目录
前言
课题背景和意义
实现技术思路
实现效果图样例
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器视觉的手写字识别系统
课题背景和意义
本文是属于手写体文字识别应用,旨在基于MindSpore AI计算框架和Atlas实现手写汉字拍照识别系统。该系统能够对写在纸上的多个汉字,使用摄像头拍摄视频,实时检测字符区域并给出识别类别。该系统包括手写汉字模型训练(云上)、模型转换、模型部署、摄像头图像采集、模型推理(端侧)、结果展示等完整训练和应用流程。其中模型采用的是深度神经网络,目前深度学习在文字识别方面有着广泛的应用,多分类问题是其中重要的一类。然而,深层网络模型的结构通常很复杂,对于一般的多类别分类任务,所需的深度网络参数通常随着类别数量的增加而呈现超线性增长。本文需要识别字库中字的类别数高达3755类,模型训练是整个流程中耗时最长且决定识别精度的重要环节,模型推理在识别流程中占据较大部分。所以这两个环节的速度和精度对于用户体验至关重要。如何研究高性能、高精度、实用性强的方案变得极具挑战性。
实现技术思路
准备数据集
1、数据集的下载与导入
由于识别手写数字这个任务相对于拟合正弦函数而言复杂一些,所以需要的数据量比较大,因此,我们采用现成的手写数字数据集MINST。这个数据集里包括了70000张28×28的灰度图片,其中训练数据60000张,测试数据10000张,每张图片都是一个手写数字。

构建神经网络模型
这一次我们要使用CNN(卷积神经网络)模型。我们不妨先来看一下卷积层中发生了什么。
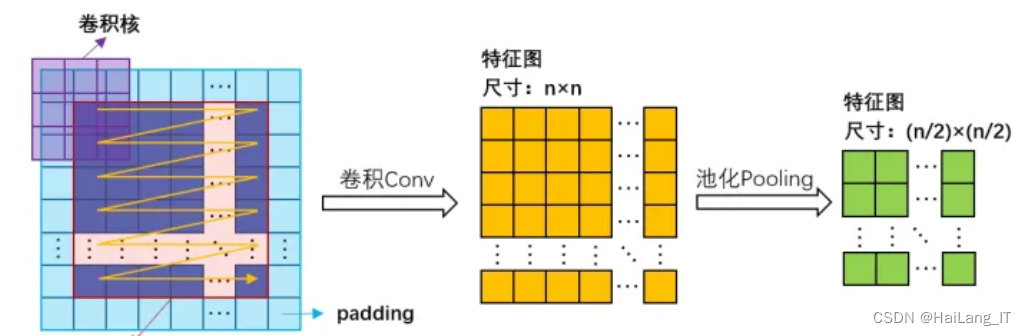
首先我们有一张图片和一个卷积核 [ 一般其大小(kernel_size)为3×3或5×5 ] ,这个卷积核会遍历这张图片,在遍历的过程中,卷积核上的数字会与图片上对应位置的像素相乘、求和,最后把这个数字写在一张新的图片里的对应位置,这就完成了一次卷积(Convolution)。而这一层的反向传播就是调整卷积核内的数字的过程。
当然,一个卷积层中也不止一个卷积核,而是有多个卷积核同时工作,提取出不同的特征以供后面的层继续操作。
不过这样“卷积”一次以后,图片就缩小了一圈,所以我们一般会在原图片的周围加一圈空白像素(padding)来确保卷积的结果与原图片大小相等。
from keras.models import Model
from keras.layers import Input, Dropout, Reshape, Activation, Flatten, Dense
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.initializers import orthogonal, constant, he_normal
from keras.regularizers import l2
from keras import backend as K
from keras.layers.normalization import BatchNormalization
from keras.layers.advanced_activations import PReLU
import config
# 这个是ReLU6,在原ReLU上加上一个约束(大于6的都变为6,这样就可以防止梯度爆炸)
def relu6(x):
"""Relu 6
"""
return K.relu(x, max_value=6.0)
def net():
inputs = Input(shape=(config.IMAGE_SIZE, config.IMAGE_SIZE, config.NUM_CHANNELS))
x = Conv2D(config.FILTER_NUM[0], (1, 3), padding='same', kernel_initializer=he_normal())(inputs)
x = Conv2D(config.FILTER_NUM[0], (3, 1), padding='same', kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
x = Conv2D(config.FILTER_NUM[1], (1, 3), padding='same', kernel_initializer=he_normal())(x)
x = Conv2D(config.FILTER_NUM[1], (3, 1), padding='same', kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
x = Conv2D(config.FILTER_NUM[2], (1, 3), padding='same', kernel_initializer=he_normal())(x)
x = Conv2D(config.FILTER_NUM[2], (3, 1), padding='same', kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
x = Conv2D(config.FILTER_NUM[3], (1, 3), padding='same', kernel_initializer=he_normal())(x)
x = Conv2D(config.FILTER_NUM[3], (3, 1), padding='same', kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = Conv2D(config.FILTER_NUM[4], (1, 3), padding='same', kernel_initializer=he_normal())(x)
x = Conv2D(config.FILTER_NUM[4], (3, 1), padding='same', kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
x = Conv2D(config.FILTER_NUM[5], (1, 3), padding='same', kernel_initializer=he_normal())(x)
x = Conv2D(config.FILTER_NUM[5], (3, 1), padding='same', kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = Conv2D(config.FILTER_NUM[6], (1, 3), padding='same', kernel_initializer=he_normal())(x)
x = Conv2D(config.FILTER_NUM[6], (3, 1), padding='same', kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
x = Flatten()(x)
x = Dense(config.FILTER_NUM[7], kernel_regularizer=l2(0.005), kernel_initializer=he_normal())(x)
x = BatchNormalization()(x)
# x = Activation(relu6)(x)
x = PReLU()(x)
x = Dropout(0.5)(x)
y = Dense(config.NUM_LABELS, activation='softmax', kernel_initializer=he_normal())(x)
model = Model(inputs=inputs, outputs=y)
return model准备损失函数和优化器
之前我们用的是MSE(均方误差)损失函数,这次我们也可以继续使用MSE,但我们有一个更好的选择——交叉熵损失函数。
交叉熵是统计学中的一个概念,用于衡量两个概率分布的差异性,而我们下神经网络输出的十个数字刚好可以看作一个概率分布。这样,利用交叉熵就可以很容易的衡量出当前的输出与目标输出的差距是多少。
我们可以直接使用pytorch内置的交叉熵损失函数

接下来就是选择优化器,我们仍然选择SGD优化器

现在神经网络的一切已经准备就绪了。
训练神经网络
训练神经网络的过程分为训练和测试两部分
训练结果的保存与读取
pytorch已经为我们提供了保存和读取神经网络参数的函数,我们只需要调用即可。
首先是在训练结束后把训练好的网络保存起来,在上面的训练代码后面填上下面这句即可。
模型定义完成,就可以进行训练了,数据读取还是采用迭代的方式,用多少读多少,不然一下子全部读进内存内存不够,有近100w张图片。
实现效果图样例

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!