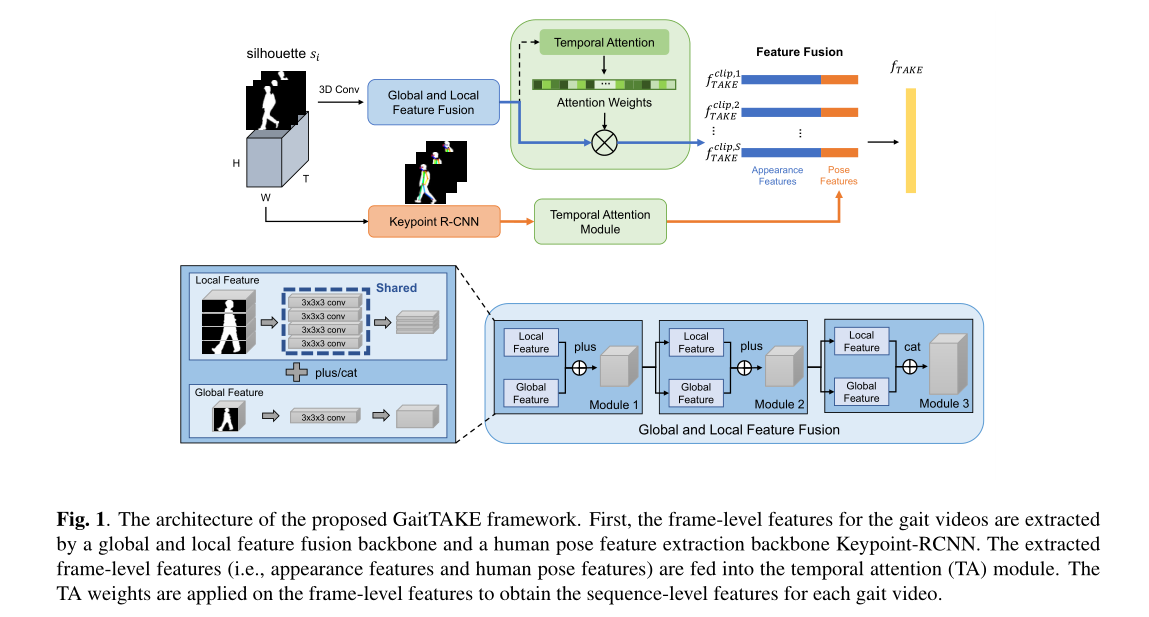
在flink cdc同步数据时,基于sql的实现方式中发现了作业DAG有个SinkMaterializer算子,而且检查checkpoint历史时发现该算子state越来越大,
有必要搞清楚为什么会多了这个算子,作用又是什么。
通过算子名称定位到了源码为类org.apache.flink.table.runtime.operators.sink.SinkUpsertMaterializer,这个算子将输入的记录以upsert key作区分保存到state中,
并为下游算子提供一下upsert视图。
An operator that maintains incoming records in state corresponding to the upsert keys and generates an upsert view for the downstream operator.
单纯看类注释和代码逻辑,并不能理解它的用处及设计背景。
设计背景
SinkUpsertMaterializer是为了解决changelog流事件乱序造成了结果不正确的问题。
示例
在分布式环境中,join, aggregate等操作经常会触发数据shuffling,可能会将source端同一主键记录的changelog分散到不同的下游算子中处理,造成数据处理乱序。
-- CDC源表:
event: event_id BIGINT, dim_id BIGINT, PRIMARY KEY(event_id)
dim: dim_id BIGINT, name VARCHAR, PRIMARY KEY(dim_id)
-- 结果表:
result: event_id BIGINT, dim_id BIGINT, name VARCHAR, PRIMARY KEY(event_id)
INSERT INTO result SELECT event.*,dim.name from event JOIN dim ON event.dim_id = dim.dim_id
两源表数据如何,event表只有1条数据,其中dim_id的值由10更新为11,所以整个流中产生了3条changelog数据。dim表中有dim_id为10,11的两条数据,没发生过修改。
| event | dim |
|---|---|
| (+I,event_id=1,dim_id=10) (-U,event_id=1,dim_id=10) (+U,event_id=1,dim_id=11) | (+I,dim_id=10,name=dim10) (+I,dim_id=11,name=dim11) |
当event表和dim表根据dim_id进行关联时,changelog数据将以dim_id为upsert keys进行shuffling,得到以下情况

由于sink接收的数据来自两个上游算子,由于网络或者是处理速度原因,sink最终接收到数据的顺序并不确定,唯一能确定的是+I会在-U之前,因为两者具有相同的dim_id(10),最终会被同一个join task顺序处理,
即最终sink的数据可能是以下几种可能:
| 情况一 | 情况二 | 情况三 |
|---|---|---|
| (+I,event_id=1,dim_id=10,name=dim10) (-U,event_id=1,dim_id=10,name=dim10) (+U,event_id=1,dim_id=11,name=dim11) | (+I,event_id=1,dim_id=10,name=dim10) (+U,event_id=1,dim_id=11,name=dim11) (-U,event_id=1,dim_id=10,name=dim10) | (+U,event_id=1,dim_id=11,name=dim11) (+I,event_id=1,dim_id=10,name=dim10) (-U,event_id=1,dim_id=10,name=dim10) |
- 情况一:sink顺序接收了changelog,最终得到正确结果(event_id=1,dim_id=11,name=dim11)
- 情况二:sink最后接收到-U,造成event_id=1记录被删除
- 情况三:同情况二
SinkUpsertMaterializer
SinkUpsertMaterializer位于sink算子之前,它通过将上游乱序数据以**upsert keys分区缓存在state中,同时为下游的sink提供一个正确的upsert视图。
原理
根据代码逻辑梳理出以下流程图

SinkUpsertMaterializer处理逻辑:
- 如果row是+|或+U,则保存到state中,如果state中不为空,表示该row是+U,否则是+I(前提是+I不能和+U发生乱序!!!)
- 如果row是-D或-U,则需要从state中删除与之对应状态的记录,如果删除后state为空,表示该key已经被删除,发送-D到下游;如果删除的记录为state中最后一条,则表示倒数第二条为该key当前最新的状态,将它标记为+U发送到下游
单纯从代码逻辑很难理解,结合上述的示例,看看会得到什么效果。
效果
分析情况二和情况三两种情况在SinkUpsertMaterializer中会产生什么效果
- 情况二
- 接收(+I,event_id=1,dim_id=10,name=dim10)并发送到下游,state=[(+I,event_id=1,dim_id=10,name=dim10)]
- 接收(+U,event_id=1,dim_id=11,name=dim11)并发送到下游,state=[(+I,event_id=1,dim_id=10,name=dim10),(+U,event_id=1,dim_id=11,name=dim11)]
- 接收(-U,event_id=1,dim_id=10,name=dim10),删除state中第一个元素同时抛弃,state=[(+U,event_id=1,dim_id=11,name=dim11)]
乱序的-U最终在SinkUpsertMaterializer中就被丢了,并不会发送到sink,而最后发到sink的是+U,最终状态与state保持一致。
- 情况三
- 接收(+U,event_id=1,dim_id=11,name=dim11)并发送到下游,state=[(+I,event_id=1,dim_id=11,name=dim11)]
- 接收(+I,event_id=1,dim_id=10,name=dim10)并发送到下游,state=[(+I,event_id=1,dim_id=11,name=dim11),(+U,event_id=1,dim_id=10,name=dim10)]
- 接收(-U,event_id=1,dim_id=10,name=dim10),删除state中最后一个元素,取第倒数第二个元素改+U往下发送(+U,event_id=1,dim_id=11,name=dim11)
情况三中,+I与+U乱序,-U与+U乱序,但是最终sink接收到的最后都是+U,数据正确。
使用方式
table.exec.sink.upsert-materialize配置项用于控制该算子的使用
- FORCE:强制使用,无论什么场景
- NONE:任何场景都不使用
- AUTO:根据执行计划自动推断是否需要开启,当输入算子数据存在更新且upsert keys不存在于sink表主键中时启用。上述示例中source为changelog,event_id为主键,dim_id为upsert keys,符合条件,所以开启。
推断的逻辑位于代码org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram.SatisfyUpdateKindTraitVisitor#analyzeUpsertMaterializeStrategy
当开启后,需要考虑state持续增大的情况,ttl受
table.exec.state.ttl控制
参考
https://blog.csdn.net/qq_32727095/article/details/129876631
https://www.ververica.com/blog/flink-sql-secrets-mastering-the-art-of-changelog-event-out-of-orderness