系软件开发日志
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:软件测试
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系软件开发日志
- 前言web自动化测试
- 一、web自动化测试是什么?
- 二、使用步骤
- 1.wait assert
- 2.显式等待 参数化 测试前置
- 一、po是什么?
- POM原则
- 1.wait assert
- 2.po的使用
- 3.出现问题如何解决
- 4.POM原则
- 1.wait assert
- 1.wait assert
- 总结
前言web自动化测试
提示:这里可以添加本文要记录的大概内容:
例如:web自动化测试,找到位置
提示:以下是本篇文章正文内容,下面案例可供参考
一、web自动化测试是什么?
示例:自动化(Automation)是指机器设备、系统或过程(生产、管理过程)在没有人或较少人的直接参与下,按照人的要求,经过自动检测、信息处理、分析判断、操纵 …
这是教科书里面的自动化的定义,回归到自动化测试其实自动化测试就是。
二、使用步骤
1.wait assert
代码如下(示例):
# Generated by Selenium IDE
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# 等待断言
class TestSearch():
def setup_method(self, method):
self.driver = webdriver.Edge()
self.driver.implicitly_wait(5)
self.vars = {}
def teardown_method(self, method):
self.driver.quit()
def test_search(self):
self.driver.get("https://ceshiren.com/")
# self.driver.set_window_size(1920, 993)
self.driver.maximize_window()
self.driver.find_element(By.CSS_SELECTOR, ".d-icon-search").click()
self.driver.find_element(By.CSS_SELECTOR, ".d-icon-sliders-h").click()
self.driver.find_element(By.CSS_SELECTOR, '.search-query').send_keys("selenium")
self.driver.find_element(By.CSS_SELECTOR, ".search-cta > .fa").click()
assert len(self.driver.find_elements(By.CSS_SELECTOR, '.search-link')) > 0
assert 'selenium' in self.driver.find_element(By.CSS_SELECTOR, '.search-link').text.lower()
# self.driver.find_element(By.CSS_SELECTOR, '.search-link').click()
# self.driver.find_element(By.LINK_TEXT, "selenium-Selenium 1 (Selenium RC)").click()
2.显式等待 参数化 测试前置
代码如下(示例):
from time import sleep
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
class TestSearchAdvance:
def setup_class(self):
self.driver = webdriver.Edge()
# 定位控件的最大超时时间 隐式等待
self.driver.implicitly_wait(3)
self.driver.get('https://ceshiren.com/t/topic/25780')
self.driver.find_element(By.ID, 'search-button').click()
self.driver.find_element(By.CSS_SELECTOR, '[title=打开高级搜索]').click()
def setup_method(self):
...
def teardown_method(self):
self.driver.find_element(By.XPATH, '//summary[contains(., "高级筛选器")]').click()
self.driver.find_element(By.CSS_SELECTOR, '.full-page-search.search-query').clear()
def hingh_light(self,locator):
self.driver.find_element(By.CSS_SELECTOR,locator)
self.driver.execute_script(f"document.querySelector('{locator}').style.border = 'solid 2px red')")
self.driver.execute_script(f"arguments[0].style.border='solid red 5px'",
self.driver.find_element(*locator))
sleep(0.5)
@pytest.mark.parametrize('keyword, min, max', [
['selenium', 10, 1000],
['web', 10, 1000],
['selenium', 0, 1000],
['selenium', 100, 1000],
# 拆分异常case
# ['selenium', 100, 0],
])
def test_search(self, keyword, min, max):
self.driver.find_element(By.CSS_SELECTOR, '.full-page-search.search-query').send_keys('%s' % keyword)
# self.driver.find_element(By.CSS_SELECTOR, '.search-advanced-additional-options').click()
self.driver.save_screenshot('search.png')
topic_number = (By.XPATH, '//summary[contains(., "话题浏览量")]')
input_min = (By.CSS_SELECTOR, '[aria-label="按最小浏览量筛选"]')
# WebDriverWait(self.driver, 5).until(expected_conditions.element_to_be_clickable(input_min))
# WebDriverWait(self.driver, 5).until(expected_conditions.element_to_be_clickable(topic_number))
# self.hingh_light(topic_number)
self.driver.find_element(*topic_number).click()
def wait(driver):
# 编写显示等待的逻辑
# 点击一个控件有时会失效 一直重试
self.driver.find_element(*topic_number).click()
# 直到某个控件出现
# self.hingh_light(input_min)
self.driver.save_screenshot('topic.png')
return self.driver.find_element(*input_min).is_displayed()
# 显式等待 使用自定义函数
WebDriverWait(self.driver, 5).until(wait)
# self.hingh_light(input_min)
self.driver.find_element(*input_min).send_keys(min)
self.driver.find_element(By.CSS_SELECTOR, '[aria-label="按最大浏览量筛选"]').send_keys(max)
self.driver.find_element(By.CSS_SELECTOR, '.search-cta[aria-label="搜索"]').click()
topic_title = (By.CSS_SELECTOR, '.topic-title')
# 显式等待
WebDriverWait(self.driver, 10).until(expected_conditions.visibility_of_element_located(topic_title))
elements = self.driver.find_elements(*topic_title)
assert len(elements) > 0
for element in elements:
assert keyword in element.text.lower()
这是显示等待的例子
一、po是什么?
示例:只有业务,用来解决抽象问题马丁福2015年page project
代码如下(示例)帮助文档:
https://www.selenium.dev/zh-cn/documentations/test_practices/encouraged/page_object_models/
page-object
POM的建模原则
不要暴漏页面的内部细节
只提供方法
方法可以返回其他的PO
POM原则
一、driver层的封装
这一层主要是对于webdriver方法的封装,这里来举一个栗子,最常用的定位方法,之前讲过统一定位方法的三种传参格式:webdriver的所有定位方法,使用find_element()方法通过BY类、字符串、元组三种方法传递定位类型和数据,这里我使用元组的形式(例如locator = ("id","name_box"))来传递参数。
1.1 定位元素方法封装示例
这个定位元素的公共方法中,加了很多东西;如果每次定位的时候写这些异常捕获、打印操作的话,那么程序会非常臃肿,所以需要单独提出来,每次需要定位的时候统一调用这个方法。
有一个入参locator,格式为("定位类型","定位参数值"),返回我们所定位到的元素
加入了元素等待,并判断该元素是否存在
对于关键信息的打印输出,方便定位监控
加入了异常捕获,定位失败后可以继续执行程序
def find_element(self, *locator):
try:
print("定位元素:%s" % (locator,))
return WebDriverWait(self.driver, 10).until(EC.presence_of_element_located(locator))
except Exception as msg:
print(u"%s 页面中未能找到 %s 元素" % (self, locator))
print("错误信息%s" % msg)
1.2 封装类的初始化
对于webdriver的封装,我们要先创建一个class,这样方便我们继承调用这些封装的方法。在class中,我这里设计了一个初始化,每次调用封装的driver时,传递三个参数,一个必填项:driver、两个非必填项:page_url、page_title,我这样的想法是每次引用这个封装类时,传递一个driver进来,如果有打开网址页面的需要,则传递网址和网址页面的title,这样也可以做一次校验。
def __init__(self, driver, page_url=None, page_title=None):
self.page_url = page_url
self.page_title = page_title
self.driver = driver
self.driver.maximize_window()
self.driver.implicitly_wait(30)
二、page层书写
page类在继承我们封装的webdriver后,主要写具体的操作步骤,例如输入登录名、输入登录密码、点击登录按钮等操作。
2.1继承pagedriver并初始化
这里的page层要继承pagedriver的类Action,然后在page层的初始化中,初始化Action。
from common.pagedriver import Action
class Login(Action):
def __init__(self, driver, page_url=None, page_title=None):
Action.__init__(self, driver, page_url, page_title)
2.2 操作步骤
比如我要写打开页面、输入用户名这两个方法:
其中元素定位放在类变量中,而登录账号我们放在case层来输入。
from common.pagedriver import Action
class Login(Action):
input_name_loc = ("xpath", "//input[@placeholder='邮箱帐号或手机号码']")
frame_loc = (0)
def __init__(self, driver, page_url=None, page_title=None):
Action.__init__(self, driver, page_url, page_title)
def open(self):
"""打开页面"""
self._open(self.page_url, self.page_title)
def input_name(self, login_name):
"""输入登录名"""
self.send_keys(self.input_name_loc, login_name)
三、case层调用
终于到了第三层,这里我们要做的就是把page层的方法,像搭积木一样搭起来,并且连成完整的操作。
3.1 使用unittest,并初始化数据
在unittest的框架基础上,主要是在setUp()方法中初始化我们的数据,例如网址、账号、driver的初始化
import unittest
from selenium import webdriver
class Demo(unittest.TestCase):
def setUp(self):
self.url = "https://mail.163.com/"
self.title = "网易"
self.user_name = "" # 登录账户
self.user_password = "" # 登录密码
self.driver = webdriver.Chrome()
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
3.2 调用方法,完成用例
首先我们引用page层,然后使用page层的方法搭建case。
from page.login_page import Login
def test_login(self):
login_page = Login(self.driver, self.url, self.title)
login_page.open()
login_page.input_name(self.user_name)
四、实例演示:登录163网易邮箱
通过上述的分层步骤,演示登录163邮箱的操作,登录后通过断言登陆成功页面title,来判断是否登录成功。
运行结果:
打开网址:https://mail.163.com/
网址预期标题: 网易
定位元素:('xpath', "//input[@placeholder='邮箱帐号或手机号码']")
输入值:
定位元素:('xpath', "//input[@placeholder='输入密码']")
输入值:
定位元素:('xpath', "//input[@placeholder='输入密码']")
输入值:
(26封未读) 网易邮箱6.0版
.
----------------------------------------------------------------------
Ran 1 test in 202.126s
OK
运行代码:
pagedriver.py
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
class Action(object):
"""
Action封装所有页面都公用的方法
"""
# 初始化driver、url、title等
def __init__(self, driver, page_url=None, page_title=None):
self.page_url = page_url
self.page_title = page_title
self.driver = driver
self.driver.maximize_window()
self.driver.implicitly_wait(30)
def open(self):
"""
定义open方法,调用_open()进行打开链接
"""
self._open(self.page_url, self.page_title)
def on_page(self, page_title):
"""
使用current_url获取当前窗口Url地址,进行与配置地址作比较,返回比较结果(True False)
"""
return page_title in self.driver.title
def _open(self, page_url, page_title):
"""
打开页面,校验页面链接是否加载正确
"""
# 使用get打开访问链接地址
if page_url and page_title is not None:
self.driver.get(page_url)
print("打开网址:%s" % page_url)
print("网址预期标题: %s" % page_title)
# 使用assert进行校验,打开的链接地址是否与配置的地址一致。调用on_page()方法
assert self.on_page(page_title), u"打开页面%s失败" % page_url
def find_element(self, *locator):
try:
print("定位元素:%s" % (locator,))
return WebDriverWait(self.driver, 20).until(EC.presence_of_element_located(locator))
except Exception as msg:
print(u"%s 页面中未能找到 %s 元素" % (self, locator))
print("错误信息%s" % msg)
def send_keys(self, locator, value, clear_first=True):
"""
重写定义send_keys方法
"""
element = self.find_element(*locator)
if clear_first:
element.clear()
element.send_keys(value)
else:
element.send_keys(value)
print("输入值:%s" % value)
def switch_frame(self, frame_loc):
"""
切换frame,
:param frame_loc:id、name、element、index
:return:
"""
self.driver.switch_to.frame(frame_loc)
login_page.py
from common.pagedriver import Action
from selenium.webdriver.common.keys import Keys
class Login(Action):
input_name_loc = ("xpath", "//input[@placeholder='邮箱帐号或手机号码']")
input_password_loc = ("xpath", "//input[@placeholder='输入密码']")
enter_login_loc = Keys.ENTER
frame_loc = (0)
def __init__(self, driver, page_url=None, page_title=None):
Action.__init__(self, driver, page_url, page_title)
def open(self):
"""打开页面"""
self._open(self.page_url, self.page_title)
def change_frame(self):
"""切换frame"""
self.switch_frame(self.frame_loc)
def input_name(self, login_name):
"""输入登录名"""
self.send_keys(self.input_name_loc, login_name)
def input_password(self, login_password):
"""输入密码"""
self.send_keys(self.input_password_loc, login_password)
def enter_login(self):
"""模拟登陆点击回车"""
self.send_keys(self.input_password_loc, self.enter_login_loc, False)
def get_login_message(self):
"""获取登录后的信息以断言"""
return self.driver.title
test_163_login.py
# -*- coding: utf-8 -*-
import unittest
from time import sleep
from page.login_page import Login
from selenium import webdriver
class Demo(unittest.TestCase):
def setUp(self):
self.url = "https://mail.163.com/"
self.title = "网易"
self.user_name = "" # 登录账户
self.user_password = "" # 登录密码
self.driver = webdriver.Chrome()
def test_wangyi_login(self):
"""登录网易邮箱"""
login_page = Login(self.driver, self.url, self.title)
login_page.open()
login_page.change_frame()
sleep(3)
login_page.input_name(self.user_name)
login_page.input_password(self.user_password)
sleep(2)
login_page.enter_login()
sleep(5)
print(login_page.get_login_message())
assert "网易邮箱6.0版" in login_page.get_login_message()
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
1.wait assert
代码如下(示例):
# Generated by Selenium IDE
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# 等待断言
class TestSearch():
def setup_method(self, method):
self.driver = webdriver.Edge()
self.driver.implicitly_wait(5)
self.vars = {}
def teardown_method(self, method):
self.driver.quit()
def test_search(self):
self.driver.get("https://ceshiren.com/")
# self.driver.set_window_size(1920, 993)
self.driver.maximize_window()
self.driver.find_element(By.CSS_SELECTOR, ".d-icon-search").click()
self.driver.find_element(By.CSS_SELECTOR, ".d-icon-sliders-h").click()
self.driver.find_element(By.CSS_SELECTOR, '.search-query').send_keys("selenium")
self.driver.find_element(By.CSS_SELECTOR, ".search-cta > .fa").click()
assert len(self.driver.find_elements(By.CSS_SELECTOR, '.search-link')) > 0
assert 'selenium' in self.driver.find_element(By.CSS_SELECTOR, '.search-link').text.lower()
# self.driver.find_element(By.CSS_SELECTOR, '.search-link').click()
# self.driver.find_element(By.LINK_TEXT, "selenium-Selenium 1 (Selenium RC)").click()
2.po的使用
代码如下(示例)search_page.py:
from datetime import datetime
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
class SearchPage:
def __init__(self, driver):
self.driver: WebDriver = driver
def highlight(self, locator):
# self.driver.execute_script(f"document.querySelector('{locator}').style.border='solid red 5px'")
# arguments
self.driver.execute_script(f"arguments[0].style.border='solid red 5px'",
self.driver.find_element(*locator))
sleep(0.5)
self.driver.save_screenshot(str(datetime.now().timestamp()) + '.png')
def search(self, keyword, min=None, max=None) -> 'SearchPage':
search_query = (By.CSS_SELECTOR, '.full-page-search.search-query')
self.highlight(search_query)
self.driver.find_element(*search_query).send_keys('%s' % keyword)
# self.driver.find_element(By.CSS_SELECTOR, '.search-advanced-additional-options').click()
topic_number = (By.XPATH, '//summary[contains(., "话题浏览量")]')
input_min = (By.CSS_SELECTOR, '[aria-label="按最小浏览量筛选"]')
# WebDriverWait(self.driver, 5).until(expected_conditions.element_to_be_clickable(input_min))
# WebDriverWait(self.driver, 5).until(expected_conditions.element_to_be_clickable(topic_number))
self.highlight(topic_number)
self.driver.find_element(*topic_number).click()
def wait(driver):
# 编写显示等待的逻辑
# 点击一个控件有时会失效 一直重试
self.highlight(topic_number)
self.driver.find_element(*topic_number).click()
# 直到某个控件出现
return self.driver.find_element(*input_min).is_displayed()
# 显式等待 使用自定义函数
WebDriverWait(self.driver, 5).until(wait)
self.highlight(input_min)
self.driver.find_element(*input_min).send_keys(min)
input_max = (By.CSS_SELECTOR, '[aria-label="按最大浏览量筛选"]')
self.highlight(input_max)
self.driver.find_element(*input_max).send_keys(max)
search = (By.CSS_SELECTOR, '.search-cta[aria-label="搜索"]')
self.highlight(search)
self.driver.find_element(*search).click()
return self
def get_search_results(self) -> list[str]:
topic_title = (By.CSS_SELECTOR, '.topic-title')
# 显式等待
WebDriverWait(self.driver, 10).until(expected_conditions.visibility_of_element_located(topic_title))
elements = self.driver.find_elements(*topic_title)
r = []
for element in elements:
r.append(element.text)
return r
def get_search_non_results(self) -> list[str]:
...
def clear(self) -> 'SearchPage':
self.driver.find_element(By.XPATH, '//summary[contains(., "高级筛选器")]').click()
self.driver.find_element(By.CSS_SELECTOR, '.full-page-search.search-query').clear()
return self
代码如下(示例)topic_page.py:
from __future__ import annotations
from selenium import webdriver
from selenium.webdriver.common.by import By
from shixun2.web.tests.ceshiren.search.pages.search_page import SearchPage
class TopicPage:
_search_button = (By.ID, 'search-button')
_advance_button = (By.CSS_SELECTOR, '[title=打开高级搜索]')
def __init__(self):
self.driver = webdriver.Edge()
# 定位控件的最大超时时间 隐式等待
self.driver.implicitly_wait(3)
self.driver.get('https://ceshiren.com/t/topic/25780')
def get_topic(self) -> TopicPage:
...
def search(self) -> SearchPage:
self.driver.find_element(*self._search_button).click()
self.driver.find_element(*self._advance_button).click()
return SearchPage(self.driver)
代码如下(示例)test_search_advance_po.py:
import pytest
from shixun2.web.tests.ceshiren.search.pages.topic_page import TopicPage
class TestSearchAdvance:
def setup_class(self):
topic_page = TopicPage()
self.search_page = topic_page.search()
def setup_method(self):
...
def teardown_method(self):
self.search_page.clear()
@pytest.mark.parametrize('keyword, min, max', [
['selenium', 10, 1000],
['web', 10, 1000],
['selenium', 0, 1000],
['selenium', 100, 1000],
# 拆分异常case
# ['selenium', 100, 0],
])
def test_search(self, keyword, min, max):
self.search_page.search(keyword, min, max)
results = self.search_page.get_search_results()
assert len(results) > 0
for text in results:
assert keyword in text.lower()
@pytest.mark.parametrize('keyword, min, max', [
['selenium20230609', 10, 1000],
# 拆分异常case
# ['selenium', 100, 0],
])
def test_search_non(self, keyword, min, max):
self.search_page.search(keyword, min, max)
results = self.search_page.get_search_results()
assert len(results) == 0
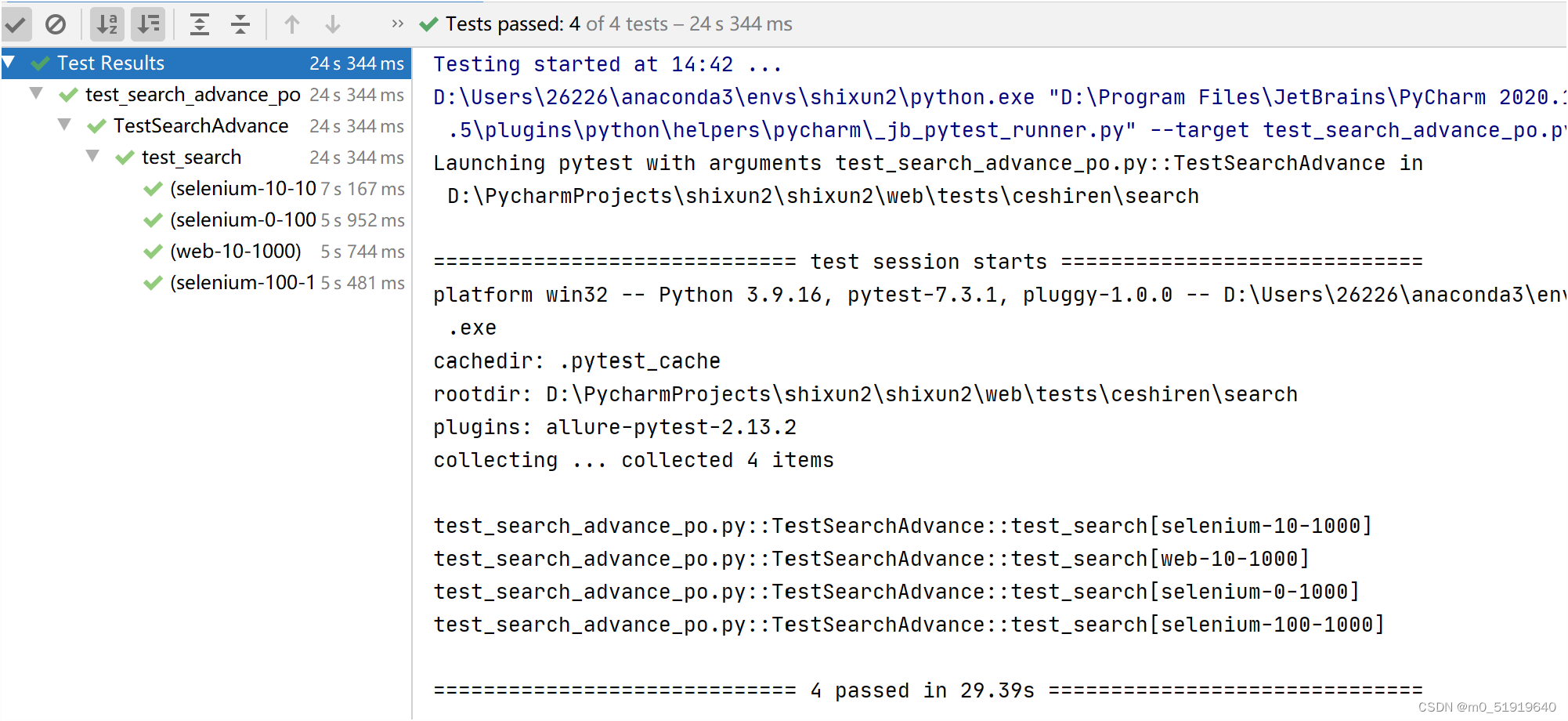
3.出现问题如何解决
代码如下(示例):
常见问题
selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: stale element not found
解决方案:等待页面稳定,使用显式等待
selenium.common.exceptions.ElementClickInterceptedException: Message: Element is not clickable at point (1120,161) because another element
obscures it
解决方案: 显式等待
例如:显示等待
4.POM原则
代码如下(示例):
PO的六大原则
class 使用类代表页面
method 使用公开方法代表页面所提供的功能
params 用参数代表一个功能的输入数据,用返回值代表一个功能的结果
return 一个方法的结果可以是页面对象,可以是当前页面对象自己,或者其他的页面对象。也可以是返回的数据
testcase 调用页面对象,使用初始化实例、调用方法、获取数据进行断言,用到测试前置、测试数据、测试的步骤,断言。
automation 页面对象的初始化方法构造与传参,具体的页面对象方法自动化过程与传参、定位符
这是显示等待的例子
1.wait assert
代码如下(示例):
这是显示等待的例子
1.wait assert
代码如下(示例):
这是显示等待的例子
总结
提示:这里对文章进行总结:
例如:这是第五天实训内容。



![[C语言实现]数据结构——手撕顺序栈之我出生就会写一个栈](https://img-blog.csdnimg.cn/1038639c1554484fbced3df51bd2bf4f.png)