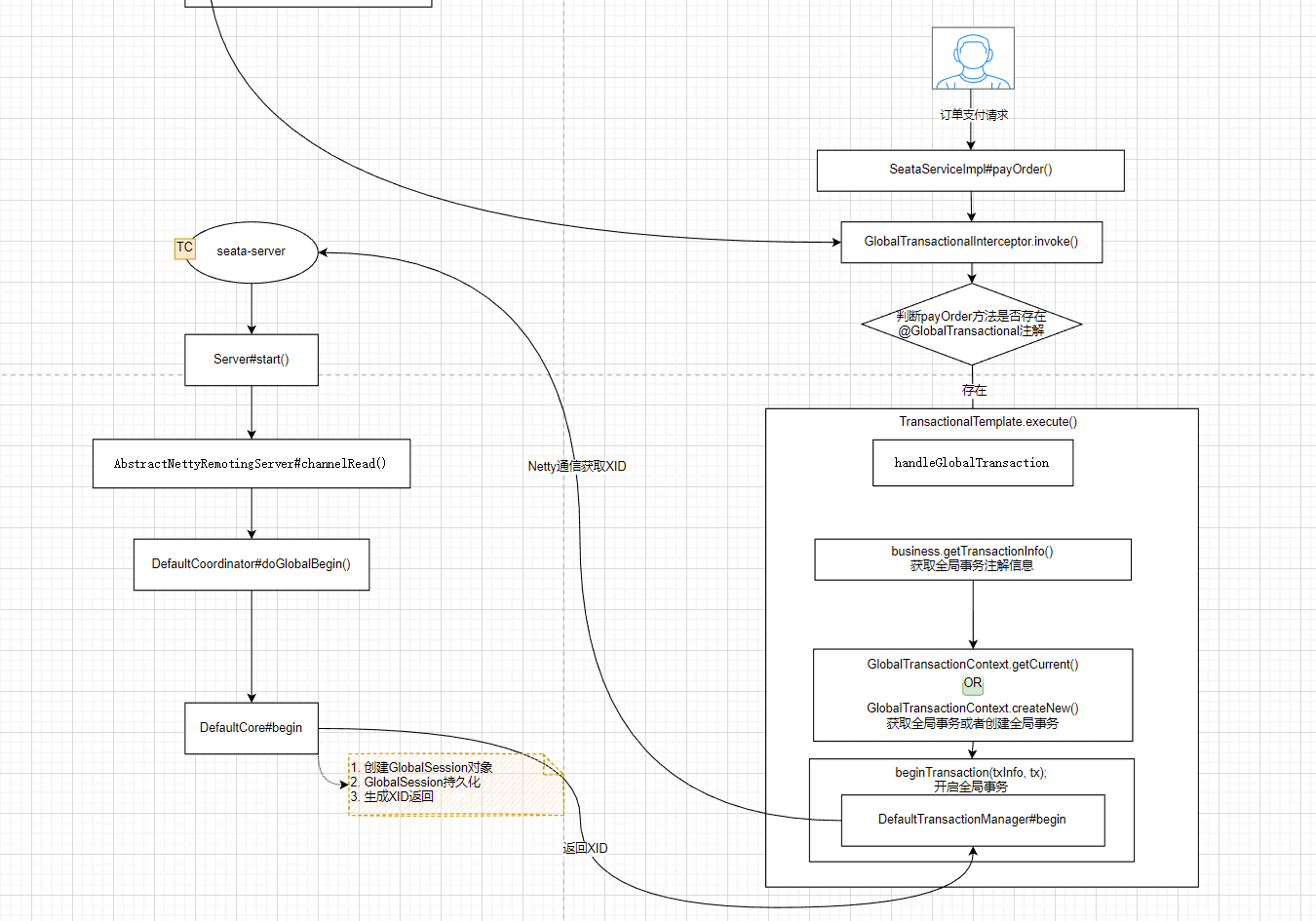
1、获取根分区剩余大小
先用df -h命令查看磁盘,确定我们需要获取字段的位置
再使用awk命令获取此字段
df -h
df -h | awk 'NR==6 {print $4}'
2、获取当前机器ip地址
ifconfig | awk 'NR==2 {print $2}'

3、统计出apache的access.log中访问量最多的5个IP
使用awk '{print $1}'去除IP地址,再对取出来的IP地址进行排序,统计
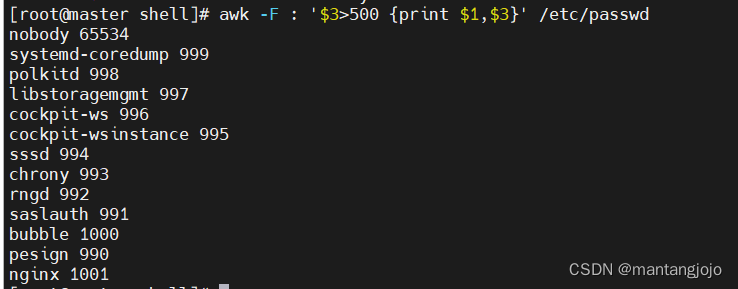
awk '{print $1}' access.log | sort -r | uniq -c | head -54、打印/etc/passwd中UID大于500的用户名和uid
需要使用-F来指定分隔符,在awk中默认空格符为空格
awk -F : '$3>500 {print $1,$3}' /etc/passwd
5、/etc/passwd 中匹配包含root或net或ucp的任意行
使用正则表达式对所需要的内容进行匹配
awk '(/root|net|ucp/) {print $0}' /etc/passwd

6、处理以下文件内容将域名取并根据域名进行计数排序处理(百度搜狐面试题)
test.txt
http://www.baidu.com/index.html
http://www.baidu.com/1.html
http://post.baidu.com/index.html
http://mp3.baidu.com/index.htm
http://www.baidu.com/3.html
http://post.baidu.com/2.html
Linux在统计时只能统计排在一起的相同数据,所以在统计之前我们需要对数据首先进行排序
awk -F / '{print $3}' test.txt | sort | uniq -c
7.一个文件,大概1亿行,每行一个ip,将出现次数最多的top10输出到一个新的文件中
sort -r:降序排序
-n:升序排序
head -n:取文件的前n行,不带n,默认去文件的前10行
(awk '{print $0}' test.txt | sort -r | uniq -c | head) >txt





![【笔记】JS的[Object file]类型转string](https://img-blog.csdnimg.cn/cec6ce1636be42fd965910e8d88a77e6.png)


![[附源码]计算机毕业设计万佳商城管理系统Springboot程序](https://img-blog.csdnimg.cn/2a7b3f66428c4821870fb9c03dec42c6.png)