本文为 How We Solve Load Balancing Challenges in Apache Kafka 阅读笔记
kafka通过利用分区来在多个队列中分配消息来实现并行性。然而每条消息都有不同的处理负载,也具有不同的消费速率,这样就有可能负载不均衡,从而使得瓶颈、延迟问题和整体系统不稳定,进而导致额外的维护工作或额外的资源分配。
在 Kafka 中,分区器和分配器策略会影响消息分发。
Producer 分区器
- Round-robin:平均分配消息至各分区。
- Sticky partitioning:短时间内固定分配到一个分区,减少 rebalance 影响。
Consumer 分配器
- Range、Round-robin:静态分配分区给消费者。
这些策略都是基于两个主要的假设
- 消费者具有相同的处理能力
- 消息的工作量都相等
挑战
异构硬件
不同的服务器硬件代次的性能不同,从而导致处理速率不同。
消息工作负载不均衡
不同的消息可能需要一组不同的处理步骤。例如,处理消息可能涉及调用第三方 HTTP 终端节点,不同的响应大小或延迟可能会影响处理速率。此外,对于涉及数据库作的应用程序,其数据库查询的延迟可能会根据查询参数而波动,从而导致处理速率不同。
过度配置
在资源分配过程中,系统为应对预期峰值负载而分配了远超实际需求的资源,导致资源利用率低下和成本浪费
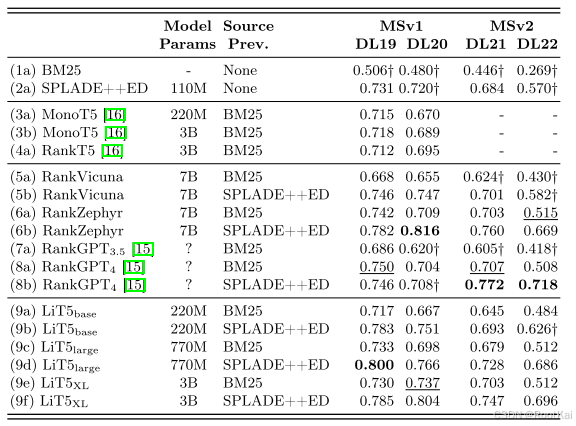
假设我们的高吞吐量和低吞吐量的处理速率分别为 20 msg/s 和 10 msg/s(根据表 1 中的数据简化)。使用两个较快的处理器和一个较慢的处理器,我们预计总容量为 20+20+10 = 50 条消息/秒。

但由于轮询均匀分配消息(每台处理器分到约16.67 msg/s),低速处理器无法处理其份额,实际系统仅能处理30 msg/s(10×3),剩余消息堆积,引发延迟。
静态平衡方案
相同pod上部署
可以考虑控制服务部署中使用的硬件类型以缓解问题。
加权负载均衡
如果容量是可预测的,并且大部分时间保持不变,则为不同的使用者分配不同的权重有助于最大限度地利用可用资源。例如,在为性能更好的使用者提供更高的权重后,我们还可以将更多流量路由到这些使用者。
响应式延迟感应
虽然是可以估算负载来通过加权方式来进行负载均衡,然而
- 消息在工作负载中并不统一,因此难以估计计算机容量
- 依赖项(例如网络和第三方连接)不稳定,有时会导致实际处理中的容量发生变化
- 系统若经常添加新功能,会增加额外的维护工作以保持权重更新
为了解决这些问题,我们在系统中实施了延迟感知机制,以动态监控每个分区中的当前延迟,并根据当前流量状况做出相应的响应。
- Log-aware Producer: 利用动态分区逻辑来考虑目标主题的滞后信息
- Log-aware Consumer: 监控当前的滞后,并在必要时自行取消订阅以触发负载的重新平衡。通常,可以采用自定义再平衡策略来调整分区分配。

Log-aware Producer
以下是不应该使用的情况下
- 纯消费类应用 :您的应用不控制消息的生产
- 多消费组:当生成的消息被多个消费组使用时,滞后感知创建器可能会为其他消费组生成不必要的倾斜负载,因为滞后是特定于一个消费组的信息
相同队列长度算法
此算法将每个分区滞后视为处理的队列大小。获取滞后信息后,它会发布适当数量的消息以填充短队列。
这种方法更适合于由于异构硬件而导致的偏斜滞后分布,其中高性能 Pod(机器)在大多数情况下能够更快地处理。
适用场景:
- 硬件异构(部分节点性能强,部分弱)。
- 消息处理时间相对稳定,但节点处理能力差异显著。

def same_queue_length_algorithm(partitions, current_lags):
total_messages = 100 # 假设本次需分配100条消息
avg_lag = sum(current_lags) / len(partitions) # 计算平均队列长度
# 计算每个分区应分配的消息量:目标是将Lag降至avg_lag
messages_per_partition = []
for partition, lag in zip(partitions, current_lags):
if lag < avg_lag:
# 低Lag分区:分配更多消息以填充队列
messages = total_messages * (avg_lag - lag) / sum(max(avg_lag - lag, 0) for l in current_lags)
else:
# 高Lag分区:分配较少消息
messages = 0 # 或按比例减少
messages_per_partition.append(messages)
return messages_per_partition
示例:
- 分区Lag:
[10, 30, 50](目标平均Lag = 30) - 分配结果:
- 分区1(Lag=10):分配较多消息(拉长队列至30)。
- 分区3(Lag=50):暂停分配,直到Lag降低。
异常值检测算法
利用统计方法来确定所有分区的高延迟异常值,并暂时停止那些缓慢异常值的消息发送过程。为了满足我们的特定需求,已经提出了 IQR(四分位间距)和 STD(标准差)异常值检测算法

- Slow partition: 由于存在滞后,这些分区的消息发布已停止
- OK partition: 为了提高性能不佳的计算机的性能,当系统尝试将慢速分区提升为良好分区时,会添加观察期。此观察阶段可以通过仅生成一小部分消息并进行观察来优化为“半开”状态。当滞后获取间隔相对较长时,半开是有益的,因为它可以防止使用者在尚未查询更新的滞后数据时延迟等待传入消息的情况
- Good partition: 照常发布并均匀分布到所有 Good Partitions
适用于
- 突发性延迟。比如依赖服务超时
- 动态负载波动大
def outlier_detection_algorithm(partitions, current_lags):
# 使用IQR方法检测异常值
q1, q3 = np.percentile(current_lags, [25, 75])
iqr = q3 - q1
upper_bound = q3 + 1.5 * iqr # 定义高延迟阈值
# 分区状态判断
for partition, lag in zip(partitions, current_lags):
if lag > upper_bound:
partition.state = "Closed" # 停止分配
elif partition.state == "Closed" and lag < q3:
partition.state = "Half-Open" # 试探性恢复
elif partition.state == "Half-Open":
if lag < q1:
partition.state = "Open" # 完全恢复
else:
partition.state = "Closed" # 重新关闭
# 仅向Open/Half-Open分区分配消息
open_partitions = [p for p in partitions if p.state != "Closed"]
messages_per_partition = distribute_evenly(open_partitions) # 均匀分配
return messages_per_partition
示例:
- 分区Lag:
[10, 12, 15, 100](IQR计算后,100被识别为异常值) - 操作:
- 分区4标记为
Closed,暂停消息分配。 - 其余分区均匀分配消息。
- 分区4标记为
Log-aware Consumer
当多个消费者组订阅同一主题时,生产者基于单一消费者组的延迟调整分区流量,可能导致其他消费者组负载失衡
因此直接在消费者侧引入实现动态负载均衡
主动退订
消费者实例监测自身处理延迟(Lag),若发现某些分区积压严重(如因硬件性能差),可主动退订这些分区,触发 Kafka 的 重平衡(Rebalance)。
在重平衡过程中,通过自定义的分区分配策略(如基于机器性能指标或实时 Lag 数据),将高负载分区重新分配给性能更强的消费者实例。