目录
一、前言
二、传统连接方式的弊端分析
1.局限性 :
2.几个弊端 :
三、数据库连接池
1.基本介绍 :
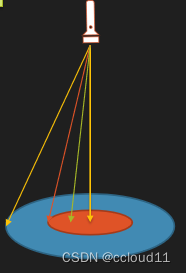
2.示意图如下 :
3.连接池种类 :
四、C3P0连接池
0.准备工作 :
1.方式一 —— 程序中指定相关参数 :
2.方式二 —— 通过配置文件 :
五、Druid(德鲁伊连接池)
0.准备工作 :
1.应用实例 :
2.工具类 :
六、总结
一、前言
- 第五节内容,up打算和大家分享一下JDBC——连接池相关的内容。
- 注意事项——①代码中的注释也很重要;②不要眼高手低;③点击文章的侧边栏目录或者文章开头的目录可以进行跳转。
- 良工不示人以朴,所有文章都会适时补充完善。大家如果有问题都可以在评论区进行交流或者私信up。 感谢阅读!
二、传统连接方式的弊端分析
1.局限性 :
我们知道,JDBC连接MySQL本质上还是走了Socket连接,即网络通讯;当Java程序在同一时间间隔内要与数据库建立较多连接时,会消耗较长的时间,网络开销大。
而且,Java程序通过JDBC连接数据库的最大连接数是有限制的,如果同一时间间隔内Java程序要建立很多与数据库的连接,甚至有多个Java程序都要与数据库建立连接,很可能会把数据库给干爆,导致数据库瘫痪,跑不起来;此时Java程序会抛出"Too many connections"异常。
2.几个弊端 :
1° 传统的JDBC连接方式是通过DriverManager类的getConnection方法来获取连接的;每次与数据库建立连接,都需要将获取到的Connection对象加载到内存中,再验证IP地址,用户名和密码等信息(通常消耗0.05~1s 时间,取决于此时计算机的网络卡顿清空和此时的并发线程数)。因此,频繁的建立与数据库的连接会占用很多的系统资源,容易造成服务器崩溃。
2° 每一次建立与数据库的连接后,使用完毕都必须断开连接;否则,如果程序出现异常而未能正常关闭,将导致数据库内存泄漏,最终将导致重启数据库。
3° 传统获取连接的方式,无法控制实际建立连接的数量,若连接过多,也可能导致内存泄漏,MySQL崩溃。
三、数据库连接池
1.基本介绍 :
数据库连接池是指,在Java程序未和数据库建立连接时,就提前创建好一定数量的连接并放入缓冲池中;当Java程序请求建立数据库连接时,就可以直接从缓冲池中“拿出”建立好的连接来用,用完后取消Java程序对该连接的引用即可,连接本身不会中断,只是“放回”了连接池(动态绑定机制)。
数据库连接池负责分配,管理和释放数据库连接,它允许用户程序重复使用一个现有的数据库连接,而不是重新建立一个。(即连接池中的连接是公共的,谁都能用,你用完我可以接着用)
当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
2.示意图如下 :

3.连接池种类 :
1° JDBC的数据库连接池使用javax.sql.DataSource来表示,DataSource只是一个接口,该接口通常由第三方来实现。
2° C3P0数据库连接池,速度相对较慢(只是慢一丢丢),但是稳定性很好,Hibernate,Spring底层用的就是C3P0。
3° DBCP数据库连接池,速度比C3P0快,但是稳定性差。
4° Proxool数据库连接池,有监控连接池状态的功能,但稳定性仍然比C3P0差一些。
5° BoneCP数据库连接池,速度较快。
6° Druid数据库连接池(德鲁伊连接池),由阿里提供,集DBCP,Proxool,C3P0连接池的优点于一身,是日常项目开发中使用频率最高的数据库连接池。
四、C3P0连接池
0.准备工作 :
去谷歌搜索JDBC C3P0,下载C3P0连接池的jar包,如下图所示 :

解压后,在lib目录下可以找到两个jar包,如下图所示 :

同之前导入mysql的jar包类似,将C3P0的这两个jar包拷贝到IDEA中存放jar包的目录下,如下图所示 :

右键jar包,选择“Add as Library...”将jar加入到项目。 加入成功后可以看到jar包下的子目录,如下图所示 :

1.方式一 —— 程序中指定相关参数 :
需要用到com.mchange.v2.c3p0包下的ComboPooledDataSource类来创建数据源对象,这个数据源对象可以理解为连接池的管理者,负责管理池内的连接。
创建数据源对象后,通过setXxx方法来设置参数。
我们来测试一下使用C3P0连接池后,对连接效率的提升大不大。up先用传统方式连接MySQL5000次,统计执行时间;然后再使用C3P0连接池方式,连接MySQL5000次,对比两者的执行时间。
先来看看传统方法,TraditionalWay类代码如下 :
package connection_pool.c3p0;
import utils.JDBCUtils;
import java.sql.Connection;
public class TraditionalWay {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = JDBCUtils.getConnection();
JDBCUtils.close(null, null, connection);
}
long end = System.currentTimeMillis();
System.out.println("传统方式下,连接MySQL5000次需要用时" + (end - start) + "ms");
}
}
运行结果 :
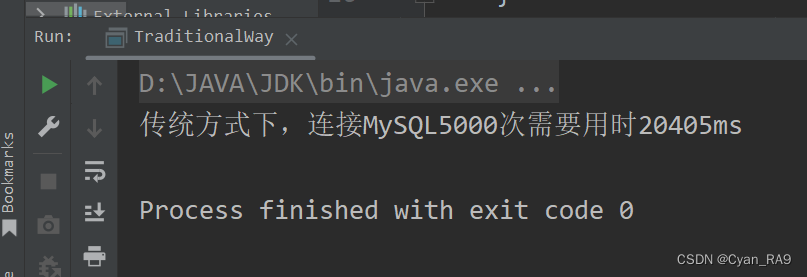
足足20多秒,来看看使用C3P0连接池后连接MySQL 5000次需要多次时间,up以C3P0_Demo1类为演示类,代码如下 :
package connection_pool.c3p0;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import java.beans.PropertyVetoException;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class C3P0_Demo1 {
public static void main(String[] args) throws IOException, PropertyVetoException, SQLException {
//创建数据源对象
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
//从properties配置文件中获取相关信息
Properties properties = new Properties();
properties.load(new FileInputStream("src/api/connection/mysql.properties"));
String driver = properties.getProperty("driver");
String url = properties.getProperty("url");
String user = properties.getProperty("user");
String password = properties.getProperty("password");
//通过ComboPooledDataSource类的setXxx方法来设置信息
comboPooledDataSource.setDriverClass(driver);
comboPooledDataSource.setJdbcUrl(url);
comboPooledDataSource.setUser(user);
comboPooledDataSource.setPassword(password);
//设置连接池初始连接数
comboPooledDataSource.setInitialPoolSize(10);
//设置连接池最大连接数
comboPooledDataSource.setMaxPoolSize(50);
/**
* 初始连接数指连接池被创建后初始化连接的数量;
* 最大连接数指连接池内的连接最多50个;
* 当50个连接全部被使用时,新的连接请求就会进入等待队列。
*/
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; ++i) {
//获取连接
Connection connection = comboPooledDataSource.getConnection();
//释放资源(仅仅是取消了对连接池内连接的引用,连接本身不受影响。
connection.close();
}
long end = System.currentTimeMillis();
System.out.println("使用C3P0连接池后,连接MySQL5000次需要" + (end - start) + "ms");
}
}
运行结果 :
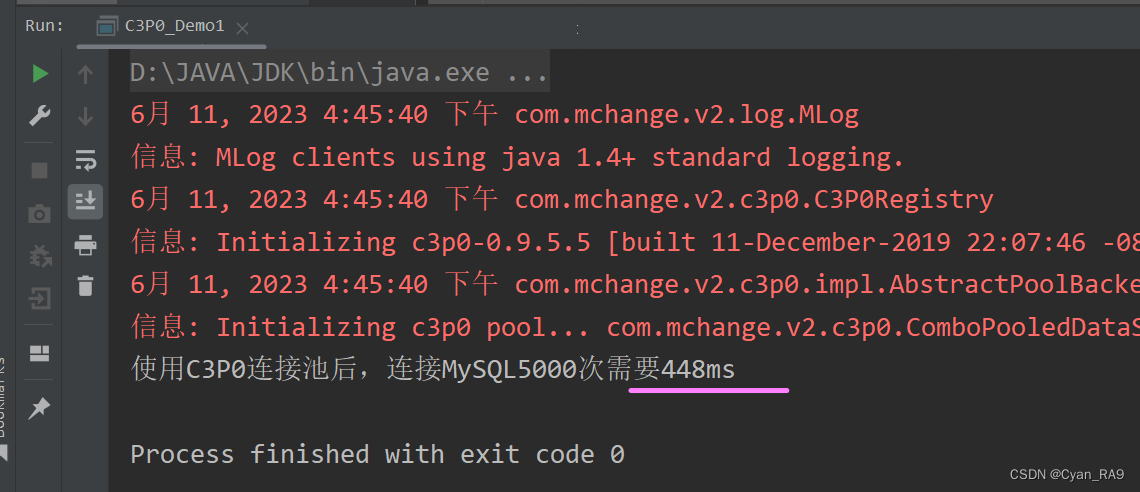
只用了不到1s,性能的提升显而易见。
2.方式二 —— 通过配置文件 :
C3P0连接池提供了一个配置文件c3p0-config.xml(名称格式固定),包含了连接数据库的常用信息。大家可以去官网下载模板自己写,也可以直接Google找一个现成的。
up的c3p0-config.xml文件内容如下 (需要更改):
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<!-- 数据源名称,代表连接池 -->
<named-config name="Cyan">
<!-- 配置数据库用户名 -->
<property name="user">root</property>
<!-- 配置数据库密码 -->
<property name="password">RA9_Cyan</property>
<!-- 配置数据库URL -->
<property name="jdbcUrl">jdbc:mysql://localhost:3306/jdbc_ex</property>
<!-- 配置数据库驱动 -->
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<!-- 数据库连接池一次性向数据库要多少个连接对象 -->
<property name="acquireIncrement">20</property>
<!-- 初始化连接数 -->
<property name="initialPoolSize">10</property>
<!-- 最小连接数 -->
<property name="minPoolSize">5</property>
<!-- 最大连接数。Default: 15 -->
<property name="maxPoolSize">50</property>
<!-- 可连接的最多命令对象数 -->
<property name="maxStatements">5</property>
<!-- 每个连接对象可连接的最多命令对象数 -->
<property name="maxStatementsPerConnection">2</property>
<!--c3p0是异步操作的,缓慢的JDBC操作通过帮助进程完成。扩展这些操作可以有效的提升性能 通过多线程实现多个操作同时被执行。Default:3 -->
<property name="numHelperThreads">3</property>
<!--用户修改系统配置参数执行前最多等待300秒。Default: 300 -->
<property name="propertyCycle">3</property>
<!-- 获取连接超时设置 默认是一直等待单位毫秒 -->
<property name="checkoutTimeout">1000</property>
<!--每多少秒检查所有连接池中的空闲连接。Default: 0 -->
<property name="idleConnectionTestPeriod">3</property>
<!--最大空闲时间,多少秒内未使用则连接被丢弃。若为0则永不丢弃。Default: 0 -->
<property name="maxIdleTime">10</property>
<!--配置连接的生存时间,超过这个时间的连接将由连接池自动断开丢弃掉。当然正在使用的连接不会马上断开,而是等待它close再断开。配置为0的时候则不会对连接的生存时间进行限制。 -->
<property name="maxIdleTimeExcessConnections">5</property>
<!--两次连接中间隔时间,单位毫秒。Default: 1000 -->
<property name="acquireRetryDelay">1000</property>
<!--c3p0将建一张名为Test的空表,并使用其自带的查询语句进行测试。如果定义了这个参数那么属性preferredTestQuery将被忽略。你不能在这张Test表上进行任何操作,它将只供c3p0测试使用。Default: null -->
<property name="automaticTestTable">Test</property>
<!-- 获取connection时测试是否有效 -->
<property name="testConnectionOnCheckin">true</property>
</named-config>
</c3p0-config>然后将c3p0-config.xml配置文件复制到当前的src目录下即可。注意,如果你使用up提供的c3p0-config.xml,一定要修改的是数据库的URL,更改为你要连的数据库的名称;以及你要登录的用户名和密码。如下图所示 :
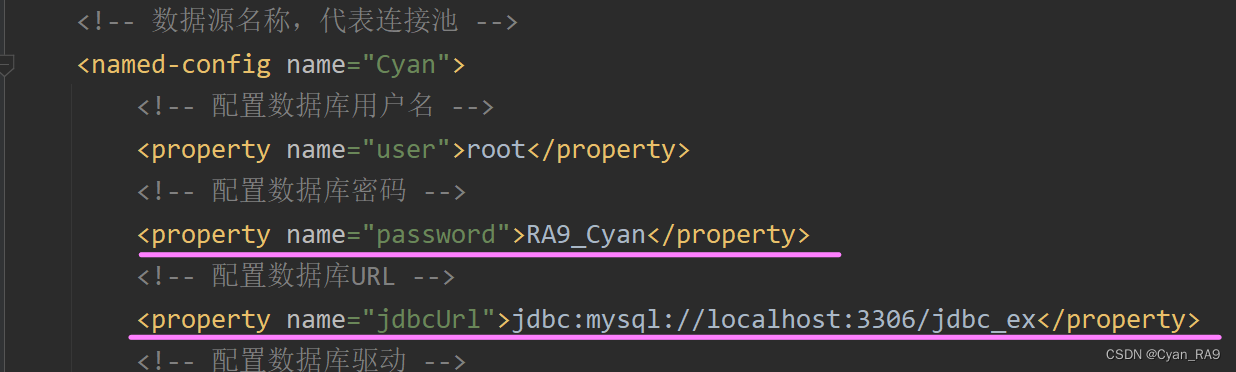
有了c3p0-config.xml配置文件后,我们只需要在创建ComboPooledDataSource对象时,传入数据源名称即可。
以C3P0_Demo2类为演示类,仍然测试一下连接MySQL5000次所需要的时间。
代码如下 :
package connection_pool.c3p0;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class C3P0_Demo2 {
public static void main(String[] args) throws SQLException {
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource("Cyan");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = comboPooledDataSource.getConnection();
connection.close();
}
long end = System.currentTimeMillis();
System.out.println("通过配置文件设置参数后,C3P0连接池连接5000次MySQL耗时" + (end - start) + "ms");
}
}
运行结果 :

可以看到,相比第一种方式时间略微增长,但两者都是一个数量级别,仍然可以说明使用连接池提高了连接效率。
五、Druid(德鲁伊连接池)
0.准备工作 :
谷歌直接搜Druid.jar下载,有很多教程里都有官方网址,网址如下 :
https://repo1.maven.org/maven2/com/alibaba/druid/1.2.9/,一直往下拉下载最新版jar包即可(注意是jar包,别下错了)。
然后,还是老规矩,把下好的jar包复制到IDEA中的存放jar包的目录一份,如下图所示 :

接着,导入jar包,导入后效果如下 :
同C3P0类似,我们也需要导入Druid连接池的配置文件,配置文件如下 :
# 驱动名称(连接MySQL)
driverClassName=com.mysql.cj.jdbc.Driver
# 参数?rewriteBatchedStatements=true表示支持批处理机制
url=jdbc:mysql://localhost:3306/jdbc_ex?rewriteBatchedStatements=true
# 用户名,注意这里是按“username”来读取的
username=root
# 用户密码(自己改)
password=RA9_Cyan
# 初始化连接数量
initialSize=10
# 最小连接数量
minIdle = 5
# 最大连接数量
maxActive=50
# 超时时间5000ms(在等待队列中的最长等待时间,若超过,放弃此次请求)
maxWait=5000
注意,登录用户的信息,以及url一定要自行按需更改!
同样地,将配置文件复制到当前项目的src目录下,如下图所示 :

1.应用实例 :
有了配置文件后,我们可以通过jar包中提供的DruidDataSourceFactory类——中的createDataSource(properties)方法,来创建一个指定参数的数据库连接池对象。其实就和之前的C3P0流程差不多,只不过C3P0创建数据源对象时,是传入了数据源的名称。
以Druid_Demo1类为演示类,代码如下 :
package connection_pool.druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.sql.Connection;
import java.util.Properties;
public class Druid_Demo1 {
public static void main(String[] args) throws Exception {
//加载配置文件
Properties properties = new Properties();
properties.load(new FileInputStream("src\\druid.properties"));
//创建一个指定参数的数据库连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; ++i) {
Connection connection = dataSource.getConnection();
connection.close();
}
long end = System.currentTimeMillis();
System.out.println("德鲁伊连接池,连接MySQL5000次耗时" + (end - start) + "ms");
}
}
运行结果 :
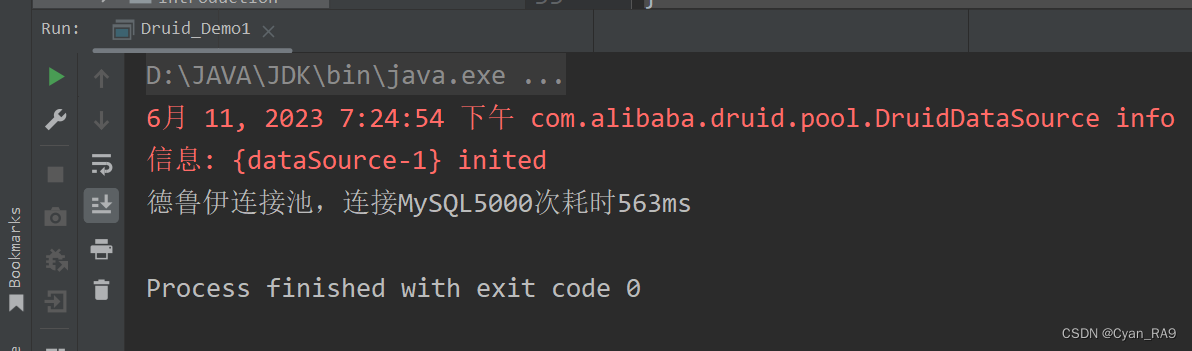
可以看到,563相比C3P0的849,确实快了那么一丢丢。
这时候可能就要有p小将(Personable小将,指风度翩翩的人)出来挑刺儿问了:前面把德鲁伊吹得那么神,结果还是和C3P0一个数量级捏😅,up不会是阿孝子吧?🤗
p哥误会了,up是华孝子(bushi)。 其实,之所以两者的差别不大,是因为我们给的连接数太小了,5000个连接咋一看还挺多,但对于一个项目来说就是杯水车薪。
于是乎,我们接下来把C3P0和德鲁伊的测试连接数都改为50个w,如下图所示 :

C3P0的执行结果如下 :

哎呀我趣,15s多,low!
再来看看我伟大的德鲁伊!
Druid的执行结果如下 :
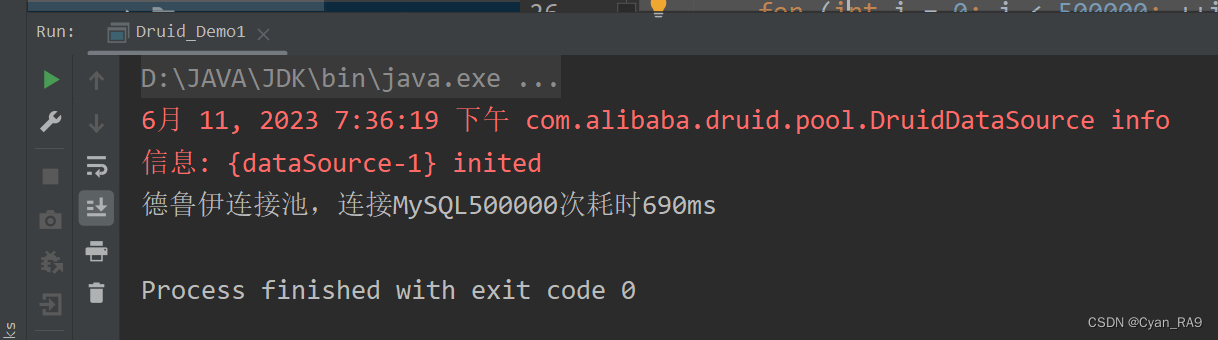
😎碾压局!德鲁伊,yyds。
2.工具类 :
还记得我们在JDBC 第三节讲到的JDBCUtils工具类吗?
当然我们将JDBC核心四部曲中的“获取连接”和“释放资源”的操作封装到了JDBCUtils工具类中,为我们提供了不少便利。但是,再便利也只是传统方式,时代变了!我们有必要对工具类进行升级——将其改造为"德鲁伊工具类"。
up以JDBCUtilsDruid类为例,代码如下 :
package connection_pool.druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class JDBCUtilsDruid {
private static DataSource dataSource;
static {
Properties properties = new Properties();
try {
properties.load(new FileInputStream("src\\druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//获取连接
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
//释放资源
/**
* 1.使用了数据库连接池技术后,close并不是真正地关闭与数据库的连接,
* 而只是取消了对连接池中连接的引用,将所用完的Connection对象放回了连接池。
* 2.简单地说,由于Connection本身是个接口,因此根据动态绑定机制,实际中调用
* 的close方法可以来自不同的实现类,底层处理机制也自然不尽相同。
*/
public static void close(ResultSet resultSet, Statement statement, Connection connection) {
try {
if (resultSet != null) {
resultSet.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
那我们就趁热打铁,来用用这个工具类。
up以DruidUtils_Test类为演示类,代码如下 :
package connection_pool.druid;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class DruidUtils_Test {
public static void main(String[] args) throws ClassNotFoundException {
//核心四部曲
//1.注册驱动(会根据配置文件中的driverClassName信息自动注册)
//Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
//3.执行SQL
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
String sql = "SELECT * " +
"FROM fruit ";
try {
connection = JDBCUtilsDruid.getConnection();
System.out.println(connection.getClass());
System.out.println("---------------------------------");
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int sweetness = resultSet.getInt("sweetness");
System.out.println(String.format("%d\t%s\t%d\t", id,name,sweetness));
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//4.释放资源
JDBCUtilsDruid.close(resultSet, preparedStatement, connection);
}
}
}
运行结果 :
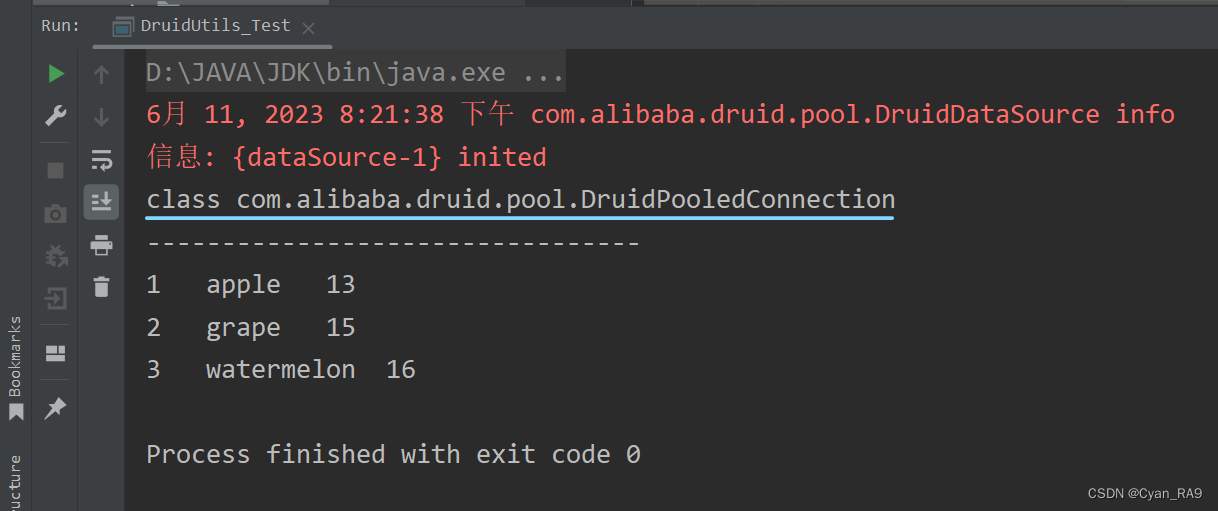
测试成功了。而且可以看到,此时Connection的运行类型是DruidPooledConnection类。
六、总结
- 🆗,以上就是JDBC系列博文第五节的全部内容了。
- 总结一下,我们先分析了传统连接方式的弊端——传统连接方式网络开销大,连接数受限制;于是我们引入了数据库连接池的概念——提前创建好一定数量的连接并放入缓冲池中;接着,我们又着重学习了C3P0(老牌连接池)和Druid(阿里巴巴)的导入和使用;最后,我们又将德鲁伊与工具类相结合,打造了🐂🍺的德鲁伊连接池。大家至少要掌握C3P0和德鲁伊连接池的具体使用流程。
- 下一节内容——JDBC ApacheDBUtils,我们不见不散。感谢阅读!
System.out.println("END-----------------------------------------------------------------------------");