5.2 清洗数据
- 5.2.1 检测与处理重复值
- 1、记录重复 drop_duplicates()
- 2、特征重复 equals()
- 5.2.2 检测与处理缺失值 isnull()、notnull()
- 1、 删除法 dropna()
- 2、替换法 fillna()
- 3、 插值法
- 5.2.3 检测与处理异常值
- 1、3σ原则
- 2、箱线图
- 5.2.4 任务实现(wei)
数据重复会导致数据的方差变小,数据分布会发生较大变化。缺失会导致样本信息减少,不仅增加了数据分析的难度,而且会导致数据分析的结果发生偏差。因此要对数据进行检测,查询是否有 重复值、 缺失值和 异常值,并且要对这些数据进行适当的处理。
5.2.1 检测与处理重复值
常见的数据重复分为两种:
一种为记录重复,即一个或者多个特征的某几条记录的值完全相同;
另一种为特征重复,即存在一个或者多个特征名称不同,但数据完全相同的情况。
1、记录重复 drop_duplicates()
方法一:利用列表list去重;
### 方法一:利用list去重
import pandas as pd
path = 'E:/Input/py/5_2_1_BE-Lon.csv'
df = pd.read_csv(path)
# 方法一:定义去重函数
def delRep(list1):
list2 = []
for i in list1:
if i not in list2:
list2.append(i)
return list2
# 去重
dff = list(df['Date'])
print("前:", len(dff))
print(dff)
data1 = delRep(dff)
print("后:", len(data1))
print(data1)
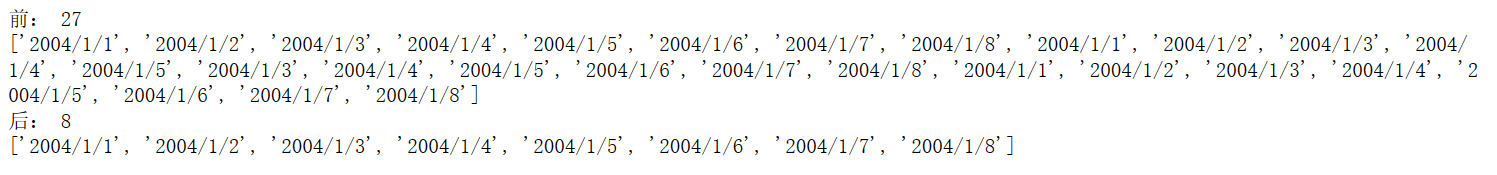
方法二:利用集合set元素唯一的特性去重,但是这种方法会导致数据的排列顺序发生变化;
# 方法二: 使用set去重,但是set()会导致数据的排列发生改变
# dff = list(df['Date'])
print("前:", len(dff))
print(dff)
data2 = set(dff)
print("后:", len(data2))
print(data2)

方法三:pandas提供了一个名为drop_duplicates的去重方法。该方法只对DataFrame或者Series类型有效。这种方法不会改变数据原始排列,并且兼具代码简洁和运行稳定的特点。该方法不仅支持单一特征的数据去重,还能够依据DataFrame的其中一个或者几个特征进行去重操作。
pandas.DataFrame(Series).drop_duplicates(self, subset=None, keep=‘first’, inplace=False)

# 方法三: 使用drop_duplicates()方法去重
print("前:", len(dff))
print(dff)
data3 = df['Date'].drop_duplicates()
print("后:", len(data3))
print(data3)

drop_duplicates()去重方法不仅支持单一特征的数据去重,还能够依据DataFrame的其中一个或者几个特征进行去重操作。
# 使用drop_duplicates()方法对多列去重
path = 'E:/Input/py/5_2_1_BE-Lon.csv'
df = pd.read_csv(path)
print("前:", df.shape)
print(df)
drop2 = df.drop_duplicates(subset = ['Date', 'NDVI'])
print("后:", drop2.shape)
print(drop2)
2、特征重复 equals()
结合相关的数学和统计学知识,去除连续的特征重复,可以利用特征间的相似度将两个相似度为1的特征去除一个。在pandas中相似度的计算方法为corr,使用该方法计算相似度时,默认为“pearson”法 ,可以通过“method”参数调节,目前还支持“spearman”法和“kendall”法。
corr()是相关矩阵,是DataFrame内置函数,不用另外调包也能生成。
corr()括号里面没有填参数时默认是皮尔逊相关系数,corr(method = ‘pearson’);
corr(method = ‘spearman’),斯皮尔曼等级相关系数,用来分析非正态分布的数据;
corr(method = ‘kendall’),秩相关系数,用来分析两定序变量相关关系;
## 2、特征重复
# 求出两列数据的kendall法相似度矩阵
# 求取LE和SWC的相似度
path = 'E:/Input/py/5_2_1_BE-Lon.csv'
df = pd.read_csv(path)
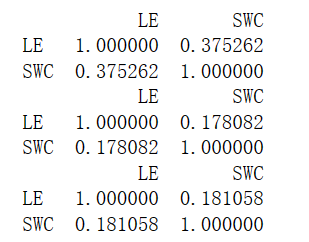
corrDet = df[['LE', 'SWC']].corr()
print(corrDet)
corrDet = df[['LE', 'SWC']].corr(method='kendall')
print(corrDet)
corrDet = df[['LE', 'SWC']].corr(method='spearman')
print(corrDet)
但是通过相似度矩阵去重存在一个弊端,该方法只能对数值型重复特征去重,类别型特征之间无法通过计算相似系数来衡量相似度,因此无法根据相似度矩阵对其进行去重处理。
除了使用相似度矩阵进行特征去重之外,可以通过DataFrame.equals的方法进行特征去重。
# 使用DataFrame.equals方法去重
path = 'E:/Input/py/5_2_1_BE-Lon.csv'
df = pd.read_csv(path)
# print(df)
## 定义求取特征是否完全相同的矩阵的函数
def FeatureEquals(df):
dfE = pd.DataFrame([], columns = df.columns, index=df.columns)
for i in df.columns:
for j in df.columns:
dfE.loc[i,j] = df.loc[:,i].equals(df.loc[:,j])
return dfE
# 应用
detEquals = FeatureEquals(df)
print(detEquals)
# 再通过遍历的方式选出完全重复的特征
## 遍历所有数据
lenDet = detEquals.shape[0]
print(lenDet)
dupCol = []
for m in range(lenDet):
for n in range(m+1, lenDet):
if detEquals.iloc[m,n] & \
(detEquals.columns[n] not in dupCol):
dupCol.append(detEquals.columns[n])
# 进行去重操作
print("需要删除的列为:", dupCol)
df.drop(dupCol, axis=1, inplace = True)
print(df)
5.2.2 检测与处理缺失值 isnull()、notnull()
利用isnull或notnull找到缺失值。
数据中的某个或某些特征的值是不完整的,这些值称为缺失值。
pandas提供了识别缺失值的方法isnull以及识别非缺失值的方法notnull,这两种方法在使用时返回的都是布尔值True和False。
结合sum函数和isnull、notnull函数,可以检测数据中缺失值的分布以及数据中一共含有多少缺失值。
# 5.2.2 检测与处理缺失值
path = 'E:/Input/py/5_2_2_BE-Lon.csv'
df = pd.read_csv(path)
print(df)
print("每个特征缺失的数目:", df.isnull().sum())
print("每个特征非缺失的数目:", df.notnull().sum())
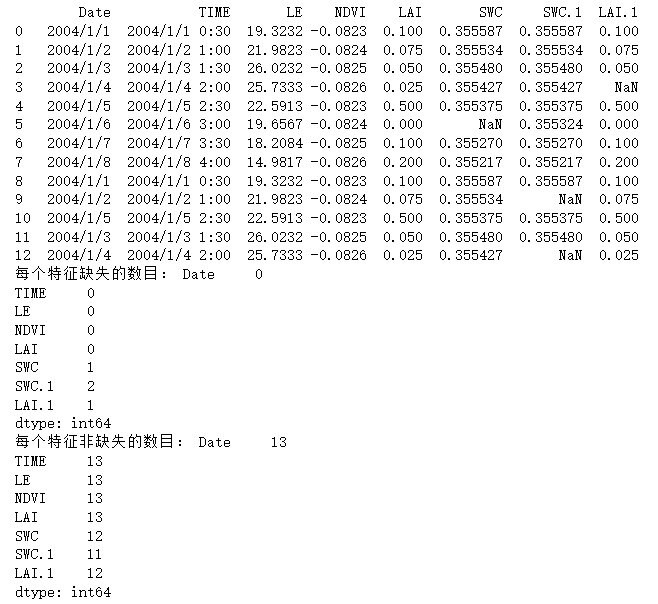
isnull和notnull之间结果正好相反,因此使用其中任意一个都可以判断出数据中缺失值的位置。
1、 删除法 dropna()
删除法是将含有缺失值的特征或者记录删除。删除法分为删除观测记录和删除特征两种,它属于利用减少样本量来换取信息完整度的一种方法,是一种最简单的缺失值处理方法。
pandas中提供了简便的删除缺失值的方法dropna(),该方法既可以删除观测记录,亦可以删除特征。
pandas.DataFrame.dropna(self, axis=0, how=‘any’, thresh=None, subset=None, inplace=False)

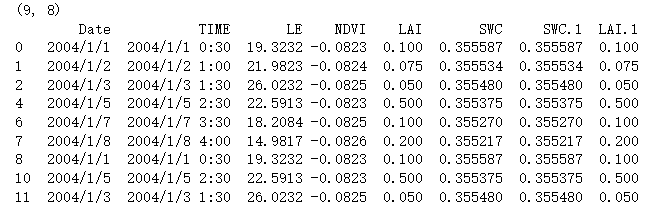
# 使用dropna方法删除缺失值 # 把含有缺失值的行都删了
data1 = df.dropna(axis=0, how='any')
print(data1.shape)
print(data1)
2、替换法 fillna()
替换法是指用一个特定的值替换缺失值。
特征可分为数值型和类别型,两者出现缺失值时的处理方法也是不同的。
缺失值所在特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来代替缺失值。
缺失值所在特征为类别型时,则选择使用众数来替换缺失值。
pandas库中提供了缺失值替换的方法名为fillna,其基本语法如下。
pandas.DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)

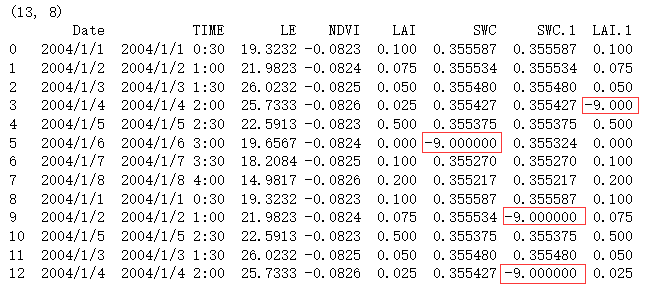
# 2、替换法
data1 = df.fillna(-9)
print(data1.shape)
print(data1)
3、 插值法
删除法简单易行,但是会引起数据结构变动,样本减少;替换法使用难度较低,但是会影响数据的标准差,导致信息量变动。在面对数据缺失问题时,除了这两种方法之外,还有一种常用的方法—插值法。
线性插值是一种较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方程得到缺失值。
多项式插值是利用已知的值拟合一个多项式,使得现有的数据满足这个多项式,再利用这个多项式求解缺失值,常见的多项式插值法有拉格朗日插值和牛顿插值等。
样条插值是以可变样条来作出一条经过一系列点的光滑曲线的插值方法,插值样条由一些多项式组成,每一个多项式都是由相邻两个数据点决定,这样可以保证两个相邻多项式及其导数在连接处连续。
# 3、插值法
import pandas as pd
import numpy as np
from scipy.interpolate import interp1d ## 注意是数字1
path = 'E:/Input/py/5_2_2_BE-Lon.csv'
df = pd.read_csv(path)
# print(df)
# 1、线性插值
linear_lai = df['LAI'].interpolate(method='linear')
print(linear_lai)
x = np.array([1, 2, 3, 4, 5, 8, 9])
y = np.array([2, 8, 18, 32, 50, 128, 162])
LinearInsValue = interp1d(x, y, kind='linear')
print(LinearInsValue([6, 7]))
# 2、拉格朗日插值法
from scipy.interpolate import lagrange
LargeInsValue = lagrange(x, y)
print(LargeInsValue([6, 7]))
# 3、样条插值
from scipy.interpolate import make_interp_spline
SplineInsValue = make_interp_spline(x, y)
print(SplineInsValue([6, 7]))
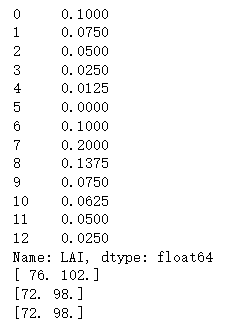
从拟合结果可以看出多项式插值和样条插值在两种情况下拟合都非常出色,线性插值法只在自变量和因变量为线性关系的情况下拟合才较为出色。
而在实际分析过程中,自变量与因变量的关系是线性的情况非常少见,所以在大多数情况下,多项式插值和样条插值是较为合适的选择。
SciPy库中的interpolate模块除了提供常规的插值法外,还提供了例如在图形学领域具有重要作用的重心坐标插值(BarycentricInterpolator)等。在实际应用中,需要根据不同的场景,选择合适的插值方法。
5.2.3 检测与处理异常值
异常值是指数据中个别值的数值明显偏离其余的数值,有时也称为离群点,检测异常值就是检验数据中是否有录入错误以及是否含有不合理的数据。
异常值的存在对数据分析十分危险,如果计算分析过程的数据有异常值,那么会对结果会产生不良影响,从而导致分析结果产生偏差乃至错误。
常用的异常值检测主要为3σ原则和箱线图分析两种方法。
1、3σ原则
3σ原则又称为拉依达法则。该法则就是先假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。
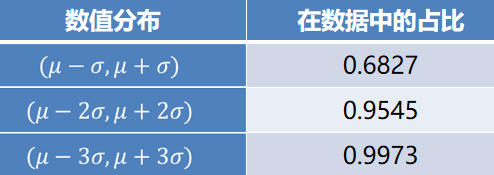
这种判别处理方法仅适用于对正态或近似正态分布的样本数据进行处理,如下表所示,其中σ代表标准差,μ代表均值,x=μ为图形的对称轴。
数据的数值分布几乎全部集中在区间(μ-3σ,μ+3σ)内,超出这个范围的数据仅占不到0.3%。故根据小概率原理,可以认为超出3σ的部分数据为异常数据。
# 5.2.3 使用3σ原则识别异常值
# print(df)
## 定义3σ原则来识别异常值函数
path = 'F:/书籍/Python数据分析与应用/37304_Python数据分析与应用_源代码和实验数据/第5章/data/detail.csv'
df = pd.read_csv(path,encoding='gbk')
def outRange(Serl):
boolInd = (Serl.mean() - 3*Serl.std() > Serl) | \
(Serl.mean() + 3*Serl.var() < Serl)
index = np.arange(Serl.shape[0])[boolInd]
outrange = Serl.iloc[index]
return outrange
outliner = outRange(df['counts'])
# print(df['counts'])
# print(outliner)
print(outliner.shape[0])
print(outliner.max())
print(outliner.min())

2、箱线图
箱型图提供了识别异常值的一个标准,即异常值通常被定义为小于QL-1.5IQR或大于QU+1.5IQR的值。
QL称为下四分位数,表示全部观察值中有四分之一的数据取值比它小。
QU称为上四分位数,表示全部观察值中有四分之一的数据取值比它大。
IQR称为四分位数间距,是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。
箱线图依据实际数据绘制,真实、直观地表现出了数据分布的本来面貌,且没有对数据做任何限制性要求,其判断异常值的标准以四分位数和四分位数间距为基础。
四分位数给出了数据分布的中心、散布和形状的某种指示,具有一定的鲁棒性,即25%的数据可以变得任意远而不会很大地扰动四分位数,所以异常值通常不能对这个标准施加影响。鉴于此,箱线图识别异常值的结果比较客观,因此在识别异常值方面具有一定的优越性。
import matplotlib.pyplot as plt
plt.figure(figsize = (10,8))
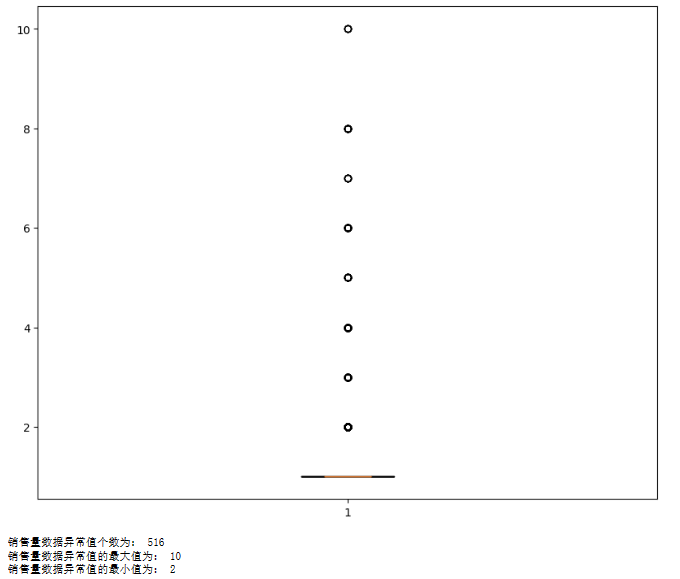
p = plt.boxplot(df['counts'].values, notch=True) # 画出箱线图
outlier1 = p['fliers'][0].get_ydata() # fliers为异常值的标签
plt.show()
print("销售量数据异常值个数为:", len(outlier1))
print("销售量数据异常值的最大值为:", max(outlier1))
print("销售量数据异常值的最小值为:", min(outlier1))
5.2.4 任务实现(wei)
p152






![[创业之路-73] :如何判断一个公司或团队是熵减:凝聚力强、上下一心,还是,熵增:一盘散沙、乌合之众?](https://img-blog.csdnimg.cn/2f6b4562c3ef468e8e327a32df5ef5af.png)