文章目录
- 一、多元向量的泰勒级数展开
- 二、扩展Kalman滤波
- 三、二阶滤波
- 四、迭代EKF滤波
一、多元向量的泰勒级数展开
{ y 1 = f 1 ( X ) = f 1 ( x 1 , x 2 , ⋯ x n ) y 2 = f 2 ( X ) = f 2 ( x 1 , x 2 , ⋯ x n ) ⋮ y m = f m ( X ) = f m ( x 1 , x 2 , ⋯ x n ) \left\{\begin{array}{c} y_{1}=f_{1}(\boldsymbol{X})=f_{1}\left(x_{1}, x_{2}, \cdots x_{n}\right) \\ y_{2}=f_{2}(\boldsymbol{X})=f_{2}\left(x_{1}, x_{2}, \cdots x_{n}\right) \\ \quad \vdots \\ y_{m}=f_{m}(\boldsymbol{X})=f_{m}\left(x_{1}, x_{2}, \cdots x_{n}\right) \end{array}\right. ⎩ ⎨ ⎧y1=f1(X)=f1(x1,x2,⋯xn)y2=f2(X)=f2(x1,x2,⋯xn)⋮ym=fm(X)=fm(x1,x2,⋯xn)
上面线性方差组,写成向量形式就是:
Y
=
f
(
X
)
\boldsymbol{Y} = \boldsymbol{f} \left( \boldsymbol{X}\right)
Y=f(X)
泰勒展开式为:
Y
=
f
(
X
(
0
)
)
+
∑
i
=
1
∞
1
i
!
(
∇
T
⋅
δ
X
)
i
f
(
X
(
0
)
)
\boldsymbol{Y}=\boldsymbol{f}\left(\boldsymbol{X}^{(0)}\right)+\sum_{i=1}^{\infty} \frac{1}{i !}\left(\nabla^{\mathrm{T}} \cdot \delta \boldsymbol{X}\right)^{i} \boldsymbol{f}\left(\boldsymbol{X}^{(0)}\right)
Y=f(X(0))+i=1∑∞i!1(∇T⋅δX)if(X(0))
其中
δ
X
=
X
−
X
(
0
)
\delta \boldsymbol{X}=\boldsymbol{X}-\boldsymbol{X}^{(0)}
δX=X−X(0) ,
∇
=
[
∂
∂
x
1
∂
∂
x
2
⋯
∂
∂
x
n
]
T
\nabla=\left[\begin{array}{llll}\frac{\partial}{\partial x{1}} & \frac{\partial}{\partial x{2}} & \cdots & \frac{\partial}{\partial x_{n}}\end{array}\right]^{\mathrm{T}}
∇=[∂x1∂∂x2∂⋯∂xn∂]T
一阶导代表梯度、二阶导代表曲率半径
一阶展开项的详细展开式:
标量的求导运算对向量求导是对向量里的每一个元素求导,
m
m
m 列多元函数对
n
n
n 行的自变量求导:
1
1
(
∇
T
⋅
δ
X
)
′
f
(
X
(
0
)
)
=
(
∂
∂
x
1
δ
x
1
+
∂
∂
x
2
δ
x
2
+
⋯
+
∂
∂
x
n
δ
x
n
)
f
(
X
)
∣
X
=
X
(
0
)
=
[
∂
f
1
(
X
)
∂
x
1
δ
x
1
+
∂
f
1
(
X
)
∂
x
2
δ
x
2
+
⋯
+
∂
f
1
(
X
)
∂
x
n
δ
x
n
∂
f
2
(
X
)
∂
x
1
δ
x
1
+
∂
f
2
(
X
)
∂
x
2
δ
x
2
+
⋯
+
∂
f
2
(
X
)
∂
x
n
δ
x
n
∂
f
m
(
X
)
∂
x
1
δ
x
1
+
∂
f
m
(
X
)
∂
x
2
δ
x
2
+
⋯
+
∂
f
m
(
X
)
∂
x
n
δ
x
n
]
X
=
X
(
0
)
=
[
∂
f
1
(
X
)
∂
x
1
∂
f
1
(
X
)
∂
x
2
⋯
∂
f
1
(
X
)
∂
x
n
∂
f
2
(
X
)
∂
x
1
∂
f
2
(
X
)
∂
x
2
⋯
∂
f
2
(
X
)
∂
x
n
⋮
⋮
⋱
⋮
∂
f
m
(
X
)
∂
x
1
∂
f
m
(
X
)
∂
x
2
⋯
∂
f
m
(
X
)
∂
x
n
]
δ
[
δ
x
1
δ
x
2
⋮
δ
x
n
]
X
=
X
(
0
)
=
J
(
f
(
X
)
)
δ
X
∣
X
=
X
(
0
)
\begin{array}{l} \frac{1}{1}\left(\nabla^{\mathrm{T}} \cdot \delta \boldsymbol{X}\right)^{\prime} \boldsymbol{f}\left(\boldsymbol{X}^{(0)}\right)=\left.\left(\frac{\partial}{\partial x_{1}} \delta x_{1}+\frac{\partial}{\partial x_{2}} \delta x_{2}+\cdots+\frac{\partial}{\partial x_{n}} \delta x_{n}\right) \boldsymbol{f}(\boldsymbol{X})\right|_{\boldsymbol{X}=\boldsymbol{X}^{(0)}} \\ =\left[\begin{array}{c} \frac{\partial f_{1}(\boldsymbol{X})}{\partial x_{1}} \delta x_{1}+\frac{\partial f_{1}(\boldsymbol{X})}{\partial x_{2}} \delta x_{2}+\cdots+\frac{\partial f_{1}(\boldsymbol{X})}{\partial x_{n}} \delta x_{n} \\ \frac{\partial f_{2}(\boldsymbol{X})}{\partial x_{1}} \delta x_{1}+\frac{\partial f_{2}(\boldsymbol{X})}{\partial x_{2}} \delta x_{2}+\cdots+\frac{\partial f_{2}(\boldsymbol{X})}{\partial x_{n}} \delta x_{n} \\ \frac{\partial f_{m}(\boldsymbol{X})}{\partial x_{1}} \delta x_{1}+\frac{\partial f_{m}(\boldsymbol{X})}{\partial x_{2}} \delta x_{2}+\cdots+\frac{\partial f_{m}(\boldsymbol{X})}{\partial x_{n}} \delta x_{n} \end{array}\right]_{\boldsymbol{X}=\boldsymbol{X}^{(0)}}=\left[\begin{array}{cccc} \frac{\partial f_{1}(\boldsymbol{X})}{\partial x_{1}} & \frac{\partial f_{1}(\boldsymbol{X})}{\partial x_{2}} & \cdots & \frac{\partial f_{1}(\boldsymbol{X})}{\partial x_{n}} \\ \frac{\partial f_{2}(\boldsymbol{X})}{\partial x_{1}} & \frac{\partial f_{2}(\boldsymbol{X})}{\partial x_{2}} & \cdots & \frac{\partial f_{2}(\boldsymbol{X})}{\partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial f_{m}(\boldsymbol{X})}{\partial x_{1}} & \frac{\partial f_{m}(\boldsymbol{X})}{\partial x_{2}} & \cdots & \frac{\partial f_{m}(\boldsymbol{X})}{\partial x_{n}} \end{array}\right]^{\delta}\left[\begin{array}{c} \delta x_{1} \\ \delta x_{2} \\ \vdots \\ \delta x_{n} \end{array}\right]_{X=X^{(0)}} \\ =\left.J(\boldsymbol{f}(\boldsymbol{X})) \delta \boldsymbol{X}\right|_{X=X^{(0)}} \quad \\ \end{array}
11(∇T⋅δX)′f(X(0))=(∂x1∂δx1+∂x2∂δx2+⋯+∂xn∂δxn)f(X)
X=X(0)=
∂x1∂f1(X)δx1+∂x2∂f1(X)δx2+⋯+∂xn∂f1(X)δxn∂x1∂f2(X)δx1+∂x2∂f2(X)δx2+⋯+∂xn∂f2(X)δxn∂x1∂fm(X)δx1+∂x2∂fm(X)δx2+⋯+∂xn∂fm(X)δxn
X=X(0)=
∂x1∂f1(X)∂x1∂f2(X)⋮∂x1∂fm(X)∂x2∂f1(X)∂x2∂f2(X)⋮∂x2∂fm(X)⋯⋯⋱⋯∂xn∂f1(X)∂xn∂f2(X)⋮∂xn∂fm(X)
δ
δx1δx2⋮δxn
X=X(0)=J(f(X))δX∣X=X(0)
其中
∫
J
(
f
(
X
)
)
=
∂
f
(
X
)
∂
X
T
\int J(\boldsymbol{f}(\boldsymbol{X}))=\frac{\partial \boldsymbol{f}(\boldsymbol{X})}{\partial \boldsymbol{X}^{\mathrm{T}}}
∫J(f(X))=∂XT∂f(X) 可称之为雅各比矩阵,
m
m
m 列多元函数对
n
n
n 行的自变量求一阶导得到的矩阵。
二阶展开项详细表达式:
1
2
(
∇
T
⋅
δ
X
)
2
f
(
X
(
0
)
)
=
1
2
(
∂
∂
x
1
δ
x
1
+
∂
∂
x
2
δ
x
2
+
⋯
+
∂
∂
x
n
δ
x
n
)
2
f
(
X
)
∣
X
=
X
(
0
)
=
1
2
tr
(
[
∂
2
∂
x
1
2
∂
2
∂
x
1
∂
x
2
⋯
∂
2
∂
x
1
∂
x
n
∂
2
∂
x
2
∂
x
1
∂
2
∂
x
2
2
⋯
∂
2
∂
x
2
∂
x
n
⋮
⋮
⋱
⋮
∂
2
∂
x
n
∂
x
1
∂
2
∂
x
n
∂
x
2
⋯
∂
2
∂
x
n
2
]
[
δ
x
1
2
δ
x
1
δ
x
2
⋯
δ
x
1
δ
x
n
δ
x
2
δ
x
1
δ
x
2
2
⋯
δ
x
2
δ
x
n
⋮
⋮
⋱
⋮
δ
x
n
δ
x
1
δ
x
n
δ
x
2
⋯
δ
x
n
2
]
)
f
(
X
)
∣
X
=
X
(
0
)
=
1
2
tr
(
∇
∇
T
⋅
δ
X
δ
X
T
)
f
(
X
)
∣
X
=
X
(
0
)
=
1
2
tr
(
∇
∇
T
⋅
δ
X
δ
X
T
)
∑
j
=
1
m
e
j
f
j
(
X
)
∣
X
=
X
(
0
)
=
1
2
∑
j
=
1
m
e
j
tr
(
∇
∇
T
⋅
δ
X
δ
X
T
)
f
j
(
X
)
∣
X
=
X
(
0
)
=
1
2
∑
j
=
1
m
e
j
tr
(
∇
∇
T
f
j
(
X
)
∣
X
=
X
(
0
)
⋅
δ
X
δ
X
T
)
=
1
2
∑
j
=
1
m
e
j
tr
(
H
(
f
j
(
X
)
∣
X
=
X
(
0
)
⋅
δ
X
δ
X
T
)
\begin{array}{l} \frac{1}{2}\left(\nabla^{\mathrm{T}} \cdot \delta \boldsymbol{X}\right)^{2} \boldsymbol{f}\left(\boldsymbol{X}^{(0)}\right)=\left.\frac{1}{2}\left(\frac{\partial}{\partial x_{1}} \delta x_{1}+\frac{\partial}{\partial x_{2}} \delta x_{2}+\cdots+\frac{\partial}{\partial x_{n}} \delta x_{n}\right)^{2} \boldsymbol{f}(\boldsymbol{X})\right|_{X=X^{(0)}} \\ =\left.\frac{1}{2} \operatorname{tr}\left(\left[\begin{array}{cccc} \frac{\partial^{2}}{\partial x_{1}^{2}} & \frac{\partial^{2}}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2}}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2}}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2}}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2}}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2}}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2}}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2}}{\partial x_{n}^{2}} \end{array}\right]\left[\begin{array}{cccc} \delta x_{1}^{2} & \delta x_{1} \delta x_{2} & \cdots & \delta x_{1} \delta x_{n} \\ \delta x_{2} \delta x_{1} & \delta x_{2}^{2} & \cdots & \delta x_{2} \delta x_{n} \\ \vdots & \vdots & \ddots & \vdots \\ \delta x_{n} \delta x_{1} & \delta x_{n} \delta x_{2} & \cdots & \delta x_{n}^{2} \end{array}\right]\right) \boldsymbol{f}(\boldsymbol{X})\right|_{X=\mathbf{X}^{(0)}} \\ \begin{array}{l} =\left.\frac{1}{2} \operatorname{tr}\left(\nabla \nabla^{\mathrm{T}} \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right) \boldsymbol{f}(\boldsymbol{X})\right|_{X=X^{(0)}}=\left.\frac{1}{2} \operatorname{tr}\left(\nabla \nabla^{\mathrm{T}} \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right) \sum_{j=1}^{m} \boldsymbol{e}_{j} f_{j}(\boldsymbol{X})\right|_{X=X^{(0)}} \\ =\left.\frac{1}{2} \sum_{j=1}^{m} \boldsymbol{e}_{j} \operatorname{tr}\left(\nabla \nabla^{\mathrm{T}} \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right) f_{j}(\boldsymbol{X})\right|_{X=X^{(0)}}=\frac{1}{2} \sum_{j=1}^{m} \boldsymbol{e}_{j} \operatorname{tr}\left(\left.\nabla \nabla^{\mathrm{T}} f_{j}(\boldsymbol{X})\right|_{X=X^{(0)}} \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right) \end{array} \\ =\frac{1}{2} \sum_{j=1}^{m} \boldsymbol{e}_{j} \operatorname{tr}\left(\mathscr{H}\left(\left.f_{j}(\boldsymbol{X})\right|_{X=X^{(0)}} \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right) \quad\right. \\ \end{array}
21(∇T⋅δX)2f(X(0))=21(∂x1∂δx1+∂x2∂δx2+⋯+∂xn∂δxn)2f(X)
X=X(0)=21tr
∂x12∂2∂x2∂x1∂2⋮∂xn∂x1∂2∂x1∂x2∂2∂x22∂2⋮∂xn∂x2∂2⋯⋯⋱⋯∂x1∂xn∂2∂x2∂xn∂2⋮∂xn2∂2
δx12δx2δx1⋮δxnδx1δx1δx2δx22⋮δxnδx2⋯⋯⋱⋯δx1δxnδx2δxn⋮δxn2
f(X)
X=X(0)=21tr(∇∇T⋅δXδXT)f(X)
X=X(0)=21tr(∇∇T⋅δXδXT)∑j=1mejfj(X)
X=X(0)=21∑j=1mejtr(∇∇T⋅δXδXT)fj(X)
X=X(0)=21∑j=1mejtr(∇∇Tfj(X)
X=X(0)⋅δXδXT)=21∑j=1mejtr(H(fj(X)∣X=X(0)⋅δXδXT)
Y = f ( X ( 0 ) ) + J ( f ( X ( 0 ) ) ) δ X + 1 2 ∑ i = 1 m e i tr ( H ( f i ( X ( 0 ) ) ) ⋅ δ X δ X T ) + O 3 \boldsymbol{Y}=\boldsymbol{f}\left(\boldsymbol{X}^{(0)}\right)+J\left(f\left(X^{(0)}\right)\right) \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{m} e_{i} \operatorname{tr}\left(\mathscr{H}\left(f_{i}\left(X^{(0)}\right)\right) \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right)+O^{3} Y=f(X(0))+J(f(X(0)))δX+21i=1∑meitr(H(fi(X(0)))⋅δXδXT)+O3
其中 H \mathscr{H} H 为海森矩阵, m m m 列多元函数对 n n n 行的自变量求二阶导得到的矩阵,m 个向量函数有 m 个海森矩阵。
二、扩展Kalman滤波
遇到非线性的状态空间模型时,对状态方程和量测方程做线性化处理,取泰勒展开的一阶项。
状态空间模型(加性噪声,噪声和状态直接是相加的)
这里简单的用加性噪声模型表示,一般形式为 X k = f ( X k − 1 , W k − 1 , k − 1 ) \boldsymbol{X}_{k}=\boldsymbol{f}\left(\boldsymbol{X}_{k-1}, \boldsymbol{W}_{k-1}, k-1\right) Xk=f(Xk−1,Wk−1,k−1) ,非线性更强,更一般,可以表示噪声和状态之间复杂的关系
{ X k = f ( X k − 1 ) + Γ k − 1 W k − 1 Z k = h ( X k ) + V k \left\{\begin{array}{l}\boldsymbol{X}_{k}=\boldsymbol{f}\left(\boldsymbol{X}_{k-1}\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1} \\ \boldsymbol{Z}_{k}=\boldsymbol{h}\left(\boldsymbol{X}_{k}\right)+\boldsymbol{V}_{k}\end{array}\right. {Xk=f(Xk−1)+Γk−1Wk−1Zk=h(Xk)+Vk
选择 k − 1 k-1 k−1 时刻参考值 X k − 1 n \boldsymbol{X}_{k-1}^{n} Xk−1n ,参考点和真实值偏差 δ X k − 1 = X k − 1 − X k − 1 n \delta \boldsymbol{X}_{k-1}=\boldsymbol{X}_{k-1}-\boldsymbol{X}_{k-1}^{n} δXk−1=Xk−1−Xk−1n
状态一步预测:上一时刻参考点带入状态方程 X k / k − 1 n = f ( X k − 1 n ) \boldsymbol{X}_{k / k-1}^{n}=\boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right) Xk/k−1n=f(Xk−1n) ,预测值的偏差 δ X k = X k − X k / k − 1 n \delta \boldsymbol{X}_{k}=\boldsymbol{X}_{k}-\boldsymbol{X}_{k / k-1}^{n} δXk=Xk−Xk/k−1n 。
量测一步预测: Z k / k − 1 n = h ( X k / k − 1 n ) \boldsymbol{Z}_{k / k-1}^{n}=\boldsymbol{h}\left(\boldsymbol{X}_{k / k-1}^{n}\right) Zk/k−1n=h(Xk/k−1n) ,偏差 δ Z k = Z k − Z k / k − 1 n \delta \boldsymbol{Z}_{k}=\boldsymbol{Z}_{k}-\boldsymbol{Z}_{k / k-1}^{n} δZk=Zk−Zk/k−1n 。
展开得状态偏差方程:
X
k
≈
f
(
X
k
−
1
n
)
+
J
(
f
(
X
k
−
1
n
)
)
(
X
k
−
1
−
X
k
−
1
n
)
+
Γ
k
−
1
W
k
−
1
X
k
−
f
(
X
k
−
1
n
)
≈
Φ
k
/
k
−
1
n
(
X
k
−
1
−
X
k
−
1
n
)
+
Γ
k
−
1
W
k
−
1
δ
X
k
=
Φ
k
/
k
−
1
n
δ
X
k
−
1
+
Γ
k
−
1
W
k
−
1
\begin{array}{ll} & \boldsymbol{X}_{k} \approx \boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right)+\boldsymbol{J}\left(\boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right)\right)\left(\boldsymbol{X}_{k-1}-\boldsymbol{X}_{k-1}^{n}\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1} \\ & \boldsymbol{X}_{k}-\boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right) \approx \boldsymbol{\Phi}_{k / k-1}^{n}\left(\boldsymbol{X}_{k-1}-\boldsymbol{X}_{k-1}^{n}\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1} \\ & \delta \boldsymbol{X}_{k}=\boldsymbol{\Phi}_{k / k-1}^{n} \delta \boldsymbol{X}_{k-1}+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1} \end{array}
Xk≈f(Xk−1n)+J(f(Xk−1n))(Xk−1−Xk−1n)+Γk−1Wk−1Xk−f(Xk−1n)≈Φk/k−1n(Xk−1−Xk−1n)+Γk−1Wk−1δXk=Φk/k−1nδXk−1+Γk−1Wk−1
展开得量测偏差方程:
Z
k
≈
h
(
X
k
/
k
−
1
n
)
+
J
(
h
(
X
k
/
k
−
1
n
)
)
(
X
k
−
X
k
/
k
−
1
n
)
+
V
k
δ
Z
k
=
H
k
n
δ
X
k
+
V
k
\begin{array}{ll} & \boldsymbol{Z}_{k} \approx \boldsymbol{h}\left(\boldsymbol{X}_{k / k-1}^{n}\right)+\boldsymbol{J}\left(\boldsymbol{h}\left(\boldsymbol{X}_{k / k-1}^{n}\right)\right)\left(\boldsymbol{X}_{k}-\boldsymbol{X}_{k / k-1}^{n}\right)+\boldsymbol{V}_{k} \\ & \delta \boldsymbol{Z}_{k}=\boldsymbol{H}_{k}^{n} \delta \boldsymbol{X}_{k}+\boldsymbol{V}_{k} \end{array}
Zk≈h(Xk/k−1n)+J(h(Xk/k−1n))(Xk−Xk/k−1n)+VkδZk=HknδXk+Vk
得偏差状态空间估计模型:
{
δ
X
k
=
Φ
k
∣
k
−
1
n
δ
X
k
−
1
+
Γ
k
−
1
W
k
−
1
δ
Z
k
=
H
k
n
δ
X
k
+
V
k
\left\{\begin{array}{l}\delta \boldsymbol{X}_{k}=\boldsymbol{\Phi}_{k \mid k-1}^{n} \delta \boldsymbol{X}_{k-1}+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1} \\ \delta \boldsymbol{Z}_{k}=\boldsymbol{H}_{k}^{n} \delta \boldsymbol{X}_{k}+\boldsymbol{V}_{k}\end{array}\right.
{δXk=Φk∣k−1nδXk−1+Γk−1Wk−1δZk=HknδXk+Vk
偏差量是线性的了,可以用Kalman滤波进行处理:
滤波更新方程:
δ
X
^
k
=
Φ
k
/
k
−
1
n
δ
X
^
k
−
1
+
K
k
n
(
δ
Z
k
−
H
k
n
Φ
k
/
k
−
1
n
δ
X
^
k
−
1
)
{\color{red}\delta \hat{\boldsymbol{X}}_{k}}=\boldsymbol{\Phi}_{k / k-1}^{n} {\color{green}\delta \hat{\boldsymbol{X}}_{k-1}}+\boldsymbol{K}_{k}^{n}\left(\delta \boldsymbol{Z}_{k}-\boldsymbol{H}_{k}^{n} \boldsymbol{\Phi}_{k / k-1}^{n} {\color{green}\delta \hat{\boldsymbol{X}}_{k-1}}\right)
δX^k=Φk/k−1nδX^k−1+Kkn(δZk−HknΦk/k−1nδX^k−1)
⟶
δ
X
^
k
=
X
^
k
−
X
k
/
k
−
1
n
δ
X
^
k
−
1
=
X
^
k
−
1
−
X
k
−
1
n
X
^
k
=
X
k
/
k
−
1
n
+
K
k
n
(
Z
k
−
Z
k
/
k
−
1
n
)
+
(
I
−
K
k
n
H
k
n
)
Φ
k
/
k
−
1
n
(
X
^
k
−
1
−
X
k
−
1
n
)
⟶
X
k
−
1
n
=
X
^
k
−
1
=
X
k
/
k
−
1
n
+
K
k
n
(
Z
k
−
Z
k
/
k
−
1
n
)
\begin{array}{l} \underset{\delta \hat{\boldsymbol{X}}_{k-1}=\hat{\boldsymbol{X}}_{k-1}-\boldsymbol{X}_{k-1}^{n}}{\underset{\delta \hat{\boldsymbol{X}}_{k}=\hat{\boldsymbol{X}}_{k}-\boldsymbol{X}_{k / k-1}^{n}}{\longrightarrow}} \hat{\boldsymbol{X}}_{k}=\boldsymbol{X}_{k / k-1}^{n}+\boldsymbol{K}_{k}^{n}\left(\boldsymbol{Z}_{k}-\boldsymbol{Z}_{k / k-1}^{n}\right)+\left(\boldsymbol{I}-\boldsymbol{K}_{k}^{n} \boldsymbol{H}_{k}^{n}\right) \boldsymbol{\Phi}_{k / k-1}^{n}\left(\hat{\boldsymbol{X}}_{k-1}-\boldsymbol{X}_{k-1}^{n}\right) \\ \stackrel{\boldsymbol{X}_{k-1}^{n}=\hat{\boldsymbol{X}}_{k-1}}{\longrightarrow}=\boldsymbol{X}_{k / k-1}^{n}+\boldsymbol{K}_{k}^{n}\left(\boldsymbol{Z}_{k}-\boldsymbol{Z}_{k / k-1}^{n}\right) \end{array}
δX^k−1=X^k−1−Xk−1nδX^k=X^k−Xk/k−1n⟶X^k=Xk/k−1n+Kkn(Zk−Zk/k−1n)+(I−KknHkn)Φk/k−1n(X^k−1−Xk−1n)⟶Xk−1n=X^k−1=Xk/k−1n+Kkn(Zk−Zk/k−1n)
将
δ
X
^
k
−
1
=
X
^
k
−
1
−
X
k
−
1
n
{\color{green}\delta \hat{\boldsymbol{X}}_{k-1}=\hat{\boldsymbol{X}}_{k-1}-\boldsymbol{X}_{k-1}^{n}}
δX^k−1=X^k−1−Xk−1n 和
δ
X
^
k
=
X
^
k
−
X
k
/
k
−
1
n
{\color{red}\delta \hat{\boldsymbol{X}}_{k}=\hat{\boldsymbol{X}}_{k}-\boldsymbol{X}_{k / k-1}^{n}}
δX^k=X^k−Xk/k−1n 带入得:
X
^
k
=
X
k
/
k
−
1
n
+
K
k
n
(
Z
k
−
Z
k
/
k
−
1
n
)
+
(
I
−
K
k
n
H
k
n
)
Φ
k
/
k
−
1
n
(
X
^
k
−
1
−
X
k
−
1
n
)
\hat{\boldsymbol{X}}_{k}=\boldsymbol{X}_{k / k-1}^{n}+\boldsymbol{K}_{k}^{n}\left(\boldsymbol{Z}_{k}-\boldsymbol{Z}_{k / k-1}^{n}\right)+{\color{pink} \left(\boldsymbol{I}-\boldsymbol{K}_{k}^{n} \boldsymbol{H}_{k}^{n}\right) \boldsymbol{\Phi}_{k / k-1}^{n}\left(\hat{\boldsymbol{X}}_{k-1}-\boldsymbol{X}_{k-1}^{n}\right)}
X^k=Xk/k−1n+Kkn(Zk−Zk/k−1n)+(I−KknHkn)Φk/k−1n(X^k−1−Xk−1n)
此公式就相当于对状态进行操作。前面部分就是Kalman滤波方程。后面多出的粉色部分包含了参考值,令
X
k
−
1
n
=
X
^
k
−
1
\boldsymbol{X}_{k-1}^{n}=\hat{\boldsymbol{X}}_{k-1}
Xk−1n=X^k−1 ,参考点选成上一时刻的估计值,后面一部分就为
0
0
0 ,得
X
k
/
k
−
1
n
+
K
k
n
(
Z
k
−
Z
k
/
k
−
1
n
)
\boldsymbol{X}_{k / k-1}^{n}+\boldsymbol{K}_{k}^{n}\left(\boldsymbol{Z}_{k}-\boldsymbol{Z}_{k / k-1}^{n}\right)
Xk/k−1n+Kkn(Zk−Zk/k−1n)
EKF滤波公式汇总
{
X
^
k
/
k
−
1
=
f
(
X
^
k
−
1
)
P
k
/
k
−
1
=
Φ
k
/
k
−
1
P
k
−
1
Φ
k
/
k
−
1
T
+
Γ
k
−
1
Q
k
−
1
Γ
k
−
1
T
Φ
k
/
k
−
1
=
J
(
f
(
X
^
k
−
1
)
)
K
k
=
P
k
/
k
−
1
H
k
T
(
H
k
P
k
/
k
−
1
H
k
T
+
R
k
)
−
1
H
k
=
J
(
h
(
X
^
k
/
k
−
1
)
)
X
^
k
=
X
^
k
/
k
−
1
+
K
k
[
Z
k
−
h
(
X
^
k
/
k
−
1
)
]
P
k
=
(
I
−
K
k
H
k
)
P
k
/
k
−
1
\left\{\begin{array}{ll}\hat{\boldsymbol{X}}_{k / k-1}=\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right) & \\ \boldsymbol{P}_{k / k-1}={\color{red}\boldsymbol{\Phi}_{k / k-1}} \boldsymbol{P}_{k-1} {\color{red}\boldsymbol{\Phi}_{k / k-1}^{\mathrm{T}}}+\boldsymbol{\Gamma}_{k-1} \boldsymbol{Q}_{k-1} \boldsymbol{\Gamma}_{k-1}^{\mathrm{T}} & {\color{red}\boldsymbol{\Phi}_{k / k-1}=\boldsymbol{J}\left(\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right)\right)} \\ \boldsymbol{K}_{k}=\boldsymbol{P}_{k / k-1} {\color{green}\boldsymbol{H}_{k}^{\mathrm{T}}}\left({\color{green}\boldsymbol{H}_{k}} \boldsymbol{P}_{k / k-1} {\color{green}\boldsymbol{H}_{k}^{\mathrm{T}}}+\boldsymbol{R}_{k}\right)^{-1} & {\color{green}\boldsymbol{H}_{k}=\boldsymbol{J}\left(\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}\right)\right)} \\ \hat{\boldsymbol{X}}_{k}=\hat{\boldsymbol{X}}_{k / k-1}+\boldsymbol{K}_{k}\left[\boldsymbol{Z}_{k}-\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}\right)\right] & \\ \boldsymbol{P}_{k}=\left(\boldsymbol{I}-\boldsymbol{K}_{k} {\color{green}\boldsymbol{H}_{k}}\right) \boldsymbol{P}_{k / k-1} & \end{array}\right.
⎩
⎨
⎧X^k/k−1=f(X^k−1)Pk/k−1=Φk/k−1Pk−1Φk/k−1T+Γk−1Qk−1Γk−1TKk=Pk/k−1HkT(HkPk/k−1HkT+Rk)−1X^k=X^k/k−1+Kk[Zk−h(X^k/k−1)]Pk=(I−KkHk)Pk/k−1Φk/k−1=J(f(X^k−1))Hk=J(h(X^k/k−1))
- 状态转移矩阵是状态方程在 k − 1 k-1 k−1 处的一阶偏导组成的雅可比矩阵。
- 设计矩阵是量测方程在 k − 1 k-1 k−1 处的一阶偏导组成的雅可比矩阵。
三、二阶滤波
状态方程的二阶泰勒展开:
X
k
=
f
(
X
k
−
1
n
)
+
Φ
k
/
k
−
1
n
δ
X
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
−
⋅
δ
X
δ
X
T
)
+
Γ
k
−
1
W
k
−
1
\boldsymbol{X}_{k}=\boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right)+\boldsymbol{\Phi}_{k / k-1}^{n} \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i}^{-} \cdot \boldsymbol{\delta} \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1}
Xk=f(Xk−1n)+Φk/k−1nδX+21i=1∑neitr(Dfi−⋅δXδXT)+Γk−1Wk−1
状态预测:上面的方程两边求均值得:
X
^
k
/
k
−
1
=
E
[
f
(
X
k
−
1
n
)
+
Φ
k
/
k
−
1
n
δ
X
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
⋅
δ
X
δ
X
T
)
+
Γ
k
−
1
W
k
−
1
]
=
f
(
X
k
−
1
n
)
+
Φ
k
/
k
−
1
n
E
[
δ
X
]
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
⋅
E
[
δ
X
δ
X
T
]
)
+
Γ
k
−
1
E
[
W
k
−
1
]
=
f
(
X
k
−
1
n
)
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
P
k
−
1
)
\begin{aligned} \hat{\boldsymbol{X}}_{k / k-1} & =\mathrm{E}\left[\boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right)+\boldsymbol{\Phi}_{k / k-1}^{n} \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i} \cdot \boldsymbol{\delta} \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1}\right] \\ & =\boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right)+\boldsymbol{\Phi}_{k / k-1}^{n} \mathrm{E}[\delta \boldsymbol{X}]+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i} \cdot \mathrm{E}\left[\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right]\right)+\boldsymbol{\Gamma}_{k-1} \mathrm{E}\left[\boldsymbol{W}_{k-1}\right] \\ & =\boldsymbol{f}\left(\boldsymbol{X}_{k-1}^{n}\right)+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i} \boldsymbol{P}_{k-1}\right) \end{aligned}
X^k/k−1=E[f(Xk−1n)+Φk/k−1nδX+21i=1∑neitr(Dfi⋅δXδXT)+Γk−1Wk−1]=f(Xk−1n)+Φk/k−1nE[δX]+21i=1∑neitr(Dfi⋅E[δXδXT])+Γk−1E[Wk−1]=f(Xk−1n)+21i=1∑neitr(DfiPk−1)
状态预测既和状态的传递有关系,也和方差
P
P
P 阵有关系,比较麻烦。
状态预测的误差:
X
~
k
/
k
−
1
=
X
k
−
X
^
k
/
k
−
1
=
Φ
k
/
k
−
1
n
δ
X
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
⋅
δ
X
δ
X
T
)
+
Γ
k
−
1
W
k
−
1
−
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
P
k
−
1
)
=
Φ
k
/
k
−
1
n
δ
X
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
(
δ
X
δ
X
T
−
P
k
−
1
)
)
+
Γ
k
−
1
W
k
−
1
\begin{aligned} \tilde{\boldsymbol{X}}_{k / k-1} & =\boldsymbol{X}_{k}-\hat{\boldsymbol{X}}_{k / k-1} \\ & =\boldsymbol{\Phi}_{k / k-1}^{n} \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i} \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1}-\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i} \boldsymbol{P}_{k-1}\right) \\ & =\boldsymbol{\Phi}_{k / k-1}^{n} \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i}\left(\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}-\boldsymbol{P}_{k-1}\right)\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1} \end{aligned}
X~k/k−1=Xk−X^k/k−1=Φk/k−1nδX+21i=1∑neitr(Dfi⋅δXδXT)+Γk−1Wk−1−21i=1∑neitr(DfiPk−1)=Φk/k−1nδX+21i=1∑neitr(Dfi(δXδXT−Pk−1))+Γk−1Wk−1
状态预测的方差:比较复杂,最后算下来和四阶矩有关系
P
k
/
k
−
1
=
E
[
X
~
k
/
k
−
1
X
~
k
/
k
−
1
T
]
=
E
[
[
Φ
k
∣
k
−
1
n
δ
X
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
(
δ
X
δ
X
T
−
P
k
−
1
)
)
+
Γ
k
−
1
W
k
−
1
]
×
[
Φ
k
l
k
−
1
n
δ
X
+
1
2
∑
i
=
1
n
e
i
tr
(
D
f
i
(
δ
X
δ
X
T
−
P
k
−
1
)
)
+
Γ
k
−
1
W
k
−
1
]
T
]
=
Φ
k
k
/
k
−
1
n
P
k
−
1
(
Φ
k
/
k
−
1
n
)
T
+
1
4
E
[
∑
i
=
1
n
e
i
tr
(
D
f
i
(
δ
X
δ
X
T
−
P
k
−
1
)
)
(
∑
i
=
1
n
e
i
tr
(
D
f
i
(
δ
X
δ
X
T
−
P
k
−
1
)
)
)
T
]
+
Γ
k
−
1
Q
k
−
1
Γ
k
−
1
T
=
Φ
k
/
k
−
1
n
P
k
−
1
(
Φ
k
/
k
−
1
n
)
T
+
1
4
∑
i
=
1
n
∑
j
=
1
n
e
i
e
j
T
E
[
tr
(
D
f
i
(
δ
X
δ
X
T
−
P
k
−
1
)
)
⋅
tr
(
D
j
j
(
δ
X
δ
X
T
−
P
k
−
1
)
)
]
+
Γ
k
−
1
Q
k
−
1
Γ
k
−
1
T
=
Φ
k
/
k
−
1
n
P
k
−
1
(
Φ
k
/
k
−
1
n
)
T
+
1
2
∑
i
=
1
n
∑
j
=
1
n
e
i
e
j
T
tr
(
D
f
i
P
k
−
1
D
f
j
P
k
−
1
)
+
Γ
k
−
1
Q
k
−
1
Γ
k
−
1
T
\begin{array}{l} \boldsymbol{P}_{k / k-1}=\mathrm{E}\left[\tilde{\boldsymbol{X}}_{k / k-1} \tilde{\boldsymbol{X}}_{k / k-1}^{\mathrm{T}}\right] \\ =\mathrm{E}\left[\left[\boldsymbol{\Phi}_{k \mid k-1}^{n} \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i}\left(\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}-\boldsymbol{P}_{k-1}\right)\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1}\right]\right. \\ \left.\times\left[\boldsymbol{\Phi}_{k l k-1}^{n} \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i}\left(\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}-\boldsymbol{P}_{k-1}\right)\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{W}_{k-1}\right]^{\mathrm{T}}\right] \\ =\boldsymbol{\Phi}_{k k / k-1}^{n} \boldsymbol{P}_{k-1}\left(\boldsymbol{\Phi}_{k / k-1}^{n}\right)^{\mathrm{T}} \\ +\frac{1}{4} \mathrm{E}\left[\sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f i}\left(\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}-\boldsymbol{P}_{k-1}\right)\right)\left(\sum_{i=1}^{n} \boldsymbol{e}_{i} \operatorname{tr}\left(\boldsymbol{D}_{f_{i}}\left(\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}-\boldsymbol{P}_{k-1}\right)\right)\right)^{\mathrm{T}}\right]+\boldsymbol{\Gamma}_{k-1} \boldsymbol{Q}_{k-1} \boldsymbol{\Gamma}_{k-1}^{\mathrm{T}} \\ =\boldsymbol{\Phi}_{k / k-1}^{n} \boldsymbol{P}_{k-1}\left(\boldsymbol{\Phi}_{k / k-1}^{n}\right)^{\mathrm{T}} \\ +\frac{1}{4} \sum_{i=1}^{n} \sum_{j=1}^{n} \boldsymbol{e}_{i} \boldsymbol{e}_{j}^{\mathrm{T}} \mathrm{E}\left[\operatorname{tr}\left(\boldsymbol{D}_{f i}\left(\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}-\boldsymbol{P}_{k-1}\right)\right) \cdot \operatorname{tr}\left(\boldsymbol{D}_{j j}\left(\delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}-\boldsymbol{P}_{k-1}\right)\right)\right]+\boldsymbol{\Gamma}_{k-1} \boldsymbol{Q}_{k-1} \boldsymbol{\Gamma}_{k-1}^{\mathrm{T}} \\ =\boldsymbol{\Phi}_{k / k-1}^{n} \boldsymbol{P}_{k-1}\left(\boldsymbol{\Phi}_{k / k-1}^{n}\right)^{\mathrm{T}}+\frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \boldsymbol{e}_{\boldsymbol{i}} \boldsymbol{e}_{j}^{\mathrm{T}} \operatorname{tr}\left(\boldsymbol{D}_{f i} \boldsymbol{P}_{k-1} \boldsymbol{D}_{f j} \boldsymbol{P}_{k-1}\right)+\boldsymbol{\Gamma}_{k-1} \boldsymbol{Q}_{k-1} \boldsymbol{\Gamma}_{k-1}^{\mathrm{T}} \\ \end{array}
Pk/k−1=E[X~k/k−1X~k/k−1T]=E[[Φk∣k−1nδX+21∑i=1neitr(Dfi(δXδXT−Pk−1))+Γk−1Wk−1]×[Φklk−1nδX+21∑i=1neitr(Dfi(δXδXT−Pk−1))+Γk−1Wk−1]T]=Φkk/k−1nPk−1(Φk/k−1n)T+41E[∑i=1neitr(Dfi(δXδXT−Pk−1))(∑i=1neitr(Dfi(δXδXT−Pk−1)))T]+Γk−1Qk−1Γk−1T=Φk/k−1nPk−1(Φk/k−1n)T+41∑i=1n∑j=1neiejTE[tr(Dfi(δXδXT−Pk−1))⋅tr(Djj(δXδXT−Pk−1))]+Γk−1Qk−1Γk−1T=Φk/k−1nPk−1(Φk/k−1n)T+21∑i=1n∑j=1neiejTtr(DfiPk−1DfjPk−1)+Γk−1Qk−1Γk−1T
量测方程的二阶展开:
Z
k
/
k
−
1
=
h
(
X
k
/
k
−
1
n
)
+
H
k
n
δ
X
+
1
2
∑
i
=
1
m
e
i
i
r
(
D
h
i
⋅
δ
X
δ
X
T
)
+
V
k
Z_{k / k-1}=h\left(X_{k / k-1}^{n}\right)+\boldsymbol{H}_{k}^{n} \delta \boldsymbol{X}+\frac{1}{2} \sum_{i=1}^{m} e_{i} i r\left(D_{h i} \cdot \delta \boldsymbol{X} \delta \boldsymbol{X}^{\mathrm{T}}\right)+V_{k}
Zk/k−1=h(Xk/k−1n)+HknδX+21i=1∑meiir(Dhi⋅δXδXT)+Vk
量测预测:
Z
^
k
/
k
−
1
=
h
(
X
k
/
k
−
1
n
)
+
1
2
∑
i
=
1
m
e
i
tr
(
D
h
i
P
k
/
k
−
1
)
\hat{\boldsymbol{Z}}_{k / k-1}=\boldsymbol{h}\left(\boldsymbol{X}_{k / k-1}^{n}\right)+\frac{1}{2} \sum_{i=1}^{m} e_{i} \operatorname{tr}\left(\boldsymbol{D}_{h i} \boldsymbol{P}_{k / k-1}\right)
Z^k/k−1=h(Xk/k−1n)+21i=1∑meitr(DhiPk/k−1)
量测预测方差阵:
P
z
z
,
k
k
−
1
=
H
k
n
P
k
/
k
−
1
(
H
k
n
)
T
+
1
2
∑
i
=
1
m
∑
j
=
1
m
e
i
e
e
j
t
(
D
h
i
P
k
/
k
−
1
D
h
j
P
k
/
k
−
1
)
+
R
k
\boldsymbol{P}_{z z, k k-1}=\boldsymbol{H}_{k}^{n} \boldsymbol{P}_{k / k-1}\left(\boldsymbol{H}_{k}^{n}\right)^{\mathrm{T}}+\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \boldsymbol{e}_{i}^{\mathrm{e}} \mathrm{e}_{j}^{\mathrm{t}}\left(\boldsymbol{D}_{h i} \boldsymbol{P}_{k / k-1} \boldsymbol{D}_{hj} \boldsymbol{P}_{k / k-1}\right)+\boldsymbol{R}_{k}
Pzz,kk−1=HknPk/k−1(Hkn)T+21i=1∑mj=1∑meieejt(DhiPk/k−1DhjPk/k−1)+Rk
状态/量测互协方差阵:
P
x
z
,
k
k
−
1
=
P
k
/
k
−
1
H
k
n
\boldsymbol{P}_{x z, k k-1}=\boldsymbol{P}_{k / k-1} \boldsymbol{H}_{k}^{n}
Pxz,kk−1=Pk/k−1Hkn
最后,得二阶滤波公式:红色部分是二阶多出来的,运算量巨大收益微小
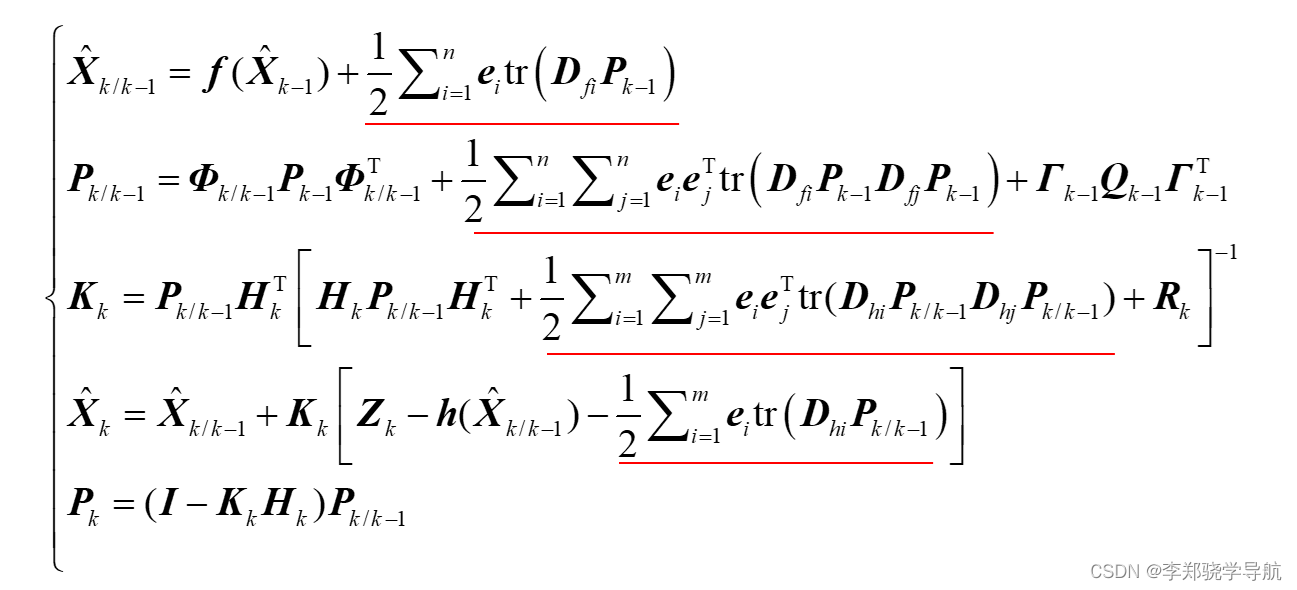
四、迭代EKF滤波
{ X ^ k / k − 1 = f ( X ^ k − 1 ) P k / k − 1 = Φ k / k − 1 P k − 1 Φ k / k − 1 T + Γ k − 1 Q k − 1 Γ k − 1 T Φ k / k − 1 = J ( f ( X ^ k − 1 ) ) K k = P k / k − 1 H k T ( H k P k / k − 1 H k T + R k ) − 1 H k = J ( h ( X ^ k / k − 1 ) ) X ^ k = X ^ k / k − 1 + K k [ Z k − h ( X ^ k / k − 1 ) ] P k = ( I − K k H k ) P k / k − 1 \left\{\begin{array}{ll}\hat{\boldsymbol{X}}_{k / k-1}=\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right) & \\ \boldsymbol{P}_{k / k-1}={\color{red}\boldsymbol{\Phi}_{k / k-1}} \boldsymbol{P}_{k-1} {\color{red}\boldsymbol{\Phi}_{k / k-1}^{\mathrm{T}}}+\boldsymbol{\Gamma}_{k-1} \boldsymbol{Q}_{k-1} \boldsymbol{\Gamma}_{k-1}^{\mathrm{T}} & {\color{red}\boldsymbol{\Phi}_{k / k-1}=\boldsymbol{J}\left(\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right)\right)} \\ \boldsymbol{K}_{k}=\boldsymbol{P}_{k / k-1} {\color{green}\boldsymbol{H}_{k}^{\mathrm{T}}}\left({\color{green}\boldsymbol{H}_{k}} \boldsymbol{P}_{k / k-1} {\color{green}\boldsymbol{H}_{k}^{\mathrm{T}}}+\boldsymbol{R}_{k}\right)^{-1} & {\color{green}\boldsymbol{H}_{k}=\boldsymbol{J}\left(\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}\right)\right)} \\ \hat{\boldsymbol{X}}_{k}=\hat{\boldsymbol{X}}_{k / k-1}+\boldsymbol{K}_{k}\left[\boldsymbol{Z}_{k}-\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}\right)\right] & \\ \boldsymbol{P}_{k}=\left(\boldsymbol{I}-\boldsymbol{K}_{k} {\color{green}\boldsymbol{H}_{k}}\right) \boldsymbol{P}_{k / k-1} & \end{array}\right. ⎩ ⎨ ⎧X^k/k−1=f(X^k−1)Pk/k−1=Φk/k−1Pk−1Φk/k−1T+Γk−1Qk−1Γk−1TKk=Pk/k−1HkT(HkPk/k−1HkT+Rk)−1X^k=X^k/k−1+Kk[Zk−h(X^k/k−1)]Pk=(I−KkHk)Pk/k−1Φk/k−1=J(f(X^k−1))Hk=J(h(X^k/k−1))
非线性系统展开点越接近你想研究的那个点,展开的精度越高。普通EKF的展开点是上一时刻 k − 1 k-1 k−1,考虑迭代修正展开点。做完一次滤波之后,有 k k k 时刻的新量测值,可以用新量测值对 k − 1 k-1 k−1 时刻做反向平滑,用反向平滑的值作为新的上一时刻的状态估计值,进行Kalman滤波。
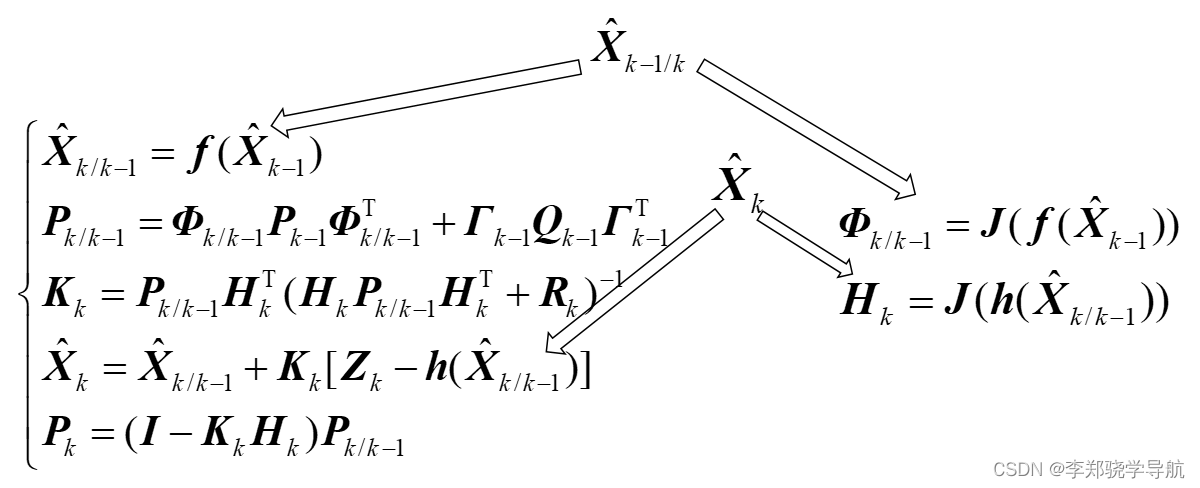
预滤波:
{
X
^
k
/
k
−
1
∗
=
f
(
X
^
k
−
1
)
P
k
/
k
−
1
∗
=
Φ
k
/
k
−
1
∗
P
k
−
1
(
Φ
k
/
k
−
1
∗
)
T
+
Γ
k
−
1
Q
k
−
1
Γ
k
−
1
T
Φ
k
/
k
−
1
∗
=
J
(
f
(
X
^
k
−
1
)
)
K
k
∗
=
P
k
/
k
−
1
∗
(
H
k
∗
)
T
[
H
k
∗
P
k
/
k
−
1
∗
(
H
k
∗
)
T
+
R
k
]
−
1
H
k
∗
=
J
(
h
(
X
^
k
/
k
−
1
∗
)
)
X
^
k
∗
=
X
^
k
/
k
−
1
∗
+
K
k
∗
[
Z
k
−
h
(
X
^
k
/
k
−
1
∗
)
]
\left\{\begin{array}{ll} \hat{\boldsymbol{X}}_{k / k-1}^{*}=\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right) \\ \boldsymbol{P}_{k / k-1}^{*}=\boldsymbol{\Phi}_{k / k-1}^{*} \boldsymbol{P}_{k-1}\left(\boldsymbol{\Phi}_{k / k-1}^{*}\right)^{\mathrm{T}}+\boldsymbol{\Gamma}_{k-1} \boldsymbol{Q}_{k-1} \boldsymbol{\Gamma}_{k-1}^{\mathrm{T}} & \boldsymbol{\Phi}_{k / k-1}^{*}=\boldsymbol{J}\left(\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right)\right) \\ \boldsymbol{K}_{k}^{*}=\boldsymbol{P}_{k / k-1}^{*}\left(\boldsymbol{H}_{k}^{*}\right)^{\mathrm{T}}\left[\boldsymbol{H}_{k}^{*} \boldsymbol{P}_{k / k-1}^{*}\left(\boldsymbol{H}_{k}^{*}\right)^{\mathrm{T}}+\boldsymbol{R}_{k}\right]^{-1} & \boldsymbol{H}_{k}^{*}=\boldsymbol{J}\left(\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}^{*}\right)\right) \\ \hat{\boldsymbol{X}}_{k}^{*}=\hat{\boldsymbol{X}}_{k / k-1}^{*}+\boldsymbol{K}_{k}^{*}\left[\boldsymbol{Z}_{k}-\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}^{*}\right)\right] & \end{array}\right.
⎩
⎨
⎧X^k/k−1∗=f(X^k−1)Pk/k−1∗=Φk/k−1∗Pk−1(Φk/k−1∗)T+Γk−1Qk−1Γk−1TKk∗=Pk/k−1∗(Hk∗)T[Hk∗Pk/k−1∗(Hk∗)T+Rk]−1X^k∗=X^k/k−1∗+Kk∗[Zk−h(X^k/k−1∗)]Φk/k−1∗=J(f(X^k−1))Hk∗=J(h(X^k/k−1∗))
反向一步平滑:可以用RTS算法
X
^
k
−
1
/
k
=
X
^
k
−
1
+
P
k
−
1
(
Φ
k
/
k
−
1
∗
)
T
(
P
k
/
k
−
1
∗
)
−
1
(
X
^
k
∗
−
X
^
k
/
k
−
1
∗
)
\hat{\boldsymbol{X}}_{k-1 / k}=\hat{\boldsymbol{X}}_{k-1}+\boldsymbol{P}_{k-1}\left(\boldsymbol{\Phi}_{k / k-1}^{*}\right)^{\mathrm{T}}\left(\boldsymbol{P}_{k / k-1}^{*}\right)^{-1}\left(\hat{\boldsymbol{X}}_{k}^{*}-\hat{\boldsymbol{X}}_{k / k-1}^{*}\right)
X^k−1/k=X^k−1+Pk−1(Φk/k−1∗)T(Pk/k−1∗)−1(X^k∗−X^k/k−1∗)
重做状态一步预测:
X
^
k
−
1
/
k
\hat{\boldsymbol{X}}_{k-1 / k}
X^k−1/k 再做泰勒级数展开
X
^
k
/
k
−
1
=
f
(
X
^
k
−
1
)
=
f
(
X
^
k
−
1
/
k
)
+
f
(
X
^
k
−
1
)
−
f
(
X
^
k
−
1
/
k
)
≈
f
(
X
^
k
−
1
/
k
)
+
J
(
f
(
X
^
k
−
1
/
k
)
)
(
X
^
k
−
1
−
X
^
k
−
1
/
k
)
\begin{aligned} \hat{\boldsymbol{X}}_{k / k-1} & =\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right)=\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1 / k}\right)+\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1}\right)-\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1 / k}\right) \\ & \approx \boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1 / k}\right)+\boldsymbol{J}\left(\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1 / k}\right)\right)\left(\hat{\boldsymbol{X}}_{k-1}-\hat{\boldsymbol{X}}_{k-1 / k}\right) \end{aligned}
X^k/k−1=f(X^k−1)=f(X^k−1/k)+f(X^k−1)−f(X^k−1/k)≈f(X^k−1/k)+J(f(X^k−1/k))(X^k−1−X^k−1/k)
重做量测一步预测:
Z
^
k
/
k
−
1
=
h
(
X
^
k
/
k
−
1
)
=
h
(
X
^
k
∗
)
+
h
(
X
^
k
/
k
−
1
)
−
h
(
X
^
k
∗
)
≈
h
(
X
^
k
∗
)
+
J
(
h
(
X
^
k
∗
)
)
(
X
^
k
/
k
−
1
−
X
^
k
∗
)
\begin{aligned} \hat{\boldsymbol{Z}}_{k / k-1} & =\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}\right)=\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k}^{*}\right)+\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k / k-1}\right)-\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k}^{*}\right) \\ & \approx \boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k}^{*}\right)+\boldsymbol{J}\left(\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k}^{*}\right)\right)\left(\hat{\boldsymbol{X}}_{k / k-1}-\hat{\boldsymbol{X}}_{k}^{*}\right) \end{aligned}
Z^k/k−1=h(X^k/k−1)=h(X^k∗)+h(X^k/k−1)−h(X^k∗)≈h(X^k∗)+J(h(X^k∗))(X^k/k−1−X^k∗)
迭代滤波:在此基础上做Kalman滤波
{
X
^
k
/
k
−
1
=
f
(
X
^
k
−
1
/
k
)
+
Φ
k
/
k
−
1
(
X
^
k
−
1
−
X
^
k
−
1
/
k
)
P
k
/
k
−
1
=
Φ
k
/
k
−
1
P
k
−
1
Φ
k
/
k
−
1
T
+
Γ
k
−
1
Q
k
−
1
Γ
k
−
1
T
Φ
k
/
k
−
1
=
J
(
f
(
X
^
k
−
1
/
k
)
)
K
k
=
P
k
/
k
−
1
H
k
T
(
H
k
P
k
/
k
−
1
H
k
T
+
R
k
)
−
1
H
k
=
J
(
h
(
X
^
k
∗
)
)
X
^
k
=
X
^
k
/
k
−
1
+
K
k
[
Z
k
−
h
(
X
^
k
∗
)
−
H
k
(
X
^
k
/
k
−
1
−
X
^
k
∗
)
]
P
k
=
(
I
−
K
k
H
k
)
P
k
/
k
−
1
\left\{\begin{array}{ll} \hat{\boldsymbol{X}}_{k / k-1}=\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1 / k}\right)+\boldsymbol{\Phi}_{k / k-1}\left(\hat{\boldsymbol{X}}_{k-1}-\hat{\boldsymbol{X}}_{k-1 / k}\right) & \\ \boldsymbol{P}_{k / k-1}=\boldsymbol{\Phi}_{k / k-1} \boldsymbol{P}_{k-1} \boldsymbol{\Phi}_{k / k-1}^{\mathrm{T}}+\boldsymbol{\Gamma}_{k-1} \boldsymbol{Q}_{k-1} \boldsymbol{\Gamma}_{k-1}^{\mathrm{T}} & \boldsymbol{\Phi}_{k / k-1}=\boldsymbol{J}\left(\boldsymbol{f}\left(\hat{\boldsymbol{X}}_{k-1 / k}\right)\right) \\ \boldsymbol{K}_{k}=\boldsymbol{P}_{k / k-1} \boldsymbol{H}_{k}^{\mathrm{T}}\left(\boldsymbol{H}_{k} \boldsymbol{P}_{k / k-1} \boldsymbol{H}_{k}^{\mathrm{T}}+\boldsymbol{R}_{k}\right)^{-1} & \boldsymbol{H}_{k}=\boldsymbol{J}\left(\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k}^{*}\right)\right) \\ \hat{\boldsymbol{X}}_{k}=\hat{\boldsymbol{X}}_{k / k-1}+\boldsymbol{K}_{k}\left[\boldsymbol{Z}_{k}-\boldsymbol{h}\left(\hat{\boldsymbol{X}}_{k}^{*}\right)-\boldsymbol{H}_{k}\left(\hat{\boldsymbol{X}}_{k / k-1}-\hat{\boldsymbol{X}}_{k}^{*}\right)\right] \\ \boldsymbol{P}_{k}=\left(\boldsymbol{I}-\boldsymbol{K}_{k} \boldsymbol{H}_{k}\right) \boldsymbol{P}_{k / k-1} & \end{array}\right.
⎩
⎨
⎧X^k/k−1=f(X^k−1/k)+Φk/k−1(X^k−1−X^k−1/k)Pk/k−1=Φk/k−1Pk−1Φk/k−1T+Γk−1Qk−1Γk−1TKk=Pk/k−1HkT(HkPk/k−1HkT+Rk)−1X^k=X^k/k−1+Kk[Zk−h(X^k∗)−Hk(X^k/k−1−X^k∗)]Pk=(I−KkHk)Pk/k−1Φk/k−1=J(f(X^k−1/k))Hk=J(h(X^k∗))
还可以多次迭代,但收益小