擦除编码EC在数据中心中的最优机架协调更新
- 介绍与背景工作
- 文章外主流的工作
- 文章摘要
- RackCU, the optimal Rack-Coordinated Update solution
- 数据增量基础更新
- 奇偶校验基础更新
- RackCU
- 其他的更新方法
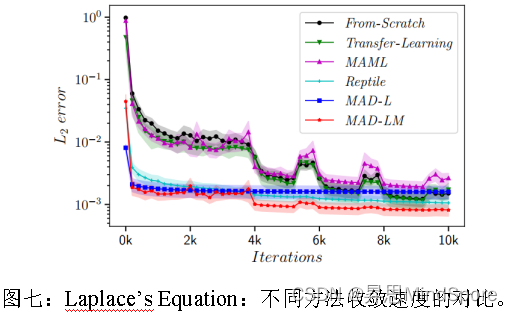
- 一些数值实验
- 可以仅需改进的地方
- 参考文献
介绍与背景工作
擦除编码(Erasure Coding, EC)是一种提高数据冗余性和可靠性的数据存储方法。在擦除编码中,存储在磁盘上的数据被分割成比特,然后对每个片段进行编码,以实现高级别的保护,然后存储在不同的磁盘中,以实现高数据可靠性。
擦除编码通过数据块生成对应数量的奇偶校验块来进行数据的容错恢复。
机架:把很多个存储节点视为一个整体,这个整体由网络核进行互联。而数据的存储与更新一般是由多个机架为交换存储的单位,机架与机架之间又会有数据的交换。需要指出的是,机架间的带宽,应视为机架内的带宽的一部分。
数据中心:一组节点首先被组织成一个机架,多个机架通过网络核心(即汇聚交换机和核心交换机)进一步相互连接。
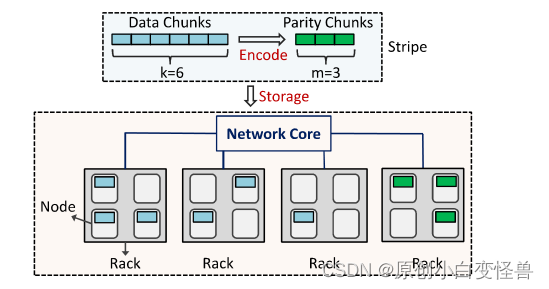
上图就是一个很好的例子,一组节点组成多个机架,机架之间有网络核管理通讯,蓝色的是数据库,绿色的是奇偶校验块(由EC编码的原理生成),它们的数量分别是6和3.
文章外主流的工作
为了解决数据错误或者丢失的问题,采用的常用操作是冗余和擦除编码。相对于冗余来说,擦除编码可以保证在存储开销更小的情况下保证相同程序的容错。但数据更新时,校验块的更新会给数据流带来额外的负担。
现有对擦除编码的研究主要有,减少磁盘的寻道,减少更新的流量等等。
文章摘要
擦除编码在当今的数据中心中被广泛应用,以解决普遍存在的故障,但它很容易引起大量的跨机架通信以进行奇偶校验更新。在本文中,我们提出了一种新的机架协同更新机制来抑制跨机架的更新流量,该机制包括两个连续的阶段:一个是增量收集阶段,它收集数据增量块;另一个是选择性校验更新阶段,它根据更新模式和校验布局更新校验块。我们进一步设计了RackCU,一个机架协调的最优更新方案,实现了跨机架更新流量的理论下限。最后,我们通过大规模仿真和真实数据中心实验进行了广泛的评估,结果表明RackCU可以减少22.1%-75.1%的跨机架更新流量,从而提高34.2%-292.6%的更新吞吐量。
接下来会按照两个更新的阶段,和RackCU的算法顺序进行介绍
RackCU, the optimal Rack-Coordinated Update solution
机架协同更新,一种新的奇偶校验更新机制,包括一个增量收集阶段和另一个选择性奇偶校验更新阶段,在数据更新后立即对数据块进行更新,目的是在保证系统可靠性的前提下最小化跨机架的更新流量。机架协同更新的主要思想是在一些专用的机架(称为收集器机架)中收集数据增量(即旧数据块和新数据块之间的差异),并通过选择适当的更新方法更新校验块。
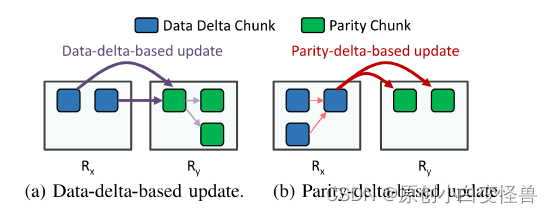
在介绍数据增量基础更新和奇偶校验块基础更新之前,我们介绍一个例子,这样可以在方法提出时进行更好的理解。
Rx和Ry分别是数据块机架和奇偶校验块机架,在数据增量基础更新中,Rx将数据增量(有改动的数据)依次发送给校验块,根据校验块的更新原理来更新校验块。在奇偶增量基础更新中,在Rx中通过计算得出奇偶增量,再发送给Ry进行校验更新。
接下来,我们从通俗的语言上说命一下两种更新方法
数据增量基础更新
该方法为直接发送数据增量块给校验块。
对于下面的图来说,数据增量更新需要传输的数据量为:
R1,R2,R3有需要发送的数据增量块6块,若采用此方法更新,则需要分别发送给R4和R5中的奇偶校验块,故有粗略的I/O次数6*4=24次
奇偶校验基础更新
通过计算数据增量产生的增量奇偶校验块,并以此发送给校验块来完成校验块的更新。
RackCU
一些假设:
每个机架内只含有数据块或者校验块
一个机架只能发送增量块给一个机架
发送过程是正确无误的
而作为RackCU提出的两个连续的更新阶段来说,我们可以给出更形象具体的例子
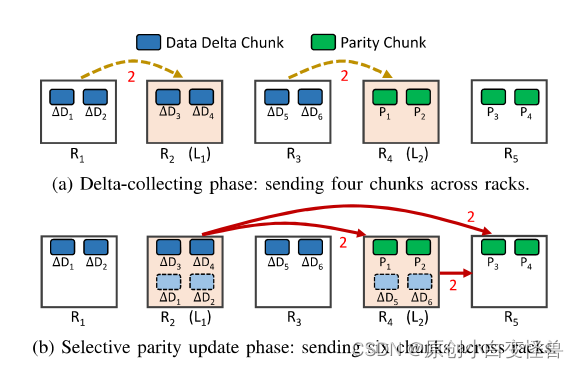
在RackCU中,会选取收集机架来收集数据增量,最后通过选择计算来发送对应数据增量块还是奇偶校验增量块给含有奇偶校验的机架。算法一共分为两个阶段,(a)和(b)。在R1,R2,R3,R4,R5机架中,1,2,3分别是数据机架,而4和5是存放校验块的机架,且每个机架中只有两个节点(这个节点可以理解为有计算能力的存储机器)。
指定进行数据收集的机架,每个机架负责收集部分的机架的数据增量
每个收集机架可以计算生成增量奇偶校验块,并对比其需传送的增量数据块的大小
并取它们的最小值进行发送,这里记作L
在上图中,选定的收集机架(collection rack)为R2和R4,R1和R3的数据增量分别发送给了R2和R4
通过选择最小值L的增量发送,来进行校验块更新。(可能发送数据增量,也可能发送奇偶校验增量)
由此我们就可以引出核心算法:

下面对算法进行大致解释
输入数据、奇偶校验块的机架,
找出需要更新的机架的节点
发送增量数据给收集机架
计算出是发送数据增量还是奇偶校验增量
进行发送和更新
思考:虽然将数据发送给收集机架需要I/O代价,但通过其计算出的最小发送块能大大优化校验块更新的效率。且进一步,提高的效率是由通过精简化大量数据增量的发送块为奇偶校验增量块来完成的。
其他的更新方法
CAU:如果数据增量没有超过发送奇偶增量校验块的大小,发送数据增量,否则发送奇偶增量块
The baselin:一旦数据更新,就发送奇偶增量块给校验块更新
Parix:第一次更新,发送全部数据,之后的校验块更新只发送数据增量
一些数值实验
这里只放部分结果图来对比显示RackCU的性能,详情请看参考文献
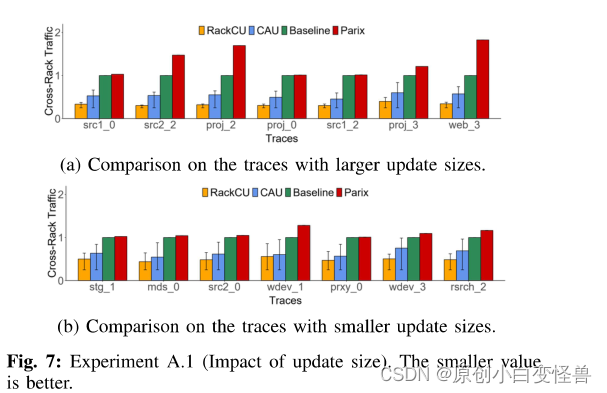
RackCU算法的机架间数据流量的减少效果都是显著的。
文章的源码可以在以下网址找到 GitHub - ggw5/RackCU-code
可以仅需改进的地方
改进的地方可以从模型的强假设中下手,比如机架内可以同时存放数据块和奇偶校验块;收集机架的选择在性能上可以进行优化,比如可以为多个,或者改成动态根据当下的性能来选择机架。通过以上的改变都可以使算法更加适应大量的实际应用。
补充:文章内容是精度完前沿文献后的总结,并加入自己的理解,且以此方式来记录分享。
在文章过程中,笔者省略掉了模型、公式和数值实验的说明,如果有继续了解的想法,请参看参考文献
参考文献
G. Gong, Z. Shen, S. Wu, X. Li and P. P. C. Lee, “Optimal Rack-Coordinated Updates in Erasure-Coded Data Centers,” IEEE INFOCOM 2021 - IEEE Conference on Computer Communications, 2021, pp. 1-10, doi: 10.1109/INFOCOM42981.2021.9488813.
论文与文章内容可以在
这里RackCu下载




![[附源码]Python计算机毕业设计Django社区住户信息管理系统](https://img-blog.csdnimg.cn/097f6469c1e5432b855ab5c8153d95aa.png)



![[附源码]JAVA毕业设计流行病调查平台(系统+LW)](https://img-blog.csdnimg.cn/dff8c562a06c4b20b3ba206960130c4a.png)