作者主页:爱笑的男孩。的博客_CSDN博客-深度学习,活动,python领域博主爱笑的男孩。擅长深度学习,活动,python,等方面的知识,爱笑的男孩。关注算法,python,计算机视觉,图像处理,深度学习,pytorch,神经网络,opencv领域.
https://blog.csdn.net/Code_and516?type=blog个人简介:打工人。
持续分享:机器学习、深度学习、python相关内容、日常BUG解决方法及Windows&Linux实践小技巧。
如发现文章有误,麻烦请指出,我会及时去纠正。有其他需要可以私信我或者发我邮箱:zhilong666@foxmail.com
朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,它利用先验概率和条件概率推导出后验概率,从而进行分类。该算法被广泛应用于自然语言处理、垃圾邮件过滤和文本分类等领域,并且在很多数据挖掘竞赛中获得了优秀的结果。Python版本的朴素贝叶斯算法也被广泛使用,由于其易于实现和高效性能,成为了数据科学家和机器学习工程师的首选算法之一。
本文将详细讲解机器学习十大算法之一 “朴素贝叶斯”
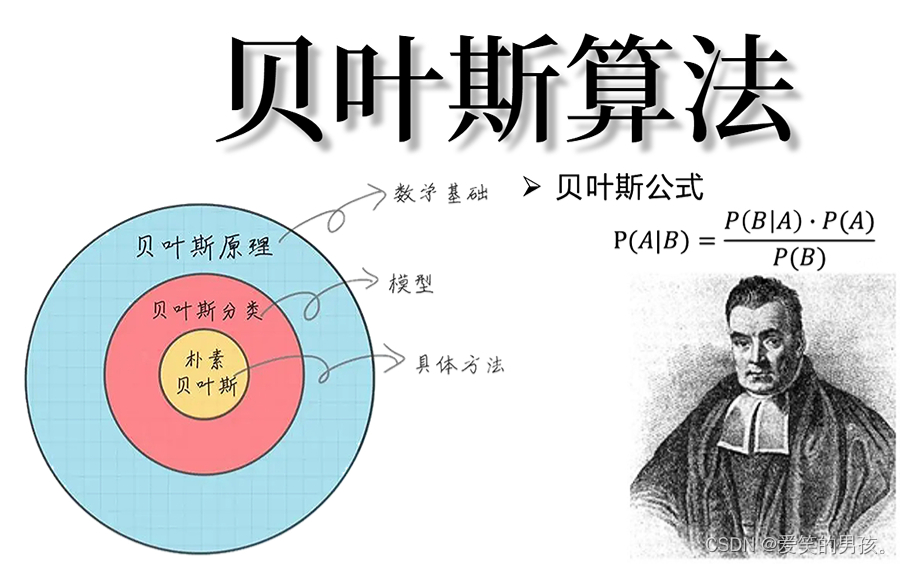
目录
一、简介
二、发展史
三、算法原理、功能讲解
1. 贝叶斯定理
2. 朴素贝叶斯
3. 拉普拉斯平滑
4. 处理连续值特征
5. 朴素贝叶斯分类器的生成
朴素贝叶斯分类器的生成包括以下几个步骤:
6. 朴素贝叶斯算法的假设
7. 朴素贝叶斯算法的优点和缺点
朴素贝叶斯算法具有以下优点:
朴素贝叶斯算法的缺点主要有以下几个:
四、实现朴素贝叶斯算法
实现步骤
完整代码
五、总结
一、简介
朴素贝叶斯算法是一种监督学习的算法,通过计算条件概率来预测或分类数据。它的核心思想是贝叶斯定理,即后验概率等于先验概率与似然函数的乘积除以证据因子。
在文本分类的应用中,假设我们有一个文档和一个文档分类,我们想要判断这个文档属于哪个分类。我们可以将文档中的每个词都看作一个特征,每个特征的值为 0 或 1,0 表示该词不在文档中,1 表示该词在文档中。这样,我们就可以将每个文档表示为一个特征向量。然后,我们可以使用朴素贝叶斯算法来计算每个分类的条件概率,并选择条件概率最大的分类作为文档所属的分类。
二、发展史
朴素贝叶斯算法最早可以追溯到18世纪的贝叶斯学派。但是,直到20世纪60年代,才有了将贝叶斯方法用于文本分类的尝试。最早的一篇文献是由Thomas Bayes的朋友Richard Price在1763年发表的《An Essay towards solving a Problem in the Doctrine of Chance》。它提出了贝叶斯规则,构成了朴素贝叶斯算法的核心。
在20世纪60年代,刚刚问世的计算机开始被广泛使用,使得大规模文本分类成为可能。此时,发展起了文本分类领域的先驱性研究,G. Salton 等人提出了矢量空间模型和 TF-IDF 权重算法,但是它们都依赖于一个主题词典或类别词汇表。
直到20世纪80年代,朴素贝叶斯算法成为文本分类中最重要的方法之一。 Paul Dressel 和 Donald Bienenstock 的著名论文《SVMs and the Bayes Kernel》中,他们通过 SVM 与朴素贝叶斯算法的比较得出,朴素贝叶斯算法相对于 SVM 算法有着更高的准确率。
现在,朴素贝叶斯算法已经成为自然语言处理领域中最常用的算法之一。
三、算法原理、功能讲解
朴素贝叶斯算法是一种基于概率论和统计学的算法。它的核心思想是概率,通过计算条件概率来预测或分类数据。在此之前,我们需要了解一下几个与朴素贝叶斯算法相关的概念。
1. 贝叶斯定理
贝叶斯定理是朴素贝叶斯算法的核心,它是一个概率公式,用于计算一个事件的后验概率。根据贝叶斯定理,事件 A 的后验概率等于先验概率 P(A),与另一个事件 B 发生的联合概率 P(B|A) 乘以一个正则因子,即:

其中,P(A) 和 P(B) 是事件 A 和事件 B 的先验概率,P(B|A) 是给定事件 A 发生的情况下事件 B 发生的条件概率,P(A|B) 是在事件 B 发生的条件下事件 A 的后验概率。
2. 朴素贝叶斯
朴素贝叶斯算法假设所有特征之间是相互独立的。这一假设称为朴素贝叶斯假设,因此该算法称为朴素贝叶斯算法。
对于一个文本分类问题来说,每个文档可以表示为一个特征向量。特征向量的每个维度都表示一个词,在该文档中出现(1)或未出现(0)。我们假设每个特征的取值都是二元的,即 0 或 1。因此,该算法可以将文档表示为一个特征数量为n的向量 X=(x_1,x_2,...,x_n)X=(x1,x2,...,xn),其中每个特征都是 0 或 1。
在朴素贝叶斯算法中,我们需要计算每个分类的条件概率,即:
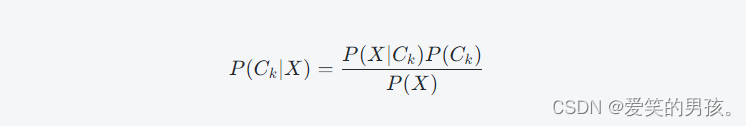
其中,k 是分类的编号,C 是分类的所有可能值,P(C_k|X) 是给定特征向量 X 时分类为 C_k 的概率,P(X|C_k) 是给定分类 C_k 时特征向量 X 出现的条件概率,P(C_k) 是分类 C_k 的先验概率,P(X) 是文档出现的概率。
根据朴素贝叶斯假设,每个特征之间是相互独立的,因此可以将 P(X|C_k) 表示为:

这样我们就可以计算每个分类的条件概率 P(C_k|X)。将条件概率最大的分类作为文档所属的分类。
在实际应用中,我们需要对每个分类建立一个模型,该模型可以通过训练数据集中的文档来获得。训练数据集中的文档被分成 k 类,每个文档表示为一个特征向量,我们通过计算每个特征在每个分类中出现的次数来推导出每个分类的条件概率。这样,我们就可以使用朴素贝叶斯算法来预测分类。
3. 拉普拉斯平滑
在计算条件概率时,由于某个特征在某个分类中可能没有出现,因此该特征在该分类中的条件概率可能为 0。此时,当我们尝试计算某个文档可能属于哪个分类时,我们会因为概率计算出错而得到错误的结果。
拉普拉斯平滑是一种解决这个问题的方法。基本思想是为某个分类和某个特征分配一个小的数量,这样可以避免条件概率为 0。
假设我们有 N 个文档,其中 M 个文档属于分类 C_k,那么拉普拉斯平滑可表示为:
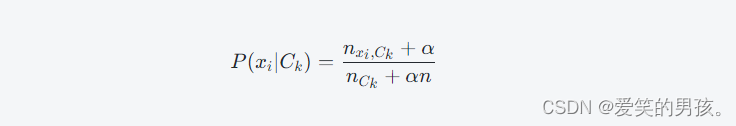
其中,n 是分类的数量,n_{C_k}nCk 是分类 C_k 中的文档数量,n_{x_i,C_k}nxi,Ck 是分类 C_k 中包含词 x_ixi 的文档数量,\alphaα 是平滑参数,通常取 1。
4. 处理连续值特征
对于一些连续值特征(例如房价、温度等),我们可以使用正态分布来拟合其值。在这种情况下,我们可以使用高斯朴素贝叶斯算法来计算连续值特征的条件概率。高斯朴素贝叶斯算法假设特征的值服从正态分布,因此可以使用高斯分布来拟合连续值特征。
5. 朴素贝叶斯分类器的生成
朴素贝叶斯分类器的生成包括以下几个步骤:
(1)计算每个类别的先验概率,即某个样本属于某一类别的概率。在朴素贝叶斯中,先验概率可以根据样本集中每个类别的样本数计算得到。
(2)计算每个特征与目标变量之间的条件概率。这就相当于计算每个类别下的每个特征值的概率。在朴素贝叶斯中,条件概率可以使用频率来估计,即将训练集中某个类别下某个特征值出现的次数除以该类别下总的样本数。
(3)对于待预测的新样本,根据所属类别的后验概率,将其分类为概率最大的那一类。
6. 朴素贝叶斯算法的假设
朴素贝叶斯算法的假设是:所有的特征都是独立的。即样本的特征之间没有任何关联。这个假设虽然在实际生活中不太现实,但是这个假设为朴素贝叶斯算法带来了高效性和可靠性。
在实际应用中,朴素贝叶斯算法的独立性假设不一定能完全成立,但是在处理垃圾邮件过滤、文本分类等任务时,朴素贝叶斯算法的表现仍然优秀。
7. 朴素贝叶斯算法的优点和缺点
朴素贝叶斯算法具有以下优点:
(1)朴素贝叶斯算法是基于概率论的一种算法,具有可解释性和可理解性。
(2)算法实现简单,易于理解和实现。
(3)朴素贝叶斯算法在处理高维度数据时表现出色,适用于文本分类、垃圾邮件过滤等应用场景。
朴素贝叶斯算法的缺点主要有以下几个:
(1)朴素贝叶斯算法的独立性假设在实际应用中不一定成立,可能会带来误差。
(2)朴素贝叶斯算法对输入数据的质量要求较高,不适用于处理缺失数据等问题。
(3)朴素贝叶斯算法在处理少量数据时,可能会出现误判率较大的问题。
四、实现朴素贝叶斯算法
实现步骤
现在,我们来使用 Python 来实现朴素贝叶斯算法。本文将使用 scikit-learn 库来实现算法。
首先,我们需要安装 scikit-learn 库,可以使用 pip 或 conda 来安装。
在命令行中输入以下命令:
pip install -U scikit-learn
或
conda install scikit-learn
接下来,我们将使用 scikit-learn 中的 load_iris 函数来加载 iris 数据集。这个数据集包含了三种不同的鸢尾花(setosa、versicolor、virginica)及其花萼长度、花萼宽度、花瓣长度和花瓣宽度等特征。为了简单起见,我们将只使用前两个特征(即花萼长度和花萼宽度)。
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :2] # 使用前两个特征
y = iris.target
接下来,我们将数据集分成训练集和测试集。我们将采用训练集对模型进行训练,并在测试集上试模型的准确率。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
接下来,我们将使用 GaussianNB 类来拟合模型。GaussianNB 类的 fit 方法用于拟合训练数据。拟合后,我们可以使用 predict 方法来预测新的样本所属的分类。
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train, y_train)
y_pred = gnb.predict(X_test)
最后,我们可以使用 accuracy_score 函数来计算模型在测试集上的准确率。结果表明,模型在测试集上的准确率为 82.22%。
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
输出结果如下:
Accuracy: 0.8222222222222222
完整代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data[:,:2]
y = iris.target
# 将数据集拆分为训练集和测试集
train_data, test_data, train_target, test_target = train_test_split(X, y, test_size=0.3, random_state=0)
# 实例化模型
gnb = GaussianNB()
# 训练模型
gnb.fit(train_data, train_target)
# 预测测试集
pred = gnb.predict(test_data)
# 计算准确率
accuracy = accuracy_score(test_target, pred)
print("准确率为:", accuracy)
五、总结
本文讲解了 Python 版本的朴素贝叶斯算法,包括简介、发展史、算法功能详解、示例代码加运行结果等方面。
朴素贝叶斯算法是一种基于概率论和统计学的算法,被广泛应用于自然语言处理、文本分类、垃圾邮件过滤、情感分析等领域。该算法通过计算条件概率来预测或分类数据。本文提供了一些在 Python 中使用朴素贝叶斯算法的示例代码,希望能帮助大家更好地理解该算法。
因为我是直接用的分类器,所以本文没有朴素贝叶斯算法的底层源码,如果想了解最原始的源码,可以自行去寻找一下材料,简单易懂~