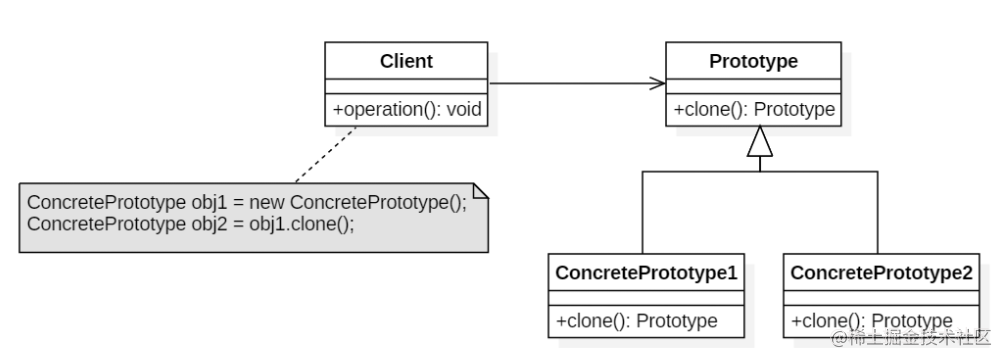
朴素贝叶斯分类
朴素贝叶斯分类是基于贝叶斯定理与特征条件独立假设的分类方法,发源于古典数学理论,拥有稳定的数学基础和分类效率。它是一种十分简单的分类算法,当然简单并不一定不好用。通过对给出的待分类项求解各项类别的出现概率大小,来判断此待分类项属于哪个类别,而在没有多余条件的情况下,朴素贝叶斯分类会选择在已知条件下,概率最大的类别。
贝叶斯分类算法的实质就是计算条件概率的公式。在事件 B 发生的条件下,事件 A 发生的概率为 P(A | B)来表示。

P(A | B)的概率为

。在日常应用中,我们经常可以直接得出 P(A | B),而 P(B | A)直接得到比较困难,通过贝叶斯定理就可以通过 P(A | B)获得 P(B | A)。
而朴素贝叶斯分类的正式定义则如下:
1.设
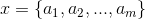
为一个待分类项,而每个 a 为 x 的一个特征属性。
2.有类别集合
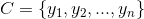
。
3.计算
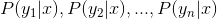
。
4.如果
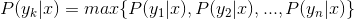
,则
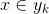
。
朴素贝叶斯算法在执行文本分类等工作是会有很好的效果,比如朴素贝叶斯算法常被使用于垃圾邮件的过滤分类中。
SVM算法
支持向量机(Support Vector Machine,常简称为 SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析。支持向量机属于一般化线性分类器,它能够同时最小化经验误差与最大化几何边缘区,因此支持向量机也被称为最大边缘区分类器。
同时支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。

SVM 算法虽然存在难以训练和难以解释的问题,但是在非线性可分问题上的表现十分优秀,在非线性可分问题中常选择 SVM 算法。
基于 KNN 的算法
K - 近邻算法,简称 KNN(k-Nearest Neighbor),它同样是一个比较简单的分类、预测算法。对选取与待分类、待预测数据的最相似的 K 个训练数据,通过对这 K 个数据的结果或者分类标号取平均、取众数等方法得到待分类、待预测数据的结果或者分类标号。

K - 近邻算法如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。在不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形)的情况下,我们可以从它的临近的样本进行判断。
如果 K=3,绿色圆点最近的 3 个邻居是 2 个红色小三角形和 1 个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果 K=5,绿色圆点的最近的 5 个邻居是 2 个红色三角形和 3 个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
从上文我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类,这就是 K 近邻算法的核心思想。
KNN 算法相比其他算法也更加简单,并且易于理解、实现,无需估计参数与训练。适合对稀有事件进行分类和多分类方面的问题,在这类问题方面 KNN 算法的表现比 SVM 更好。
人工神经网络算法
人工神经网络,简称神经网络或类神经网络,是一种模仿生物神经网络结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。
下图为人工神经网络示意图,人工神经网络由很多的层组成,最前面这一层叫输入层,最后面一层叫输出层,最中间的层叫隐层,并且每一层有很多节点,节点之间有边相连的,每条边都有一个权重。对于文本来说输入值是每一个字符,对于图片来说输入值就是每一个像素。
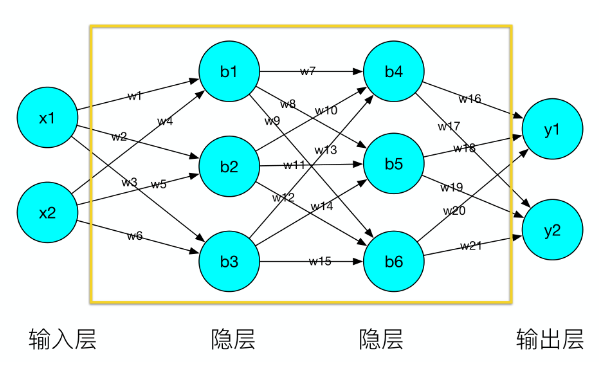
人工神经网络是如何工作的?
1.前向传播:对于一个输入值,将前一层的输出与后一层的权值进行运算,再加上后一层的偏置值得到了后一层的输出值,再将后一层的输出值作为新的输入值传到再后面一层,一层层传下去得到最终的输出值。
2.反向传播:前向传播会得到预测值,但是这个预测值不一定是真实的值,反向传播的作用就是修正误差,通过与真实值做对比修正前向传播的权值和偏置。
人工神经网络在语音、图片、视频、游戏等各类应用场景展现出了优异的性能,但是存在需要大量的数据进行训练来提高准确性的问题。
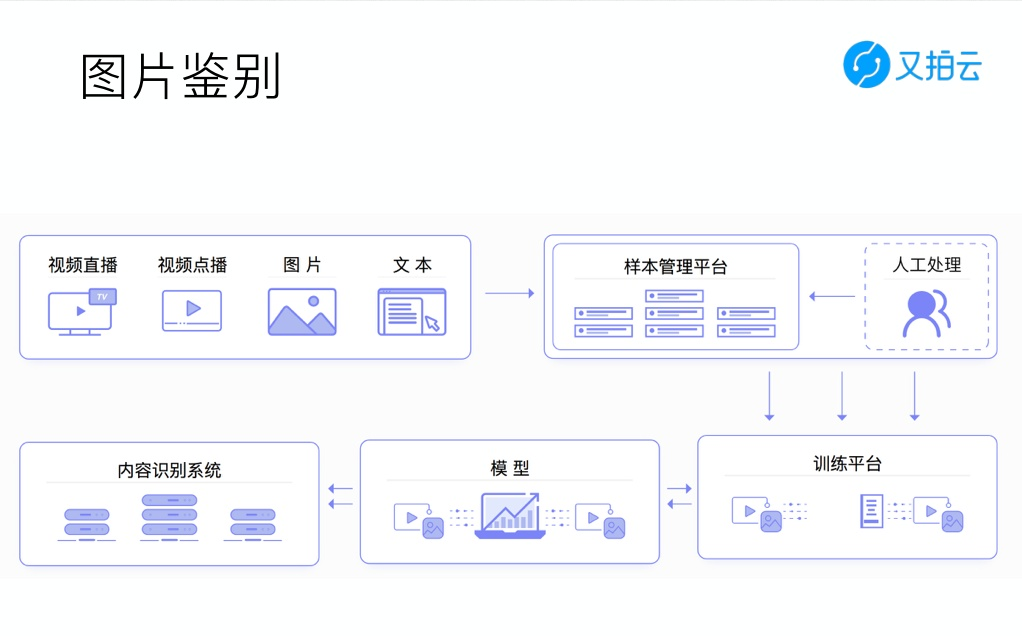
又拍云内容识别服务
又拍云内容识别中使用的便是人工神经网络算法,通过上传图片到样本管理平台,首先进行人工标注图片是否为性感图、色情图、广告图或者是暴恐图片,标注完成后将它放到线下处理平台训练,得出训练模型和结果,再将模型发回线上进行智能鉴别。
人工神经网络算法在测试中表现出了识别迅速、准确率高的特性,目前又拍云内容识别应用于色情识别的正确率高达 99.7%。