paper:A Comprehensive Overhaul of Feature Distillation
official implementation:GitHub - clovaai/overhaul-distillation: Official PyTorch implementation of "A Comprehensive Overhaul of Feature Distillation" (ICCV 2019)
本文的创新点
本文研究了知识蒸馏的各个方面,并提出了一种新的特征蒸馏方法,使蒸馏损失在教师特征变换、学生特征变换、特征蒸馏位置、距离函数各方面之间协同作用。具体来说,本文提出的蒸馏损失包括一个新设计的margin relu特征变换方法、一个新的蒸馏位置、以及一个partial L2距离函数。在ImageNet中,本文提出的方法使得ResNet-50取得了21.65%的top-1 error,优于教师网络ResNet-152的精度。
方法介绍
蒸馏位置
激活函数是神经网络的重要组成部分,它使网络具有了非线性。但之前的大部分蒸馏方法都没有考虑到激活函数,蒸馏位置大都在于某各个layer或某个block的尾端,却没有考虑和激活函数如ReLU的关系。本文提出的方法中,蒸馏位置位于某个layer的尾端和第一个ReLU之间,如下图所示

pre-ReLU的位置可以使学生接触到教师模型通过ReLU之间的信息,避免了信息的分解和丢失。
损失函数
由于蒸馏位置是在ReLU之前,因此特征中的正值包含教师会利用的信息而负值没有,如果教师网络中的值是正值,学生网络应该生成和教师一样的值,如果教师网络中是负值,学生也应该生成负值从而使得激活状态和教师一致。因此作者提出的教师变换函数,保存正值同时有一个负值margin
![]()
其中 \(m\) 是一个小于0的margin值,作者取名为margin ReLu。\(m\) 的具体值定义为每个通道的负响应值的期望,如下
![]()
\(m\) 一方面可以在训练过程中直接计算,如https://github.com/clovaai/overhaul-distillation/issues/7所示。也可以通过前一个BN层的参数来计算,作者在附录中给出了具体计算方法。
对于一个通道 \(\mathcal{C}\) 和教师特征 \(F^{i}_{t}\) 的第 \(i\) 个元素,该通道的margin值 \(m_{c}\) 为训练图片的期望值即式(3)。通常我们不知道 \(F^{i}_{t}\) 的分布,所以只能通过训练过程中的平均值来得到期望。但是ReLU前的BN层决定了一个batch中的特征 \(F^{i}_{t}\) 的分布,BN层将每个通道的特征归一化为均值 \(\mu\) 方差 \(\sigma\) 的高斯分布,即
![]()
每个通道的均值方差 \((\mu,\sigma)\) 对应BN层的参数 \((\beta,\gamma)\),因此利用 \(F^{i}_{t}\) 的分布可以直接计算边际值

利用高斯分布的概率密度函数pdf进行积分就可以得到期望,其中范围小于0。积分的结果可以通过正太分布的cdf累积分布函数 \(\Phi(\cdot)\) 进行简单的表示。
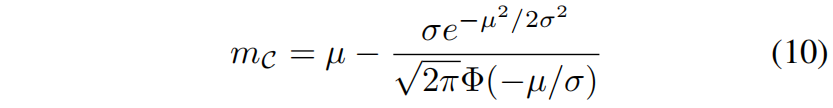
在官方实现中,也是通过这种方式即式(10)来计算margin值的。
因为蒸馏的位置是在ReLU函数前,negative response没有经过ReLU的过滤,因此蒸馏损失函数需要考虑到ReLU。在教师特征中,positive response实际上被网络使用,这意味着教师的正响应应该通过具体的值来传递,但负响应却不是。对于教师的负响应,如果学生的响应值高于目标值应该降低,而如果低于目标值不需要增加,因为不管具体值是多少都会被ReLU过滤掉。因此,本文提出了partial L2 distance函数,如下
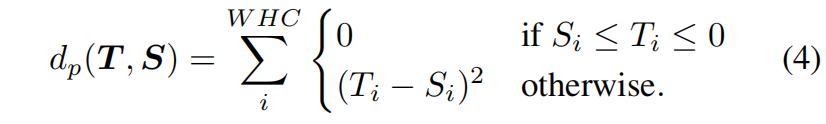
完整的蒸馏损失函数如下
![]()
其中 \(\sigma_{m_{c}}\) 是教师转换函数margin ReLU,\(r\) 是是学生转换函数1x1 conv + BN,\(d_{p}\) 是距离函数patial L2 distance。
实验结果
在CIFAR-100数据集上,不同的教师网络和学生网络的结果如表2所示

不同的教师-学生网络组合,本文的方法和其它蒸馏方法的结果对比如下,可以看出,在所有组合下,本文提出的方法都得到了最低的error。

在ImageNet数据集上和其它方法的对比如表4,可以看出本文的方法error也是最低的。

代码解析
实现代码主要在distiller.py中,本文的第一个创新点在蒸馏的位置,即ReLU前,实现如下
t_feats, t_out = self.t_net.extract_feature(x, preReLU=True)
s_feats, s_out = self.s_net.extract_feature(x, preReLU=True)学生特征的转换为1x1卷积+BN,即实现中的self.Connectors,具体实现如下
def build_feature_connector(t_channel, s_channel):
C = [nn.Conv2d(s_channel, t_channel, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(t_channel)]
for m in C:
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
return nn.Sequential(*C)教师特征的转换为本文提出的margin ReLU,边际margin值的计算如下,即上述的式(10)
def get_margin_from_BN(bn):
margin = []
std = bn.weight.data
mean = bn.bias.data
for (s, m) in zip(std, mean):
s = abs(s.item())
m = m.item()
if norm.cdf(-m / s) > 0.001:
margin.append(- s * math.exp(- (m / s) ** 2 / 2) / math.sqrt(2 * math.pi) / norm.cdf(-m / s) + m)
else:
margin.append(-3 * s)
return torch.FloatTensor(margin).to(std.device)蒸馏损失函数实现如下,其中第一行就是教师特征的转换函数,即式(2)
def distillation_loss(source, target, margin):
target = torch.max(target, margin)
loss = torch.nn.functional.mse_loss(source, target, reduction="none")
loss = loss * ((source > target) | (target > 0)).float()
return loss.sum()