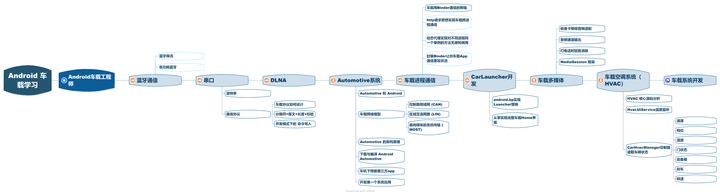
1 介绍:
RabbitMQ 是一个开源的消息中间件,它实现了 AMQP(高级消息队列协议)标准,并且支持多种语言和操作系统,包括 Java、Python、Ruby、PHP、.NET、MacOS、Windows、Linux 等等。RabbitMQ 提供了可靠的消息传递机制,能够保证消息的可靠性和可靠传输,同时还支持消息的路由与转发,能够实现灵活的消息处理模式。
RabbitMQ 的核心概念是消息、生产者、消费者和队列。生产者通过发送消息到队列中,而消费者则从队列中接收消息。RabbitMQ 支持多个消费者从同一队列中接收消息,从而实现集群的负载均衡和高可用性。
RabbitMQ 支持多种交换机类型(Direct、Fanout、Topic、Headers),使得用户可以根据业务需求选择不同的交换机类型,实现不同的消息路由逻辑。此外,RabbitMQ 还支持队列内的消息单个或批量的确认,保证了消费者接收到消息的可靠性。
总之,RabbitMQ 是一款功能强大的消息中间件,它的特点是可靠性、可扩展性、可路由性、高可用性、多语言支持等等。它被广泛应用于企业级应用程序,如分布式系统、互联网和大数据等领域。
2 工作流程:
2.1 工作过程:
RabbitMQ 的核心组件包括生产者、消费者、队列、交换机和绑定,它们的工作流程如下:
- 生产者将消息发送到交换机,消息被路由到一个或多个队列。
- 队列中有消费者消费消息,消费者从队列中获取消息并进行处理。
- 如果消费者无法处理消息,或者出现异常情况,消息会被发送到死信交换机或进行重试。
- 如果消费者成功处理消息,会发送一个确认消息给 RabbitMQ,RabbitMQ 将从队列中删除该消息。
在这个过程中,队列、交换机和绑定起到了关键作用。队列用于存储消息,交换机用于路由消息,绑定用于将交换机和队列关联起来。
当生产者发送消息时,它指定了一个交换机和一个路由键。交换机根据路由键将消息路由到相关队列。这个过程又可以被分为四种类型:
- Direct:按照指定的路由键将消息发送到与之匹配的队列中。
- Fanout:发送到所有绑定到交换机的队列中。
- Topic:发送到匹配到路由键的队列中。
- Headers:根据消息头(header)中的属性进行匹配,将消息发送到符合条件的队列中。
消费者从队列中获取消息,并进行处理。如果发生错误或异常,消费者会暂停获取消息,等待一段时间后再次尝试。如果多次尝试都失败,则会将该消息发送到死信交换机或进行重试。
最后,如果消费者成功处理了消息,它会发送一个确认消息给 RabbitMQ,告诉 RabbitMQ 已经成功地处理了该消息。RabbitMQ 将从队列中删除该消息,保证消息只会被消费一次。
2.2 工作模型:
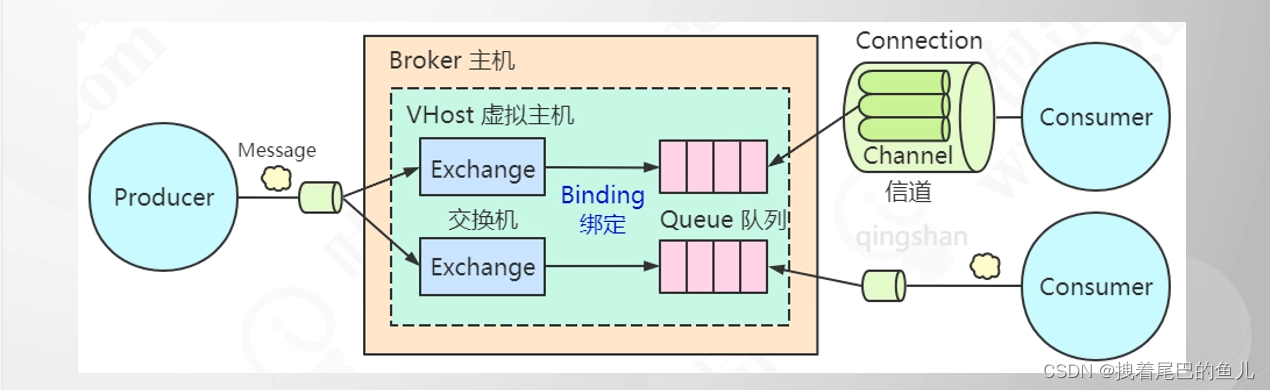
- Producer 生产者用于发送消息;
- Broker Rabbitmq 服务器;
- VHost :虚拟主机,一个broker 中可以创建多个vhost 用于不同 生产端和消费端的连接,用于服务级别的隔离;
- Exchangel:消息交换机,通过绑定Queue ,当消息到来时可以路由到对应的队列中;
- Channel :消息的传输管道,Channel 是一个接收消息的 “道路”(或者说信道)。在一个 RabbitMQ 连接中,可以打开多个 Channel。一个 RabbitMQ 连接的信道数量是有限制的,但是通过合理的资源管理可以提高每个连接中信道的数量;
2.3 消息发送:
RabbitMQ 客户端(Producer)发送消息到服务端(Broker)的:步骤如下:
-
建立 TCP 连接:客户端与服务器建立一个 TCP 连接,用于传输消息。
-
创建虚拟连接:在 TCP 连接之上,创建一个 AMQP 虚拟连接。
-
创建通道:在 AMQP 虚拟连接之上,创建一个 AMQP 通道。后续的消息传输将在该通道中进行。
-
声明队列:如果队列不存在,客户端将在服务端上声明一个队列。
-
发布消息:向队列发布消息。
-
关闭通道:完成消息发布之后,关闭 AMQP 通道。
-
关闭虚拟连接:完成消息发布之后,关闭 AMQP 虚拟连接。
-
关闭 TCP 连接:最后,断开 TCP 连接。
2.3.1 客户端 TCP 链接的建立:
客户端连接的建立有两种模式CHANNEL和 CONNECTION,可以通过配置项进行设置:
# spring.rabbitmq.cache.connection.mode = connection
spring.rabbitmq.cache.connection.mode = channel
模式项选择:
public static enum CacheMode {
CHANNEL,// 缓存管道模式
CONNECTION;// 缓存连接模式
private CacheMode() {
}
}
2.3.2 两种模式的介绍:
首先我们需要知道一个CONNECTION 对象中可以创建多个Channle 对象用于通信;而客户端默认使用的模式是CHANNEL 模式;
2.3.2.1 CONNECTION 缓存模式: 缓存的对象是 Connection 对象,即连接对象;
- 在 CONNECTION 缓存模式下,连接会被缓存,并在需要时重新使用。
- 每个线程都可以使用 Connection 对象的一个实例,而多个线程将共享相同的连接池。
- 当线程需要连接时,它会从连接池中获取可用连接并使用它。 如果没有可用的连接,线程将等待,直到另一个线程释放连接。
- 由于 Connection 是一个长期存在的对象,因此在创建连接时需要耗费相对较多的 CPU 和内存资源。
- 默认的连接池大小为1 ,可以通过以下命令配置连接池的大小,如果您将此值设置为 0,则使用的是无限大的线程池(只有在CONNECTION 模式下改参数才生效):
spring.rabbitmq.cache.connection.size=25
使用改模式的注意事项:
事项(1):连接池大小 设置
-
在 RabbitMQ 客户端中,每个连接都由一个专用线程处理 IO 操作。这意味着,在任何给定时间,一个连接只有一个线程可以进行 I/O 操作。当某个I/O操作在该线程中进行时,其他I/O操作必须等待该操作完成后才能获得该线程;
-
在连接缓存模式下,每个缓存的连接都具有一个专用线程。这意味着,如果使用了连接缓存模式并且只有一个连接,则只有一个线程会执行所有 I/O 操作,包括消息发送和接收。如果在同一时间有多操作要进行,那么其中某些操作就会在等待线程空闲时被阻塞,从而降低了应用程序的性能;
-
虽然可以在一个连接上创建多个通道(Channel),但是所有通道都必须共享该连接的专用线程。当一个通道正在进行I/O操作中时,其他通道将被阻塞,并且必须等待该操作完成后才能获得该线程;
-
增加连接池的大小可以提高您应用程序的并发能力,并且避免因线程阻塞而导致您的应用程序性能下降的情况;
总之,RabbitMQ 客户端中的每个连接都由一个专用线程处理 I/O 操作,并且在连接缓存模式下,每个缓存的连接都具有一个专用线程。在单一连接上创建多个通道可以提高连接的复用性,但是所有通道仍然必须共享该连接的专用线程。如果专用线程繁忙,任何通道上的操作都可能被阻塞。
事项(2):效率问题:
对于多线程环境下使用 RabbitMQ 的情况,使用此模式的优点是 Connection 对象能够自动适应多线程环境,同时能够提供多个 Channel 对象,从而提高并发能力;但是,如果同时启用了确认模式或事务模式,则该模式的效率可能会降低。
2.3.2.2 CHANNEL 缓存模式:缓存的对象是 Channel象,即信道对象;
-
使用此模式,多个线程会共享同一个 Connection 实例;
-
使用此模式,每个线程会使用自己的 Channel,多个线程可以并发使用多个 Channel,但是不同线程之间不能共享同一个 Channel;
-
因为 Channel 对象是轻量级的对象,而Connection 对象则是重量级的对象,所以选择 CHANNEL 缓存模式会比选择 CONNECTION 更加轻量化,从而提高应用程序的性能;
总之,在 CHANNEL 缓存模式下,多个线程都可以共享同一个 Connection 实例,而每个线程又都自己持有独立的 Channel 实例,而不会相互干扰,这样可以最大程度地提高并发处理量,从而提高应用程序的性能和效率。对于高并发的情况,建议使用该模式。但是,如果对缓存对象的数量有限制,则可能会受到影响。
2.3.2.3 对每个connection连接中 channel 管道数量的设置:
spring.rabbitmq.cache.channel.size=50
spring.rabbitmq.cache.channel.size 是 Spring Boot 集成 RabbitMQ 客户端连接工厂(ConnectionFactory)的一个属性,用于设置缓存的通道(channel)数量。它可控制应用程序与 RabbitMQ Broker 之间的通道(channel)复。
-
在 RabbitMQ 中,设备连接(Connection)是相对昂贵的,因此创建一个新的设备连接需要消耗较高的资源。但是,创建通道(Channel)的消耗非常低。因此,建议不要创建太多的设备连接,相反,可以使用一些可重用的通道来处理大量的I/O操作。
-
缓存通道是一项优化技术,它可以在相同的设备连接上重新使用通道,从而减少初始化通道的开销,提高生产力。
-
spring.rabbitmq.cache.channel.size 定义了每个连接缓存的通道的数量,因此可以控制缓存的通道的数量。当您的应用程序需要许多通道时,缓存通道会提高性能,而不需要每次发送消息时重新初始化新通道。在这种情况下,较高的通道缓存大小可能会提高吞吐量,因为它可以处理更多的消息并可重用通道,而不是创建新的通道。
-
但是,连接池和通道缓存的大小应该在业务性能和可用资源之间进行权衡。如果缓存的通道数量过高,将会占用过多的资源,并可能对应用程序的性能产生负面影响。在另一方面,如果设置的通道缓存过于小,则可能会导致频繁地创建和删除通道,从而增加了通道的开销。
总之,spring.rabbitmq.cache.channel.size 是应用程序的可配置属性,可用于优化连接池和通道复用。通过设置正确的值,可以提高应用程序的性能并最大程度地减少应用程序的资源占用。
2.3 消费消息:
RabbitMQ 消费端消费消息的步骤如下:
- 创建连接和通道:消费端需要先创建连接和通道,连接用于连接 RabbitMQ 服务器,通道用于发送和接收消息。
- 声明队列:消费端需要声明要消费的队列,如果队列不存在,则需要创建。
- 设置消费者:消费端需要设置消费者并指定消费的队列。消费者在接收到消息后,会触发回调函数进行消息处理。
- 接收消息:消费者通过
basicConsume方法开始接收消息。当有消息到达队列时,消费者会自动触发回调函数进行消息处理。 - 消息确认:消费端在处理完消息后,需要向 RabbitMQ 服务器发送确认消息,告诉服务器已经成功消费了该消息。如果消费端没有发送确认消息,RabbitMQ 服务器会认为该消息没有被成功消费,并重新将该消息发送给其他消费者。
- 关闭通道和连接:消费端在处理完所有消息后,需要关闭通道和连接。
总之,消费端需要创建连接和通道,声明队列,设置消费者,接收消息,消息确认,并在处理完所有消息后关闭通道和连接。
2.3.1 连接和通道的创建:
消费连接的创建和连接中channel 的创建,与生产端类似它们的区别介绍如下:
-
连接对象的创建方式不同:消费端和生产端的连接对象创建方式一样,都是通过 RabbitMQ 的客户端 API 创建连接对象。但是,在生产端,通常通过 ConnectionFactory 创建连接对象,并设置相关属性,例如连接到 RabbitMQ 服务器的主机名、端口号、用户名、密码等等。而在消费端,则通常需要使用生产端创建出来的 ConnectionFactory 对象创建连接对象。
-
通道的目的不同:在生产端,通道主要用于将消息发送到队列中,而在消费端,通道主要用于从队列中接收消息。因此,它们在通道的声明和使用方法上可能略有不同。
-
声明和供应队列的职责不同:在生产端,通常会在应用程序启动时声明队列,并供应给消费端,以确保在生产者发送消息之前,队列已经存在并已经绑定了交换机。在消费端,通常还需要重复声明队列,以确保队列已经存在并且符合消费者的需求。
-
对消息的处理方式不同:在生产端,通常是将消息封装到消息对象中,包括消息体、路由键和一些元数据信息,然后发送到相应的队列中。而在消费端,通常是使用回调函数接收队列中的消息,并在回调函数中处理消息体。
2.3.2 消息的消费:
2.3.2.1 可以设置消费者的线程数量来提高消费的速度(此方法并不是批量消费):
# 并发消费最小线程数
spring.rabbitmq.listener.simple.concurrency=1
# 并发消费最大线程数
spring.rabbitmq.listener.simple.max-concurrency=1
2.3.2.2 消息消费后的确认有3种:none ;AUTO;MANUAL:
- none 表示消费者不会发送任何确认消息给 RabbitMQ,即消息会被消费者收到并立即从队列中删除,而不管消费者是否成功处理该消息。因此,将 acknowledge-mode 设置为 none 可能会导致消息丢失和重复消费的问题;
- AUTO: 自动确认消息。当消费者成功处理完消息时,会自动发送 ack 消息,表示消息已经被成功消费;当消费者处理消息时发生异常时,会自动发送 nack 消息,表示消息消费失败,需要重新进入队列进行重;
- MANUAL: 手动确认消息。消息处理函数必须调用 Channel#basicAck(long deliveryTag, boolean multiple) 方法来确认消息,deliveryTag 表示该消息的标识符,multiple 表示是否批量确认。如果该方法没有得到调用,则消息会被重新加入队列,等待消费者重新消费;
其中最常用的应该就是MANUAL 消费消息后手动提交ack 确认:
@RabbitListener(queues = "my_queue_one")
public void receiveMessage(List<Message> messages, Channel channel) throws IOException {
log.debug("逐条消费消息:{}", messages);
for (Message message : messages) {
try {
// 处理消息
log.debug("Received message: {}" , message);
// 手动发送 ack 消息
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception ex) {
// 发生异常,手动发送 nack 消息
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, true);
}
}
}
channel.basicAck 是 RabbitMQ Java 客户端库中的一个方法,用于向 RabbitMQ 服务器发送确认消息,表示消息已经被成功消费。该方法的参数含义如下:
- deliveryTag :表示消息的唯一标识符,是一个非负整数。每个消息的 deliveryTag 是唯一的,用于标识 RabbitMQ 服务器上的消息。
- multiple :表示是否批量确认消息。当该参数设置为 true 时,表示确认所有 deliveryTag 小于等于当前 deliveryTag 的所有消息;当该参数设置为 false 时,表示只确认当前 deliveryTag 对应的消息。
需要注意的是, channel.basicAck 方法只能在消费者接收到消息后调用,用于告知 RabbitMQ 服务器消息已经被成功消费,否则消息会一直保留在队列中,直到消费者发送确认消息为止。在使用该方法时,需要确保消费者已经成功处理了消息,避免消息重复消费或者丢失的问题;
message.getMessageProperties().getDeliveryTag() deliveryTag 属相介绍:
RabbitMQ 服务端对每条消息的 deliveryTag 属性是在处理消费者的 basic.deliver 命令时设置的。当消费者注册到队列并开启消费之后,服务端会发送 basic.deliver 命令到消费者,该命令中包括了消息的 deliveryTag 属性。
-
deliveryTag 属性是一个递增的整数值,它用于表示传递给消费者的消息的唯一标识符。在缺省情况下,RabbitMQ 服务端将 deliveryTag 属性设置为从 1 开始的递增值,即第一条消息的 deliveryTag 属性为 1,第二条消息的 deliveryTag 属性为 2。
-
消费者通过回调函数接收到消息后,可以调用
channel.basicAck方法来确认接收到这条消息,并将 deliveryTag 属性值传递给 RabbitMQ 服务端。消费者确认接收到消息后,RabbitMQ 服务端将清除所有 deliveryTag 属性值小于等于确认消息 deliveryTag 属性的消息。 -
需要注意的是,当消费者拒绝一条消息或者一条消息上发生错误时(例如消息处理失败),消费者可以使用
channel.basicNack方法将消息返回到队列中,并指定需要重新处理的标志位。此时,RabbitMQ 服务端也会重新设置 deliveryTag 属性,保证递增不重复。
2.4 消息的存储:
rabbitmq 中的消息都存储与队列中,类似于java 的 ArrayList;RabbitMQ 服务端中 Queue 的存储结构采用了一种基于数组和内存映射文件的混合结构,称之为 Slab Allocator。
-
Slab Allocator 是一种高效的内存分配方式,用于管理可变长度的数据结构,例如 Linked List 或 Hash Table,它的基本思路是预先分配一块足够大的内存区域,然后将其划分成若干个固定大小的块(Slab),每个 Slab 可以存储固定大小的对象(Chunk)。当需要分配新的对象时,从 Slab 中选择一个空闲的 Chunk 进行分配,并将其标记为已使用。当需要释放对象时,将其标记为空闲状态,不释放 Chunk 的内存,便于下次分配时复用。
-
RabbitMQ Queue 是一个基于 Linked List 的 FIFO 队列,Slab Allocator 就是用来管理 Linked List 中的节点的内存分配的。其中,使用到了一种称为 “Page Cache” 的内存管理机制,将内存的分配和释放操作转化为读写操作,以减少操作系统的系统调用,从而提高性能。
-
在 Java 中,类似的数据结构是 ArrayList、LinkedList 等。但是需要注意的是,RabbitMQ 服务端的 Queue 存储结构并不完全相同,Slab Allocator 采用了一些 C 语言中的特性,例如内存映射文件等,在实现上与 Java 的数据结构有一些区别。
-
在 RabbitMQ 中,一个 Queue 只对应一个队列。一个 Queue 的作用就是暂存待处理的消息,消费者在 Queue 上订阅消息。多个消费者可以同时消费同一个 Queue 中的消息,但这些消费者实际上是在不同的通道上消费的,而不是在 Queue 上直接消费。
-
在 RabbitMQ 中,可以通过设置不同的 Routing Key 和绑定到不同的 Exchange 上来实现向多个 Queue 中发送同一份消息,从而达到消息的分发目的。不同的 Queue 可以有不同的消费者数量、处理速度以及消息的处理方式,以实现不同的业务场景需求。
-
值得注意的是,一个 Queue 虽然只对应一个队列,但是可以被多个 Exchange 绑定,或者多个 Routing Key 绑定到同一个 Exchange 上,进而接收来自多个生产者的消息。
2.5 顺序消费消息:
在 RabbitMQ 中,队列的消息消费是默认按照先进先出(FIFO)的顺序进行的,也就是说消息会按照发送的顺序,依次进入队列后按顺序被消费者取出并处理。
如果想要确保队列中消息的顺序性,在消息发送时需要保证消息的 Routing Key 相同,或将其绑定到同一个 Exchange 上。这样就可以通过消费者的数量来控制并发度,来保证同一 Routing Key 或同一个 Exchange 相关的消息,按先进先出的顺序被消费。
需要注意的是,RabbitMQ 并不能完全保证消息消费的顺序性。在多消费者并发消费的情况下,消费者在取出消息并处理时的速度不同,也可能会导致消息的错误顺序消费。因此,在某些应用场景下,需要通过控制消费者的并发度、优化消费端处理能力、设计状态机等方式来确保消息顺序的强一致性。
2.6 延迟消息:
RabbitMQ Delayed Message Exchange插件可以让我们在RabbitMQ中实现延迟消息。该插件会在RabbitMQ中添加一个新的交换机类型,即x-delayed-message。使用该插件时,我们需要在RabbitMQ服务器上安装该插件,并创建一个x-delayed-message类型的交换机,然后将消息发送到该交换机中,RabbitMQ会根据消息中的延迟时间将消息路由到对应的队列中。
RabbitMQ 延迟插件不支持 mandatory=true 参数,如果启用会同时收到延迟消息和路由失败消息;因为 RabbitMQ 在实现延迟队列时使用了死信交换机的机制,而死信交换机会在消息无法匹配到队列时进行重发和路由。在这种情况下,如果开启了 mandatory 参数,那么无法匹配到队列的消息就会被视为不可路由,从而触发 ReturnCallback,同时也会在消息到期后被重新路由到延迟队列中,如果在ReturnCallback 方法中重写进行消息的发送,最终会有两条相同的消息,导致该消息被重复消费,这就是同时收到延迟消息和路由失败消息的原因。
所以在生产者发送消息的确认机制中需要排除延迟消息:
@Autowired
RabbitTemplate rabbitTemplate;
// 设置 ConfirmCallback 回调函数 确认消息是否成功发送到 Exchang
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
if (null == correlationData) {
// 延迟消息 correlationData 为null
return;
}
log.debug("Message sent successfully:{} ", correlationData.getId());
} else {
if (null == correlationData && null == cause) {
// 延迟消息 correlationData 为null
return;
}
// 失败消息处理
log.error("Message sent failed: {}", correlationData.getId() + ", cause: " + cause);
}
});
// ReturnCallback 处理的是未路由的消息返回的情况
rabbitTemplate.setReturnCallback((oneMessage, replyCode, replyText, exchange, routingKey) -> {
// 判断是否是延迟消息
if (routingKey.indexOf("delay") != -1) {
// 是一个延迟消息,忽略这个错误提示
return;
}
// 失败消息处理
log.debug("Message returned: {}", new String(oneMessage.getBody()) + ", replyCode: " + replyCode + ", replyText: " + replyText + ", exchange: " + exchange + ", routingKey: " + routingKey);
});
return "producerAckMessage";
}
因为延迟消息的确认correlationData 是null 所以需要进行一次非空判断;
correlationData 是 RabbitMQ 中用于将生产者发送的消息与消费者接收的消息进行关联的一个重要参数。具体来说,它的作用包括:
-
确认消息是否成功到达目标队列:当生产者发送消息时,可以在发送消息时携带一个唯一的 correlationData,当消息成功到达目标队列时,消费者会将 correlationData 返回给生产者的 ConfirmCallback 回调方法,这样生产者就可以通过 correlationData 确认消息是否已经成功到达目标队列。
-
区分消息的处理结果:在消息被消费者处理后,消费者可以将 correlationData 返回给生产者的 ReturnCallback 回调方法,通知生产者消息的处理结果,告知生产者是否需要进行重发等操作。
-
技术实现:在实现消息应答机制时,需要使用 correlationData 来将消费者消费的消息与生产者发送的消息进行关联,从而保证消息的可靠传输。
-
因此,correlationData 是 RabbitMQ 中一个非常重要的参数,可以帮助消息生产者和消费者进行消息关联和消息追踪,并确保消息的可靠传输。
-
延迟消息本质上是使用 RabbitMQ 的 TTL(生存时间)和死信交换机特性实现的,它会将消息发送到一个指定的延迟队列中,然后在指定的延迟时间过后再将消息转发到实际的目标队列中。在这个过程中,消息的 correlationData 在延迟队列中是没有意义的,因为它仅用于确认消息是否正确发送到实际的目标队列中。
3 总结:
生产端:
- 生产端的消息发送是通过绑定交换机,通过路由建,进入到最终消息存储的queue 队列中,然后进行消息的实例化;
- 生产端在发送消息失败时,可以通过重试机制(默认3次),完成消息的重新发送,(消息重试有可能造成消息的重复);
- 生产端可以通过confirm 确认消息发送是否成功,当重试一定次数后 ,调用ConfirmCallback 可以通过ack 确认消息是否发送成功,可用通过correlationData.getId() 得到消息的业务id;
- 生产端发送消息时可以通过new CorrelationData(消息唯一id) ,设置消息的唯一id,用作ConfirmCallback 中消息的业务判断;
- 对于延迟消息的发送因为会在过期后 在到绑定的队列中,所以会返回消息没有路由键匹配的问题,但是消息实际已经在过期后成功进入到队列中,并且ConfirmCallback 返回的CorrelationData 是null;
消费端:
- 消费端通过channel 管道绑定想要queue 队列,进行单个或者批量消费;
- 在义务中一般在消费消息之后都需要手动提交ack 给到rabbitmq 服务端,从而rabbitmq 服务端将队列中改消息进行移除,消费端提交到rabbitmq 服务端队列的消息标识为消息的顺序编码;
- 当消息失败时,消费端可以启动重试机制,完成消费,一定次数后仍然失败会被被重新入队;
4 参考:
4.1 Java 客户端 API 指南;
4.2 rabbitmq 配置;