目录
Kafka读写流程
LEO log end offset
物理存储 稠密索引 稀疏索引
Kafka物理存储
深入了解读数据流程
删除消息
Kafka读写流程
写流程:
- 通过zookeeper 找leader
- 分配开始读写
- Isr中的副本同步数据,并返回给leader ack
- 返回给 分片ack
读流程:
- 通过zookeeper 找leader
- 通过zookeeper 找到 消费者对应的offset
- 然后从offset顺序拉去
- 提交offset 自动提交 手动提交
LEO log end offset
文件默认最大1个G

物理存储 稠密索引 稀疏索引
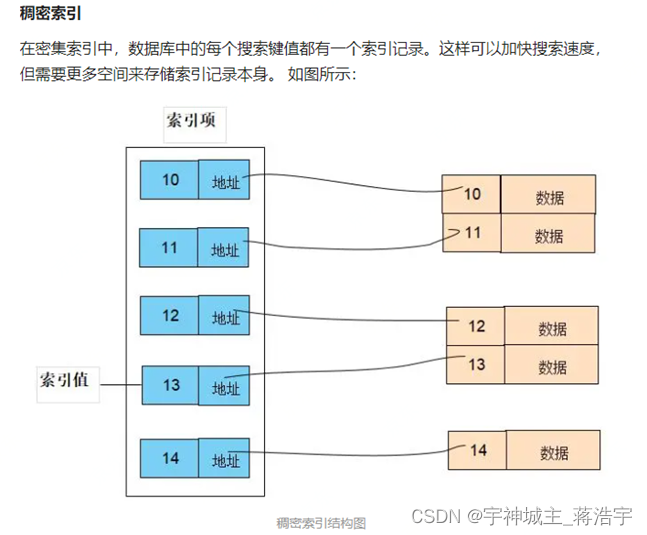
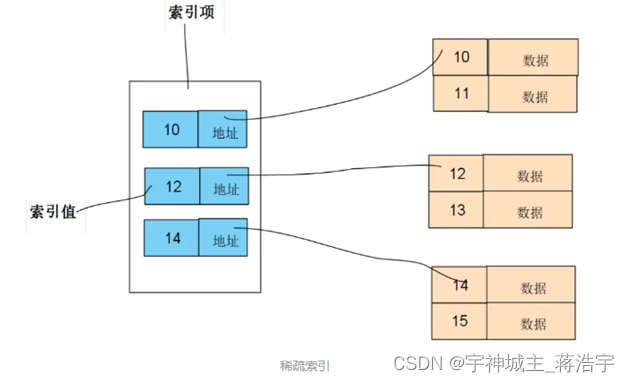
- 稀疏索引需要的空间小,占用内存也小,但是查询次数更多,速度较慢。
- 稠密索引占用空间大,但是查询次数更少,速度更快。
- Offset 找对应的数据
- 全局offset 找到对应的分片,分片对应offset 对应多个文件每个文件对应单独的offset
- 对应稀疏索引 俩层索引寻址
分片油多个文件组成,每个文件设置大小默认1G
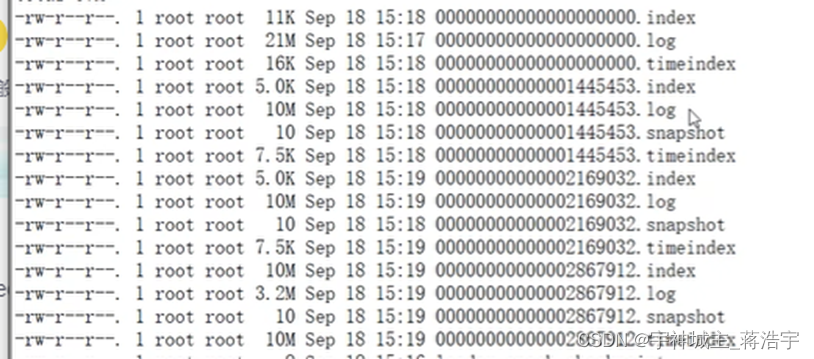
- Segment 段包含 index log timeindex snapshot
Kafka物理存储
- Topic
- Parition
- Segment
- Log数据文件
- Index索引文件
- Timeindex 稀疏索引
深入了解读数据流程
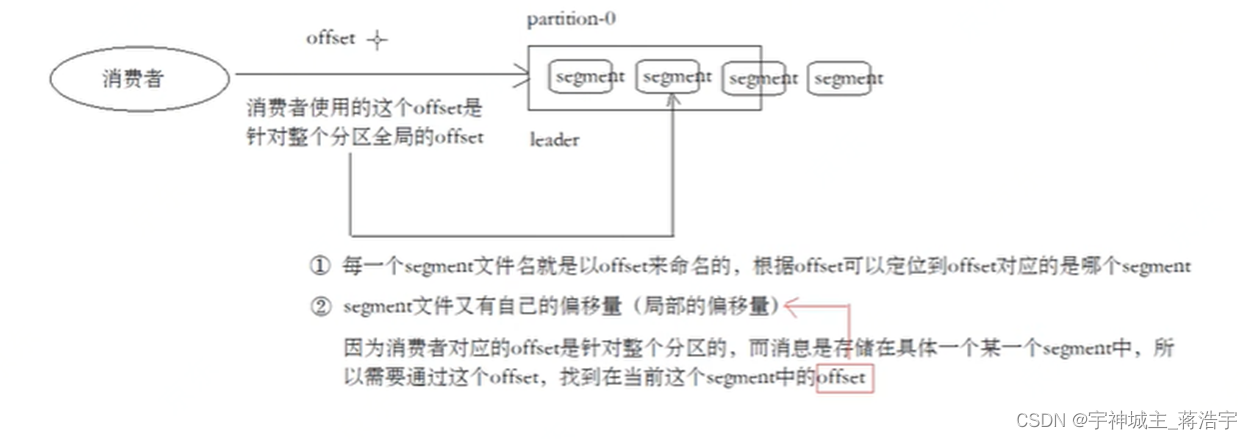
- 消费者offset 针对一个 分片找到 全局offset
- 根据这个全局offset找到对应的segment组的局部offset
- 根据全局的offset可以从index稀疏索引找到对应数据的位置
- 开始顺序读取
删除消息
Kafka定期清理数据,一次删除对应的 segment段的数据
Kafka日志管理器 会根据配置删除
ok
持续更新