点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
移船相近邀相见,添酒回灯重开宴。
大家好,我是Python进阶者。
一、前言
前几天在有个粉丝问了个问题,大概意思是这样的:基于Python代码,要求输出word文档中的关键词和词频,并且将关键词的词性也标注出来,最终输出一个Excel文件,一共3列,列名分别是关键词、词频和词性。
二、实现过程
这里一开始我也不知道怎么处理,后来问了科大讯飞的AI平台,给了一个代码,如下所示,但是跑不起来。
import win32com.client as win32
import jieba
from collections import Counter
import xlwt
# 打开Word文档
word = win32.gencache.EnsureDispatch('Word.Application')
doc = word.Documents.Open('C:\\Desktop\\example.docx')
# 读取文档内容并将其存储为字符串
content = doc.Content.Text
# 将字符串转为列表,并进行分词和词性标注
words = jieba.cut(content)
tags = [word.tag for word in words]
freqs = Counter([word for word, tag in zip(words, tags) if tag != 'x'])
# 创建Excel工作簿和工作表
book = xlwt.Workbook()
sheet = book.add_sheet('Keywords')
# 写入表头
sheet.write(0, 0, '关键词')
sheet.write(0, 1, '词频')
sheet.write(0, 2, '词性')
# 写入关键词和对应的信息
for i, (word, freq) in enumerate(freqs.items()):
sheet.write(i+1, 0, word)
sheet.write(i+1, 1, str(freq))
sheet.write(i+1, 2, tags[i])
# 将分词结果转换为列表并写入Excel表格中
words_list = [word for word, tag in zip(words, tags) if tag != 'x']
for i, word in enumerate(words_list):
sheet.write(i+1+len(words), 0, word)
freq = str(freqs[word])
sheet.write(i+1+len(words), 1, freq)
pos = '' if not tags else tags[i] + '/' + pos_tag[tags[i]]
sheet.write(i+1+len(words), 2, pos)
# 保存Excel文件
book.save('C:\\Desktop\\example.xls')一直提示AttributeError: 'str' object has no attribute 'tag',没办法,方法是好的,把tag改为flag,也不好使。后来求助了Zelinai,其给了一个解决方法,如下所示:
可以使用 Python 中的 docx 和 openpyxl 库实现该功能,具体步骤如下:
使用 docx 库读取 word 文档中的所有文本,并将其存入一个字符串中。
使用 jieba 分词库对文本进行分词处理,并过滤掉无用词汇。
利用 Python 中的 Collection 库的 Counter 类,统计每个单词的词频。
使用 Python 中的 NLTK 库对每个单词进行词性标注,将其存入一个字典中。
使用 openpyxl 库创建一个 Excel 文件,并在其中创建一个工作表。
将关键词、词性和词频分别写入文件的不同列中。
下面是可能的实现代码:
import docx
import jieba
from collections import Counter
import openpyxl
from openpyxl import Workbook
from nltk import pos_tag
# 读取 word 文档中的内容
doc = docx.Document('test.docx')
text = ""
for para in doc.paragraphs:
text += para.text
# 对文本进行分词,并过滤无意义单词
words = [word for word in jieba.cut(text) if len(word) > 1 and not word.isnumeric()]
# 统计单词词频
word_counts = Counter(words)
# 对每个单词进行词性标注
pos_dict = dict(pos_tag(word_counts.keys()))
# 将关键词、词性、词频存入列表中
keywords = []
for word, count in word_counts.items():
pos = pos_dict[word]
keywords.append([word, count, pos])
# 创建 Excel 文件
wb = Workbook()
sheet = wb.active
# 将关键词、词性、词频写入 Excel 文件
sheet['A1'] = '关键词'
sheet['B1'] = '词频'
sheet['C1'] = '词性'
for i, row in enumerate(keywords):
sheet['A{}'.format(i+2)] = row[0]
sheet['B{}'.format(i+2)] = row[1]
sheet['C{}'.format(i+2)] = row[2]
# 保存 Excel 文件
wb.save('keywords.xlsx')请注意在使用前需要先安装 jieba, nltk 和 openpyxl 库。
这里运行之后,会出现一个这样的报错,(nltk加载词性词库报错)Resource averaged_perceptron_tagger not found. Please use the NLTK Downloader to obtain the resource:。
其实就是未找到资源averaged_perceptron_tagger,请使用NLTK下载器获取资源。根据报错给的URL,然后去下载对应的语义安装包即可,然后放到任意的一个目录之下,就出来了。
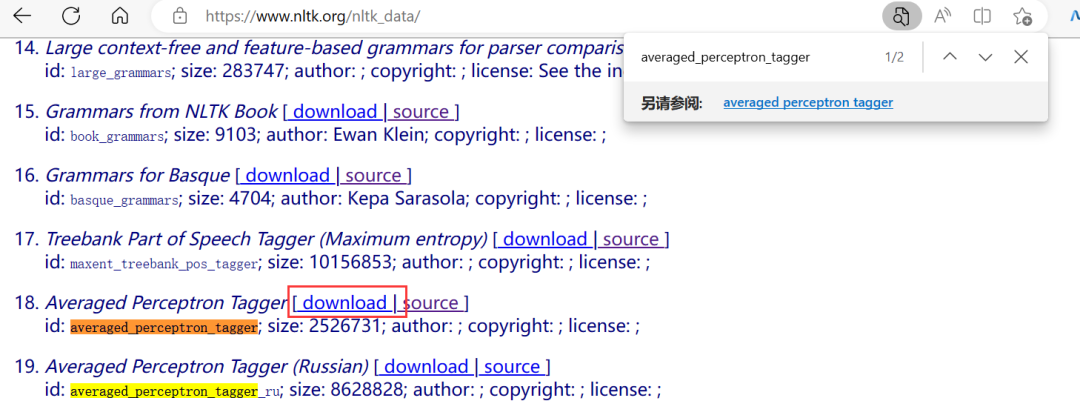
查了蛮多资料,后来总算是找到了一个靠谱的解决方法。
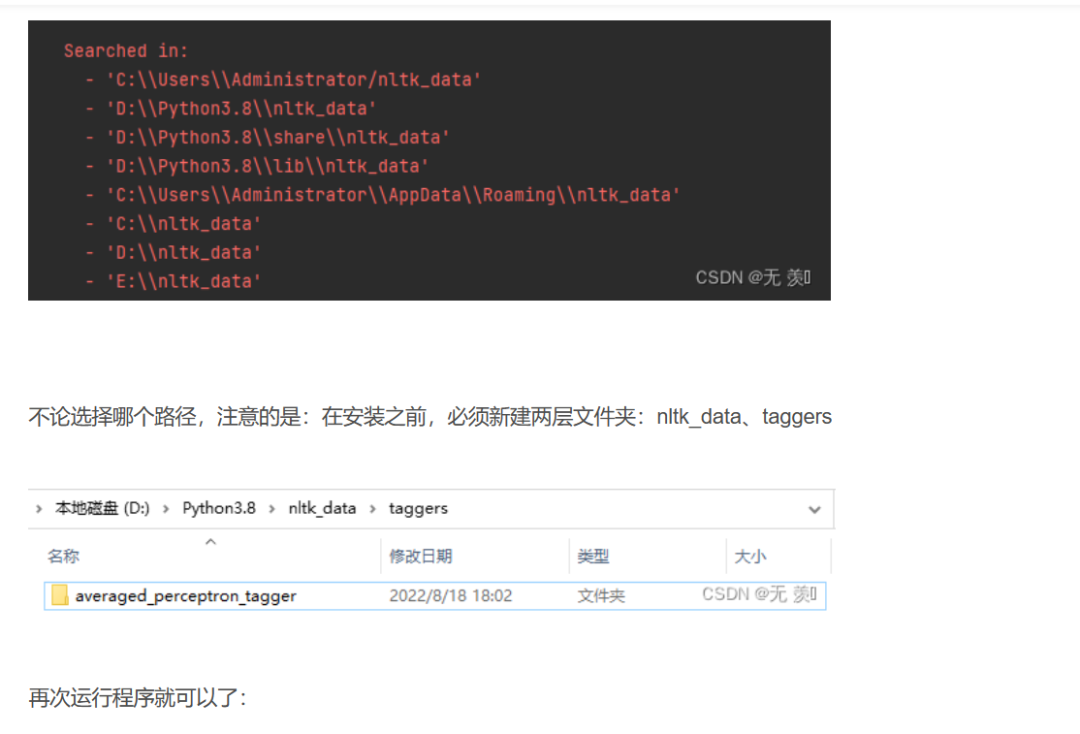
最后就可以得到预取的结果了,如下图所示:
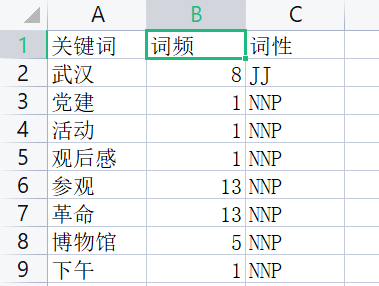
关于词性的意思,网上一大堆,这里就不再一一例举了。
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python文本分析处理的问题,使用Python获取了Word文本中的关键词、词频和词性,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
if a and b and c and d:这种代码有优雅的写法吗?
Pycharm和Python到底啥关系?
都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
站不住就准备加仓,这个pandas语句该咋写?

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~