文章目录
- 人脸识别过程
- 人脸检测
- 人脸对齐
- 人脸特征提取
- 特征距离比对
- 人脸识别系统
人脸识别过程
在深度学习领域做人脸识别的识别准确率已经高到超出人类识别,但综合考虑模型复杂度(推理速度)和模型的识别效果,这个地方还是有做一些工作的需求的。
人脸识别的过程基本由下面的流程组成。
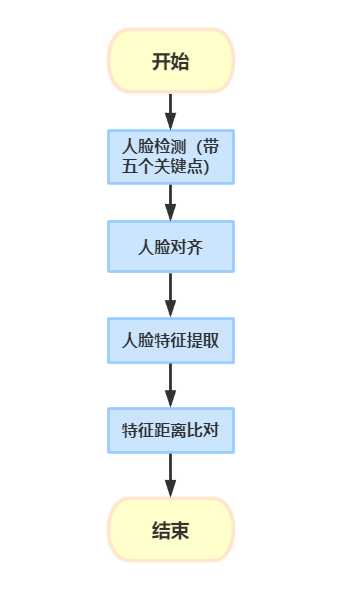
人脸检测
yolov5-face、yolov7-face等github项目都可以做到这一点,在公开数据集上训练,得到的效果还不错。
但想要效果更好,可以增加一些训练数据。
人脸检测和五个关键点回归是一种常见的人脸识别任务,涉及使用深度学习模型来检测人脸位置,并准确地回归出人脸中的五个关键点位置。这些关键点通常包括眼睛、鼻子和嘴巴等特征点,它们的位置信息对于人脸识别和表情识别等任务至关重要。
在深度学习中,通常使用卷积神经网络(Convolutional Neural Network,CNN)来实现人脸检测和关键点回归任务。这些网络模型通过在大量标注的人脸图像上进行训练,学习到了人脸的特征表示和关键点的位置关系。
人脸检测模型首先会对输入图像进行处理,通过卷积层、池化层和激活函数等构建深层特征表示。然后,这些特征会被送入全连接层,进一步提取图像中存在人脸的区域,并给出其边界框的位置。
在关键点回归阶段,通常使用回归模型来预测人脸中的关键点位置。这个模型可以基于同样的卷积神经网络结构,或者通过将其与人脸检测模型进行联合训练,共享一些卷积层和特征提取部分,以提高预测的准确性。
训练这样的深度学习模型需要大量的标注人脸图像和对应的关键点位置。一般情况下,这些数据集会由专业的团队进行手动标注,以确保准确性和一致性。然后,使用这些标注数据来训练模型,通过优化损失函数,使得预测的人脸位置和关键点位置与真实标注尽可能接近。
人脸检测和五个关键点回归的深度学习模型在人脸识别、表情识别、人脸特征提取等领域有着广泛的应用。它们可以用于人脸识别系统、人脸表情分析、人脸姿态估计等任务,为人机交互和计算机视觉领域带来了很多便利和创新。
下图是人脸检测效果图,得到bbox框选和五个人脸关键点。

人脸对齐
人脸对齐是指通过对人脸图像进行几何变换,使得人脸在图像中的位置和朝向达到一致。对齐后的人脸图像通常具有固定的尺寸和标准的姿态,便于后续的人脸识别、特征提取等任务。
在给定人脸关键点的情况下,人脸对齐的过程可以通过以下步骤实现:
1、根据人脸关键点的位置,提取需要对齐的区域。通常使用关键点来确定人脸的位置和尺度,以便进行后续的对齐操作。
2、定义一个参考的标准人脸关键点位置。这些标准关键点位置可以是经过统计分析得到的平均值或预定义的固定位置。
3、利用人脸关键点和参考关键点之间的对应关系,计算出变换矩阵。常用的方法是使用相似性变换(Similarity Transform),该变换可以通过最小二乘法估计出最合适的变换参数,以使得人脸关键点与参考关键点尽可能匹配。
4、使用得到的变换矩阵对原始图像进行几何变换,得到对齐后的人脸图像。常见的几何变换包括仿射变换(Affine Transform)和透视变换(Perspective Transform)等。
对齐是将人脸拉回到正脸位置或者基本处于正脸的状态:

人脸特征提取
人脸特征提取是指通过深度学习模型从人脸图像中提取出具有辨识度的高维特征向量。这些特征向量能够表达人脸的独特特征,例如面部轮廓、纹理和结构等,可以用于人脸识别、人脸验证、人脸检索等任务。
人脸特征提取模型的训练特点主要体现在以下几个方面:
1、数据集构建:训练人脸特征提取模型通常需要一个大规模的人脸数据集。这个数据集需要包含多个人脸的图像,并对每个人脸进行标注,以提供准确的身份标签。构建这样的数据集需要耗费大量的时间和人力资源,通常会利用大规模的公开人脸数据集和人工标注来完成。
2、模型架构选择:人脸特征提取模型的架构选择对于模型性能至关重要。常用的模型架构包括经典的卷积神经网络(Convolutional Neural Network,CNN),如VGG、ResNet、Inception等,以及一些针对人脸特征提取任务设计的模型,如SphereFace、ArcFace、CosFace等。这些模型通常具有较深的网络结构和特定的损失函数,能够有效地提取具有判别性的人脸特征。
3、损失函数设计:人脸特征提取模型通常采用特定的损失函数来优化特征向量的表达能力。常用的损失函数包括三元组损失(Triplet Loss)、角度间隔损失(Angular Margin Loss)等,这些损失函数能够增强同一人脸特征向量的相似性、增大不同人脸特征向量的差异性,从而提高特征的辨识度。
特征距离比对
人脸特征的距离比对是一种用于比较和匹配人脸图像的技术。它通过计算不同人脸特征之间的相似度或距离来确定它们之间的相似程度。
在人脸识别领域,常用的人脸特征表示方法之一是人脸特征向量,也称为人脸特征模型。这种特征向量是通过将人脸图像转换为高维特征空间中的向量表示得到的。常见的人脸特征表示方法包括主成分分析(PCA)、线性判别分析(LDA)、人工神经网络等。
要进行人脸特征的距离比对,一种常见的方法是使用欧氏距离或余弦距离等度量方式来计算不同人脸特征向量之间的相似度。欧氏距离衡量了向量之间的几何距离,而余弦距离则测量了向量之间的夹角相似度。
在进行人脸比对时,通常会将待识别的人脸图像与一个数据库中的人脸特征进行比对。数据库中的数据包含已经预先提取和存储的人脸特征向量。通过计算待识别人脸图像的特征向量与数据库中已有数据的特征向量之间的距离,可以找到与之最相似的人脸。
当人脸数量庞大时,可以使用特征搜索引擎来提高比对效率。特征搜索引擎使用索引和快速搜索算法,将数据库中的人脸特征进行高效的组织和存储。这些引擎可以通过将待比对的人脸特征与数据库中的索引进行比较,快速定位到可能的匹配结果,从而减少比对时间和计算成本。
一些流行的人脸识别技术和框架,如OpenCV、Dlib、FaceNet、ArcFace等,提供了用于人脸特征提取、距离比对和数据库比对的相关函数和工具。这些技术通常基于深度学习和人工智能的方法,具备较高的识别准确度和性能。
人脸识别系统
基本做到了在CPU上实时进行人脸识别,如下方可以识别侧脸的人是周杰伦,识别效果还不错:









![[游戏开发]Unity颜色矫正无障碍方案](https://img-blog.csdnimg.cn/d22187a9b071467ea62a831c48a2a04e.png)