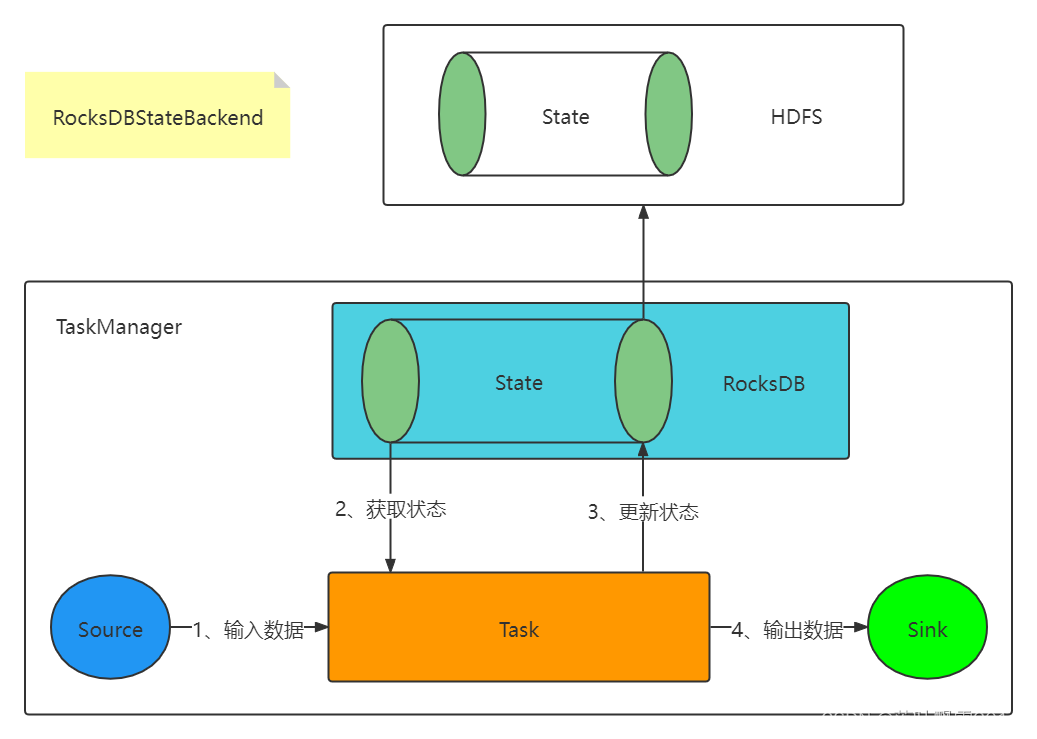
文章目录
- Boost库搜索引擎
- 1. 项目背景
- 2. 宏观原理
- 3. 搜索引擎技术栈和项目环境
- 4.正排索引vs倒排索引(index.hpp)
- 1. 正排索引:数组vector<>
- 2. 目标文档进行分词(方便倒排索引和查找)
- 3. 倒排索引:unordered_map<>
- 模拟一次查找的过程
- 5. 数据去标签和数据清洗模块 Parser
- parser.cc 实现去标签的作用
- 编写parser.cc
- 6. 建立索引Index
- 正排索引
- 倒排索引
- 获取正排索引 GetFordIndex()
- 获取倒排拉链 GetInvertedList()
- 构建索引 BuildIndex()
- 7.编写searcher
- 调试 debug处理信息打印出现错误
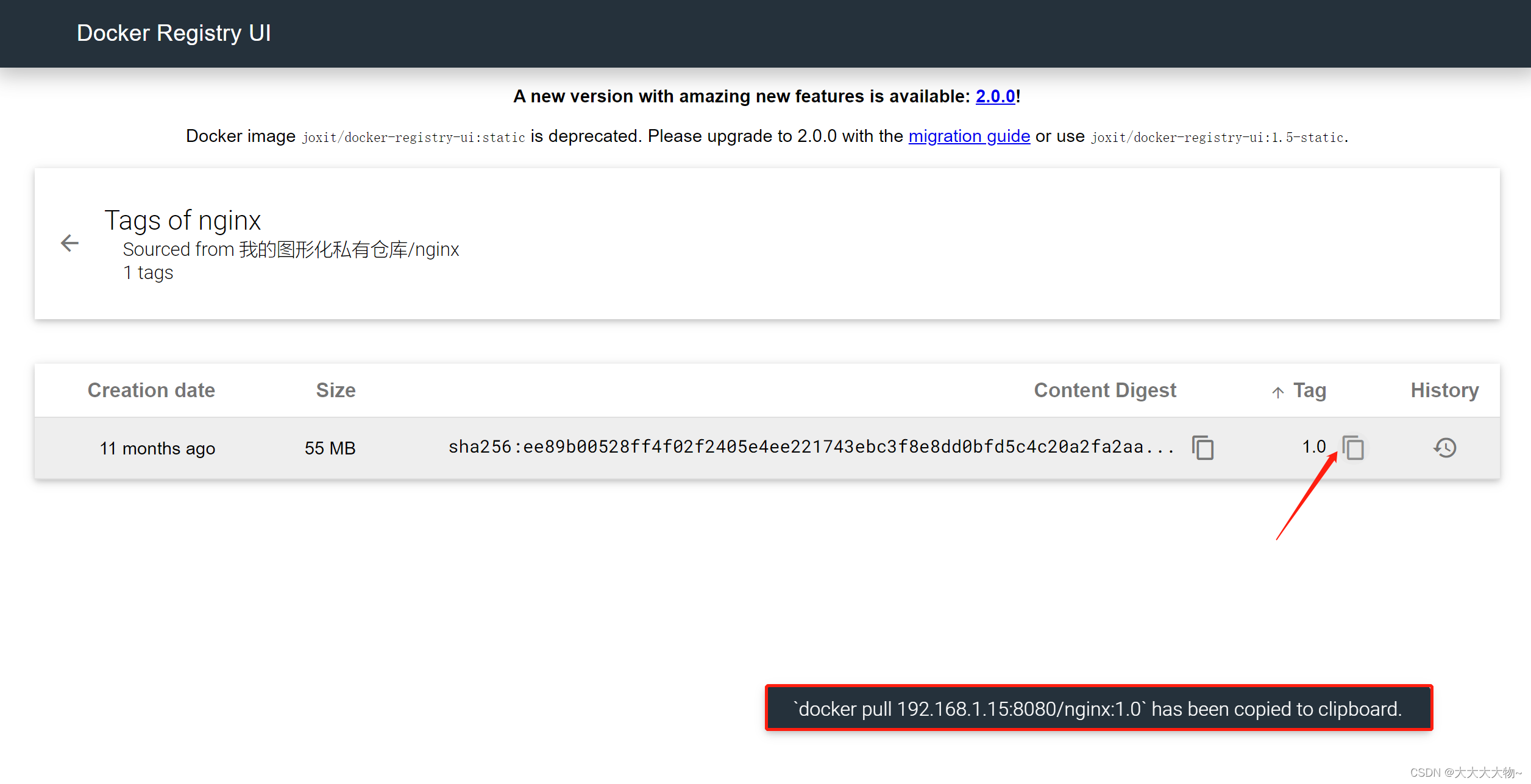
- 8. httplib引入-让网页能够访问
- 编写http_server. cc
- 前端代码略
- 9. 处理去重问题
Boost库搜索引擎
1. 项目背景
百度,搜狗,头条新闻客户端等搜索是全网搜索。而我做的是基于boost库的站内搜索,类似于cplusplus.com,这类搜索的特点是:搜索的数据更加垂直,范围中的关联性更强,数据量更小。
-
网页返回的信息有三部分:
网页的title,网页内容的摘要描述,即将跳转的网址url。
-
boost的官网是没有站内搜索的。建立doc/库下的搜索引擎。
-
获得数据源的方式是把库下下来(可升级为爬虫程序)
-
访问方式浏览器输入IP,端口号8082
2. 宏观原理

-
去标签和数据处理。在全网当中通过爬虫程序取出广告,保留标题,内容和url。
-
建立索引信息,方便快速查找。正排索引(id->文档),倒排索引(文档关键字->所在文档的id)
-
http请求的方式,进行搜索任务。通过GET的方式,上传搜索关键字。
-
server检索索引,得到对应的标题,内容和网址,相关的html。
-
拼接多个网页的title+desc+url,构建一个网页,返回给用户。
数据清理应该得到的文档信息:
- 清理出来的文档信息应该包括几部分
- 标题
- 内容
- 网址
- 文档id
3. 搜索引擎技术栈和项目环境
- 技术栈:C/C++,C++11,STL,准标准库Boost,jsoncpp(CS端的数据交换的目的,序列化和反序列化交互),**cppjieba(进行词的切分),**cpp.httplib(将信息在网页上呈现)
- 项目环境:Centos7云服务器,vim/g++,vscode(网页前端设计)
4.正排索引vs倒排索引(index.hpp)
1. 正排索引:数组vector<>
就是从文档ID找到文档内容(文档中的关键字),数组下标就是一种映射关系
2. 目标文档进行分词(方便倒排索引和查找)
搜索引擎停止词:了,的,吗,一般是在分词的时候先忽略,区分唯一性价值不大。
3. 倒排索引:unordered_map<>
根据关键字找到文档ID,根据文档内容,分词,整理不重复的各个关键字,对应联系到文档ID的方案。
模拟一次查找的过程
用户输入:大学生->倒排索引->提取文档ID(1,2)->根据正排索引找到文档内容->title+desc+url文档结果进行摘要->构建响应结果。
5. 数据去标签和数据清洗模块 Parser
下载Boost库:doc/html目录里面都是各种网页html充当数据源。

data/input下放的就是从doc目录下拷贝过来的数据源,建立索引,拼接url,构建跳转url。
parser.cc 实现去标签的作用
<>括里面的:html的标签,对我们进行搜索的操作是没用的,所以需要去掉这个标签,一般的标签是成对出现的。
清洗之后的结果放到raw_html中,干净的文档放到input文件夹中。我们下载下来的一共有8171个。

目标:把每个文档都去标签清洗之后,然后写入到同一个文件中,每个文档内容之间不需要换行,只占一行!文档和文档之间用\3进行区分。控制字符属于不可显示字符中3是^C,不会污染原来的内容。
编写parser.cc
如果参数的类型是const& :输入,*:输出,&:输入输出
-
将文档内容进行读取,放到
vector<string>file_list中,EnumFile();引入boost库中的filesystem中的方法,boost库的安装。链接时报错,makefile中需要引入两个库,
-lboost_system -lboostfilesystem首先需要用路径构建对象才能够调用接下来的方法。
-
判断你给的起始路径是否存在,如果没有数据源就没有了
boost::filesystem::exists();

-
判断路径中的文件是否是普通文件(不能是图片之类的)引入boost库中的is_regular_fille();

-
挑选后缀是.html的文件-> 迭代器对象中的
iter->path().extension()=='.html';判断路径 名的后缀是否是.html

-
将符合条件的文件的路径插入到file_list中,因为我们用原目录构造了一个Boost库中的对象采用的上面的方法,但是插入的时候需要将路径对象转化为字符串类型才能插入,所以引入对象.string()的方法。

-
-
读取file_list中的内容,并对内容进行解析ParseHtml();放到DocInfo_t结构体对象中,最后形成了8000+个对象,放到vector<DocInfo_t>中。
-
读取文件,util.hpp/FileUtil::ReadFile();打开文件失败就去找下一个文件
采用std::ifstream对文件进行打开,然后使用getline()将文件中的内容按行读取出来。
-
解析指定文件提取title-》ParseTitle();
就是在文档中搜索
<title></title>,中间就是title内容,查找关键字,然后前闭后开区间 -
解析指定文件提取content-》ParseContent();
- 去标签,凡是在标签内部的都去掉。要么是在遍历标签内容,要么就是合法内容所以引入状态机,两种状态进行标识内容是啥类型。
- 字符形式遍历,只要碰到>就是标签结束的标志。后面大概率是CONTENT,但是也可能是另一个标签的开始,所以加一个特判就行了。细节:不想保留原始数据中的\n,因为想用\n作为html解析之后的文本分隔符。
-
解析指定文件路径构建url-》ParseUrl();
Boost库的官方文档,和我们下载的文档是有路径的关联的。
下载文件的路径:

官网路径:

为了拼接网页url,所以只需要用https://www.boost.org/doc/libs/1_80_0/doc/html/替换data/input就行了。
-
-
解析文件内容放到output中,按照\3为分隔符SaveHtml();
-
同一个文档中区分出来的title content url部分之间用\3分割,不同文档之间用\n来分割,这样保存文件便于在下一次读取的时候方便用getline()依次读取到各个文档的完整内容。
title\3content\3url\ntitle\3content\3url
-
以二进制的方式写入文件,这样原文档是什么样写入的就是什么样。
-
6. 建立索引Index
正排索引
数据结构采用类似数组,数组下标天然是文档的id。vector<>
倒排索引
会存在多个结果对应一个关键字,一个关键字和一组InvertedElem对应。采用unordered_map对应关系,用vector 承装一组节点,给他整体typedef起个名字InvertedList,倒排拉链。InvertedElem结构体中成装的是对应文档的id,关键字,和权重(便于后续构建网页时的排序)。
构成了关键字和倒排拉链的关系。
获取正排索引 GetFordIndex()
根据docid获取文档内容。vector<>根据下标直接返回DocInfo* 。
获取倒排拉链 GetInvertedList()
根据关键字string unordered_map查找关键字返回拉链指针。
构建索引 BuildIndex()
需要parse处理完毕的数据的路径给我,构建正排倒排索引
-
读取文件内容,按行读取文件
-
建立正排索引,返回根据读取的line填充好的DocInfo信息结构体
-
解析Line,字符串切分Util.hpp/StringUtil::Split();返回值是vector<>
->Boost库中的split()方法
-
字符串进行填充DocInfo中
doc_id其实就是数组下标,我第一次插,之前的大小是0,我差的位置也是0。所以先更新id再插入。
doc.doc_id=forward_index.size(); -
插入到正排索引的vector中
返回最后一个元素的地址DocInfo*,采用vector<>.back();
-
-
建立倒排索引
//我们拿到的文档内容 struct DocInfo { std::string title; //文档标题 std::string content; //文档对应的去标签之后的内容 std::string url; //官网文档url uint64_t doc_id; //文档的id }; //拉链节点 struct InvertedElem { uint64_t doc_id; int weight; std::string word; }; //根据文档内容,形成一个或者多个文档描述结构体INvertedElem。 //一个文档包含很多词,都应该对应到当前的dic_id 1. 对title&content进行分词--使用cppjieba分词 2. 词频统计来充当相关性(标题中出现相关性更高一点) 遍历内容,词频++。 unordered_map<string ,word_cnt> count; class word_cnt { title_cnt; word_cnt; }; 3. 自定义相关性 遍历word_cnt,拿到每一个词,由map得到具体一个词的和文档的对应关系,当有多个不同的词指向同一个文档,由相关性决定优先显示哪一个。- 分词
获取jieba,然后git clone即可。词库在dict软连接下,头文件在inc软连接下。将cppjieba/deps下的limonp拷贝到include/cppjieba 中,各种头文件.为了让demo.cpp能够编译通过。
-
编写到倒排索引
-
对标题内容进行分词和词频统计,word_map(unordered_map)用来暂存词频的映射表.[]如果存在就操作,如果不存在就新建添加。
-
对文档中内容进行分词和词频统计,大小写不区分,所以都转换成小写再进行统计。使用boost::tolower();因为不对原来词汇进行修改,所以for()遍历时不加&,都是拷贝。呈现上不修改原文档,算法上统一用小写实现了忽略大小写的目的。
-
建立倒排索引-因为我们是按个文档走下来的,所以只需要遍历词频表,计算当前文档和分出来的那些词之间的关系,然后放在InvertedElem结构体中,构建一个倒排拉链的节点就行。
然后将词依次插入到倒排索引的unorered_map中,映射的是一个倒排拉链。[]的优势就是如果有就是拉链的引用,如果没有就新建一个。然后因为倒排拉链是vector所以只需要将填充好的item插入就行了。
-

- 随后会建立各种分词和此文档之间的关系,即倒排拉链倒排索引。
7.编写searcher
-
初始化InitSeacher():
-
获取创建index对象-单例模式(最好只有一份index)
-
index的拷贝构造和赋值构造都禁用,设置
static Index* instance;初始化:Index* Index::instance=nullptr; -
编写获取单例的函数GetInstance();会存在线程安全问题,引入c++中的mutex。
两层判断是否是第一次建立索引,减少很多加锁和申请锁的过程。
-
-
根据Index对象建立索引
index->BuildIndex();
-
-
搜索服务的接口Seacher():搜索关键字qurey,返回给用户浏览器的json_string串。
-
[分词]:我们的搜索关键字query也要在服务端进行分词方便查找
util.hpp/JiebaUtil::Cutstring();
-
[触发]:就是根据分词的各个词进行index查找
->对关键字的每一个分词进行遍历,
->查找每个词的倒排拉链,index->GetIndexList();
->将所有的拉链整合到vector<>数组中,
inverted_list_all.insert(inverted_list_all.end(),inverted_list->begin(),inverted_list->end());
-

帮助理解图:

- 存在问题:可能不同的两个词的倒排索引是一样的,所以就要去重。(最后处理)
-
[合并排序]:汇总查找结果,按照相关性降序排列sort();
根据相关性倒排,所以需要写回调函数用lambda表达式,每两个倒排拉链之间要进行排序,也就是不同关键词分词在文档中的相关性进行大小排序。
-
[构建]:根据查找结果构建json_string(jsoncpp)
-
根据拉链中元素的doc_id进行正排索引获取到DocInfo*=index->GetForwordList();
-
将拉链中每一个节点的doc结构体中的属性填充给Json::Value::item,title,content并不要全部只要一部分就行,url。
-
string GetDesc();找到在文档中首次出现的位置,往前一部分,往后一部分截取出来。

-
判断边界时,都用加法实现都是正整数。一部分随意决定字符个数,如果前面没有50个就从开头来,同理结尾。
int start =0; int end =html_content.size()-1; //如果之前没有50字节,就从头开始 //如果有50字节,就从倒数第50字节开始 //加法全变成正整数 if(pos>start+prev_step ) start = pos-prev_step; if(pos <end-next_step) end=pos+next_step; if(start>=end) return "None2"; std::string desc = html_content.substr(start,end-start); desc+="..."; return desc;检查条件:url是否正确,排序是否是按照权重排序的。
-
-
填充进Json::Value::root中,然后整体写入到*json_string中返回。
-
调试 debug处理信息打印出现错误
- cin是以空格为分隔符的,遇到空格就会停止读取,只会读取到其中的一部分,所以选择fgets();会将输入的内容全部读取出来,包括换行符号,在打印的时候都会打印出来。

-
搜索结果desc的时候出现空值的情况,也就是索引有问题或者是摘要有问题。
- 获取摘要的时候size_t 也就是无符号的坑,相减之后小于0仍然被当成一个很大的值造成报错。全设置为Int。
- 在html_content文档中查找关键字首次出现的位置的问题时,采用find是区分大小写的,也就是我们在原文档中(大小写都有)搜索已经在建立倒排拉链的时候全部转化为小写的关键字word,索引里面的都是已经转化好的小写内容,但是在获取摘要的时候找的是原文档,就会出现大小不匹配的情况造成搜索不到word的位置造成空值的情况。所以采用C++中忽略大小写的函数search();,在文档中搜索字符串首次出现的位置,两个形参是两个字符,用仿函数或者lambda表达式专门比较两个字符是否相等,比较的时候都转化为小写。

-
排序是否是按照权重排序的?权值和预期结果不太匹配
- 分词的时候和网页的分词搜索不太一样。
- 对整个文档去标签,标签中可能就存在分词的存在。
- 如果一个词在title中出现,一定会被当标题和当内容分别被统计一次。
8. httplib引入-让网页能够访问
-
cpp-libhttplib需要更高版本的gcc编译器。gcc -v查看编译器版本信息。配置bash/profile文件使得每次都是较为新版本的gcc。
-
安装cpp-httplib
最新的版本会使得不是较新的gcc编译之后在运行的时候出现问题。
-
只需要httplib.h文件引入到项目中就行。
-
编译时需要引入-lpthread
- 设置默认根目录wwwroot,里面整网页信息index.html
编写http_server. cc
-
首先需要初始化Search,也就是需要创建单例,获取对象索引信息。
-
content_type对照表

- 对外服务Search()函数
前端代码略
9. 处理去重问题
-
去重,也就是很多分词都是同一个文档,导致收到同一个内容。
struct InvertedElemPrint{}; tokes_map;
去重去掉的就是相同的Inverted_Elem,如果同一个doc_id之下的文档的很多分词,每一个分词分别获取自己的倒排拉链,遍历这些个分词的拉链节点,doc_id相同的就重叠处理,然后权值相加,并把它们放到一个数组当中,整体处理统一返回。将重新处理之后的Elem插入到InvertedListall链表之中(之前是在遍历关键字切分数组的时候直接将链表插入InvertedListall链表)。
此时获取摘要的时候item 就不止是一个单词了,而是一个填充了很多docid相同的词的数组 words[]数组,那么我只需要取其中一个获取摘要就行了。