在我们设计架构治理平台 ArchGuard 2.0 的架构时,一直在强调的点是:基于规范 + 模式的工具化。简单来说,规范是架构设计的共时,也是架构知识的显性化。所以,在让 AI 设计架构时,规范是我们要考虑的第一要素,第二要素是:基于现有实现地设计。
在 ArchGuard 里,我们遇到的其中一个挑战是:如何识别不可言表的设计?于是,我们尝试构建 ArchGuard Co-mate 来理解这些设计,挑战也变为:如何让 AI 基于规范和架构已有上下文设计?因此,在这篇文章里,我们将介绍 Co-mate 分析过程与实现方式:基于 AI 原子能力的动态函数生成。
TL;DR 版本:
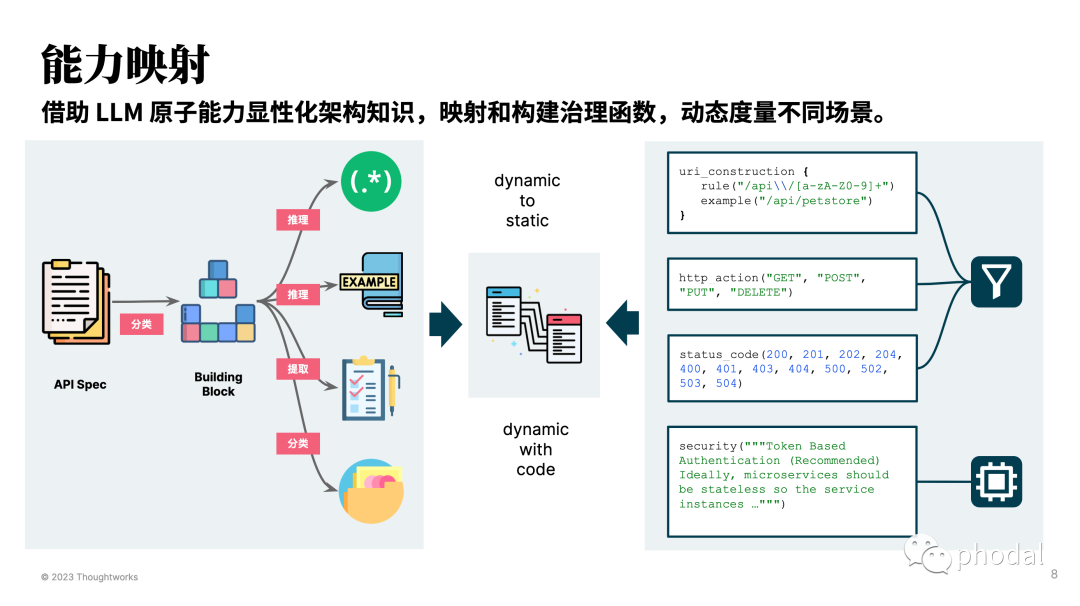
简单来说,本文就是要解释上图的过程。
经典工具的局限性:无法识别不可言表的设计
在年初的 QCon 上,我和同事雨青在《组织级架构治理的正确落地方式》总结了架构治理的现状和挑战。
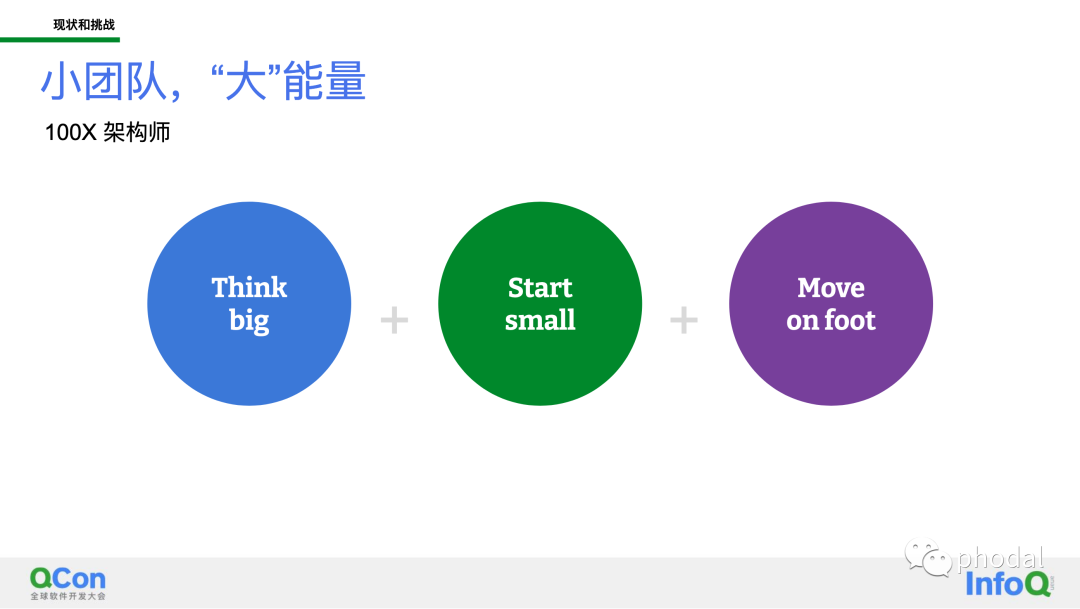
Think Big。通常来说,组织架构治理的顶层目标和范围都是比较大的,比如整合管理整个组织的应用资产、实现整体IT成本降低、效能提升等等。
Start Small。这里的 small 指的是架构治理团队,可能有的叫架构办、有的叫技术委,大多是 3-5 人这个数量级,也有十多人的比较少。和整体研发组织规模相比,很多是属于 1:100 的这个比例,也就是 1 个架构治理人员对应 100 个研发人员,甚至更多。
Move on foot。即徒步前行,指的是架构治理工作很多都是手工完成的,包括大规模的架构现状盘点、持续的架构评审等活动,很少有工具支撑的。
尽管,ArchGuard 2.0 能解决一部分问题,但是依旧有问题没有解释:不可言表的设计。这个问题出现在:ArchGuard 一直难以对一个项目的架构建模,有太多抽象的内容无法建模,而这些对于 LLM 是很容易的:
当前(As-Is)架构或者未来(To BE)架构。系统本身是一直在变化的,变化的原因可能出自于多种上下文。
分层架构不规范。如果分层架构(三层架构、DDD/四层架构)本身是规范的,那么工具可以识别出来;然而现实是不规范的分层架构,导致人也难以知道原先是三层还是四层的。
技术栈的百花齐放。过多的技术栈,使得我们难以用工具识别架构的核心所在,而种总结对于人类和 LLM 来说轻而易举。
所以,我们转换了一下思路:如果 LLM 能否抽象这些不可言表的设计呢?所以,如何能否动态生成系统上下文的治理函数?
规范即函数:基于 LLM 原子能力的动态函数生成
在先前的一系列文章里,我们已经介绍了结合 LLM 设计软件架构,需要的是一系列的 DSL。即可以由 LLM 来动态生成,又可以是我们设计的。但是,我并不相信 LLM 的代码能力,所以我更愿意的做法是:让 LLM 来理解文档、DSL,以编排 DSL 来治理架构。
这也是基于 LLM 原子能力来动态生成治理函数的核心所在。
要素一:围绕 LLM 原子能力的设计
回到某个 AIGC 的闭门会议上,路宁老师提到了一个 AI 应用架构设计的要点:我们需要考虑分解 LLM,提取原子能力(类似于微服务)。再基于约束好的工程化步骤,构建完我们的上下文,可以构建出更理想的 AI 应用。
简单来说:结合 AI 的能力,看能解决我们的哪些问题。LLM 擅长什么,不擅长的点是否直接给 ArchGuard 完成。
比如说,在 Co-mate 的 REST API 治理场景下,我们使用的 LLM 能力包括了:
分类:让 LLM 分析 API 文档,让我们后续根据 URI、HTTP Action、安全等几个不同的能力维度来选择适合的工具。
逻辑推理:让 LLM 分析 API 文档的 URI Construction 部分,生成用于检查的 URI 正则表达式部分,以及适合于人类阅读的 by example 部分。当然了,也包含了其它场景之下的推理。
提取:由 LLM 按 API 规范的不同维度来提取一些关键信息。
分类:由 LLM 来总结哪些部分难以简单的通过代码总结,诸如于安全等不适合于所有的 API 场景。
……
由此构成了 “能力映射” 的左图部分,这种方式适用于不同的规范分解。尽管如此,对于当前方式来说,依然还有一系列的可优化的空间,诸如于对 security、 misc 进行进一步的能力分解。
要素二:丰富基于规范的架构治理 “函数”
再回到我们的 API 规范上,我们从网上找了一个 API 规范示例(可以见 ArchGuard Co-mate 源码里的 docs/ ),初步将其分解为五个维度:HttpActionRule、StatusCodeRule、UriConstructionRule、MiscRule、SecurityRule。前三者由传统的规则检查工具来处理,后两者则由 LLM 进行二次的检查。
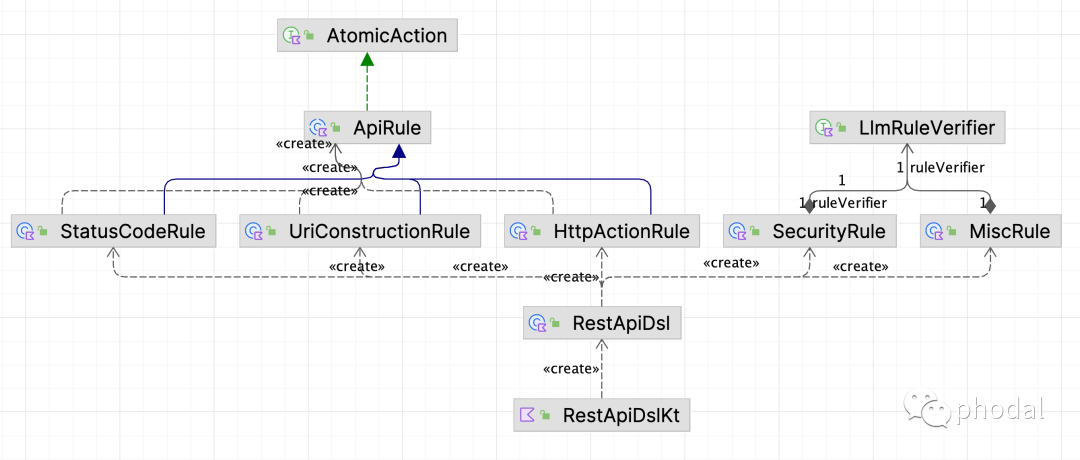
在验证了 LLM 基于文档的检查能力之后,我们将其转换为工具化的一部分。而把所有的 API 直接扔给 LLM 来检查是不合理的,也是不科学的。所以,结合 LLM 的能力、API 分类、检查频率等,将其划分了多个维度:
rest_api {
uri_construction {
rule("/api\\/[a-zA-Z0-9]+\\/v[0-9]+\\/[a-zA-Z0-9\\/\\-]+")
example("/api/petstore/v1/pets/dogs")
}
http_action("GET", "POST", "PUT", "DELETE")
status_code(200, 201, 202, 204, 400, 401, 403, 404, 500, 502, 503, 504)
security("""Token Based Authentication (Recommended) Ideally, ...""")
misc("""....""")
}如在 API 场景下,我们需要对其进行分类。诸如于可以分为通用的 HTTP 资源型 API,登录等其它 API。
通用 HTTP 资源治理。大部分可以直接由本地治理函数来完成。
杂项 API。往往需要通过人或者 LLM 来进行分解,诸如于鉴权、health 等 API。
也因此,在未来我们需要的其实是大语言模型友好的架构规范。而这也是现阶段大部分文档不友好的地方,它们本身对于人是不友好的,工具编写时也缺乏一定的条理性。
要素三:构建实时的、动态的架构治理功能
在由 LLM 分析规范文档、分类的 spec,并生成基本的治理函数之后,我们需要结合两种不同的动态能力,以使它们有机的结合在一起。
在 ArchGuard Co-mate 里,我们依旧使用的是基于 DSL + Kotlin REPL Runtime 的方式来实现这个功能。
治理 DSL。即步骤二的代码示例。其基于 Kotlin 的 Type-safe builders 实现。
Kotlin REPL。与之前的 ArchGuard 架构治理工作台一样,基于 Kotlin Jupyter Runtime 构建,并把 Co-mate 的相关依赖添加到进去,以实现直接的函数调用。
在由 ArchGuard API 提取了 API 之后,剩下的部分就可以交由 LLM 来实现,即交由神奇的 prompt 去进行分析:

作为一个黑盒的函数,调试 prompt 真是一件痛苦的事情。
小结:LLM 编排架构治理函数
对于本文而言,我们主要是通过 LLM 来进行治理函数的提取与编排,进而进行架构的治理。与需要大量上下文的编码相比,LLM 在编排上做得更好,只需要基本的推理和逻辑能力即可。
更详细的内容请阅读源码:https://github.com/archguard/co-mate