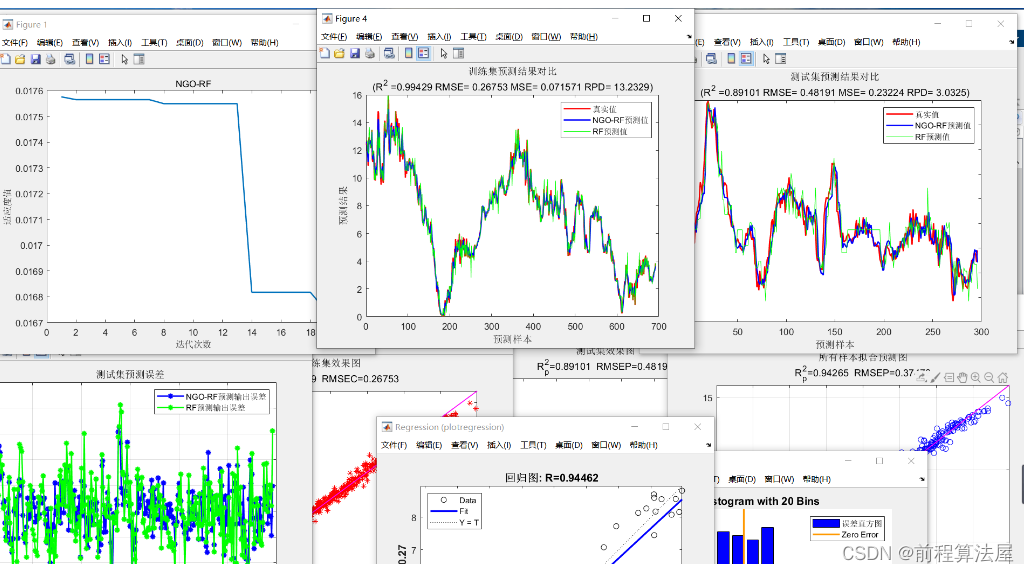
机器学习【线性回归】
回归预测的结果是离散型变量,身高和年龄
损失函数:SSE(误差平方和),RSS(残差平方和),误差越大越差
最小二乘法:通过最小化真实值和预测值之间的RSS来求解参数的方法
线性回归的损失函数是SSE(误差平方和)RSS(残差平方和)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P2iQ648w-1686053924076)(C:\Users\Administrator\Desktop\b.png)]](https://img-blog.csdnimg.cn/99075314bb584007b0e4e9f783b44af5.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SHCYJBjE-1686053924078)(C:\Users\Administrator\Desktop\c.png)]](https://img-blog.csdnimg.cn/04e9fb51bb1044e89187b78adf78e4f6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9zTl6H1e-1686053924079)(C:\Users\Administrator\Desktop\d.png)]](https://img-blog.csdnimg.cn/3fab53b8299a474c86172e93b9fc526b.png)
1.线性回归
回归是一种应用广泛的预测建模技术,这种技术的核心在于预测的结果是连续型变量。 决策树,随机森林,支持向量 机的分类器等分类算法的预测标签是分类变量,多以{0,1}来表示,而 无监督学习算法比如PCA,KMeans并不求解标签,注意加以区别。
回归算法源于统计学理论,它可能是机器学习算法中产生最早的算法之一,其在现实中的应用 非常广 泛,包括使用其他经济指标预测股票市场指数,根据喷射流的特征预测区域内的降水量,根据公司的广 告花费预测总销售额,或者根据有机物质中残留的碳-14的量来估计化石的年龄等等,只要一切基于特 征预测连续型变量的需求,我们都使用回归技术。
既然线性回归是源于统计分析,是结合机器学习与统计学的重要算法。通常来说,我们认为统计学注重 先验,而机器 学习看重结果,因此机器学习中不会提前为线性回归排除共线性等可能会影响模型的因 素,反而会先建立模型以查看 效果。模型确立之后,如果效果不好,我们就根据统计学的指导来排除可 能影响模型的因素。我们的课程会从机器学习的角度来为大家讲解回归类算法,如果希望理解统计学角 度的小伙伴们,各种统计学教材都可以满足你的需求。
回归类算法的数学相对简单。通常,理解线性回归可以有两种角度:矩阵的角度和代数的角度。几乎所 有机器学习的教材都是从代数的角度来理解线性回归的。相对的,在我们的课程中一直都缺乏比较系统 地使用矩阵来解读算法的角度,因此在本堂课中,我将全程使用矩阵方式(线性代数的方式)为大家展 现回归大家族的面貌。 学完这堂课之后,大家需要对线性模型有个相对全面的了解,尤其是需要掌握线性模型究竟存在什么样 的优点和问 题,并且如何解决这些问题。
2.SKlearn中的线性回归
sklearn中的线性模型模块是linear_model,我们曾经在学习逻辑回归的时候提到过这个模块。 linear_model包含了 多种多样的类和函数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qJMpaQwH-1686053924080)(C:\Users\Administrator\Desktop\q.png)]](https://img-blog.csdnimg.cn/5e8b7bf07e4c4069b2ba047b9e66e45a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gv0y2Ngc-1686053924081)(C:\Users\Administrator\Desktop\w.png)]](https://img-blog.csdnimg.cn/35e18f26ef2d4799b748c3a8d3bec74a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PfQubEuZ-1686053924082)(C:\Users\Administrator\Desktop\e.png)]](https://img-blog.csdnimg.cn/6d63cdea7d1e4ce0b8d603fe082ffd31.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0MEIlpQk-1686053924082)(C:\Users\Administrator\Desktop\r.png)]](https://img-blog.csdnimg.cn/60ccb2d3fe4c4db6b4765ed5a95c5f1b.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3evmApX6-1686053924083)(C:\Users\Administrator\Desktop\t.png)]](https://img-blog.csdnimg.cn/b32447256c694b11874fc392bad5e146.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2MUZd0sn-1686053924084)(C:\Users\Administrator\Desktop\y.png)]](https://img-blog.csdnimg.cn/6589047ec94341d4bb8079dac0fe0dc8.png)
3.线性回归评判相关
3.1导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
plt.rcParams['font.sans-serif']=['SimHei']
3.2示例数据
x=np.array([1,2,3,4,5,6]).reshape(-1,1)
y=np.array([2,4,6,8,10,12])
3.3建模
model = LinearRegression()
model.fit(x,y)
3.4 预测
y_pred=model.predict(x)
3.5评估指标
# mse——均值平方误差
mse = mean_squared_error(y,y_pred)
# mae——平方绝对值误差
mae=mean_absolute_error(y,y_pred)
# rmse——均方根误差
rmse = np.sqrt(mse)
#r2(r方)——决定系数
r2 = r2_score(y,y_pred)
4.交叉验证
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P0B8ueVn-1686053924085)(C:\Users\Administrator\Desktop\11.png)]](https://img-blog.csdnimg.cn/ed5263fc6e084369a5bffed3b5b0e3d1.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iv0tfSNP-1686053924086)(C:\Users\Administrator\Desktop\22.png)]](https://img-blog.csdnimg.cn/b35468aed55b4b9aa702f1c1e12a235f.png)
5.网格搜索
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a56Oyahx-1686053924087)(C:\Users\Administrator\Desktop\33.png)]](https://img-blog.csdnimg.cn/0f85c20354b14cdab88b55406a2157fc.png)
6.KNN回归与线性回归对比
#导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
#生成数据
x = np.linspace(0,2*np.pi,60)
y = np.sin(x)
plt.scatter(x,y)
#噪声数据
bias = np.random.random(30) - 0.5
y[::2] +=bias
plt.scatter(x,y)
#特征工程
X=x.reshape(-1,1)
# 建模
# knn
knn = KNeighborsRegressor(n_neighbors=3)
knn.fit(X,y)
#构建测试数据并预测
X_test = np.linspace(0,2*np.pi,45).reshape(-1,1)
y_=knn.predict(X_test)
# KNN模型结果可视化
plt.scatter(x,y,label='True Date',color='blue')
plt.plot(X_test,y_,label='KNN prediction',color='red')
plt.legend()
plt.show()
#使用线性回归进行预测
liner=LinearRegression()
liner.fit(X,y)
y2_ = liner.predict(X_test)
#对比分析两者结果
plt.scatter(x,y,label='True Date',color='blue')
plt.plot(X_test,y_,label='KNN prediction',color='red')
plt.plot(X_test,y2_,label='liner prediction',color='black')
plt.legend()
plt.show()