y , f ∗ ( x ) ) L(y, f^*(x)) L(y,f∗(x))在所有输入图像 x x x和标签集合 y y y上的平均值最小。这可以通过以下优化问题表示:
f ∗ = arg min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) f^* = \arg\min_{f \in \mathcal{F}} \frac{1}{N} \sum_{i=1}^N L(y_i, f(x_i)) f∗=argf∈FminN1i=1∑NL(yi,f(xi))
其中 N N N表示训练数据集的大小。
-
优化算法:为了求解上述优化问题,我们需要设计一种优化算法。在深度学习领域,常见的优化算法包括:随机梯度下降(SGD)、Adam、RMSProp等。这些算法通过不断地更新模型参数,使得损失函数逐渐收敛到最小值。
通过以上数学建模,我们可以将开放词汇的计算机视觉任务转化为一个可解的优化问题,从而实现自动更新和学习新标签的目标。
2.3 开放词汇的学习与推导
为了学习开放词汇,我们可以采用 自监督学习 (Self-supervised learning)的方法。自监督学习是一种无需人工标签的训练方法,它通过设计一种 预测任务 ,使得计算机视觉系统能够从 大量无标签数据 中学习有用的特征。在开放词汇的场景下,我们可以设计以下预测任务:
-
上下文预测:给定一个图像 x x x中的局部区域 R i R_i Ri,预测其周围的区域 R j R_j Rj。这种任务可以帮助计算机视觉系统学习到物体和场景的 空间结构 信息。
-
时序预测:给定一段视频 V V V中的一帧图像 t k t_k tk,预测其前后帧图像 t k − 1 t_{k-1} tk−1和 t k + 1 t_{k+1} tk+1。这种任务可以帮助计算机视觉系统学习到物体和场景的 动态变化 信息。
-
多模态预测:给定一个图像 x x x和与之相关的文本描述 d d d,预测 d d d中的单词与 x x x中的区域之间的关联。这种任务可以帮助计算机视觉系统学习到物体和场景的 语义信息 。
通过这些预测任务,计算机视觉系统可以在遇到新标签时,自动地学习到与之相关的特征,并更新其输出标签集合。
3. 研究现状
开放词汇在计算机视觉领域的研究仍然处于 初级阶段 。目前,研究者们主要关注以下几个方向:
-
自监督学习方法的改进:研究者们致力于设计更有效的自监督学习任务,以便在开放词汇的场景下,提高计算机视觉系统的性能。
-
基于模型的推理方法:一些研究者试图利用概率图模型等方法,对开放词汇中的物体和场景进行建模,并推导出它们的关联。
-
跨模态学习:为了学习到更丰富的语义信息,研究者们探索将计算机视觉与自然语言处理等其他领域的技术结合起来。
-
开放词汇的评估方法:由于开放词汇的场景与传统计算机视觉任务有很大不同,因此研究者们还需要开发新的评估方法,以便更准确地衡量计算机视觉系统在开放词汇下的性能。
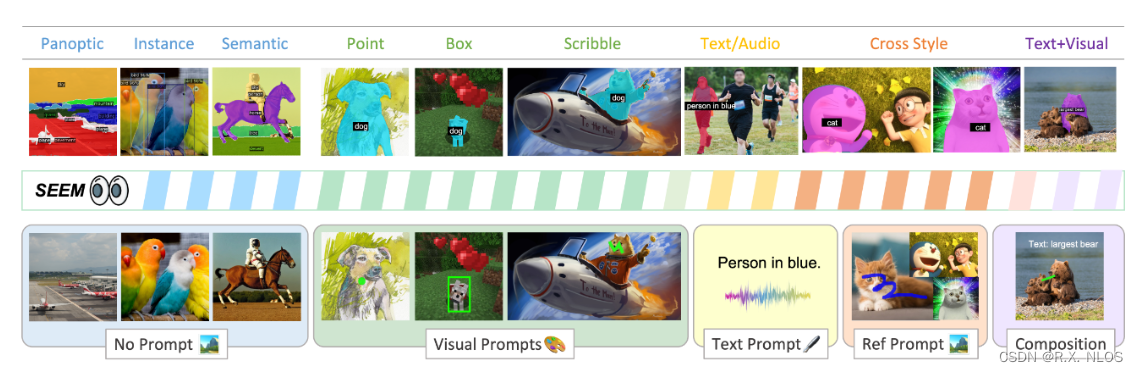
(https://arxiv.org/pdf/2304.06718v1.pdf)
4. 挑战
在开放词汇计算机视觉领域,研究者们面临着以下挑战:
-
数据不足:开放词汇任务通常需要大量的无标签数据来进行自监督学习。然而,现实世界中的数据往往是稀疏和不均匀分布的。这使得在某些罕见类别和场景下,模型的学习和泛化能力受到限制。
-
模型泛化能力:由于开放词汇任务中新标签的不断出现,模型需要具有较强的泛化能力,以便在不增加过多计算和存储资源的前提下,适应新的任务和场景。然而,现有的计算机视觉模型往往在这方面表现不佳。
-
计算资源限制:开放词汇任务涉及到大量的数据和复杂的模型,这使得计算资源成为一个关键因素。在有限的计算资源下,如何设计高效和可扩展的算法,以实现实时更新和学习新标签,是一个重要挑战。
-
任务之间的依赖关系:在开放词汇的计算机视觉任务中,物体和场景之间通常存在复杂的依赖关系。这些依赖关系可能会对模型的学习和泛化能力产生影响。因此,如何在模型中建立和利用这些依赖关系,以提高模型的性能,是一个重要挑战。
-
噪声和异常值:在现实世界中,数据往往受到各种噪声和异常值的影响。这可能导致模型学到错误的知识和规律。如何在开放词汇任务中,设计鲁棒的算法,以应对这些噪声和异常值,是一个关键挑战。
-
评估指标:由于开放词汇任务的复杂性,通常很难为模型的性能设定一个统一的评估指标。这使得不同方法之间的比较和模型选择变得困难。因此,如何设计合适的评估指标,以衡量模型在各个方面的性能,是一个重要挑战。
为了克服这些挑战,研究者们提出了许多方法,如:数据增强、迁移学习、多任务学习、元学习等。这些方法在不同程度上都有助于提高模型在开放词汇计算机视觉任务中的性能。然而,这些方法仍然存在许多局限性,如何进一步提升模型性能,仍然是一个活跃的研究领域。