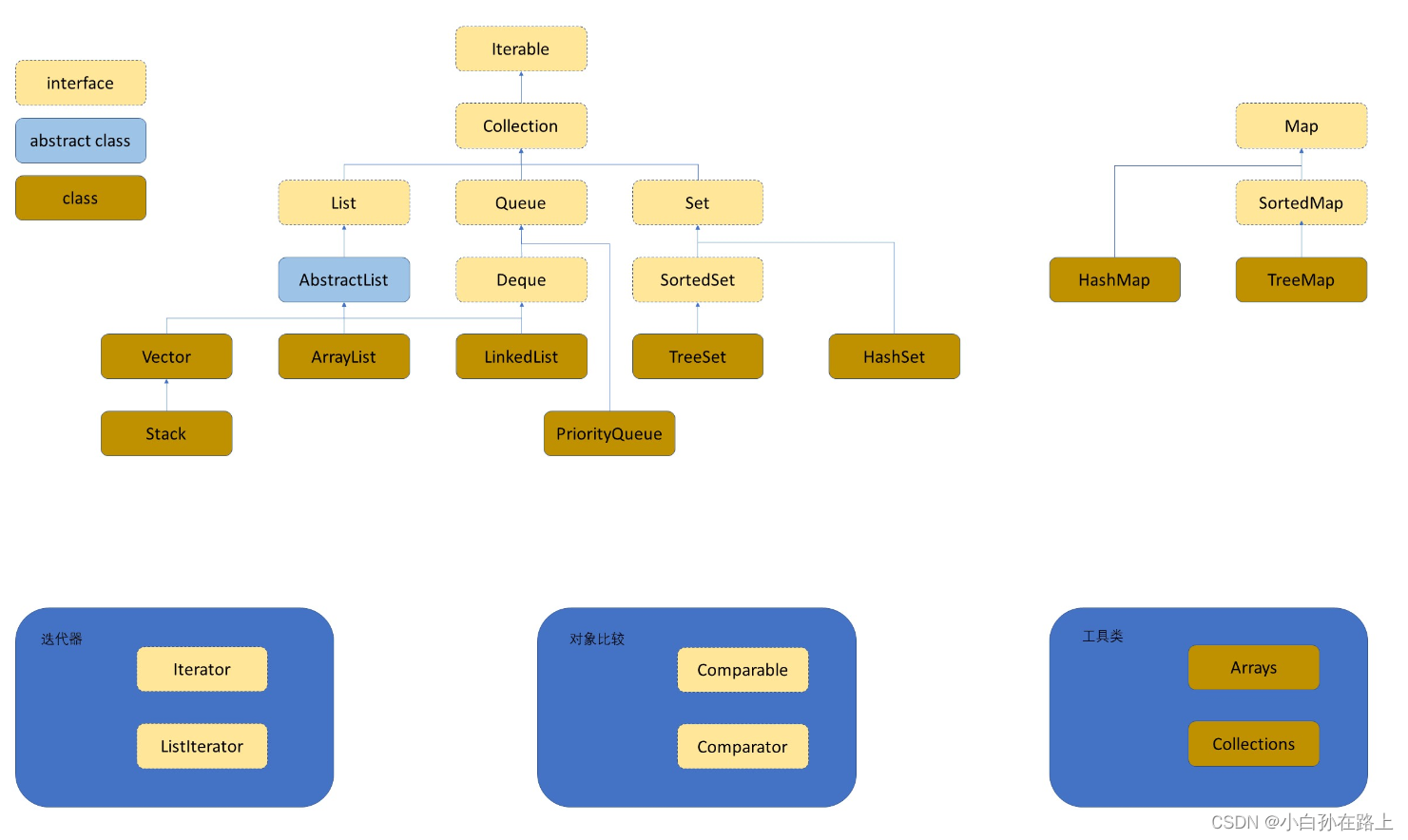
目录
一,泛型
1 什么是泛型
2 引出泛型
2.1语法
3 泛型类的使用
3.1 语法
3.2 示例
3.3 类型推导(Type Inference)
4.裸类型(Raw Type)
5 泛型如何编译的
5.2 为什么不能实例化泛型类型数组
6 泛型的上界
6.1 语法
6.3 复杂示例
7 泛型方法
7.1 定义语法
二.通配符
2 通配符上界
通配符下界
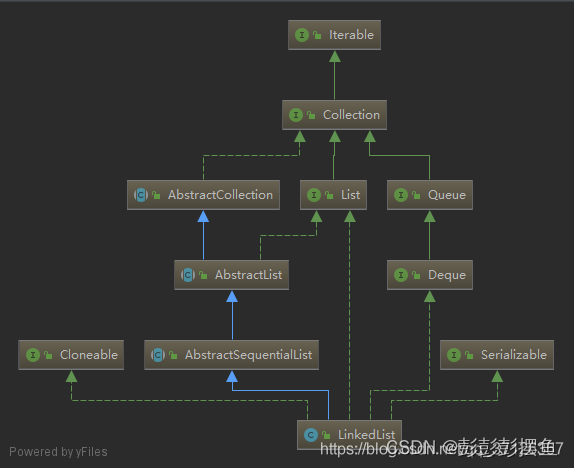
三.Map和Set
1.搜索
1.1 概念及场景
1.2模型
2.Map 的使用
2.1 关于Map的说明
2.2 关于Map.Entry的说明
2.3 Map 的常用方法说明
7. TreeMap和HashMap的区别
3.Set 的说明
4.练习
一,泛型
1 什么是泛型
一般的类和方法,只能使用具体的类型: 要么是基本类型,要么是自定义的类。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大。----- 来源《Java编程思想》对泛型的介绍。
泛型是在JDK1.5引入的新的语法,通俗讲,泛型:就是适用于许多许多类型。从代码上讲,就是对类型实现了参数化。
2 引出泛型
实现一个类,类中包含一个数组成员,使得数组中可以存放任何类型的数据,也可以根据成员方法返回数组中某个下标的值?
思路:
1.我们以前学过的数组,只能存放指定类型的元素,例如:int[] array = new int[10]; String[] strs = new String[10];
2.所有类的父类,默认为Object类。数组是否可以创建为Object?
class MyArray {
public Object[] array = new Object[10];
public Object getPos(int pos) {
return this.array[pos];
}
public void setVal(int pos,Object val) {
this.array[pos] = val;
}
}
public class TestDemo {
public static void main(String[] args) {
MyArray myArray = new MyArray();
myArray.setVal(0,10);
myArray.setVal(1,"hello");//字符串也可以存放
String ret = myArray.getPos(1);//编译报错
System.out.println(ret);
}
}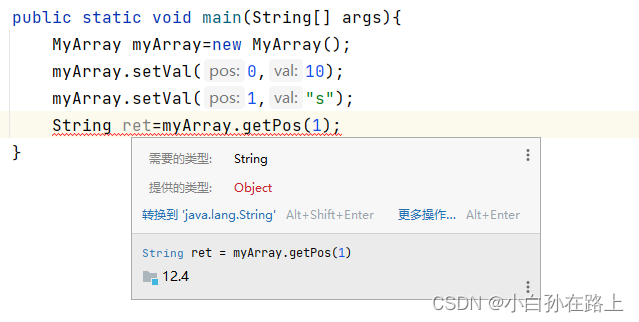

问题:以上代码实现后 发现
- 任何类型数据都可以存放
- 1号下标本身就是字符串,但是确编译报错。必须进行强制类型转换
虽然在这种情况下,当前数组任何数据都可以存放,但是,更多情况下,我们还是希望他只能够持有一种数据类型。而不是同时持有这么多类型。所以,泛型的主要目的:就是指定当前的容器,要持有什么类型的对象。让编译器去做检查。此时,就需要把类型,作为参数传递。需要什么类型,就传入什么类型。
2.1语法
class 泛型类名称<类型形参列表> {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> {
}
class 泛型类名称<类型形参列表> extends 继承类/* 这里可以使用类型参数 */ {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {
// 可以只使用部分类型参数
}
class MyArray<T> {
public T[] array = (T[])new Object[10];//1这种是错误的
public T getPos(int pos) {
return this.array[pos];
}
public void setVal(int pos,T val) {
this.array[pos] = val;
}
}
public class TestDemo {
public static void main(String[] args) {
MyArray<Integer> myArray = new MyArray<>();//2
myArray.setVal(0,10);
myArray.setVal(1,12);
int ret = myArray.getPos(1);//3
System.out.println(ret);
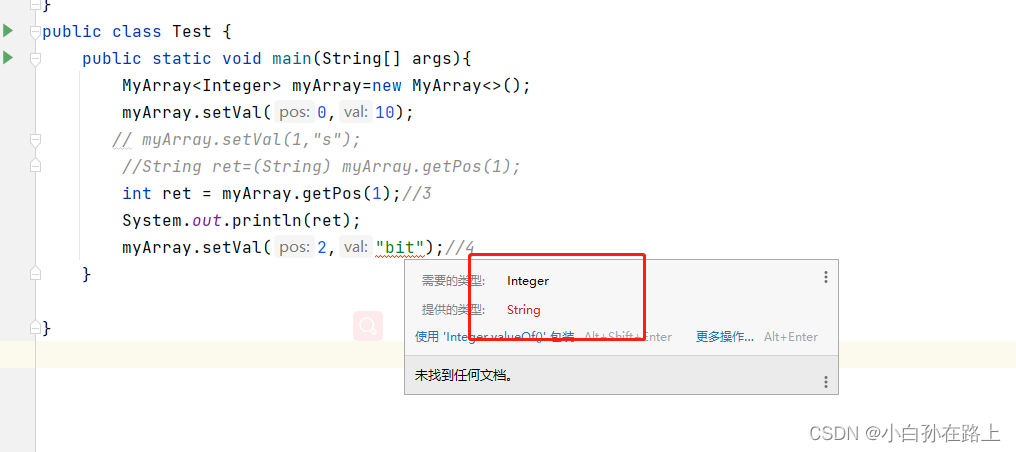
myArray.setVal(2,"bit");//4
}
}类名后的 代表占位符,表示当前类是一个泛型类
1.【规范】类型形参一般使用一个大写字母表示,常用的名称有:
E 表示 Element
K 表示 Key
V 表示 Value
N 表示 Number
T 表示 Type
S, U, V 等等 - 第二、第三、第四个类型
2.注释1处,不能new泛型类型的数组

- 注释2处,类型后加入 指定当前类型
- 注释3处,不需要进行强制类型转换
- 注释4处,代码编译报错,此时因为在注释2处指定类当前的类型,此时在注释4处,编译器会在存放元素的时
候帮助我们进行类型检查。
3 泛型类的使用
3.1 语法
泛型类<类型实参> 变量名; // 定义一个泛型类引用 new 泛型类<类型实参>(构造方法实参); // 实例化一个泛型类对象
3.2 示例
MyArray<Integer> list = new MyArray<Integer>();
注意:泛型只能接受类,所有的基本数据类型必须使用包装类!不能用int
3.3 类型推导(Type Inference)
当编译器可以根据上下文推导出类型实参时,可以省略类型实参的填写
MyArray<Integer> list = new MyArray<>(); // 可以推导出实例化需要的类型实参为 Integer
4.裸类型(Raw Type)
裸类型是一个泛型类但没有带着类型实参,例如 MyArrayList 就是一个裸类型
MyArray list = new MyArray();
注意: 我们不要自己去使用裸类型,裸类型是为了兼容老版本的 API 保留的机制
下面的类型擦除部分,我们也会讲到编译器是如何使用裸类型的。
小结:
- 泛型是将数据类型参数化,进行传递
- 使用 表示当前类是一个泛型类。
- 泛型目前为止的优点:数据类型参数化,编译时自动进行类型检查和转换
5 泛型如何编译的
通过命令:javap -c 查看字节码文件,所有的T都是Object。
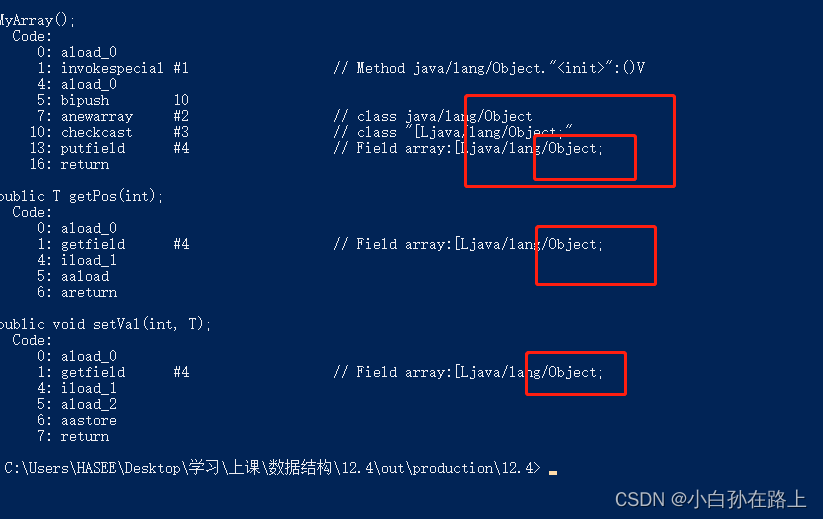
在编译的过程当中,将所有的T替换为Object这种机制,我们称为:擦除机制。
Java的泛型机制是在编译级别实现的。编译器生成的字节码在运行期间并不包含泛型的类型信息。
Java泛型擦除机制之答疑解惑 - 知乎
1、那为什么,T[] ts = new T[5]; 是不对的,编译的时候,替换为Object,不是相当于:Object[] ts = new
Object[5]吗?
2、类型擦除,一定是把T变成Object吗?
5.2 为什么不能实例化泛型类型数组
class MyArray<T> {
public T[] array = (T[])new Object[10];
public T getPos(int pos) {
return this.array[pos];
}
public void setVal(int pos,T val) {
this.array[pos] = val;
}
public T[] getArray() {
return array;
}
}
public static void main(String[] args) {
MyArray<Integer> myArray1 = new MyArray<>();
Integer[] strings = myArray1.getArray();
}
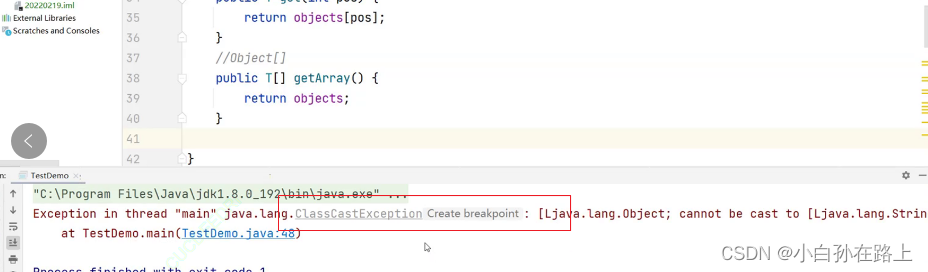
/*
Exception in thread "main" java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.Integer;
at TestDemo.main(TestDemo.java:31)
*/原因:替换后的方法为:将Object[]分配给Integer[]引用,程序报错。
通俗讲就是:返回的Object数组里面,可能存放的是任何的数据类型,可能是String,可能是Person,运行的时候,直接转给Integer类型的数组,编译器认为是不安全的。

class MyArray<T> {
public T[] array;
public MyArray() {
}
/**
* 通过反射创建,指定类型的数组
* @param clazz
* @param capacity
*/
public MyArray(Class<T> clazz, int capacity) {
array = (T[])Array.newInstance(clazz, capacity);
}
public T getPos(int pos) {
return this.array[pos];
}
public void setVal(int pos,T val) {
this.array[pos] = val;
}
public T[] getArray() {
return array;
}
}
public static void main(String[] args) {
MyArray<Integer> myArray1 = new MyArray<>(Integer.class,10);
Integer[] integers = myArray1.getArray();
}
6 泛型的上界
在定义泛型类时,有时需要对传入的类型变量做一定的约束,可以通过类型边界来约束。
6.1 语法
class 泛型类名称<类型形参 extends 类型边界> {
...
}
public class MyArray<E extends Number> {
......
只接受 Number 的子类型作为 E 的类型实参
MyArray<Integer> l1; // 正常,因为 Integer 是 Number 的子类型
MyArray<String> l2; // 编译错误,因为 String 不是 Number 的子类型
error: type argument String is not within bounds of type-variable E
MyArrayList<String> l2;
^
where E is a type-variable:
E extends Number declared in class MyArrayList没有指定类型边界 E,可以视为 E extends Object
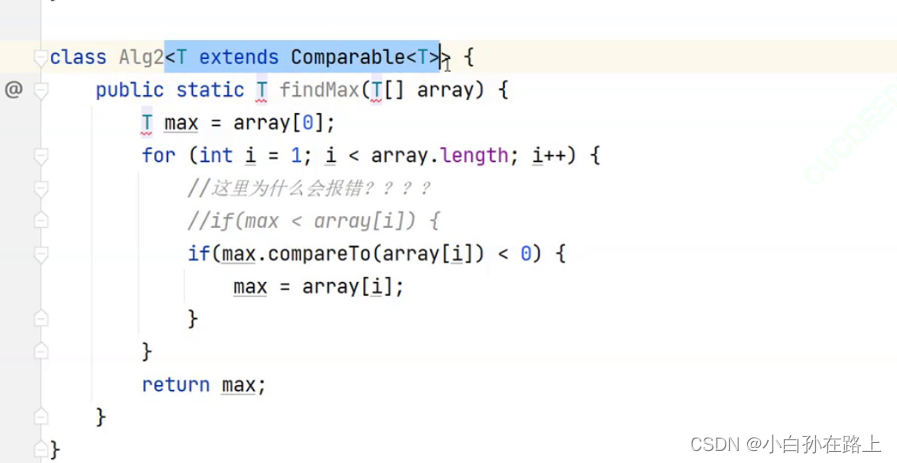
6.3 复杂示例
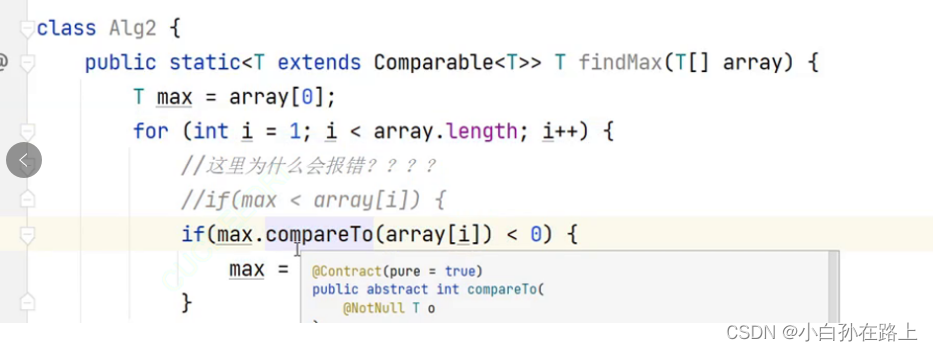
public class MyArray<E extends Comparable<E>> { ... }
E必须是实现了Comparable接口的


泛型的参数都是引用类型 需要用copare来比较 java的类都默认实现的是compareABLE接口

不是compareator比较器
如果没有指定上界.就会擦除到object但是object是没有实现compareAble接口的

所以就没有办法比较.所以我们就定义一个compare上界

具体的代码实现

class Alg<T extends Comparable<T>>{
public T findMax(T[] array){
T max=array[0];
for (int i = 0; i < array.length; i++) {
/* if(max<array[i]){
max=array[i];
}*/
if(max.compareTo(array[i])<0){
max=array[i];
}
}
return max;
}
}7 泛型方法
7.1 定义语法
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) { ... }
public class Util {
//静态的泛型方法 需要在static后用<>声明泛型类型参数
public static <E> void swap(E[] array, int i, int j) {
E t = array[i];
array[i] = array[j];
array[j] = t;
}
}
加上static表示不需要new对象的,就没有那个参数的传递了.所以会报错

就默认是这样
二.通配符
? 用于在泛型的使用,即为通配符


传给他的是任何类型,只能用object来接收

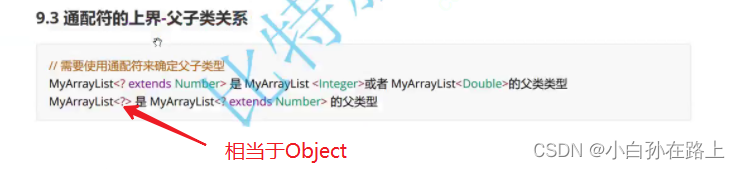
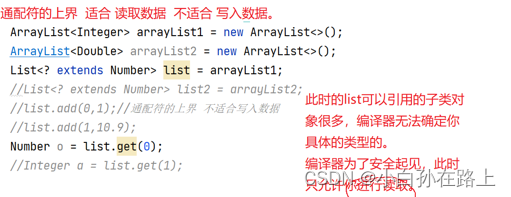
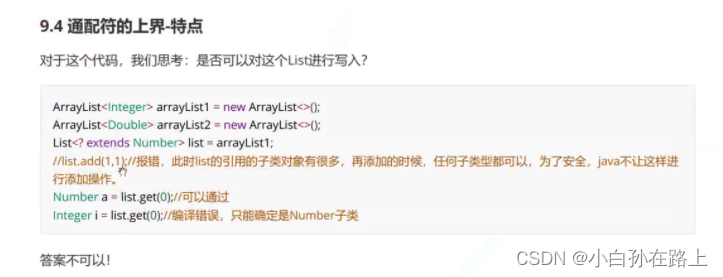
2 通配符上界
<? extends 上界>
<? extends Number>//可以传入的实参类型是Number或者Number的子类
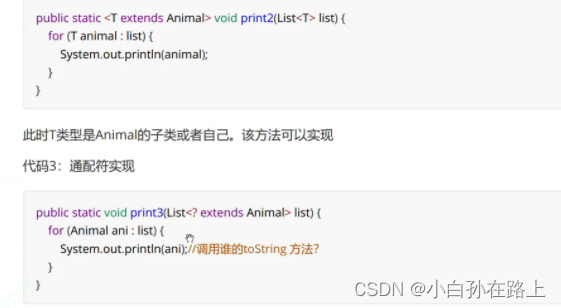
传入的是谁就调用谁的toString 但是我们用的是Animal接收,这里就发生了向上转型.


通配符下界

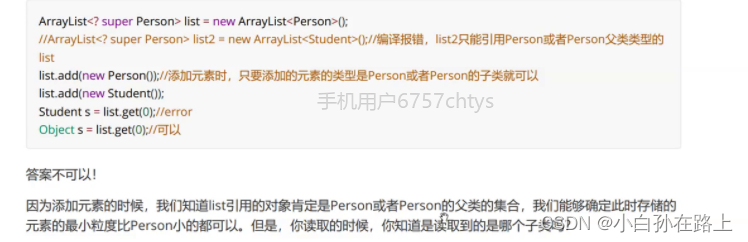
// 可以传入类型实参是 Integer 父类的任意类型的 MyArrayList
public static void printAll(MyArrayList<? super Integer> list) {
...
}
// 以下调用都是正确的
printAll(new MyArrayList<Integer>());
printAll(new MyArrayList<Number>());
printAll(new MyArrayList<Object>());
// 以下调用是编译错误的
printAll(new MyArrayList<String>());
printAll(new MyArrayList<Double>());


三.Map和Set
1.搜索
1.1 概念及场景
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。以前常见的
搜索方式有
- 直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
- 二分查找,时间复杂度为 ,但搜索前必须要求序列是有序的
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
- 根据姓名查询考试成绩
- 通讯录,即根据姓名查询联系方式
- 不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,本节介绍的Map和Set是
一种适合动态查找的集合容器
1.2模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以
模型会有两种:
- 纯 key 模型,比如:
有一个英文词典,快速查找一个单词是否在词典中
快速查找某个名字在不在通讯录中
2. Key-Value 模型,比如:
统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:
梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
而Map中存储的就是key-value的键值对,Set中只存储了Key。
2.Map 的使用
2.1 关于Map的说明
Map是一个接口类,该类没有继承自Collection,该类中存储的是结构的键值对,并且K一定是唯一的,不能重复。

2.2 关于Map.Entry的说明
Map.Entry 是Map内部实现的用来存放键值对映射关系的内部类,该内部类中主要提供了
的获取,value的设置以及Key的比较方式


2.3 Map 的常用方法说明
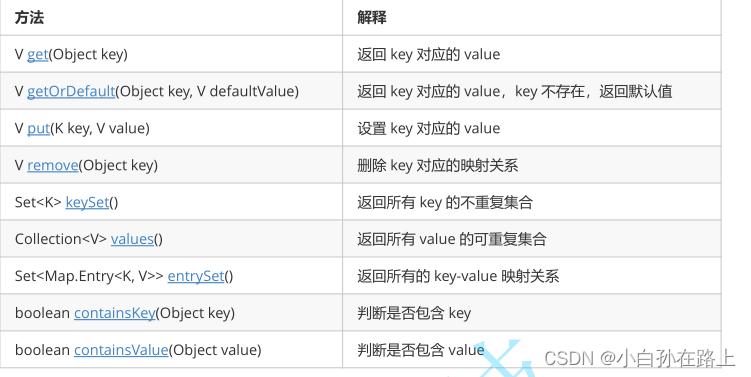
注意:
- Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap
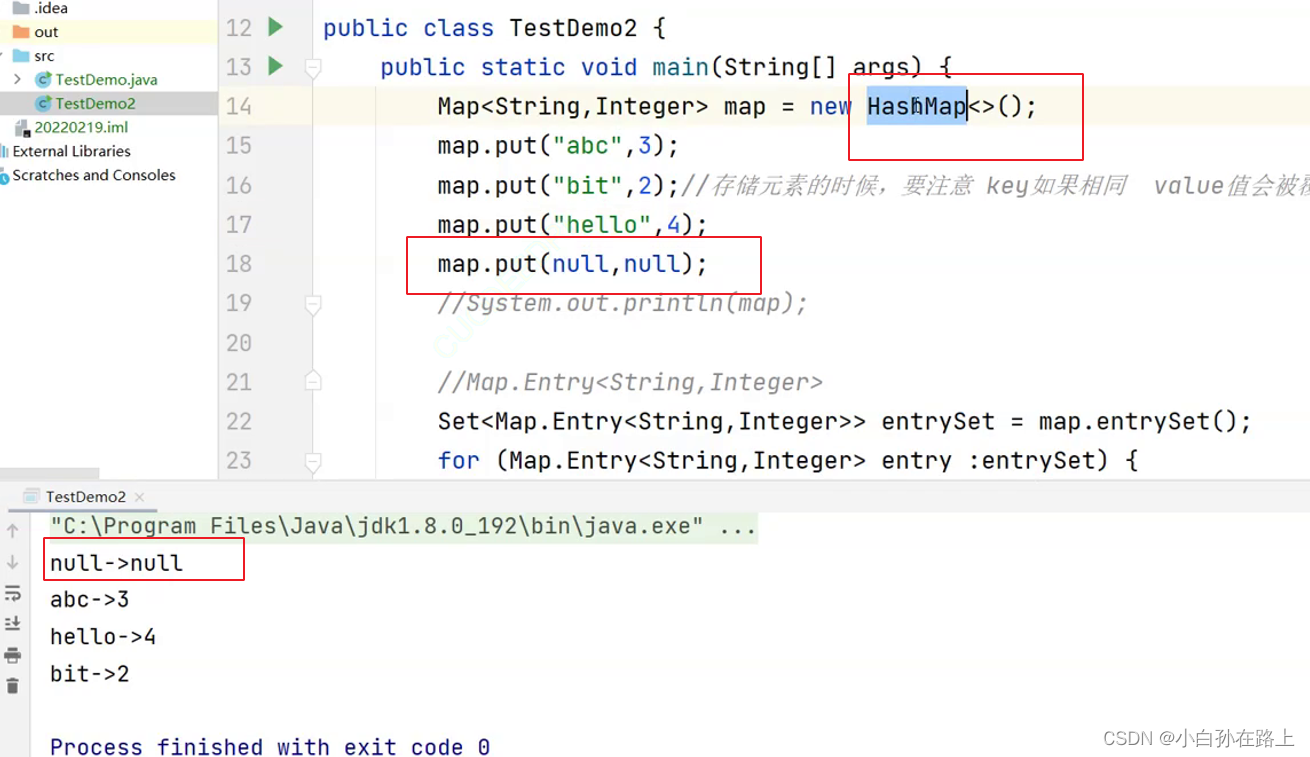
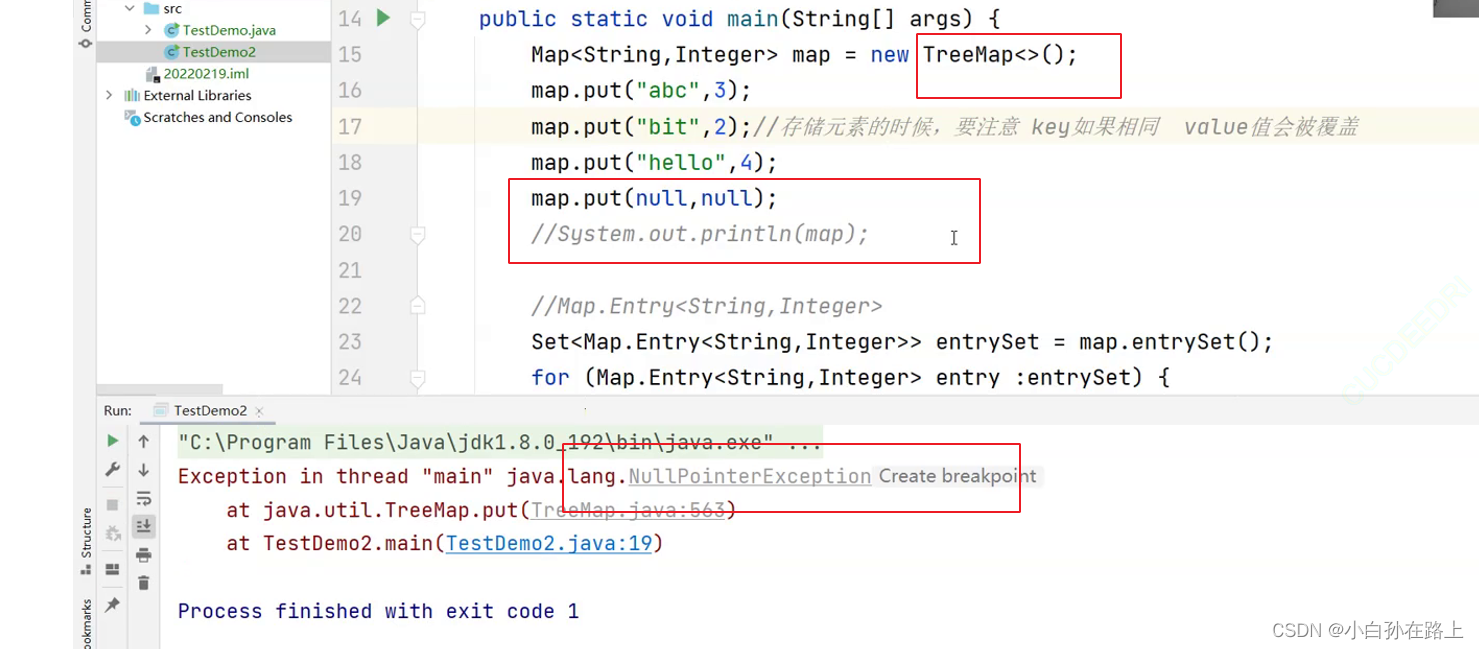
- Map中存放键值对的Key是唯一的,value是可以重复的
- 在Map中插入键值对时,key不能为空,否则就会抛NullPointerException异常,但是value可以为空
- Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
- Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
- Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行
重新插入。
7. TreeMap和HashMap的区别

3.Set 的说明
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key
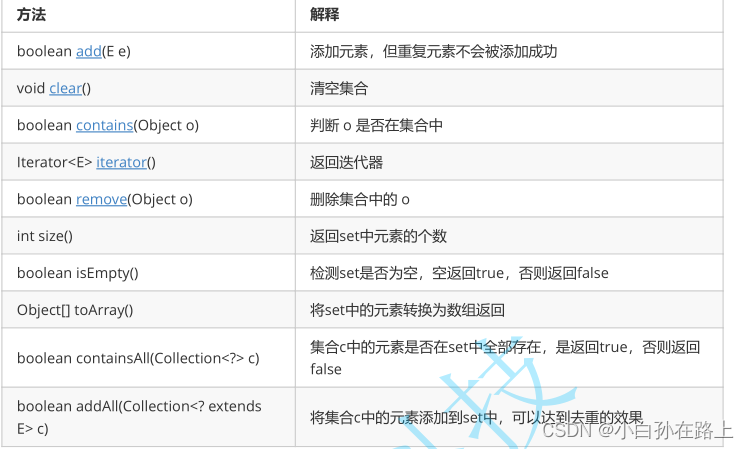
注意:
- Set是继承自Collection的一个接口类
- Set中只存储了key,并且要求key一定要唯一
- Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
- Set最大的功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础
上维护了一个双向链表来记录元素的插入次序。
6. Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
7. Set中不能插入null的key。
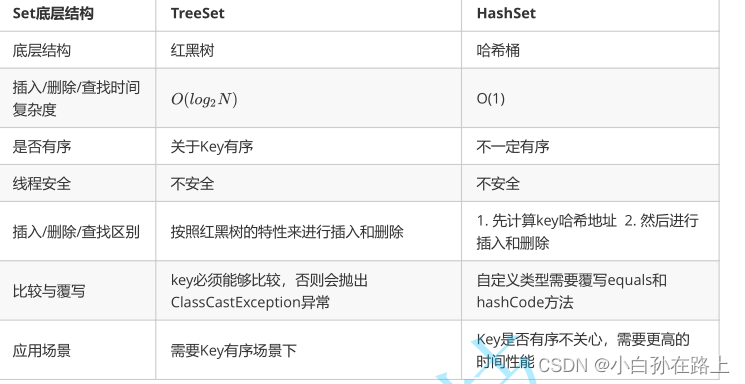
8. TreeSet和HashSet的区别

4.练习
遍历,按顺序放,如果map有就让对应的val值+1/没有,就设置为1
最后打印

- 只出现一次的数字
- 复制带随机指针的链表
- 宝石与石头
- 坏键盘打字
- 前K个高频单词