我的scala版本为2.12
<scala.binary.version>2.12</scala.binary.version>我的Flink版本为1.13.6
<flink.version>1.13.6</flink.version>FlinkSql读取kafka数据流需要如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>我们首先建一个kafka主题person_test。然后建立一个scala类作为kafka的生产者,示例内容如下:
package cha01
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import java.util.Properties
import Util._
import scala.util.Random
object FlinkSqlKafkaConnectorProducer {
def main(args: Array[String]): Unit = {
val producerConf = new Properties()
producerConf.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"single01:9092")
producerConf.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"10")
producerConf.setProperty(ProducerConfig.LINGER_MS_CONFIG,"50")
producerConf.setProperty(ProducerConfig.RETRIES_CONFIG,"2")
producerConf.setProperty(ProducerConfig.ACKS_CONFIG,"1")
producerConf.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.IntegerSerializer")
producerConf.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val topic = "person_test"
val producer:KafkaProducer[Integer,String] = new KafkaProducer(producerConf);
val rand = new Random()
for(i <- 1 to 2000){
val line: String = s"$i,Origami$i,${rand.nextInt(30)+18},${if (rand.nextInt(10) >=8) "Male" else "Female"}"
val record: ProducerRecord[Integer, String] =
new ProducerRecord[Integer, String](topic, 0, System.currentTimeMillis(), i, line)
producer.send(record)
Thread.sleep(50+rand.nextInt(500))
}
producer.flush()
producer.close()
}
}
此kafka生产者会随机生产出一系列类似以下内容的数据,类型为csv:
id,name,age,gender
1,Origami1,25,Female
2,Origami2,30,Male
3,Origami3,22,Female随后再在工程中建立一个scala类,内容示例如下:
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object CSVKafkaSystem {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val see: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tabEnv: StreamTableEnvironment = StreamTableEnvironment.create(see)
tabEnv.executeSql(
"""
|CREATE TABLE person(
|id INT,
|name STRING,
|age INT,
|gender STRING
|) WITH (
|'connector' = 'kafka',
|'topic'= 'person_test',
|'properties.bootstrap.servers' = 'single01:9092',
|'properties.group.id' = 'person_test_group',
|'scan.startup.mode' = 'earliest-offset',
|'format' = 'csv',
|'csv.ignore-parse-errors' = 'true',
|'csv.field-delimiter' = ','
|)
|""".stripMargin)
tabEnv.sqlQuery("SELECT * FROM person").execute().print()
}
}
其中的一些参数解释如下:'
connector' = 'kafka'
指定连接器类型为kafka
'topic'= 'person_test'
指定要读取的kafka主题为person_test
'properties.bootstrap.servers' = 'single01:9092'
指定kafka所在的服务器的ip地址以及端口号
'properties.group.id' = 'person_test_group'
指定 Kafka 消费者组的 ID为person_test_group
'scan.startup.mode' = 'earliest-offset'
指定了控制 Flink 从 Kafka 中读取数据时的起始位置
earliest-offset表示从 Kafka 中每个分区的最早消息开始读取。latest-offset表示从 Kafka 中每个分区的最新消息开始读取。group-offsets表示使用 Kafka 消费者组的偏移量来恢复上次消费的位置
'format' = 'csv'
指定了 kafka 消息的格式为csv
'csv.ignore-parse-errors' = 'true'
指定了忽略解析异常的信息
'csv.field-delimiter' = '
指定 CSV 数据中字段的分隔符为,
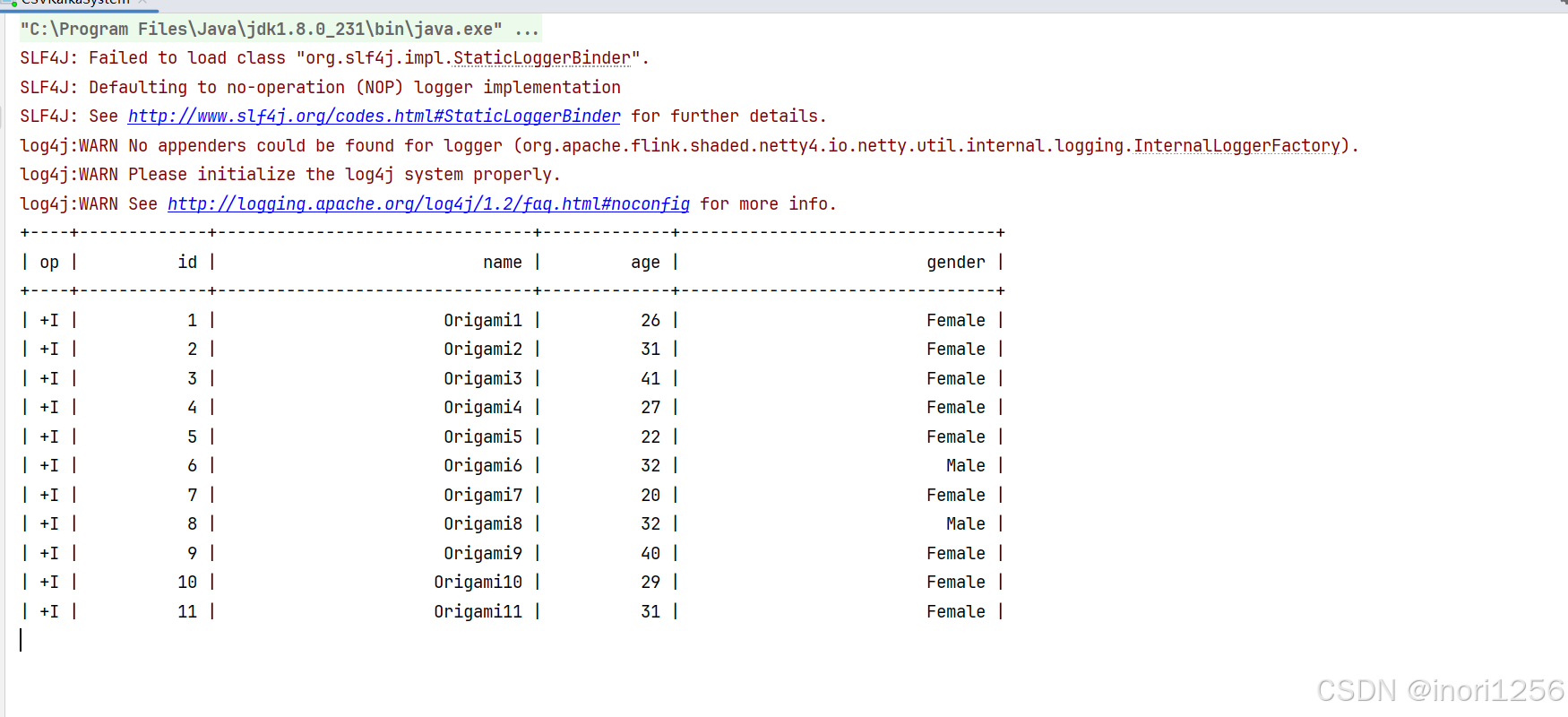
可以看到最终结果如下,数据在源源不断的生成,flinkSQL也在源源不断的读取表内容