Linux学习内核思路
学习过程:
- Linux内核引导及如何初始化
- 进程管理、内存管理
内核引导及过程:
CPU通电后,首先执行引导程序,引导程序把内核加载到**内存,**然后执行内核,内核初始化完成后,启动用户空间的进程。CPU通电后,自动把程序计数器设置为CPU厂商设计的某个固定值。嵌入式设备通常用NOR闪存作为只读存储器存放引导程序。
嵌入式设备通常使用U-Boot作为引导程序。
- 函数_main
ENTRY(_main)–>U->boot程序初始化完成之后,准备处理命令是通过数组init_sequence_r,最后一个函数run_main_loop()实现。
- kernel_entry()–>start_kernel()
- ARM架构下SMP系统自旋表引导过程?(内核技术面试)
引导处理器启动从处理器方法3种:
a. 自旋表
b. 电源状态协调接口
c. ACPI停车协议
用户空间和内核空间: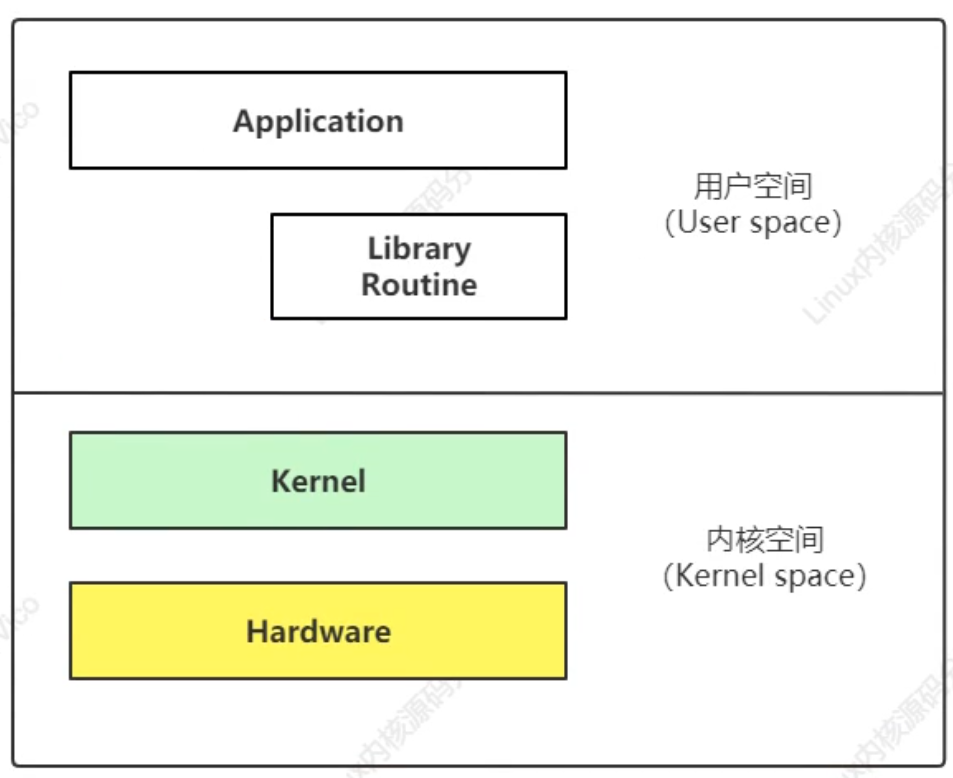
系统调用: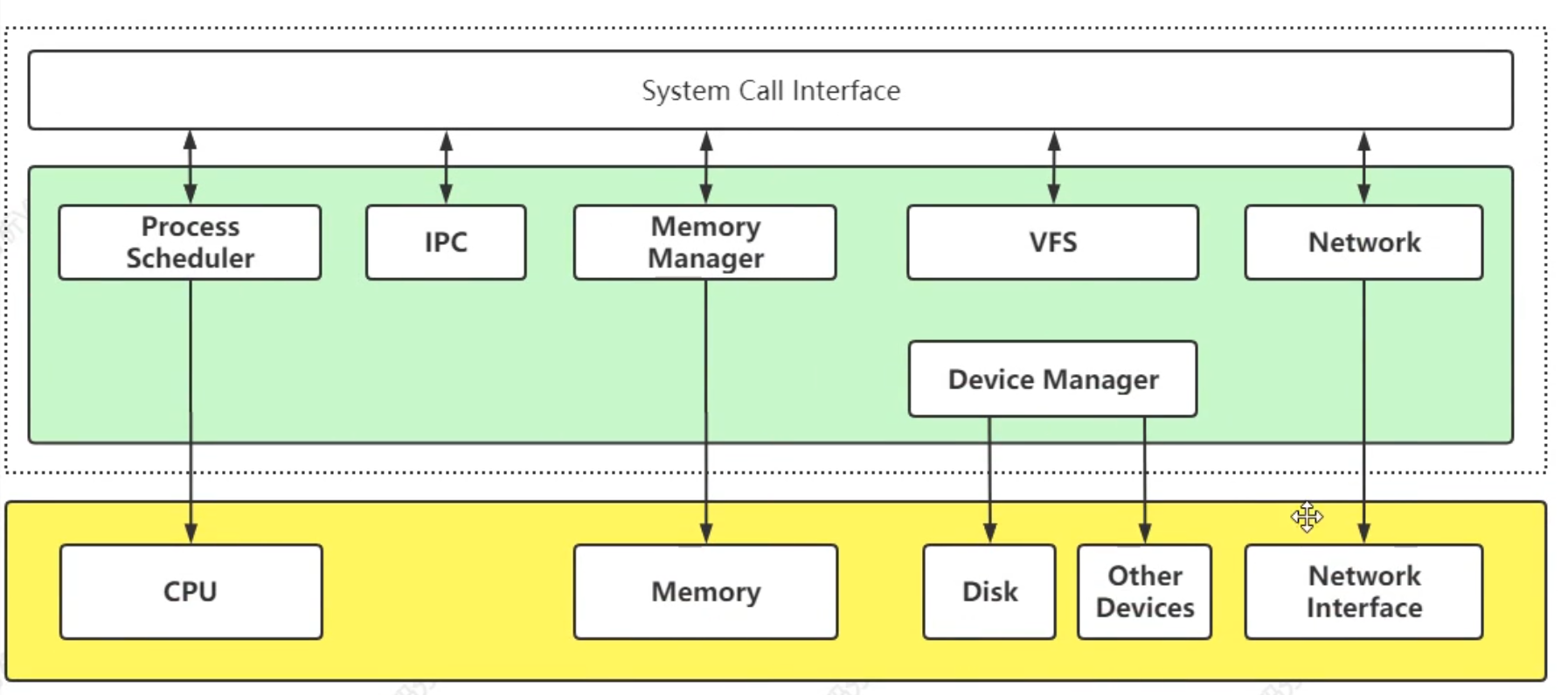
进程:
内存: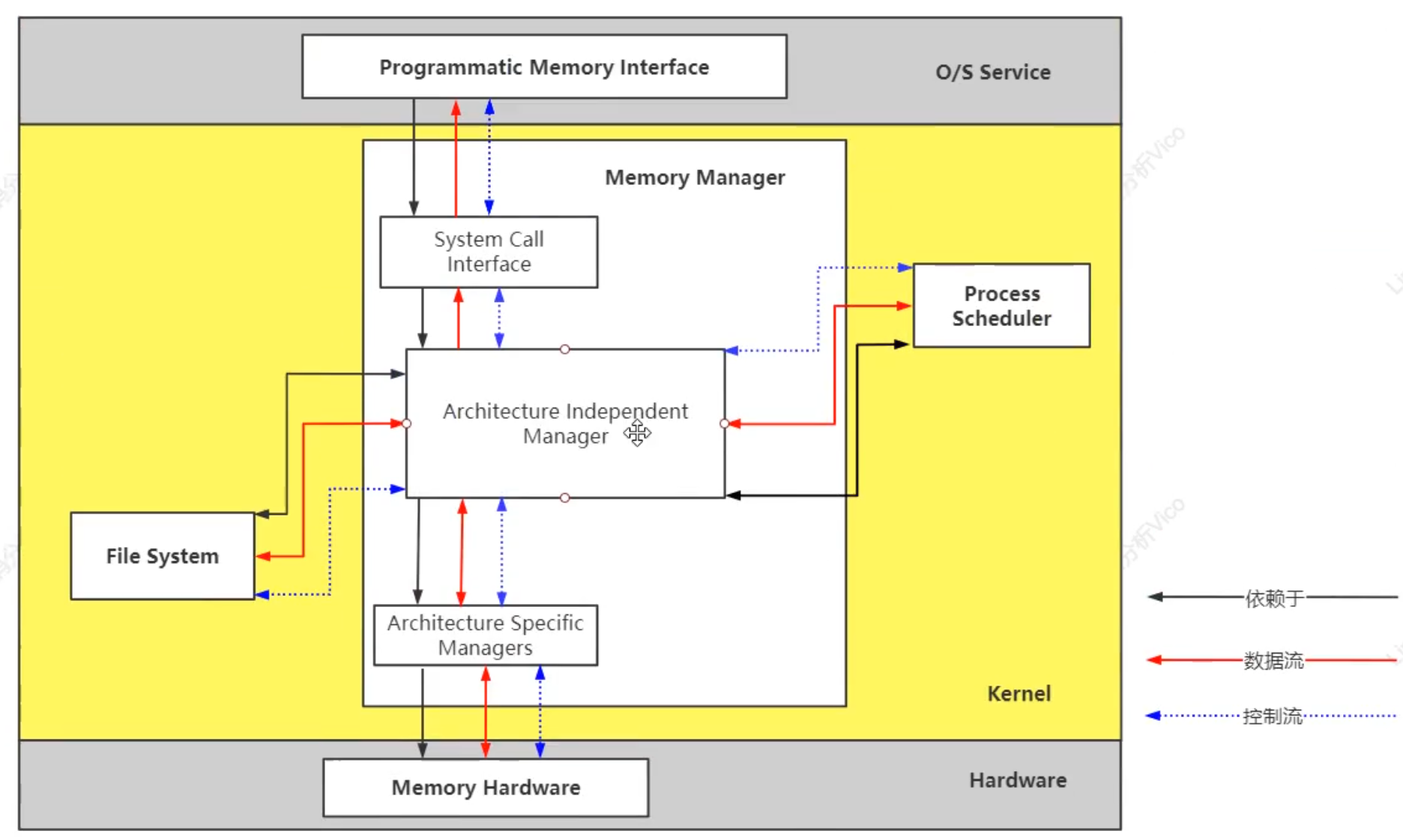
文件系统: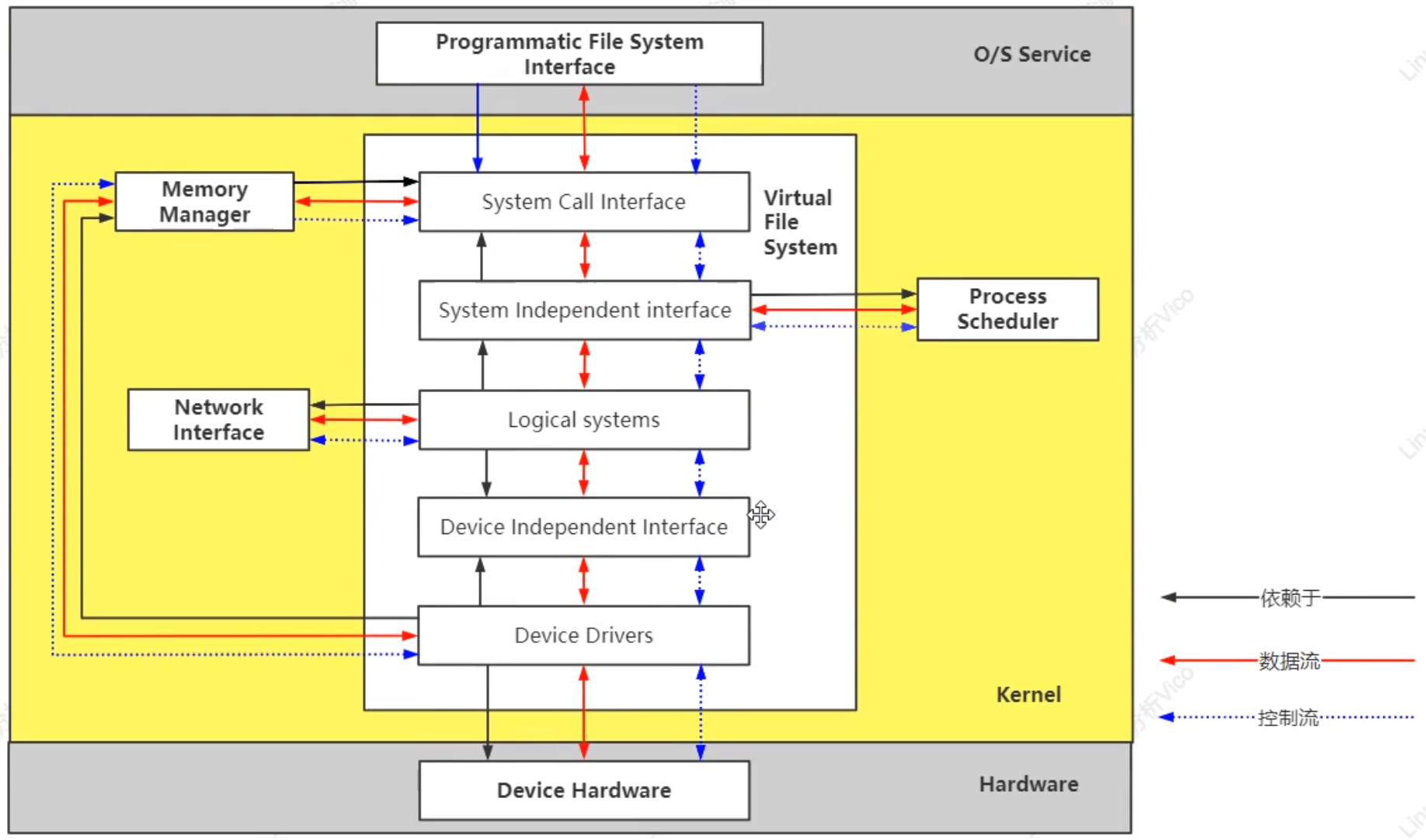
网络: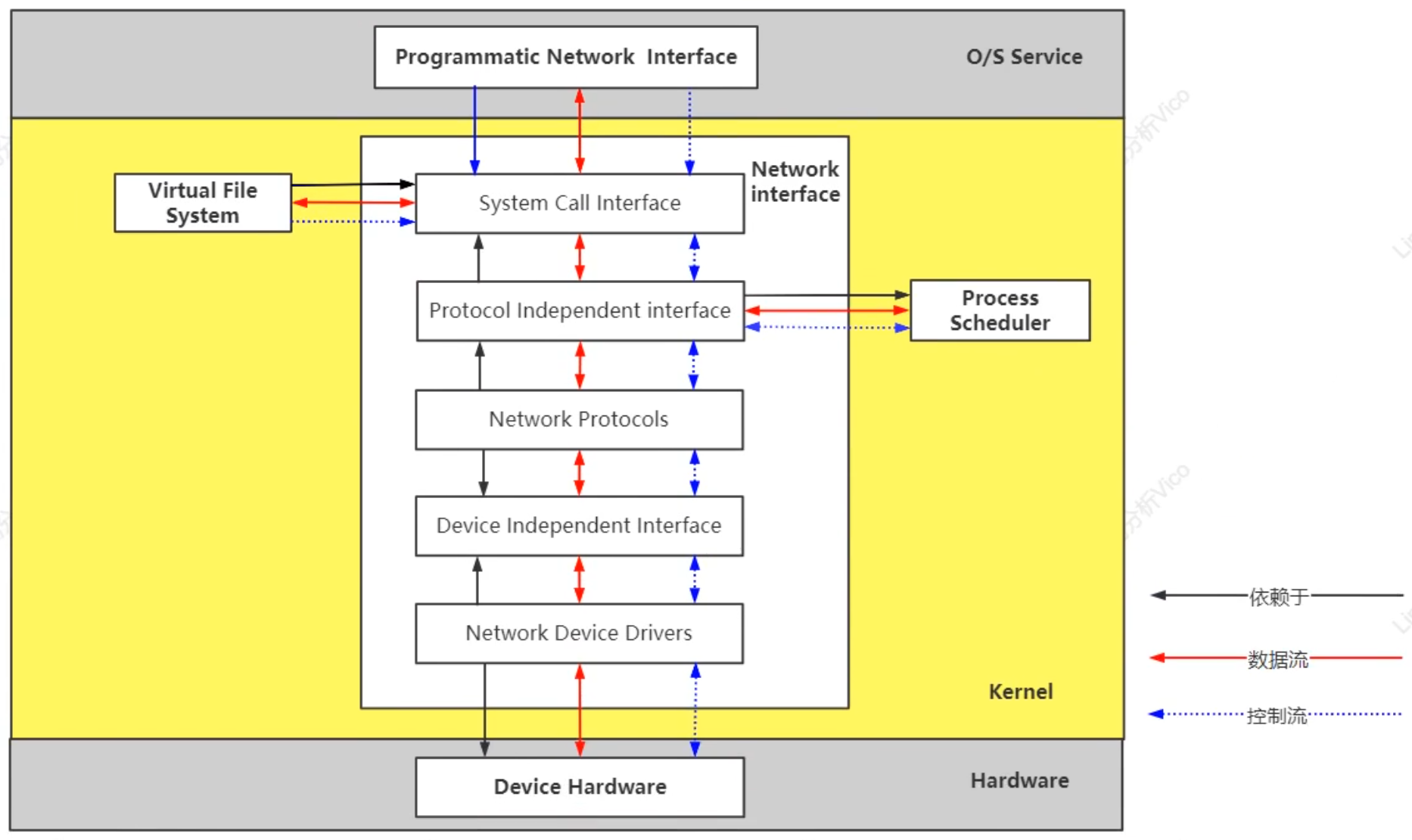
Linux内核源码
Linux内核版本介绍
linux版本分为两类:
- 内核版本:免费的,它只是操作系统的核心,负责控制硬件、管理文件系统、程序进程等,并不给用户提供各种工具和应用软件;
- 发行版本:不一定免费,出了操作系统核心外,还包含一套强大的软件,例如:C/C++编译器和库等
内核版本
1.1)内核版本命名:
Linux内核版本号由3组数字组成:第一个组数字.第二组数字.第三组数字
- 第一个组数字:目前发布的内核主版本。
- 第二个组数字:偶数表示稳定版本;奇数表示开发中版本。
- 第三个组数字:错误修补的次数。
可以使用uname -r 查看内核版本号,例如:2.6.32-754.2.1.el6.x86_64
- 第一个组数字: 2 , 主版本号
- 第二个组数字: 6 , 次版本号,表示稳定版本(因为有偶数)
- 第三个组数字: 32 , 修订版本号 ,表示修改的次数。
- 第四个组数字: 754.2.1,表示发型版本的补丁版本,这里是 CentOS 6.10 。
- el6 则表示我正在使用的内核是 RedHat / CentOS 系列发行版专用内核;x86_64 表示64位cpu。
除了前面的版本号外,最后的有多种,例如:2.6.32-358.6.1.el6.i686、2.6.18-128.ELsmp、2.6.32-642.el6.x86_64
- EL : Enterprise Linux ;
- ELsmp:指出了当前内核是为EL特别调校的,其中smp : 表示支持多处理器 , 表示该内核版本支持多处理器;
- i386:几乎任何的X86平台,不论是旧的pentum或是新的pentum-IV和K7系统CPU,都能够正常工作,i指得是Intel兼容的CPU,至于386就是CPU的等级;
- i586:就是586等级的电脑,包括pentum第一代MMX CPU,AMD的K5,K6系统CPU(socket7插脚)等CPU都是这个等级;
- i686:pentum 2 以后的Intel系统CPU及K7以后等级的CPU都属于这个686等级;
- x86_64:采用的是64位的CPU;
- generic:当前内核版本为通用版本,另有表示不同含义的server(针对服务器);
- pae(Physical Address Extension):物理地址扩展,为了弥补32位地址在PC服务器应用上的不足而推出,表示此32位系统可以支持超过4G的内存
1.2)内核版本历史:
linux内核大致分为以下几个阶段:
- 2.6.0之前版本:
- 2.6.x版本:2.6 时代跨度非常大,从2.6.0 (2003年12月发布[36]) 到 2.6.39(2011年5月发布), 跨越了 40 个大版本;
- 3.x.y:3.0(原计划的 2.6.40, 2011年7月发布) 到 3.19(2015年2月发布)
- 4.x.y:4.0(2015年4月发布)到4.2(2015年8月底发布)
- 5.x.y:
截止到2021年,很多线上系统仍然使用2.6.x的内核。Linux2.6版本内核发布,与2.4内核版本相比,它在很多方面进行了改进,如支持多处理器配置和64位计算,它还支持实现高效率线和处理的本机POSIX 线程库(NPTL)。实际上,性能、安全性和驱动程序的改进是整个2.6.x 内核的关键。
https://en.wikipedia.org/wiki/Linux_kernel_version_history#Releases_before_2.6.0
发行版本
人们以Linux核心为中心,再集成搭配各种各样的系统管理软件或应用工具软件组成一套完整的操作系统,如此的组合便称为Linux发行版。
Linux的发行版本可以大体分为两类:
- 一类是商业公司维护的发行版本:以著名的Redhat(REHL)为代表;
- 一类是社区组织维护的发行版本:以Debian为代表;
1)Redhat(小红帽),应该称为Redhat系列,包括RHEL(Redhat Enterprise Linux,也就是所谓的Redhat Advance Server,收费版本)、Fedora Core(由原来的Redhat桌面版本发展而来,免费版本)、CentOS(RHEL的社区克隆版本,免费)。Redhat应该说是在国内使用人群最多 的Linux版本,甚至有人将Redhat等同于Linux,而有些老鸟更是只用这一个版本的Linux。所以这个版本的特点就是使用人群数量大,资料非常多,言下之意就是如果你有什么不明白的地方,很容易找到人来问,而且网上的一般Linux教程都是以Redhat为例来讲解的。Redhat系列的包管理方式采用的是基于RPM包的YUM包管理方式,包分发方式是编译好的二进制文件。稳定性方面RHEL和CentOS的稳定性非常好,适合于服务器使用, 但是Fedora Core的稳定性较差,最好只用于桌面应用。
2)Debian,或者称Debian系列,包括Debian和Ubuntu等。Debian是社区类Linux的典范,是迄今为止最遵循GNU规范 的Linux系统。Debian最早由Ian Murdock于1993年创建,分为三个版本分支(branch): stable, testing 和 unstable。其中,unstable为最新的测试版本,其中包括最新的软件包,但是也有相对较多的bug,适合桌面用户。testing的版本都经 过unstable中的测试,相对较为稳定,也支持了不少新技术(比如SMP等)。而stable一般只用于服务器,上面的软件包大部分都比较过时,但是 稳定和安全性都非常的高。Debian最具特色的是apt-get / dpkg包管理方式,其实Redhat的YUM也是在模仿Debian的APT方式,但在二进制文件发行方式中,APT应该是最好的了。Debian的资 料也很丰富,有很多支持的社区,有问题求教也有地方可去:)
3)Ubuntu严格来说不能算一个独立的发行版本,Ubuntu是基于Debian的unstable版本加强而来,可以这么说,Ubuntu就是 一个拥有Debian所有的优点,以及自己所加强的优点的近乎完美的 Linux桌面系统。根据选择的桌面系统不同,有三个版本可供选择,基于Gnome的Ubuntu,基于KDE的Kubuntu以及基于Xfc的 Xubuntu。特点是界面非常友好,容易上手,对硬件的支持非常全面,是最适合做桌面系统的Linux发行版本。
POSIX标准
POSIX:可移植操作系统接口(英语:Portable Operating System Interface,缩写为POSIX),是IEEE为要在各种UNIX操作系统上运行的软件,而定义API的一系列互相关联的标准的总称,其正式称呼为IEEE 1003,而国际标准名称为ISO/IEC 9945。它基本上是Portable Operating System Interface(可移植操作系统接口)的缩写,而X则表明其对Unix API的传承。
此标准源于一个大约开始于1985年的项目,POSIX这个名称是由理查德•斯托曼应IEEE的要求而提议的一个易于记忆的名称。
这个标准并不是一个强制性或者大家都在使用的标准:
- Linux基本上逐步实现了POSIX兼容,但并没有参加正式的POSIX认证
- 微软的Windows NT声称部分实现了POSIX标准。
linux和posix的关系:
linux一些函数的功能与posix标准的一些函数(接口)功能相同,只是签名不同,你可以认为只是改了个名字。如果你使用posix标准的函数,那么你为其它可以使用posix标准的系统写代码,就不用重新修改原来的函数签名,而只需要重新编译(因为实现的代码是不同的)一遍就行了。
GNU和Linux的关系
UNIX操作系统最初是由贝尔实验室开发的,当时的贝尔实验室是电信业巨头AT&T(美国电报电话公司)旗下的一员。在20世纪70年代,unix成为一种非常流行的多用户、多任务操作系统。Unix 系统被发明之后,大家用的很爽,但是后来开始收费和商业闭源了。。。
理查德 · 斯托曼 在 1983年发起GNU计划,其目标是建立完全自由的操作系统GNU,取代Unix。在1985年创建自由软件基金会(FSF),在1989年发布GPL许可协议保护和传播由FSF发布的自由软件。自由软件是权利问题,不是价格问题。要理解这个概念,你应该考虑“free”是“言论自由(free speech)”中的“自由”;而不是“免费啤酒(free beer)”中的“免费”。
GNU(“GNU’s Not Unix”的递归首字母缩写词)是一个类Unix操作系统,它是由多个应用程序、系统库、开发工具乃至游戏构成的程序集合。GNU的开发始于1984年1月,称为GNU工程,GNU的许多程序在GNU工程下发布,我们称之为GNU软件包。主要由:
- GCC:GNU编译器集,它包括GNU C编译器。
- G++:C++编译器,是GCC的一部分。
- GDB:源代码级的调试器。
- GNU make:UNIX make命令的免费版本。
- Bison:与UNIX yacc兼容的语法分析程序生成器。
- bash:命令解释器(shell)。
- GNU Emacs:文本编辑器及环境。
许多其他的软件包也是在遵守自由软件的原则和GPL条款的情况下开发和发行的,包括电子表格、源代码控制工具、编译器和解释器、因特网工具、图形图像处理工具(如Gimp),以及两个完整的基于对象的环境(GNOME和KDE)。有了这么多可用的自由软件,再加上Linux内核,我们可以说:创建一个GNU的、自由的类UNIX系统的目标已经实现了。(GNU早起也有自己的内核,后面选用了Linux)
众所周知,一个完整的通用操作系统至少需要内核、编译套件、shell以及主要应用软件。GUN最初的内核组件Hurd开发于1990年(早于linux),但设计过于复杂进展缓慢。正巧,1991年10月林纳斯·托瓦兹(Linus Torvalds)发布了他的玩具内核源代码,这是他在学习Minix操作系统源码的过程中耗时六个月,用C写出来的POSIX不完整兼容的内核,并将GNU的基础软件Gcc和Bash成功的移植到了上面,这之后大量用户参与开发,并在1994年使用GPL协议发布了Linux 1.0内核。
从此,GNU计划和Linux天衣无缝的、互相弥补的就结合在了一起,成为了完全自由并且完整的操作系统——GNU/Linux。RedHat等以GNU/Linux作为产业的大厂随即出现,大力发展了GNU/Linux,使其变得越来越实用,逐渐取代了Unix操作系统的位置。
Linux-4.12内核源码目录
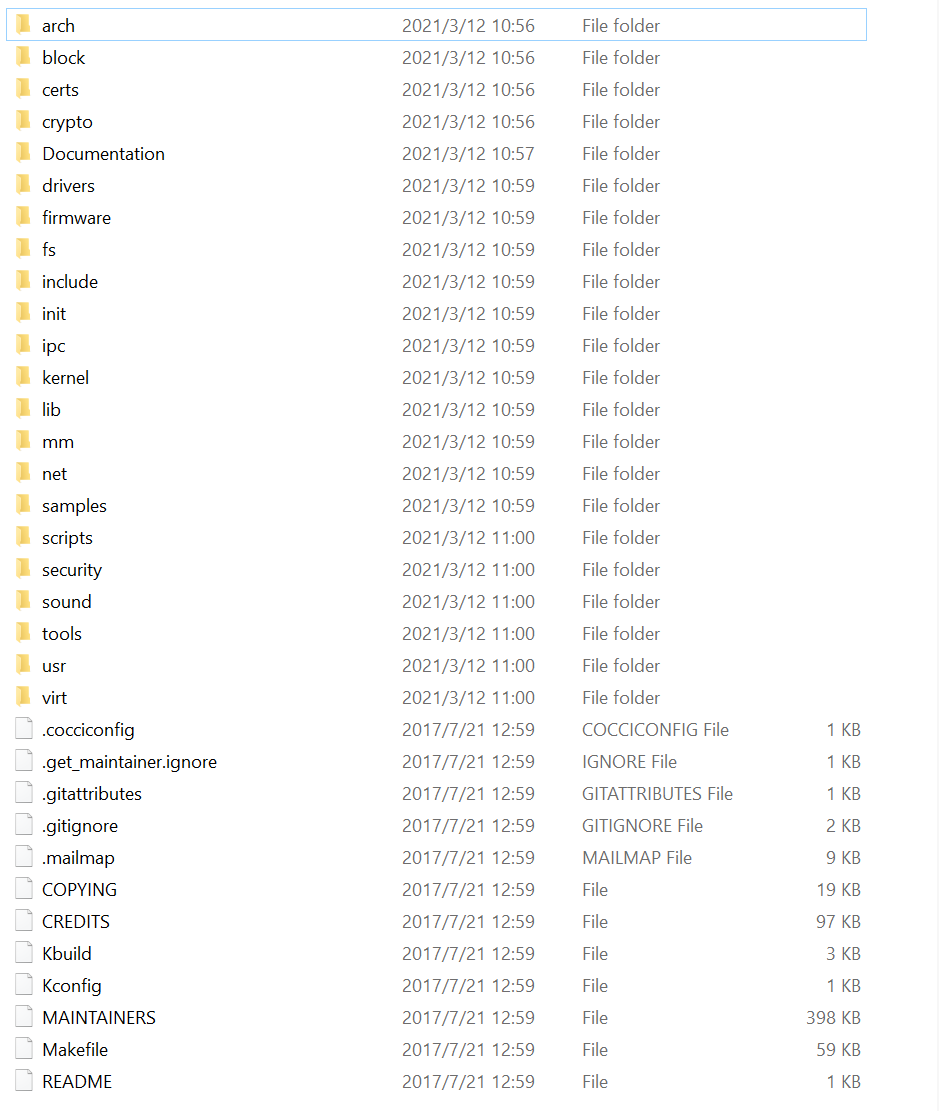
| 目录 | 开发关注度 | 描述 | 存放功能 |
|---|---|---|---|
| arch | 5⭐ | 即architecture,意为架构的意思, 常见的一些架构有mips、x86、arm。 适配一款芯片的linux内核,首先需要知道芯片属于什么架构 | dts、内存管理,系统调用,动态调频,主频率设置、库文件等 |
| block | 4⭐ | block,意为块,与块设备相关的功能,如SD卡、iNand、Nand、硬盘等块设备相关的操作 | 块设备相关代码 |
| certs | 即certificates,意为签名认证,与签名认证相关功能 | 认证签名相关代码 | |
| crypto | 4⭐ | 可以记为encryption,与压缩加密相关的功能,如md5、sha1、 hash等 | 各类加密算法相关的功能代码 |
| Documentation | 5⭐ | linux内核各类机制相关的文档,全英文,可以查阅各类机制的实现说明 | 官方文档 |
| drivers | 5⭐ | 即驱动,linux的驱动代码, 如GPIO、网络、usb、蓝牙等驱动源码,一般做开发都需要修改或添加该目录下的文件 | 驱动源码相关 |
| frimware | 3⭐ | 存放一些固件代码(.bin) | |
| fs | 4⭐ | 即files system, linux的文件系统, 如ext2-4、jffs2、nfs、squashfs、ramfs、romfs等文件系统的实现代码 | 文件系统相关源码 |
| include | 5⭐ | linux库文件的头文件,如fs.h、mdio.h、mm.h等, include/linux存放与平台无关的功能的头文件 | linux内核功能相关的头文件 |
| init | 5⭐ | 即initialization ,初始化相关源码,main.c也在其中 | linux初始化相关 |
| ipc | 4⭐ | 即Inter-Process Communication,进程间通信, 如共享内存、信号量、消息队列等 | 进程间通信相关代码 |
| kernel | 5⭐ | 即内核,linux内核相关的功能实现源码,如panic、pid、module、irq、cpu相关 | 内核功能源码 |
| lib | 4⭐ | 即library, 实现一些库功能,如decompress、crc32、atomic等 | 库功能实现源码 |
| mm | 5⭐ | 即memory management,内存管理相关功能实现 ,mmap、page、mempool等 | 内存管理相关源码 |
| net | 5⭐ | network, 网络功能相关的源码,如tcp/ip、dns、ipv4/v6、802.11、ethernet等 | 网络协议功能 |
| samples | 3⭐ | 一些linux功能代码使用的标准实例 示例参考代码 | |
| scripts | 3⭐ | 与内核无关的脚本代码,如内核编译相关、menuconfig相关 | 内核无关的脚本 |
| security | 2⭐ | SELinux的模块。安全相关 | 安全相关代码,具体未知 |
| sound | 3⭐ | 声卡与声音驱动相关代码,包含i2c、spi、usb等接口 | 音频功能实现代码 |
| tools | 3⭐ | 与c编译、链接生成一个完整内核镜像相关的工具 | 编译相关 |
| usr | 3⭐ | 用户打包和压缩内核实现代码 | |
| virt | 3⭐ | 虚拟化相关的代码,允许搭建虚拟机环境,运行多个系统 | 虚拟化相关代码实现 |
| 文件 | 描述 |
|---|---|
| COPYING | 许可授权信息 |
| CREDITS | 贡献者相关信息列表 |
| Kbuild | 内核设定的脚本 |
| Kconfig | 内核开发人员配置内核用到的配置 |
| makefile | 编译内核的makefile文件 |
| MAINTAINERS | 维护内核者的相关信息 |
Linux内核进程
一、进程原理
1、进程
Linux内核把进程称为任务(task),进程的虚拟地址空间分为用户虚拟地址空间和内核虚拟地址空间,所有进程共享内核虚拟地址空间,每个进程有独立的用户空间虚拟地址空间。
进程有两种特殊形式:没有用户虚拟地址空间的进程称为内核线程,共享用户虚拟地址空间的进程称为用户线程。通用在不会引起混淆的情况下把用户线程简称为线程。共享同一个用户虚拟地址空间的所有用户线程组成一个线程组。
C标准库的进程专业术语和Linux内核的进程专业术语对应关系如下:
| C标准库的进程专业术语 | Linux内核的进程专业术语 |
|---|---|
| 包含多个线程的进程 | 线程组 |
| 只有一个线程的进程 | 进程或任务 |
| 线程 | 共享用户虚拟地址空间的进程 |
2、Linux进程四要素
- 有一段程序供其执行。
- 有进程专用的系统堆栈空间。
- 在内核有task_struct数据结构;
- 有独立的存储空间,拥有专有的用户空间。
如果只具备前三条而缺少第四条,则称为“线程”。如果完全没有用户空间,就称为“内核线程”;而如果共享用户空间映射就称为“用户线程”。内核为每个进程分配一个task_struct结构时。实际分配两个连续物理页面(8192字节),数据结构task_struct的大小约占1kb字节左右,进程的系统空间堆栈的大小约为7kb字节(不能扩展,是静态确定的)。
3、进程描述符task_struct数据结构内核源码,其主要核心成员如下
struct task_struct {
...
volatile long state; //进程的状态
void *stack; //指向内核栈
...
pid_t pid; //全局进程号
pid_t tgid; //全局线程组的标识符
...
struct pid_link pids[PIDTYPE_MAX]; //进程号,进程组标识符和会话标识符
...
struct task_struct __rcu *real_parent; //指向真实父进程
struct task_struct __rcu *parent; //指向父进程,如果进程被另一个进程使用系统调用ptrace,那么父进程跟踪进程,否则和real_parent相同
...
struct task_struct *group_leader; //指向线程组的组长
...
char comm[TASK_COMM_LEN]; //进程名称
...
// 调度策略和优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
...
cpumask_t cpus_allowed; //允许进程在哪些处理器上运行
...
// 指向内存描述符
// 进程:mm和active_mm指向同一个内存描述符
// 内核线程:mm是空指针,当内核线程运行时,active_mm指向从进程借用的内存描述符
struct mm_struct *mm;
struct mm_struct *active_mm;
...
/* Filesystem information: */
struct fs_struct *fs; //文件系统信息,主要是进程的根目录和当前工作目录
/* Open file information: */
struct files_struct *files; //打开文件表
/* Namespaces: */
struct nsproxy *nsproxy; //命名空间
...
//信号处理
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
struct sigpending pending;
...
}
4、创建新进程
在Linux内核中,新进程是从一个已经存在的进程复制出来的,内核使用静态数据结构造出0号内核线程,0号内核线程分叉生成1号内核线程和2号内核线程(kthreadd线程)。1号内核线程完成初始化以后装载用户程序,变成1号进程,其他进程都是1号进程或者它的子孙进程分叉生成的;其他内核线程是kthreadd线程分叉生成的。
3个系统调用可以用来创建新的进程:
- fork(分叉):子进程是父进程的一个副本,采用定时复制技术。
- vfor:用于创建子进程,之后子进程立即调用execve以装载新程序的情况,为了避免复制物理页,父进程会睡眠等待子进程装载新程序。现在fork采用了定时复制技术,vfork失去了速度优势,已经被废弃。
- clone(克隆):可以精确地控制子进程和父进程共享哪些资源。 这个系统调用的主要用处是可供pthread库用来创建线程。clone是功能最齐全的函数,参数多使用复杂,fork是clone的简化函数。
Linux内核定义系统调用的独特方式,目前以系统调用fork为例: 系统调用的函数名称以"sys_"开头,创建新进程的3个系统调用在文件"kernel/fork.c"中,它们把工作委托给函数__do_fork。
long _do_fork(unsigned long clone_flags, //克隆标志
unsigned long stack_start, //只有我们在创建线程时有意义,用来指定线程的用户栈起始地址
unsigned long stack_size, //只有我们在创建线程时有意义,用来指定线程的用户栈的长度
int __user *parent_tidptr, //只有我们在创建线程时有意义,如果clone_flags参数指定标志位CLONE_PARENT_SETID
int __user *child_tidptr, //只有我们在创建线程时有意义,存放新线程保存自己的进程标识符的位置,如果参数clone_flags指定标识符CLONE_CHILD_CLEARTID/CLONE_CHILD_SETID
unsigned long tls //只有我们在创建线程时有意义,如果clone_flags参数指定标志位CLONE_SETTLS,那么参数tls指定新线程的线程本地存储的地址
)
{
...
//相关性验证
...
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
...
}
Linux内核函数_do_fork()执行流程如下图所示: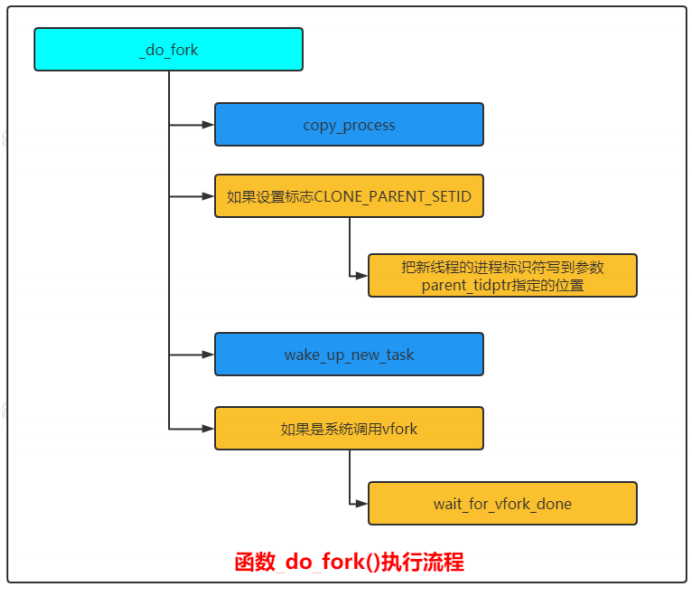
函数copy_process()内核源码如下:
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
...
/// 状态检查 ///
// 同时设置 CLONE_NEWNS/CLONE_FS, 即新进程属于新的挂载命名空间,同时和当前进程共享文件系统信息
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
// 同时设置 CLONE_NEWUSER/CLONE_FS, 即新进程属于新的用户命名空间,同时和当前进程共享文件系统信息
if ((clone_flags & (CLONE_NEWUSER|CLONE_FS)) == (CLONE_NEWUSER|CLONE_FS))
return ERR_PTR(-EINVAL);
// 即新进程和当前进程属于同一个线程组, 但是不共享信号处理程序
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
// 即新进程和当前进程共享信号处理程序, 但是不共享虚拟内存
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
...
/// dup_task_struct ///
//同一个线程组的所有线程必须属于相同的用户命名空间和进程号命名空间
p = dup_task_struct(current, node);
...
/// 检查用户创建的进程数量是否超过限制 ///
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
...
/// cpoy_creds ///
//设置权限
retval = copy_creds(p, clone_flags);
...
/// 检查线程数量是否超过限制 ///
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
...
/// 初始化task_struct ///
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
...
/// sched_fork ///
//kernel/sched/core.c
void __sched_fork(unsigned long clone_flags, struct task_struct *p) //为新进程设置调度器相关的参数
...
/// 设置或共享资源 ///
...
retval = copy_semundo(clone_flags, p); //只有属于同一个线程组的线程之间才会共享UNIX系统5个信号量
if (retval)
goto bad_fork_cleanup_security;
retval = copy_files(clone_flags, p); //打开文件表,只有属于同一个线程组的线程之间才会共享打开文件表
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p); //文件系统信息,进程的文件系统信息包括:根目录,当前工作目录,文件模式创建掩码,只有属于同一个线程组的线程之间才会共享文件系统信息
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p); // 信号处理, 只有属于同一个线程组的线程之间才会共享信号处理程序
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p); //信号结构体, 只有属于同一个线程组的线程之间才会共享信号结构体
if (retval)
goto bad_fork_cleanup_sighand;
retval = copy_mm(clone_flags, p); //虚拟内存, 只有属于同一个线程组的线程之间才会共享虚拟内存
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p); //创建或共享命名空间
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p); //创建或共享IO上下文
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread_tls(clone_flags, stack_start, stack_size, p, tls); //复制寄存器值并且修改一部分寄存器值,不同处理器架构的寄存器不同,所以各种处理器架构需要自己定义结构体pt_regs和thread_struct,实现函数copy_thread_tls
if (retval)
goto bad_fork_cleanup_io;
/// 设置进程号和进程关系等等 ///
if (pid != &init_struct_pid) {
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (IS_ERR(pid)) {
retval = PTR_ERR(pid);
goto bad_fork_cleanup_thread;
}
}
...
}
函数copy_process():创建新进程的主要工作由此函数完成,具体处理流程如下图所示: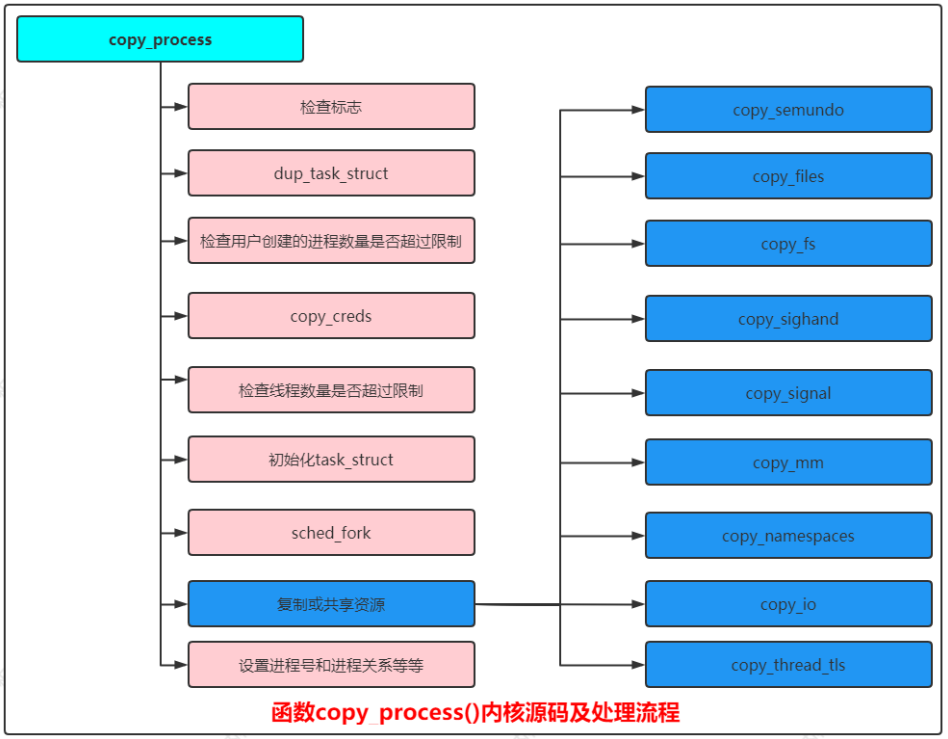
二、进程状态迁移
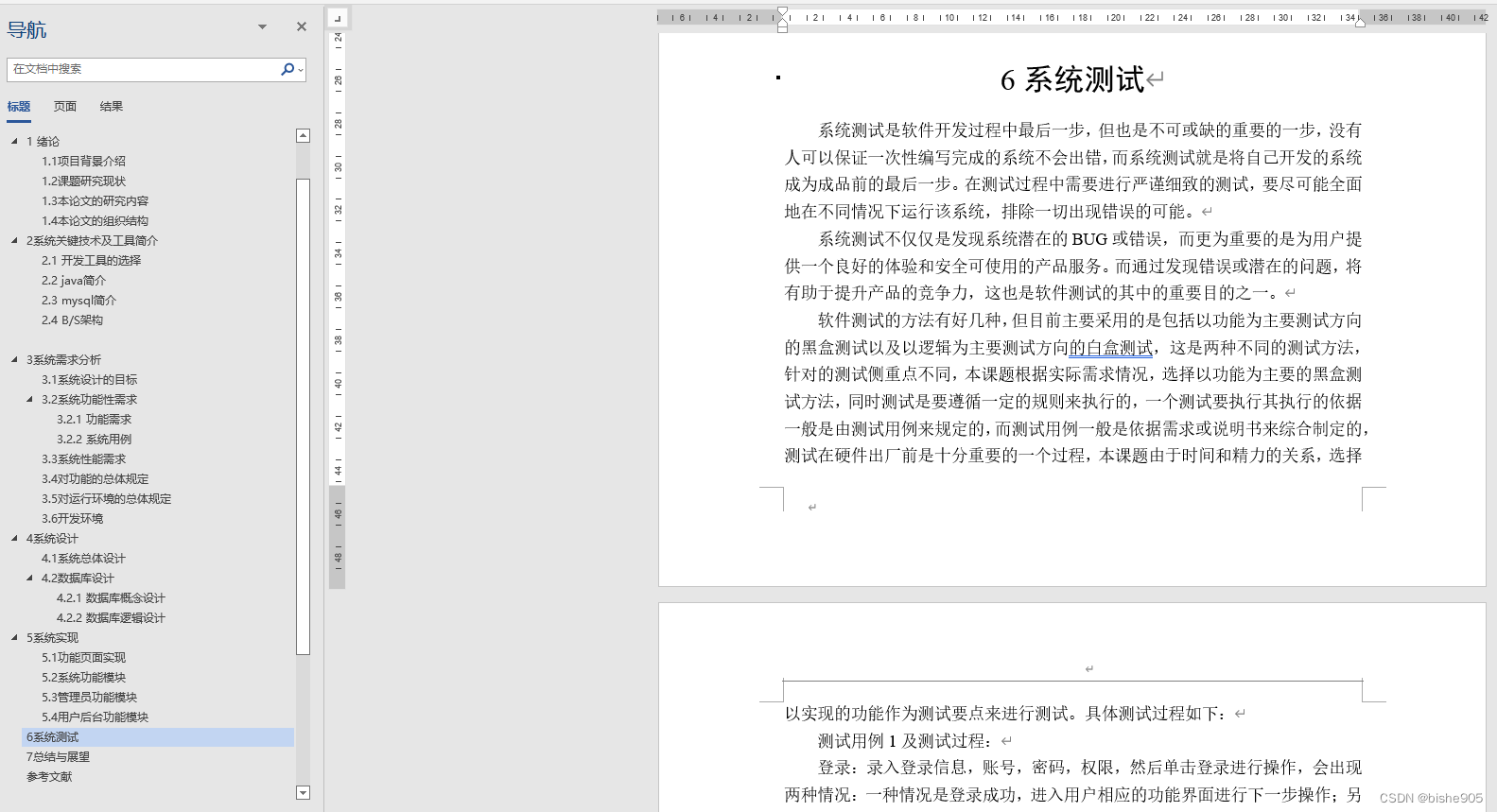
进程主要有7种状态:就绪状态、运行状态、轻度睡眠、中度睡眠、深度睡 眠、僵尸状态、死亡状态,它们之间状态变迁如下:

struct task_struct {
...
volatile long state; //进程的状态
...
}
/* Used in tsk->state: */
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* Used in tsk->exit_state: */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->state again: */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_NOLOAD 1024
#define TASK_NEW 2048
#define TASK_STATE_MAX 4096
#define TASK_STATE_TO_CHAR_STR "RSDTtXZxKWPNn"
/* Convenience macros for the sake of set_current_state: */
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
#define TASK_IDLE (TASK_UNINTERRUPTIBLE | TASK_NOLOAD)
/* Convenience macros for the sake of wake_up(): */
#define TASK_NORMAL (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE)
#define TASK_ALL (TASK_NORMAL | __TASK_STOPPED | __TASK_TRACED)
/* get_task_state(): */
#define TASK_REPORT (TASK_RUNNING | TASK_INTERRUPTIBLE | \
TASK_UNINTERRUPTIBLE | __TASK_STOPPED | \
__TASK_TRACED | EXIT_ZOMBIE | EXIT_DEAD)
#define task_is_traced(task) ((task->state & __TASK_TRACED) != 0)
#define task_is_stopped(task) ((task->state & __TASK_STOPPED) != 0)
#define task_is_stopped_or_traced(task) ((task->state & (__TASK_STOPPED | __TASK_TRACED)) != 0)
#define task_contributes_to_load(task) ((task->state & TASK_UNINTERRUPTIBLE) != 0 && \
(task->flags & PF_FROZEN) == 0 && \
(task->state & TASK_NOLOAD) == 0)
三、调度策略及优先级
1、Linux内核支持调度策略
- 先进先出调度(SCHED_FIFO)、轮流调度(SCHED_RR)、限期调度策略(SCHED_DEADLINE)采用不同的调度策略调度实时进程。
- 普通进程支持两种调度策略:标准轮流分时(SCHED_NORMAL)和SCHED_BATCH调度普通的非实时进程。
- 空闲(SCHED_IDLE)则在系统空闲时调用idle进程。
先进先出调度(SCHED_FIFO):没有时间片,如果没有更高优先级的实时进程,并且它不睡眠,那么它会一直占用处理器。
轮流调度(SCHED_RR):有时间片,进程用完时间片以后加入优先级对应运行队列的尾部,把处理器给优先级相同的其他实时进程。
标准轮流分时策略调度(SCHED_NORMAL):使用完全公平调度算法,把处理器时间公平分配给每个进程。
空闲策略调度(SCHED_IDLE):用来执行优先级非常低的后台作业,优先级比使用标准轮流分时策略(SCHED_NORMAL)和相对优先级为19的普通进程(SCHED_BATCH)还要低,进程的相对优先级空闲调度策略没有影响。
2、进程优先级
限期进程的优先级比实时进程高,实时进程的优先级比普通进程高。
- 限制进程的优先级是-1。
- 实时进程的褚优先级是1-99,优先级数值越大,表示优先级越高。
- 普通进程 的静态优先级是100-139,优先级值越小,表示优先级越高,可通过修改nice值改变普通进程 的优先级,优先级等于120加上nice值。
在task_struct结构体中,4个成员和优先级有关如下: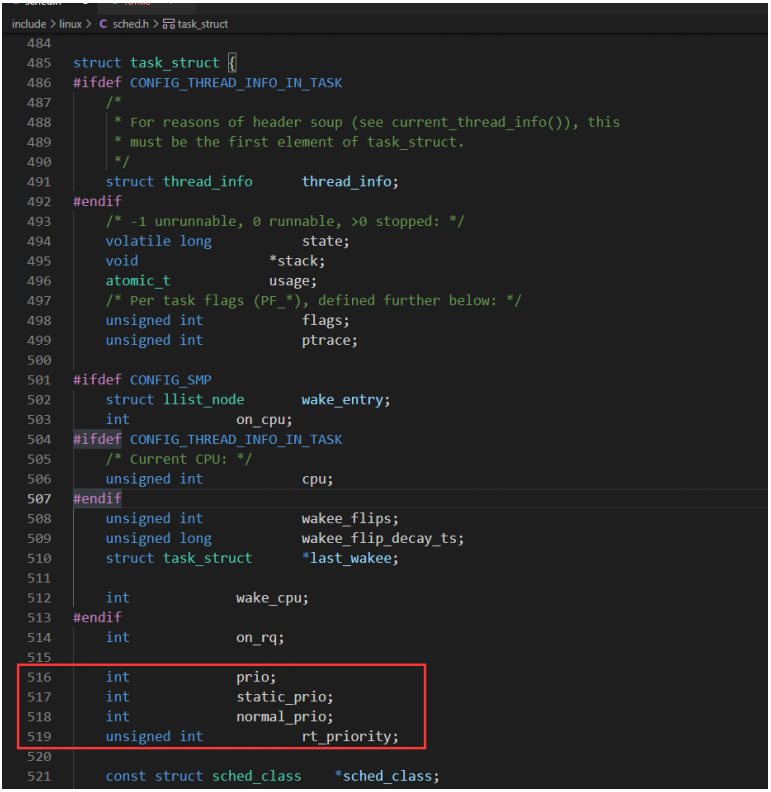
| 优先级 | 限期进程 | 实时进程 | 普通进程 |
|---|---|---|---|
| prio调度优先级(数值越小,表示优先级越高) | 大多数情况下prio等于normal_prio 特殊情况:如果进程a占有实时互斥锁,进程b正在等待锁,进程b的优先级比较进程a的优先级高,那么把进程a的优先级临时提高到进程b的优先级,即进程a的prio值等于进程b的prio值 | ||
| static_prio静态优先级 | 没意义,为0 | 没意义,为0 | 120+nice值,数值越小,表示优先级越高 |
| normal_prio正常优先级(数值越小,表示优先级越高) | -1 | 99-rt_priority | static_prio |
| rt_priority实时优先级 | 没意义,为0 | 实时进程的优先级,范围是1-99,数值越大,表示优先级越高 | 没意义,为0 |
如果优先级低的进程占有实时互斥锁,优先级高的进程等待实时互斥锁,将把占有实时互斥锁的进程的优先级临时提高到等待实时互斥锁的进程的优先级,称为优先级继承。
四、写时复制
写时复制核心思想:只有在不得不复制数据内容时才去复制数据内容。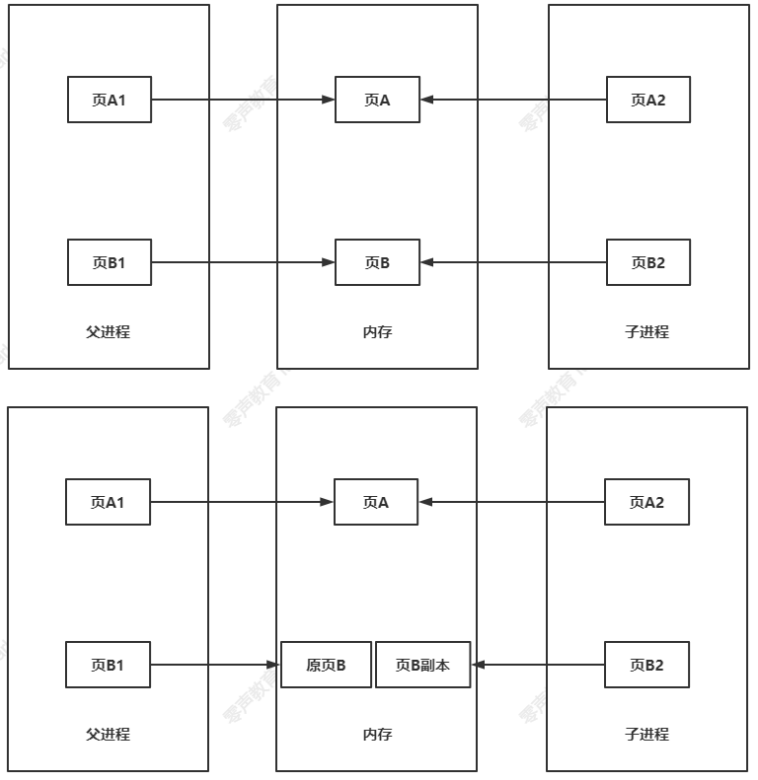
Linux调度机制
一、调度器
1、核心调度器
调度器的实现基于两个函数:周期性调度器函数和主调度器函数。这些函数根据现有进程的优先级分配CPU时间。这也是为什么整个方法称之为优先调度的原因。
a.主调度器函数
在内核中的许多地方,如果要将CPU分配给与当前活动进程不同的另一个进程,都会直接调用主调度器函数 (schedule)。
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
EXPORT_SYMBOL(schedule);
主调度器负责将CPU的使用权从一个进程切换到另一个进程。周期性调度器只是定时更新调度相关的统计信息。 cfs队列实际上是用红黑树组织的,rt队列是用链表组织的。
b.周期性调度器函数
周期性调度器在scheduler_tick中实现,如果系统正在活动中,内核会按照频率HZ自动调用该函数。该函数主要有两个任务如下:
(1) 更新相关统计量:管理内核中与整个系统和各个进程的调度相关的统计量。其间执行的主要操作是对各
种计数器加1。
(2) 激活负责当前进程的调度类的周期性调度方法。
void scheduler_tick(void)
{
// 获取当前CPU上的全局就绪队列rq和当前运行的进程curr
// 在SMP的情况下, 获得当前CPU的ID, 如果不是SMP, 那么返回0
int cpu = smp_processor_id();
// 获得CPU的全局就绪队列rq, 每个CPU都有一个就绪队列rq
struct rq *rq = cpu_rq(cpu);
// 获取就绪队列上正在运行的进程curr
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
// 更新rq当前时间戳, 即使rq->clock变为当前时间戳
// 处理就绪队列时钟的更新, 本质上就是增加struct rq当前实例的时钟时间戳
update_rq_clock(rq);
// 由于调度器的模块化结构, 主要工作可以完全由特定调度器类方法实现。task_tick实现模式取决底层的调度器类
// 执行当前运行进程所在调度类的task_tick函数进行周期性调度
curr->sched_class->task_tick(rq, curr, 0);
// 将当前负荷加入数组的第一个位置
cpu_load_update_active(rq);
// 更新全局CPU就绪队列的calc_global_update, 更新CPU的活动计数, 主要是更新全局CPU就绪队列calc_global_update
calc_global_load_tick(rq);
// 解锁
rq_unlock(rq, &rf);
// 与perf计数事件有关
perf_event_task_tick();
#ifdef CONFIG_SMP
// 判断CPU是否为空闲状态
rq->idle_balance = idle_cpu(cpu);
// 如果进程周期性负载平衡, 则触发SCHED_SOFTIRQ
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}
更新统计量函数:update_rq_clock()/calc_global_load_tick()
<update_rq_clock函数>
// 处理就绪队列时钟的更新, 本质上就是增加struct rq当前实例的时钟时间戳
void update_rq_clock(struct rq *rq)
{
s64 delta;
lockdep_assert_held(&rq->lock);
if (rq->clock_update_flags & RQCF_ACT_SKIP)
return;
#ifdef CONFIG_SCHED_DEBUG
if (sched_feat(WARN_DOUBLE_CLOCK))
SCHED_WARN_ON(rq->clock_update_flags & RQCF_UPDATED);
rq->clock_update_flags |= RQCF_UPDATED;
#endif
delta = sched_clock_cpu(cpu_of(rq)) - rq->clock;
if (delta < 0)
return;
rq->clock += delta;
update_rq_clock_task(rq, delta);
}
<calc_global_load_tick函数>
// 更新全局CPU就绪队列的calc_global_update, 更新CPU的活动计数, 主要是更新全局CPU就绪队列calc_global_update
void calc_global_load_tick(struct rq *this_rq)
{
long delta;
if (time_before(jiffies, this_rq->calc_load_update))
return;
delta = calc_load_fold_active(this_rq, 0);
if (delta)
atomic_long_add(delta, &calc_load_tasks);
this_rq->calc_load_update += LOAD_FREQ;
}
2、调度类及运行队列
a.调度类
为方便添加新的调度策略,Linux内核抽象一个调度类sched_class,目前为止实现5种调度类:
停机调度类(stop_sched_class):支持期限调度类,迁移线程的优先级必须比期限进程的优先级高,能够抢占所有其他进程,才能够快速处理调度器发出的迁移移求,把进程从当前处理器迁移到其他处理器。
期限调度类(dl_sched_class):使用优先算法(使用红黑树)把进程按照绝对截至期限从小到大排序,每次调度时选择绝对截至期限最小的进程。
实时调度类(rt_sched_class):为每个调度优先级维护一个队列,源码如下
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */ //包含一个作为分割符的位
struct list_head queue[MAX_RT_PRIO];
};
位图bitmap用来快速查找第一个非空队列,队列queue的下标是实时进程的调度优先级,下标越小,优先级越高。即每次调度,先找到优先级最高的非空队列(bitmap),然后从队列当中选择第一个进程。
SCHED_FIFO:进程执行时无时间片,如果没有更高优先级,那么会一直执行直到结束。
SCHED_RR:进程执行时有时间片。
公平调度类(fair_sched_class):使用完全公平调度算法,引入虚拟运行时间。
虚拟运行时间=实际运行时间*nice 0对应的权重/进程的权重
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
//nice 0 对应权重是1024
//nice n-1 的权重大概是nice n 权重的1.2倍左右
空闲调度类(idle_sched_class):每个处理器有一个空闲线程,即0号线程。空闲调度类的优先级最低,仅当没有其他进程可以调度的时候,才会执行调度空闲线程。
调度类优先级:stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_sched_class。
调度类选择下一个进程:
停机调度类:pick_next_task_stop
限期调度类:pick_next_task_dl
实时调度类:pick_next_task_rt
公平调度类:pick_next_task_fair
b.运行队列
每个处理器有一个运行队列,结构体是rq,定义的全局变量如下:
rq是描述就绪队列,其设计是为每一个CPU就绪队列,本地进程在本地队列上排序
struct rq中嵌入公平运行队列cfs,实时运行队列rt,限期运行队列dl,停机调度类和空闲调度类在每个处理器上只有一个内核线程,不需要运行队列,直接定义成员stop/idle分别指向迁移线程的空闲线程。
3、调度进程
主动调度进程的函数是schedule() ,它会把主要工作委托给__schedule()去处理。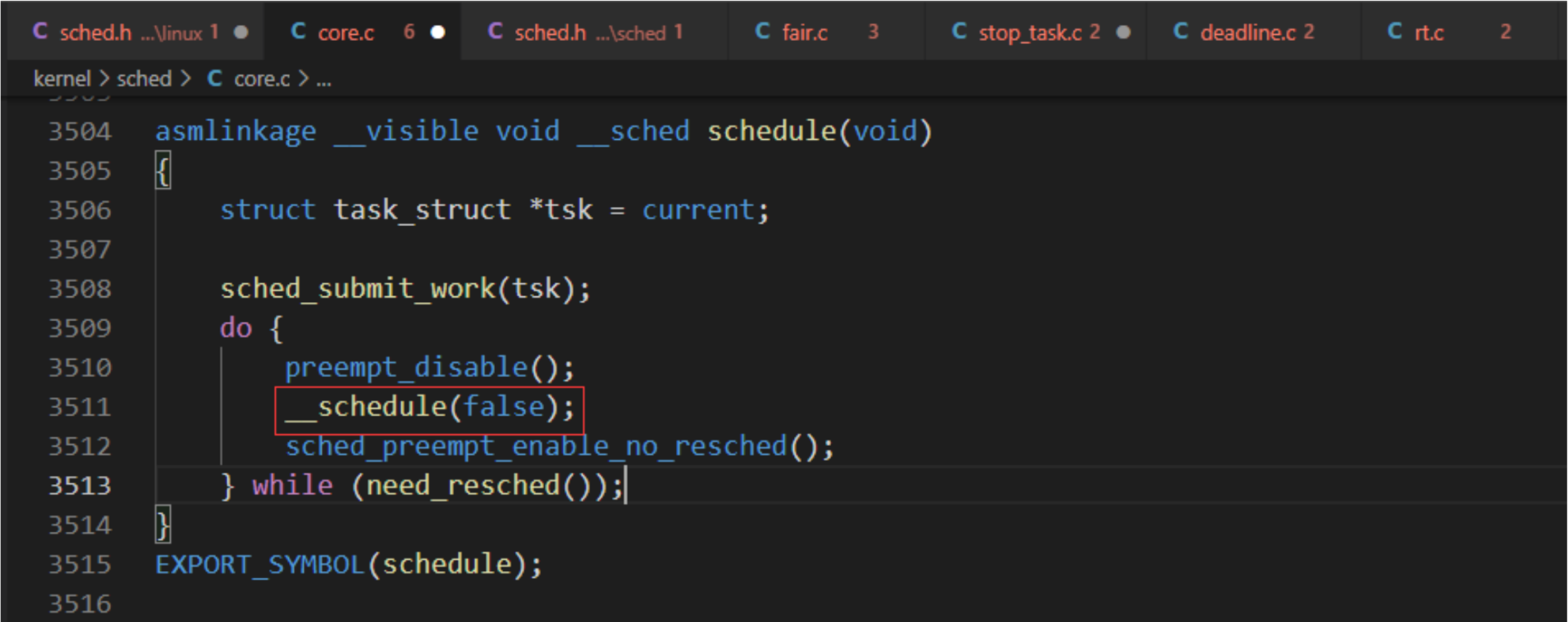
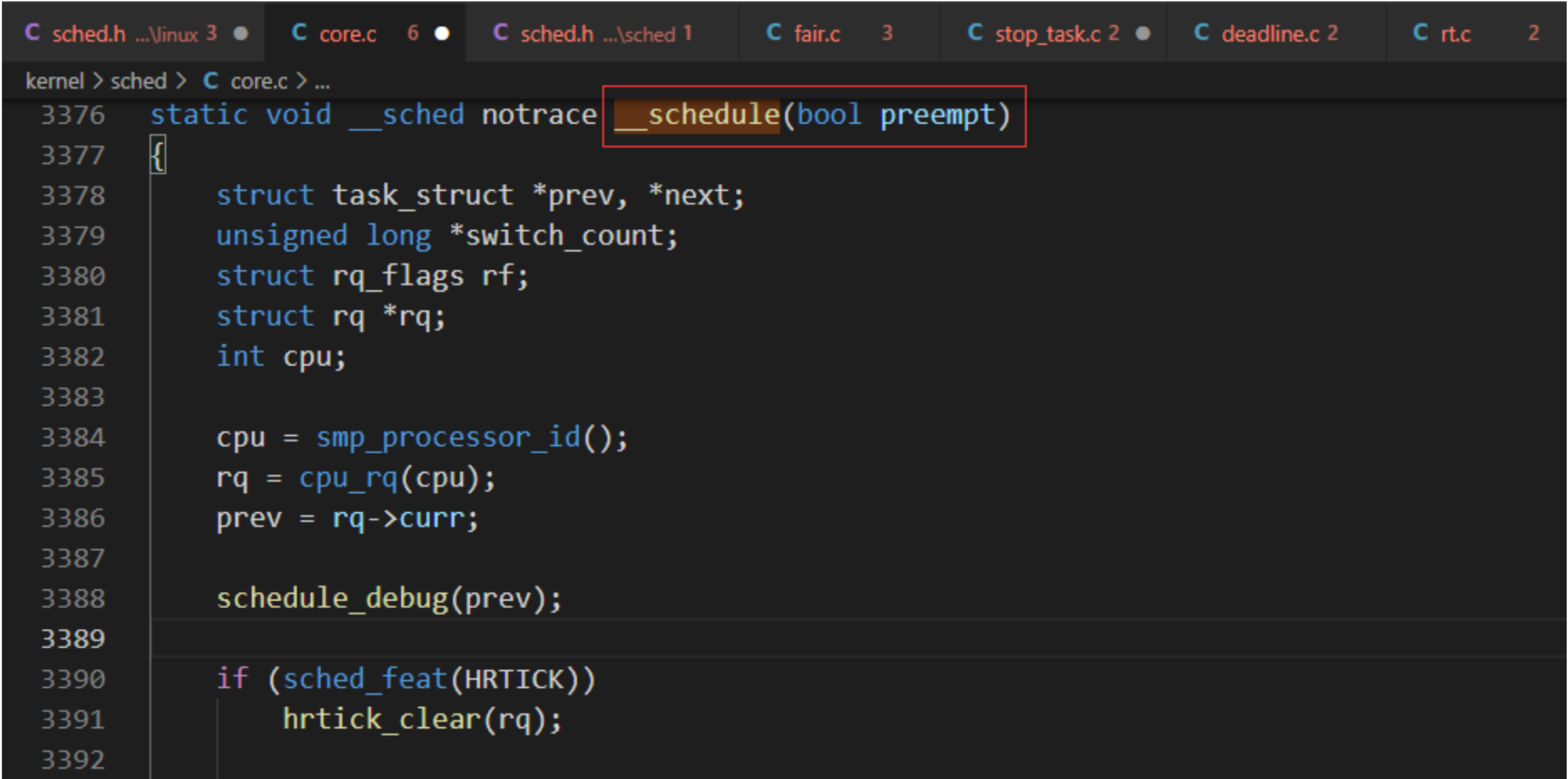
函数参数preempt表示是否抢占调度
- true:表示抢占调度, 强制剥夺当前进程对处理器的使用权。
- false:表示主动调度, 当前进程主动让出处理器。
函数__shcedule的主要处理过程如下:
- 调用pick_next_task()以选择下一个进程。
- 调用context_switch()以切换进程。
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
// 执行进程切换的准备工作
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
// 开始上下文切换, 是每种处理器架构必须定义的函数
arch_start_context_switch(prev);
// 如果下一个进程是内核线程(成员mm是空指针), 内核线程没有用户虚拟地址空间,
if (!mm) {
next->active_mm = oldmm;
mmgrab(oldmm);
// 此函数通知处理器架构不需要切换用户虚拟地址空间, 这种加速进程切换的技术就是tlb
enter_lazy_tlb(oldmm, next);
} else
// 如果下一个进程是用户进程, 那么就调用此函数, 切换进程的用户虚拟地址空间
switch_mm_irqs_off(oldmm, mm, next);
// 如果上一个进程是内核线程, 把成员active_mm置为空指针, 断开它与借用的用户虚拟地址空间的联系, 把它借用的用户虚拟地址空间保存在运行队列的成员prev_mm中。
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
rq_unpin_lock(rq, rf);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
a、切换用户虚拟地址空间,ARM64架构使用默认的switch_mm_irqs_off,其内核源码定义如下:

switch_mm函数内核源码处理如下:
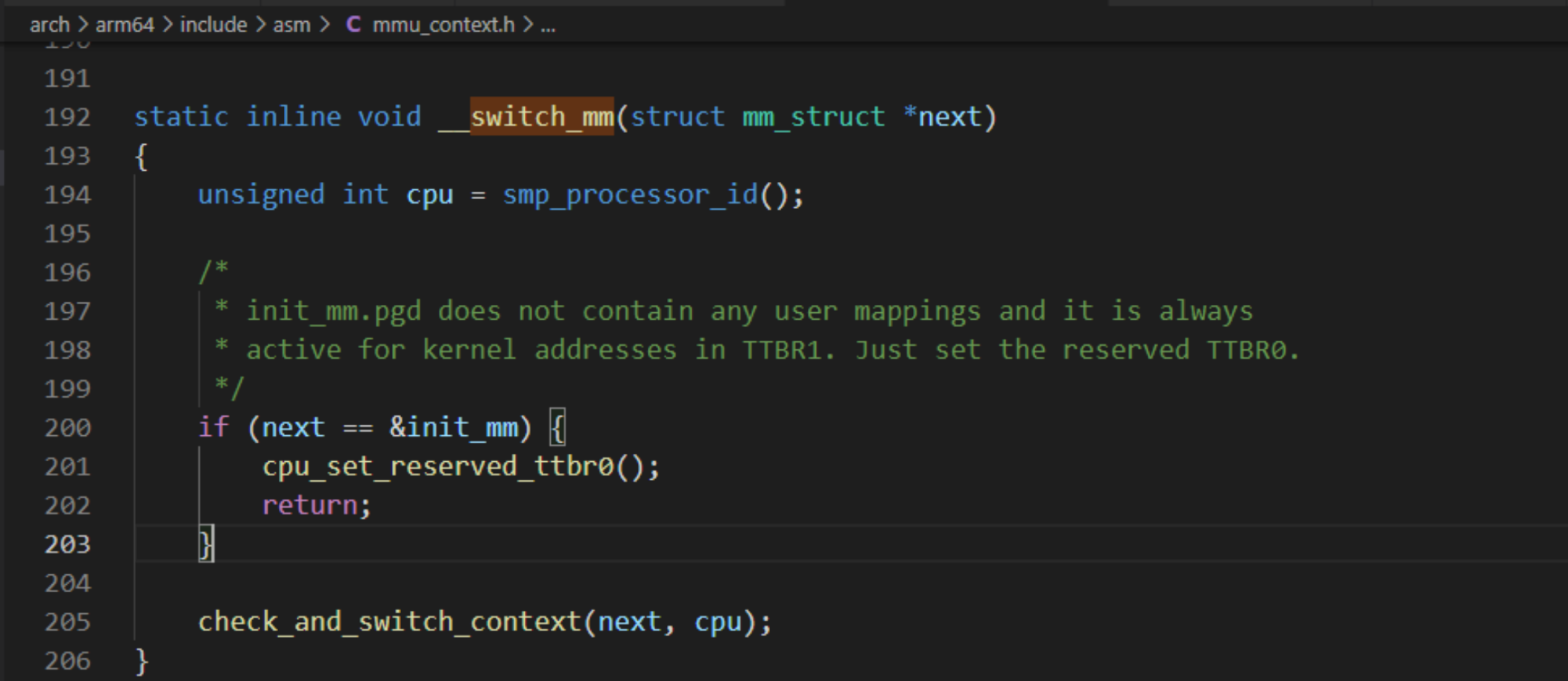
内核态和用户态的切换
内核态:CPU可以访问内存所有的数据,包括外围设备(网卡、硬盘等),CPU也可以将自己从一个程序切换至另一个程序。
用户态:只能受限的访问,并且不允许访问外围设备,占用CPU的能力被剥夺,CPU资源可以被其他程序获取。
b、切换寄存器,宏switch_to把这项工作委托给函数__switch_to:

__notrace_funcgraph struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *next)
{
struct task_struct *last;
fpsimd_thread_switch(next); //切换到浮点寄存器
tls_thread_switch(next); //切换线程本地存储相关的寄存器
hw_breakpoint_thread_switch(next); //切换调试寄存器
contextidr_thread_switch(next); //切换上下文标识符寄存器
entry_task_switch(next); //使用当前处理器每处理器变量记录下一个进程的进程描述符地址
uao_thread_switch(next);
/*
* Complete any pending TLB or cache maintenance on this CPU in case
* the thread migrates to a different CPU.
*/
// 在这个处理器上执行完前面的所有页表缓存或缓存维护操作, 防止线程迁移到其他处理器
dsb(ish);
/* the actual thread switch */
// 实际的线程切换
last = cpu_switch_to(prev, next);
return last;
}
4、调度时机
调度进程的时机如下:
- 进程主动调用schedule()函数。
- 周期性地调度,抢占当前进程,强迫当前进程让出处理器。
- 唤醒进程的时候,被唤醒的进程可能抢占当前进程。
- 创建新进程的时候,新进程可能抢占当前进程。
如果我们编译内核的时候,开启了对内核抢占的支持,那么内核还要增加一些抢占点。
a、主动调度
进程在用户模式下运行的时候,无法直接调用schedule()函数,只能通过系统调用进入内核模式,如果系统调用需要等待某个资源,如互斥锁或信号量,就会把进程的状态设置为睡眠状态,然后调用schedule()函数来调度进程。
进程也可以通过系统调用sched_yield()让出处理器,这种情况下进程不会睡眠。
在内核中有三种主动调度方式:
- 直接调用schedule()函数。
- 调用有条件重调度函数cond_resched()。
- 如果需要等待某个资源(如互斥锁或信号量)
b、周期调度
有些“地痞流氓”进程不主动让出处理器,内核只能依靠周期性的时钟中断夺回处理器的控制权,时钟中断是调度器的脉博。时钟中断处理程序检查当前进程的执行时间有没有超过限额,如果超过限额,设置需要重新调度的标志。当时钟中断处理程序准备返点处理器还给被打断的进程时,如果被打断的进程在用户模式下运行,就检查有没有设置需要重新调度的标志,如果设置了,调用schedule函数以调度进程。
如果需要重新调度,就为当前进程的thread_info结构体的成员flags设置需要重新调度的标志。
二、SMP调度
SMP:是Symmetric Multi Processing的简称,意为对称多处理系统。
SMP内有许多紧耦合多处理器,这种系统的最大特点就是共享所有资源。另外与之相对立的标准是MPP (Massively Parallel Processing),意为大规模并行处理系统,这样的系统是由许多松耦合处理单元组成的,要注意的是这里指的是处理单元而不是处理器。
在SMP系统中,进程调度器必须支持如下:
- 需要使用每个处理器的负载尽可能均衡。
- 可以设置进程的处理器亲和性,即允许进程在哪些处理器上执行。
- 可以把进程从一个处理器迁移到另一个处理器。
1、进程的处理器亲和性
设置进程的处理器亲和性,通俗就是把进程绑定到某些处理器,只允许进程在某些处理器上执行,默认情况是进程可以在所有处理器上执行。应用编程接口和使用cpuset配置具体详解分析。
应用编程进程内核只有两个系统调用:
- sched_setaffinity:设置进程的处理器亲和性掩码
- sched_getaffinity:用来获取进程的处理器亲和性掩码
内核线程可以使用两个函数来设置处理器亲和性和亲和性掩码:
- kthread_bind:用来把一个刚刚创建的内核线程绑定到一个处理器。
- set_cpus_allowed_ptr:用来设置内核线程的处理器亲和性掩码。
2、期限调度类的处理器负载均衡
限期调度类的处理器负载均衡简单,调度选择下一个限期进程的时候,如果当前正在执行的进程是限期进程, 将会试图从限期进程超载的处理器把限期进程搞过来。
限期进程超载定义:
- 限期运行队列至少有两个限期进程。
- 至少有一个限期进程绑定到多个处理器。
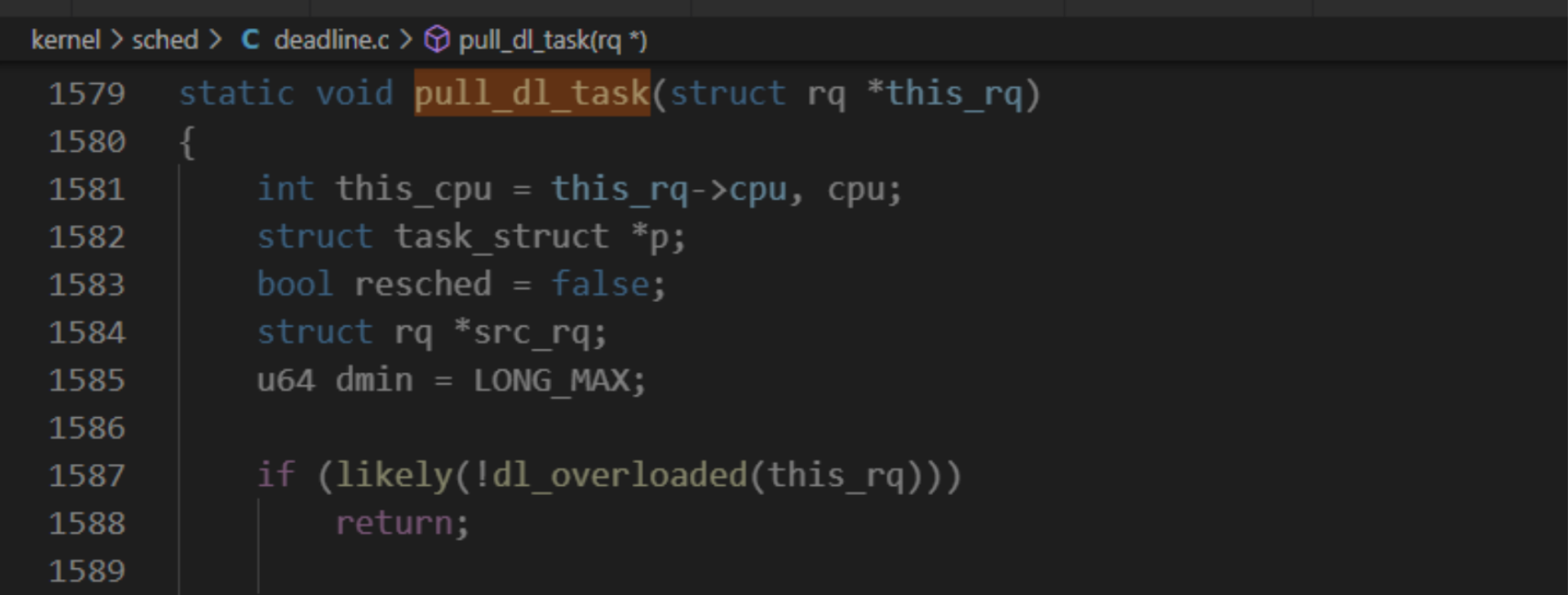
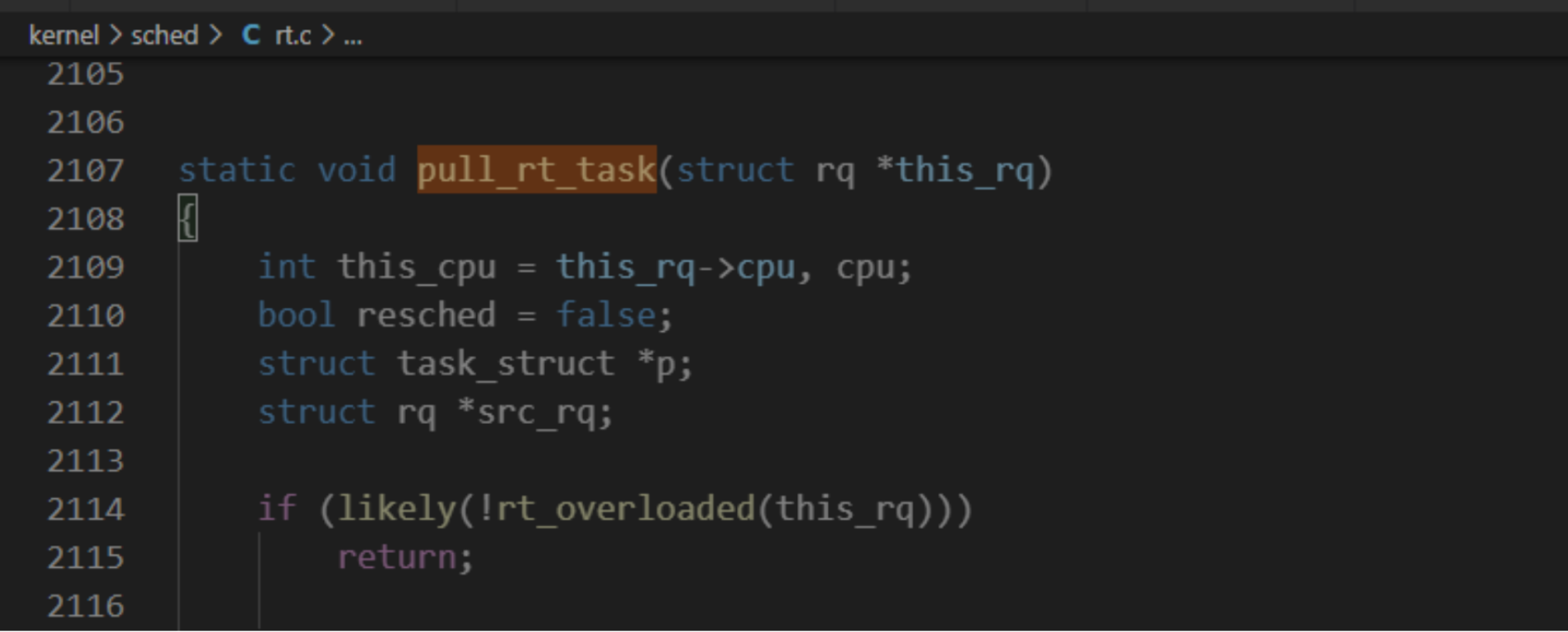
3、实时调度类的处理器负载均衡
实时调度类的处理器负载均衡和限期调度类相似。调度器选择下一个实时进程时,如果当前处理器的实时运行队列中的进程的最高调度优先级比当前正在执行的进程的调度优先级低,将会试图从实时进程超载的处理器把可推送实时进程拉过来。
实时进程超载的定义:
- 实时运行队列至少有两个实时进程。
- 至少有一个可推送实时进程。
4、公平调度类的处理器负载均衡
目前多处理器系统有两种体系结构:NUMA和SMP。
处理器内部的拓扑如下:
a.核(core):一个处理器包含多个核,每个核独立的一级缓存,所有核共享二级缓存。
b.硬件线程:也称为逻辑处理器或者虚拟处理器,一个处理器或者核包含多个硬件线程,硬件线程共享一级缓存和二级缓存。MIPS处理器的叫法是同步多线程(Simultaneous Multi-Threading,SMT),英特尔对它的叫法是超线程。
Linux锁与进程间通信
一、内核控制机制
1、竞态条件
几个进程在访问资源的时候彼此干扰的情况通常称为竞态条件(race condition)。
由于导致竞态条件的情况非常罕见,因此需要提出一个问题:是否值得做一些(有时候是大量的)工作来保护代码避免竞态条件。在某些环境中(比如航空飞机的控制系统、重要机械的监控、危险装备),竞态条件是致命问题。
2、临界区
每个进程中访问临界资源的那段代码称为临界区(Critical Section)(临界资源是一次仅允许一个进程使用的共享资源)。
属于临界资源的硬件如打印机等,属于临界资源的软件有消息缓冲队列、数组、缓冲区等。进程间采取互斥方式,实现对这些资源进行共享。
二、内核锁机制
内核可以不受限制地访问整个地址空间。在多处理器系统上,这会引起一些问题。如果几个处理器同时处于核心态,则理论上它们可以同时访问同一个数据结构。在第一个提供了SMP功能的内核版本中,该问题的解决方案非常简单,即每次只允许一个处理器处于核心态。因此,对数据未经协调的并行访问被自动排除了。令人遗憾的是,该方法因为效率不高,很快被废弃了。现在内核使用由锁组成的细粒度网络,来明确地保护各个数据结构。如果处理器A在操作数据结构S,则处理器B可以执行任何其他的内核操作,但不能操作S。
内核为此提供了各种锁选项,分别优化不同的内核数据使用模式。
原子操作:这些是最简单的锁操作。它们保证简单的操作,诸如计数器加1之类,可以不中断地原子执行。即使操作由几个汇编语句组成,也可以保证。
自旋锁:这些是最常用的锁选项。它们用于短期保护某段代码,以防止其他处理器的访问。在内核等待自旋锁释放时,会重复检查是否能获取锁,而不会进入睡眠状态(忙等待)。当然,如果等待时间较长,则效率显然不高。
信号量:这些是用经典方法实现的。在等待信号量释放时,内核进入睡眠状态,直至被唤醒。唤醒后,内核才重新尝试获取信号量。互斥量是信号量的特例,互斥量保护的临界区,每次只能有一个用户进入。
读者/写者锁:这些锁会区分对数据结构的两种不同类型的访问。任意数目的处理器都可以对数据结构进行并发读访问,但只有一个处理器能进行写访问。事实上,在进行写访问时,读访问是无法进行的。
三、自旋锁/互斥锁
1、自旋锁
a、自旋锁概念
自旋锁用于处理器之间的互斥,适合保护很短的临界区,并且不允许在临界区睡眠。申请自旋锁的时候,如果自旋锁被其他处理器占有,该处理器自旋等待(也称为忙等待)。若进程、软中断和硬件中断都可以使用自旋锁。目前内核的自旋锁是排队自旋锁(queued spinlock,也称为"FIFO ticket spinlock"),核心算法类似银行柜台排队叫号。
自旋锁算法核心思路案例(银行柜台排队叫号):
a. 锁拥有排队号和服务号,服务号是当前占有锁的进程的排队号;
b. 每个进程申请锁的时候,首先申请一个排队号,然后轮询服务号是否等于自己的排队号,如果等于,表示自己占有锁,可以进入临界区,否则继续轮询;
c. 当进程释放时,把服务号加1,下一个进程看到服务号等于自己的排队号,退出轮询,进入临界区。
Linux内核自旋锁源码定义如下:
//如果打上实时内核补丁, 那么spinlock使用实时互斥锁保护临界区, 在临界区内可以被抢占和睡眠, 但raw_spinlock还是自旋
//到目前为止, 还没有合并实时内核补丁, 代码可以兼容实时内核, 最好坚持3个原则:
//1.尽可能使用spinlock
//2.绝对不允许被抢占和睡眠的地方使用raw_spinlock, 否则使用spinlock
//3.如果临界区足够小, 使用绝对不允许被抢占和睡眠的地方使用raw_spinlock
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
b、处理器架构都要定义自己的数据类型arch_spinlock_t,如下ARM64架构定义如下:
typedef struct {
#ifdef __AARCH64EB__ // 大端字节序(高位存放在低地址)
u16 next; //排队号
u16 owner; //服务号
#else //小端字节序(低位存放在低地址)
u16 owner;
u16 next;
#endif
} __aligned(4) arch_spinlock_t;
c、Linux内核自旋锁申请/释放常用函数如下:
spin_lock/spin_lock_bh/spin_trylock/spin_lock_irq
spin_unlock/spin_unlock_bh/spin_unlock_irq/spin_unlock_irqrestore
// 申请自旋锁, 如果锁被其他处理器占有, 当前处理器自旋等待
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
// 申请自旋锁, 并且禁止当前处理器的软中断
static __always_inline void spin_lock_bh(spinlock_t *lock)
{
raw_spin_lock_bh(&lock->rlock);
}
// 申请自旋锁, 如果申请成功返回1, 如果锁被其他处理器占有, 当前处理器不等待, 立即返回0
static __always_inline int spin_trylock(spinlock_t *lock)
{
return raw_spin_trylock(&lock->rlock);
}
// 申请自旋锁, 并且禁止当前处理器的硬中断
static __always_inline void spin_lock_irq(spinlock_t *lock)
{
raw_spin_lock_irq(&lock->rlock);
}
d、在多处理器系统当中,函数spin_lock负责申请自旋锁,其内核源码如下:
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
/* Atomically increment the next ticket. */
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n"
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n",
/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"
__nops(3)
)
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"
/*
* No: spin on the owner. Send a local event to avoid missing an
* unlock before the exclusive load.
*/
" sevl\n"
"2: wfe\n"
" ldaxrh %w2, %4\n"
" eor %w1, %w2, %w0, lsr #16\n"
" cbnz %w1, 2b\n"
/* We got the lock. Critical section starts here. */
"3:"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}
函数spin_unlock负责释放自旋锁,其内核源码如下:
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" ldrh %w1, %0\n"
" add %w1, %w1, #1\n"
" stlrh %w1, %0",
/* LSE atomics */
" mov %w1, #1\n"
" staddlh %w1, %0\n"
__nops(1))
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
}
e、读写自旋锁
读写自旋锁(又称为读写锁)是对自旋锁的改进,区分读者和写者,允许多个读者同时进入临界区,读者和写者互斥,写者和写者互斥。如果读者占用读锁,写者申请写锁的时候自旋等待。如果写者占有写锁,读者申请读锁的时候自旋等待。
读写自旋锁内核源码定义定义如下:
typedef struct {
arch_rwlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} rwlock_t;
不同处理器架构都要自己定义数据类型arch_rwlock_t,ARM64架构定义如下:
// 各种处理器架构需要自定义数据类型
typedef struct {
/* no debug version on UP */
} arch_rwlock_t;
内核申请读锁/释放锁,申请写锁/释放锁常用函数查阅Linux内核笔记文档。
读写自旋锁缺点:如果读者太多,写者很难获取写锁,可能饿死。假设有一个读者占有读锁,然后写者申请写锁,写者需要自旋等待,接着另一个读者申请读锁,它可以获取读锁,如果两个读者轮流占有读锁,可能造成写者饿死。解决此问题,内核实现排队读写锁,主要改进是,如果写者正在等待写锁,那么读者申请读锁时自旋等待,写者在锁被释放以后先得到写锁。排队读写锁配置是宏设置的。
2、互斥锁
互斥锁只允许一个进程进入临界区,适合保护比较长的临界区,因为竞争互斥锁时进程可能睡眠和再次唤醒,代价很高。尽管可以把二值信号当作互斥锁使用,但是内核单独实现互斥锁,内核源码的互斥锁定义如下:
struct mutex {
atomic_long_t owner;
spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
申请互斥锁常用函数:
mutex_lock(struct mutex*lock); //申请互斥锁,如果锁被占有,进程深度睡眠
mutex_lock_interruptible(struct *lock); //申请互斥锁,如果锁被占用,进程轻度睡眠
mutex_lock_killable(struct *lock); //申请互斥锁,如果锁被占用,进程中度睡眠
mutex_lock_trylock(struct *lock); //申请互斥锁,如果申请成功返回1,如果锁被其他进程占有,那么进程不等待返回0
所有释放互斥锁使用的函数如下:
mutex_unlock(struct mutex*lock);
实时互斥锁
实时互斥锁是对互斥锁进行改进的,实现了优先继承,解决了优先级反转问题。什么是优先级反转问题?
优先级反转问题:假设进程1的优先级低,进程2的优先级高。进程1持有互斥锁,进程2申请互斥锁,因为进程1已经占用互斥锁,所以进程2必须睡眠等待,导致优先级高的进程2等待优先级低的进程1。
实时互斥锁的作用就是当优先级低的进程持有互斥锁,并且优先级高的进程等待互斥锁,就把持有互斥锁优先级低的进程的优先级临时提高到优先级高的等待互斥锁的进程的优先级。
原子变量
原子变量用来实现对整数的互斥访问,通常用来实现计数器。
假设:写一行代码把变量a加1,编译器把代码编译成3条汇编指令:
a. 把变量a从内存加载到寄存器;
b. 把寄存器的值加1;
c. 把寄存器的值写回到内存。
四、消息队列
进程间通信共有7种:
- PIPE:管道,匿名管道
- FIFO:有名管道
- SIGNAL:信号
- MESSAGE:消息队列
- SEMAPHORE:信号量
- SHARE MEMORY:共享内存
- SOCKET:套接字
消息队列
消息队列是消息的链接表,包括 Posix 消息队列和 System V 消息队列。消息队列克服了信号承载信息量少、管道只能承载无格式字节流以及缓冲区大小受限等缺点,克服了早期 Linux 通信机制的一些缺点。消息队列将消息看作一个记录,具有特定的格式以及特定的优先级,对消息队列有写权限的进程可以向中按照一定的规则添加新消息;对消息队列有读权限的进程则可以从消息队列中读取消息,消息队列是随内核持续的。
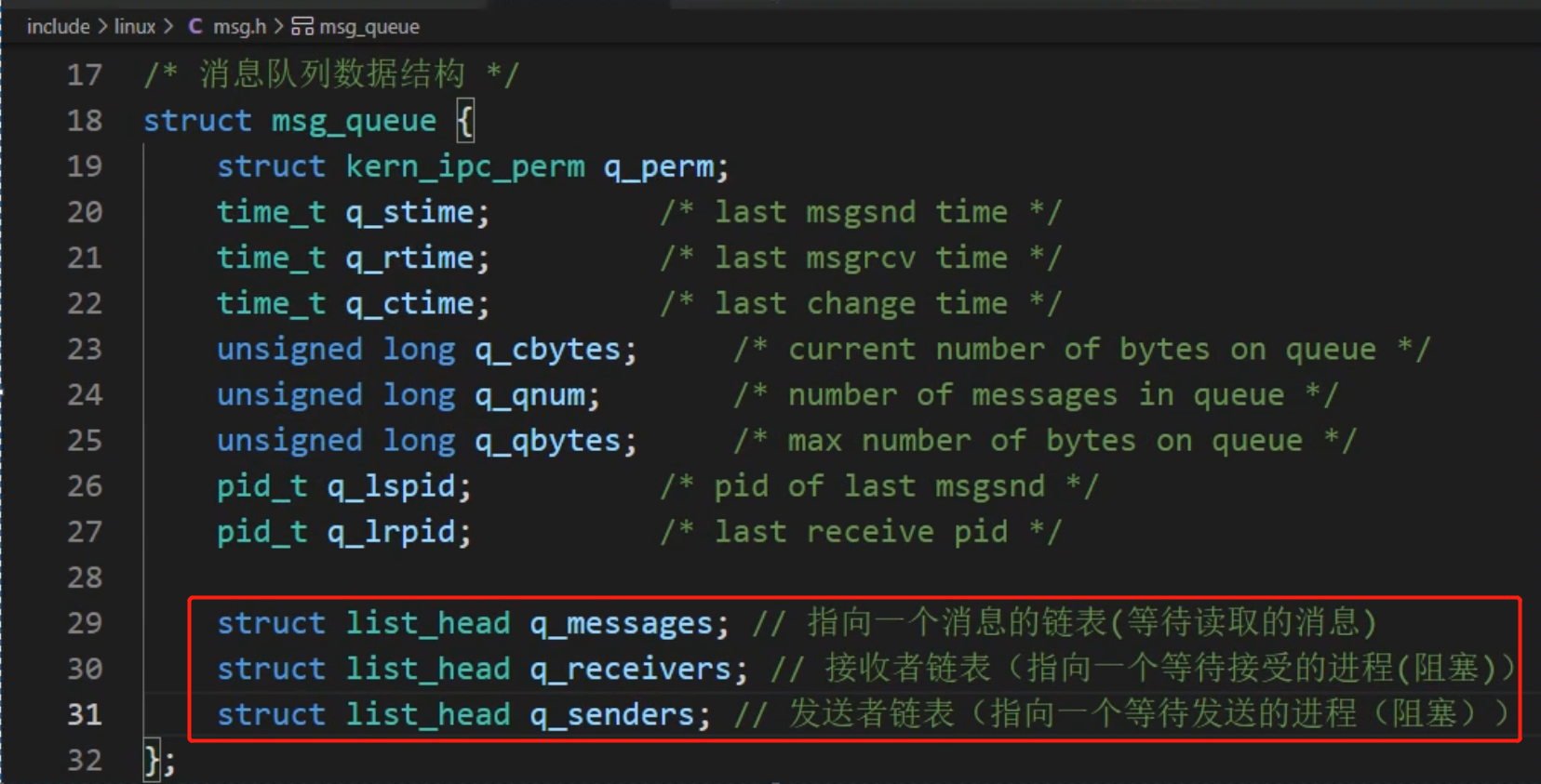
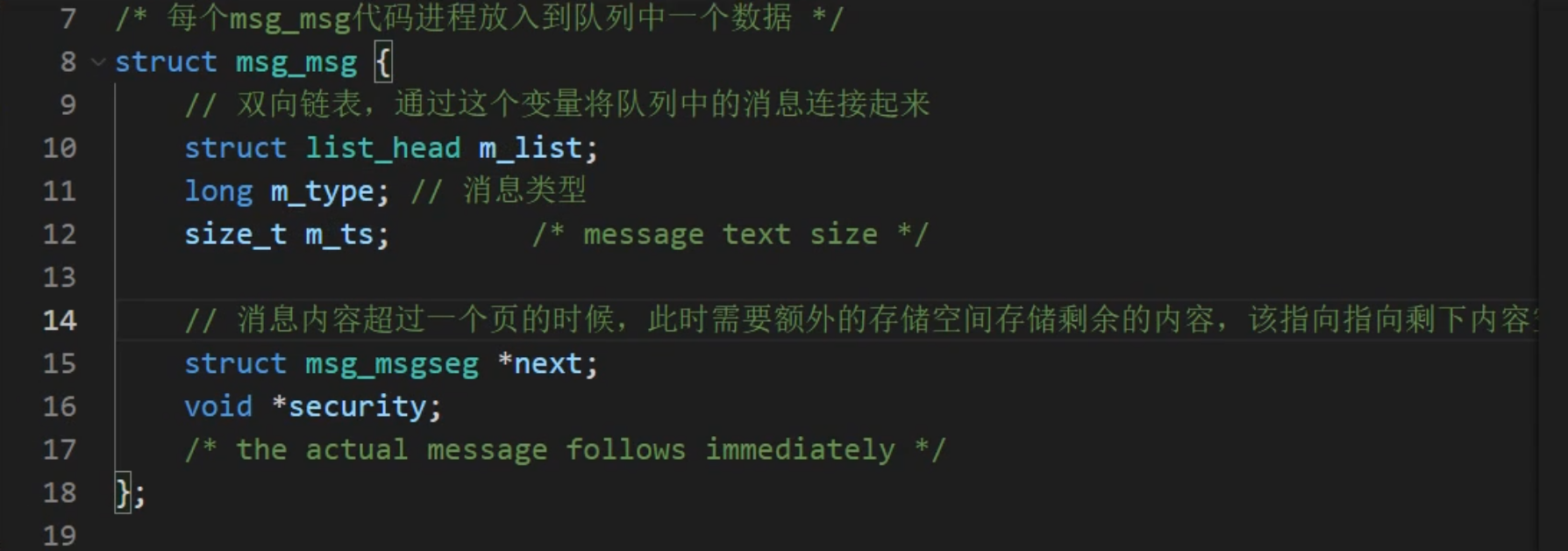
1、消息队列msg_queue数据结构
2、系统调用定义
在程序上层可以直接调用msgsnd(msqid,&msgs,sizeof(struct msgstru),IPC_NOWAIT) 这样的形式来发送消息,但是在底层是用以下的形式来调用 :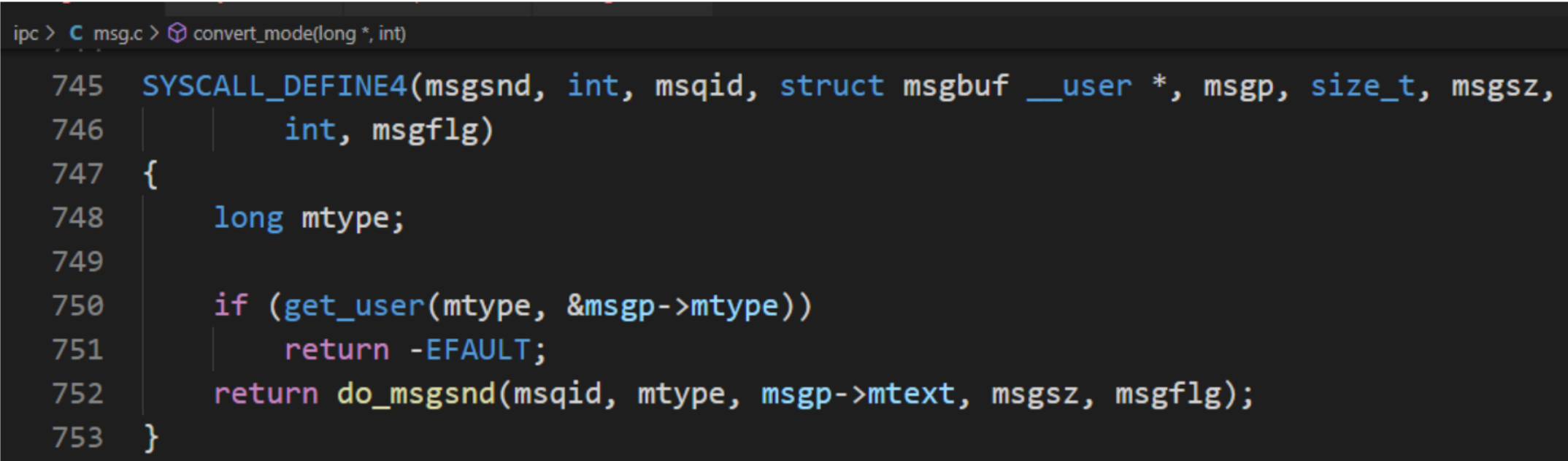
对于 SYSCALL_DEFINE4,首个变量用于函数名,剩下的偶数对参数,依次代表参数类型与参数变量。
SYSCALL_DEFINEx,随后的 x 就是对于不同的参数的个数。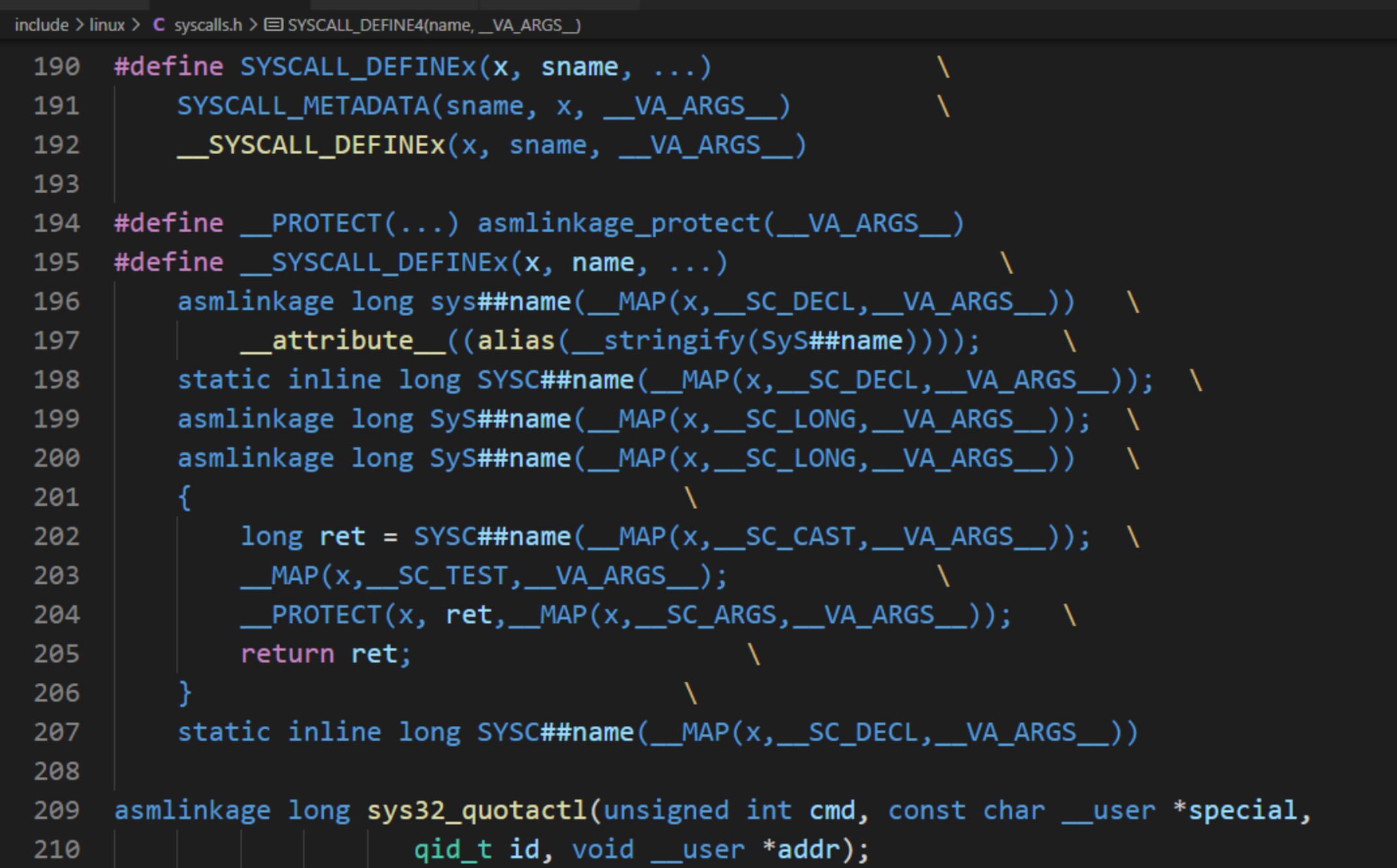
SYSCALL_DEFINEx 的定义和它具体调用的方法中 ## 是连接符,直接将参数的原来的字符替换为 ## 后的占位符。VA_ARGS 代表前面… 里面的可变参数最后调用了__do_sys##name 的方法,在后面加上大括号就是一个函数的具体定义了。
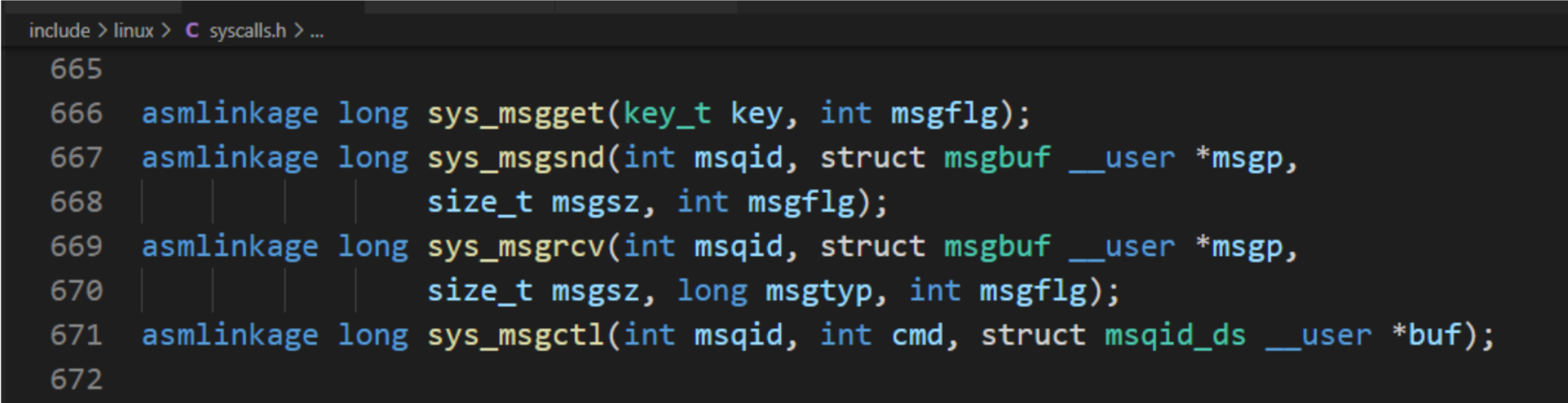
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
a.msgget 函数
得到消息队列标识符或创建一个消息队列对象并返回消息队列标识符。
b.msgsnd 函数
将消息写入到消息队列。
c.msgrcv 函数
从消息队列读取消息。 msgflag:IPC_NOWAIT/IPC_EXCEPT/IPC_NOERROR
d.msgctl函数
获取和设置消息队列的属性。
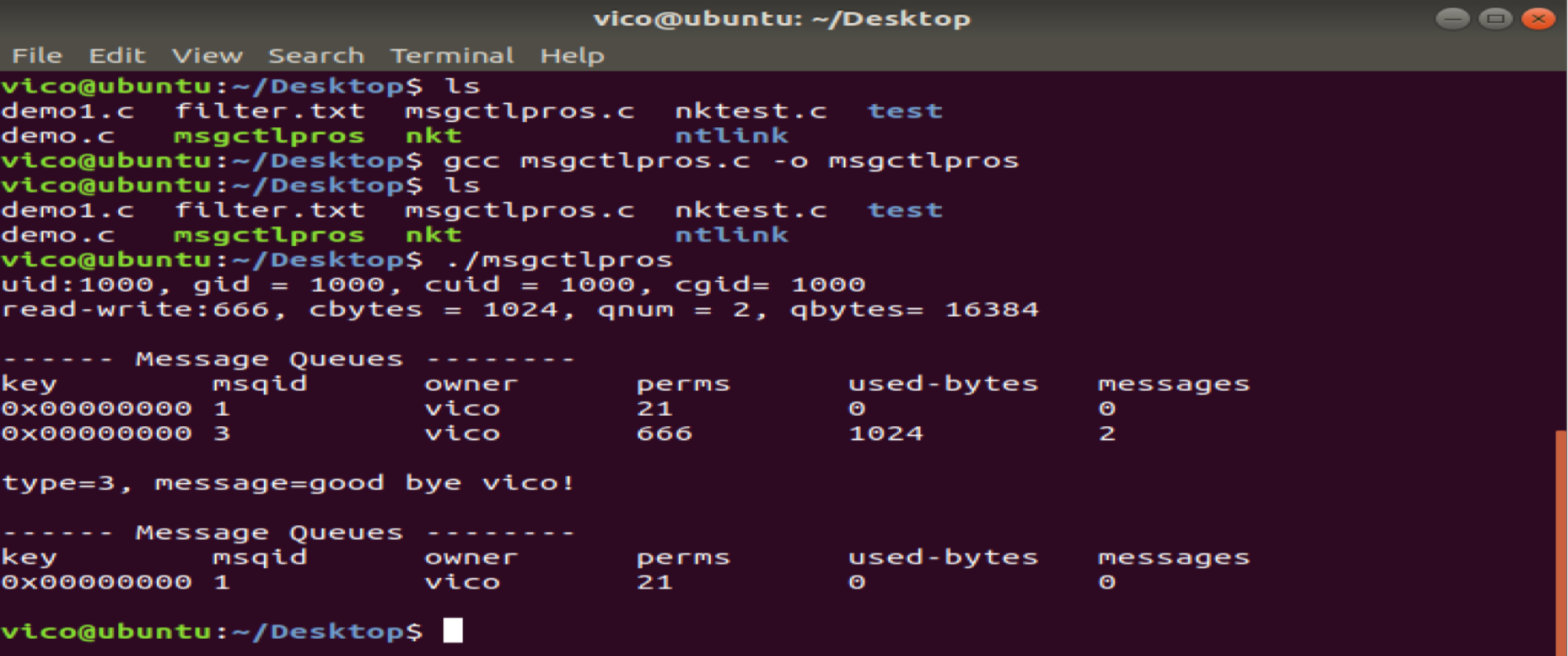
3、消息队列项目实战分析(供参考)
3.1 消息队列控制
#include <stdio.h>
#include <stdlib.h> /* system function*/
#include <string.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <error.h>
#define TEXT_SIZE 512
struct msgbuf
{
long mtype ;
char mtext[TEXT_SIZE] ;
};
int main(int argc, char **argv)
{
int msqid ;
struct msqid_ds info ;
struct msgbuf buf ;
struct msgbuf buf1 ;
int flag ;
int sendlength, recvlength ;
msqid = msgget( IPC_PRIVATE, 0666 ) ;
if ( msqid < 0 )
{
perror("get ipc_id error") ;
return -1 ;
}
buf.mtype = 1 ;
strcpy(buf.mtext, "How do you do!") ;
sendlength = sizeof(struct msgbuf) - sizeof(long) ;
flag = msgsnd( msqid, &buf, sendlength , 0 ) ;
if ( flag < 0 )
{
perror("send message error") ;
return -1 ;
}
buf.mtype = 3 ;
strcpy(buf.mtext, "good bye vico!") ;
sendlength = sizeof(struct msgbuf) - sizeof(long) ;
flag = msgsnd( msqid, &buf, sendlength , 0 ) ;
if ( flag < 0 )
{
perror("send message error") ;
return -1 ;
}
flag = msgctl( msqid, IPC_STAT, &info ) ;
if ( flag < 0 )
{
perror("get message status error") ;
return -1 ;
}
printf("uid:%d, gid = %d, cuid = %d, cgid= %d\n" ,info.msg_perm.uid, info.msg_perm.gid, info.msg_perm.cuid, info.msg_perm.cgid ) ;
printf("read-write:%03o, cbytes = %lu, qnum = %lu, qbytes= %lu\n" ,info.msg_perm.mode&0777, info.msg_cbytes, info.msg_qnum, info.msg_qbytes ) ;
system("ipcs -q") ;
recvlength = sizeof(struct msgbuf) - sizeof(long) ;
memset(&buf1, 0x00, sizeof(struct msgbuf)) ;
flag = msgrcv( msqid, &buf1, recvlength ,3,0 ) ;
if ( flag < 0 )
{
perror("recv message error") ;
return -1 ;
}
printf("type=%ld, message=%s\n", buf1.mtype, buf1.mtext) ;
flag = msgctl( msqid, IPC_RMID,NULL) ;
if ( flag < 0 )
{
perror("rm message queue error") ;
return -1 ;
}
system("ipcs -q") ;
return 0 ;
}
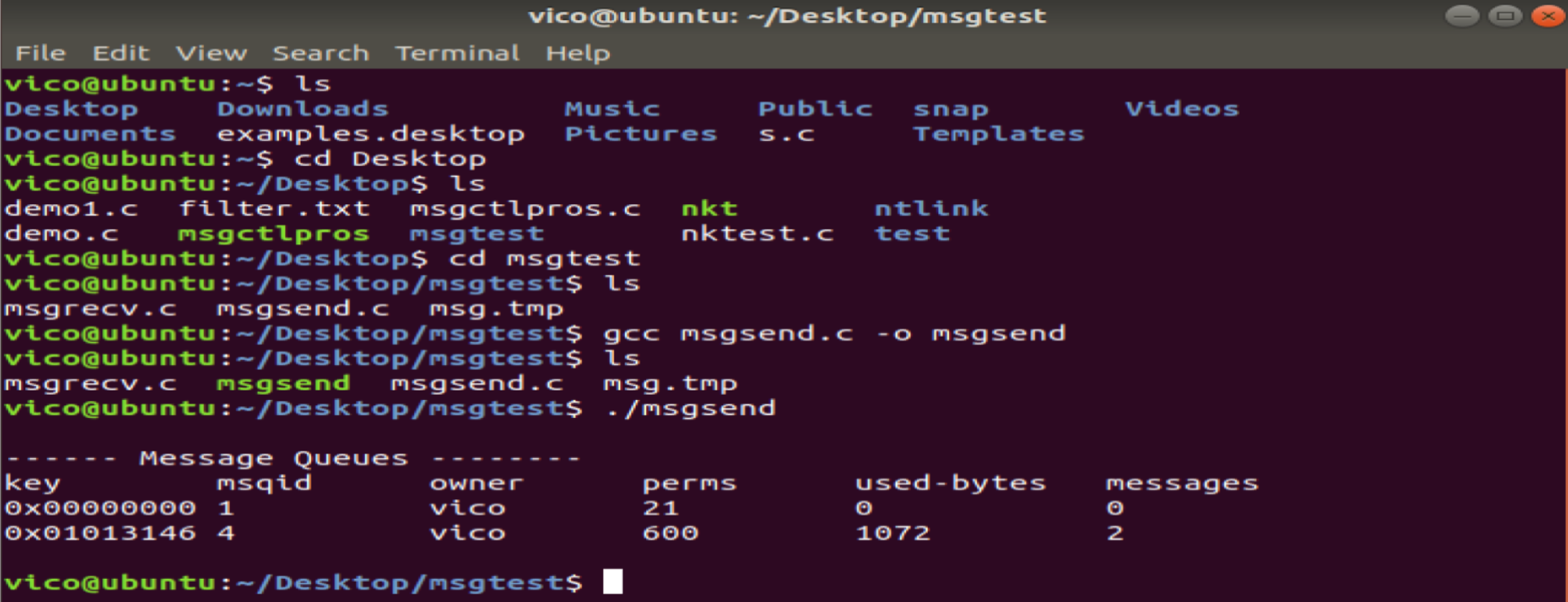
3.2 两个进程间消息队列收发消息
发送方:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <time.h>
#define TEXT_SIZE 512
struct msgbuf
{
long mtype ;
int status ;
char time[20] ;
char mtext[TEXT_SIZE] ;
} ;
char *getxttime()
{
time_t tv ;
struct tm *tmp ;
static char buf[20] ;
tv = time( 0 ) ;
tmp = localtime(&tv) ;
sprintf(buf,"%02d:%02d:%02d",tmp->tm_hour , tmp->tm_min,tmp->tm_sec);
return buf ;
}
int main(int argc, char **argv)
{
int msqid ;
struct msqid_ds info ;
struct msgbuf buf ;
struct msgbuf buf1 ;
int flag ;
int sendlength, recvlength ;
int key ;
key = ftok("msg.tmp", 0x01 ) ;
if ( key < 0 )
{
perror("ftok key error") ;
return -1 ;
}
msqid = msgget( key, 0600|IPC_CREAT ) ;
if ( msqid < 0 )
{
perror("create message queue error") ;
return -1 ;
}
buf.mtype = 1 ;
buf.status = 9 ;
strcpy(buf.time, getxttime()) ;
strcpy(buf.mtext, "Hello world vico!") ;
sendlength = sizeof(struct msgbuf) - sizeof(long) ;
flag = msgsnd( msqid, &buf, sendlength , 0 ) ;
if ( flag < 0 )
{
perror("send message error") ;
return -1 ;
}
buf.mtype = 3 ;
buf.status = 9 ;
strcpy(buf.time, getxttime()) ;
strcpy(buf.mtext, "good bye vico!") ;
sendlength = sizeof(struct msgbuf) - sizeof(long) ;
flag = msgsnd( msqid, &buf, sendlength , 0 ) ;
if ( flag < 0 )
{
perror("send message error") ;
return -1 ;
}
system("ipcs -q") ;
return 0 ;
}
接收方:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#define TEXT_SIZE 512
struct msgbuf
{
long mtype ;
int status ;
char time[20] ;
char mtext[TEXT_SIZE] ;
} ;
int main(int argc, char **argv)
{
int msqid ;
struct msqid_ds info ;
struct msgbuf buf1 ;
int flag ;
int recvlength ;
int key ;
int mtype ;
key = ftok("msg.tmp", 0x01 ) ;
if ( key < 0 )
{
perror("ftok key error") ;
return -1 ;
}
msqid = msgget( key, 0 ) ;
if ( msqid < 0 )
{
perror("get ipc_id error") ;
return -1 ;
}
recvlength = sizeof(struct msgbuf) - sizeof(long) ;
memset(&buf1, 0x00, sizeof(struct msgbuf)) ;
mtype = 1 ;
flag = msgrcv( msqid, &buf1, recvlength ,mtype,0 ) ;
if ( flag < 0 )
{
perror("recv message error\n") ;
return -1 ;
}
printf("type=%ld,time=%s, message=%s\n", buf1.mtype, buf1.time, buf1.mtext) ;
system("ipcs -q") ;
return 0 ;
}
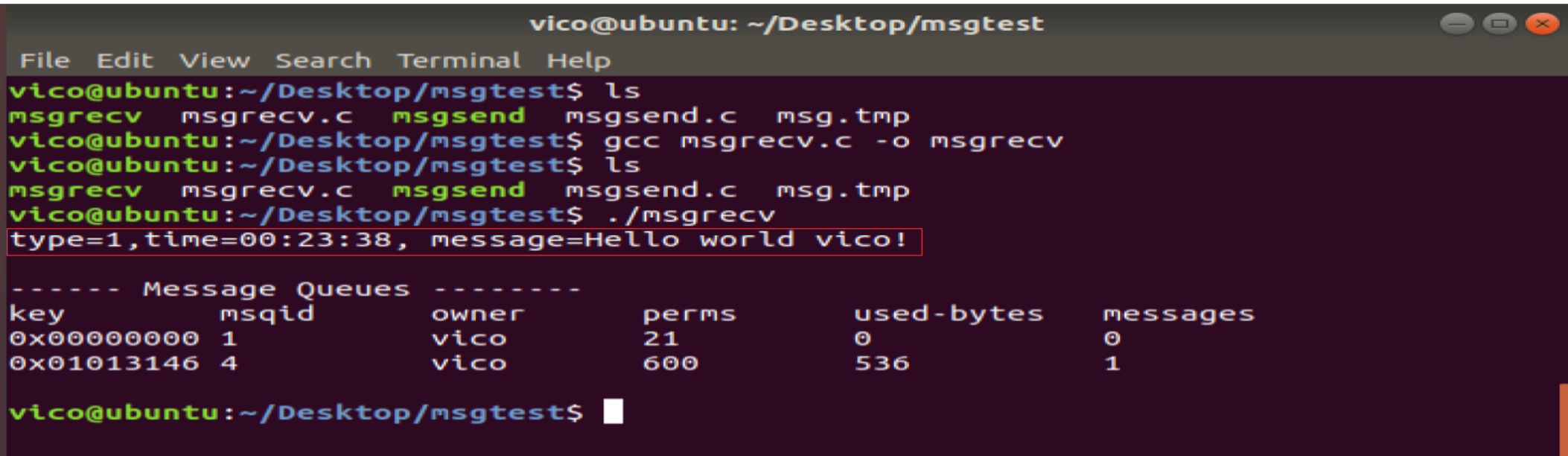
备注:删除该消息队列,否则就一直存在于系统当中。另外信号量和共享内存也是随着内核持续存在的。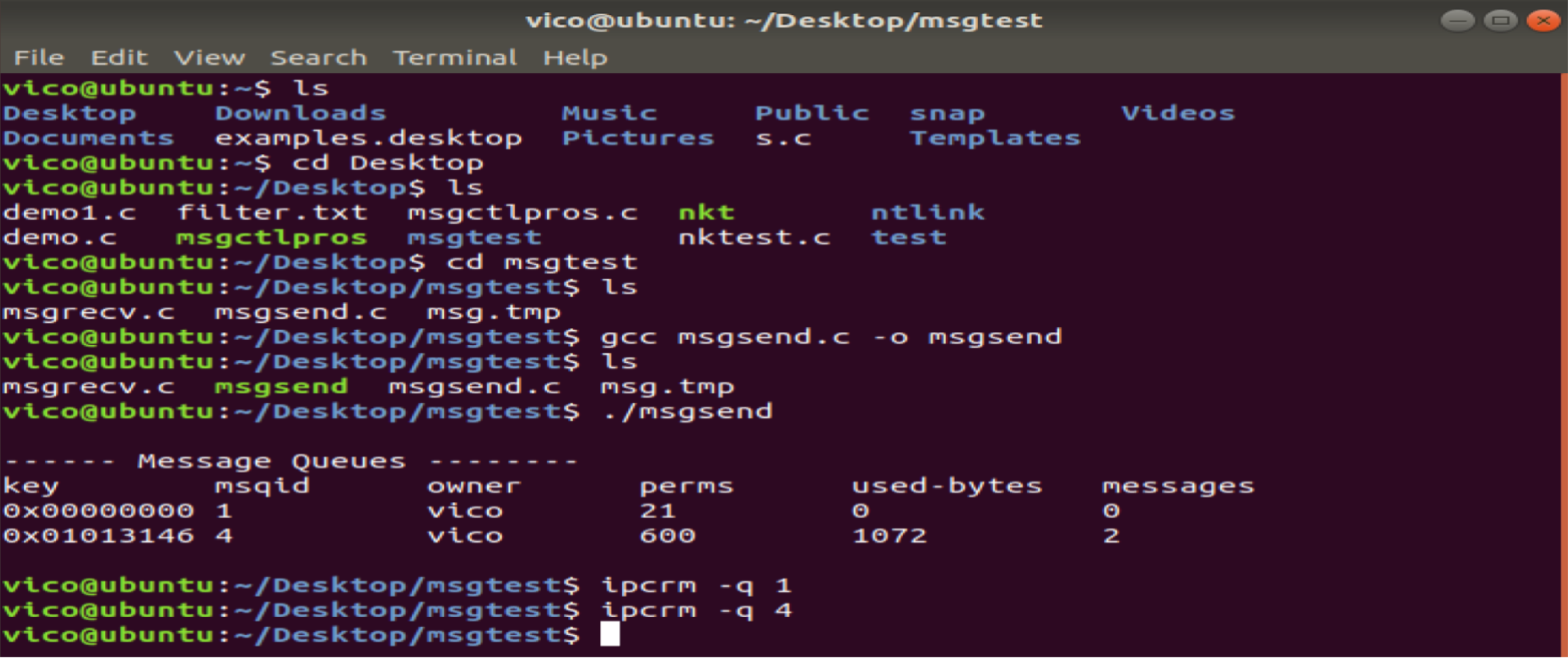
五、共享内存(原理机制)
共享内存就是允许两个或多个进程共享一定的存储区。就如同 malloc() 函数向不同进程返回了指向同一个物理内存区域的指针。当一个进程改变这块地址中内容的时候,其它进程都会察觉到这个更改。因为数据不需要在客户机和服务器端之间复制,数据直接写到内存,不用若干次数据拷贝,所以这是最快的一种IPC。备注:共享内存没有任何的同步与互斥机制,所以要使用信号量来实现对共享内存的存取的同步。
共享内存是IPC通信中传输速度最快的通信方式没有之一。共享内存原理结构图如下: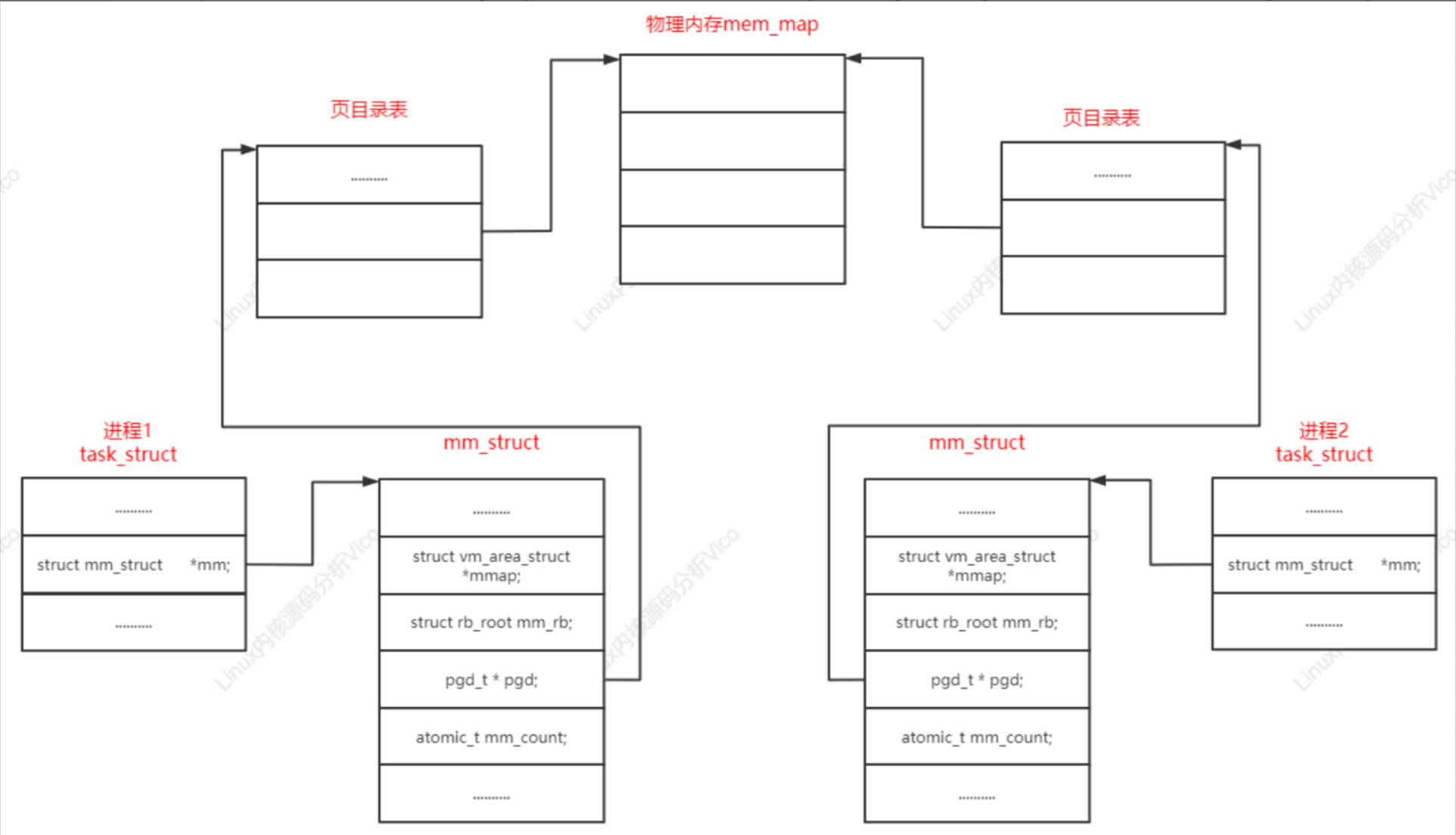
实现多个进程对共享内存的同步访问?
通常使用信号量来实现对共享内存的同步访问控制。
共享内存有关常用函数:
- shmget(); //创建共享内存,成功返回共享内存的id,错误返回-1
- shmat(); //连接操作,成功返回指向共享内存段的指针,错误返回-1
- shmdt(); //分离操作,成功返回0,错误返回-1
使用共享内存的优点:
共享内存进行进程间的通信非常方便,函数接口非常简单,数据的共享还使进程间的数据不用传递,而是直接内存访问,也加快程序的效率。
使用共享内存的缺点:
共享内存没有提供同步机制,在使用共享内存进行进程间通信时,要借助其他手段来解决同步工作。
Linux内存原理与分析
一、UMA/NUMA内存结构
共享存储型多处理机有两种模型:
- 均匀存储器存取(Uniform-Memory-Access,简称UMA)模型
- 非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型

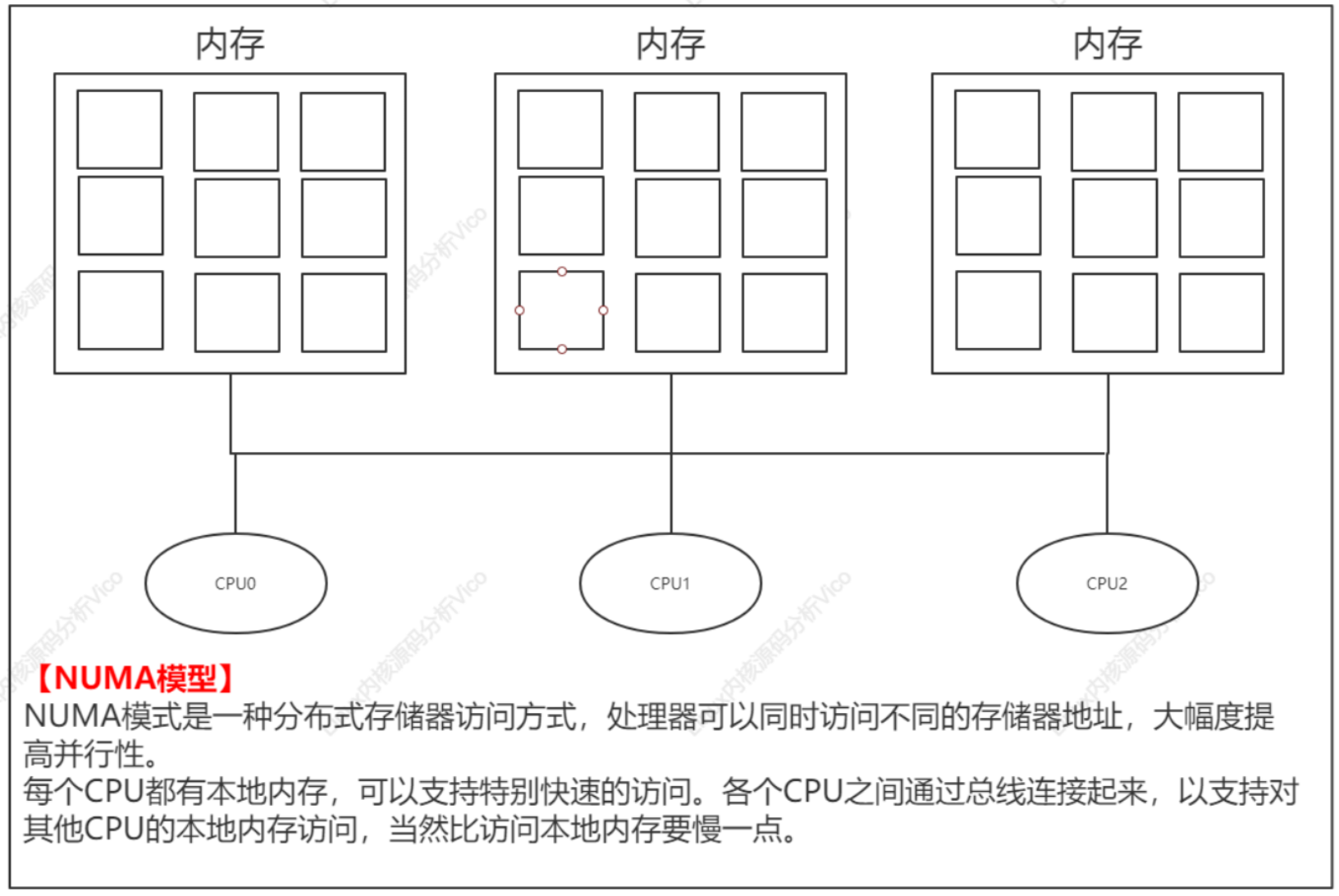
比较典型NUMA服务器:SUN15K、IBMp690等
二、mm_struct结构体
Linux内核内存管理子系统架构如下图所示,分为用户空间、内核空间和硬件层3个层面。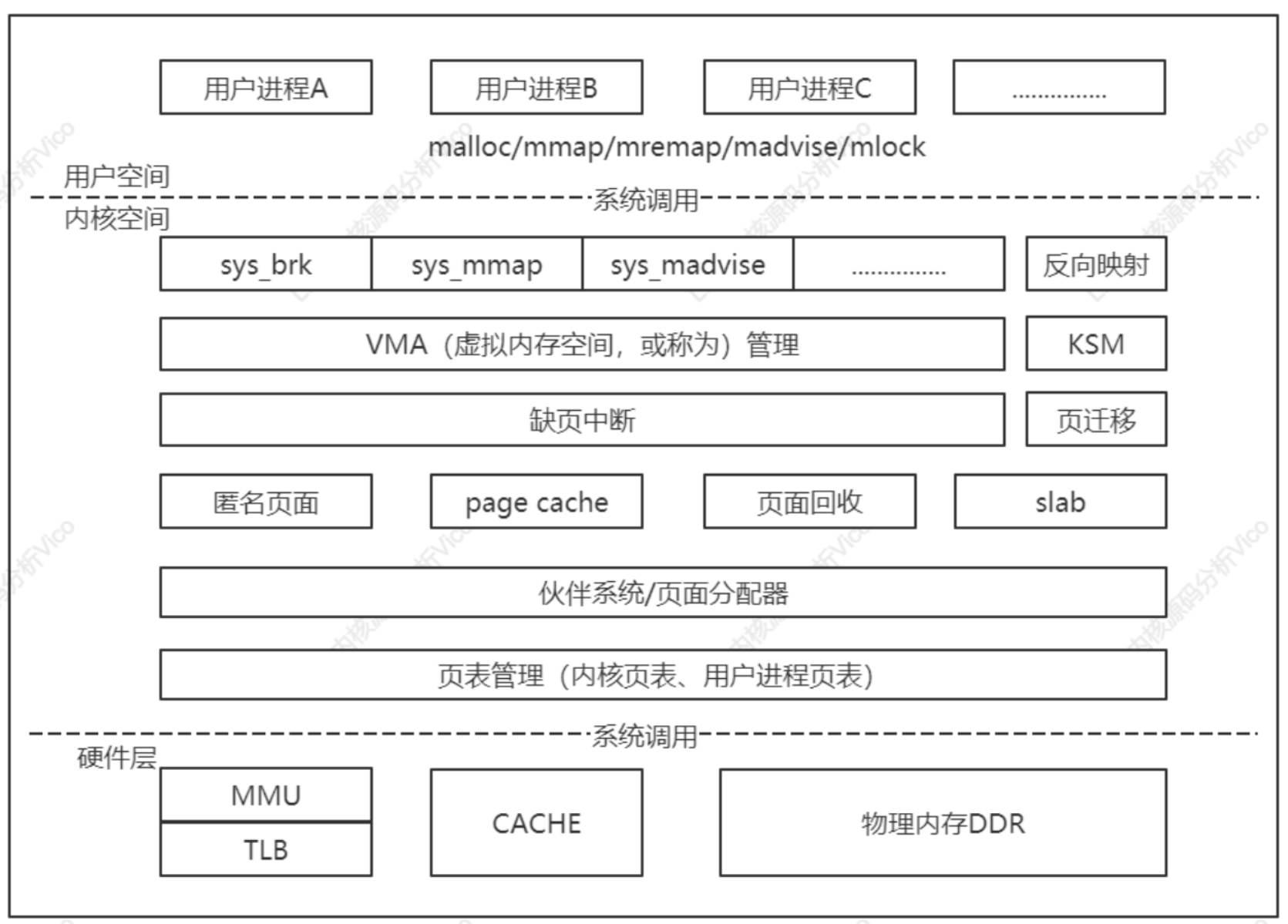
用户空间:malloc/free–>ptmalloc(glibc)/jemalloc(FreeBSD)/tcmalloc(Google)
内核空间:sys_brk、sys_mmap、sys_munmap等等
1、用户空间
应用程序使用malloc()申请内存,使用free()释放内存,malloc()/free()是glibc库的内存分配器ptmalloc提供的接口,ptmalloc使用系统调用brk/mmap向内核以页为单位申请内存,然后划分成小内存块分配给用户应用程序。用户空间的内存分配器,除glibc库的ptmalloc,google的tcmalloc/FreeBSD的jemalloc。
2、内核空间
内核空间的基本功能:虚拟内存管理负责从进程的虚拟地址空间分配虚拟页,sys_brk用来扩大或收缩堆,sys_mmap用来在内存映射区域分配虚拟页,sys_munmap用来释放虚拟页。
页分配器负责分配物理页,当前使用的页分配器是伙伴分配器。内核空间提供把页划分成小内存块分配的块分配器,提供分配内存的接口kmalloc()和释放内存接口kfree()。块分配器:SLAB/SLUB/SLOB。
内核空间的扩展功能:不连续页分配器提供了分配内存的接口vmalloc和释放内存接口vfree,在内存碎片化时,申请连续物理页的成功率很低,可申请不连续的物理页,映射到连续的虚拟页,即虚拟地址连续页物理地址不连续。
连续内存分配器(contiguous memory allocator,CMA)用来给驱动程序预留一段连续的内存,当驱动程序不用的时候,可以给进程使用;当驱动程序需要使用的时候,把进程占用的内存通过回收或迁移的方式让出来,给驱动程序使用。
3、硬件层面
处理器包含一个称为内存管理单元(Memory Management Unit,MMU)的部件,负责把虚拟地址转换成物理地址。内存管理单元包含一个称为页表缓存(Translation Lookaside Buffer,TLB)的部件,保存最近使用的页表映射,避免每次把虚拟地址转换物理地址都需要查询内存中的页表。
4、虚拟地址空间布局
a、虚拟地址空间划分

以ARM64处理器为例:虚拟地址 的最大宽度是48位。内核虚拟地址在64位地址空间顶部,高16位全是1,范围是[0xFFFF 0000 0000 0000,0xFFFF FFFF FFFF FFFF]。用户虚拟地址 在64位地址 空间的底部,高16位全是0,范围是[0x0000 0000 0000 0000,0x0000 FFFF FFFF FFFF]。
在编译ARM64架构的Linux内核时,可以选择虚拟地址宽度:
a.选择页长度4KB,默认虚拟地址宽度为39位;
b.选择页长度16KB,默认虚拟地址宽度为47位;
c.选择页长度64KB,默认虚拟地址宽度为42位;
d.选择48位虚拟地址。
在ARM64架构linux内核中,内核虚拟地址 和 用户虚拟地址宽度相同。所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间,同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。
b、用户虚拟地址空间布局
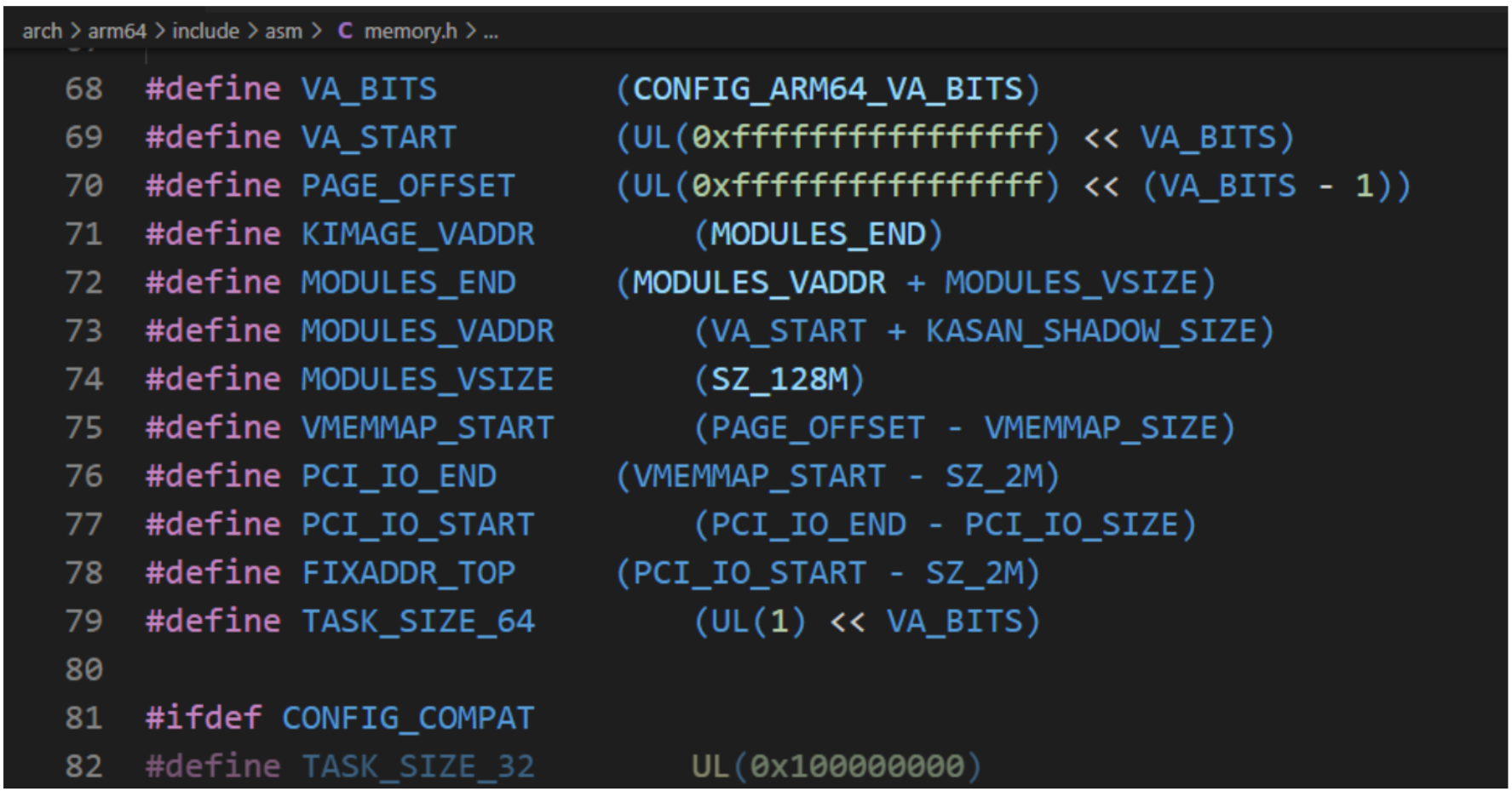
进程的用户虚拟地址空间的起始地址是0,长度是TASK_SIZE,由每种处理器架构定义自己的宏TASK_SIZE。ARM64架构定义宏TASK_SIZE如下所示:
- 32位用户空间程序:TASK_SIZE的值是TASK_SIZE_32,即0x10000000,等于4GB。
- 64位用户空间程序:TASK_SIZE的值是TASK_SIZE_64,即2的VA_BITS次方字节,VA_BITS是编译内核时选择的虚拟地址位数。
Linux内核使用内存描述符mm_struct描述进程的用户虚拟地址空间,主要核心成员如下:
// 内存描述符结构体类型(今后要用的主要成员)
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */ //虚拟内存区域链表
struct rb_root mm_rb; //虚拟内存区域红黑树
u32 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags); //在内存映射区域找到一个没有映射的区域
#endif
unsigned long mmap_base; /* base of mmap area */ //内存映射区域的起始地址
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
#ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES
/* Base adresses for compatible mmap() */
unsigned long mmap_compat_base;
unsigned long mmap_compat_legacy_base;
#endif
unsigned long task_size; /* size of task vm space */ //用户虚拟地址空间的长度
unsigned long highest_vm_end; /* highest vma end address */
pgd_t * pgd; //指向页的全局目录, 即第一级页表
/**
* @mm_users: The number of users including userspace.
*
* Use mmget()/mmget_not_zero()/mmput() to modify. When this drops
* to 0 (i.e. when the task exits and there are no other temporary
* reference holders), we also release a reference on @mm_count
* (which may then free the &struct mm_struct if @mm_count also
* drops to 0).
*/
atomic_t mm_users; //共享同一个用户虚拟地址空间的进程数量, 也就是线程组包含的进程的数量
/**
* @mm_count: The number of references to &struct mm_struct
* (@mm_users count as 1).
*
* Use mmgrab()/mmdrop() to modify. When this drops to 0, the
* &struct mm_struct is freed.
*/
atomic_t mm_count; //内存描述符的引用计数
atomic_long_t nr_ptes; /* PTE page table pages */
#if CONFIG_PGTABLE_LEVELS > 2
atomic_long_t nr_pmds; /* PMD page table pages */
#endif
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem;
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long def_flags;
// 代码段/数据段的起始地址和结束地址
unsigned long start_code, end_code, start_data, end_data;
// 堆的起始地址和结束地址 栈的起始地址
unsigned long start_brk, brk, start_stack;
// 参数字符串起始地址和结束地址 环境变量的起始地址和结束地址
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
/* Architecture-specific MM context */
mm_context_t context; // 处理器架构特定的内存管理上下文
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
struct user_namespace *user_ns;
/* store ref to file /proc/<pid>/exe symlink points to */
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACK
struct cpumask cpumask_allocation;
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that the PTEs will be marked
* pte_numa. NUMA hinting faults will gather statistics and migrate
* pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and setting pte_numa */
unsigned long numa_scan_offset;
/* numa_scan_seq prevents two threads setting pte_numa */
int numa_scan_seq;
#endif
#if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION)
/*
* An operation with batched TLB flushing is going on. Anything that
* can move process memory needs to flush the TLB when moving a
* PROT_NONE or PROT_NUMA mapped page.
*/
bool tlb_flush_pending;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
struct work_struct async_put_work;
};
c、进程的进程描述和内存描述符关系如下图所示:
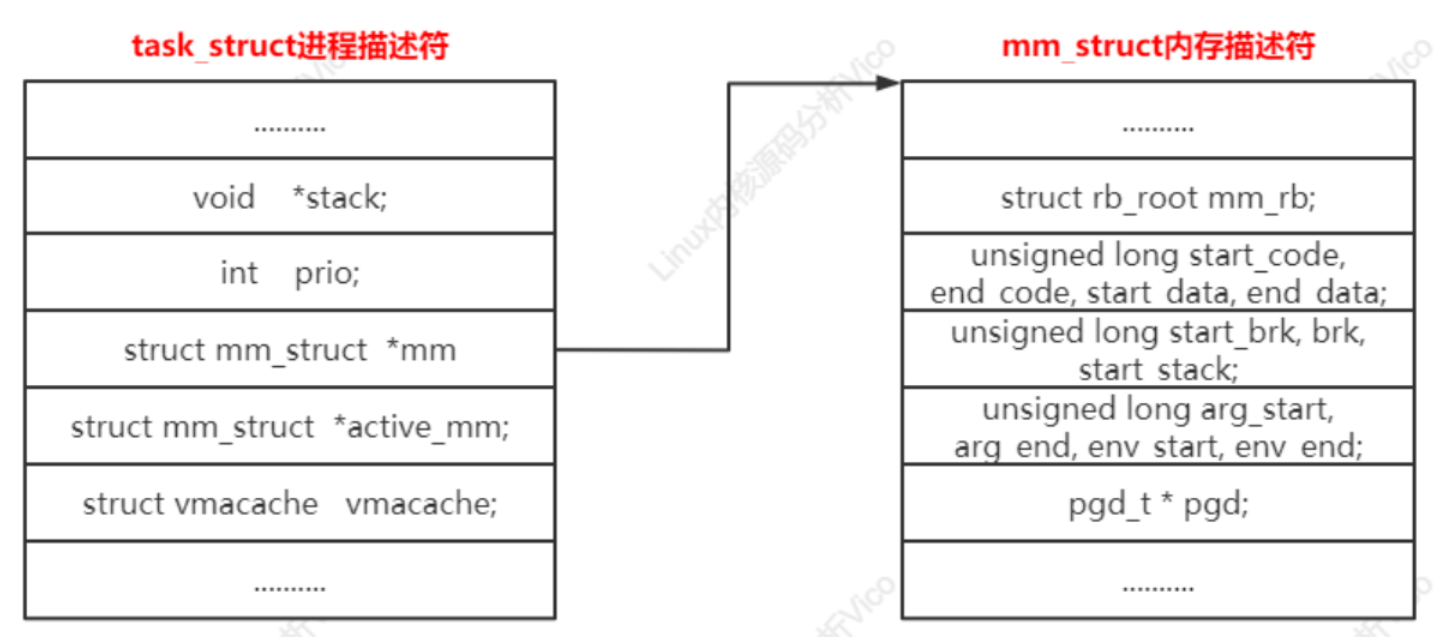
进程描述符的成员
struct mm_struct *mm; // 进程的mm指向一个内存描述符,内核线程没有用户虚拟地址空间,所以mm是空指针。
struct mm_struct *active_mm; // 进程的active_mm和mm总是指向一个内存描述符,内核线程的active_mm在没有运行时是空指针,在运行时指向上一个进程借用的内存描述符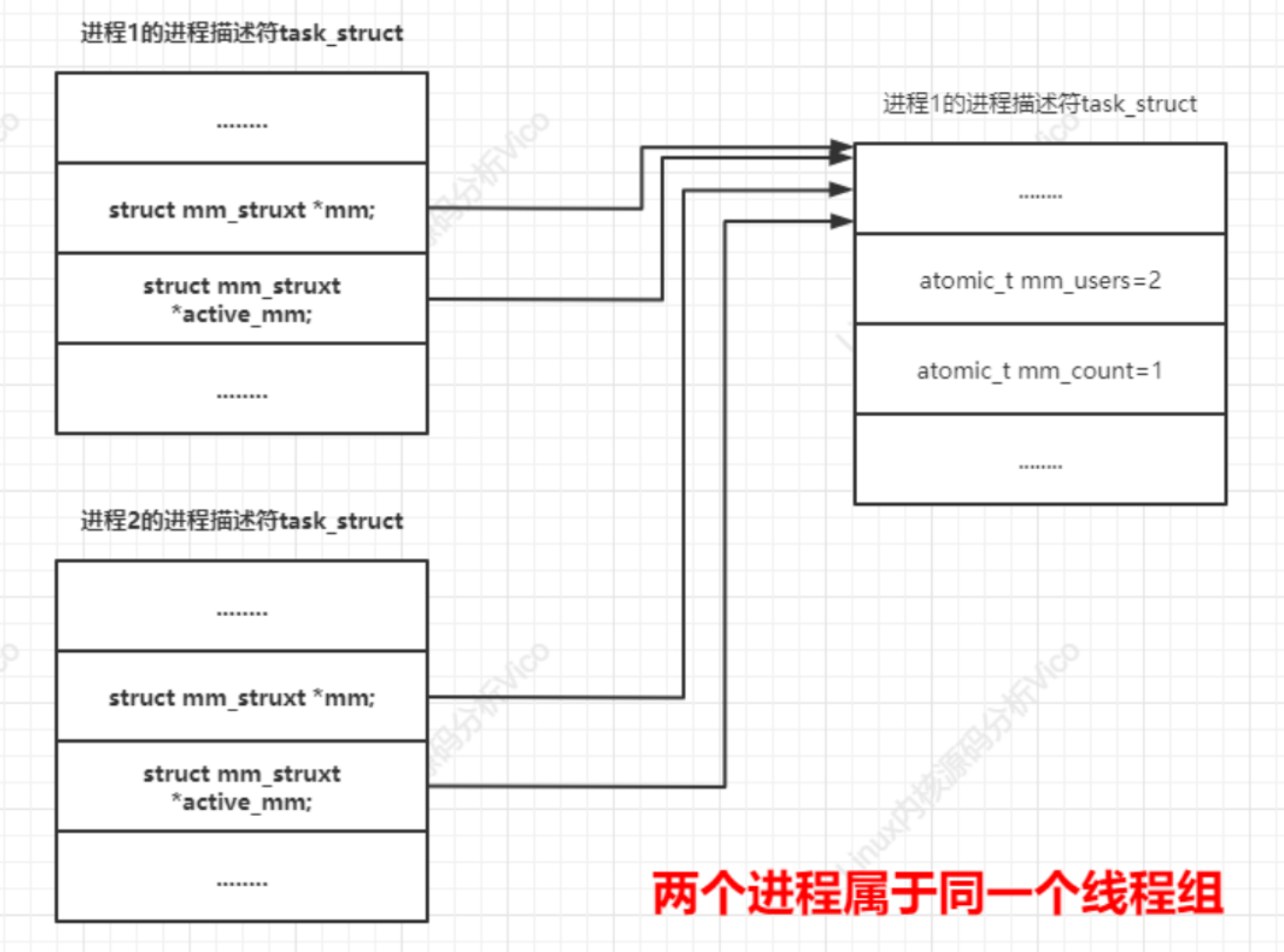
d、内核地址空间布局
ARM64处理器架构的内核地址空间布局如下: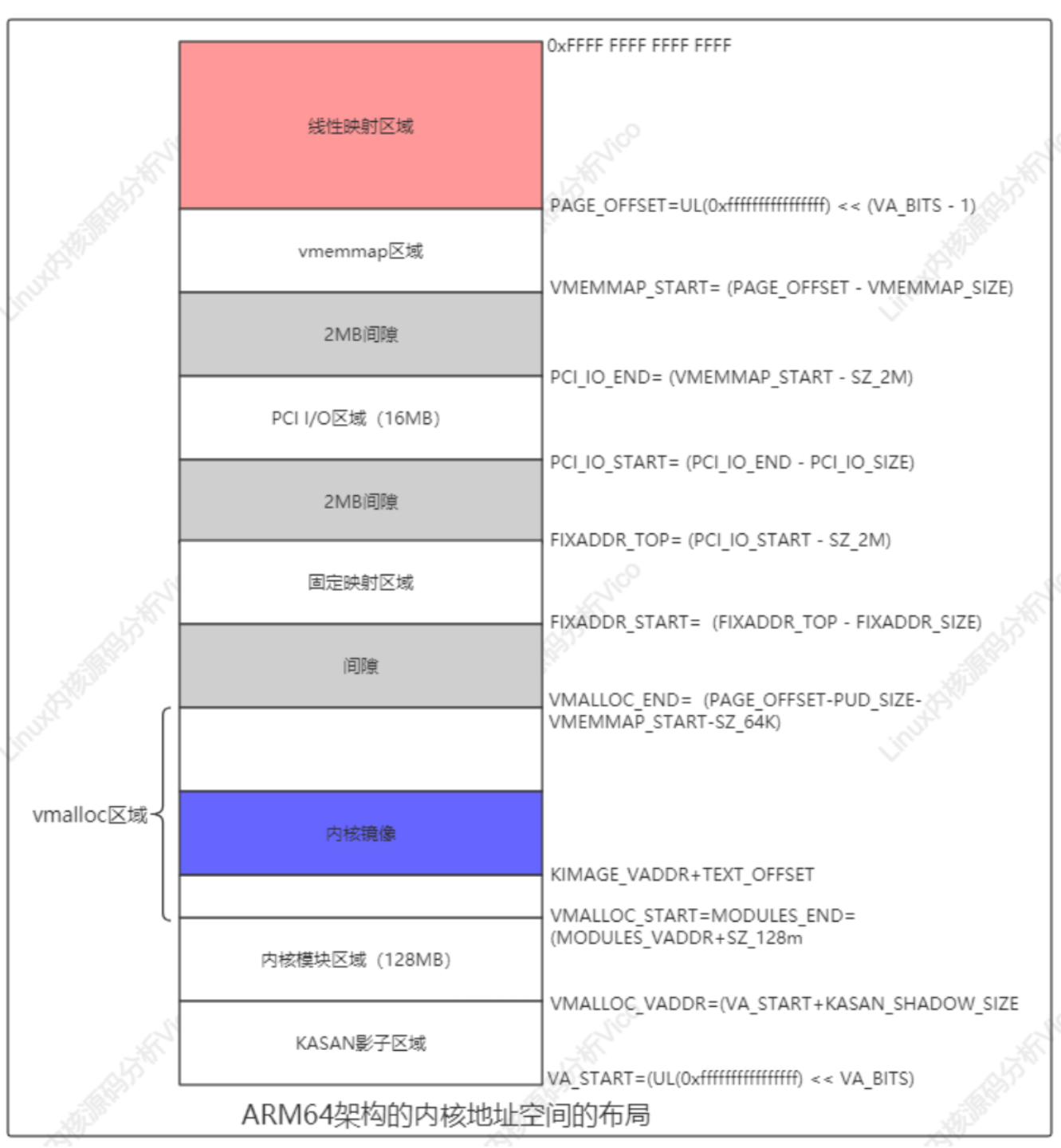
三、TLB工作原理
处理器的内存管理单元(Memory Management Unit,MMU)负责把虚拟地址转换成物理地址,为了改进虚拟地址到物理地址的转换速度,避免每次转换都需要查找内存中的页表,处理器厂商在内存管理单元里面增加一个称为TLB (Translation Lookaside Buffer,TLB)的高速缓存,TLB直接为转换后备缓冲区,意译为页表缓存。
1、TLB表项格式
不同处理器架构的TLB表项的格式不同,ARM64处理器的每条TLB表项不仅包含虚拟地址和物理地址,也包含属性:内存类型、缓存策略、访问权限、地址空间标识符(ASID)和虚拟机标识符(VMID)。
2、TLB管理
如果内核修改了可能缓存在TLB里面的页表项,那么内核必须负责使旧的TLB表项失效,内核定义每种处理器架构必须实现的函数如下:
// 使所有tlb表项失效
static inline void flush_tlb_all(void)
{
dsb(ishst);
__tlbi(vmalle1is);
dsb(ish);
isb();
}
// 使指定用户地址空间的所有tlb表项失效, 参数mm是进程的内存描述符
static inline void flush_tlb_mm(struct mm_struct *mm)
{
unsigned long asid = ASID(mm) << 48;
dsb(ishst);
__tlbi(aside1is, asid);
dsb(ish);
}
// 使指定用户地址空间的某个范围tlb表项进行失效, 参数vma是虚拟内存区域, start是起始地址, end是结束地址
static inline void flush_tlb_range(struct vm_area_struct *vma,
unsigned long start, unsigned long end)
{
__flush_tlb_range(vma, start, end, false);
}
// 使指定用户地址空间里面的指定虚拟页的tlb表项失效, 参数vma是虚拟内存区域, uaddr是虚拟页中的任意虚拟地址
static inline void flush_tlb_page(struct vm_area_struct *vma,
unsigned long uaddr)
{
unsigned long addr = uaddr >> 12 | (ASID(vma->vm_mm) << 48);
dsb(ishst);
__tlbi(vale1is, addr);
dsb(ish);
}
// 使内核的某个虚拟地址范围的tlb表项失效, 参数start是起始地址, end是结束地址
static inline void flush_tlb_kernel_range(unsigned long start, unsigned long end)
{
unsigned long addr;
if ((end - start) > MAX_TLB_RANGE) {
flush_tlb_all();
return;
}
start >>= 12;
end >>= 12;
dsb(ishst);
for (addr = start; addr < end; addr += 1 << (PAGE_SHIFT - 12))
__tlbi(vaae1is, addr);
dsb(ish);
isb();
}
3、ARM64架构TLB失效指令:
TLB[IS]{,}
- type:
- ALL(所有表项)
- VMALL(当前虚拟机的阶段1的所有表项,即表项的VMID是当前虚拟机的VMID)。虚拟机里面运行的客户操作系统的虚拟地址 转换成物理地址分两个阶段:1把虚拟地址转换成中间物理地址;2把中间物理地址 转换成物理地址。
- level(指定异常级别):
- E1:异常级别1
- E2:异常级别2
- E3:异常级别3
- IS表示内存共享(inner Shareable),多个核共享。如果不使用字段IS,表示非共享,只被一个核使用。在SMP系统中,如果指令TLBI不携带字段IS,仅仅使当前核的TLB表项失效;如果指令TLBI携带字段IS,表示使所有核的TLB表项失效。
- 选项Xt是X0-X31中的任何一个寄存器。
flush_tlb_all用来使所有核的所有TLB失效,内核代码如下: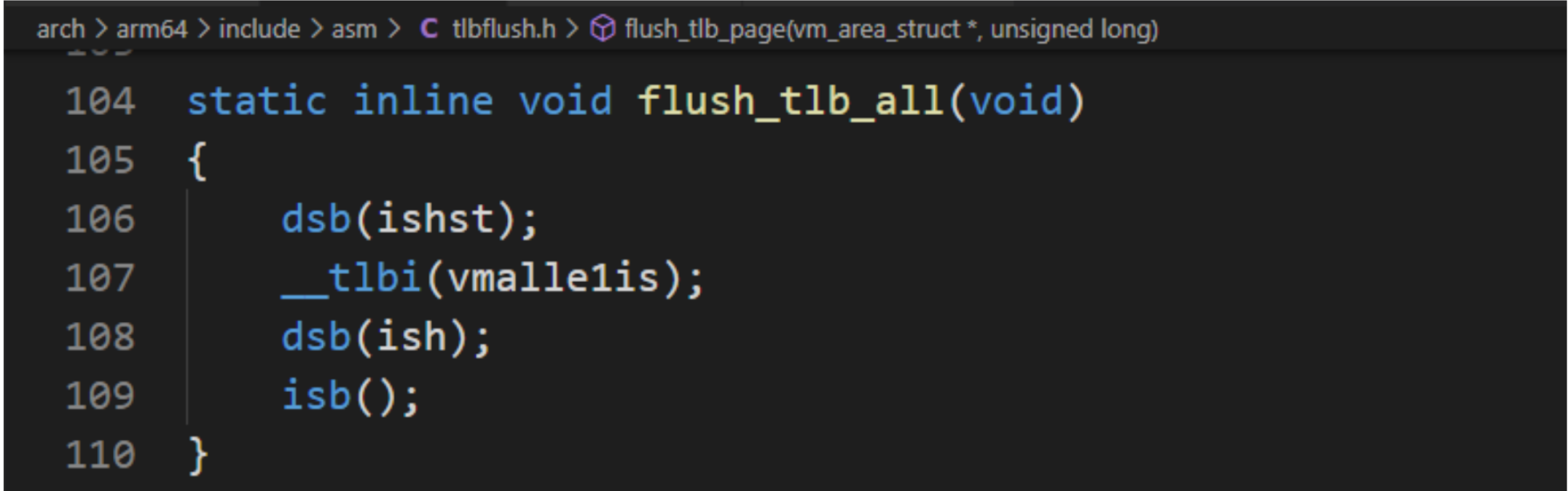
- dsb(ishst):确保屏障前面的存储指令执行完毕,dsb是数据同步屏障,ishst中ish表示共享域是内部共享,st表示存储 ,ishst表示数据同步屏障指令对所有核的存储指令起作用。
- __tlbi(vmalle1is):使用所有核上匹配当前VMID、阶段1和异常级别1的所有TLB表项失效。
- dsb(ish):确保当前的TLB失效指令执行完毕,ish表示数据同步屏障指令对所有核起作用。
- isb():isb是指令同步屏障,这条指令冲刷处理器流水线,重新读取屏障指令后面的所有指令。
4、地址空间标识符
为了减少在进程切换时清空页表缓存的需要,ARM64处理器的页表缓存使用非全局位区分内核和进程的页表项,使用地址空间标识符(Address Space Identifier,ASID)区分不同进程的页表项。
5、虚拟机标识符
虚拟机里面运行的客户OS的虚拟地址转换成物理地址 分为两个阶段:
a.把虚拟地址转换成中间物理地址(由客户操作系统的内核控制,和非虚拟化的转换过程相同);
b.把中间物理地址转换成物理地址(由虚拟机监控器控制,虚拟机监控器为每个虚拟机维护一个转换表,分配一个虚拟机标识符VMID(Virutal machine identifier));
每个虚拟机有独立的ASID空间,页表缓存使用虚拟标识 符区别不同虚拟机转换表项,可以避免每次虚拟机切换都要清空页表缓存,只需要在虚拟机标识符回绕时把处理器的页表缓存清空。
四、页表
层次化的页表用于支持对大地址空间的快速、高效的管理。页表用于建立用户进程的虚拟地址空间和系统物理内存(内存、页帧)之间的关联。页表用来把虚拟页映射到物理页,并且存放页的保护位,即访问权限。Linux内核把页表分为4级:
PGD、PUD、PMD、PT。
- PGD(Page Global Directory)–>页全局目录
- PUD(Page Upper Directory)–>页上层目录
- PMD(Page Middle Directory)–>页中间目录
- PT(Page Table)–>直接页表
4.11以后版本把页表扩展到五级,在页全局目录和页上层目录之间增加了页四级目录(Page 4th Directory,P4D)
选择四级页表:页全局目录、页上层目录、页中间目录、直接页表;
选择三级页表:页全局目录、页中间目录、直接页表;
选择二级页表:页全局目录、直接页表;
处理器架构怎么选择多少级?在内核配置宏CONFIG_PGTABLE_LEVELS配置页表级数,
案例分析五级页表结构如下: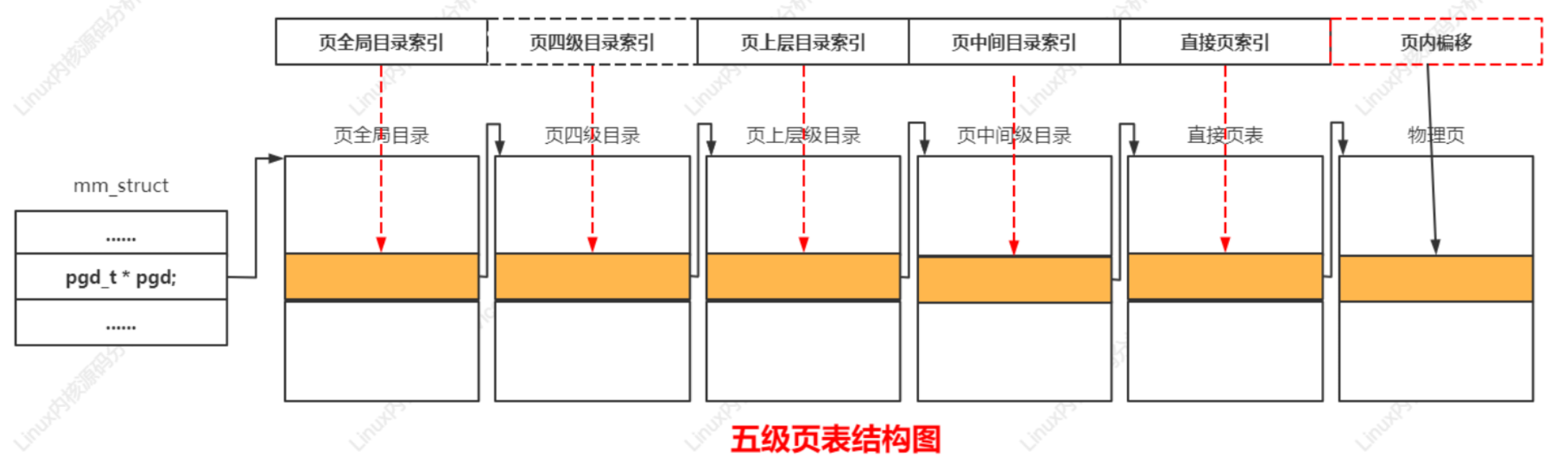
Linux物理内存与虚拟内存管理
一、伙伴分配器
内核初始化完毕后,使用页分配器管理物理页,当前使用的页分配器就是伙伴分配器,伙伴分配器的特点是管理算法简单且高效。
1、基本伙伴分配器
连续的物理页称为页块(page block),阶(order)是页的数量单位,2的n次方个连续页称为n阶页块,满足如下条件的两个n阶页块称为伙伴(buddy)。
1)两个页块是相邻的,即物理地址是连续的;
2)页块的第一页的物理面页号必须是2的n次方的整数倍;
3)如果合并(n+1)阶页块,第一页的物理页号必须是2的括号(n+1)次方的整数倍。
伙伴分配器分配和释放物理页的数量单位也为阶(order)。
以单页为说明,0号页和1号页是伙伴,2号页和3号页是伙伴。1号页和2号页不是伙伴?因为1号页和2号页合并组成一阶页块,第一页的物理页号不是2的整数倍。
分配n阶页块的过程:
a. 查看是否有空闲的n阶页块,如果有,直接分配,如果没有,继续执行下一步;
b. 查看是否存在空闲的(n+1)阶页块,如果有把(n+1)阶页块分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去,如果没有,继续执行下一步;
c. 查看是否存在空闲的(n+2)阶页块,如果有,把(n+2)阶页块分裂为两个(n+1)阶页块,一个插入空闲(n+1)阶页块链表,另一个分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去;如果没有继续查看更高阶是否存在空闲页块。
内核在基本伙伴分配器基础上进一步扩展:
a. 支持内存节点和区域,称为分区的伙伴分配器;
b. 为预防内存碎片,把物理页根据可移动性分组;
c. 针对分配单页做性能优化,为减少处理器之间的锁竞争,在内存区域增加1个每处理器页集合。
2、分区伙伴分配器
内存区域的结构体成员free_area用来维护空闲页块,数组下标对应页块的阶数。结构体free_area的成员free_list是空闲页块的链表,nr_free是空闲页块的数量。内存区域的结构体成员managed_pages是伙伴分配器管理的物理页的数量。
2.1)内存区域数据结构分析如下:
...
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
...
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
......
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
......
/* free areas of different sizes */
// MAX_ORDER是最大阶数, 实际上是可分配的最大除数加1, 默认值是11, 意味伙伴分配器一次 最多可分配2的10次方页
struct free_area free_area[MAX_ORDER];
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;

2.2)区域水线数据结构分析
首选的内存区域在什么情况下从备用区域借用物理页?此问题从区域水线讲解深入理解,每个内存区域有3个水线。
a.高水线(HIGH):如果内存区域的空闲页数大于高水线,说明该内存区域的内存充足;
b.低水线(LOW):如果内存区域的空闲页数小于低水线,说明该内存区域的内存轻微不足;
c.最低水线(MIN):如果内存区域空闲页数小于最低水线,说明该内存区域的内存严重不足。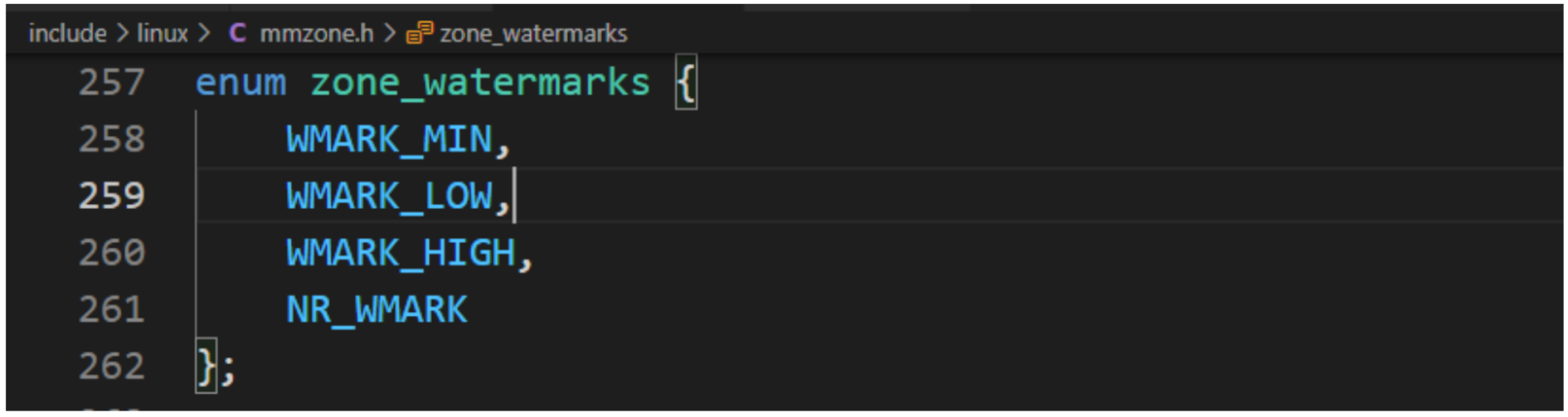
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
......
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
计算水线时,有两个重要的参数:
- min_free_kbytes是最小空闲字节数,默认值是4*pow(lowmem_kbytes, 1/2),并且限制范围是由机器决定。lowmem_kbytes是低端内存大小,单位是kb。
修改最小空闲字节数方式:
cat /proc/sys/vm/min_free_kbytes
- watermark_scale_factor是水线缩放因子,默认值是10,取值范围[1, 1000]
修改水线缩放因子方式:
cat /proc/sys/vm/watermark_cacle_factor
通过函数__setup_per_zone_wmarks()负责计算每个内存区域的最低水线、低水线和高水线。
计算最低水线方法:
min_free_pages=min_free_kbytes对应的页数。
lowmem_pages=所有低端内存区域伙伴分配器管理的页数总和。
高端内存区域最低水线=zone->managed_pages/1024。
低端内存区域最低水线=min_free_pages*zone->managed_pages/lowmem_pages。
计算低水线和高水线方法:
增量=(最低水线/4, managed_pageswatermark_scale_factor/10000) 取得最大值
低水线=最低水线+增量
高水线=最低水线+增量2
如果(最低水线/4)比较大,那么计算公式简化为:
低水线=最低水线5/4
高水线=最低水线3/2
二、Slab/Slub/Slob块分配器
1、基本概念
Buddy提供以page为单位的内存分配接口,这对内核来说颗粒度还太大,所以需要一种新的机制,将page拆分为更小的单位来管理。
Linux中支持的主要有:slab、slub、slob。其中slob分配器的总代码量比较少,但分配速度不是最高效的,所以不是为大型系统设计,适合内存紧张的嵌入式系统。
2、slab块分配器原理
slab分配器的作用不仅仅是分配小块内存,更重要的作用是针对经常分配和释放的对象充当缓存。slab分配器的核心思路是:为每种对象类型创建一个内存缓存,每个内存缓存由多个大块组成,一个大块是由一个或多个连续的物理页,每个大块包含多个对象。slab采用面向对象的思想,基于对象类型管理内存,每种对象被划分为一类,比如进程描述符task_struct是一个类,每个进程描述符实例是一个对象。如下图所示为内存缓存的组成结构: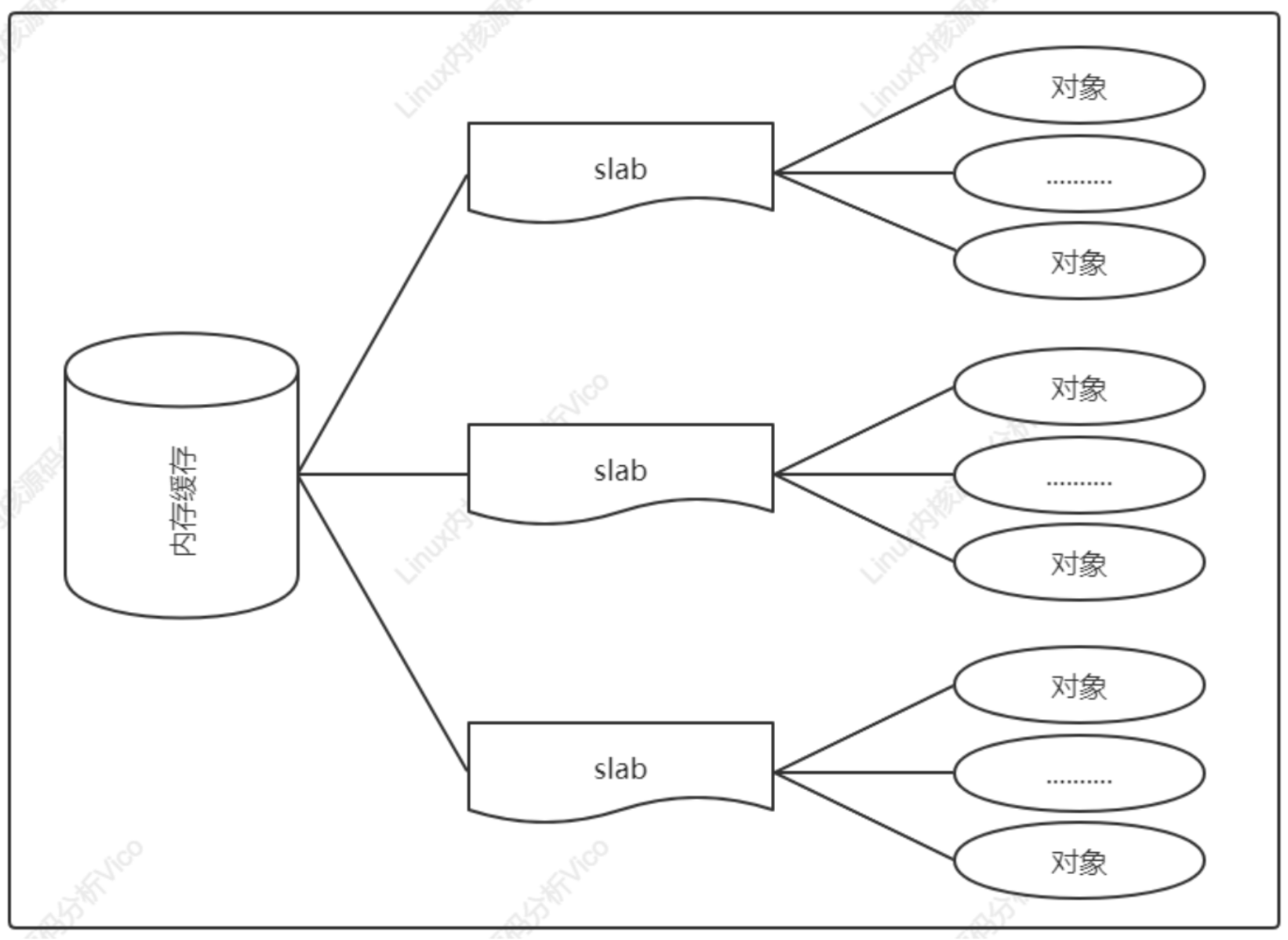
slab分配器在某些情况下表现不太优先,所以Linux内核提供两个改进的块分配器。
- 在配备大量物理内存的大型计算机上,slab分配器的管理数据结构的内存开销比较大,所以设计了slub分配器;
- 在小内存的嵌入式设备上,slab分配器的代码过多、相当复杂,所以设计一个精简slob分配器。
目前slub分配器已成为默认的块分配器。
3、系统编程接口
通用的内存缓存的编程接口如下:
a. 分配内存kmalloc;
kmalloc(size_t size,gfp_t flags)
b. 重新分配内存krealloc;
krealloc(const void *p,size_t new_size,gpf_t flags)
c. 释放内存kfree;
kfree(const void *objp)
创建专用的内存缓存编程接口如下:
a. 创建内存缓存kmem_cache_create
b. 指定内存缓存分配kmem_cache_alloc
c. 释放对象kmem_cache_free
d. 销毁内存缓存keme_cache_destroy
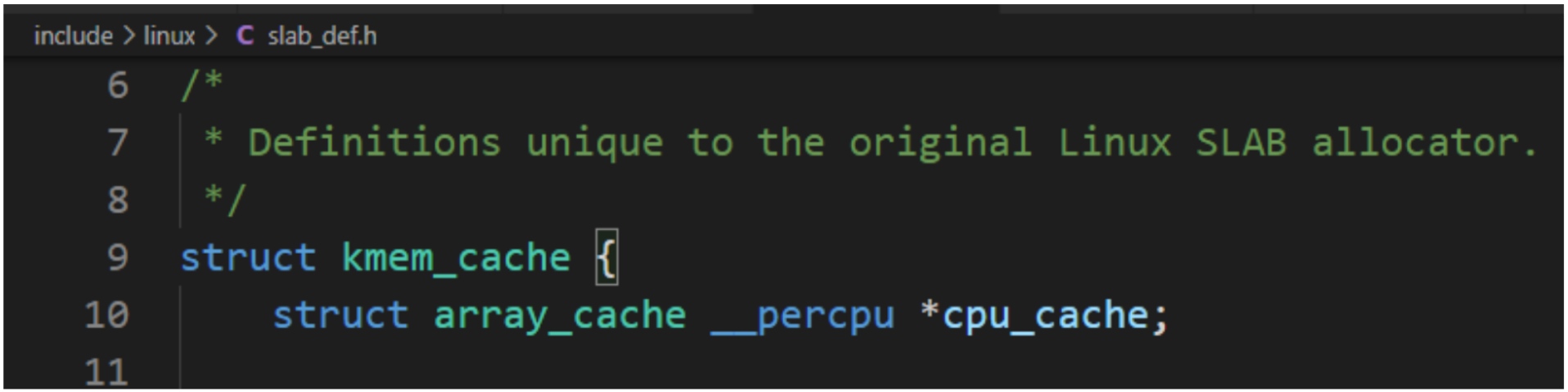
4、内存缓存的数据结构
内存缓存的数据结构如下图所示: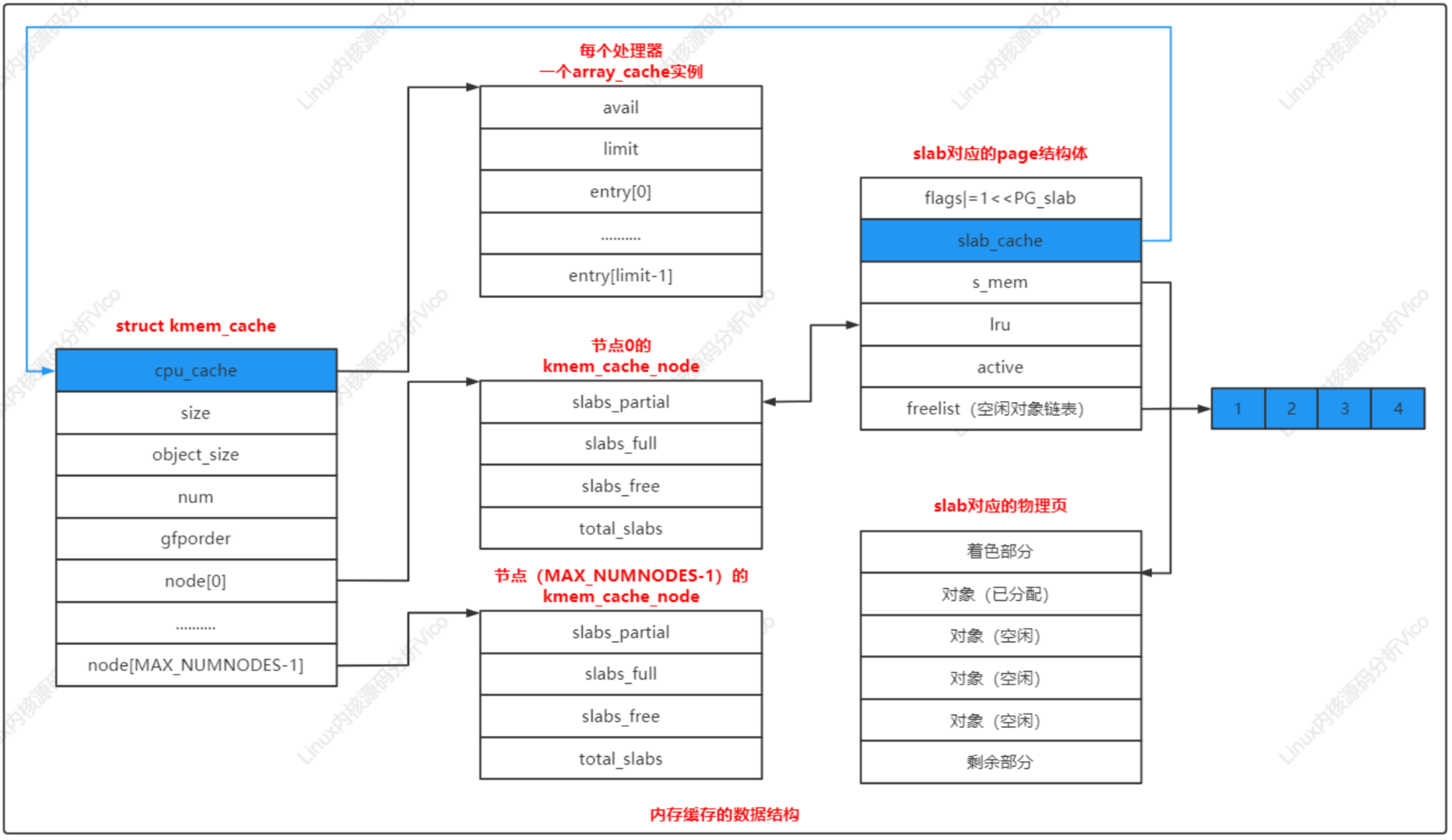
slab分配器 数据结构
a. 每一个内存缓存对应一个kmem_cache实例
b. 每一个内存节点对应一个kmem_cache_node实例
每个slab由一个或多个连续的物理页组成,页的阶数是kmem_cache.gfporder,如果阶数大于0,组成一个复合页,slab被划分为多个对象,大多数情况下slab长度不是对象长度的整数倍,slab有剩余部分,可以用来给slab进行着色。着色:把slab的第一个对象从slab的起始位置偏移一个数值,偏移值是处理器的一级缓存行长度的整数倍,不同slab的偏移值不同,使用不同slab的对象映射到处理器不同的缓存行。
5、计算slab长度及着色
a. 计算slab
函数calculate_slab_order负责计算slab长度,从0阶到kmalloc()函数支持最大阶数KMALLOC_MAX_ORDER。
如果阶数大于或等于允许的最大slab阶数,那么选择这个阶数,尽量选择低的阶数,因为申请高阶页块成功的概率低。如果剩余长度小于或等于slab长度的1/8,那么选择这个阶数。slab_max_order:允许的最大slab阶数,如果内存容量大于32MB,那么默认值是0,否则值为0,通过内核参数slab_max_order指定。
b.着色
slab是一个或多个连续的物理页,起始地址总是页长度的整数倍,不同slab中相同偏移的位置在处理器一级缓存中的索引相同。如果slab的剩余部分的长度超过一级缓存行的长度,剩余部分对应的一级缓存行没有被利用;如果对象的填充字节的长度超过一级缓存行的长度,填充字节对应的一级缓存行没有被利用。这两种情况导致处理器的某些缓存行被过度使用,另一些缓存行很少使用。
6、每处理器数组缓存
内存缓存为每个处理器创建一个数组缓存(结构体array_cahce)。释放对象时,把对象存放到当前处理器对应的数组缓存中;分配对象的时候,先从当前处理器的数组缓存分配对象,采用后进先出(Last In First Out,LIFO)的原则,这种做可以提高性能。
每处理器数组缓存:
- 刚释放的对象很可能还在处理器缓存中,可以更好地利用处理器缓存
- 减少链表操作
- 避免处理器之间的互斥,减少自旋锁操作
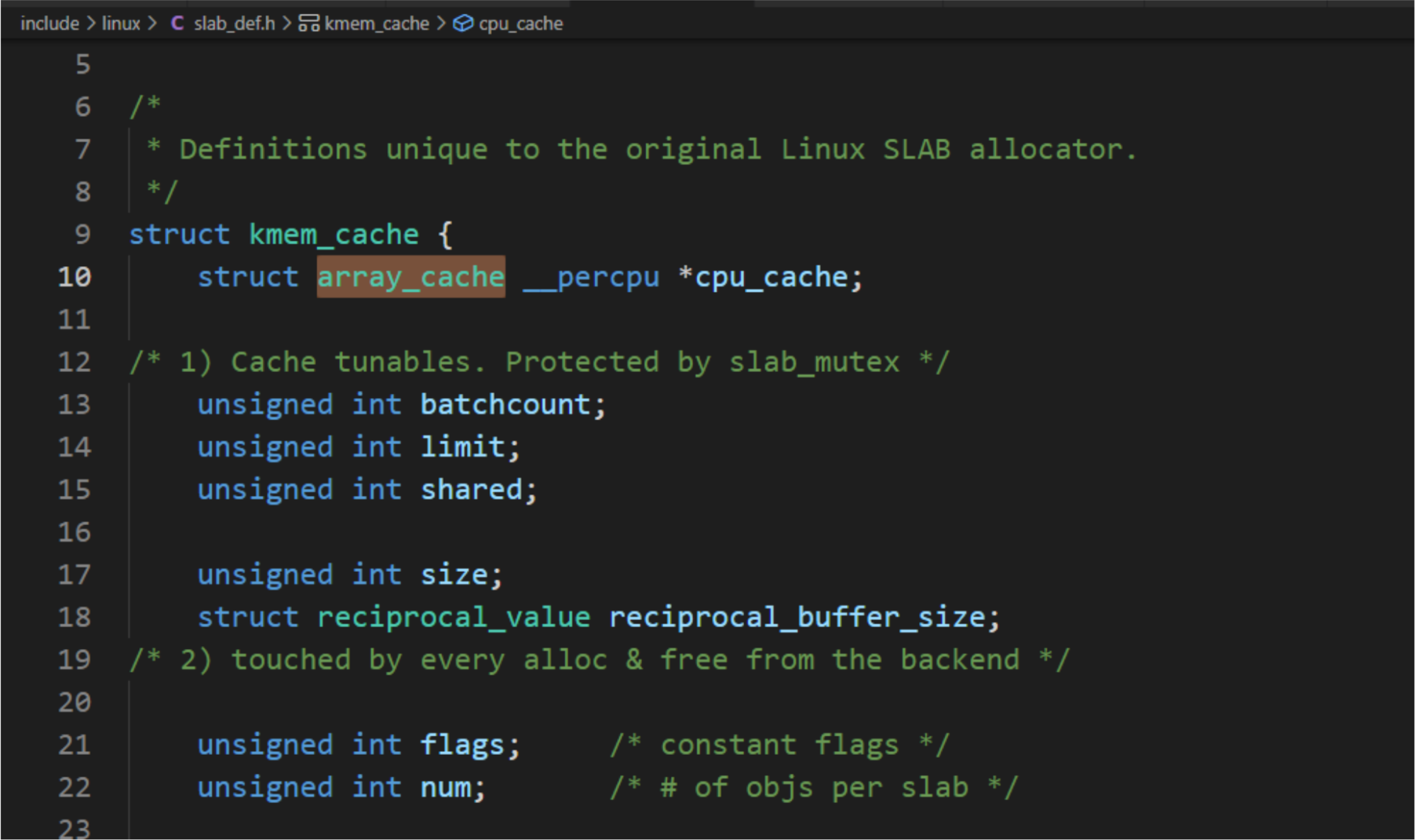
struct array_cache {
unsigned int avail; //数组存放的对象的数量
unsigned int limit; //数组的大小, 和结构体kmem_cache成员limit值相同, 根据对象长度猜测一个值
unsigned int batchcount; //批量值, 和结构体kmem_cache成员batchcount值相同, 批量值是数组大小的一半
unsigned int touched;
void *entry[]; /*
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
};
7、slab分配器支持NUMA体系结构
内存缓存针对每个内存节点创建一个kmem_cache_node实例。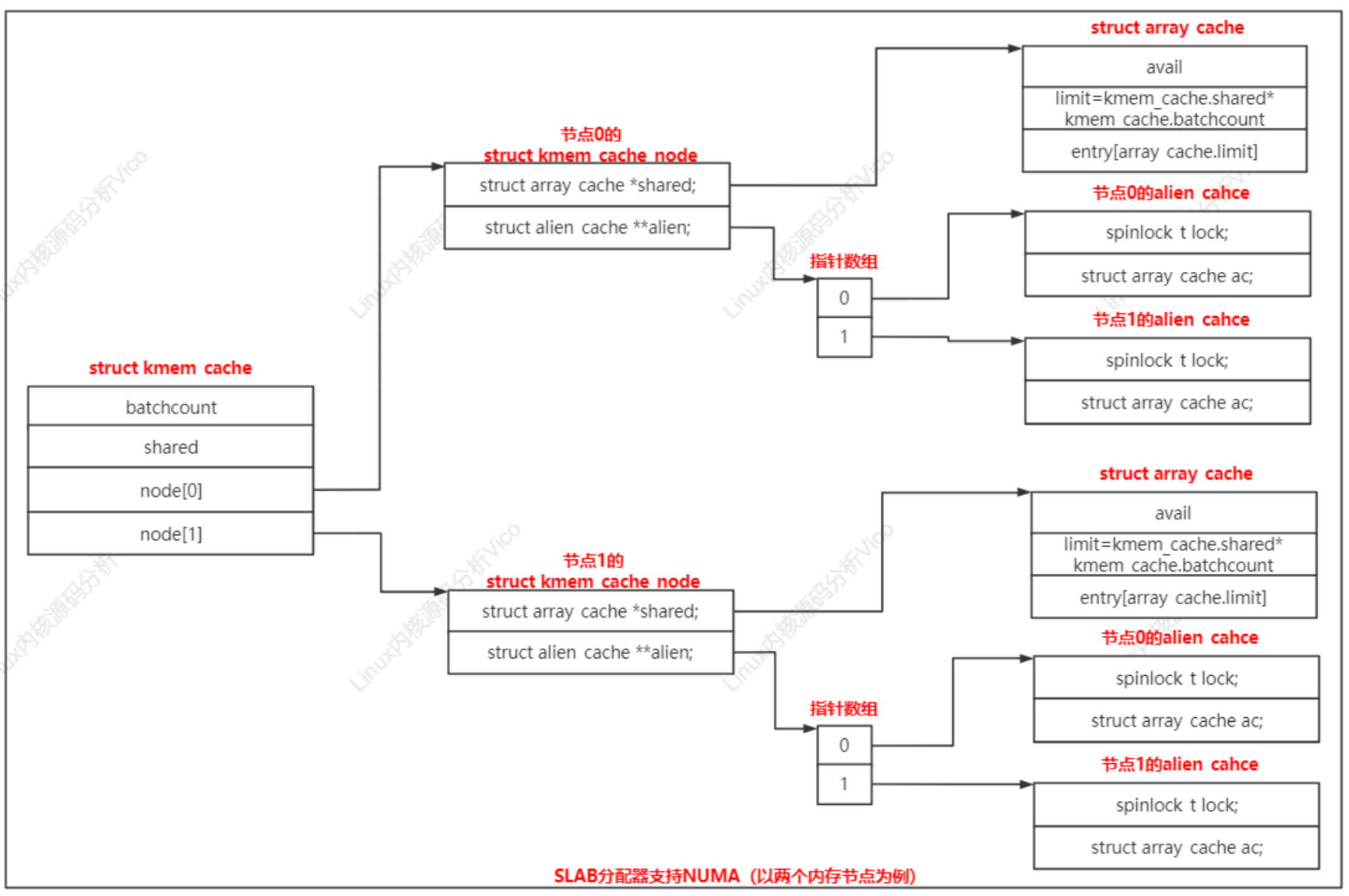
struct kmem_cache {
......
struct kmem_cache_node *node[MAX_NUMNODES];
};
kmem_cache_node实例的成员shared指向共享数组缓存,成员alien指向远程节点数组缓存,每个节点一个远程节点数组缓存。
分配和释放本地内存节点的对象时,也会使用共享数组缓存
a. 申请分配对象时,如果当前处理器的数组缓存是空的,共享数组缓存里面的对象可以用来重填;
b. 释放对象时,如果当前处理器的数组缓存是满的,并且共享数组缓存有空闲空间,可以转移一部分对象到共享数组缓存,不需要把对象批量还给slab,然后把正在释放的对象添加到当前处理器的数组缓存中。
8、回收内存
对于所有对象空闲的slab,没有立即释放,而是放在空闲slab链表中。只有内存节点上空闲对象的数量超过限制,才开始回收空闲slab,直到空闲对象的数量小于或等于限制。
结构体kmem_cache_node的成员slabs_free是空闲slab链表的头节点,成员free_objects是空闲对象的数量,成员free_limit是空闲对象的数量限制。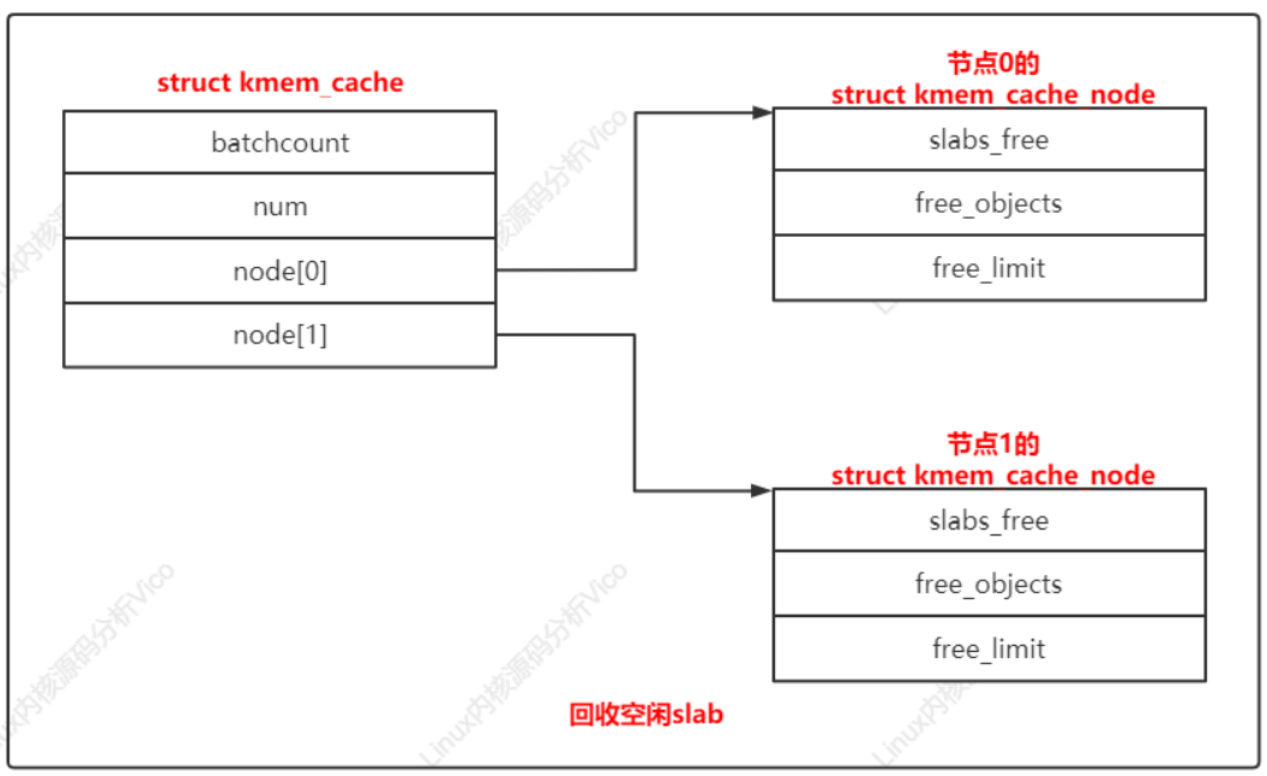
节点x的空闲对象的数量限制=(1+节点的处理器数量)*keme_cache.batchcount+kmem_cache.num
每个处理器每隔2秒针对每个内存缓存执行
a. 回收节点x对应的远程节点数组缓存中的对象
b. 如果过去2秒没有从当前处理器的数组缓存分配对象,那么回收数组缓存中的对象。
三、不连续页分配器
当设备长时间运行后,内存碎片化,很难找到连续的物理页。在这种情况下,如果需要分配长度超过一页的内存块,可以使用不连续页分配器,分配虚拟地址连续但是物理地址不连续的内存块。在32位系统中不连续分配器还有一个好处:优先从高端内存区域分配页,保留稀缺的低端内存区域。
1、系统编程接口
a.不连续页分配器提供的编程接口:
- vmalloc:分配不连续的物理页并且把物理页映射到连续的虚拟地址空间
- vfree:释放vmalloc分配的物理页和虚拟地址空间
- vmap:把已经分配的不连续物理页映射到连续的虚拟地址空间
- vunmap:释放使用vmap分配的虚拟地址空间
b.内核提供函数接口:
- kvmalloc:首先尝试使用kmalloc分配内存块,如果失败,那么使用vmalloc函数分配不连续的物理页
- kvfree:如果内存块是使用vmalloc分配的,那么使用vfree释放,否则使用kfree释放
2、数据结构
不连续页分配器的数据结构关系如下: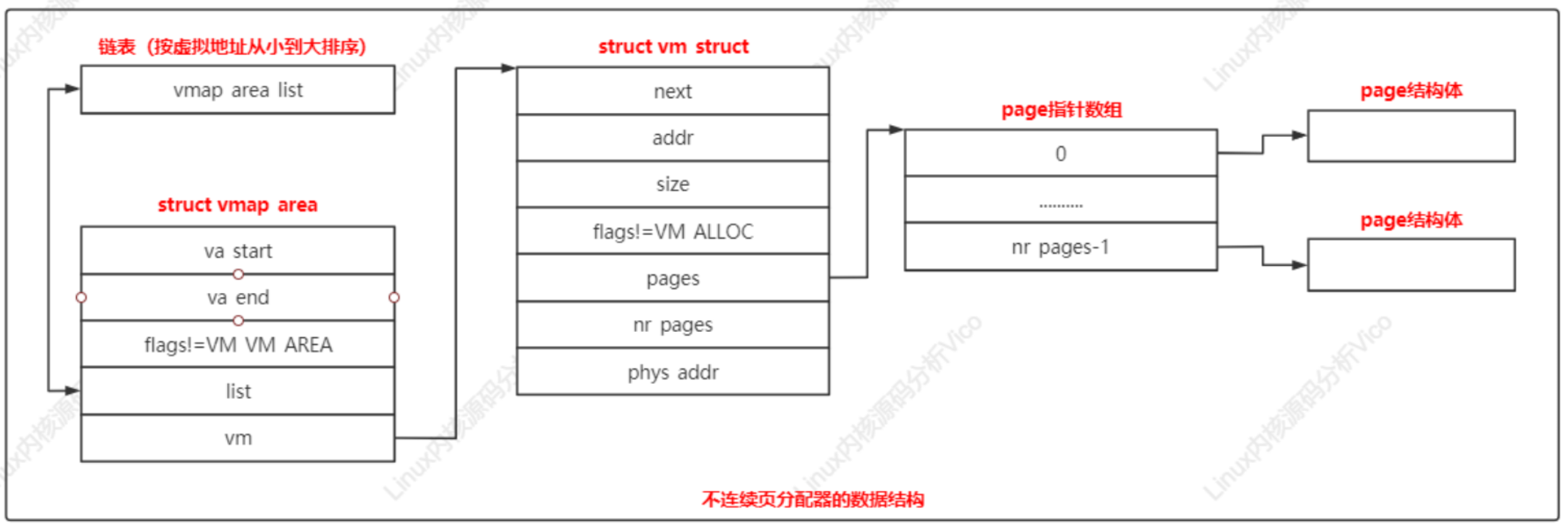

每个虚拟内存区域对应一个vmap_area实例;
每个vmap_area实例关联一个vm_struct实例;
3、技术原理
vmalloc虚拟地址空间的范围是(VMALLOC_START,VMALLOC_END),每种处理器架构都需要定义这两个宏。如ARM64架构定义宏如下:
vmalloc函数执行过程:
a.分配虚拟内存区域
b.分配物理页
c.在内核的页表中把虚拟页映射到物理页
Linux虚拟内存及API系统调用
一、内存映射原理与创建/删除映射
内存映射是在进程的虚拟地址空间中创建一个映射,可为分两种:
- 文件映射:文件支持的内存映射,把文件的一个区间映射到进程的虚拟地址空间,数据源是存储设备上的文件。
- 匿名映射:没有文件支持的内存映射,把物理内存映射到进程的虚拟地址空间,没有数据源。
通常把文件映射的物理页称为文件页,把匿名映射的物理页称为匿名页。
【内存映射原理】
a. 创建内存映射的时候,在进程的用户虚拟地址空间中分配一个虚拟内存区域。
b. Linux内核采用延迟分配物理内存的策略,在进程第一次访问虚拟页的时候,产生缺页异常。如果是文件映射,那么分配物理页,把文件指定区间的数据讲到物理页中,然后在页表中把虚拟页映射到物理页;如果是匿名映射,那么分配物理页,然后在页表中把虚拟页映射到物理页。
根据修改是否其他进程可见和是否传递到底层文件,内存映射分为共享映射和私有映射:
共享映射:修改数据时映射相同区域的其他进程可以看见,如果是文件支持的映射,修改会传递到底层文件;
私有映射:第一次修改数据时会从数据源复制一个副本,然后修改副本,其他进程看不见,不影响数据源;
两个进程可以使用共享的文件映射实现共享内存。匿名映射通常是私有映射,共享的匿名映射只有出现在父进程和子进程之间。在进程的虚拟地址空间中,代码段和数据段是私有的文件映射,未初始化数据段、堆栈是私有的匿名映射。
1、应用编程接口
内存管理子系统提供系统调用:
- mmap():用来创建内存映射;
- mremap():用来扩大或缩小已经存在的内存映射,可能同时移动;
- munmap():用来删除内存映射;
- brk():用来设置堆的上界;
- remap_file_pages():用来创建非线性的文件映射,即文件区间和虚拟地址空间之间的映射不是线性关系,现在这些新版已将删除;
- mprotect():用来设备虚拟内存区域的访问权限;
- madvise():用来向内核提出内存使用的建议,应用程序告诉内核期望怎么样使用指定的虚拟内存区域, 以方便内核可以选择合适的预读和缓存技术。
在内核空间中可以使用两个函数:
- remap_fpn_range():把内存的物理页映射到进程的虚拟地址空间,这个函数的用处是实现进程和内核共享内存。
- io_remap_pfn_range():把外设寄存器的物理地址映射到进程的虚拟地址空间,进程以直接访问外设寄存器。
1、系统调用mmap():进程创建匿名的内存映射,把内存的物理页映射到进程的虚拟地址空间;进程把文件映射到进程的虚拟地址空间,可以像访问内核一样访问文件,不需要调用系统调用read()/write()访问文件 ,从页避免用户模式和内核模式之间的切换,提高读写文件速度。两个进程针对同一个文件 创建共享的内存映射,达到共享内存。调用此函数成功:返回虚拟地址,否则返回负的错误号。
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);
addr:起始虚拟地址,如果addr为0,内核选择虚拟地址,否则内核把这个参数作为提示,在附近选择虚拟地址;
length: 映射的长度,单位是字节;
prot:保护位
PROT_EXEC(页可执行)
PROT_READ(页可读)
PROT_WRITE(页可写)
PROT_NONE(页不可访问)
flags:标志
MAP_SHARED(共享映射)
MAP_PRIVATE(私有映射)
MAP_ANONYMOUS(匿名映射)
MAP_FIXED(固定映射)
MAP_LOCKED(把页锁在内存中)
MAP_POPULATE(填充页表,即分配并且映射到物理页,如果是文件映射,该标志导致预读文件 )
fd:文件描述符:仅当创建文件映射的时候,此参数才有意义。
offset:偏移,单位是字节,必须是页长度的整数倍。
int munmap(void *addr, size_t length);
2、系统调用mprotect():用来设置虚拟内存区域的访问权限。
#include <sys/mman.h>
int mprotect(void *addr, size_t len, int prot);
addr:起始虚拟地址,必须是页长度的整数倍
len:虚拟内存区域的长度,单位是字节
prot:保护位
PROT_NONE:页不可以访问
PROT_READ:页可读
PROT_WRITE:页可写
PROT_EXEC:页可执行
调用此函数:如果成功返回0,否则返回负的错误号。
2、数据结构
虚拟内存区域是分配给进程的一个虚拟地址范围,内核使用结构体vm_area_struct描述虚拟内存区域。具体内核源码如下:
//虚拟内存区域结构体类型
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */ //起始地址
unsigned long vm_end; /* The first byte after our end address_space-//结束地址
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
// 虚拟内存区域链表, 按起始地址排序
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb; //红黑树节点
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */ //指向内存描述符, 即虚拟内存区域所属的用户虚拟地址空间
pgprot_t vm_page_prot; /* Access permissions of this VMA. */ //保护位, 即访问权限
unsigned long vm_flags; /* Flags, see mm.h. */ //标志
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
// 为了支持查询一个文件区间被映射到哪些虚拟内存区域, 把一个文件映射到的所有虚拟内存区域加入到该文件的地址空间结构体address_space的成员i_mmap指向的区间树
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
// 把虚拟内存区域关联的所有anon_vma实例串联起来, 一个虚拟内存区域会关联到父进程的anon_vma实例和自己自己的anon_vma实例
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */ //指向一个anon_vma实例, 结构体anon_vma用来组织匿名页被映射到的所有虚拟地址空间。
/* Function pointers to deal with this struct. */
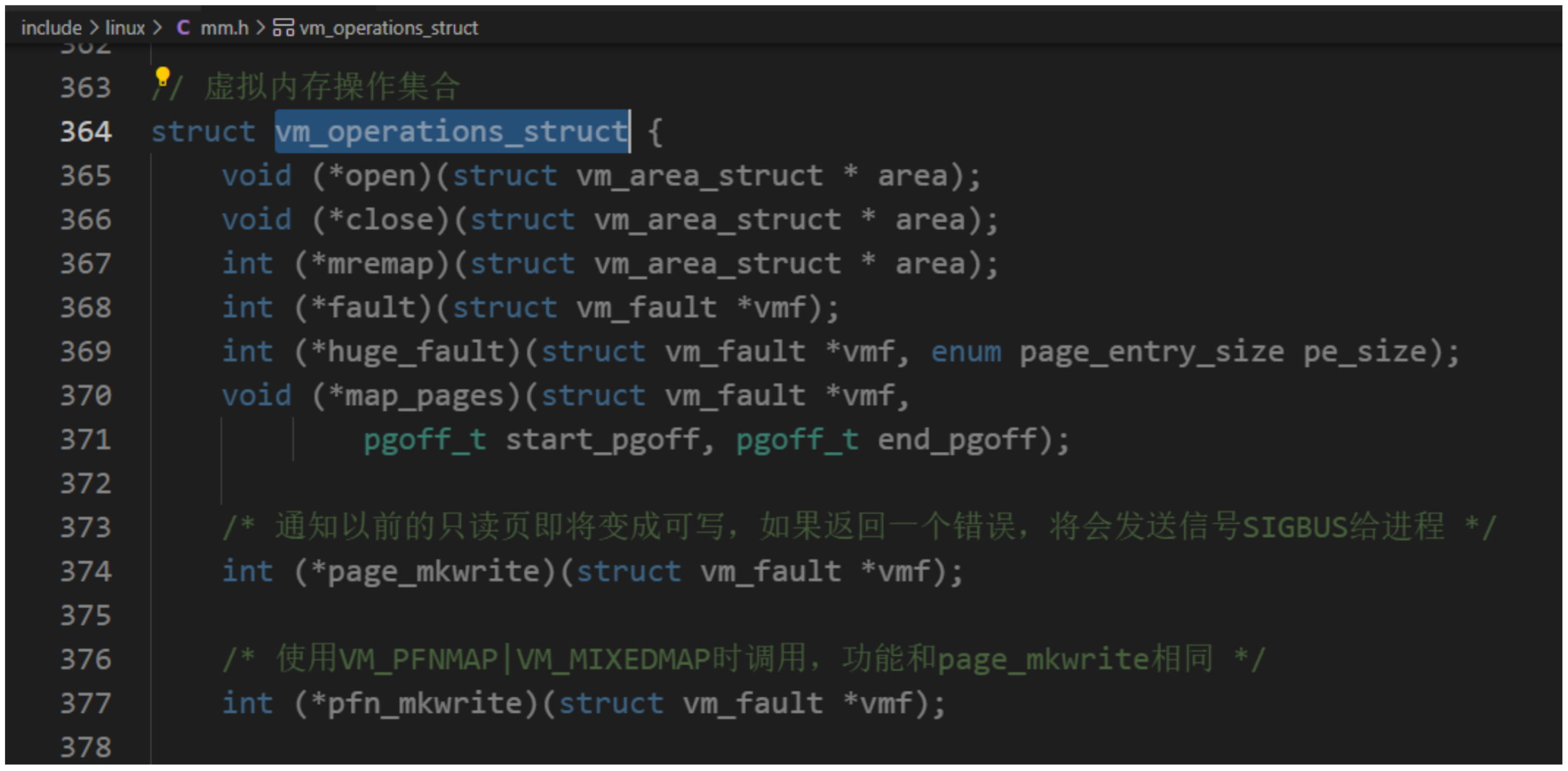
const struct vm_operations_struct *vm_ops; //虚拟内存操作集合
/* Information about our backing store: */
// 文件偏移, 单位为页
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */ //文件, 如果是私有的匿名映射, 成员是空指针
void * vm_private_data; /* was vm_pte (shared mem) */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
};
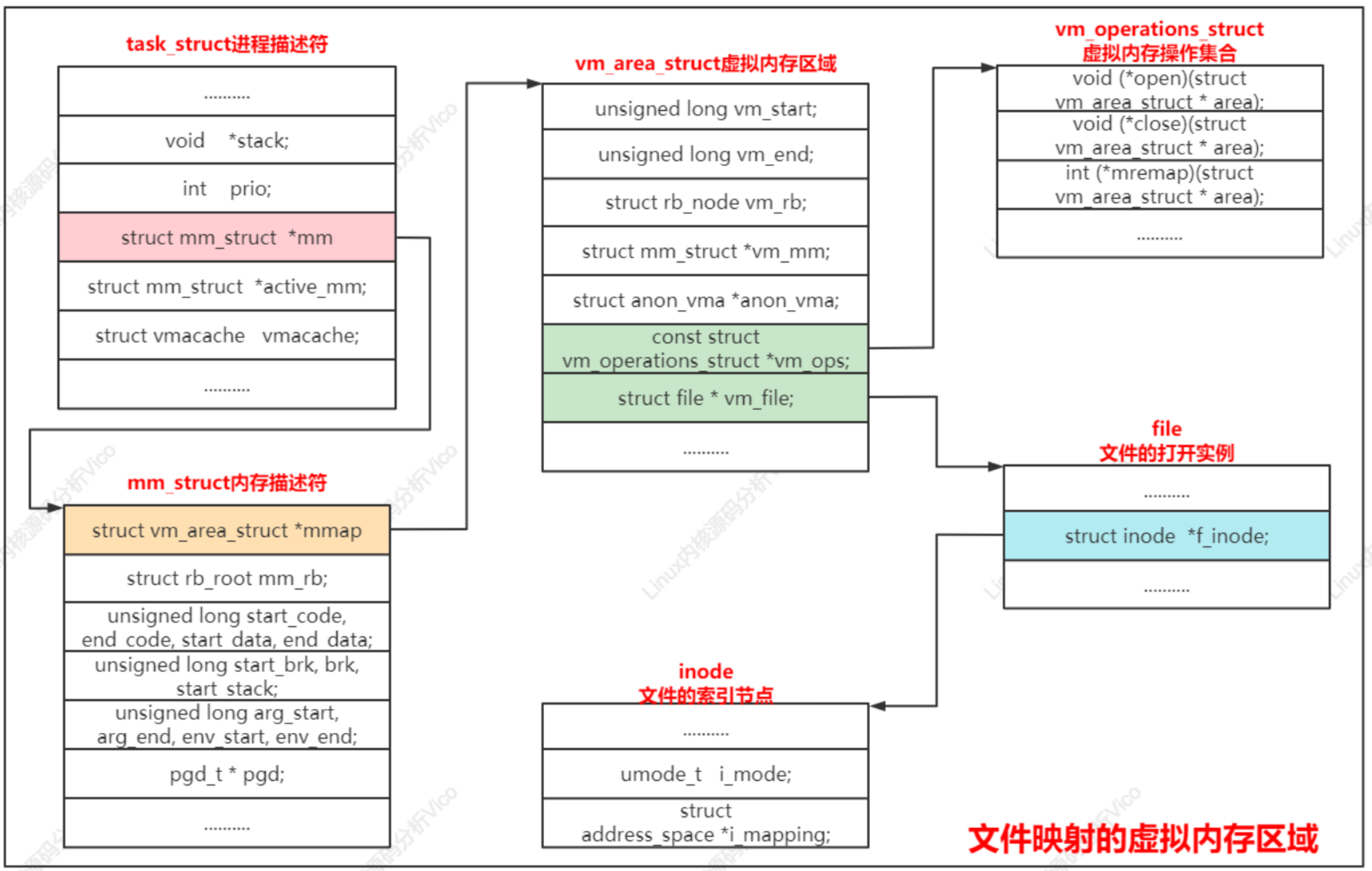
虚拟内存区域的标志:结构体vm_area_struct成员vm_flags存放虚拟内存区域的标志:
3、创建内存映射
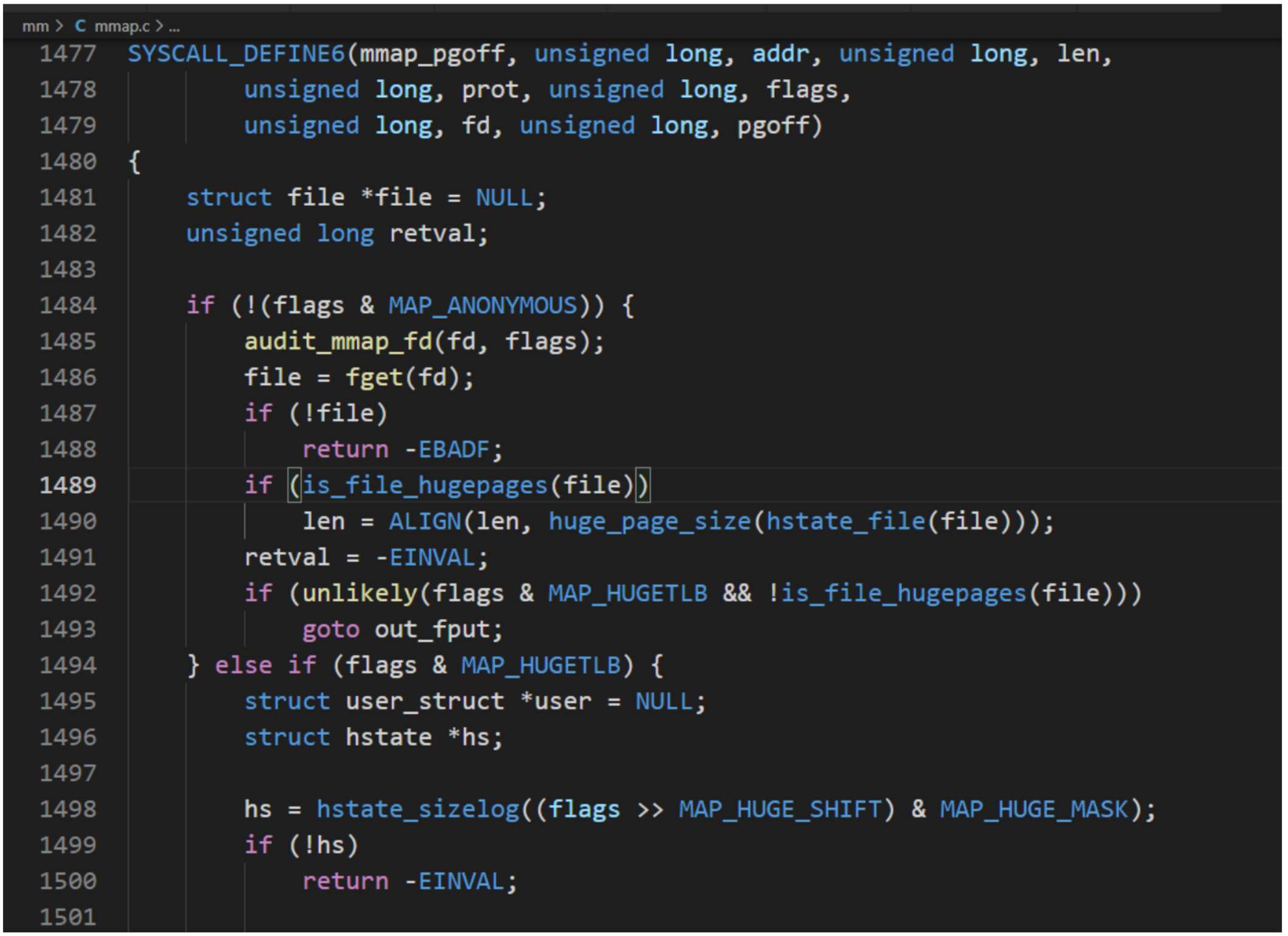
C标准库封装函数mmap用来创建内存映射,内核提供POSIX标准定义系统调用mmap。系统调用执行流程:
- 检查偏移是不是页的整数倍,如果偏移不是页的整数倍,则返回“-EINVAL”。
- 如果偏移是页的整数倍,那么把偏移转换成以页为单位的偏移,然后调用函数sys_mmap_pgoff。

函数sys_mmap_pgoff和函数do_mmap执行流程如下: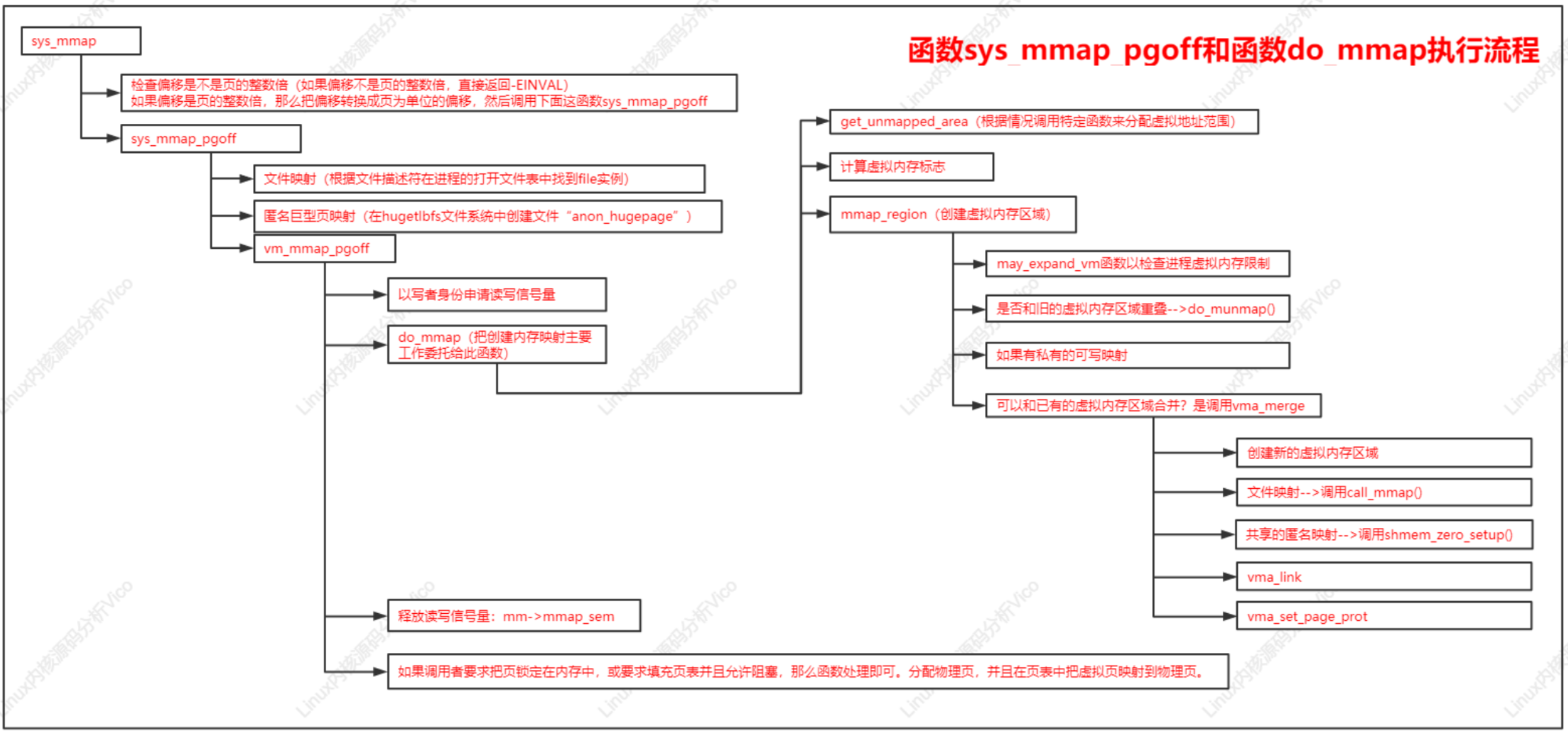
4、删除内存映射
系统调用munmap用来删除内存映射,它有两个参数:起始地址和长度。系统调用munmap的执行流程,主要把工作委托给源文件“mm/mmap.c"中的函数do_munmap。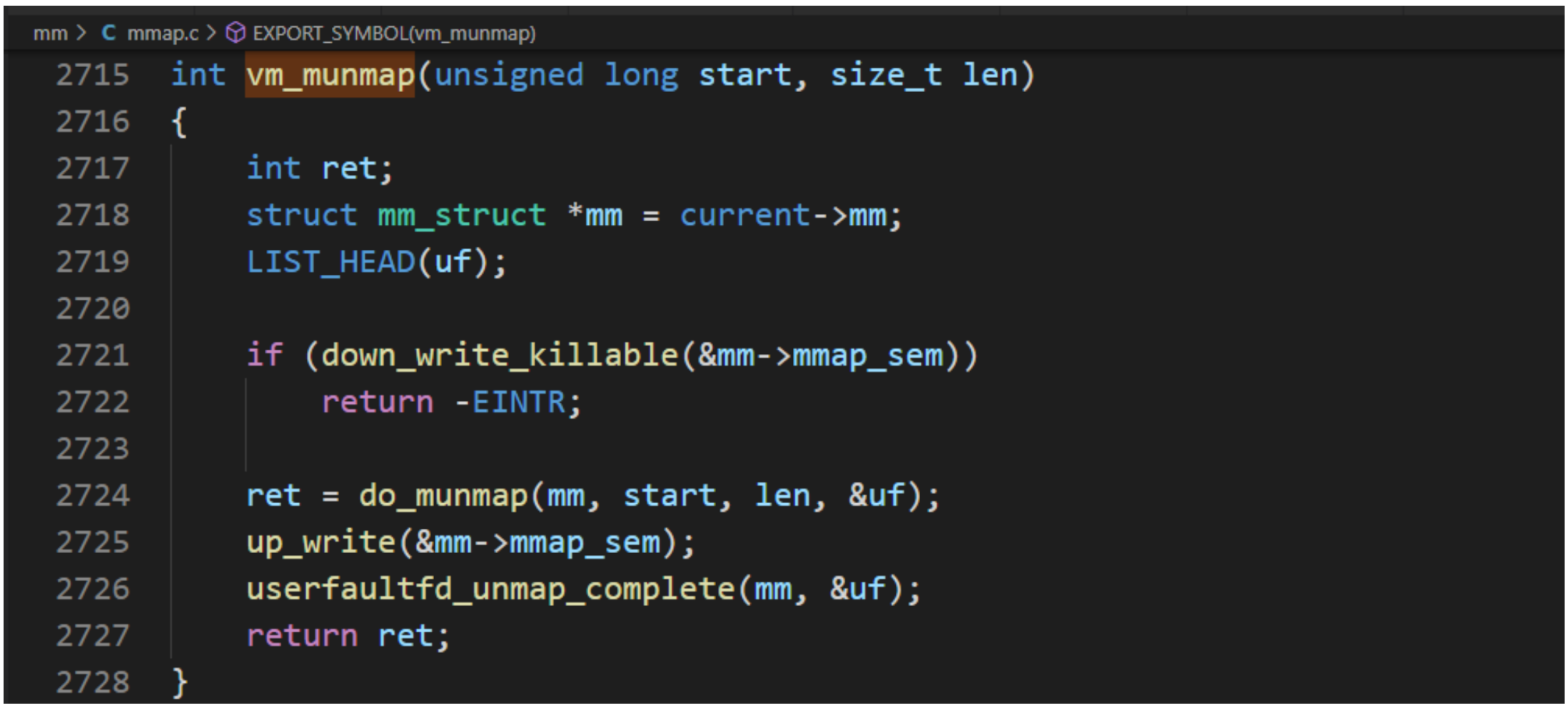
系统调用munmap执行流程如下: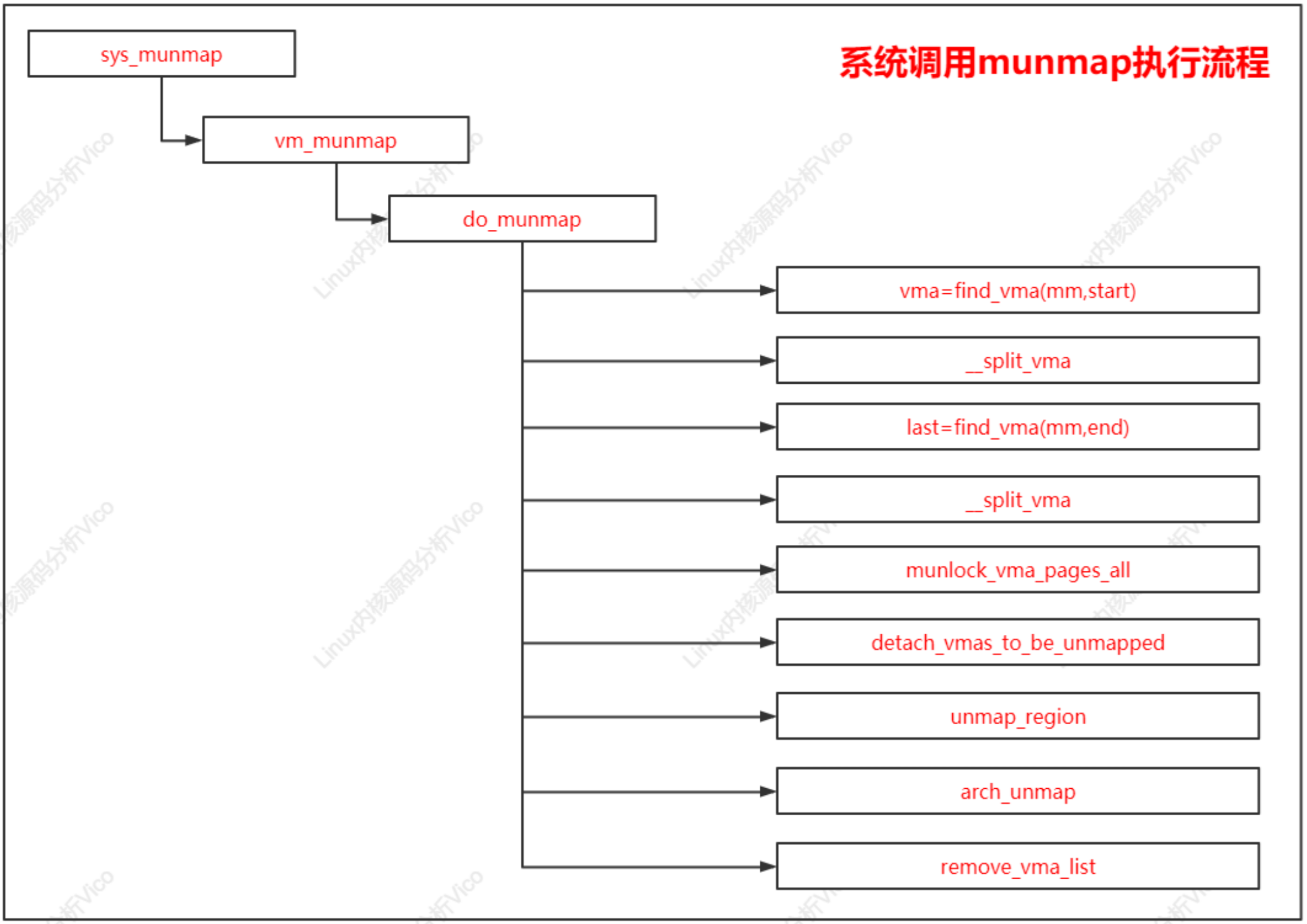
二、物理内存组织结构
1、体系结构
非一致内存访问(Non-Uniform Memory Access,NUMA):指内存被划分成多个内存节点的多处理器系统,访问一个内存节点花费的时间取决于处理器和内存节点的距离。
对称多处理器(Symmetric Multi-Processor, SMP):即一致内存访问(Uniform Memory Access,UMA),所有处理器访问内存花费的时间是相同的。
在实际应用中可以采用混合体系结构,在NUMA节点内部使用SMP体系。
2、内存模型
内存模型是从处理器的角度看到的物理内存分布情况,内核管理不同内存模型的方式存在差异。内存管理子系统支持3种内存模型:
- 平坦内存(Flat Memory):内存的物理地址空间是连续,没有空洞。
- 不连续内存(Discontiguous):内存的物理地址空间存储空洞,这种模型可以高效地处理空洞。
- 稀疏内存(Sparse Memory):内存的物理地址空间存储空洞。如果支持内存热插拔,只能选择稀疏内存模型。
什么情况下会出现内存的物理地址空间存在空洞?
如果内存的物理地址空间存在空洞,应该选择那种内存模型?
3、三级结构(内存节点/内存区域/物理页)
内存管理子系统使用节点(node)、区域(zone)和页(page)三级结构描述物理内存。
a、内存节点(内存节点分成2种情况)
- NUMA系统的内存节点,根据处理器和内存的距离划分。
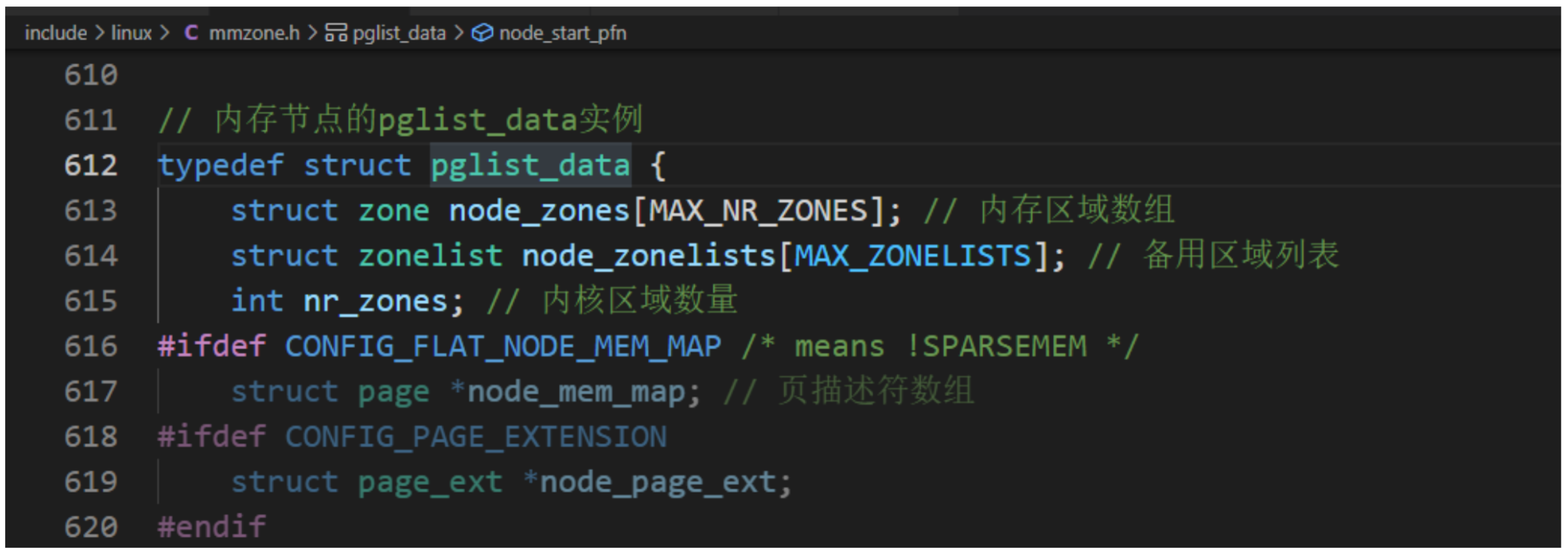
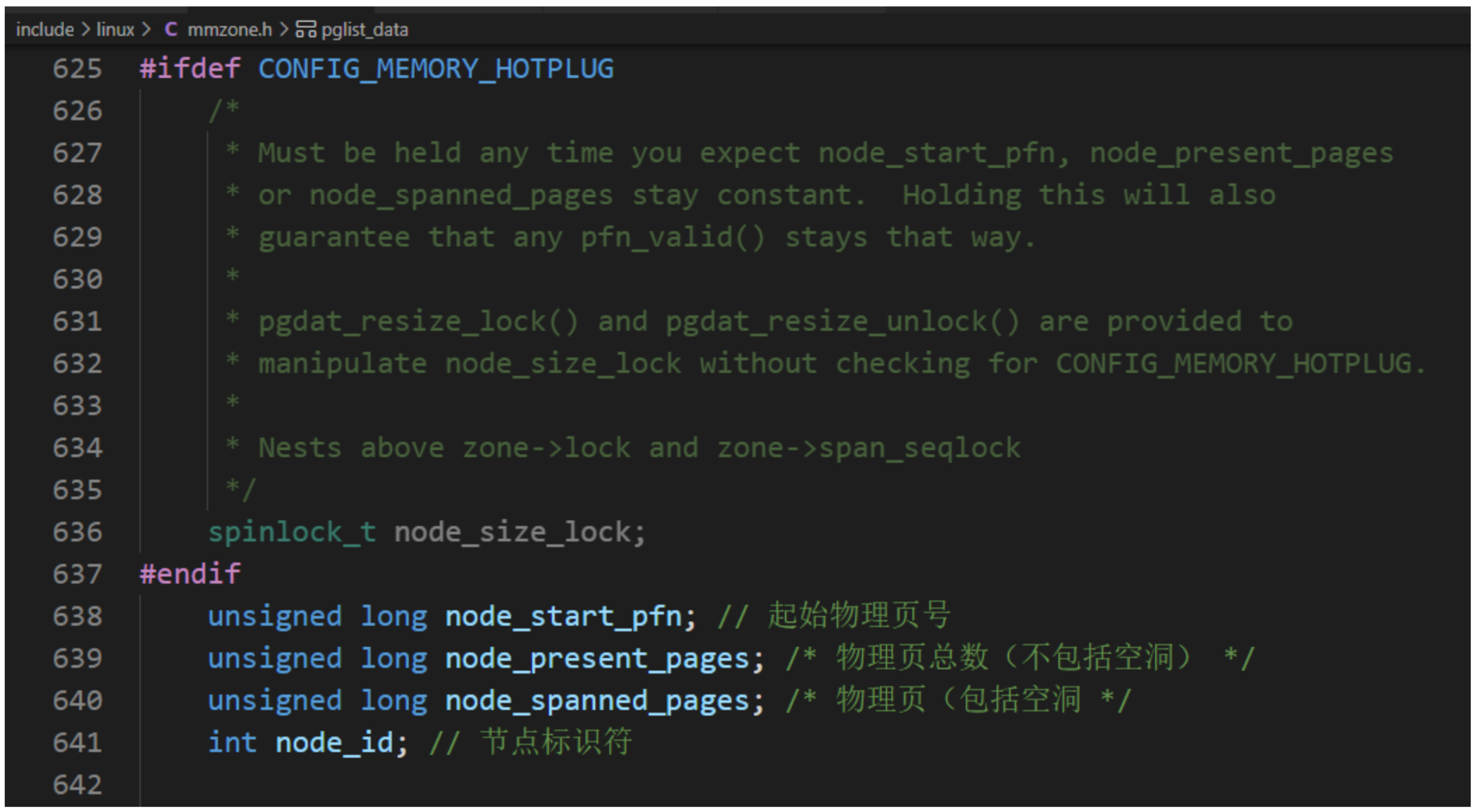
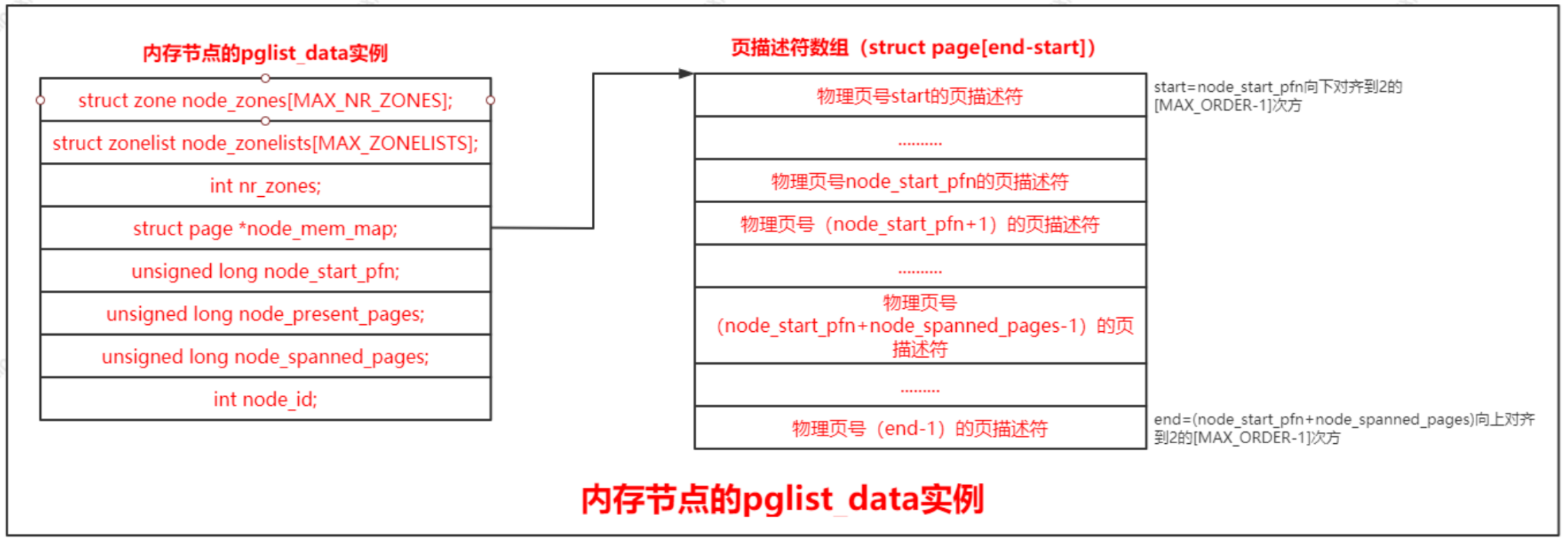
- 在具有不连续的内存的UMA系统中,表示比区域的级别更高的内存区域,根据物理地址是否连续划分,每块物理地址连续的内存是一个内存节点。内存节点使用一个pglist_data结构体描述内存布局。对于平坦内存模型,只有一个pglist_data实例
b、内存区域
内存节点被划分为内存区域,内核定义区域类型如下:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
- ZONE_DMA:直接内存访问;
- ZONE_DMA32:64位系统,如果既要支持只能直接访问16MB以下内存设备,又要支持只能直接访问4GB以下的内存的32位设备,那么必须使用DMA32区域。
- ZONE_NORMAL:直接映射到内核虚拟地址空间的内存区域,又称为直接映射区域,或者叫线性映射区域。ARM处理器需要使用页表映射,MIPS不需要页表映射。
- ZONE_HIGHMEM高端内存区域,DMA/DMA32/ZONE_NORMAL统称低端内存区域。
- ZONE_MOVABLE:它是一个伪内存区域,用来防止内存碎片。
- ZONE_DEVICE:支持持久内存热插拔增加的内存区域。
每个内存区域用一个zone结构体描述,其内核源码如下:
struct zone {
/* Read-mostly fields */
/* 区域水线,使用宏访问 */
unsigned long watermark[NR_WMARK]; // 页分配器使用水线
unsigned long nr_reserved_highatomic;
// 页分配器使用,当前区域保留多少页不能借给高的区域类型
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
// 指向内存节点的pglist_data实例
struct pglist_data *zone_pgdat;
// 每处理器集合
struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn; // 当前区域的起始物理页号
unsigned long managed_pages; // 伙伴分配器管理 的物理页的数量
unsigned long spanned_pages; // 当前区域跨越的总页数,包括空洞
unsigned long present_pages; // 当前区域存在的物理页的数量,不包括空洞
const char *name; // 区域名称
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
// MAX_ORDER最大除数,实际上是可分配的最大除数加1,默认值是11,
// 意味伙伴分配器一次最多可分配2的10次方页
struct free_area free_area[MAX_ORDER]; // 不同长度的空闲区域
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
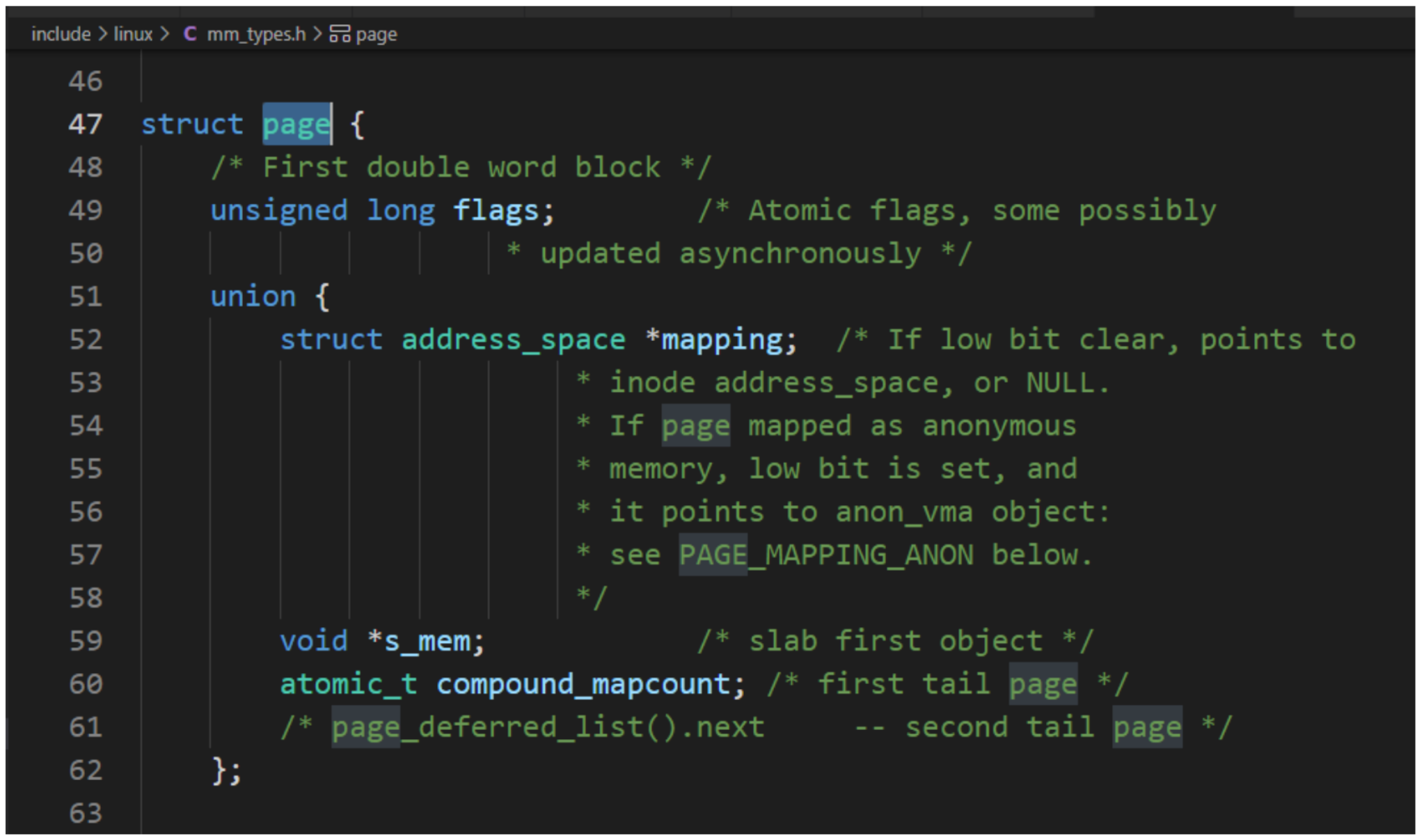
c、物理页
每个物理页对应一个page结构体,称为页描述符,内存节点的pglist_data实例的成员node_mem_map指向该内存节点包含的所有物理页的页描述符组成的数据。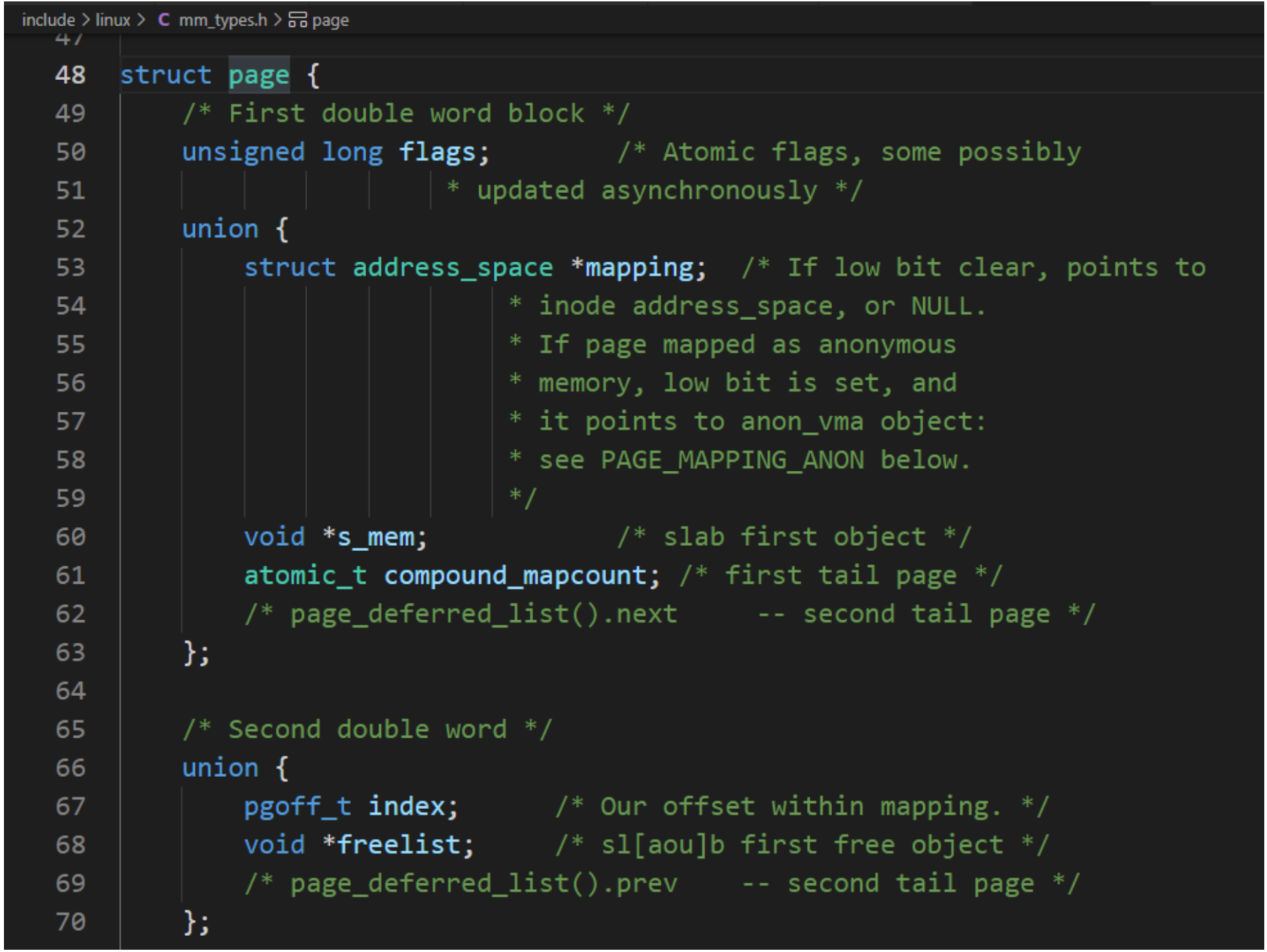
因物理页的数量很大,所以在page结构体中增加1成员,可能导致所有page实例占用的内存大幅度增加。为了减少内存消耗,内核努力使page结构体尽可能小,对于不会同时生效的成员,使用联合体,这种做法带来的负面影响是page结构体的可读性差。
三、系统调用kmalloc/vmalloc(内核内存),malloc()分配用户的内存
1、kmalloc():用于申请较小的、连续的物理内存;
void * kmalloc (size_t size, gfp_t flags);
2、vmalloc():用于申请较大的内存空间,虚拟内存是连续的。
void *vmalloc(unsigned long size);
Linux 块设备运行原理
一、资源管理
首先掌握管理资源的数据结构和函数。
1、树数据结构
Linux 提供了一个通用构架,用于在内存中构建数据结构。这些结构描述了系统中可用的资源,使得内核代码能够管理和分配资源。注意,其中关键的数据结构是resource,定义如下:
树型结构中的资源管理如下: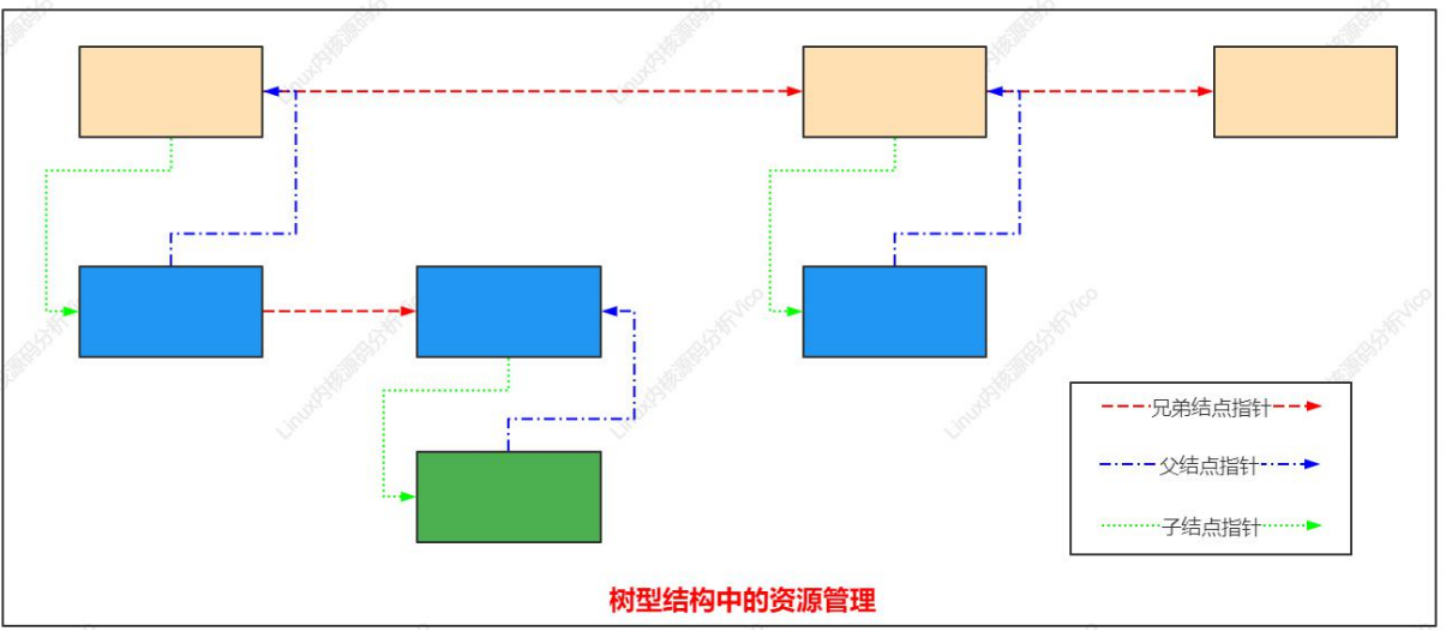
用于连接parent、child、sibling成员的规则:
- 每个子节点只有一个父节点;
- 一个父节点可以有任意数目的子结点;
- 同一个父节点的所有的子节点,会连接到兄弟节点链表上;
2、请求资源和释放资源
为确保可靠地配置资源(无论何种类型),内核必须提供一种机制来分配和释放资源。一旦资源已经分配,则不能由任何其他驱动程序使用。请求和释放资源,无非是从资源树中添加和删除项而已。
**请求资源 **
内核提供了__request_resource 函数,用于请求一个资源区域。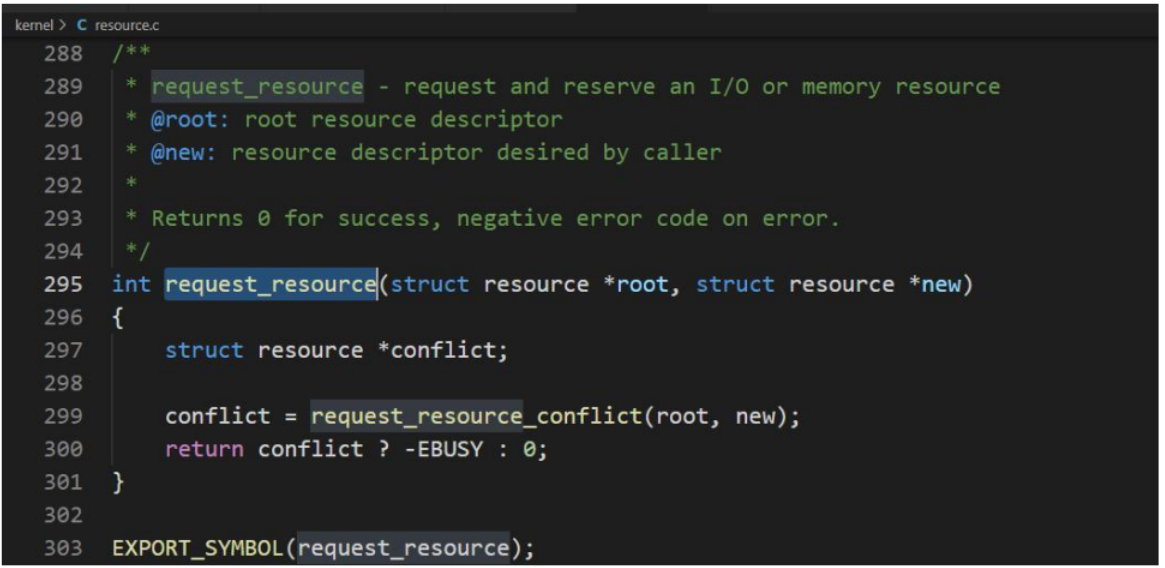
**释放资源 **
调用 release_resource 函数释放使用中的资源。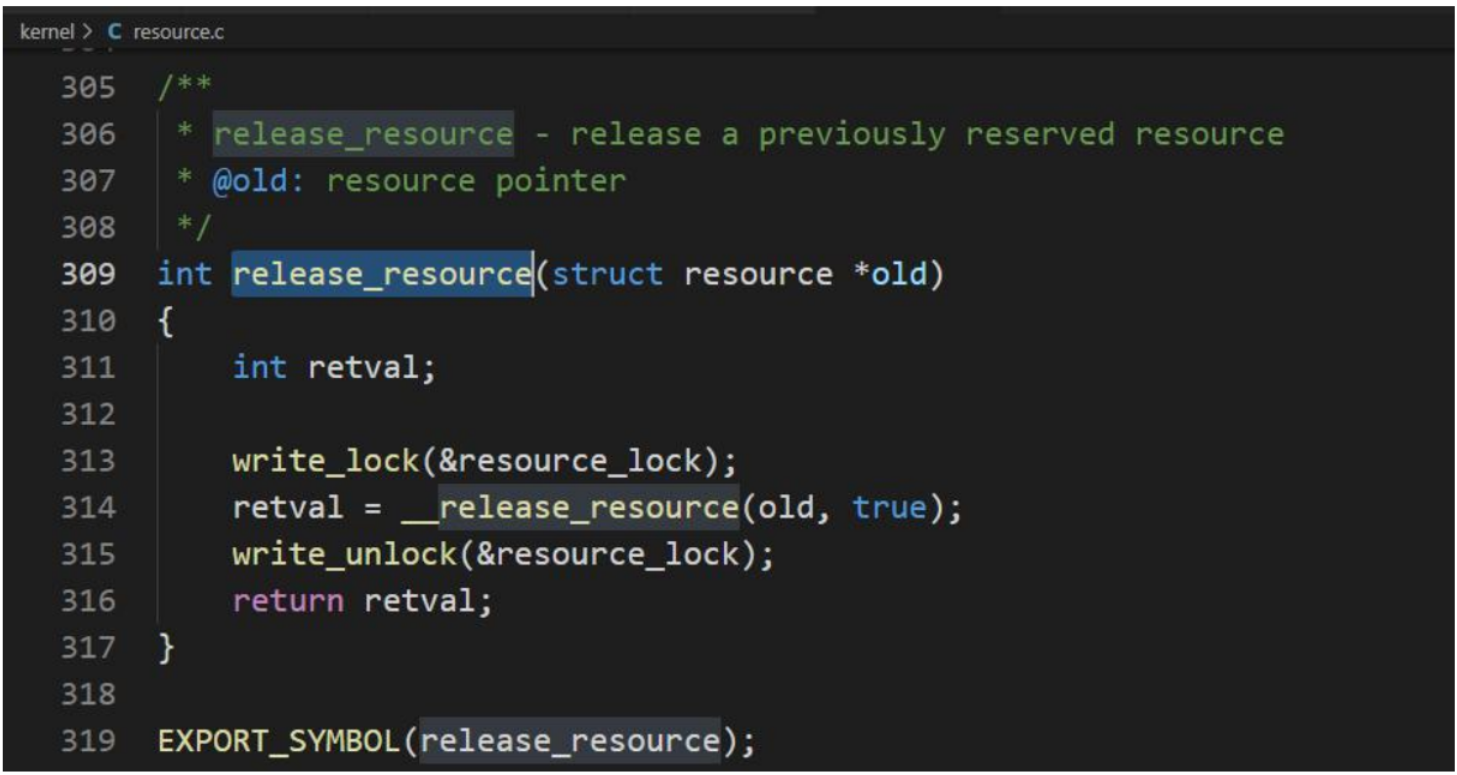
二、BIO 结构
在给出 BIO 的准确定义之前,最好先讨论其原理,如下图所示。BIO 的主要管理结构(bio)关联到一个向量(即数组),各个数组项都指向一个内存页(切记:不是页在内存中的地址,而是对应于该页帧的 page实例)。这些页用于从设备接收数据、向设备发送数据。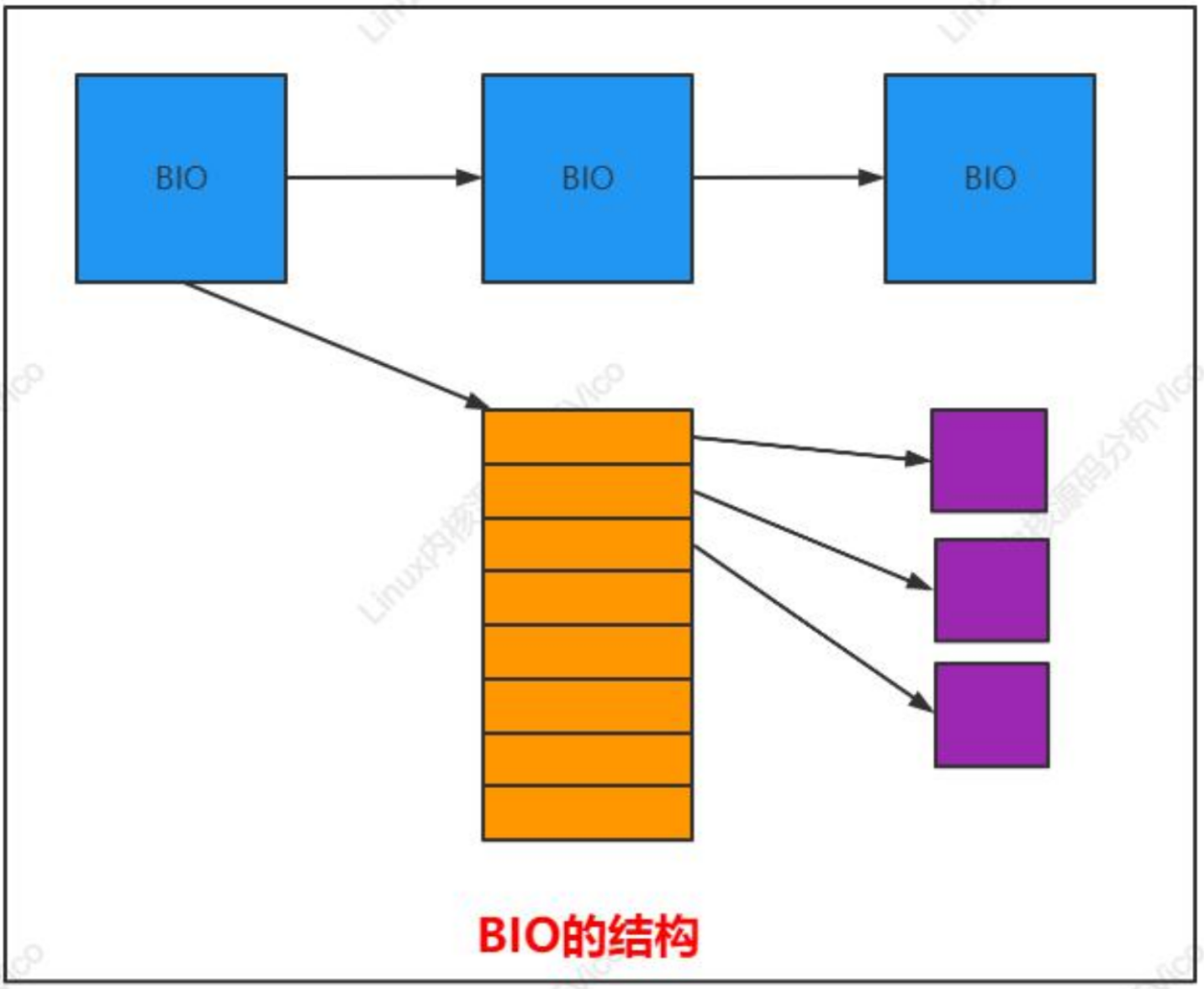
BIO 在内核源码数据结构定义如下
各个数组元素的结构的定义:
bio_vec(
bio_page(指向用于数据传输的页对应page实例)
bio_len(指向用于数据的字节数目)
bio_offset(页内的偏移量)
)
三、I/O 调度
内核采用的各种用于调度和重排 I/O 操作的算法,称之为 I/O 调度器(对比通常的进程调度器,或网络中控制通信数据量的数据包调度器)。通常,I/O 调度器也称作电梯(elevator)。它们由下列数据结构中的一组函数表示: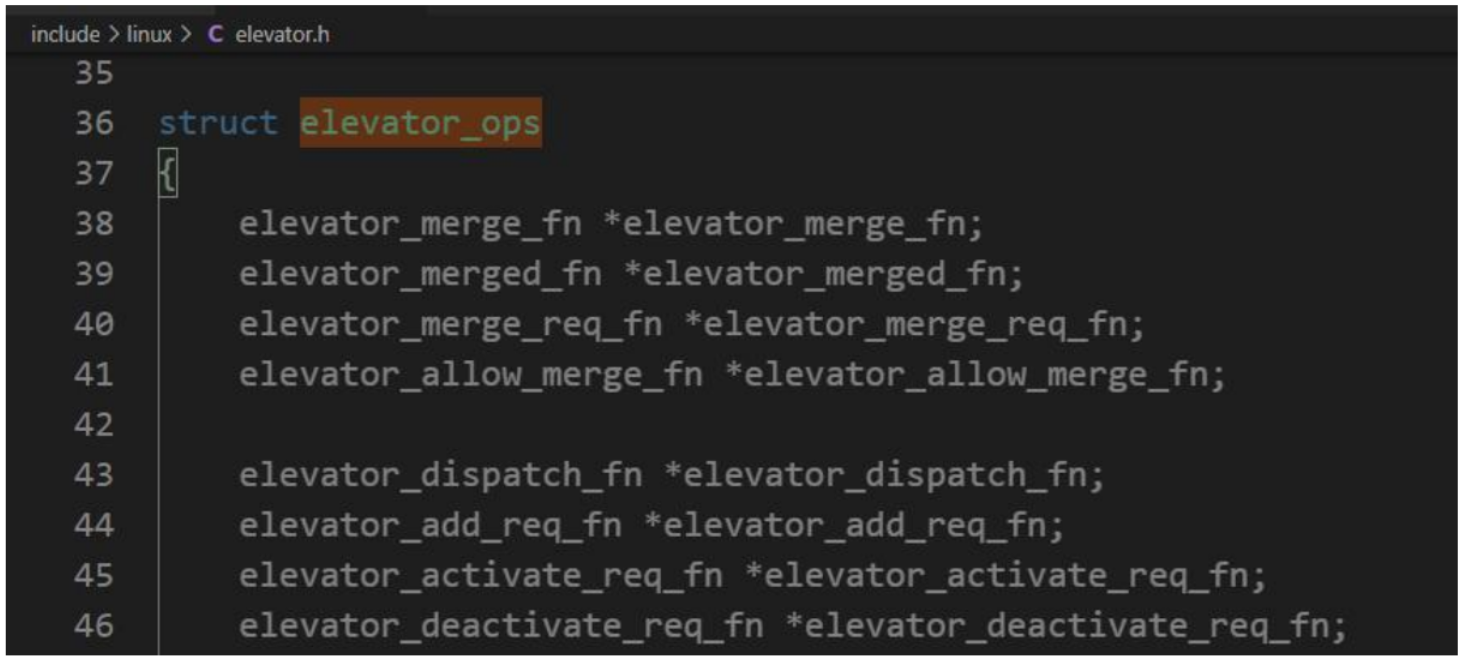
每个 I/O 调度器都封装在下列数据结构中,其中还包含了供内核使用的其他信息:
内核将所有I/O调度器在一个标准的双链表中维护,链表元素是list成员
四、PCI 总线原理
1、系统总结知识
系统总线上传送的信息包括数据信息、地址信息、控制信息,因此,系统总线包含有三种不同功能的总 线 , 即数 据 总 线 DB ( Data Bus ) 、地 址 总 线 AB (Address Bus)和控制总线 CB(Control Bus)。
数据总线(Data Bus):将CPU的数据传送到存储器或IO接口等等部件,也可以将其他部件数据传送到CPU。
地址总线(Address Bus):专门传送地址的,由于地址只能从CPU传向外部存储器或IO端口,所以地址总线是单向三态的。比如:地址总线为n位,寻址空间为2的n次方个地址空间(存储单元)。
控制总线(Control Bus):用来传送控制信号和时序信号。
2、系统总线工作原理
系统总线在微型计算机中的地位,如同人的神经中枢系统,CPU 通过系统总线对存储器的内容进行读写,同样通过总线,实现将 CPU 内数据写入外设,或由外设读入 CPU。微型计算机都采用总线结构。总线就是用来传送信息的一组通信线。微型计算机通过系统总线将各部件连接到一起,实现了微型计算机内部各部件间的信息交换。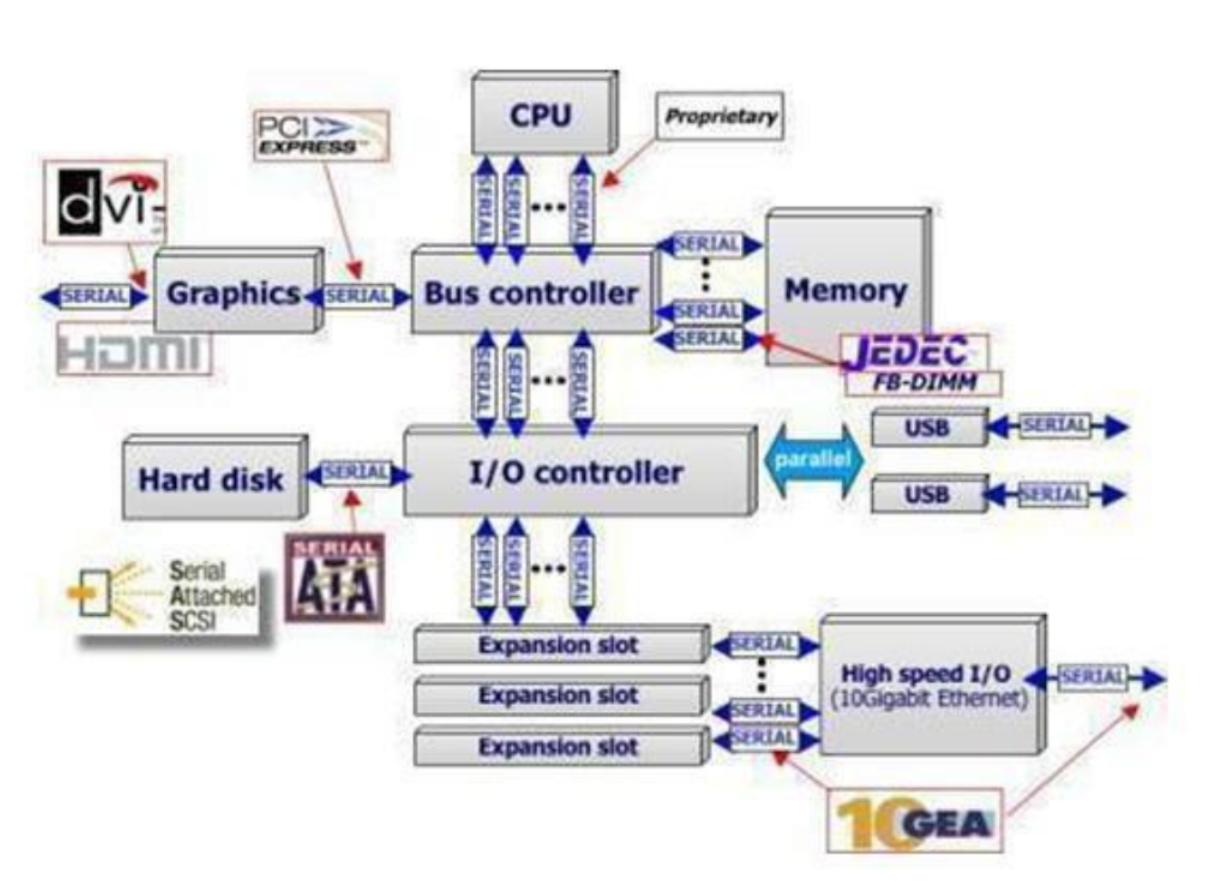
3、PCI 总线
PCI(peripheral component interconnect)总线是当前最流行的总线之一,它是由 Intel 公司推出的一种局部总线。它定义了 32 位数据总线,且可扩展为 64 位。 PCI 总线主板插槽的体积比原 ISA 总线插槽还小,其功能比 VESA、ISA 有极大的改善,支持突发读写操作,最大传输速率可达 132MB/s,可同时支持多组外围设备。PCI 局部总线不能兼容现有的 ISA、EISA、MCA(micro channel architecture)总线,但它不受制于处理器,是基于奔腾等新一代微处理器而发展的总线。
PCI 总线规定了以下设计目标:
- 支持高传输带宽,以适应具有大数据流的多媒体应用。
- 简单且易于自动化配置附接的外设。
- 平台独立性,即不绑定到特定的处理器类型或系统平台。
PCI系统的布局(内核中PCI):
设备标识(系统某个PCI总线上每个设备。都由一组3个编号标识)
总线编号:设备所在总线的编号,0-255
插槽编号:总线内核的一个唯一标识编号。一个总线最多可附接32个设备。
功能编号:用于在一个扩展卡,实现包括多个扩展设备的设备(IDE控制器、USB控制器等等)。扩展设备必须通过功能编号来进行区分。PCI标准将一个设备上功能部件最大数目为8,每个设备都通过一个16位编号唯一标识(8位用于总线编号,5位用于插槽编号,3位用于功能编号)
PCI配置空间,PCI有三个相互独立的物理地址(IO地址空间、配置空间、设备存储器地址空间)
PCI总线规范配置空间总长度为256个字节。
PCI 配置空间布局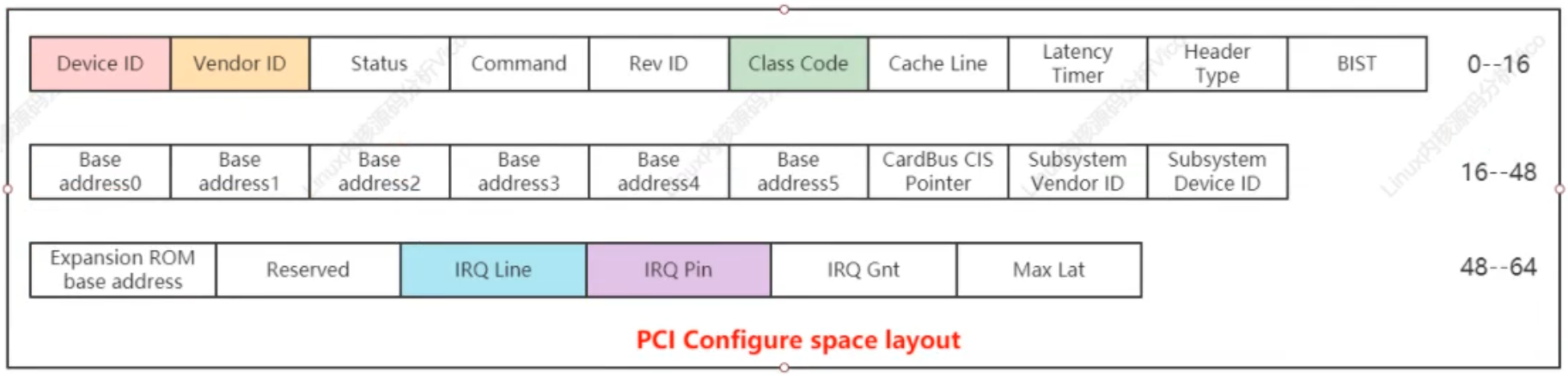
Device ID:设备ID
Vendor ID:厂商ID
Rev ID:用于区分不同设备修订级别
Class Code:用于将设备分配到各种不同的功能组
基类及子类pci_ids.h中对应常数的名称:
大容量的存储器(PCI_BASE_CLASS_STOREAGE):SCSI、IDE、RAID
网络(PCI_BASE_CLASS_NETWORK):以太网、FDDI
系统组件(PCI_BASE_CLASS_SYSTEM):实时时钟、DMA控制器
PCI 总线数据结构
在内存中,每个 PCI 总线都通过 pci_bus 数据结构的一个实例表示,该结构定义如下: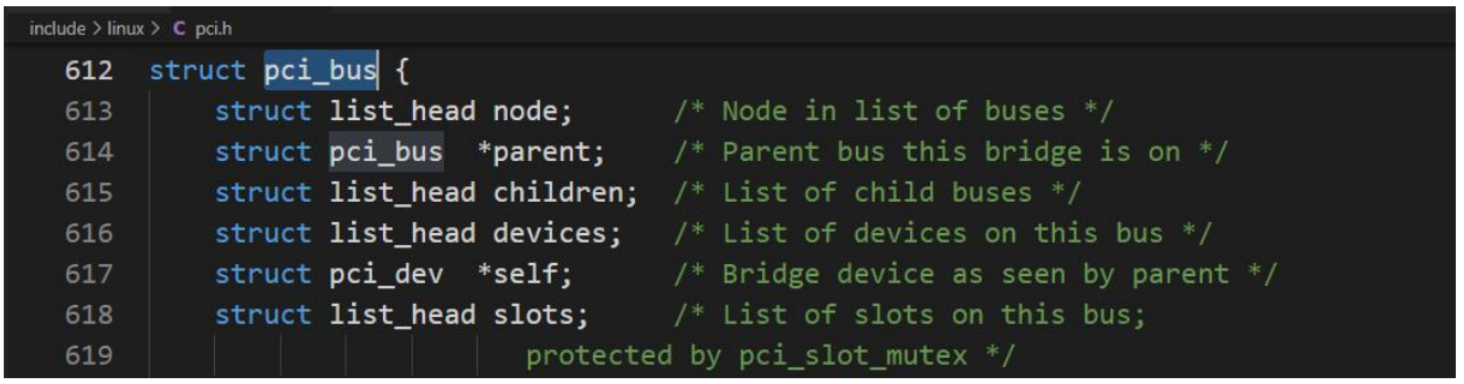
结构成员:系统中的各个总线由pci_bus的实例表示;
pci_dev结构表示各个设备、扩展卡和功能部件;
每个驱动程序都通过pci_driver的一实例描述。
4、设备管理
struct pci_dev 是一个关键的数据结构,用于表示系统中的各个 PCI 设备。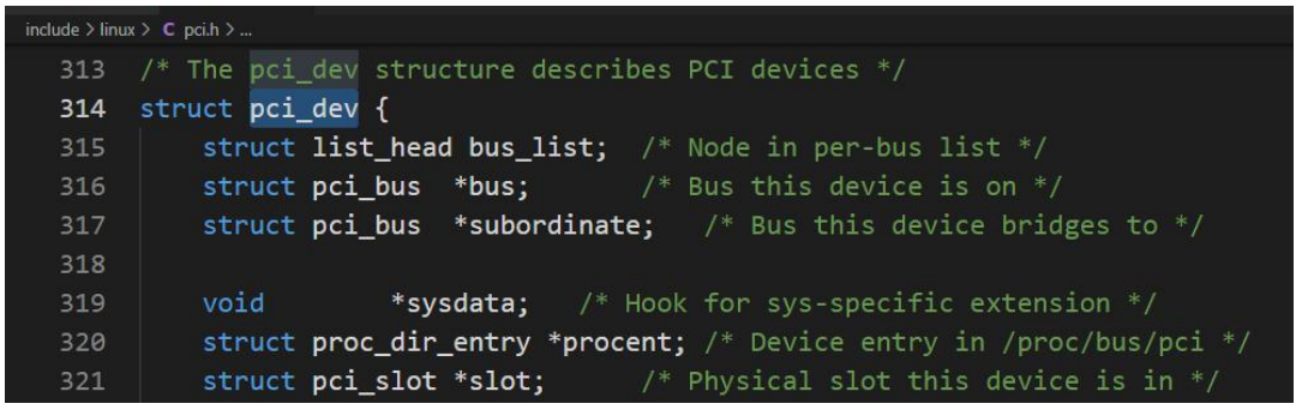
5、驱动程序函数
PCI 层中最后一个基本的数据结构是 pci_driver。它用于实现 PCI 驱动程序,表示了通用内核代码和设备的底层硬件驱动程序之间的接口。每个 PCI 驱动程序都必须将其函数填到该接口中,使得内核能够一致地控制可用的驱动程序。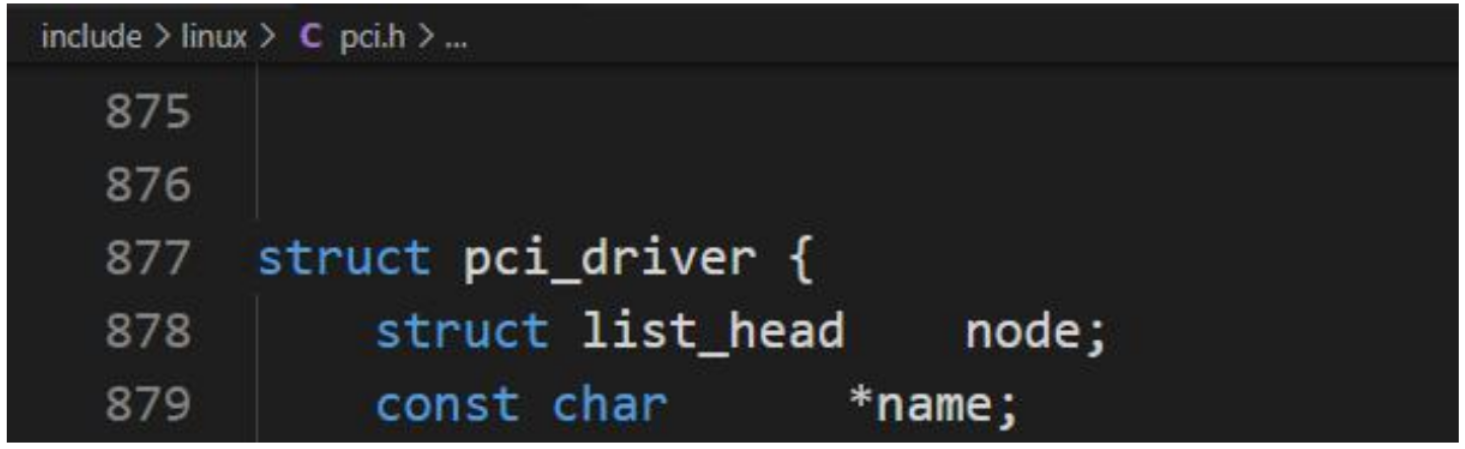
6、注册驱动程序
PCI 驱动程序可以通过 pci_register_driver 注册。该函数十分简单,其主要任务是,对相关函数已经分配的一个 pci_device 实例,填充一些剩余的字段。
![[附源码]计算机毕业设计二次元信息分享平台的设计及实现](https://img-blog.csdnimg.cn/a368dfa3bf2842058df943b87303bf0d.png)