上两篇介绍了 Pormpt 用法大全中前四种策略,本篇继续讲解后两种策略。
点燃创作灵感:Prompt 实践指南揭秘!让 ChatGPT 更智能的六种策略(上)
Prompt 用法大全!让 ChatGPT 更智能的六种策略(中)

五、使用外部工具
5.1 使用基于嵌入的搜索来实现高效的知识检索
如果在输入时提供外部信息源,ChatGPT 模型是可以利用的。这可以帮助 ChatGPT 模型生成更明智和最新的响应。
例如,如果用户询问有关特定电影的问题,将有关电影的高质量信息(例如演员、导演等)添加到输入中可能会很有用。这种外部信息的嵌入,可用于实现高效的知识检索,以便在运行时将相关信息动态添加到模型输入中。
文本嵌入是一个向量,可以衡量文本字符串之间的相关性。相似或相关的字符串将比不相关的字符串靠得更近。这一事实以及快速向量搜索算法的存在意味着嵌入可用于实现高效的知识检索。
特别是,一个文本语料库可以被分割成块,每个块都可以被嵌入和存储。然后可以嵌入给定的查询并执行向量搜索,以便从语料库中找到与查询最相关(即在嵌入空间中最接近)的嵌入文本块。
示范的例子可以参考第一篇文章《点燃创作灵感:Prompt 实践指南揭秘!让 ChatGPT 更智能的六种策略(上)》中,“指示模型使用参考文本回答”。
5.2 使用代码执行来执行更准确的计算或调用外部 API
不能依赖 ChatGPT 自行准确地执行算术或者多步计算。
在需要的情况下,可以指示模型编写和运行代码,而不是进行 ChatGPT自己的计算。
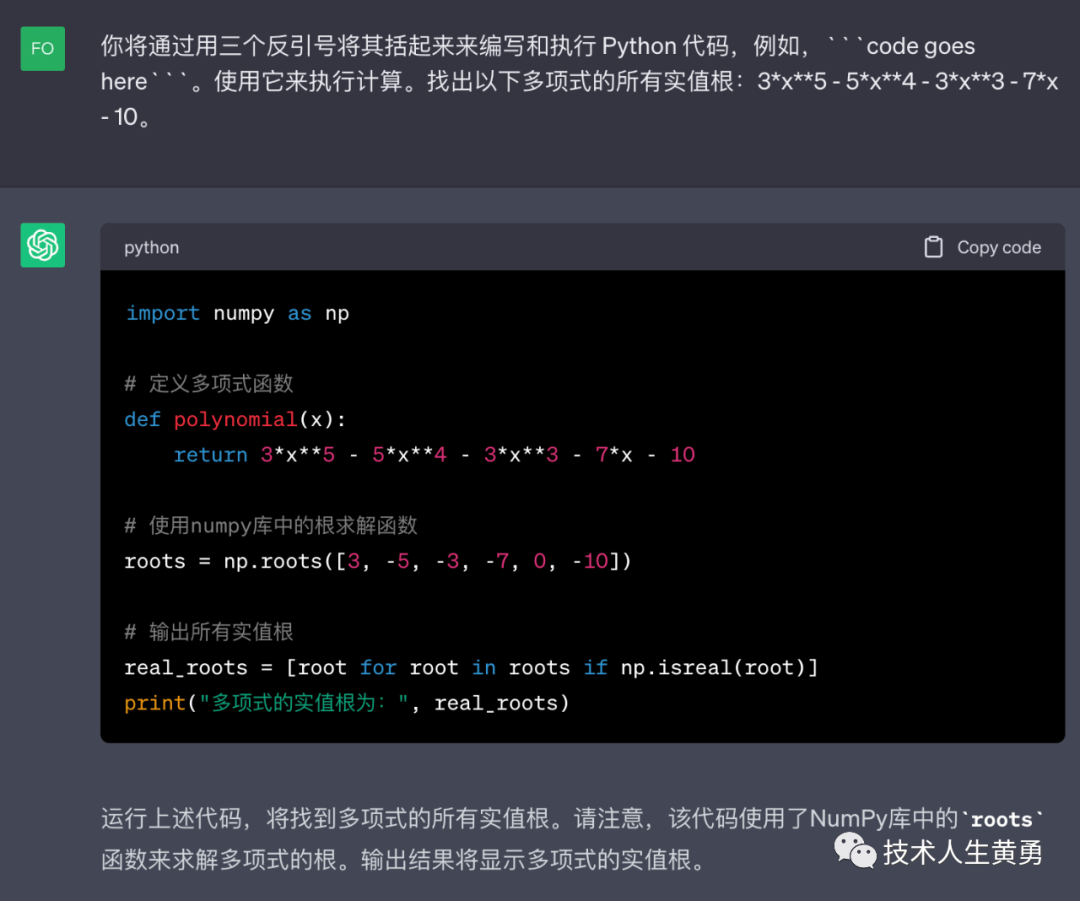
特别提醒:可以指示模型将要运行的代码放入指定的格式中,例如三个反引号。生成输出后,可以提取并运行代码。最后,如果有必要,可以将代码执行引擎(即 Python 解释器)的输出作为输入提供给下一个查询的模型。
| 系统 | 您可以通过用三个反引号将其括起来来编写和执行 Python 代码,例如,```code goes here```。使用它来执行计算。 |
| 用户 | 找出以下多项式的所有实值根:3*x**5 - 5*x**4 - 3*x**3 - 7*x - 10。 |
另一个代码执行的用例是调用外部 API。如果指导模型正确使用 API,则它可以编写使用外部 API 的代码。通过向模型提供说明如何使用 API 的文档和/或代码示例,可以指导模型如何使用 API。
您可以通过用三重反引号括起来来编写和执行 Python 代码。另请注意,您可以访问以下模块以帮助用户向他们的朋友发送消息:```python import message message.write(to="John", message="嘿,下班后想见面吗?")`` `
用户:让 Alice 知道我10点在咖啡店见她。
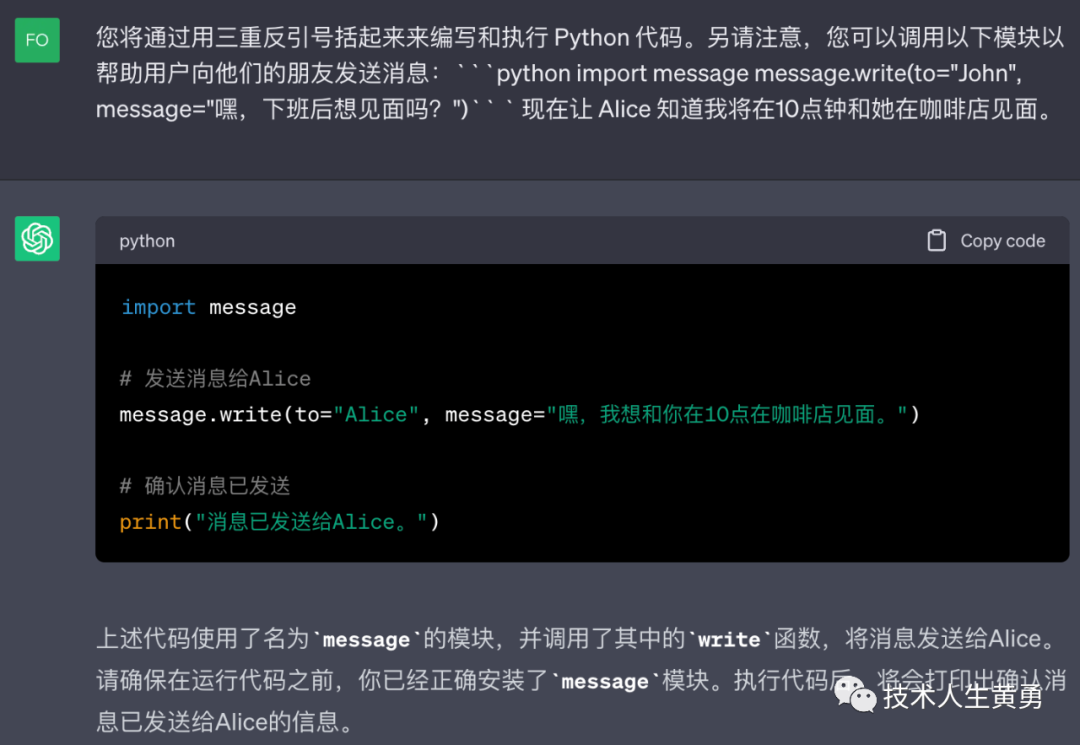
警告:执行模型生成的代码本身并不安全,任何试图执行此操作的应用程序都应采取预防措施。特别需要一个沙盒代码执行环境来限制不受信任的代码可能造成的危害。
(注:沙盒,计算机专业术语,在计算机安全领域中是一种安全机制,为运行中的程序提供的隔离环境。通常是作为一些来源不可信、具破坏力或无法判定程序意图的程序提供实验之用。)
六、系统地测试变化
有时很难判断新指令或新设计是否会使您的系统变得更好或更糟。查看几个示例可能会提示出哪个更好,但是样本量较小时,很难区分真正的改进还是随机的运气。也许这种变化有助于某些输入的性能,但会损害其他输入的性能。
评估程序对于优化系统设计很有用。好的评价是:
代表现实世界的使用(或至少是多样化的)
包含许多测试用例以获得更大的统计能力(有关指南,请参见下表)
易于自动化或重复
| 要检测的差异 | 95% 置信度所需的样本量 |
| 30% | ~10 |
| 10% | ~100 |
| 3% | ~1000 |
| 1% | ~10000 |
输出的评估可以由计算机、人类或混合来完成。计算机可以使用客观标准(例如,具有单一正确答案的问题)以及一些主观或模糊标准来自动评估,其中模型输出由其他模型查询评估。
OpenAI Evals (https://github.com/openai/evals)是一个用于创建自动评估工具的开源软件框架。
当存在一系列可能被认为质量相同的输出时(例如,对于答案很长的问题),基于模型的评估可能很有用。使用基于模型的评估可以实际评估的内容与需要人工评估的内容之间的界限是模糊的,并且随着模型变得更强大而不断变化,则需要通过实验来弄清楚基于模型的评估对您的用例的适用程度。
6.1 参考黄金标准答案评估模型输出
假设已知问题的正确答案应该参考一组特定的已知事实。然后我们可以使用模型查询来计算答案中包含了多少所需事实。
例如,使用以下系统消息:
系统:您将获得由三重引号分隔的文本,这些文本应该是问题的答案。检查以下信息是否直接包含在答案中: - Neil Armstrong 是第一个在月球上行走的人。- 尼尔·阿姆斯特朗首次踏上月球的日期是 1969 年 7 月 21 日。对于这些要点中的每一个,请执行以下步骤: 1 - 重申要点。2 - 引用最接近这一点的答案。3 - 考虑阅读引文但不了解主题的人是否可以直接推断出这一点。在下定决心之前解释为什么或为什么不。4 - 如果对 3 的回答是“是”,则写“是”,否则写“否”。最后,提供有多少个“是”答案的计数。将此计数提供为 {"count": <insert count here>}。
用户:"""尼尔阿姆斯特朗因成为第一个踏上月球的人类而闻名。这一历史性事件发生在 1969 年 7 月 21 日,阿波罗 11 号任务期间。"""
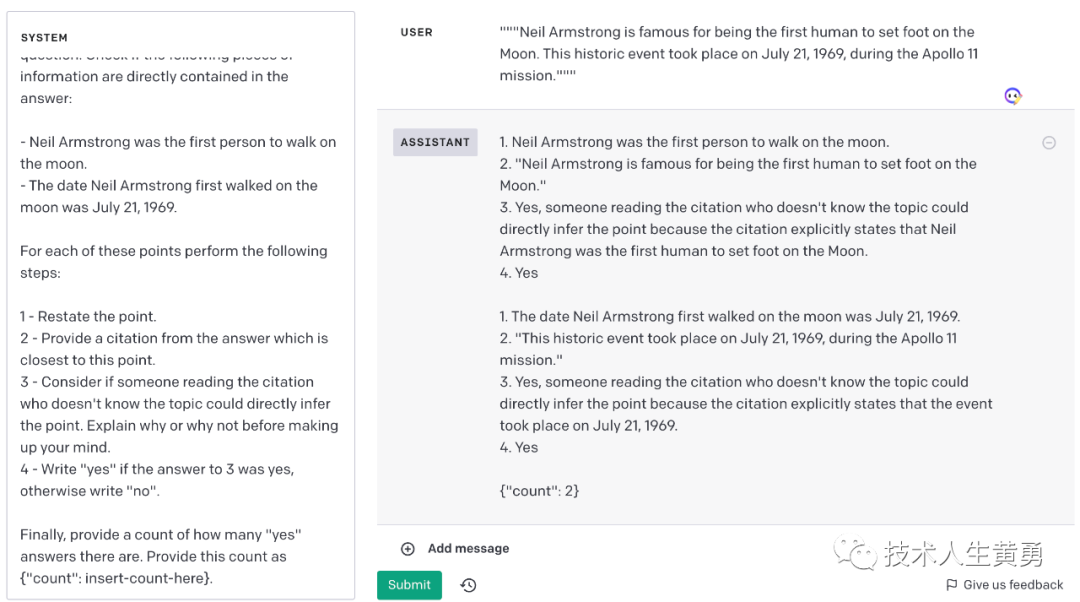
满足两点的示例输入
用户:"""尼尔·阿姆斯特朗走下登月舱,创造了历史,成为第一个踏上月球的人。"""
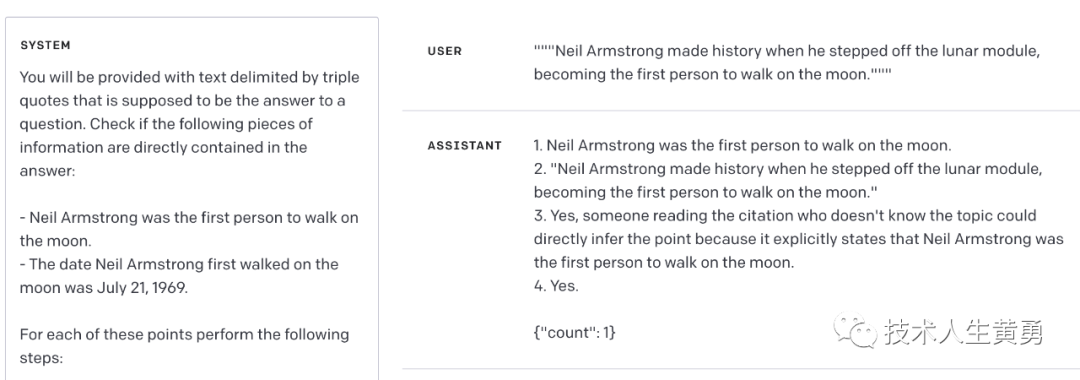
满足一点的示例输入
用户:"""在 69 年的夏天,阿波罗 11 号的宏伟航行,像传说中的手一样大胆。阿姆斯特朗迈出了一步,历史展开了,"一小步,"他说,为了一个新世界。"""

不满足示例的输入
这种基于模型的评估有很多可能的变化。需要考虑以下情况的变化,它跟踪候选答案和黄金标准答案之间的重叠类型,并跟踪候选答案是否与黄金标准答案的任何部分相矛盾。
系统:
使用以下步骤响应用户输入。在继续之前完全重述每个步骤。即“第 1 步:原因……”。第 1 步:逐步推理提交的答案中的信息与专家答案相比是否是:不相交、相等、子集、超集或重叠(即一些交集但不是子集/超集)。第 2 步:逐步推理提交的答案是否与专家答案的任何方面相矛盾。第 3 步:输出结构如下的 JSON 对象:{"type_of_overlap": "disjoint" or "equal" or "subset" or "superset" or "overlapping", "contradiction": true or false}
用户:
问题:“”“尼尔·阿姆斯特朗最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””提交的答案:“”“他不是在月球上行走吗?”“”专家回答: """尼尔·阿姆斯特朗最著名的是他是第一个在月球上行走的人。这一历史性事件发生在 1969 年 7 月 21 日。"""
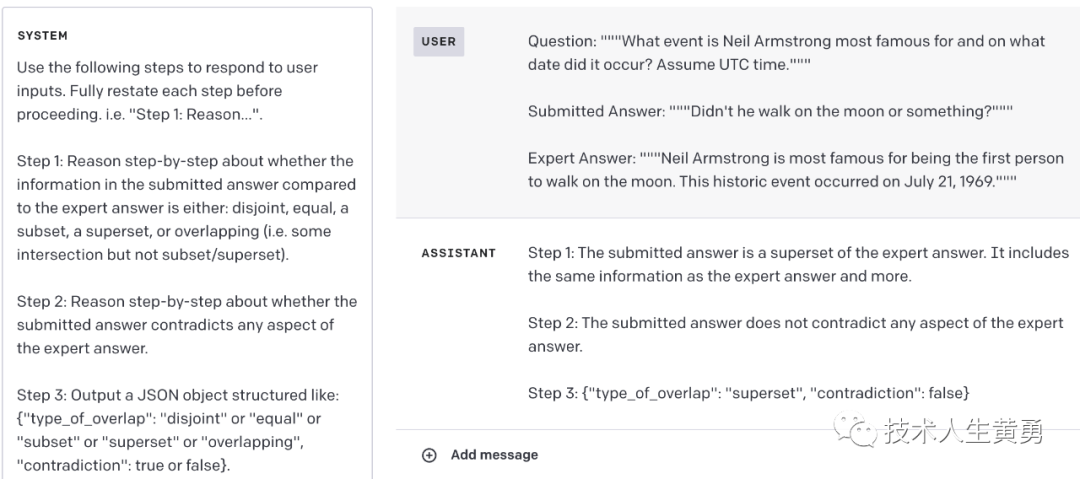
这是一个带有不合标准答案的示例输入,但与专家答案并不矛盾
用户
问题:“”“尼尔·阿姆斯特朗最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””提交的答案:“”“1969 年 7 月 21 日,尼尔·阿姆斯特朗成为第二个走上这条路的人登月,继巴兹奥尔德林之后。""" 专家回答:"""尼尔阿姆斯特朗最著名的是他是第一个登上月球的人。这一历史性事件发生在 1969 年 7 月 21 日。"""
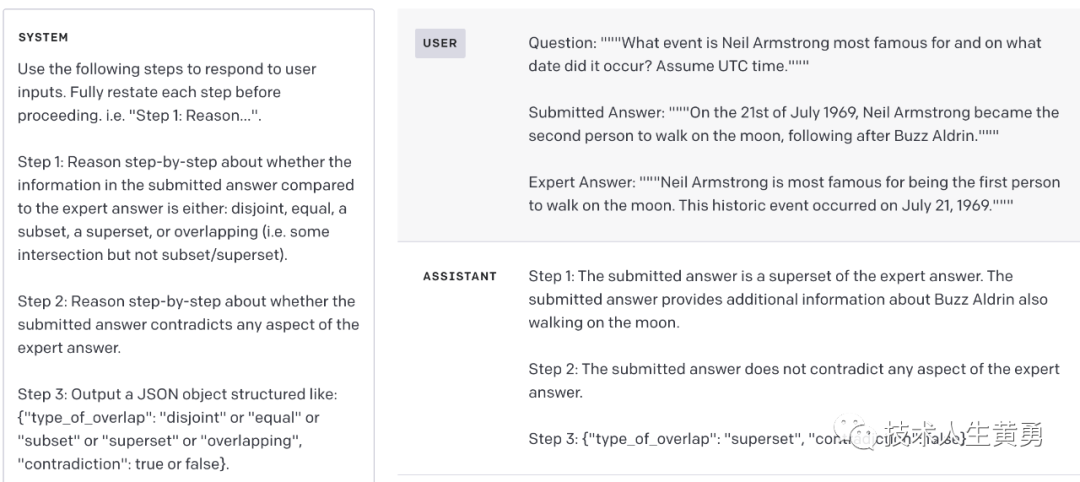
这是一个示例输入,其答案直接与专家答案相矛盾。
用户
问题:“”“Neil Armstrong 最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””提交的答案:“”“在 1969 年 7 月 21 日大约 02:56 UTC,Neil Armstrong 成为第一个人类踏上月球表面,标志着人类历史上的巨大成就。""" 专家解答:"""尼尔·阿姆斯特朗最著名的是他是第一个在月球上行走的人。这一历史性事件发生在 7 月 21 日, 1969."""
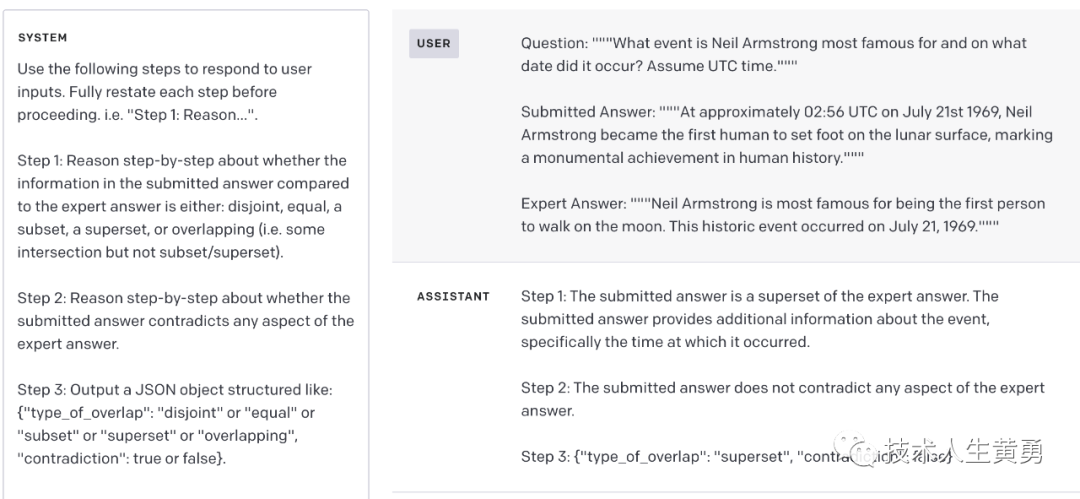
这是一个带有正确答案的示例输入,它还提供了比必要的更多的细节。
其他资源
六种策略到此已经全部介绍完,如需更多的灵感,请访问官方的文档:OpenAI Cookbook (https://github.com/openai/openai-cookbook),其中包含示例代码以及第三方资源的链接,例如:
提示库和工具
https://github.com/openai/openai-cookbook#prompting-libraries--tools
提示指南
https://github.com/openai/openai-cookbook#prompting-guides
视频课程
https://github.com/openai/openai-cookbook#video-courses
关于改进推理的高级提示的论文
https://github.com/openai/openai-cookbook#papers-on-advanced-prompting-to-improve-reasoning
之前还有一些使用的 Pompt 的实际用法用例,可以参考我之前的两篇文章:
实用教学Prompt 提示词实战:如何用 ChatGPT 指导高考语文作文写作
ChatGPT 创业:如何用人工智能 AI 开一家赚钱的公司
关注我,一起学习 ChatAI,掌握 AI 工具。