文章目录
- 聚合函数
- 分组group by使用
- OJ题目
- 描述
- 描述
本篇主要介绍mysql的聚合函数和group by的使用,最后是OJ题目的练习。
聚合函数
MySQL中的聚合函数用于对数据进行计算和统计,常见的聚合函数包括下面列举出来的聚合函数:
函数 说明
COUNT([DISTINCT] expr) 返回查询到的数据的数量
SUM([DISTINCT] expr) 返回查询到的数据的总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的最小值,不是数字没有意义
对于上面所列举出来的聚合函数,下面我们通过一些案例来进行对聚合函数的运用,增强理解,话不多说
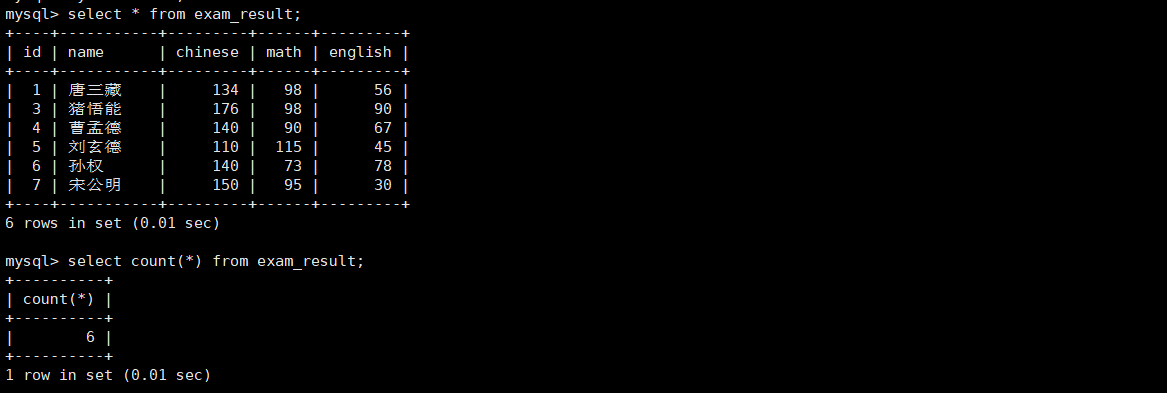
- 统计班级共有多少同学
-- 使用 * 做统计,不受 NULL 影响
select count(*) from exam_result;
-- 使用表达式做统计
select count(1) from exam_result;

- 统计班级的数学成绩有多少个
select count(math) from exam_result;

但是我们看到了数学成绩是有重复的,如何去重?distinct
select distinct count(distinct math) from exam_result;

- 统计数学成绩总分
select sum(math) from exam_result;

- 统计数学成绩的平均分
select sum(math)/count(*) from exam_result;
select avg(math) from exam_result;

- 统计英语成绩不及格的人数
select count(*) from exam_result where english<60;

- 返回英语最高分
select max(english) from exam_result;

- 返回 > 70 分以上的数学最低分
select min(math) from exam_result where math>70;

分组group by使用
分组的目的是为了进行分组之后,方便进行聚合统计
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
先创建一个雇员信息表
EMP员工表
DEPT部门表
SALGRADE工资等级表
如何显示每个部门的平均工资和最高工资

- 显示每个部门的平均工资和最高工资
select deptno,max(sal) 最高,avg(sal) 平均 from emp group by deptno;

分组就是把一组按照条件拆分成多个组,进行各自组内的统计分组;就是把一张表按照条件在逻辑上拆成了多个子表,然后分别对各自的子表进行聚合统计。
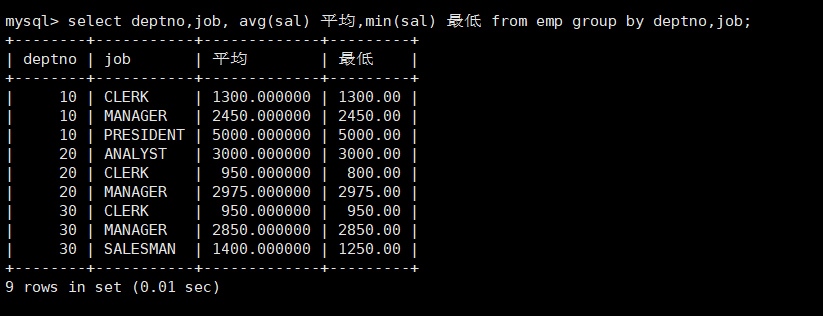
- 显示每个部门的每种岗位的平均工资和最低工资
select deptno,job, avg(sal) 平均,min(sal) 最低 from emp group by deptno,job;
- 显示平均工资低于2000的部门和它的平均工资
统计各个部门的平均工资
select avg(sal) from EMP group by deptno
having和group by配合使用,对group by结果进行过滤
select avg(sal) as myavg from EMP group by deptno having myavg<2000;
having就是对聚合后的统计数据,条件筛选
- having和where区别理解,执行顺序

条件筛选的阶段是不同的。不要单纯的认为只有在磁盘上表结构导入到mysql,真实存在的表才叫做表,中间筛选出来的包括最终结果全部都是逻辑上的表,可以理解为mysql一切皆为表。未来只要我们能够处理好单标的CURD,所有的sql场景我们全部都能用统一的方式进行。
学习完上面的知识之后,我们下面进行一些OJ题目练习,题目来源牛客网与leetcode,做一做,提高自己编写sql的能力
OJ题目
SQL228 批量插入数据
描述
题目已经先执行了如下语句:
drop table if exists actor; CREATE TABLE actor ( actor_id smallint(5) NOT NULL PRIMARY KEY, first_name varchar(45) NOT NULL, last_name varchar(45) NOT NULL, last_update DATETIME NOT NULL)请你对于表actor批量插入如下数据(不能有2条insert语句哦!)
actor_id first_name last_name last_update 1 PENELOPE GUINESS 2006-02-15 12:34:33 2 NICK WAHLBERG 2006-02-15 12:34:33
sql语句如下:
insert into actor (actor_id,first_name,last_name,last_update) values (1,'PENELOPE','GUINESS','2006-02-15 12:34:33'),(2,'NICK','WAHLBERG','2006-02-15 12:34:33');
SQL202 找出所有员工当前薪水salary情况
描述
有一个薪水表,salaries简况如下:
emp_no salary from_date to_date 10001 72527 2002-06-22 9999-01-01 10002 72527 2001-08-02 9999-01-01 10003 43311 2001-12-01 9999-01-01 请你找出所有员工具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示,以上例子输出如下:
salary 72527 43311
sql语句如下:
select distinct salary from salaries order by salary desc;
SQL195 查找最晚入职员工的所有信息
描述
有一个员工employees表简况如下:
emp_no birth_date first_name last_name gender hire_date 10001 1953-09-02 Georgi Facello M 1986-06-26 10002 1964-06-02 Bezalel Simmel F 1985-11-21 10003 1959-12-03 Parto Bamford M 1986-08-28 10004 1954-05-01 Christian Koblick M 1986-12-01 请你查找employees里最晚入职员工的所有信息,以上例子输出如下:
emp_no birth_date first_name last_name gender hire_date 10004 1954-05-01 Christian Koblick M 1986-12-01
select * from employees order by hire_date desc limit 1;
SQL196 查找入职员工时间排名倒数第三的员工所有信息
描述
有一个员工employees表简况如下:
emp_no birth_date first_name last_name gender hire_date 10001 1953-09-02 Georgi Facello M 1986-06-26 10002 1964-06-02 Bezalel Simmel F 1985-11-21 10003 1959-12-03 Parto Bamford M 1986-08-28 10004 1954-05-01 Christian Koblick M 1986-12-01 请你查找employees里入职员工时间排名倒数第三的员工所有信息,以上例子输出如下:
emp_no birth_date first_name last_name gender hire_date 10001 1953-09-02 Georgi Facello M 1986-06-26 注意:可能会存在同一个日期入职的员工,所以入职员工时间排名倒数第三的员工可能不止一个。
select * from employees
where hire_date=(select distinct hire_date from employees order by hire_date desc limit 2,1);
SQL201 查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t
select emp_no,count(*) as t from salaries group by emp_no having t>15;
从titles表获取按照title进行分组
select title,count(title) as t from titles
group by title having t>=2;
182. 查找重复的电子邮箱
select email from Person group by email having count(email)>1;
595. 大的国家
select name,population,area from world
where area >= 3000000 or population >= 25000000;




![[游戏开发]Unity颜色矫正无障碍方案](https://img-blog.csdnimg.cn/d22187a9b071467ea62a831c48a2a04e.png)