官方文档不同版本配置变更记录:Spring Boot Start 配置 :: ShardingSphere
pom.xml配置:
<!--shardingsphere分库分表依赖-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<!--mybatis-plus依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>建表sql:
CREATE TABLE `orders_0` (
`id` bigint NOT NULL COMMENT '主键',
`order_no` varchar(255) NOT NULL COMMENT '订单号',
`user_id` bigint NOT NULL COMMENT '用户id',
`pay_amount` decimal(20,2) NOT NULL DEFAULT '0' COMMENT '支付金额',
`order_status` int NOT NULL COMMENT '订单状态 1-已预约 2-已取车 3-已还车 4-已取消',
`pay_status` int NOT NULL DEFAULT '0' COMMENT '支付状态 0-未支付 1-支付成功',
`pay_method` int DEFAULT NULL COMMENT '支付方式 1-微信 2-支付宝',
`pay_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '支付时间',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `orders_1` (
`id` bigint NOT NULL COMMENT '主键',
`order_no` varchar(255) NOT NULL COMMENT '订单号',
`user_id` bigint NOT NULL COMMENT '用户id',
`pay_amount` decimal(20,2) NOT NULL DEFAULT '0' COMMENT '支付金额',
`order_status` int NOT NULL COMMENT '订单状态 1-已预约 2-已取车 3-已还车 4-已取消',
`pay_status` int NOT NULL DEFAULT '0' COMMENT '支付状态 0-未支付 1-支付成功',
`pay_method` int DEFAULT NULL COMMENT '支付方式 1-微信 2-支付宝',
`pay_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '支付时间',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
......
CREATE TABLE `orders_9` (
`id` bigint NOT NULL COMMENT '主键',
`order_no` varchar(255) NOT NULL COMMENT '订单号',
`user_id` bigint NOT NULL COMMENT '用户id',
`pay_amount` decimal(20,2) NOT NULL DEFAULT '0' COMMENT '支付金额',
`order_status` int NOT NULL COMMENT '订单状态 1-已预约 2-已取车 3-已还车 4-已取消',
`pay_status` int NOT NULL DEFAULT '0' COMMENT '支付状态 0-未支付 1-支付成功',
`pay_method` int DEFAULT NULL COMMENT '支付方式 1-微信 2-支付宝',
`pay_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '支付时间',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
yml配置:
spring:
shardingsphere:
datasource:
common:
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
names: db0,db1
db0:
url: jdbc:mysql://localhost:3306/test
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
db1:
url: jdbc:mysql://localhost:3306/zkq_oms_test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
# 默认数据源,未分片的表默认执行库
sharding:
default-data-source-name: db1
rules:
sharding:
key-generators:
# 此处必须要配置,否则会导致报错,因为shardingsphere-jdbc-core-spring-boot-starter需要加载此项配置,官网的demo例子有错
# 分布式序列算法:https://shardingsphere.apache.org/document/current/cn/user-manual/common-config/builtin-algorithm/keygen/
snowflake:
type: SNOWFLAKE
props:
# 在单机模式下支持用户自定义配置,如果用户不配置使用默认值为0。
# 在集群模式下会由系统自动生成,相同的命名空间下不会生成重复的值。
worker-id: 0
sharding-algorithms:
# 分片算法:https://shardingsphere.apache.org/document/current/cn/user-manual/common-config/builtin-algorithm/sharding/
table-mod:
# 取模类型分片键的值必须是数字,否则会报错
type: MOD
props:
sharding-count: 10
tables:
orders:
# 配置逻辑表:orders与真实库表的对应规则
actual-data-nodes: db0.orders_$->{0..9}
# 配置分表规则
table-strategy:
standard:
sharding-column: order_no
sharding-algorithm-name: table-mod
enabled: true
# 展示修改以后的sql语句
props:
sql-show: true
mybatis:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
type-aliases-package: com.example.demo.entity
mapper-locations: classpath:mapper/*.xmlorders对象实体:
package com.example.demo.entity;
import com.baomidou.mybatisplus.annotation.TableId;
import lombok.Data;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.Date;
@Data
public class Orders implements Serializable {
@TableId
private Long id;
/**
* 订单号
*/
private String orderNo;
/**
* 用户id
*/
private Long userId;
/**
* 订单状态 1-已预约 2-已取车 3-已还车 4-已取消
*/
private Integer orderStatus;
/**
* 支付状态 0-未支付 1-支付成功
*/
private Integer payStatus;
/**
* 支付方式 1-微信 2-支付宝
*/
private Integer payMethod;
/**
* 支付金额
*/
private BigDecimal payAmount;
/**
* 支付时间
*/
private Date payTime;
/**
* 创建时间
*/
private Date createdAt;
/**
* 修改时间
*/
private Date updatedAt;
}
OrdersMapper:
package com.example.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.springframework.stereotype.Repository;
import com.example.demo.entity.Orders;
import java.util.List;
@Repository
public interface OrdersMapper extends BaseMapper<Orders> {
Orders getOrderByNo(String orderNo);
List<Orders> getOrderList();
}
OrdersMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper
namespace="com.example.demo.mapper.OrdersMapper">
<sql id="Base_Column_List">
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
</sql>
<select id="getOrderByNo" parameterType="java.lang.String"
resultType="com.example.demo.entity.Orders">
select
<include refid="Base_Column_List" />
from orders where order_no=#{orderNo}
</select>
<select id="getOrderList" resultType="com.example.demo.entity.Orders">
select
<include refid="Base_Column_List" />
from orders order by created_at desc limit 10, 10
</select>
</mapper>单元测试:
package com.example.demo;
import com.example.demo.mapper.OrdersMapper;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import com.example.demo.entity.Orders;
import java.math.BigDecimal;
import java.util.Date;
import java.util.List;
import java.util.Map;
@RunWith(SpringRunner.class)
@SpringBootTest
public class DemoApplicationTest {
@Autowired
private OrdersMapper ordersMapper;
@Test
public void saveOrder() {
Orders orders = new Orders();
orders.setOrderNo("297454965260130002");
orders.setUserId(2L);
orders.setPayAmount(new BigDecimal("32"));
orders.setOrderStatus(1);
orders.setPayStatus(1);
orders.setPayMethod(1);
orders.setPayTime(new Date());
orders.setCreatedAt(new Date());
orders.setUpdatedAt(new Date());
ordersMapper.insert(orders);
}
@Test
public void contextLoads() {
Orders order = ordersMapper.getOrderByNo("297454965260130002");
System.out.println("查询结果:" + order);
}
@Test
public void getOrderList() {
List<Orders> orderList = ordersMapper.getOrderList();
orderList.forEach((e)-> System.out.println("查询结果:" + e));
}
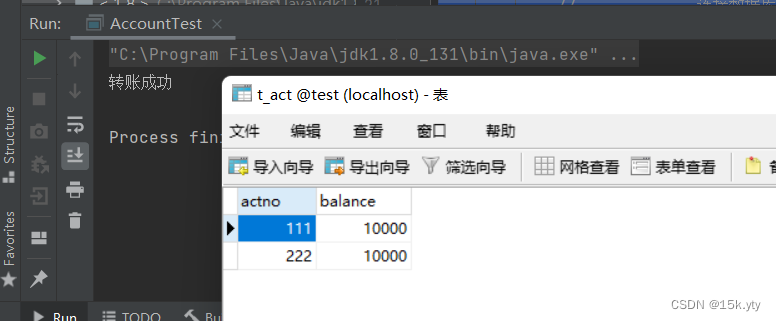
}1、插入数据结果,按order_no分片取模,分片数为10,该数据被写入表orders_2:

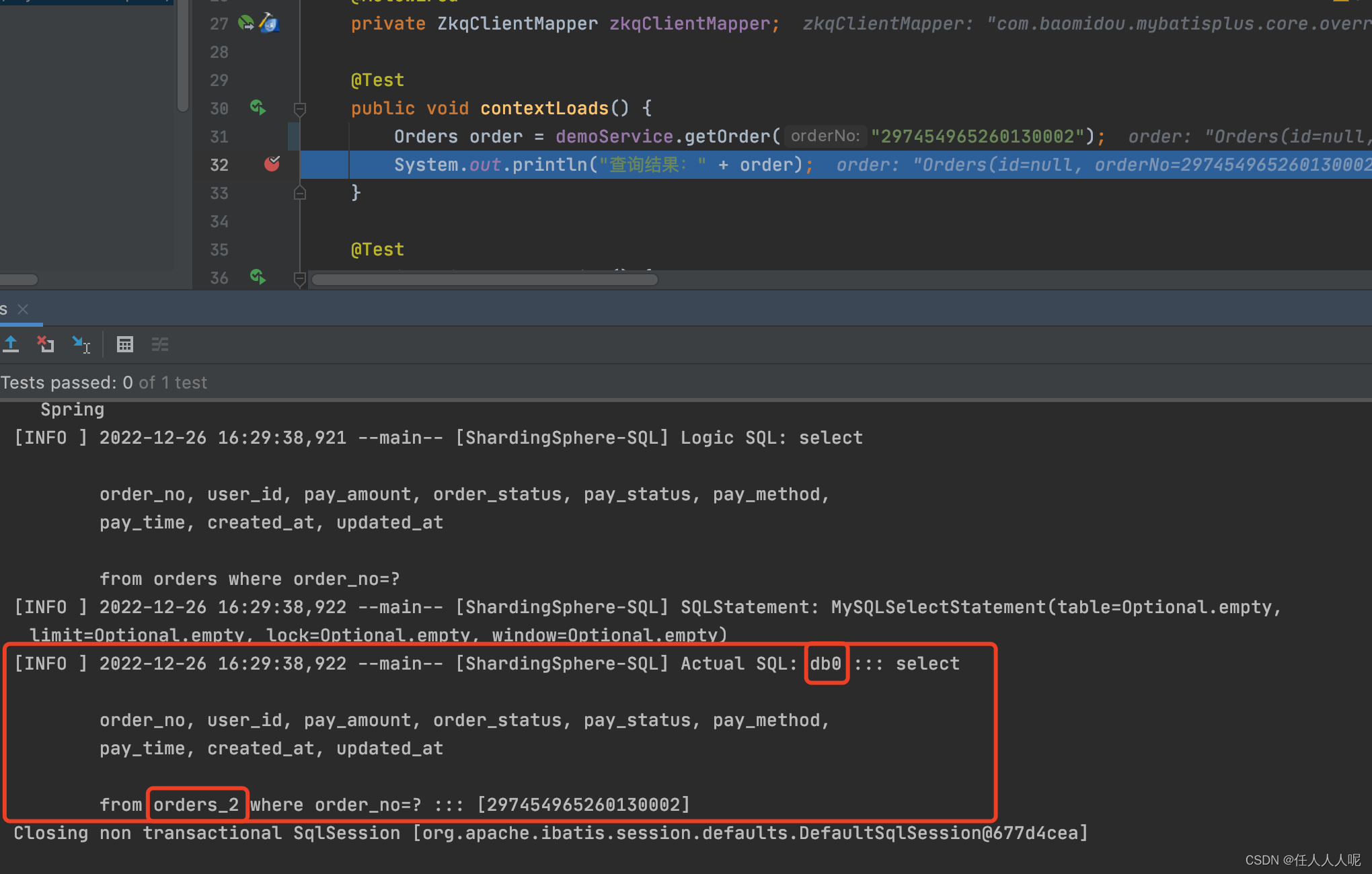
2、查询数据sql,按order_no分片取模,分片数为10,该数据直接查询表orders_2:
3、未传分片键,执行ordersMapper.getOrderList(); 查询所有表:
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@2fcad739] was not registered for synchronization because synchronization is not active
JDBC Connection [org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection@4e93d23e] will not be managed by Spring
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Logic SQL: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders order by created_at desc limit 10, 10
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] SQLStatement: MySQLSelectStatement(table=Optional.empty, limit=Optional[org.apache.shardingsphere.sql.parser.sql.common.segment.dml.pagination.limit.LimitSegment@6c65c6f0], lock=Optional.empty, window=Optional.empty)
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_0 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_1 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_2 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_3 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_4 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_5 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_6 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_7 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,294 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_8 order by created_at desc limit 0, 20
[INFO ] 2022-12-26 16:38:50,295 --main-- [ShardingSphere-SQL] Actual SQL: db0 ::: select
order_no, user_id, pay_amount, order_status, pay_status, pay_method,
pay_time, created_at, updated_at
from orders_9 order by created_at desc limit 0, 20
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@2fcad739]
根据以上日志可以看到,逻辑sql为:
select order_no, user_id, pay_amount, order_status, pay_status, pay_method, pay_time, created_at, updated_at from orders order by created_at desc limit 10, 10;
但实际sql是分别查询orders_0到orders_9,limit 0, 20
这是由于shardingsphere会对逻辑sql进行路由、改写,然后归并结果集。所以在使用中一定要注意,未传分片键查询的话会造成广播路由(用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL和DML,以及DDL等)
注:shardingsphere-jdbc在采用主从模型时,为了保证主从库间的事务一致性,避免跨服务的分布式事务,添加@Transactional事务注解开启事务后,事务中的数据读写均用主库。(在JUnit环境下的@Transactional注解,默认情况下会对事务进行回滚)