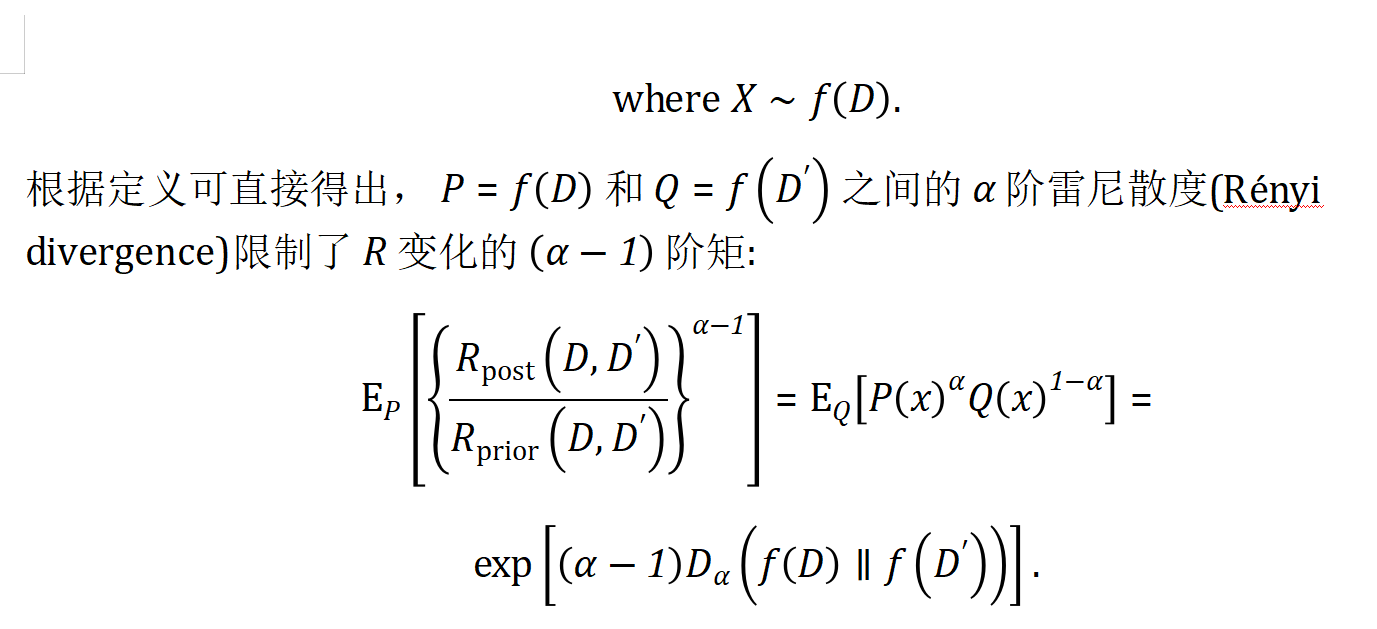上一章,讲解java (java.util.concurrent.atomic) 包中的 支持基本数据类型的原子类,以及支持数组类型的原子类,这一章继续讲解支持对实体类的原子类,以及原子类型的修改器。
还有最后java (java.util.concurrent.atomic) 包中对累计加载计算的功能专门提供性能特别高的工具类:LongAccumulator 和 LongAdder。
一,数组类型的原子类
在Java的J.U.C的原子包中,提供了支持对象的原子类操作的。类型如下:
AtomicReference、AtomicStampedReference,AtomicMarkableReference
1.1 AtomicReference 案例
package com.toast.javase.source.thread.juc.atomic;
import java.util.concurrent.atomic.AtomicReference;
/**
* @author liuwq
* @time 2025/4/1
* @remark
*/
class User {
String name;
int age;
User(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + " - " + age;
}
}
public class AtomicReferenceExample {
public static void main(String[] args) {
AtomicReference<User> atomicUser = new AtomicReference<>(new User("张三", 20));
User newUser = new User("李四", 25);
boolean updated = atomicUser.compareAndSet(atomicUser.get(), newUser); // CAS 操作
System.out.println("修改成功:" + updated);
System.out.println("当前用户:" + atomicUser.get());
}
}
输出结果:
修改成功:true
当前用户:李四 - 25解释:
compareAndSet(expected, newValue)方法会检查当前值是否等于expected,如果相等,则更新为newValue,否则失败。- 适用于简单的引用更新,但可能会遇到 ABA 问题(即值从
A → B → A,导致compareAndSet误以为没有变化)。
1.2 AtomicReference 模拟ABA问题案例
public class AtomicReferenceABA {
public static void main(String[] args) {
User zs = new User("张三", 20);
User ls = new User("李四", 23);
User ww = new User("王五", 25);
AtomicReference<User> atomicRef = new AtomicReference<>(zs);
Thread t1 = new Thread(() -> {
atomicRef.compareAndSet(zs, ls); // zs -> ls
atomicRef.compareAndSet(ls, zs); // ls -> zs (ABA 发生)
});
Thread t2 = new Thread(() -> {
try { Thread.sleep(100); } catch (InterruptedException ignored) {}
boolean success = atomicRef.compareAndSet(zs, ww); // zs -> ww,理论上不应该成功
System.out.println("修改成功:" + success);
System.out.println("当前用户:" + atomicRef.get());
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException ignored) {}
}
}
输出结果:
修改成功:true
当前用户:王五 - 25解释:
t1 执行 zs -> ls -> zs,但 对象引用没有变化(还是 zs)。
t2 误以为 zs 还是最初的 zs,但其实它已经被 ls 覆盖过一次了。
compareAndSet(zs, ww) 成功了,导致 t2 不知情地修改了已经变更过的数据,这就是 ABA 问题。
1.3 AtomicStampedReference 示例
适用场景:
- 解决 ABA 问题,因为它在更新引用的同时,维护一个 时间戳(版本号)。
/**
* @author liuwq
* @time 2025/4/1
* @remark
*/
public class AtomicStampedReferenceExample {
public static void main(String[] args) {
User zs = new User("张三", 20);
User ls = new User("李四", 23);
User ww = new User("王五", 25);
int initialStamp = 1;
AtomicStampedReference<User> atomicStampedRef = new AtomicStampedReference<>(zs, initialStamp);
Thread t1 = new Thread(() -> {
int stamp = atomicStampedRef.getStamp(); // 获取当前时间戳
atomicStampedRef.compareAndSet(zs, ls, stamp, stamp + 1); // zs -> ls
atomicStampedRef.compareAndSet(ls, zs, stamp + 1, stamp + 2); // ls -> zs (ABA 发生)
});
Thread t2 = new Thread(() -> {
try { Thread.sleep(100); } catch (InterruptedException ignored) {}
int stamp = atomicStampedRef.getStamp();
boolean success = atomicStampedRef.compareAndSet(zs, ww, stamp, stamp + 1); // zs -> ww
System.out.println("修改成功:" + success);
System.out.println("当前时间戳:" + atomicStampedRef.getStamp());
System.out.println("当前用户:" + atomicStampedRef.getReference());
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException ignored) {}
}
}
输出结果:
修改成功:true
当前时间戳:4
当前用户:王五 - 25尽管当前用户被修改成 王五 - 25,但是当前时间戳的版本是4意味着之前张三被李四覆盖的修改被记录了,所以并没有发生ABA问题。
解析:
AtomicStampedReference代码 不会触发 ABA,因为t1改变了时间戳,而t2获取的时间戳是最新的3,所以它的CAS是安全的。- 真正的 ABA 问题 发生在 时间戳未变化 的情况下,比如
AtomicReference,它只比较对象引用,不关心数据是否被改动过。
1.4 AtomicMarkableReference 模拟购物车中的商品软删除
适用场景:
- 适用于需要使用布尔标记来表示某个对象是否被修改或删除的场景(例如:延迟删除、软删除)。
业务场景:购物车中的商品软删除
在电商系统中,用户可以将商品加入购物车。如果用户删除商品,我们希望:
- 先标记商品为 "待删除" 状态(类似于软删除)。
- 后台任务在适当时候(如 30 分钟后)真正删除商品
【真正的问题】
- 用户可能在 "待删除" 状态下 撤销删除,即取消软删除。
- 需要保证并发情况下,删除操作不会误删仍在使用的商品。
解决方案:使用 AtomicMarkableReference
AtomicMarkableReference<T>允许对一个对象(如CartItem)和一个布尔标记(表示是否待删除)进行原子操作。- 如果用户删除商品,系统不会立即移除,而是先标记。
- 后台任务检查标记后,真正删除商品,但前提是用户没有撤销删除。
package com.toast.javase.source.thread.juc.atomic;
import java.util.concurrent.atomic.AtomicMarkableReference;
/**
* @author liuwq
* @time 2025/4/1
* @remark
*/
class CartItem {
String productId;
String name;
public CartItem(String productId, String name) {
this.productId = productId;
this.name = name;
}
@Override
public String toString() {
return "CartItem{" + "productId='" + productId + "', name='" + name + "'}";
}
}
public class AtomicMarkableReferenceExample {
public static void main(String[] args) throws InterruptedException {
CartItem item = new CartItem("5090XT", "Laptop");
AtomicMarkableReference<CartItem> cartItemRef = new AtomicMarkableReference<>(item, false);
// 用户删除商品(设置标记为 true)
Thread userDeletesItem = new Thread(() -> {
boolean success = cartItemRef.compareAndSet(item, item, false, true);
System.out.println("用户删除" + item.productId + "商品:" + success + ",当前标记:" + cartItemRef.isMarked());
});
// 用户撤销删除(恢复标记为 false)
Thread userRestoresItem = new Thread(() -> {
boolean success = cartItemRef.compareAndSet(item, item, true, false);
System.out.println("用户撤销删除" + item.productId + ":" + success + ",当前标记:" + cartItemRef.isMarked());
});
// 后台任务检查标记并尝试真正删除
Thread backgroundCleanup = new Thread(() -> {
try { Thread.sleep(1000); } catch (InterruptedException ignored) {}
boolean[] markHolder = new boolean[1];
CartItem currentItem = cartItemRef.get(markHolder);
if (markHolder[0]) { // 只有标记仍为 true 才能删除
boolean deleted = cartItemRef.compareAndSet(currentItem, null, true, false);
System.out.println("后台真正删除" + item.productId + "商品:" + deleted + ",当前商品:" + cartItemRef.getReference());
} else {
System.out.println("后台检查:" + item.productId + "商品未被删除,保持原状");
}
});
userDeletesItem.start();
userRestoresItem.start();
userDeletesItem.join();
userRestoresItem.join();
backgroundCleanup.start();
backgroundCleanup.join();
}
}
输出结果:
用户撤销删除5090XT:true,当前标记:false
用户删除5090XT商品:true,当前标记:true
后台检查:5090XT商品未被删除,保持原状这个方案可以有效解决并发环境下的软删除问题,避免因用户操作冲突导致错误删除!🚀
二,原子类型的属性修改器
在一个类之中可能会存在有若干不同的属性,但是有可能在进行线程同步处理的时候不是该类中所有的属性度会被进行所谓的同步操作,只有部分的属性需要进行同步的处理操作,所以在J.U.C提供的原子类型里面,就包含有一个属性修改器,利用属性修改器可以安全的修改属性的内容,原子开发包中提供的属性修改器一共包含有三种:
public abstract class AtomicIntegerFieldUpdater<T> {}
public abstract class AtomicLongFieldUpdater<T> {}
public abstract class AtomicReferenceFieldUpdater<T,V> {} 这三个 AtomicFieldUpdater 适用于需要 对类的字段进行原子更新,但又不想使用 volatile 变量或者 AtomicInteger 等包装类的场景。它们的优势:
- 减少对象开销:避免将单个整数或对象包装成
AtomicInteger或AtomicReference,直接对类的字段进行原子操作。 - 支持并发更新:适用于高并发场景,如计数器、状态更新等。
- 可用于非
final变量:但必须是volatile修饰的字段,以确保可见性。
2.1 场景 1:网站 PV(页面访问量)计数
- 使用
AtomicIntegerFieldUpdater,避免给每个页面创建一个AtomicInteger实例,减少对象开销。 - 高并发场景下,多个线程同时更新
pageViews,保证安全。
/**
* @author liuwq
* @time 2025/4/1
* @remark 网站 PV(页面访问量)计数
* ● 使用 AtomicIntegerFieldUpdater,避免给每个页面创建一个 AtomicInteger 实例,减少对象开销。
* ● 高并发场景下,多个线程同时更新 pageViews,保证安全。
*/
class WebPage {
private String url;
volatile int pageViews = 0; // 必须是 volatile
public WebPage(String url) {
this.url = url;
}
public String getUrl() {
return url;
}
}
public class AtomicIntegerFieldUpdaterExample {
private static final AtomicIntegerFieldUpdater<WebPage> pageViewUpdater =
AtomicIntegerFieldUpdater.newUpdater(WebPage.class, "pageViews");
public static void main(String[] args) throws InterruptedException {
WebPage page = new WebPage("https://example.com");
// 模拟多线程访问
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 100; j++) {
pageViewUpdater.incrementAndGet(page); // 原子增加 PV
}
});
threads[i].start();
}
for (Thread t : threads) {
t.join();
}
System.out.println("最终访问量:" + page.pageViews);
}
}输出结果:
最终访问量:1000适用业务场景
- 高并发 PV 计数:避免使用锁,提高性能。
- 热点统计数据:如点赞数、访问量、点击量等。
2.2 场景2:订单状态管理
- 使用
AtomicLongFieldUpdater,用于高并发修改订单状态。 - 示例:订单从 "创建" -> "支付" -> "完成" 状态的原子更新。
class Order {
private String orderId;
volatile long status = 0; // 0=创建, 1=支付, 2=完成
public Order(String orderId) {
this.orderId = orderId;
}
public String getOrderId() {
return orderId;
}
}
public class AtomicLongFieldUpdaterExample {
private static final AtomicLongFieldUpdater<Order> statusUpdater =
AtomicLongFieldUpdater.newUpdater(Order.class, "status");
public static void main(String[] args) {
Order order = new Order("ORDER123");
// 线程1:支付订单
Thread t1 = new Thread(() -> {
boolean success = statusUpdater.compareAndSet(order, 0, 1);
System.out.println("支付成功:" + success + ",当前状态:" + order.status);
});
// 线程2:完成订单
Thread t2 = new Thread(() -> {
try { Thread.sleep(100); } catch (InterruptedException ignored) {}
boolean success = statusUpdater.compareAndSet(order, 1, 2);
System.out.println("订单完成:" + success + ",当前状态:" + order.status);
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException ignored) {}
}
}输出结果:
支付成功:true,当前状态:1
订单完成:true,当前状态:2适用业务场景
- 订单状态管理:如从 创建 -> 处理中 -> 完成,确保状态变更的原子性。
- 任务流转:如 任务从待处理 -> 进行中 -> 完成。
2.3 场景3:动态切换系统配置
- 使用
AtomicReferenceFieldUpdater来原子替换配置信息。 - 示例:更新系统的数据库配置,并确保其他线程能安全读取最新的配置。
/**
* @author liuwq
* @time 2025/4/1
* @remark
*/
class Config {
volatile DatabaseConfig dbConfig;
public Config(DatabaseConfig initialConfig) {
this.dbConfig = initialConfig;
}
}
class DatabaseConfig {
String url;
String username;
String password;
public DatabaseConfig(String url, String username, String password) {
this.url = url;
this.username = username;
this.password = password;
}
@Override
public String toString() {
return "DatabaseConfig{url='" + url + "', user='" + username + "'}";
}
}
public class AtomicReferenceFieldUpdaterExample {
private static final AtomicReferenceFieldUpdater<Config, DatabaseConfig> configUpdater =
AtomicReferenceFieldUpdater.newUpdater(Config.class, DatabaseConfig.class, "dbConfig");
public static void main(String[] args) {
Config systemConfig = new Config(new DatabaseConfig("jdbc:mysql://old-db", "root", "123456"));
System.out.println("初始配置:" + systemConfig.dbConfig);
// 线程1:更新数据库配置
Thread updateThread = new Thread(() -> {
DatabaseConfig newConfig = new DatabaseConfig("jdbc:mysql://new-db", "admin", "654321");
boolean success = configUpdater.compareAndSet(systemConfig, systemConfig.dbConfig, newConfig);
System.out.println("数据库配置更新:" + success);
});
// 线程2:读取最新配置
Thread readThread = new Thread(() -> {
try { Thread.sleep(100); } catch (InterruptedException ignored) {}
System.out.println("最新配置:" + systemConfig.dbConfig);
});
updateThread.start();
readThread.start();
try {
updateThread.join();
readThread.join();
} catch (InterruptedException ignored) {}
}
}适用业务场景
- 动态配置切换:如数据库连接配置、缓存策略等。
- 原子更新全局状态:如切换日志级别、热更新服务配置。
初始配置:DatabaseConfig{url='jdbc:mysql://old-db', user='root'}
数据库配置更新:true
最新配置:DatabaseConfig{url='jdbc:mysql://new-db', user='admin'} 这三个 AtomicFieldUpdater 类提供了一种轻量级的原子性操作方式,适用于并发场景下的字段更新,避免了 AtomicInteger 这样的独立对象带来的额外开销!🚀
并且如果需要在多线程并发的环境下去修改属性,那对应的属性需要被 volatile 关键字所修改。这样就保证了被修改的数据在线程之间的可见性。且保证了一定的指令重排作用。
三,LongAccumulator & LongAdder & Striped64
在Java (J.U.C并发包)之中为计数器专门提供了高性能计数器,主要用于高并发场景,解决 AtomicLong 原子类在高并发竞争环境下的性能瓶颈。
3.1. LongAdder
📌 适用场景
- 计数、累加(如访问量统计、计数器等)
- 高并发情况下减少 CAS 失败,比
AtomicLong性能更优
✅ 特点
- 支持多线程高并发累加,使用分段累加(Cell 数组)
- 最终获取总和时才做合并,提升写入性能
- 不支持减法(只能增加)
🚀 示例:网站访问量统计
/**
* @author liuwq
* @time 2025/4/1
* @remark
*/
public class LongAdderExample {
private static final LongAdder counter = new LongAdder();
public static void main(String[] args) throws InterruptedException {
int threadCount = 10;
Thread[] threads = new Thread[threadCount];
// 每个线程执行 10000 次累加
for (int i = 0; i < threadCount; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
counter.increment();
}
});
}
for (Thread thread : threads) thread.start();
for (Thread thread : threads) thread.join();
System.out.println("最终计数值:" + counter.sum()); // 100000
}
}输出结果:
最终计数值:100000📝 解释:
increment():每个线程局部累加,减少竞争sum():合并所有分片的值,获取最终结果- 比
AtomicLong.incrementAndGet()性能更优
3.2. LongAccumulator
📌 适用场景
- 自定义计算逻辑(不是单纯累加,可以做乘法、最小值、最大值等)
- 累加器模式(不同线程可提供不同计算逻辑)
✅ 特点
- 需要提供自定义函数
- 适用于非加法计算,如乘法、最大值、最小值等
🚀 示例:计算最大值
public class LongAccumulatorExample {
public static void main(String[] args) throws InterruptedException {
// 自定义函数:取较大值
LongBinaryOperator maxFunc = Math::max;
LongAccumulator maxValue = new LongAccumulator(maxFunc, Long.MIN_VALUE);
int threadCount = 5;
Thread[] threads = new Thread[threadCount];
long[] values = {10, 20, 50, 5, 100};
for (int i = 0; i < threadCount; i++) {
final int index = i;
threads[i] = new Thread(() -> maxValue.accumulate(values[index]));
}
for (Thread thread : threads) thread.start();
for (Thread thread : threads) thread.join();
System.out.println("最大值:" + maxValue.get()); // 100
}
}输出结果:
最大值:1003.3. LongAdder vs LongAccumulator
| 特性 |
|
|
| 默认操作 | 仅支持 累加 | 可自定义,如最大值、最小值、乘法等 |
| 适用场景 | 计数器(如访问量统计、累加任务) | 复杂计算(如最大值、最小值) |
| 并发优化 | 分段累加,合并时计算 | 自定义合并逻辑 |
| 线程安全 | 是 | 是 |
3.4. 什么时候用哪一个?
- 需要做高并发计数 ➝
LongAdder - 需要自定义计算逻辑(最大值、最小值、乘法等) ➝
LongAccumulator DoubleAccumulator与LongAccumulator支持两种数据类型
📌 总结
LongAdder适用于高并发累加,不支持减法LongAccumulator适用于自定义计算(最大值、最小值等)- 比
AtomicLong更适合高并发场景
这样选择就更清晰啦!💡🚀
3.5 Striped64 讲解
Striped64 是 LongAdder 和 LongAccumulator 等类的父类,这些类用来处理高并发场景下的数值计算(如计数器、累加器等)。Striped64 的主要设计目标是减少锁竞争,提高性能,特别是在多线程高并发的环境下。
而刚刚我们提到了LongAdder 和 LongAccumulator解决了对应的原子类比 AtomicLong 性能瓶颈,性能更优。其原因就是拥有着Striped64 支持。引入了分段锁的思想。
那多问一个问题AtomicLong 等原子类的性能瓶颈是多少,体现在哪里?为什么是通过引入分段锁的思想来优化。
AtomicLong 等原子类的性能瓶颈及优化
AtomicLong 和其他原子类(如 AtomicInteger、AtomicReference 等)是用于在多线程环境中实现原子操作的类,它们通过底层的 CAS(Compare-And-Swap)机制确保了线程安全,而不需要使用传统的锁机制(如 synchronized)。然而,在高并发场景下,即使是原子类也会有性能瓶颈。了解这些瓶颈并采取优化措施非常重要。
🔹 1. 性能瓶颈:
在多线程并发环境下,AtomicLong 等原子类的性能瓶颈主要体现在以下几个方面:
1.1 单个共享变量的争用
AtomicLong 等原子类通过 CAS 操作确保线程安全,当多个线程竞争修改同一个共享变量时,CAS 会尝试将当前变量的值与期望值进行比较并交换。如果多个线程同时尝试更新该变量的值,它们的操作会产生竞争,并且只有一个线程能够成功更新变量值,其它线程则需要重新进行 CAS 操作。
- 问题:如果多个线程频繁访问同一个原子变量,CAS 操作的失败会增加 CPU 的消耗,导致大量的缓存一致性问题和内存屏障。尤其是在高并发情况下,这种竞争会极大地降低性能。
1.2 伪共享
伪共享是指多个线程操作的不同变量在内存中的缓存行(cache line)相同,从而导致缓存一致性问题。在 AtomicLong 等原子类中,如果多个线程同时修改某个共享变量,并且这些变量的位置位于同一缓存行中,则会导致频繁的缓存失效(即缓存行的同步)。
- 问题:在多个线程频繁修改变量时,缓存一致性会变得非常昂贵,从而影响性能。
🔹 3. 分段锁的具体实现:
以 LongAdder 为例,它继承自 Striped64,使用了分段计数器:
Cell[] cells:是Striped64中的一个数组,存储多个Cell(每个Cell具有一个AtomicLong),每个线程通常会选择一个不同的Cell进行操作。base:当Cell[]中的所有Cell的值都合并完成时,base中的值会保存最终的累加结果。
这样,在高并发的场景下,线程间的竞争被分散到多个 Cell,从而减少了锁竞争和伪共享的问题。
🔹 4. 总结
AtomicLong 等原子类在高并发环境中面临的性能瓶颈主要是由于竞争、CAS 操作的失败以及伪共享问题。为了优化这些问题,引入了分段锁的思想(如在 LongAdder 和 LongAccumulator 中),通过将数据分为多个小的原子计数器,减少了线程间的竞争,提高了性能。这种方式减少了对单一变量的争用,并避免了缓存行的伪共享,从而在高并发情况下提供了显著的性能提升。
🔹 1. Striped64 类简介
Striped64 的核心思想是:通过将数据分段来减少线程间的竞争。它维护了一个 Cell[] 数组,其中每个 Cell 是一个小的原子计数器。每个线程操作不同的 Cell,这样避免了多个线程同时操作同一个计数器,从而降低了锁竞争。
Striped64 本身并不直接提供外部可见的接口(如 increment()、accumulate() 等),它主要为 LongAdder 和 LongAccumulator 提供基础实现。
2. 主要实现细节
- 分段原子性:
Striped64使用了多个原子变量 (Cell[]),每个Cell是一个具有原子性操作的AtomicLong。 - 合并操作:当计算完成时,
Striped64会合并所有Cell中的结果以得到最终的值。
在 LongAdder 和 LongAccumulator 中,具体的操作(如累加或自定义计算)都会基于 Striped64 来实现数据的分段管理,从而有效地避免了竞争问题。
四,VarHandler
在Java并发包(java.util.concurrent.atomic)之中,该atomic原子包下的原子类,其原子性是通过无锁机制的CAS来保证其原子性。而提供该原子性的操作的类是Unsafe类,但是在AtomicReferenceArray类之中却发现,提供CAS操作的类并非Unsafe类,而是VarHandler 类。
其他的原子类也是一样的将Unsafe 替换为VarHandler类。
public class AtomicReferenceArray<E> implements java.io.Serializable {
private static final long serialVersionUID = -6209656149925076980L;
private static final VarHandle AA = MethodHandles.arrayElementVarHandle(Object[].class);
}观察VarHandler类
/**
* @since 9 JDK9 提供的
*/
public abstract class VarHandle implements Constable {/** 忽略其他代码 */} 4.1 Unsafe与VarHandler的区别
Unsafe 和 VarHandle 都是 Java 中用于直接操作内存和变量的一些类,它们在处理低级内存操作时提供了非常强大的功能。然而,它们有一些关键的区别,特别是在设计、使用场景和安全性方面。
1. Unsafe 类
Unsafe 类是 sun.misc 包中的一个类,提供了一组直接访问底层操作系统和硬件的API。它通常用于执行一些非常底层的操作,比如直接内存操作、原子操作、内存屏障、对象实例化等,Java应用程序通常不需要直接使用它,但它被一些框架(如 Netty、Concurrent 类库等)用来优化性能。
主要功能:
- 直接内存操作:可以通过
allocateMemory()等方法直接分配、读取和修改内存。 - 对象字段访问:可以通过
getObject()和putObject()等方法直接访问对象的字段,不受private或final限制。 - 原子操作:提供了
compareAndSwap(CAS)等方法进行原子性更新。 - 类的实例化:可以绕过
constructor直接分配对象内存和初始化对象。
局限性和问题:
- 不安全:
Unsafe是一个非常底层的工具,容易引发错误并导致内存泄漏或崩溃。因为它绕过了 Java 的垃圾回收和内存管理机制,所以使用不当可能会导致严重的问题。 - 与平台相关:它依赖于底层操作系统,使用
Unsafe的代码往往是与平台紧密耦合的,可能会在不同的JVM或操作系统上有不同的行为。 - 不再推荐使用:虽然它非常强大,但通常不建议直接使用
Unsafe,而是通过提供更安全和高层的API(如VarHandle)来替代。
2. VarHandle 类
VarHandle 是 Java 9 引入的一个类,它提供了对变量(包括字段、数组元素、以及静态变量)进行底层操作的功能。VarHandle 是对 Unsafe 功能的改进,提供了一种更安全、类型安全的方式来进行低级别的内存访问,特别是为了替代 Unsafe 的一些操作。
主要功能:
- 类型安全:与
Unsafe不同,VarHandle在编译时就检查类型,因此更加安全。你不能直接操作原始类型,而必须遵循类型规则。 - 支持原子操作:
VarHandle提供了对字段的原子性访问操作(类似于Atomic类),包括支持compareAndSet()和getAndAdd()等操作。 - 支持并发编程:提供了一些用于并发控制的功能,如内存屏障、原子操作等。
- 字段更新与访问:你可以使用
VarHandle来读取、写入甚至修改对象字段的值。它可以跨类、跨方法地安全地访问变量。
优势:
- 安全性:
VarHandle提供了更高层次的抽象和类型检查,使用时不会像Unsafe那样绕过 Java 的类型系统。 - 灵活性:可以通过
VarHandle来操作各种类型的字段(普通字段、静态字段、数组元素等),且这些操作通常是并发安全的。 - 跨平台支持:相比于
Unsafe,VarHandle更加通用,能确保在不同的平台上具有一致性。
3. 主要区别总结
| 特性 |
|
|
| 引入版本 | Java 1.0(但不建议直接使用) | Java 9 |
| 类型安全性 | 不安全,绕过 Java 的类型检查,使用时容易出错。 | 类型安全,提供了类型检查。 |
| 操作粒度 | 支持直接的内存操作、对象字段、数组操作等,功能强大但容易出错。 | 主要用于变量字段的操作,支持原子操作,功能更专注。 |
| 并发操作支持 | 支持原子操作,但需要手动实现并发控制。 | 内置对原子操作的支持(如 ),更适合并发场景。 |
| 使用难度 | 难度较大,风险高,容易造成崩溃或错误。 | 更易于使用和理解,避免了很多潜在的风险。 |
| 平台依赖性 | 与平台和操作系统相关,可能在不同的 JVM 上表现不同。 | 设计为跨平台,不依赖于特定平台或操作系统。 |
| 可替代性 |
是较低级的操作,更多用于高性能库和框架。 |
是一个较高层的 API,逐渐成为推荐的替代方案。 |
4. 何时使用 Unsafe 或 VarHandle?
- 使用
Unsafe:仅在你需要极限性能优化,并且确切知道自己在做什么的情况下。Unsafe允许绕过 JVM 的很多安全和类型检查,因此很容易出错,建议仅在需要进行底层优化时使用,比如构建高性能的并发工具或底层库(如 Netty、Disruptor 等)。 - 使用
VarHandle:在 Java 9 及以上版本中,推荐使用VarHandle,因为它提供了安全、类型安全的原子操作,并且能够避免Unsafe的许多危险用法。对于现代并发编程,VarHandle提供了比Unsafe更好的性能和更高的可维护性。
5. 示例代码:
public class UnsafeCounterExample {
private static final Unsafe unsafe;
static {
try {
// 获取 Unsafe 实例
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
unsafe = (Unsafe) f.get(null);
} catch (Exception e) {
throw new Error(e);
}
}
private long counter = 0; // 需要进行操作的字段
// 定义字段的内存偏移量
private static final long COUNTER_OFFSET;
static {
try {
// 确保 counter 字段存在,并获取它的内存偏移量
COUNTER_OFFSET = unsafe.objectFieldOffset(UnsafeCounterExample.class.getDeclaredField("counter"));
} catch (NoSuchFieldException e) {
throw new Error("No such field: counter", e);
} catch (Exception e) {
throw new Error("Unexpected error", e);
}
}
// 原子地增加 counter
public void increment() {
unsafe.getAndAddLong(this, COUNTER_OFFSET, 1); // 使用 Unsafe 直接操作 long 类型字段
}
public static void main(String[] args) {
UnsafeCounterExample example = new UnsafeCounterExample();
example.increment();
System.out.println("Counter: " + example.counter); // 输出: Counter: 1
}
}public class VarHandleExample {
private long counter = 0;
// 定义一个 VarHandle 来操作字段
private static final VarHandle COUNTER;
static {
try {
// 使用 MethodHandles.lookup() 获取字段的 VarHandle 实例
COUNTER = MethodHandles.lookup().findVarHandle(VarHandleExample.class, "counter", long.class);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException("VarHandle initialization failed", e);
}
}
public void increment() {
COUNTER.getAndAdd(this, 1); // 使用 VarHandle 进行原子操作
}
public static void main(String[] args) {
VarHandleExample example = new VarHandleExample();
example.increment();
System.out.println("Counter: " + example.counter); // 输出: Counter: 1
}
}结论:
Unsafe 是一个底层的工具,适用于极限性能优化,但使用不当可能导致严重的内存问题。VarHandle 则提供了更为安全、简洁的接口,适用于并发操作中的字段访问,尤其在 Java 9 及以后版本,推荐使用 VarHandle 来替代 Unsafe。