最近看到了一篇蛮有意思的论文,如下:

将深度学习开发应用到了地震事件分析分类领域中去了,感觉挺有意思,就想着也来自己体验下看看,这里的数据集是网上找到的一个地震波应该是仿真实验的数据集,我们先来看下数据集的整体情况,代码实现如下所示:
data=np.load(filename)
print("type_data: ", type(data))
for one_key in data:
print("one_key: ", one_key)
X_waveform = data['X_waveform']
label=data['y']
print("X_waveform_shape: ", X_waveform.shape)
print("label_shape: ", label.shape)
结果输出如下所示:

可以看到:这是一个相当小的样本数据集了,包含了100个样本数据。
接下来开发构建一个简单基础的CNN模型来对其实现分类处理,核心代码实现如下所示:
data = np.load(filename)
X_waveform = data["X_waveform"]
label = data["y"]
x_train, y_train, x_test, y_test = dataSplit()
model = initModel()
history = model.fit(
x_train,
y_train,
epochs=50,
validation_split=0.2,
batch_size=128,
shuffle=True,
callbacks=callbacks,
)
acc = history.history["acc"]
val_acc = history.history["val_acc"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.subplot(1, 2, 1)
plt.plot(acc, label="Training Accuracy")
plt.plot(val_acc, label="Validation Accuracy")
plt.title("Training and Validation Accuracy")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label="Training Loss")
plt.plot(val_loss, label="Validation Loss")
plt.title("Training and Validation Loss")
plt.legend()
plt.savefig("train1.png")
其中,模型搭建实现如下所示:
def initModel(
input_shape,
kernel_size,
pooling_size,
root_filters,
clip_filters,
dense_dropout,
cnn_dropout,
n_layers,
activation,
output_class,
output_activation,
):
inputs = Input(shape=input_shape)
y = layers.Conv2D(
filters=root_filters,
kernel_size=kernel_size,
activation=activation,
padding="same",
)(inputs)
y = layers.MaxPooling2D(pooling_size)(y)
n_kernels = root_filters
for i in range(n_layers):
if clip_filters:
if n_kernels > clip_filters:
n_kernels = clip_filters
else:
n_kernels *= 2
else:
n_kernels *= 2
y = layers.Conv2D(
filters=n_kernels,
kernel_size=kernel_size,
padding="same",
activation=activation,
)(y)
y = layers.Dropout(cnn_dropout)(y)
y = layers.MaxPooling2D(pooling_size)(y)
y = layers.Flatten()(y)
y = layers.Dropout(dense_dropout)(y)
y = layers.Dense(100, activation=activation)(y)
outputs = layers.Dense(output_class, activation=output_activation)(y)
baseline_model = models.Model(inputs=inputs, outputs=outputs)
baseline_model.summary()
baseline_model.compile(
optimizer=keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=["acc"],
)
return baseline_model训练可视化如下所示:

这里仅仅训练了30个epoch,接下来我们训练100次epoch看下效果:

因为数据有限,后面再继续训练也没有效果的提升了。
GradCAM(Gradient-weighted Class Activation Mapping)是一种用于热力图可视化的技术,可以帮助理解卷积神经网络(CNN)在分类任务中的决策依据。下面是对GradCAM技术原理的详细介绍:
-
卷积神经网络(CNN): GradCAM技术应用于CNN,而CNN是一种常用于图像分类任务的深度学习模型。它由多个卷积层和池化层组成,最后连接全连接层进行分类。
-
特征图和类别激活图: 在CNN中,卷积层的输出被称为特征图(feature map)。每个特征图包含一系列特定的特征,对应于输入图像在不同位置和尺度上的特征表示。
类别激活图(class activation map)是GradCAM要生成的热力图。它表示CNN对某个特定类别的重要性分布,即哪些区域对于该类别的分类起到了关键作用。
-
反向传播与梯度: Gradient-weighted Class Activation Mapping使用了反向传播过程中的梯度信息。在CNN中,误差反向传播算法通过计算误差函数对网络各参数的偏导数来更新参数值。这些偏导数也可以用于计算输入图像的梯度。
-
GradCAM的步骤:
- 前向传播:将输入图像通过CNN进行正向传播,生成特征图和最终的分类结果。
- 反向传播:计算分类结果对于特征图的梯度。这个梯度表示了特征图对于最终分类的重要性。
- 特征图的空间权重:将每个特征图的通道上的梯度进行空间上的加权求和,用于得到每个特征图的重要性分数。
- 热力图生成:对于每个特征图,将其重要性分数与相应的特征图相乘,得到加权后的特征图。然后将所有加权后的特征图进行叠加,形成最终的热力图。
-
可视化效果: 生成的GradCAM热力图可以通过叠加到原始输入图像上进行可视化。在热力图中,更亮的区域表示对于特定类别分类的重要贡献更大。通过观察热力图,可以理解CNN模型在进行分类决策时关注的区域。
总结来说,GradCAM技术利用CNN中反向传播过程中的梯度信息,对特征图进行空间权重计算,然后生成热力图来显示卷积神经网络在分类任务中关注的区域。这种可视化技术有助于解释和理解CNN模型的决策过程,以及识别图像分类中重要的区域和特征。
接下来基于GradCAM想要实现数据热力图可视化分析,核心代码实现如下所示:
model = keras.models.load_model("best.h5")
y_pred = model.predict(X)
ix = np.array([i])
sampling_rate = 100
times = np.arange(2000) / sampling_rate
cam = GradCAM(model, 0)
heatmap_eq = cam.compute_heatmap(X[ix])
cam = GradCAM(model, 1)
heatmap_exp = cam.compute_heatmap(X[ix])
cam = GradCAM(model, 2)
heatmap_noise = cam.compute_heatmap(X[ix])
heatmap_exp /= np.max(heatmap_exp)
heatmap_eq /= np.max(heatmap_eq)
heatmap_noise /= np.max(heatmap_noise)
tr_data = X[ix][0, :, 0, 0]
y_true = y[ix][0]
fig, axes = plt.subplots(nrows=3, figsize=(12, 8))
axes[0].plot(times, tr_data, "grey")
ymin, ymax = axes[0].get_ylim()
sc = axes[0].scatter(
times, tr_data, c=heatmap_exp, cmap=plt.cm.jet, zorder=10, s=5, alpha=0.8
)
axes[0].set_title(
f"True: {mapping[y_true]}, Estimate: EQ, with probability {y_pred[ix][0][0]:.2f}"
)
axes[0].set_xlim(0, 20)
axes[0].set_xticks([])
axes[1].plot(times, tr_data, "grey")
sc = axes[1].scatter(
times, tr_data, c=heatmap_eq, cmap=plt.cm.jet, zorder=10, s=5, alpha=0.8
)
axes[1].set_title(
f"True: {mapping[y_true]}, Estimate: noise, with probability {y_pred[ix][0][1]:.2f}"
)
axes[1].set_xlim(0, 20)
axes[1].set_xticks([])
axes[2].plot(times, tr_data, "grey")
sc = axes[2].scatter(
times, tr_data, c=heatmap_noise, cmap=plt.cm.jet, zorder=10, s=5, alpha=0.8
)
axes[2].set_title(
f"True: {mapping[y_true]}, Estimate: EXP, with probability {y_pred[ix][0][2]:.2f}"
)
axes[2].set_xlabel("Time (sec)")
axes[2].set_xlim(0, 20)
fig.colorbar(sc, ax=[axes[0], axes[1], axes[2]], label="Normalized Grad-CAM weights")
path = "GradCAM/" + b[i] + ".jpg"
plt.savefig(path)
接下来看下对应的效果图:


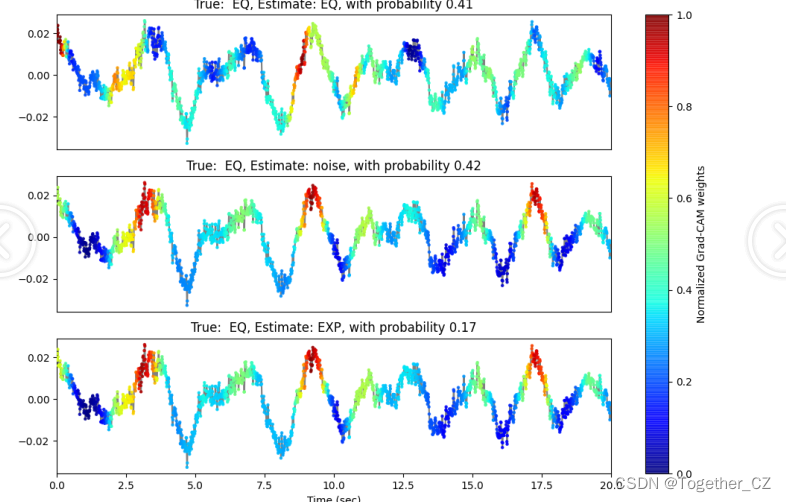


整体来看还是不错的:跟论文中的整体呈现结果还是比较相像的。

接下来我们进一步通过仿真实验生成了大批量的数据集,如下:
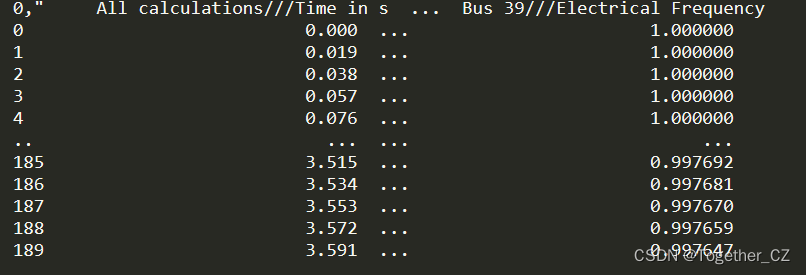



共包含了主要的四个维度的特性数据。
这里针对模型开发层面我们一共设计开发了:lenet、alexnet、vgg、resnet、mobilenet和原论文模型等多种卷积神经网络模型。
时间关系这里就不多展开介绍了,我们直接看下结果:


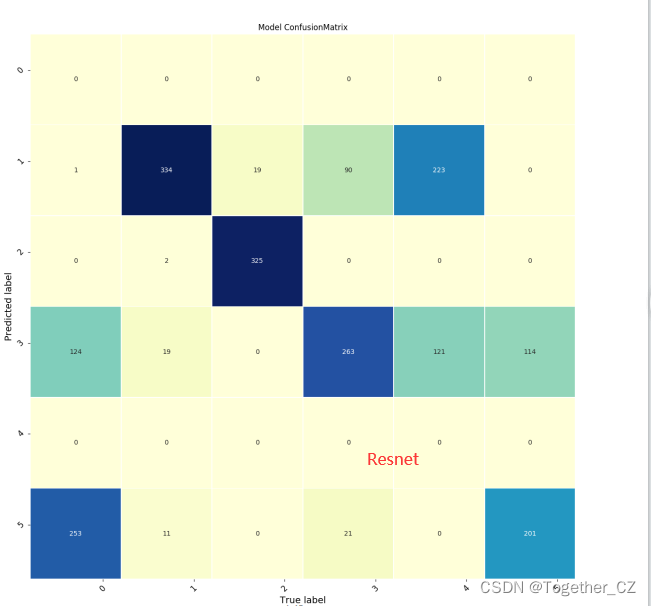
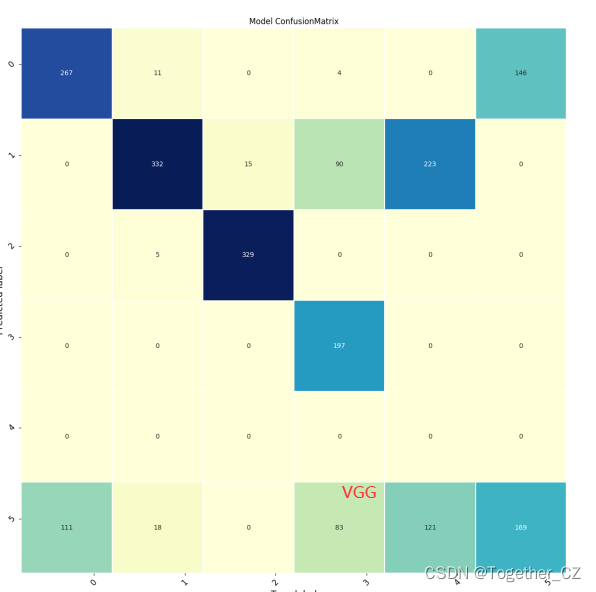

训练过程可视化如下:

这里同样借助于GradCAM算法实现了热力图的可视化展示,如下:






![[游戏开发]Unity颜色矫正无障碍方案](https://img-blog.csdnimg.cn/d22187a9b071467ea62a831c48a2a04e.png)