卷友们好,我是穆尧。
最近由Chatgpt所引爆的新一代人工智能的革命正在如火如荼的进行,几乎重塑了所有的互联网产品,如办公软件、浏览器插件、搜索引擎、推荐系统等。这样巨大的改变,让大家对通用人工智能又燃起了新的希望,而可能成为我们通往通用人工智能(AGI)的最后一公里。具身智能将AI从基于互联网的虚拟领域转化为具有实体形态和与物理世界实时交互能力的实体,这对于达到或超越人类智能的实现至关重要。构建具备第一视角认知、决策规划、运动交互能力的智能体,以更好地模拟人类的具身智能,逐渐成为研究热点。
早在1950年,图灵首次提出了具身智能的概念。具身智能是指通过自身身体体验来产生智能的能力。它以第一视角为基础,使个体能够理解环境、制定决策规划,并真正与环境进行互动执行底层动作。同时,具身智能还能够从自身的探索经验或他人传授的经验中总结教训,并提升自身策略的能力。这种能力使得个体能够通过感知、运动和互动与环境紧密联系,从中获取信息和经验,不断学习和适应环境,以实现更高效的智能表现。
然而,要实现真正的具身智能仍然面临着许多挑战:
1)建立第一视角下灵活的具身认知系统,使智能体能够以第一人称视角准确地感知和理解周围的物理环境。与传统CV任务不同的是,除了像detection 和segemntation 这样关于位置和语义的理解外,具身认知系统更强调对物体可操作性的理解,比如在开抽屉这样一个例子当中,它会更关注抽屉可操纵的部分如把手等信息。另一个例子是组装问题,以Metaworld中的一个任务举例,环境中包含一个带手柄的圆环和一个楔子,任务的需求是将圆环装配到楔子上,这就要求感知模型能够捕捉圆环的中心和手柄的位置,而在一般的预训练视觉模型中,这些信息并不容易获得。



2)实现高度自主的决策规划能力。具身智能需要智能体能够根据环境的变化和任务的要求,灵活地制定决策和行动计划。这需要智能体具备推理、推断和规划的能力,做出环境适应性强的决策。比如橱柜的门可能是可以拉开的,也可能是可以向右滑开的,这需要智能体将自身的知识和当前的观测和认知结果做强有力的结合,来判断具体怎么才能够打开柜门。这是仅根据现成的caption模型+Chatgpt组合起来也很难做到的事情。
3)实现目标驱动的与物理世界的精确运动交互。智能体需要具备精细的运动控制能力,能够在复杂的物理环境中执行各种任务和动作。这涉及到机器人技术、传感器融合和动作规划等领域的研究,需要解决动作规划、路径规划、运动控制和力触觉等方面的问题。而现实世界的任务千变万化,传统的机器人运动学难以满足AGI的要求,目前学术界解决该问题大概有三条路径,其一是利用强化学习通过大量的交互来学习精确地运动交互,其二是采用少量的示范数据fewshot的快速学习该技能,其三是采用目标驱动的生成模型直接以AIGC的范式来做Motion的生成。第一条路线是学界已经研究数十年的路线,但由于该方法交互的代价昂贵每一个技能都进行大量探索很难适应于AGI的发展,第二条路线,目前包括Meta 和谷歌等公司都在建立基于模仿学习的通用技能体,该路线的核心问题是对未曾见过的任务,如何只通过非常少的人类示范数据来即能学到对应的技能。路线三希望使motion生成能够像目前图像生成一样,能够灵活的针对prompt的要求,生成准确的actions,十分具有前景,但这样的生成模型要求任务的种类非常丰富,而目前并没有能够覆盖如此全面的机器人数据集。
要做到能够在环境中实际交互级别的高质量规划,只依靠如GPT4等语言模型基于大模型内置的知识库是完全不够的,具身智能要求:
视觉观测和语言的alignment能够达到把手、按钮这样的Part级别的对准
拥有对一个action(如抓住把手)第一视角的理解,怎么算抓住了?抓住之后怎么拉,拉动把手和向右推动把手机械臂的抓手和橱柜把手之间的位置关系是怎么样的?
针对上述三大难题,香港大学MMLAB联合上海人工智能实验室OpenGVLab构建了EmbodiedGPT大模型,具有具身认知,具身规划和具身执行能力。
论文链接:https://arxiv.org/abs/2305.15021
1)通过构建具备多模态思维链的人类操纵视频文本数据集EgoCOT, 将视觉信息与具体操纵任务中的sub-goal相关联在一起。
首先我们需要一个大规模的第一视角的视觉+详细规划的视频文本数据集,在第一视角的视频数据中, Ego4D具有7T的超大体量和规模,且包含超级丰富的hand-object interaction数据,美中不足的是caption没有具体到细致的part级别,针对此问题我们通过具身思维链,通过设计合理的Prompt模版,利用Chatgpt对Ego4D数据集进行了有效的扩充,并通过后处理过滤保障了数据的对准质量。下面是一个例子:

2)提出了基于多模态思维链的视觉语言预训练方法,使模型具备根据视觉输入做出强相关的可执行性强的决策规划的能力,具备图像、视频理解和基于视觉的规划能力。且能够通过观看自身第一视角操作的视频,认知到自己的执行与实际规划的偏差在哪,以及如何更正规划的偏差。
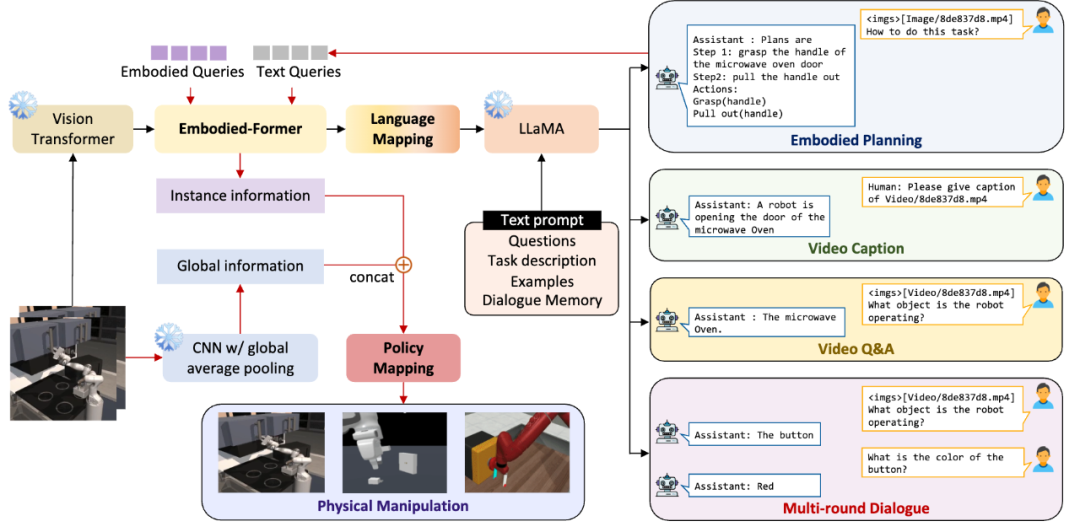
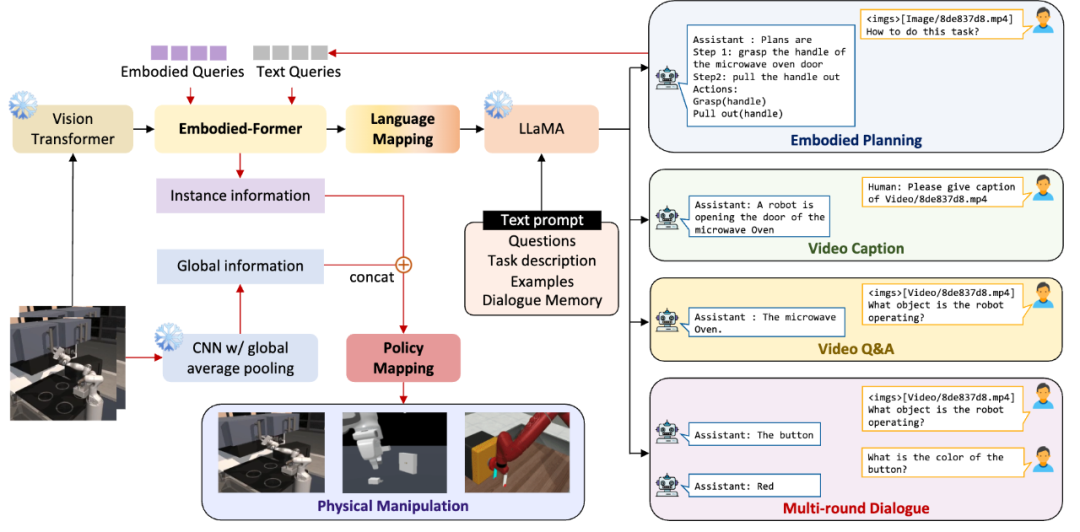
基于此技术构造出了大规模的视频-具身思维链数据集,以支持具身大模型认知能力的学习。针对具身大模型的训练,我们与谷歌PALM-E的方法有所不同。首先,在选择和训练基础模型方面,我们采用了对高校和非超级大厂更友好的视觉和语言模型,其中视觉模型为ViT-Large,语言模型为7B的LaMMA。网络结构如下图所示:
3)基于自注意力机制,提取出当前视觉观测和planning中的具体sub-goal高度相关的特征,使模型具备仅通过少量示范数据即能够学会执行底层控制。
我们设计了Embodied-former作为视觉和语言规划之间的桥梁。通过可学习的Embodied Queries和视觉特征以及文本特征之间的attention机制,我们能够提取出与具身规划控制任务最相关的特征信息,并将其传递给语言模型通过language mapping layer。这样的设计使得语言模型能够更好地理解具身规划任务的视觉输入。
在训练过程中,为了降低训练成本,我们将视觉基础模型和语言模型冻结。我们使用prefix adapter在锁定大语言模型的基础上,在EGOCOT数据集上进行训练,以引导Embodied-former和language mapping layer实现视觉观测和语言的Part级别对齐。通过adapter的引入,语言模型还能够生成一系列子目标的规划,从而避免了语言模型过于散漫地回答问题,同时提高了语言模型对第一视角的具身视觉输入生成结构化规划的能力。
那么上层的规划如何与底层的动作执行链接起来呢?这里Embodied-former再一次的派上了用场,Embodied-former的职能是对可学习的Embodied Queries,视觉特征和文本特征之间的attention机制进行建模,我们将EmbodiedGPT所输出的对任务的step by step的详细规划作为文本输入到Embodied-former当中,从而提取出与当前任务关系最为密切的特征, 并通过轻量级的policy network映射到底层的action输出。
基于这样任务高度相关的特征,我们只需要利用很少的demonstration demos 即可学会完成任务。同时,EmbodiedGPT强大的第一视角下的认知能力,能够通过自己在底层执行时的历史观测形成的视频输入,知道自己实际的执行情况与demonstration是否一致,以及自己当前具体执行到了所制定的Planning的哪一步。如果执行任务不成功,EmbodiedGPT通过自己执行过程中的视频输出文本形式的经验总结,也可以作为Prompt来辅助Planning的重新制定,这样的良性循环也是具身智能的提现所在。
总结
虽然挑战诸多,但具身智能在这个大模型时代机遇无限,大模型对学术界的诸多研究方向都产生了剧烈的打击,而在具身智能上却带来了勃勃的生机,利用强大的视觉模型和语言模型,构建第一视角下灵活的具身认知,高度自主的具身决策规划和目标驱动的具身交互系统是实现AGI的最后一公里。


我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼











![[opencv]opencv-python环境搭建](https://img-blog.csdnimg.cn/659a3c34ae1141e8850f7b7f162e3633.png)