1 详细理解lucene存储结构
存储结构 :

索引(Index) :
- 一个目录一个索引,在Lucene中一个索引是放在一个文件夹中的。
段(Segment) :
- 一个索引(逻辑索引)由多个段组成, 多个段可以合并, 以减少读取内容时候的磁盘IO。
- Lucene中的数据写入会先写内存的一个Buffer,当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是批量追加,能达到很高的吞吐量。Segment中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并。
文档(Document) :
- 文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。
- 新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
域(Field) :
- 一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,描述等,都可以保存在不同的域里。
- 不同域的索引方式可以不同。
词(Term) :
- 词是索引的最小单位,是经过词法分析和语言处理后的字符串。
2 索引库物理文件
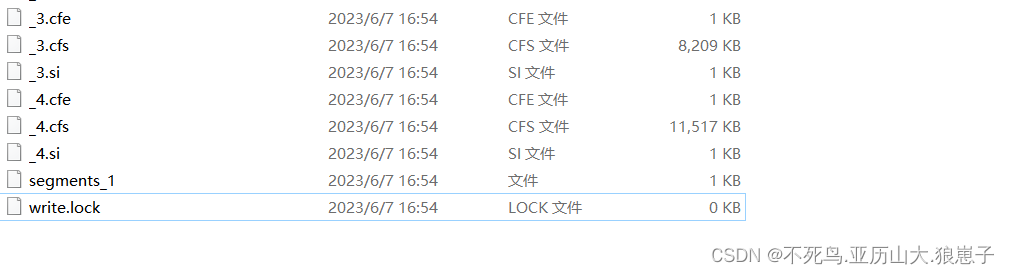
3 索引库文件扩展名对照表
| 名称 | 文件扩展名 | 简短描述 |
| Segments File | segments_N | 保存了一个提交点(a commit point)的信息 |
| Lock File | write.lock | 防止多个IndexWriter同时写到一份索引文件中 |
| Segment Info | .si | 保存了索引段的元数据信息 |
| Compound File | .cfs,.cfe | 一个可选的虚拟文件,把所有索引信息都存储到复合索引文件中 |
| Fields | .fnm | 保存fields的相关信息 |
| Field Index | .fdx | 保存指向field data的指针 |
| Field Data | .fdt | 文档存储的字段的值 |
| Term Dictionary | .tim | term词典,存储term信息 |
| Term Index | .tip | 到Term Dictionary的索引 |
| Frequencies | .doc | 由包含每个term以及频率的docs列表组成 |
| Positions | .pos | 存储出现在索引中的term的位置信息 |
| Payloads | .pay | 存储额外的per-position元数据信息,例如字符偏移和用户payloads |
| Norms | .nvd,.nvm | .nvm文件保存索引字段加权因子的元数据,.nvd文件保存索引字段加权数据 |
| Per-Document Values | .dvd,.dvm | .dvm文件保存索引文档评分因子的元数据,.dvd文件保存索引文档评分数据 |
| Term Vector Index | .tvx | 将偏移存储到文档数据文件中 |
| Term Vector Documents | .tvd | 包含有term vectors的每个文档信息 |
| Term Vector Fields | .tvf | 字段级别有关term vectors的信息 |
| Live Documents | .liv | 哪些是有效文件的信息 |
| Point values | .dii,.dim | 保留索引点,如果有的话 |
4 词典的构建
为何Lucene大数据量搜索快, 要分两部分来看 :
- 一点是因为底层的倒排索引存储结构。
- 另一点就是查询关键字的时候速度快, 因为词典的索引结构。
4.1 词典数据结构对比
倒排索引中的词典位于内存,其结构尤为重要,有很多种词典结构,各有各的优缺点,最简单如排序数组,通过二分查找来检索数据,更快的有哈希表,磁盘查找有B树、B+树,但一个能支持TB级数据的倒排索引结构需要在时间和空间上有个平衡,下图列了一些常见词典的优缺点:
| 数据结构 | 优缺点 |
| 跳跃表 | 占用内存小,且可调,但是对模糊查询支持不好 |
| 排序列表Array/List | 使用二分法查找,不平衡 |
| 字典树 | 查询效率跟字符串长度有关,但只适合英文词典 |
| 哈希表 | 性能高,内存消耗大,几乎是原始数据的三倍 |
| 双数组字典树 | 适合做中文词典,内存占用小,很多分词工具均采用此种算法 |
| Finite State Transducers (FST) | 一种有限状态转移机,Lucene 4有开源实现,并大量使用 |
| B树 | 磁盘索引,更新方便,但检索速度慢,多用于数据库 |
Lucene3.0之前使用的也是跳跃表结构,后换成了FST,但跳跃表在Lucene其他地方还有应用如倒排表合并和文档号索引。
4.2 跳跃表原理
Lucene3.0版本之前使用的跳跃表结构后换成了FST结构
优点 :结构简单、跳跃间隔、级数可控,Lucene3.0之前使用的也是跳跃表结构,,但跳跃表在
Lucene其他地方还有应用如倒排表合并和文档号索引。
缺点 :模糊查询支持不好。
单链表 :
单链表中查询一个元素即使是有序的,我们也不能通过二分查找法的方式缩减查询时间。
通俗的讲也就是按照链表顺序一个一个找。
举例: 查找85这个节点, 需要查找7次。

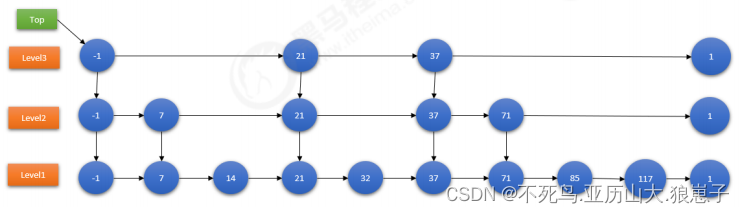
跳跃表:
举例: 查询85这个节点, 一共需要查询6次.
- 在level3层, 查询3次, 查询到1结尾, 退回到37节点
- 在level2层, 从37节点开始查询, 查询2次, 查询到1结尾, 退回到71节点
- 在level1层, 从71节点开始查询, 查询1次, 查询到85节点.
4.3 FST原理简析
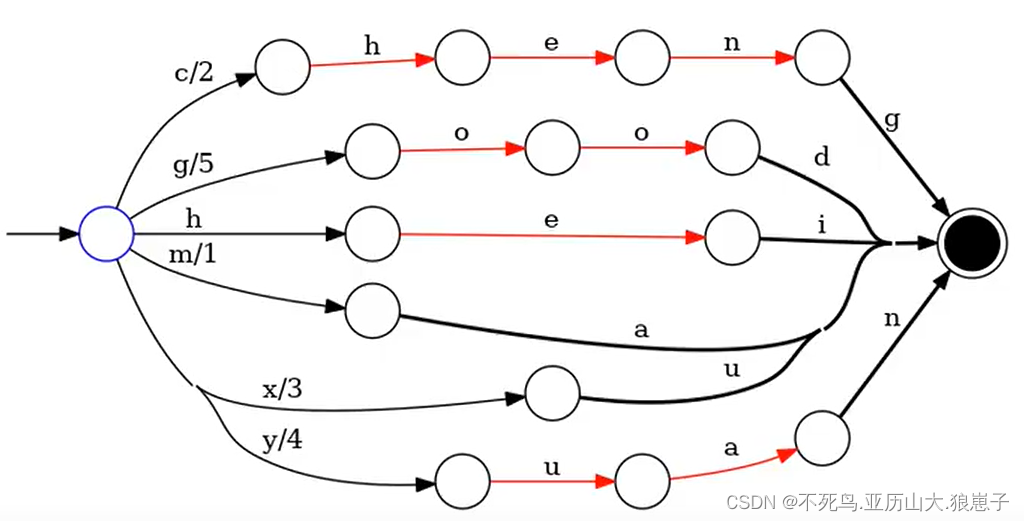
Lucene现在采用的数据结构为FST,它的特点就是: 优点:内存占用率低,压缩率一般在3倍~20倍之间、模糊查询支持好、查询快 缺点:结构复杂、输入要求有序、更新不易。
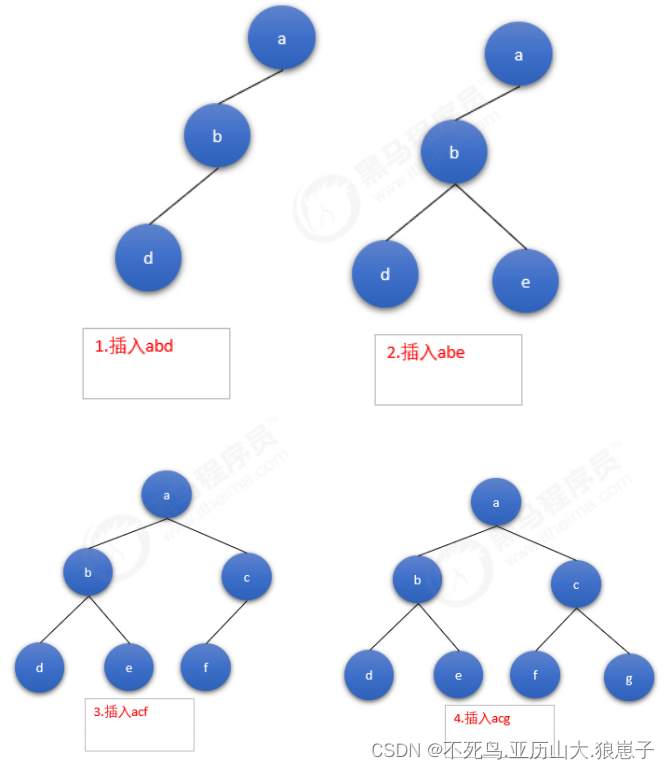
已知FST要求输入有序,所以Lucene会将解析出来的文档单词预先排序,然后构建FST,我们假设输入为abd,abe,acf,acg,那么整个构建过程如下:
输入数据:
String inputValues[] = {"hei","ma","cheng","xu","yuan","good"};
long outputValues[] = {0,1,2,3,4,5};输入的数据如下:
hei/0
ma/1
cheng/2
xu/3
yuan/4
good/5
存储结果如下: